1
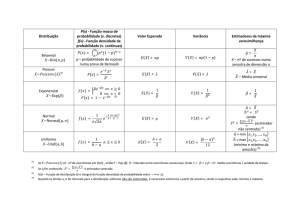
13 ESTIMAÇÃO DE PARÂMETROS E DISTRIBUIÇÃO AMOSTRAL
Como visto em amostragem no primeiro bimestre, existem fatores que fazem com que a
observação de toda uma população em uma pesquisa seja impraticável, muitas vezes em virtude do
custo e do tempo gasto. Considera-se então uma amostra, e se esta for representativa, os resultados
poderão ser generalizados para a população.
Toda conclusão tirada por uma amostragem, quando generalizada para a população, virá
acompanhada de um grau de incerteza ou risco.
O conjunto de técnicas e procedimentos que permitem obter informações sobre uma
população a partir de resultados observados na amostra recebe o nome de Inferência Estatística.
Um problema importante da Inferência Estatística é a estimação de parâmetros (tais como
a média (µ ) , o desvio padrão (σ ) , a variância σ 2 , etc) correspondente.
Existem dois casos de estimação de parâmetros: a estimação por ponto e a estimação por
intervalo. No primeiro caso, obtém-se um valor único para o parâmetro, ao passo que, no segundo,
constrói-se um intervalo em torno da estimativa por ponto, o qual deverá com probabilidade
conhecida, conter o parâmetro.
( )
13.1 ESTIMADOR /ESTATÍSTICA E ESTIMATIVA
Estimador T de um parâmetro θ é a variável aleatória, função dos elementos da amostra,
que será utilizada na estimação.
O valor numérico obtido para o estimador considerado, numa certa amostra, é denominado
de estimativa.
Por exemplo, ao estimarmos a média de uma população utilizamos como estimador a
média aritmética amostral, obtendo como estimativa o valor 173,5cm, por exemplo. Assim, o
estimador é a média aritmética e a estimativa é x = 173,5 cm.
A notação utilizada para o estimador geralmente é feita por letras maiúsculas, e para a
estimativa, letras minúsculas. No caso da média, a notação do estimador será X e da estimativa
será x .
13.2 DISTRIBUIÇÃO AMOSTRAL
Considere todas as possíveis amostras de tamanho n que podem ser extraídas de
determinada população. Se para cada uma delas se calcular um valor do estimador, tem-se uma
distribuição amostral desse estimador. Ora, como o estimador é uma variável aleatória, pode-se
determinar suas características, isto é, encontrar sua média, variância e desvio padrão.
Assim, a distribuição de probabilidade de um estimador, por exemplo X , é chamada de
distribuição amostral, neste caso distribuição amostral das médias.
13.2.1 Distribuição amostral das médias
Lembrando o conceito de distribuição amostral, visto anteriormente, buscamos descobrir
qual é a distribuição de probabilidade da média aritmética X .
Figura 1: Distribuição amostral das médias
2
Teorema 1: A média da distribuição amostral das médias, denotada por µ x é igual à média
E (X ) = µ x = µ
populacional µ . Isto é:
Assim, a média das médias amostrais é igual à média populacional.
(
)
Demonstração: Primeiramente vamos relembrar que X ~ N µ , σ 2 , assim:
n
∑ xi 1 n 1 n
= E ∑ x i = ∑ E ( x i ) = 1 ∑ µ = 1 nµ = µ
E (X ) = E
n n i =1 n i =1
n i =1
n
∑ xi 1
nσ 2 σ 2
=
(
)
=
=
V (X ) = V
V
x
i
2
n n2 ∑
n
n
σ2
Portanto: X ~ N µ ,
n
Teorema 2: Se a população é infinita, ou se a amostragem é com reposição, então o desvio padrão
(também chamado de erro padrão) da distribuição amostral das médias, denotado por σ x é dado
σx =
por:
σ
n
Teorema 3: Se a população é finita, ou se a amostragem é sem reposição, então o desvio padrão da
distribuição amostral das médias é dado por:
σ N −n
σx =
n N −1
N −n
Onde o fator
é denominado de fator de população finita.
