6. Amostragem e estimação pontual
Definição 6.1: População é um conjunto cujos elementos possuem qualquer característica em comum.
Definição 6.2: Amostra é um subconjunto da população.
Exemplo 6.1: Um partido encomenda uma sondagem sobre a intenção
de voto nele nas próximas eleições. Por exemplo, a sondagem poderá
ser baseada numa amostra (aleatória) da população de interesse de dimensão 10000 em 100000 votantes. Note-se que há uma v.a. para cada
eleitor, i.e.,
(
1, se o eleitor i tenciona votar no partido;
Xi =
0, c.c.,
podendo p = P (Xi = 1) = 1 − P (Xi = 0) (desconhecido) ser estimado pelo número de votantes sondados que tencionam votar a favor
do partido.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 96/200
Estatística descritiva e Inferência Estatística.
• Estatística descritiva: Parte da Estatística que visa sumariar e in-
terpretar conjuntos de dados numa análise exploratória.
• Inferência Estatística: Parte da Estatística que visa fazer induções
sobre características de uma população a partir de uma amostra da
mesma.
O estudo de uma população centra-se usualmente em uma ou mais
variáveis aleatórias. Em geral, a distribuição de probabilidade destas
quantidades não é completamente conhecida e, portanto, com base em
uma informação por amostragem, pode-se inferir estatisticamente sobre
os seus aspectos desconhecidos, e.g.,
• Estimação pontual ou intervalar de parâmetros distribucionais.
• Testes de hipóteses sobre o valor de parâmetros ou sobre o próprio
tipo distribucional daquelas variáveis aleatórias.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 97/200
Amostragem aleatória.
Importantes questões relativamente ao processo de amostragem:
• Como recolher a amostra?
• Qual a informação pertinente a retirar da amostra?
• Como se comporta esta informação quando a amostra tende para a
população?
Alguns tipos de amostragem:
• Amostragem aleatória simples: Todos os elementos da população
têm a mesma probabilidade de serem seleccionados.
• Amostragem por conglomerados: A população está dividida em
pequenos grupos (e.g., bairros, quarteirões, etc.), chamados conglomerados, que são amostrados aleatoriamente.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 98/200
• Amostragem estratificada: A população encontra-se dividida em
subpopulações ou estratos (e.g., classes sociais, graus de instrução, etc.), agrupados por alguma característica em comum, de cada
um dos quais se amostra aleatoriamente alguns dos seus elementos.
Estes tipos de amostragem têm em comum a recolha aleatória dos elementos da amostra. Todavia, há outros métodos de amostragem não
aleatórios, e.g., quando os elementos da amostra são voluntários (ensaios clínicos) ou são os únicos disponíveis.
Definição 6.3: Dada uma população a que está associada uma variável
aleatória X com uma certa distribuição de probabilidade, uma amostra aleatória (a.a.) de tamanho n dessa população é uma sequência de
n variáveis aleatórias X1 . . . , Xn independentes e identicamente distribuídas (i.i.d.).
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 99/200
Definição 6.4: Dada uma amostra aleatória (X1 . . . , Xn ) de uma população X com f.m.p. (f.d.p.) fX (x), a distribuição de probabilidade
amostral (f.m.p. ou f.d.p. conjunta) é dada por
f (x1 , . . . , xn ) =
n
Y
fXi (xi ) =
i=1
n
Y
fX (xi ).
i=1
Exemplo 6.1a: Uma a.a. da população de votantes no partido com n
elementos reporta-se a n v.a. X1 . . . , Xn i.i.d., tal que
(
1, se o eleitor i tenciona votar no partido;
Xi =
0, c.c.,
sendo p = P (Xi = 1) = 1 − P (Xi = 0), i = 1, . . . , n. Consequentemente, a respectiva distribuição de probabilidade amostral é dada por
n
Y
P
P
xi
xi
1−xi
n− i xi
i
f (x1 , . . . , xn ) =
p (1 − p)
=p
(1 − p)
.
i=1
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 100/200
Estatísticas.
Definição 6.5: Dada uma amostra (X1 . . . , Xn ) de uma população X,
uma estatística T é uma variável aleatória (vector aleatório) função da
amostra, i.e.,
T = T (X1 , . . . , Xn ).
As estatísticas mais comuns são:
Pn
• Média amostral: X̄ = 1
i=1 Xi .
n
• Variância amostral (corrigida): S 2 =
1
n−1
Pn
i=1 (Xi
• Mínimo amostral: X(1) = min(X1 , . . . , Xn ).
− X̄)2 .
• Máximo amostral: X(n) = max(X1 , . . . , Xn ).
