MOQ-13 PROBABILIDADE
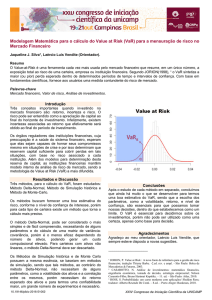
E ESTATÍSTICA
Professor: Rodrigo A. Scarpel
[email protected]
www.mec.ita.br/~rodrigo
Programa do curso:
Semanas
Conteúdo
1
Introdução à probabilidade (eventos, espaço amostral, axiomas, propriedades, probabilidade condicional e independência).
2
Teorema da probabilidade total e teorema de Bayes. Variáveis aleatórias. Distribuições de probabilidade. Funções massa,
densidade, e distribuição acumulada. Funções de variáveis aleatórias.
3
Valor esperado e variância. Momentos de uma variável aleatória. Função geradora de momentos. Principais distribuições de
probabilidade discretas (Bernoulli, Binomial e Poisson).
4
Principais distribuições de probabilidade contínuas (Exponencial negativa e Normal).
5
Feriado (2/4)
6
Variáveis aleatórias conjuntas, função distribuição conjunta e marginal. Independência estatística. Covariância e Coeficiente
de Correlação.
7
Prova
8
Princípios de estatística. Estimadores e estimativas. Estimação pontual de parâmetros (Métodos dos momentos e da máxima
verossimilhança). Estatística Descritiva.
9
Amostras aleatórias. Distribuições amostrais. Teorema do limite central. Variáveis aleatórias Qui-quadrado e t-Student.
10
Propriedades dos estimadores. Intervalos de confiança (estimação por intervalo). Tamanho da amostra. Princípios de testes
de hipóteses.
11
Testes de Hipóteses. Inferência baseada em 2 amostras (entre parâmetros de populações distintas).
12
Testes não-paramétricos (associação, independência e de aderência).
13
Feriado (4/6)
14
Prova
15 e 16
Regressão linear simples e correlação.
Aplicações de modelos de regressão linear.
DISTRIBUIÇÕES
AMOSTRAIS
Professor: Rodrigo A. Scarpel
[email protected]
www.mec.ita.br/~rodrigo
Estatísticas e suas distribuições:
Quando estudamos estatística descritiva, observamos uma amostra única
(x1, x2, …,xn) de tamanho n da população para obter estimativas pontuais
dos momentos amostrais (x e s2).
Se selecionarmos 2 amostras (cada uma de tamanho n) é de se esperar
que as observações da segunda amostra serão diferentes das observações
da primeira amostra. Por exemplo:
Amostra 1 (n=3 carros) → x1=30,7 x2=29,4 x3=31,1
Amostra 2 (n=3 carros) → x1=28,8 x2=30,0 x3=31,3
Essas estimativas pontuais são utilizadas para fazer inferências em
relação ao valor esperado e ao desvio-padrão / variância da população, os
quais são desconhecidos.
Estatísticas e suas distribuições:
Def: ESTATÍSTICA é qualquer quantidade cujo valor pode ser calculado a
partir de uma amostra. Como há incerteza em relação a esses valores toda
estatística é uma variável aleatória (iid).
Toda estatística, por ser uma variável aleatória, tem uma distribuição de
probabilidade. A distribuição de probabilidade de uma estatística é
chamada distribuição amostral.
Def: Distribuição amostral é a distribuição de probabilidade de uma
estatística e descreve como o valor da estatística varia em função das
amostras selecionadas.
A distribuição amostral depende da distribuição de probabilidade da
população, do tamanho da amostra e do método de amostragem (neste
curso vamos estudar apenas a aleatória)
Distribuição da média amostral (x):
Sejam x1, x2, …, xn n elementos de uma amostra aleatória de uma
população normal com parâmetros E[x] = µ e Var[x] = σ2. Então:
i. E[ x ] = µ
ii. Var[ x ] = σ2/n
iii. To = x1 + … + xn , E[To] = nµ
µ, Var[To] = nσ
σ2
De acordo com i a distribuição amostral de x é centrada no valor esperado
da população da qual a amostra foi selecionada, com ii que a distribuição
se torna mais concentrada em torno de µ com o crescimento do tamanho
da amostra (n).
Distribuição da média amostral (x):
Proposição: Seja x1, x2, …, xn uma amostra aleatória de uma população
normal com E[x] = µ e Var[x] = σ2, então, para qualquer n:
σ2
x ~ N µ,
n
⇒
x−µ
σ
P( X)
Maior
tamanho
de
amostra
Menor
tamanho
de
amostra
A
~Z
n
(
B
To ~ N nµ , nσ
µ
2
)
⇒
To − nµ
σ n
~Z
X
Distribuição de uma combinação linear de v.as:
Sendo Y = a1X1 +…+ anXn
⇒ E[Y] = a1E[X1] +…+ anE[Xn] = a1µ1+ … + anµn
Se as variáveis aleatórias são independentes,
Var[a1X1 +…+ anXn] = a12Var[X1] + … + an2Var[Xn]
Distribuição da diferença entre médias de populações normais:
Sejam A e B duas populações normais com parâmetros µA, σA, µB e σB.