N −1
N −n
= 1 . Dessa forma quando tiramos uma amostra grande de
N → +∞ N − 1
uma população muito maior (pelo menos o dobro), é indiferente usar o fator de população finita
para se calcular σ x , pois o erro será muito, pequeno.
Para n suficientemente grande ( n ≥ 30 ), tem-se que a distribuição amostral das médias é
aproximadamente normal, garantido pelo Teorema central do Limite1. Se a população for normal,
a distribuição amostral das médias também será normal, independente do tamanho da amostra.
Pode-se notar que lim
Teorema 4: Podemos concluir que:
σ N −n
σ
para populações finitas.
X ~ N µ ,
para populações infinitas, e X ~ N µ ,
N
−
1
n
n
Para os casos de populações infinitas ou finitas, as variáveis padronizadas serão dadas,
respectivamente por:
X −µ
X −µ
Z=
ou
Z=
σ
σ N −n
n
n N −1
1
Se estivermos realizando uma amostragem de uma população que tenha uma distribuição de probabilidade
desconhecida, a distribuição amostral de média da amostra será aproximadamente normal, com média µ e variância
σ 2 n , se o tamanho da amostra for grande. Esse é um dos teoremas mais úteis em estatística. Ele é chamado de
Teorema Central do limite .
3
13.2.2 Distribuição Amostral das Variâncias
Tomando todas as amostras aleatórias possíveis, de tamanho n, de uma população, e
calculando a variância de cada amostra, obtemos a distribuição amostral das variâncias. Se as
amostras de tamanho n forem extraídas de uma população normal de variância σ 2 , então a variável
aleatória χ 2 , dada por
(n − 1)s 2
χ2 =
σ2
onde s 2 é a variância amostral, dada por
n
s2 =
∑ ( x i − x )2
i =1
n −1
que tem uma distribuição qui-quadrado com ν = n − 1 graus de liberdade.
Dessa forma, temos que :
(n − 1)s 2
σ
2
~ χ n2−1 .
Podemos dizer também, que
s2 =
σ2
n −1
⋅ χ n2−1
isto é, s 2 segue uma distribuição χ 2 , com ν = n − 1 graus de liberdade.
Figura 3: Distribuição amostral da estatística qui-quadrado
Pode-se demonstrar que a distribuição amostral das variâncias s 2 , a média µ s 2 e a variância σ s22
são dadas respectivamente por:
µ s2 = E s 2 = σ 2
( )
σ s2 = V (s 2 ) =
2
2σ 4
n −1
13.2.3 Distribuição amostral das proporções ou freqüências relativas
Seja X uma população infinita tal que p seja a probabilidade de sucesso de certo evento e
q = 1 − p a probabilidade de fracasso. Seja ( x1 , x2 , K , x n ) uma amostra aleatória de n elementos
dessa população e h o número de sucessos na amostra, identificado como uma variável aleatória
com distribuição Binomial, de média np e variância npq. Podemos determinar ainda a freqüência
4
h
. O conjunto das freqüências relativas calculadas para cada
n
amostra constitui a distribuição amostral das proporções ou freqüências relativas.
relativa ou proporção como f r = P =
Figura 3: Distribuição amostral das proporções
( )
A média (µ P ) e a variância σ P2 dessa distribuição serão dadas, respectivamente, por:
h np
E (P ) = E =
= p ⇒ µP = p
n n
npq pq
pq
h 1
V (P ) = V = 2 ⋅ V (h ) = 2 =
⇒ σ P2 =
n
n
n
n n
Logo, a distribuição amostral das médias tem uma média µ P = p e desvio padrão
σP =
pq
.
n
No caso de amostragem obtida sem reposição ou população finita, tem-se que:
µP = p e σ P =
pq N − n
⋅
n N −1
Sendo as amostras suficientemente grandes, a distribuição amostral das proporções, que
segue a distribuição binomial, poderá se aproximar de uma distribuição normal de mesma média e
mesma variância. Na prática, essa aproximação é utilizada para np ≥ 5 e nq ≥ 5. Assim, para esses
pq
casos, P ~ N p,
e os valores da variável padronizada são dados por:
n
P − µP
Z=
pq
n
Como a distribuição amostral das proporções é Binomial, que é discreta, e vamos usar uma
1
,
aproximação pela normal, que é contínua, o cálculo de Z deve ser corrigido por meio do fator
2n
1
P±
− µP
2n
ficando: Z =
.