• Amplitude amostral: R = X(n) − X(1) .
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 101/200
Definição 6.6: Um parâmetro é uma medida usada para descrever uma
característica da população.
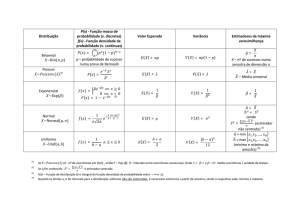
Notação usual de parâmetros e estatísticas:
Medida
População
média
µ
variância
σ2
número de elementos
N
proporção
p
Amostra
aleatória concreta
X̄
x̄
S2
s2
n
n
X̄
x̄
Se (X1 . . . , Xn ) é uma a.a. de uma população X, então
• média populacional: µ = E(X),
• média amostral: X̄ = (X1 + · · · + Xn )/n.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 102/200
Estimação pontual: estimador e estimativa.
Definição 6.7: Seja (X1 . . . , Xn ) uma amostra aleatória de uma população X indexada pelo parâmetro θ. Um estimador de θ é uma estatística
T = T (X1 , . . . , Xn ) usada para estimar θ.
Definição 6.8: O valor observado de um estimador em cada amostra
concreta t = T (x1 , . . . , xn ) é conhecido por estimativa.
Exemplo 6.1b: Numa amostra aleatória de n = 100000 eleitores,
observaram-se 38900 eleitores com intenção de voto no partido em
causa. Neste cenário, X1 , . . . , Xn são v.a. i.i.d. com distribuição de
Bernoulli (p), onde p é a proporção (populacional) de votantes no partido. O parâmetro p pode ser estimado pela média amostral X̄, i.e., a
proporção amostral de votantes no partido, cujo estimativa é
x̄ = 38900/100000 = 0.389 ou 38.9%.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 103/200
Propriedades dos estimadores.
Exemplo 6.2: A fim de estudar a exactidão e precisão de 4 jogadores
(A,B,C,D) de tiro ao alvo, foram-lhes dadas 6 possibilidades de acertar
ao alvo. O resultado dessa experiência encontra-se a seguir.
'$
A
* *
* t *
* *
&%
'$
C
t*
**
**
*
&%
B
*
* '$
* *
t
&%
*
*
'$
D
t
**
****&%
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 104/200
Um resumo da qualidade (exactidão e precisão) dos jogadores:
• Jogador A: muita exactidão e pouca precisão;
• Jogador B: pouca exactidão e pouca precisão;
• Jogador C: muita exactidão e muita precisão;
• Jogador D: pouca exactidão e muita precisão.
Exactidão = concordância das observações com o valor visado.
Precisão = concordância das observações entre si.
A exactidão (accuracy) está associada aos erros sistemáticos, e.g., deficiências de instrumentos de medição, enquanto a precisão (precision) se
reporta aos erros aleatórios que são responsáveis por pequenas variações
imprevisíveis nas medições realizadas, cujas causas não são completamente conhecidas.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 105/200
Definição 6.9: Seja (X1 . . . , Xn ) uma a.a. de X com distribuição indexada pelo parâmetro θ. O estimador T = T (X1 , . . . , Xn ) é dito ser um
estimador centrado (não enviesado) de θ se E(T ) = θ.
Exemplo 6.3: Seja (X1 . . . , Xn ) uma a.a. de X com E(X) = µ e
P
V ar(X) = σ 2 . Será ni=1 (Xi − X̄)2 um estimador centrado de σ 2 ?
Se X1 , . . . , Xn são v.a. i.i.d. com E(Xi ) = µ e V ar(Xi ) = σ 2 , i =
1, . . . , n, então E(X̄) = µ e V ar(X̄) = σ 2 /n. Logo,
E(
Pn
2
i=1 (Xi − X̄) ) =
=
=
=
∴ Não, mas S 2 =
1
n−1
Pn
P
P
E( i Xi2 − 2X̄ i Xi + nX̄ 2 )
n E(X 2 ) − E(X̄ 2 )
n [(σ 2 + µ2 ) − (σ 2 /n + µ2 )]
(n − 1)σ 2
i=1 (Xi −X̄)
2
é um estimador centrado de σ 2 .
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 106/200
Definição 6.10: Seja T = T (X1 , . . . , Xn ) um estimador do parâmetro θ.
Chama-se viés (enviesamento) de T como estimador de θ à quantidade
E(T ) − θ. Note-se que o viés é nulo se e somente se T é um estimador
centrado de θ.
