MOQ-13 PROBABILIDADE
E ESTATÍSTICA
Professor: Rodrigo A. Scarpel
[email protected]
www.mec.ita.br/~rodrigo
Programa do curso:
Semanas
Conteúdo
1
Introdução à probabilidade (eventos, espaço amostral, axiomas, propriedades, probabilidade condicional e independência).
2
Teorema da probabilidade total e teorema de Bayes. Variáveis aleatórias. Distribuições de probabilidade. Funções massa,
densidade, e distribuição acumulada. Funções de variáveis aleatórias.
3
Valor esperado e variância. Momentos de uma variável aleatória. Função geradora de momentos. Principais distribuições de
probabilidade discretas (Bernoulli, Binomial e Poisson).
4
Principais distribuições de probabilidade contínuas (Exponencial negativa e Normal).
5
Feriado (2/4)
6
Variáveis aleatórias conjuntas, função distribuição conjunta e marginal. Independência estatística. Covariância e Coeficiente
de Correlação.
7
Prova
8
Princípios de estatística. Estimadores e estimativas. Estimação pontual de parâmetros (Métodos dos momentos e da máxima
verossimilhança). Estatística Descritiva.
9
Amostras aleatórias. Distribuições amostrais. Teorema do limite central. Variáveis aleatórias Qui-quadrado e t-Student.
10
Propriedades dos estimadores. Intervalos de confiança (estimação por intervalo). Tamanho da amostra.
11
Testes de Hipóteses. Inferência baseada em 2 amostras (entre parâmetros de populações distintas).
12
Testes não-paramétricos (associação, independência e de aderência).
13
Feriado (4/6)
14
Prova
15 e 16
Regressão linear simples e correlação.
Aplicações de modelos de regressão linear.
PROPRIEDADES DOS
ESTIMADORES
Professor: Rodrigo A. Scarpel
[email protected]
www.mec.ita.br/~rodrigo
O processo de inferência:
TESTAR
ADERÊNCIA
POPULAÇÃO
AMOSTRA
HIPÓTESES
ESTIMAÇÃO DOS
PARÂMETROS
FAZER INFERÊNCIAS EM
RELAÇÃO A POPULAÇÃO
Hipóteses: - iid ⇒ Amostra aleatória
- Distribuições populacional e amostral (TLC)
- Parâmetros conhecidos ou não (σ
σ)
Estimadores e Estimativas pontuais:
Def: Uma estimativa pontual de um parâmetro θ é um valor que pode ser
considerado representativo para o verdadeiro valor de θ
Uma estimativa pontual é obtida selecionando-se uma estatística
apropriada e calculando seu valor a partir de uma amostra.
Def: Um estimador pontual ( ^θ ) de um parâmetro θ é essa estatística
apropriada selecionada.
Pergunta: O que é uma estatística apropriada??
Justeza (Unbiasedness)
Eficiência
Consistência
Propriedades e escolha de estimadores:
Justeza (Unbiasedness): um estimador pontual θ é não viesado se E( θ )= θ.
Se ^
θ é viesado, a diferença E( θ^ ) - θ é chamada de viés (bias). Assim, se θ é
^
não viesado, sua distribuição
de probabilidade é centrada no real valor do
parâmetro.
P(X)
Unbiased
A
Biased
C
µ
X
Propriedades e escolha de estimadores:
Estimadores não viesados:
n
MÉDIA: E[x] = µ ? Sim, se x =
∑x
i =1
n
i
, se for uma amostra
aleatória e se n for grande.
^ = p ? Sim, se
PROPORÇÃO: E[p]
pˆ =
x .
n
n
VARIÂNCIA: E[σ
σ^ 2] = σ2? Sim, se σˆ 2 =
2
(
)
x
−
µ
∑ i
i =1
n −1
, se for
uma amostra aleatória e se n grande
Propriedades e escolha de estimadores:
Eficiência: o estimador pontual mais eficiente é o não-tendencioso de
mínima variância (MVUE). No exemplo, ambos os estimadores são não
viesados, mas suas distribuições amostrais são diferentes.
