UNIVERSIDADE DE SÃO PAULO
Faculdade de Arquitetura e Urbanismo
DISTRIBUIÇÃO AMOSTRAL
ESTIMAÇÃO
AUT 516
Estatística Aplicada a Arquitetura e Urbanismo
2
DISTRIBUIÇÃO AMOSTRAL
Na aula anterior analisamos as técnicas de descrição de dados coletados de uma amostra
extraída de uma população. Esses dados foram tabulados e organizados em forma de
gráficos de freqüências. Estes gráficos nós chamamos de histogramas quando
apresentavam barras para representar as freqüências, mas que podiam apresentar outras
formas, como o gráfico de “pizza”.
Analisamos também os principais descritores das amostras, e para isso calculamos as
medidas de tendência central como a média, moda, mediana e, as medidas de dispersão
como a variância e o desvio padrão. Na seqüência analisamos o conceito de
probabilidade junto com as distribuições teóricas de probabilidades das variáveis
aleatórias discretas e contínuas, com o objetivo de estudar o conceito de inferência
estatística Como vimos anteriormente, o objetivo da inferência estatística é descrever
uma realidade que está presente na população a partir de uma amostra extraída desta
população.
Nesta apostila vamos estudar alguns exemplos de inferência estatística focando uma
característica específica da população: os valores médios. Para isso vamos considerar um
descritor particular da amostra, que é a média amostral. Antes de iniciarmos o processo
de inferência estatística apresentamos abaixo alguns conceitos essenciais.
Suponhamos que levamos a cabo um processo de amostragem, ou seja, retiramos várias
amostras de dados de uma população. Neste caso é importante que tenhamos em conta
que:
● Toda medida descritiva e numérica de uma população é única e é
chamada de parâmetro.
● Todo valor obtido por cálculo de uma série de observações de uma
amostra é denominada de estatística.
● Os valores de diversas médias amostrais tiradas de uma população,
não são necessariamente iguais entre si, mas podem variar.
● Os valores das médias amostrais não são necessariamente iguais ao
valor da média da população.
● O conjunto das médias amostrais forma uma série de médias sobre a
qual podemos calcular uma média e um desvio padrão.
● A existência de uma variabilidade nos valores das diversas médias
amostrais gera uma distribuição de freqüências, que terá uma média
das médias e um desvio padrão da variação das médias em torno da
média (das médias).
2
3
● A distribuição de freqüências das médias amostrais é chamada de
distribuição amostral.
● Cada média amostral é uma variável aleatória, é denominada
estatística e é representada por . Já O desvio padrão da distribuição
amostral é chamado de erro padrão, e é representado por σ .
● A média da população é denominada parâmetro e é representada por
μ. Já o desvio padrão da população é denominado parâmetro e é
representado por σ .
● Na inferência estatística os parâmetros da população μ e σ serão
considerados conhecidos. Na verdade estes parâmetros não são
conhecidos, mas essa premissa é útil para o entendimento do conceito
de distribuição amostral.
Exemplo 1
Suponhamos que são formados 10 grupos de alunos de estatística da FAU e que cada
grupo tenha como tarefa calcular a média do número de pessoas vivendo em 100
domicílios em um bairro da cidade. Como cada grupo levanta dados em um único bairro,
ao concluírem a tarefa estes alunos terão formado uma série 10 médias amostrais
representadas como 1, 2, 3, ..., 10.
Estas 10 médias amostrais calculada pelos alunos são denominadas de estatísticas.
● Os 10 valores das médias amostrais serão em sua maioria diferentes.
● Os valores das médias amostrais não serão iguais ao valor da média da população.
● As 10 médias amostrais formaram uma série de médias sobre a qual se pode calcular
sua média e seu desvio padrão.