Definição 6.11: Seja T = T (X1 , . . . , Xn ) um estimador do parâmetro
θ. Uma medida de precisão do estimador T é o erro quadrático médio
(EQM), dado por
EQM (T ) ≡ E((T − θ)2 ) = V ar(T ) + (E(T ) − θ)2 .
Definição 6.12: Sejam T = T (X1 , . . . , Xn ) e U = U (X1 , . . . , Xn ) dois
estimadores do parâmetro θ. Diz-se que T é mais eficiente do que U , se
EQM (T ) ≤ EQM (U ), ∀ θ
com desigualdade estrita para algum θ.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 107/200
Se T e U são estimadores centrados do parâmetro θ, então T é mais
eficiente do que U se V ar(T ) ≤ V ar(U ), ∀ θ com desigualdade estrita
para algum θ.
Exemplo 6.4: Seja (X1 . . . , Xn ) uma a.a. de X ∼ Bernoulli(p). Considere ainda X1 e X̄ como dois estimadores de p. Qual dos dois é o
estimador mais eficiente?
P
Sendo Xi ’s v.a. i.i.d. Bernoulli (p), ni=1 Xi ∼ Binomial (n, p),
• E(X1 ) = p e
P
E(X̄) = n−1 E( ni=1 Xi ) = n−1 n p = p.
∴ X1 e X̄ são estimadores centrados de p.
• V ar(X1 ) = p(1 − p) e
V ar(X̄) = n−2 V ar(
⇒
V ar(X̄)
V ar(X1 )
=
1
n
Pn
i=1
Xi ) = n−1 p (1−p)
< 1, ∀ n > 1.
∴ X̄ é mais eficiente do que X1 na estimação de p.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 108/200
Exemplo 6.3a: Seja (X1 . . . , Xn ) uma a.a. de uma população X
Normal com E(X) = µ e V ar(X) = σ 2 . Será a variância amosP
tral (corrigida) S 2 = (n − 1)−1 ni=1 (Xi − X̄)2 mais eficiente do que
P
σ̂ 2 = n−1 ni=1 (Xi − X̄)2 na estimação de σ 2 ?
Como
• E(
Pn
i=1 (Xi − X̄)
2
) = (n−1)σ 2 ,
σ2.
⇒ E(S 2 ) = σ 2 e E(σ̂ 2 ) = n−1
n
P
• V ar( n (Xi − X̄)2 ) = 2(n−1)σ 4 ,
i=1
• EQM (S 2 ) = V ar(S 2 ) + (E(S 2 ) − σ 2 )2 = 2(n−1)−1 σ 4 ,
• EQM (σ̂ 2 ) = V ar(σ̂ 2 ) + (E(σ̂ 2 ) − σ 2 )2 = (2n−1)n−2 σ 4 ,
⇒
EQM (S 2 )
EQM (σ̂ 2 )
=
2n2
(n−1)(2n−1)
> 1, ∀ n > 1.
∴ σ̂ 2 é mais eficiente do que S 2 (n > 1) na estimação de σ 2 .
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 109/200
Definição 6.13: Seja (X1 . . . , Xn ) uma a.a. de uma população X indexada pelo parâmetro θ. Uma sucessão {Tn } de estimadores de θ é
consistente se lim P (|Tn − θ| > ǫ) = 0, ∀ ǫ > 0, o que é garantido por
n→∞
i) lim E(Tn ) = θ,
n→∞
ii) lim V ar(Tn ) = 0.
n→∞
Exemplo 6.4a: Seja (X1 . . . , Xn ) uma a.a. de X ∼ Bernoulli(p). Será
X̄ um estimador consistente de p?
P
Sendo Xi ’s v.a. i.i.d. Bernoulli (p), ni=1 Xi ∼ Binomial (n, p),
P
• E(X̄) = E( n Xi )/n = p. X̄ é um estimador centrado de p.
i=1
Condição i) logicamente satisfeita.
P
• V ar(X̄) = V ar( n Xi )/n2 = p (1 − p)/n. Por conseguinte,
i=1
limn→∞ V ar(X̄) = limn→∞ p(1−p)
= 0. Condição ii) satisfeita.
n
Portanto, X̄ é um estimador consistente de p.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 110/200
Método da máxima verosimilhança.
Definição 6.14: Dada uma a.a. (X1 . . . , Xn ) de uma população X com
f.m.p. ou f.d.p. fX (x) indexada pelo parâmetro (desconhecido) θ, a
função de verosimilhança de θ relativa à amostra (x1 , . . . , xn ), denotada
por L(θ|x1 , . . . , xn ), é a função de θ que é numericamente idêntica à
distribuição de probabilidade amostral avaliada em (x1 , . . . , xn ), i.e.,
L(θ|x1 , . . . , xn ) ≡ f (x1 , . . . , xn |θ) =
n
Y
i=1
fX (xi |θ).