pq
n
Esse fator de correção corresponde à semi-amplitude dos intervalos entre dois valores
consecutivos de P. Dessa forma, um valor de P passa a ser representado por um intervalo de
1
1
.
amplitude e extremos P ±
n
2n
5
Exercícios
1) Uma população se constitui dos números 2, 3, 4 e 5. Considere todas as amostras possíveis, de
tamanho 2, que podem ser extraídas dessa população sem reposição. Determine a distribuição
amostral das médias, calculando a média e o desvio padrão dessa distribuição.
Resposta: µ x = 3,5 e σ x = 0,64
2) Seja X ~ N (80, 26) . Retira-se dessa população uma amostra de tamanho n = 25 . Calcular:
a) P( x > 83)
b) P( x < 82)
c) P ( x − 2σ x ≤ µ ≤ x + 2σ x )
Respostas: a) 0,0016
b) 0,975
c) 0,9544
3) Seja X ~ N (1200, 840) . Qual deverá ser o tamanho de uma amostra de tal forma que
P(1196 < x < 1204) = 0,9 ?
Resposta: n ≈ 144
4) Uma indústria fabrica válvulas elétricas, sendo 5% defeituosas. Foi adquirido um lote de 1000
válvulas. Qual a probabilidade de que o lote tenha:
a) exatamente 30 válvulas defeituosas?
b) mais de 60 válvulas defeituosas?
c) no máximo 50 válvulas defeituosas?
Respostas: a) 0,013
b) 0,0262
c) 0,5359
5) A granja “Ovo Bom” vende ovos aos supermercados em lotes de 100 caixas de seis dúzias. Dado
que seus lotes costumam apresentar 5% de ovos chocos, em quantas amostras de 20 caixas esperamse encontrar menos de 90% de ovos bons?
Resposta: Em no máximo 1 caixa.
6) Deseja-se saber qual a proporção de pessoas da população portadoras de determinada doença.
Retira-se uma amostra de 400 pessoas, obtendo-se 8 portadores da doença. Definir limites de
confiabilidade de 99% para a proporção populacional.
Resposta: 12 ≤ p ≤ 1488 proporção de pessoas portadoras de doenças.
4) Certa indústria remete 1000 caixas contendo 30 componentes eletrônicos cada uma. Se 4% dos
componentes são defeituosos, em quantas caixas podemos esperar que existam pelo menos 27
componentes perfeitos?
Resposta: 983 caixas
13.3 Qualidade de um bom estimador
Quanto maior o grau de concentração da distribuição amostral do estimador em torno do
verdadeiro valor do parâmetro populacional, melhor será o estimador. As principais qualidades de
um estimador devem ser:
a) Consistência (estimador consistente);
b) Ausência de vício (estimador não-tendencioso);
c) Eficiência (estimador de variância mínima);
d) Suficiência (estimador suficiente).
6
13.3.1 Estimador consistente
Um estimador Tn de um parâmetro θ é dito consistente se as seguintes condições forem
satisfeitas:
lim E (Tn ) = θ e lim V (Tn ) = 0 .
n →∞
n →∞
De forma geral, pode-se dizer que um estimador é consistente quando para amostras
suficientemente grandes tornam o erro de estimação tão pequeno quanto se queira.
Exercício 1: Mostre que a média amostral X é um estimador consistente da média populacional µ
(considere amostragem com reposição).
Resolução:
Obs :Se a população é infinita ou se a amostragem é com reposição, então o desvio padrão da
média, também chamado de erro padrão, é σ x =
n
∑ xi
lim E (X ) = lim E i =1
n →∞
n →∞
n
lim V ( X ) = lim
n →∞
n→∞
σ2
n
σ
.
n
n
n
n
= lim 1 E x = lim 1 E ( x ) = lim 1 µ = lim 1 nµ = µ
∑
∑
∑
i
i
n→∞ n i =1 n→∞ n i =1
n→ ∞ n
n →∞ n
i =1
=0
13.3.2 Estimador não-tendencioso
Um estimador Tn de um parâmetro θ é dito não-tendencioso, não-viciado, justo ou nãoviesado se:
E (Tn ) = θ .
