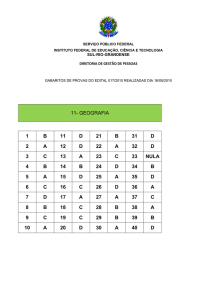
Cálculo do tamanho amostral
e da potência estatística
Paulo Nogueira
Exemplo 1
• Existe diferença na eficácia do Salbutamol e do
ipratropium no tratamento da Asma?
• O investigador delineou um ensaio aleatorizado do efeito destes
fármacos na FEV1 (Forced Experatory Volume durante um
segundo) após uma semana do tratamento.
• Um estudo anterior relatou que a média do FEV1 em pessoas com
asma tratadas 2.0 litros, com desvio padrão de 1.0 litros.
• O investigador pretende ser capaz de detectar uma diferença de
10% ou mais na média de FEV1 entre os dois grupos de
tratamento.
• Quantos pacientes são necessários em cada grupo (Salbutamol e
ipratropium ) para alfa (bi-caudal) de 5% e uma potência de 80%?
Variáveis
• Que variáveis estão envolvidas neste
problema?
• De que tipo são estas variáveis?
• Como é usual estudar (estatisticamente)
este problema, qual é o teste usado?
Hipóteses
• Qual a hipótese em estudo?
• Qual a hipótese nula?
• Qual a hipótese alternativa?
Termos
• Que termos do problema são novos?
Exemplo 2
• Fumadores idosos têm maior incidência de
cancro da pele do que os não fumadores?
• Uma revisão da literatura científica pré existente
sugere que a incidência 5 anos de cancro da
pele é cerca de 0,20 nos não fumadores idosos.
• A um nível de alfa de 5% (bi-caudal) e uma
potência de 80%, quantos fumadores e não
fumadores é necessário estudar para
determinar se a incidência 5 anos de cancro da
pele é pelo menos 0,30 nos fumadores?
Variáveis
• Que variáveis estão envolvidas neste
problema?
• de que tipo são estas variáveis?
• Como é usual estudar (estatisticamente)
este problema, qual é o teste usado?
Hipóteses
• Qual a hipótese em estudo?
• Qual a hipótese nula?
• Qual a hipótese alternativa?
Termos
• Que termos do problema são novos?
Noções breves de Estatística
Para que serve a estatística?
Qual o seu principal objectivo?
Noções breves de Estatística
Para que serve a estatística?
Qual o seu principal objectivo?
Recolha, organização, classificação, análise e interpretação de dados
através da criação de instrumentos adequados: quadros, gráficos,
permitindo de uma maneira geral fazer inferências a partir de um conjunto
de dados.
obter conclusões sobre a população usando uma
amostra!
População
Amostragem
Amostra
Uma ou mais variáveis
(X) são observadas
Noções de Estatística
População – conjunto de objectos, indivíduos ou resultados
experimentais acerca do qual se pretende estudar alguma característica
comum. Aos elementos da população chamamos unidades estatísticas.
Amostra – parte ou subconjunto da população que é observada com o
objectivo de obter informação para estudar a característica pretendida.
População
Verdadeiro valor
µ
Amostragem
Amostra
Uma ou mais variáveis
(X) são observadas
medição
média
Noções breves de Estatística
1. Estatística Descritiva
Explorar, apresentar e resumir os dados da amostra.
(tabelas, Gráficos, medidas de localização, medidas de
dispersão, etc.)
2. Inferência Estatística
Afirmações sobre parâmetros da população.
(Estimativas pontuais, intervalos de confiança, Testes de
hipóteses)
Noções breves de Estatística
Exemplos de variáveis
X - indica o Sexo (Masculino, Feminino).
X - representa a Altura (cm).
X - representa o Número de filhos.
X - representa o Grupo Sanguíneo.
X - representa o Colesterol (mg/dL)
X - representa o Resultado do Tratamento
(melhoria, sem alterações, pioria).
Tipos de Variáveis
Qualitativas
Quantitativas
Noções de Estatística
Qualitativas
Nominais
Não existe uma ordem entre as categorias
Exemplos:
Sexo (dicotómica),
Grupo sanguíneo (policotómico).
Ordinais
Existe uma ordem natural
Exemplos:
Resultado do tratamento ( - ; = ; + )
Habilitações literárias
Classe social.