Devido o fato do valor da média amostral ser uma variável obtém-se uma distribuição
amostral das médias, o que significa que os valores das médias amostrais têm sua própria
distribuição de freqüências. Se outros 10 grupos de alunos fizerem novas amostragens
nestes mesmos bairros em domicílios selecionados ao acaso, teremos novos valores de
médias amostrais, em geral diferentes dos valores obtidos pelos 10 grupos anteriores.
Cada média amostral é uma estatística e é também uma variável aleatória que possui
uma distribuição de freqüências, um valor próprio de média e de desvio padrão. À
distribuição de freqüências das médias amostrais denomina-se distribuição amostral, e
ao desvio padrão denomina-se erro padrão.
3
4
Teorema do Limite Central
À medida que o tamanho da amostra aumenta, a distribuição de freqüências das médias
amostrais tende a se aproximar cada vez mais da distribuição normal. Em outras
palavras: se o tamanho n da amostra for suficientemente grande, a média de uma
amostra aleatória retirada de uma população de dados , terá uma distribuição de
aproximadamente normal independentemente da população.
Já se a população tem distribuição normal, então a média amostral terá distribuição
normal qualquer que seja o tamanho da amostra.
Pelo teorema do limite central pode-se afirmar então que a distribuição da média
amostral é aproximadamente normal e que os valores da média e desvio padrão estão
relacionados com os valores da média e desvio padrão da população.
Assim se uma população de dados tem média μ e desvio padrão σ, da qual se retira uma
amostra de tamanho n e média amostral
, pode-se afirmar que:
O valor esperado das médias amostrais E [ ] é igual à média da população:
E[ ] = μ
O desvio padrão da distribuição amostral (denominado erro padrão) é igual:
σ
= σ x σ / √n
Exemplo: Seja uma população formada por 5 vias arteriais de uma cidade que
apresentam os seguintes índices de congestionamento nos horários de pico:
Via
km/Cong.
A
2
B
4
C
6
D
8
E
10
Vamos selecionar (por sorteio) uma amostra formada por duas vias para avaliar o índice
médio de congestionamento da cidade. Observe que uma das vias tem a mesma chance
de ser selecionada (mesma probabilidade). Observe também que dependendo das vias
sorteadas o índice de congestionamento pode ficar acima ou abaixo da média. Neste
caso devemos definir o espaço amostral e determinar o valor esperado das médias
amostrais
de tamanho n = 2 retiradas da população:
Solução:
- a média do congestionamento da população formada pelas 5 vias é igual a 6 km.
- cada uma das 5 vias tem probabilidade 20% de ser sorteada.
4
5
- Espaço amostral:
2,4
3
Amostra
Média
2,6
4
2,8
5
2,10
6
4,6
5
4,8
6
4,10
7
8
10%
9
6,8
7
6,10
8
8,10
9
- Distribuição de Freqüências das médias amostrais
Média
Freqüência
3
4
5
10%
10%
20%
6
20%
7
20%
10%
- Valor Esperado das Médias Amostrais
E[ ] = 3 x0,1 + 4 x0,1 + 5 x0,2 + 6 x0,2 + 7 x0,2 + 8 x0,1 + 9 x0,1 = 6 = μ
Histograma
3
2
2
1
1
0
3
4
5
6
7
8
9
5
6
DISTRIBUIÇÃO NORMAL
Sabemos que a probabilidade de ocorrência de um evento em um levantamento
amostral é igual ao número de vezes que o evento ocorre dividido pelo tamanho da
amostra:
P (xi) = F (xi) / n
F = Freqüência;
P = Probabilidade
A média (ou valor esperado) de uma variável aleatória X é a somatória dos produtos dos
valores numéricos de cada variável pelas probabilidades (ou freqüências) de sua
ocorrência.
Assim:
Média = E (X) = ∑ xi . P(xi)
E = valor esperado = média ponderada
A Curva de Gaus é uma função matemática que serve para simular uma distribuição
Normal de freqüências da variável X. Assumindo portanto, que esta função serve para
descrever a variabilidade dos dados que estamos analisando, vamos utilizar as
propriedades desta função matemática para fazer inferências estatísticas.