O valor da tendenciosidade B é definida como sendo B = E (t n ) − θ .
Observação: para estimadores não-tendenciosos, a condição de consistência é
simplesmente lim V (t n ) = 0 .
n →∞
(
)
Exercício 2: Seja X ~ N µ , σ 2 . Sabemos que X é um estimador não-tendencioso de µ , pois
n
como já demonstrado, E (X ) = µ . Mostre que s 2 =
σ 2 , ou seja, E (s 2 ) = σ 2 .
Resolução:
n
2
∑ ( xi − x )
E s 2 = E i =1
n −1
n
1
E s2 =
E ∑ xi2 − 2nx 2 + nx 2
n − 1 i =1
( )
( )
( )
E s2 =
1
n
E ∑ xi2 − nx 2
n − 1 i =1
∑ ( x i − x )2
i =1
n −1
é um estimador não-tendencioso de
7
( )
E s2 =
1 n
E ∑ xi − E nx 2
n − 1 i =1
( )
1
E (s 2 ) =
∑ E ( xi ) − nE (x 2 )
n − 1 i =1
n
(
(1)
)
Temos que X ~ N µ , σ 2 , então:
( ) − [E ( X )]
V (X ) = E X
2
2
( ) = V ( X ) + [E ( X )]
E (X ) = σ + µ
E X
2
2
2
2
(2)
2
E além disso:
2
V (X ) = E X 2 − [E ( X )]
σ
2
( )
= E (X ) − µ
2
n
( )=
E X
2
σ2
n
2
(3)
+ µ2
Assim:, substituindo (2) e (3) em (1) , temos:
( )
σ 2
1 n
∑ σ 2 + µ 2 − n
+ µ 2
n − 1 i =1
n
1
=
nσ 2 + nµ 2 − σ 2 − nµ 2
n −1
1
=
σ 2 (n − 1)
n −1
=σ 2
(
E s2 =
( )
E s2
( )
E (s )
E s2
2
)
(
(
)
)
Portando s 2 é um estimador não tendencioso de σ 2 .
13.3.3 Estimador de variância mínima
Dados dois estimadores T1 e T2 , usados na estimação de um mesmo parâmetro θ , diz-se
que T1 é mais eficiente que T2 como estimador de θ se, para o mesmo tamanho da amostra
E (T1 − θ ) < E (T2 − θ ) .
2
2
Se T1 e T2 forem estimadores não-tendenciosos de θ , ou seja E (T1 ) = θ e E (T2 ) = θ , essa
condição indicará que a variância de T1 é menor que a variância de T2 , ou seja, V (T1 ) < V (T2 ) .
Se T1 é mais eficiente que T2 como estimador de θ , pode-se definir a relação
[
E [(T
]
−θ ) ]
E (T1 − θ )
2
2
2
como sendo a eficiência de T2 em relação a T1 como estimador de θ . Se T1 e T2 forem ambos nãotendenciosos, a eficiência relativa se reduzirá ao quociente das respectivas variâncias, ou seja,
V (T1 )
.
V (T2 )
8
13.3.5 Estimador suficiente
Um estimador Tn de θ é suficiente se ele tem a capacidade de retirar da amostra toda
informação que ela pode fornecer.
Exemplo: A média X é um estimador suficiente de µ .
13.4 Estimação por ponto
Na estimação por ponto o parâmetro é estimado através de um valor único, que
corresponde a um ponto sobre o eixo de variação da variável. A seguir são apresentados alguns dos
principais estimadores por ponto.
13.4.1 Estimador da média populacional µ
O estimador nesse caso é a média aritmética amostral, sendo não-tendencioso, eficiente e
suficiente, dado por:
n
X =
∑ xi
i =1
n
13.4.2 Estimador da variância populacional σ 2
Quando a média populacional µ for conhecida, o estimador será a variância amostral s 2 ,
dada por:
n
s2 =
∑ ( x i − µ )2
i =1
n
.
Quando µ for desconhecida, a variância amostral s 2 será dada por:
n
s2 =
∑ ( x i − x )2
i =1
n −1
Nos dois casos temos estimativas não-tendenciosas.