Assim,
(
X A ~ N µ A ,σ A2 n A
)
e
(
X B ~ N µ B , σ B2 nB
2
2
σ
σ
A
B ⇒ (X A − X B ) − (µ A − µ B ) ~ Z
+
X A − X B ~ N µ A − µB ,
n A nB
σ A2 σ B2
+
nA
nB
)
Distribuição amostral de estatísticas:
Existem dois métodos para obter a distribuição amostral de uma estatística:
Método 1: Utilizando regras da probabilidade
Ex: Serviço
Preço: x
p(x)
A
40
0,2
B
45
0,3
C
50
0,5
µ = E[x] = 40 * 0,2 + 45 * 0,3 + 50 * 0,5 = 46,5
σ2 = Var[x] = 0,2 * (40-46,5)2 +0,3 * (45-46,5)2 +0,5 * (50-46,5)2 =15,25
Método 2: Realização de um experimento de simulação
Usa-se um computador para obter k amostras aleatórias de tamanho n
da distribuição designada. Para cada amostra calcula-se as estatísticas
de interesse e cria-se um histograma para avaliar a distribuição amostral
aproximada da estatística.
Distribuição amostral de estatísticas:
Método 1: n=2
x2
40
45
50
40
45
50
40
45
50
p(x1)
0,2
0,2
0,2
0,3
0,3
0,3
0,5
0,5
0,5
p(x2) p(x1,x2)
0,2
0,04
0,3
0,06
0,5
0,1
0,2
0,06
0,3
0,09
0,5
0,15
0,2
0,1
0,3
0,15
0,5
0,25
x
40
42,5
45
42,5
45
47,5
45
47,5
50
2
s
0
12,5
50
12,5
0
12,5
50
12,5
0
DISTRIBUIÇÃO DE PROBABILIDADE DA MÉDIA
0,35
0,3
0,25
PROBABILIDADE
x1
40
40
40
45
45
45
50
50
50
0,2
0,15
0,1
0,05
0
40
42,5
45
VALORES
E[ x ] = 40 * 0,04 + 42,5 * 0,12 + ... + 50 * 0,25 = 46,5
Var[ x ] = 0,04 * (40-46,2)2 + ... + 0,25 * (50-46,5)2 = 7,625
E[ s2 ] = 0 * 0,38 + 12,5 * 0,42 + 50 * 0,20 = 15,25
47,5
50
Distribuição amostral de estatísticas:
x4
40
45
50
40
45
50
40
45
50
p(x1)
0,2
0,2
0,2
0,2
0,2
0,2
0,2
0,2
0,2
p(x2)
0,2
0,2
0,2
0,2
0,2
0,2
0,2
0,2
0,2
p(x3)
0,2
0,2
0,2
0,3
0,3
0,3
0,5
0,5
0,5
...
...
...
...
...
...
...
p(x4)
0,2
0,3
0,5
0,2
0,3
0,5
0,2
0,3
0,5
50
50
50
50
50
50
50
50
50
40
45
50
0,5
0,5
0,5
0,5
0,5
0,5
0,5
0,5
0,5
0,2
0,3
0,5
p(x1,x2,x3,x4)
0,0016
0,0024
0,004
0,0024
0,0036
0,006
0,004
0,006
0,01
0,025
0,0375
0,0625
x
40
41,25
42,5
41,25
42,5
43,75
42,5
43,75
45
2
s
0
6,25
25
6,25
8,333
22,92
25
22,92
33,33
...
x3
40
40
40
45
45
45
50
50
50
...
x2
40
40
40
40
40
40
40
40
40
...
x1
40
40
40
40
40
40
40
40
40
...