Considerando uma variável aleatória contínua X que tenha uma função de probabilidade
f(x) cuja distribuição é aproximadamente similar à curva normal, podemos utilizar o
modelo de Gaus (ou da curva normal) para fazer inferências. Este modelo apresenta as
seguintes propriedades:
+∞
Valor esperado de X
∫
E (X) = μ = x f(x) dx
-∞
+∞
Variância de X
E [(X – E [X])2] = σ =
2
∫ (x - E[X])
2
f(x) dx
-∞
Função de densidade de probabilidade
A função densidade de probabilidade de uma variável aleatória X tem distribuição normal
2
com parâmetros de média μ e variância σ é assim definida,
Se a variável aleatória X tem uma distribuição aproximada da normal escreve-se:
X ~ N (μ,σ2).
6
7
Se μ = 0 e σ = 1, a distribuição é chamada de distribuição normal padrão e a função de
densidade de probabilidade se transforma em:
A distribuição normal é uma das mais importantes distribuições de frequências pois ela
representa a maioria dos casos na vida real.
Exemplo: Numa população de dados quando μ = 0 e σ = 1, a curva de distribuição nornal
f(X) para volores da variável aleatória X é apresentada na figura abaixo.
.
A distribuição normal permite calcular qualquer valor da probabilidade se for conhecida a
média e o desvio padrão de uma população sendo pesquisada.
Características da Distribuição Normal
1 – A curva é simétrica ao redor da média;
2 – A área sob a curva define 100% da probabilidade. Sendo cada metada tem 50% de
probabilidade;
3 – A probabilidade de um valor da variável estar entre o intervalo (m,n) é definida como:
P (m ≤ X ≥ n)
O valor da probabilidade: P (m ≤ X ≥ n) = área sob a curva entre os valores m e n
7
8
Distribuição Normal Padronizada
O cálculo das probabilidades de uma variavel X P(X), partir da da curva de Gauus é muito
trabalboso pois exige integrar a função f(X) da distribuição normal entre os limites
(-∞,+∞).
Para facilitar os cálculos os estatísticos desenvolveram cáculos para uma curva de
distribuição chamada de distribuição normal padronizada para a qual foi utilizado um
desvio padrão normalizado Z que serve como referencial de conversão para qualquer
distribuição normal de variaveis.
A variavel aleatória desvio padrão normalizado Z de uma distribuição normal
padronozada é dada pela seguinte fórmula:
Z=
X–μ
-----------σ
Utilizando a formula de transformacao, qualquer variavel aleatoria normal X é convertida
em uma variavel normal padronizada Z onde:
σ é o desvio padrão
μ é a média aritmética
Características da Distribuição Normal Padronizada
1 – E ( Z ) = 0 e Var ( Z ) = 1
2- A curva é simétrica em torno da média
3 – Após a transformação a curva da distribuição normal padronizada tem a mesma
forma que a distribuição normal, tendo como média μ = 0 e desvio padrão σ = 1
8
9
Tabela da Distribuição Normal Padrão
P(Z<z)
9
10
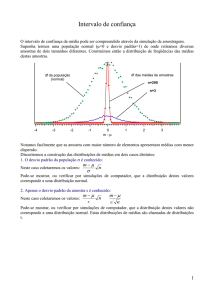
ESTIMAÇÃO
Nas seções anteriores vimos que a média
de uma amostra de tamanho grande n
retirada de uma população com média µ x e desvio padrão σx está contida numa
distribuição de médias amostrais que tem um valor esperado igula ao da média da
população e um desvio padrão igual a σ
= σx / √n.
O objetivo desta seção é estimar o valor da média de uma população a partir das
informações contidas numa única amostra. Este processo de uma inferir sobre a média
da população é chamado estimação.