13.4.3 Estimador do desvio padrão populacional σ
Sabemos que o desvio padrão é definido como a raiz quadrada da variância, porém, mesmo
sendo s um estimador não-tendencioso da variância populacional, a raiz quadrada de s 2 não é um
estimador não-tendencioso do desvio padrão populacional σ . Entretanto, a tendenciosidade de s
tende a zero no caso de grandes amostras. Portanto, para grandes amostras, quando µ for
conhecida,
2
n
s=
∑ (xi − µ )2
i =1
n
9
e quando µ for desconhecida,
n
∑ ( x i − x )2
i =1
s=
n −1
.
13.4.4 Estimador da proporção populacional p
O estimador não-tendencioso P da proporção populacional p é fornecido por:
h
P=
n
onde h é o número de sucessos na amostra.
Exercício: Uma amostra de 10 válvulas eletrônicas foi testada e os tempos de vida (em horas)
foram:
2100, 2150, 2200, 2130, 2180, 2120, 2180, 2100, 2130 e 2160
Estimar o tempo médio de vida e a variância desse tipo de válvula.
Resposta: X = 1205,56 , V (X ) = 2145h
13.5 Estimação por Intervalos
A estimação por pontos de um parâmetro não possui uma medida do possível erro
cometido na estimação. Uma maneira de expressar a precisão da estimação é estabelecer limites,
que com certa probabilidade incluam o verdadeiro valor do parâmetro da população.
Seja o parâmetro θ , tal que P(t1 ≤ θ ≤ t 2 ) = 1 − α . O intervalo t1 ≤ θ ≤ t 2 é denominado de
intervalo de confiança (IC); os extremos desse intervalo (t1 e t 2 ) são denominados de limites de
confiança; a probabilidade (1 − α ) é denominada de nível de confiança; e α é o nível de incerteza
da inferência, ou nível de significância.
A escolha do nível de confiança (1 − α ) depende da precisão com que se deseja estimar o
parâmetro. É muito comum a utilização dos níveis de 95% e 99%. Evidentemente, o aumento da
confiança no intervalo implica no aumento de sua amplitude.
13.5.1 Intervalo de confiança para a media populacional µ
1° caso: O desvio padrão populacional σ é conhecido.
Considere uma população normal com média desconhecida que desejamos estimar e
variância σ 2 conhecida, ou seja, X ~ N ?, σ 2 .
Procedimento para a construção do IC:
1. Retiramos uma amostra casual simples de tamanho n.
2. Calculamos a média amostral X .
(
)
3. Calculamos o desvio padrão da média amostral: σ x =
σ
n
4. Fixamos o nível de significância α , e com ele determinamos zα / 2 , tal que
P (Z > z α / 2 ) =
α
2
e P (Z < z α / 2 ) =
α
2
. Graficamente temos:
10
Portanto, P (− zα / 2 ≤ Z ≤ zα / 2 ) = 1 − α . Substituindo Z =
x−µ
σ
e isolando µ , temos:
n
σ
σ
≤ µ ≤ x + zα / 2 ⋅
= 1 − α
P x − zα / 2 ⋅
n
n
Dessa forma, o IC de (1 − α )% para µ será:
x − zα / 2 ⋅
σ
n
≤ µ ≤ x + zα / 2 ⋅
σ
n
Exercícios:
1) De uma população normal X, com σ 2 = 9 , tiramos uma amostra de 25 observações, obtendo
25
∑ xi = 152. Determinar um IC de 90% para a média populacional.
i =1
Resposta: (5,09;7,07 )
2) O desvio padrão dos comprimentos das peças produzidas por certa máquina é 2 mm. Uma
amostra de 50 peças produzidas por essa máquina apresentou média x = 25 mm. Construir o IC de
95% para o verdadeiro comprimento das peças produzidas por essa máquina.
Resposta: (24,4;25,6)
3) De uma população normal com σ = 5 , tiramos uma amostra de 50 elementos e obtemos x = 42 .
a) Determine o IC para a média ao nível de significância de 5%.
b) Qual o erro de estimação ao nível de 5%.
c) Para que o erro seja menor ou igual a 1, com probabilidade de acerto de 95%, qual deverá ser o
tamanho da amostra?