Distribuição
P( X) amostral de
θ^1
B
Distribuição
amostral de
^
θ2
A
µ
x
Propriedades e escolha de estimadores:
Consistência: Com o crescimento do tamanho da amostra a distribuição
amostral se torna mais centrada. Em termos práticos significa que pode-se
com amostras suficientemente grandes tornar o erro de estimação tão
pequeno quanto se queira.
P(X)
Maior
tamanho
de
amostra
B
Menor
tamanho
de
amostra
A
µ
x
Propriedades e escolha de estimadores:
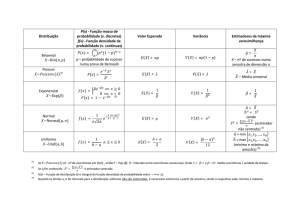
Estimadores consistentes:
MÉDIA: Var[x] = σ2 / n (população normal e σ conhecido)
= σ2 / n (pelo TLC e σ conhecido)
= s2 / n (população normal e σ não conhecido)
^ = p(1-p) / n
PROPORÇÃO: Var[p]
Def: Erro padrão de um estimador é seu desvio padrão
(σ
σθ = (Var(θ
θ))1/2). Quanto maior o tamanho da amostra (n) menor
será o erro padrão de um estimador consistente.
ESTIMAÇÃO POR
INTERVALO
Professor: Rodrigo A. Scarpel
[email protected]
www.mec.ita.br/~rodrigo
Estimação por intervalo:
Uma estimativa pontual, por ser um único valor, não fornece por si mesma
qualquer informação sobre a precisão e a confiabilidade da estimativa.
Uma alternativa para apresentar um único valor sensato para o parâmetro
que está sendo estimado é calcular e relatar um intervalo completo de
valores plausíveis: intervalo de confiança (IC).
Exemplo:
Clientes / minuto
x
Nível de confiança:
Um intervalo de confiança sempre é calculado selecionando-se primeiro o
nível de confiança, que é uma medida do grau de confiabilidade do
intervalo.
Níveis de confiança usados com mais frequência: 90%, 95% e 99%
Interpretação: o nível de confiança de x% implica que x% de todas as
amostras forneceriam um intervalo que inclui o parâmetro que está sendo
estimado (ex: µ, σ), e apenas (1-x)% de todas as amostras dariam um
intervalo errôneo.
As informações sobre a precisão de uma estimativa de intervalo são
transmitidas pela sua extensão. Assim, se o nível de confiança for alto e o
intervalo resultante for restrito, é possível dizer que o conhecimento do
valor do parâmetro é preciso.
Propriedades básicas de ICs:
Os conceitos e propriedades básicas dos ICs são introduzidos mais
facilmente enfocando primeiro uma situação simples:
O parâmetro de interesse é a média populacional (µ)
A distribuição da população é normal
O valor do desvio-padrão (σ) é conhecido.