Sabe-se que o valor da média da amostra nem sempre é igual ao da média da população,
portanto para estimar a média devemos ter um controle do erro cometido, pois não
conhecemos os valores dos parametros da população (média e desvio padrão). Assim o
objetivo é estimar os valores destes parametros fundamentando-se em conceitos de
probabilidade tendo em vista assegurar a confiabilidade da estimativa.
Estimativa da Média da População
Para estimar a média de uma população devemos:
1 – Selecionamos uma amostra aleatória desta população e calculamos a média
2 – Sabemos que a média da população é µ (embora não conhecida).
3 – A diferença entre o verdadeiro valor da média a média µ e o valor da média
.
amostral , chamamos de erro de estimativa.
4 – Estabelecer o intervalo de confiança
Intervalo de Confiança
O intervalo de confiança é um intervalo de valores—delimitado por um valor mínimo e
um valor máximo—que se utiliza para estimar um parâmetro desconhecido da
população, de tal maneira que permita afrimar que o verdadeiro valor do parâmetro ( no
caso a média) está contido dentro deste intervalo.
Sabemos que se o tamanho da amostra for suficintemente grande, as média amostrais
terão uma distribuição normal e terá um valor esperado igual à média da população.
Sabemos pelas propriedades da distribuição normal que 95,44% das médias amostrais se
situarão entre +2 e -2 desvios padraões em torno da média. Sabemos também que a
média da população estará situada dentro deste intervalo de +2 e -2 desvios padrões em
torno da média amostral em 95,44 das vezes. Em outras palavras se retirarmos infinitas
amostras podemos dizer que em 95,44% das vezes o valor da média da população estará
dentro do intervalo:
10
11
-2 σ
≤
- 2σ
Assim podemos dizer que:
em termos de probabilidade temos que,
- 2σ
P(
≤ µ
≤
≤ +2 σ
≤ µ ≤
+ 2σ
+ 2σ ) = 0,9544
Exemplo:
Numa amostra de 64 pessoas foi perguntado o pêso das mesmas e obteve-se como
média amostral 50 Kg. Sabe-se que o desvio padrão do peso das pessoas na população é
de 16. Pede-se estimar o valor da média da população para um intervalo de confiança de
95%.
Resolução:
Na tabela de distribuição normal, o valor da probabilidade de 95% em torno da média
determina os seguintes valores de Z:
Z= 1,96 e Z= + 1,96
Usando a fórmula:
-µ
Z
= __________
σ
/ √n.
±Zσ
µ
=
µ
= 50 ± 1,96. 16
46, 08 ≤
µ
≤ 53,9 2
11
12
Exemplo
Numa amostra de 100 domicílios selecionados ao acaso em vários bairros da cidade
obteve-se a média amostral de 5 para o número de pessoas vivendo por domicílio. O
desvio padrão da amostra foi de 4. Pede-se estimar a média de pessoas por domicílio na
cidade como um todo, para um intervalo de confiança de 80%, 90%, 95%, 99%..
Resolução:
Na tabela de distribuição normal, o valor da probabilidade para 90% os valores de Z são:
P (X)
Z
-
+
80%
±1,28
4,48
5,51
90%
±1,64
4,34
5,65
95%
±1,96
4,21
5,78
99%
±2,58
3,96
6,03
-µ
Z = _________
µ
=
± Z σ / √n
µ
= 5 ± 1,28. (4/ √100)
4,48 ≤ µ
≤ 5,51
µ
=
± Z σ / √n
µ
= 5 ± 1,64. (4/ √100) 4,34 ≤ µ
≤ 5,65
µ
=
± Z σ / √n
µ
= 5 ± 1,96. (4/ √100) 4,21 ≤ µ
≤ 5,78
µ
=
± Z σ / √n
µ
= 5 ± 2,58. (4/ √100) 3,96 ≤ µ
≤ 6,03
σ / √n.
-µ
Z = _________
σ / √n.
-µ
Z = _________
σ / √n.
-µ
Z = _________
σ / √n.
12