Noções de Estatística
Quantitativas
Discretas (contagens)
Exemplos:
Nº. de elementos do agregado familiar.
Número de glóbulos brancos numa amostra de sangue.
Contínuas
Exemplos:
Altura, Idade, Pressão arterial.
Testes de Hipóteses
Hipótese
H0: Não existe efeito vs. H1: Existe efeito
Hipótese nula
Hipótese alternativa
Estatística de teste
Varia conforme a natureza do problema
Distribuição da estatística de teste
Varia conforme a natureza do problema
Decisão (Região Crítica)
Ou rejeito a hipótese nula o que significa que existe um efeito de tratamento
Ou não rejeito a hipótese nula o que significa que não existem evidências
de um efeito de tratamento
Aceitar ou Não rejeitar?
Do ponto de vista estatístico puro não se diz “Aceito H0”,
porque existem sempre erros.
O facto de não se rejeitar H0 pode ter duas causas:
•Ou o efeito não existe
•Ou não existe potência para mostrar o efeito.
Interpretação dos p-values
O p-value é a probabilidade de observar os dados quando a
hipótese nula é verdadeira.
Por exemplo num ensaio clínico
Estamos interessados na diferença observada entre dois
grupos de tratamento.
Relacionamos então os dados com a provável variação numa
amostra devida ao acaso quando a hipótese nula é verdadeira
na população.
Regra geral,
Se o p-value > 0,05
Se o p-value < 0,05
o resultado do teste não
é significativo
o resultado do teste é significativo
(rejeita-se a hipótese nula)
Se o p-value < 0,01
Pode-se dizer que o resultado é
muito significativo
Erros de Tipo I e Tipo II
Existem sempre erros ao fazer um teste de hipóteses.
Realidade: H0
Decisão: H0
Verdadeira
Falsa
Verdadeira
Falsa
confiança
Erro II
1−α
β
Erro I
Potência
α
1−β
α = P[erro de tipo I] = P[Rejeitar H 0 | H 0 é verdadeira ]
β = P[erro de tipo II] = P[Não Rejeitar H 0 | H 0 é falsa ]
Potência = 1 − β = P[Rejeitar H 0 | H 0 é Falsa ]
Amostragem
POPULAÇÃO
Conjunto de elementos que partilham pelo
menos uma característica comum
Colecção completa de unidades, a partir da qual
se podem constituir amostras (universo)
AMOSTRA
Uma parte seleccionada de uma população
UNIDADE DE OBSERVAÇÃO
Cada um dos elementos da amostra
Passos para a amostragem
• Definição do tamanho da amostra – número de
elementos a seleccionar
• Sobre dimensionamento para precaver as perdas ou
não respostas
• Escolha de uma boa lista (pool) da população
• Método aleatório para a selecção dos elementos
• Método rigoroso de colheita dos dados
Recolha da amostra
(como é que eu faço a recolha da amostra?)
• Não há respostas mágicas!
• Devemos procurar não incorrer em erros
sistemáticos?
– Erros que a metodologia estatística não
controla
Que factores podem afectar o fenómeno que estamos a
medir?
– Tempo?
– Espaço/geografia?
– Vegetação/água?
• Evitar erro sistemático!
– Não fazer amostragem sempre
• no mesmo dia da semana;
• à mesma hora do dia.
– Não deixar amostragem depender do critério pessoal
• Fazer plano de amostragem
• Fazer aleatorização
• A amostra é recolhida numa única sessão
ou em várias?
– Uma única sessão pode não cobrir toda a
variabilidade existente
• aleatorizar
• Planear!
– Conceber uma grelha
– Listar freguesias/localidades/áreas
– Listar, listar, listar…
• Seleccionar aleatoriamente
• Recolher
1
2
3
4
5
6
7
8
9
10
11
12
13 14
15
16
•Lista de números aleatórios
•Excel
•SPSS
•Etc.