Resposta: a) (40,61;43,386)
b) 1,39
c) n ≥ 96
11
2° caso: O desvio padrão populacional σ é desconhecido.
Neste caso utilizamos a distribuição t de Student. Os procedimentos são os mesmos do
caso anterior e graficamente temos:
Devemos então, determinar o valor de tα / 2 , tal que:
P(− tα / 2 ≤ t ≤ tα / 2 ) = 1 − α
onde t =
x−µ
, com ν = n − 1 graus de liberdade.
s
n
Portanto, IC de (1 − α )% para µ será:
x − tα / 2 ⋅
s
n
≤ µ ≤ x + tα / 2 ⋅
s
n
.
Sabemos que a distribuição t de Student tende para a distribuição normal padrão quando
ν → ∞ , e como ν depende de n , podemos utilizar a distribuição normal quando n > 30 .
Exercícios
1) Uma mostra de cabos produzidos por uma indústria foi ensaiada e as tensões de ruptura obtidas
foram (em kgf): 750, 780, 745, 770 e 765. Construir o IC de 99% para a verdadeira tensão de
ruptura dos cabos.
Resposta: (7324;791,6)
2) A altura dos homens de uma cidade apresenta distribuição normal. Para estimar a altura média
150
dessa população, levantou-se uma amostra de 150 indivíduos obtendo-se
∑ xi = 25800 cm e
i =1
150
∑ xi2 = 4.440.075 cm 2 .
i =1
Resposta: (171,23;172,78)
3) Uma amostra aleatória de 80 notas de matemática de uma população com distribuição normal de
5000 notas apresenta média de 5,5 e desvio padrão de 1,25.
a) Quais os limites de confiança de 95% para a média das5000 notas?
b) Com que grau de confiança diríamos que a média das notas é maior que 5,0 e menor que 6,0?
Resposta: a) (5,23;5,77 )
b) 99,96%
12
13.5.2 Intervalo de confiança para a diferença entre duas médias populacionais µ1 e µ 2
1º caso: Os desvios padrões populacionais σ 1 e σ 2 são conhecidos
Neste caso utilizamos a estatística z dada por:
(x − x2 ) − (µ1 − µ 2 )
z= 1
σ 12
n1
+
σ 22
n2
onde P(− zα / 2 ≤ z ≤ zα / 2 ) = 1 − α .
Substituindo a estatística z na probabilidade acima e isolando µ1 − µ 2 , obtemos o IC de
(1 − α )100% para a diferença entre as médias:
(x1 − x2 ) − zα / 2 ⋅
σ 12
n1
+
σ 22
n2
≤ µ1 − µ 2 ≤ ( x1 − x 2 ) + zα / 2 ⋅
σ 12
n1
+
σ 22
n2
Exemplos:
1) Das populações normais e independentes X e Y extraem-se amostras de tamanho n x = 9 e
n y = 15 . As médias amostrais são x = 10 e y = 5 ; os desvios padrões populacionais são σ x = 6 e
σ y = 3 . Determine o IC da diferença das médias populacionais a um nível de significância de 3%.
Resposta: 0,346 ≤ µ x − µ y ≤ 9,65
2) Os desvios padrões das durações das lâmpadas elétricas fabricadas pelas indústrias A e B são,
respectivamente, 50h e 80h. Foram ensaiadas 40 lâmpadas de cada marca e as durações médias
obtidas foram 1200h e 1100h, para A e B, respectivamente. Construir o IC de 99% para a diferença
entre os tempos médios de vida das lâmpadas de marcas A e B.
Resposta: 61,5 ≤ µ A − µ B ≤ 138,5
2º caso: Os desvios padrões populacionais σ 1 e σ 2 são desconhecidos e supostamente iguais
Neste caso utilizamos a estatística t dada por:
t=
(x1 − x2 ) − (µ1 − µ 2 )
1
1
s 2p +
n1 n2
, onde s 2p =
(n1 − 1)s12 + (n2 − 1)s 22
n1 + n 2 − 2
e ν = n1 + n2 − 2
Dessa forma, construímos o IC de (1 − α )100% para a diferença entre as médias:
1
1
1
1
s 2p + ≤ µ1 − µ 2 ≤ ( x1 − x 2 ) + tα / 2 ⋅ s 2p +
n1 n2
n1 n2
Exemplo: Os diâmetros (em mm) de uma amostra de 5 tubos da fábrica A sã: 45, 47, 45, 44 e 46.