O método de máxima verosimilhança consiste em maximizar a função
de verosimilhança para obter o valor mais verosímil de θ, denominado
estimativa de máxima verosimilhança de θ.
Ao determinar o valor que maximiza θ, usa-se frequentemente o facto
de que L(θ|x1 , . . . , xn ) e log L(θ|x1 , . . . , xn ) têm o seu máximo no
mesmo valor de θ.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 111/200
Exemplo 6.5: Seja (X1 . . . , Xn ) uma a.a. de uma população X ∼
Poisson(λ). Qual o estimador de máxima verosimilhança (EMV) de
λ?
A função de verosimilhança de λ, dado (x1 , . . . , xn ), é
n
Y
e−λ λxi
L(λ|x1 , . . . , xn ) =
.
x
!
i
i=1
Seja Lλ ≡ log L(λ|x1 , . . . , xn ) = −n λ + log λ
•
dLλ
dλ
Pn
−1
= −n + λ
⇒ λ=
i=1 xi = 0
Pn
2
• d L2λ = −λ−2
i=1 xi < 0, ∀λ.
dλ
n
X
i=1
1
n
n
Y
xi − log xi !.
i=1
Pn
i=1
xi = x̄
∴ x̄ é a estimativa de máxima verosimilhança de λ e o EMV de λ é
n
1X
λ̂ = X̄ =
Xi .
n i=1
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 112/200
Teorema 6.1: Se θ̂ é o estimador de máxima verosimilhança de um
parâmetro θ, então g(θ̂) é o estimador de máxima verosimilhança de
g(θ) (propriedade de invariância).
Exemplo 6.6: Seja (X1 . . . , Xn ) uma a.a. de X ∼ Uniforme(0, θ]. Qual
o EMV de log θ?
A função de verosimilhança de θ, dado x1 , . . . , xn , é
L(θ|x1 , . . . , xn ) =
=
n
Y
1
θ
I(0,θ] (xi )
i=1
1
I
(θ)
θn [x(n) ,∞)
L(θ)
6
1
x(n)
- θ
&
x(n)
⇒ X(n) = max(X1 , . . . , Xn ) é o EMV de θ.
∴ Pela propriedade de invariância dos estimadores de máxima verosimilhança, log X(n) é o EMV de log θ.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 113/200
Momentos da média amostral e de variâncias
amostrais.
Exemplo 6.7: Suponha uma população com v.a. X de distribuição uniforme em {2, 4, 6} da qual se retira (com reposição) uma amostra de
tamanho 2. Qual o valor esperado da média e da variância amostrais?
Como os elementos da população X são equiprováveis,
P
1
• E(X) =
x xfX (x) = 3 (2 + 4 + 6) = 4.
P 2
1
• E(X 2 ) =
x x fX (x) = 3 (4 + 16 + 36) = 56/3
⇒ V ar(X) = E(X 2 ) − (E(X))2 = 56/3 − 16 = 8/3.
Seja Xi o resultado da extracção i, i = 1, . . . , n (n = 2). Recorde-se que
a média amostral e a variância amostral são, respectivamente,
P
P
X̄ = n−1 ni=1 Xi e S 2 = (n−1)−1 ni=1 (Xi − X̄)2 .
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 114/200
A distribuição de probabilidade conjunta de (X1 , X2 ) é dada por
X1 \X2
2
4
6
2
1/9
1/9
1/9
4
1/9
1/9
1/9
6
1/9
1/9
1/9
A distribuição amostral da estatística X̄ = (X1 + X2 )/2 é
X̄
2
P (X̄ = x̄) 1/9
E(X̄) =
X
u
3
2/9
u P (X̄ = u) = 2 ×
4
3/9
5
2/9
6
1/9
1
36
1
+ ··· + 6 × =
=4
9
9
9
⇒ E(X̄) = E(X).
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 115/200
• E(X̄ 2 ) =
P
u
1
9
156
9
u2 P (X̄ = u) = 4 ×
• V ar(X̄) = E(X̄ 2 ) − (E(X̄)2 =
+ · · · + 36 ×
− 16 =
12
9
=
1
9
4
3
=
156
9
⇒ V ar(X̄) = V ar(X)/n.
A distribuição amostral da estatística S 2 =
S2
0
P (S 2 = s2 ) 3/9
E(S 2 ) =
X
v
v P (S 2 = v) = 0 ×
P2
2
4/9
i=1 (Xi
− X̄)2 é
8
2/9
3
4
2
24
8
+2× +8× =
=
9
9
9
9
3
⇒ E(S 2 ) = V ar(X).