Seja x1, x2, …, xn uma amostra aleatória de uma distribuição normal com média µ e
desvio-padrão σ. Neste caso, independentemente do tamanho da amostra
(n):
σ2
x ~ N µ,
n
µx = µ
σ 2x =
σ2
n
Propriedades básicas de ICs:
Padronizando x obtém-se:
Z=
x−µ
σ/ n
~ N (0,1)
x−µ
Assim: P − 1,96 <
< +1,96 = 0,95
σ/ n
σ
σ
= 0,95
... P x − 1,96
< µ < x + 1,96
n
n
x − 1,96
σ
x + 1,96
n
σ
n
Clientes /
x
minuto
Se fizermos ∞
amostragens em
95% delas µ estará
no IC
Propriedades básicas de ICs:
Generalizando:
O intervalo de confiança de 100(1-α
α)% da média (µ
µ) de uma população
normal, quando σ é conhecido é dado por:
σ
σ
x − Z α
, x + Zα
2
2
n
n
NÍVEL DE
CONFIANÇA
Zα/2
90%
1,645
95%
1,96
99%
2,575
ou por
x ± Zα
x
σ
2
n
Nível de confiança, Precisão e Tamanho da Amostra:
Sendo o nível de confiança 100(1-α
α)%, a precisão e o tamanho da amostra (n)
relacionados, uma boa estratégia é especificar o nível de confiança, e a
semi-amplitude do intervalo de confiança (B) e então determinar o
tamanho da amostra. Assim:
x ± Zα
σ ... n = Z σ
α /2
2
n
B
2
↑B→↓n
↑σ→↑n
↑ Zα/2→ ↑ n
Intervalo de confiança para amostras grandes:
Teorema do Limite Central: Seja x1, x2, xn uma amostra aleatória de uma
distribuição qualquer com E[x] = µ e Var[X] = σ2. Se n é suficientemente
grande, então:
σ
x ~& N µ ,
n
2
(
To ~& N nµ , nσ 2
µx = µ
σ
2
x
=
σ2
n
)
Obs: qto. maior for o valor de n,
melhor será a aproximação (n>30)
Assim, mesmo que a população não seja normalmente distribuída, se σ é
conhecido:
x−µ
σ
⇒
P
−
Z
<
<
+
Z
≈
1
−
α
~& Z
⇒ x ± Zα
α
α2
2
σ/ n
2
σ/ n
n
x−µ
com nível de confiança de aproximadamente 100(1-α
α)%
Intervalo de confiança para amostras grandes:
Uma dificuldade prática na criação do intervalo de confiança é que deve-se
conhecer o valor de σ. Se substituirmos σ por s:
Z=
x−µ
Neste caso, existe aleatoriedade no numerador e no
s/ n
denominador ( x e s variam de amostra para amostra).
Entretanto, quando n é grande, o uso de s acrescenta
pouca variablidade extra a Z (é possível dizer que possui
aproximadamente distribuição normal padronizada).
⇒ x ± Zα
s
2
n
IC (µ
µ) de amostra grande (n>40) com nível confiança de
aproximadamente 100(1-α
α)% (é válido independentemente
da distribuição populacional).
Intervalo de confiança geral para amostras grandes:
ˆ −θ
θ
P − Z α <
< + Z α ≈ 1 − α ⇒ θˆ ± Z α sθˆ
2
2
2
s
θˆ
Tamanho da amostra:
θˆ ± Zα
s
... n = Zα / 2
B
n
2
s
2
Obs: Uma estimativa inicial de s é obtida por amplitude/4.
Intervalo de confiança monocaudais:
Se o interesse é determinar apenas limites superiores ou inferiores (de uma
amostra grande) deve-se criar limites de confiança:
x−µ
P
< +1,645 ≈ 0,95
s/ n
x−µ
≈ 0,95
P − 1,645 <
s/ n
Portanto, o limite de confiança superior para µ é:
E o limite de confiança inferior para µ é:
CONFIANÇA
90%
95%
99%
Zα
1,285
1,645
2,328
µ < x + Zα
µ > x − Zα
s
n
s
n
Intervalo de confiança para proporção (p):
Pelo TLC, se X é uma variável aleatória que “conta” o número de sucessos
em n tentativas independentes, e n é suficientemente grande
n o sucessos = x ~& N (np, np (1 − p ) )
x
= pˆ ~& N ( p, p (1 − p ) n )
n
Assim
pˆ − p
p(1 − p) n
⇒ P − Z α <
2
≈Z
< + Zα ≈ 1 − α
2
p(1 − p ) n
pˆ − p
Intervalo de confiança para proporção (p):
Desenvolvendo chega-se em:
pˆ (1 − pˆ )
pˆ +
± Zα
+ 22
2
2n
n
4n
p=
1 + Z α2 n
2
Z α2
Quando n é grande:
2
Zα
Z α2
2
2
Zα
2
2n
2
Zα
2
n
0
2
2
4n
0
0
⇒ p = pˆ ± Z α
2
pˆ (1 − pˆ )
n
Nível de confiança, Precisão e Tamanho da Amostra:
Sendo o nível de confiança 100(1-α
α)%, a precisão e o tamanho da amostra (n)
relacionados, uma boa estratégia é especificar o nível de confiança, e a
semi-amplitude do intervalo de confiança (B) e então determinar o
tamanho da amostra. Assim:
pˆ ± Zα
2
pˆ (1 − pˆ ) ... n = Z 2 pˆ (1 − pˆ )
α /2
2
B
n
Intervalo de confiança para variância e desvio padrão
de uma população Normal:
Seja x1, …, xn a amostra aleatória de uma distribuição normal com
parâmetros µ e σ2. Então a v.a.