Método 1: n=4
47,5
48,75
50
25
6,25
0
DISTRIBUIÇÃO DE PROBABILIDADE DA MÉDIA
0,25
PROBABILIDADE
0 ,2
E[ x ]=40*0,016+...+50*0,0625=46,5
0,15
0 ,1
Var[ x ] = 3,8125 (s2 / 4)
0,05
0
40
41,25
42 ,5
43 ,75
45
VALORES
4 6,25
4 7,5
48,7 5
50
Distribuição da média amostral (x):
Distribuição de x para uma população não normal:
,3
,2
,1
,0
0,25
0,25
0,25
0,25
1
2
3
4
E[x] = 1 * 0,25 + 2 * 0,25 + 3 * 0,25 + 4 * 0,25 = 2,5
Var[x] = E[x-E(x)] = 0,25 * (1-2,5)2 +0,25 * (2-2,5)2
+ 0,25 * (3-2,5)2 + 0,25 * (4-2,5)2 =1,12
Distribuição da média amostral (x):
Distribuição de x para uma população não normal:
N
AMOSTRAS (1a,2a):
a
∑x
i
a
1
Obs
2 Observação
1
2
3
4
1
1,1 1,2 1,3 1,4
2
2,1 2,2 2,3 2,4
3
3,1 3,2 3,3 3,4
4
4,1 4,2 4,3 4,4
MÉDIAS DAS
AMOSTRAS:
µx =
i =1
N
1,0 + 1,5 + L + 4,0
=
= 2,5
16
N
2
(
)
x
−
µ
∑i x
σx =
1a
Obs
2a Observação
1
2
3
4
1
1,0 1,5 2,0 2,5
2
1,5 2,0 2,5 3,0
3
2,0 2,5 3,0 3,5
4
2,5 3,0 3,5 4,0
i=1
N
,3
=
(1,0 − 2,5)2 +L = 0,79
16
P(x)
,2
,1
x
,0
1,0 1,5 2,0 2,5 3,0 3,5 4,0
Teorema do limite central:
TLC: Seja x1, x2,…, xn uma amostra aleatória de uma distribuição
qualquer com parâmetros E[X] = µ e Var[X] = σ2. Se n é
suficientemente grande, a distribuição de x aproxima-se a uma
normal com E[x] = µ e Var[x] = σ2/n e a distribuição do Total
(x1+…+xn) aproxima-se a uma distribuição normal com E[To] =nµ
µ
e Var[To] =nσ
σ2. Assim,
σ2
x ~& N µ ,
n
(
Distribuição
Distribuição Populacional
Populacional
σ = 10
x−µ
⇒
~& Z
σ n
To ~& N n µ , n σ
2
)⇒
To − n µ
σ
n
µ = 50
X
Distribuição
Distribuição amostral
~& Z
n=4
σX = 5
n =30
σX = 1.8
µX-X = 50
X
Distribuição amostral da proporção (e frequência):
O TLC pode ser utilizado para justificar a aproximação da Binomial
pela Normal pois se X é uma variável aleatória que “conta” o número
de sucessos em n tentativas independentes, como a probabilidade de
sucesso é constante os Xs são iid.
Portanto, se n é suficientemente grande
n sucessos = X ~& N (np, np (1 − p ) ) ⇒
o
X
= pˆ ~& N ( p, p (1 − p ) n ) ⇒
n
X − n. p
n. p.(1 − p)
pˆ − p
p.(1 − p ) n
~& Z
~& Z
Distribuição amostral de s2:
Quando há incerteza em relação ao valor de σ estima-se o seu valor por:
n
σˆ 2 = s 2 =
2
(
x
−
x
)
∑ i
i =1
n −1
Teorema: Se s2 é a variância de uma amostra aleatória de tamanho n,
retirada de uma população normal com parâmetros µ e σ2, então a
estatística
n
2
(
)
x
−
x
∑ i
i =1
σ
2
=
(n − 1) s 2
σ2
tem distribuição χ2 com n-1 graus de liberdade.
σ2
Na utilização é necessário obter χ2calc= (n-1)s2/σ
Distribuição
amostral de s2:
Graus de liberdade:
Os graus de liberdade podem ser vistos como uma medida da
informação amostral.
Sabendo que
n
2
(
)
x
−
µ
∑ i
σ2 →
i =144
1
42444
3
~ χ n2
n
2
(
)
x
−
x
∑ i
σ2
i =144
1
42444
3
~ χ n2−1
quando µ não é conhecido há 1 grau de liberdade a menos ou
considera-se que um grau de liberdade é perdido na estimação de µ.
Generalização: Há n graus de liberdade, ou partes de informação
independentes, em uma amostra aleatória de uma população normal e
cada vez que se utiliza uma estatística em substituição a um parâmetro
perde-se um grau de liberdade.
x, s e a distribuição t-Student:
A dificuldade prática em relação ao TLC é que ele demanda o
conhecimento de σ.
A ferramenta utilizada para lidar com essa dificuldade é a distribuição t
(William Gosset, 1908) que é formada pela divisão
Z
χ n2−1
n −1
=
x−µ σ / n
(n − 1) s 2 / σ 2
n −1
x−µ σ
x−µ
=
. =
σ / n s s/ n
Assim, é possível fazer inferências em relação a µ usando uma
estimativa de σ fornecida pela mesma amostra que gerou x.
Def: Seja x1, …, xn uma amostra aleatória de uma população normal
(
)
com E[X] = µ e Var[X] = σ2, então T = (x − µ ) s / n tem distribuição
t com n-1 graus de liberdade.
x, s e a distribuição t-Student:
Propriedades das distribuições t-student: Seja tν a curva da função
densidade dos gl de ν.
1. Cada curva tν possui um formato de sino e está centrada em 0.
2. Toda curva tν é mais dispersa que a curva normal padronizada (Z).
3. À medida que ν aumenta, a dispersão da curva tν correspondente diminui.
4. À medida que ν → ∞ a seqüência das
curvas tν se aproxima da curva normal
padronizada (de forma que a curva Z é
chamada geralmente de t com gl= ∞).
x, s e a distribuição t-Student:
Para casa:
• Lista de Exercícios 7 (site: www.mec.ita.br/~rodrigo/)
• Leitura: Devore – cap. 5: Distribuições … e amostras aleatórias (5.3 a 5.5)
Walpole et al. – cap. 8: Distribuições amostrais … (8.1 a 8.7)