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 116/200
Distribuições amostrais da média e variância
numa população normal.
Para melhor avaliar a estimação de um parâmetro θ a partir de uma
estatística T = T (X1 , . . . , Xn ), deve-se conhecer a distribuição de T .
A distribuição da estatística T , conhecida como distribuição amostral
de T , tem em conta todos os valores possíveis da amostra (X1 . . . , Xn ).
Teorema 6.2: Se (X1 . . . , Xn ) é uma a.a. de uma população X com
E(X) = µ e V ar(X) = σ 2 , então o valor esperado e variância da
média amostral X̄ são, respectivamente,
P
−1
• E(X̄) = n−1
n µ = µ;
i E(Xi ) = n
P
−2
• V ar(X̄) = n−2
n σ 2 = σ 2 /n.
i V ar(Xi ) = n
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 117/200
Teorema 6.3: Seja (X1 . . . , Xn ) uma a.a. de uma população X com
E(X) = µ e V ar(X) = σ 2 , 0 < σ 2 < ∞. Pelo Teorema do Limite
Central, a distribuição amostral de X̄ é aproximada pela distribuição
Normal com média µ e variância σ 2 /n, para n suficientemente grande.
Corolário 6.1: Se (X1 . . . , Xn ) é uma a.a. de uma população X ∼
N (µ, σ 2 ), 0 < σ 2 < ∞, então
Z=
X̄ − µ
√ ∼ N (0, 1).
σ/ n
Exemplo 6.8: Seja (X1 . . . , Xn ) uma a.a. de X ∼ Bernoulli(p). Qual a
P
distribuição aproximada da proporção amostral X̄ = n−1 ni=1 Xi ?
Sabendo que E(X) = p e V ar(X) = p(1 − p), pelo Teorema 6.3
p(1 − p)
X̄ − p
a
a
p
∼ N (0, 1) ⇒ X̄ ∼ N p,
.
n
p(1 − p)/n
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 118/200
Distribuição qui-quadrado.
Definição 6.15: Se X1 , . . . , Xk são v.a. i.i.d. com distribuição N (0, 1),
Q = X12 + · · · + Xk2
é dito ter uma distribuição qui-quadrado com k graus de liberdade, denotada por χ2(k) , cuja f.d.p. é dada por
fQ (q) =
onde Γ(a) =
R∞
0
1
k
2
k
2 Γ( k2 )
q
q 2 −1 e− 2 , q > 0,
xa−1 e−x dx, a > 0.
O valor esperado e a variância de uma v.a. Q ∼ χ2(k) são:
• E(Q) = k;
• V ar(Q) = 2 k.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 119/200
0.20
Função Densidade de Probabilidade − Qui−quadrado
0.10
0.00
0.05
f(x)
0.15
k=1
k=5
k=10
0
5
10
15
20
25
30
x
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 120/200
Distribuição t-Student.
Definição 6.16: Se Z e Q são v.a. independentes com Z ∼ N (0, 1) e
Q ∼ χ2(k) , então
Z
T =p
Q/k
é dito ter uma distribuição t-Student com k graus de liberdade, denotada
por t(k) , cuja f.d.p. é dada por
k−1
2
2
)
1 Γ( k−1
t
2
, −∞ < t < ∞.
1
+
fT (t) = √
k
k π Γ( k2 )
O valor esperado e a variância de uma v.a. T ∼ t(k) são:
• E(T ) = 0, k > 1.
• V ar(T ) = k/(k − 2), k > 2.
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 121/200
0.4
Função Densidade de Probabilidade − t−Student
0.2
0.0
0.1
f(x)
0.3
k=1
k=5
k=100
−4
−2
0
2
4
6
x
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 122/200
Teorema 6.4: Se (X1 . . . , Xn ) é uma a.a. de uma população X ∼
N (µ, σ 2 ), então
2
n 2
X
(X
−
µ)
X
−
µ
i
i
i=1
=
∼ χ2(n)
2
σ
σ
i=1
Pn
e
Pn
i=1 (Xi −
σ2
X̄)2
(n − 1)S 2
=
∼ χ2(n−1) .
2
σ
Teorema 6.5: Se (X1 . . . , Xn ) é uma a.a. de uma população X ∼
N (µ, σ 2 ), então
√
X̄ − µ
(X̄ − µ)/(σ/ n)
√ ∼ t(n−1) .
p
=
S/ n
(((n − 1)S 2 )/σ 2 )/(n − 1)
NOTAS DE PROBABILIDADES E ESTATÍSTICA – 123/200