(n − 1) s
σ2
2
∑ (X
=
i
− x)
i
σ2
possui distribuição de Qui-Quadrado (χ
χ2)
com n-1 gl.
Intervalo de confiança para variância e desvio padrão
de uma população Normal:
2
2
(
n − 1)s
2
⇒ P χ 1−α ,n −1 <
< χ α ,n −1 = 1 − α
2
2
2
σ
2
2
(
n − 1)s
(n − 1)s
2
... P 2
<σ < 2
= 1−α
χ1−α ,n −1
χα ,n −1
2
2
IC de σ2 com
nível de
:
confiança de
100(1-α
α)%
(n − 1)s 2 < σ 2 < (n − 1)s 2
2
2
χα
2
, n −1
χ1−α
2
, n −1
Intervalo de confiança para amostras pequenas:
Quando n é pequeno, s provavelmente não será mais próximo de σ, de modo
que haverá maior variabilidade na distribuição do estimador.
(
Assim, a distribuição de (x − µ ) s / n
) será mais dispersa que a distribuição
normal padronizada.
Teorema: Quando x é a média amostral de tamanho n de uma população normal
com média µ, a v.a. T possui uma distribuição t-Student com n-1 graus de
liberdade.
T=
x−µ
s/ n
Intervalo de confiança para amostras pequenas:
Seja tα,νν = o número no eixo de medição para o qual a área sob a curva t
com gl ν à direita de tα,νν é α; tα,νν é chamado valor crítico t.
⇒ P − tα ,n −1 < T < +tα ,n −1 = 1 − α
2
2
em que
T=
x−µ
s/ n
⇒ x ± tα
s
2
, n −1
n
IC de µ com nível
de confiança de
100(1-α
α)% para uma
população normal.
Intervalo de confiança para um único valor:
Em muitas aplicações o investigador deseja prever um único valor de uma
variável a ser observada futuramente, em vez de estimar o valor médio
dessa variável. Neste caso o interesse é no intervalo de previsão.
Seja x1, …, xn uma amostra aleatória de uma população com distribuição
normal e queremos prever o valor de xn+1. O previsor pontual é x e o erro
de previsão é (x – xn+1). Assim:
E[x – xn+1] = E[x] – E[xn+1] = µ – µ = 0
Var[x – xn+1] = Var[x] + Var[xn+1] = (σ
σ2/n) + σ2 = σ2 (1 + 1/n)
Intervalo de confiança para um único valor:
Assim:
(
(
x − xn +1 ) − 0
x − xn +1 )
Z=
=
2
1
σ 1 +
n
2
1
σ 1 +
n
E substituindo σ por s chega-se no intervalo de previsão (IP) de uma única
observação com nível de previsão de 100(1-α
α)%:
T=
(x − xn +1 )
1
s 1 +
n
⇒ xn +1
1
= x ± tα , n −1 s 1 +
n
2
Para casa:
• Lista de Exercícios 8 (site: www.mec.ita.br/~rodrigo/)
• Leitura: Devore – cap. 6: Estimativa pontual (até 6.1)
cap. 7: Intervalos estatísticos baseados …
Walpole et al. – cap. 9: Problemas de estimação … (9.1 a 9.7, 9.10
e 9.12)