Uma amostra de 6 tubos da fábrica B apresentou os diâmetros: 43, 45, 44, 44, 46 e 43 mm.
Construir o IC de 95% para a diferença entre os diâmetros médios.
Resposta: − 0,38 ≤ µ A − µ B ≤ 2,78
(x1 − x2 ) − tα / 2 ⋅
13
3º caso: Os desvios padrões populacionais σ 1 e σ 2 são desconhecidos e supostamente diferentes
Nesse caso utilizamos um método aproximado denominado Aspin-Welch, cuja estatística é
dada por:
t=
(x1 − x2 ) − (µ1 − µ 2 )
s12 s 22
+
n1 n2
com os graus de liberdade sendo o inteiro mais próximo ao resultado da relação:
ν≅
(w1 + w2 )2
w12
w22
+
n1 − 1 n 2 − 1
, onde w1 =
s12
s2
e w1 = 2
n1
n2
Exemplo: Em certo município, registros pluviométricos mostram que nos últimos 8 anos, durante o
mês de janeiro, a queda média foi de 125 mm com desvio padrão s1 = 25 mm. Outro município
apresentou nos últimos 5 anos, também no mês de janeiro, uma queda média de 100 mm cm desvio
padrão s 2 = 5 mm. Construa um IC de 99% para a diferença entre as quedas pluviométricas médias
µ1 e µ 2 .
Resposta: − 5,6 ≤ µ1 − µ 2 ≤ 55,6
13.5.3 Intervalo de confiança para a variância populacional σ 2
Observando a figura abaixo percebemos que P (χ
2
1−α / 2
≤ χ ≤ χα / 2
2
com ν = n − 1 graus de liberdade.
O IC de (1 − α )100% para σ 2 será:
(n − 1)s 2 ≤ σ 2 ≤ (n − 1)s 2
2
2
χα / 2
χ1−α / 2
2
) = 1 − α , onde χ
2
(
n − 1)s 2
=
,
σ2
14
Para construir o IC de (1 − α )100% para o desvio padrão populacional σ basta considerar a
raiz quadrada positiva do IC para a variância σ 2 . Dessa forma, temos para este caso:
(n − 1)s 2 ≤ σ
2
χα / 2
≤
(n − 1)s 2
χ12−α / 2
Exemplo: De uma amostra aleatória de dez itens de uma população normal obteve-se: x = 8 e
s 2 = 0,25 . Estime a variância e o desvio padrão populacionais, a 5% de significância.
Resposta: 0,34 ≤ σ ≤ 0,91
13.5.4 Intervalo de confiança para a proporção populacional p
Sabemos que para amostras suficientemente grandes, a distribuição amostral das proporções
P− p
é aproximadamente normal, com z =
.
pq
n
Para construirmos o IC para a proporção p populacional, determinamos p̂ na amostra,
h
onde pˆ = P = e qˆ = 1 − pˆ = 1 − P . Dessa forma, temos o IC de (1 − α )100% para p dado por:
n
P − zα / 2 ⋅
pˆ (1 − pˆ )
≤ p ≤ P + zα / 2 ⋅
n
pˆ (1 − pˆ )
n
Exemplos:
1) Em uma linha de produção de certa peça mecânica, colheu-se uma amostra de 100 itens,
constatando-se que 4 peças eram defeituosas. Construir o IC para a proporção p das peças
defeituosas ao nível de10%.
Resposta: 0,00767 ≤ p ≤ 0,00723
2) Para se estimar a porcentagem de alunos de um curso favoráveis à modificação do currículo
escolar, tomou-se uma amostra de 100 alunos, dos quais 80 foram favoráveis.
a) Construir um IC para a proporção de todos os alunos do curso favoráveis à modificação ao nível
de 4%.
b) Qual o valor do erro de estimação cometido em (a)?
Resposta: a) 0,718 ≤ p ≤ 0,88
b) e = 0,082