Sequência de números aleatórios
Obtida com o EXCEL (Folha de dados)
6
11
7
12
10
9
7
14
7
16
7
4
13
6
13
6
8
13
13
3
7
7
5
10
16
13
13
7
2
1
5
6
5
5
1
14
13
1
10
16
6
11
11
5
16
6
2
12
16
5
7
11
9
11
10
7
4
3
3
4
9
10
16
7
• Leitura da lista de números aleatórios
– Escolher ao acaso uma posição (apontar de olhos
fechados)
• Numa lista feita expressamente para o efeito não é muito
importante verificar esta regra
– Escolher uma direcção (esq-dta) ou (cima-parabaixo)
– Listar número
– Se o número é repetido ignorar e passar ao
seguinte
– Se o número não existe nos nossos itens (ex 18 e só
temos itens de 1 a 16) ignorar e passar ao
seguinte
Exemplo
• Vamos ler a esq-dta (em linha)
• Escolher 3 unidades amostrais
• Escolhida posição inicial suponhamos
linha 4, coluna 2
• 6;13
• O número seguinte é 6 novamente, já faz
parte da lista, passamos ao seguinte 8
• A lista final é 6;13;8
resultado
1
2
3
4
5
6
7
8
9
10
11
12
13 14
15
16
Amostra probabilística – todos os elementos tiveram a mesma probabilidade
de fazer parte da amostra
• Regra prática para fazer uma lista no
Excel
– Numa qualquer célula, escrever:
•
=int(aleatório()*k+1)
• Arrastar fórmula ao longo de várias células
• k é o número máximo de itens da lista
– A função “aleatório()” é volátil, sempre que
fizermos alguma operação no excel a lista
muda.
Tamanho da amostra
(qual é a dimensão da amostra que preciso?)
• Perguntas comuns que não se devem
fazer!
– Qual é o tamanho de amostra significativo?
– Qual é o tamanho de amostra representativo
para o meu caso?
• Coisas que se deve evitar dizer:
– Não há dados nenhuns sobre este meu tema;
– Não se sabe nada sobre o assunto;
– Estamos a partir do zero.
• Se for o caso, o que se pode fazer está
mais ou menos bem definido
Tamanho da amostra
(qual é a dimensão da amostra que preciso?)
• Situações usuais
– Uma população
• Proporções/prevalências
• Médias
– Duas populações
•
•
•
•
Comparação de Proporções
Comparação de Médias
Correlação
Risco relativo
– Correlação
– Várias populações
• ANOVA
– Regressão
– Emparelhamento
• Proporções
• Médias
Tamanho da amostra
(qual é a dimensão da amostra que preciso?)
• Situações usuais
– Uma população
• Proporções/prevalências
• Médias
– Duas populações
•
•
•
•
Comparação de Proporções
Comparação de Médias
Correlação
Risco relativo
– Várias populações
• ANOVA
– Emparelhamento
• Proporções
• Médias
Situações mais comuns
Tamanho da amostra
(qual é a dimensão da amostra que preciso?)
• Situações usuais
– Uma população
• Proporções/prevalências
• Médias
– Duas populações
•
•
•
•
Comparação de Proporções
Comparação de Médias
Correlação
Risco relativo
– Várias populações
• ANOVA
– Emparelhamento
• Proporções
• Médias
Situações mais fáceis
Para determinar um tamanho de amostra o
investigador tem de responder a diversas
questões
• Qual a variação dos dados?
• Qual o erro que tolera na conclusão de
que existe um efeito/diferença quando na
realidade ele(a) não existe?
• Qual a magnitude do efeito/diferença a
detectar?
• Qual a certeza com que queremos
detectar o efeito/diferença?
Passos para a amostragem
• Definição do tamanho da amostra – número de
elementos a seleccionar
• Sobre dimensionamento para precaver as perdas ou
não respostas
• Escolha de uma boa lista (pool) da população
• Método aleatório para a selecção dos elementos
• Método rigoroso de colheita dos dados
Linguagem estatística
• Erro tipo I (α)
• Probabilidade de rejeitar a hipótese nula quando é verdadeira
• Erro tipo II (β)
• Probabilidade de não rejeitar a hipótese nula quando esta é falsa
• Potência (1-β)
• Probabilidade de rejeitar a hipótese nula quando é falsa
• Confiança (1-α)
• Probabilidade de não rejeitar a hipótese nula quando é verdadeira
• Quantis de distribuições
– Normal
– T-de-student
– F
• Diferença (Effect size)
A considerar
• Qual a variação dos dados?
– Quando se trata de uma proporção
(estimar a prevalência de asma região Norte)
• Basta ter a estimativa da proporção (estimar a prevalência
de carraças na região Norte)
• Não é um problema muito grave
– Quando se trata de uma média
(nível de colesterol numa população específica)
• É necessário ter uma noção do valor médio esperado e da
respectiva variância
– revisão bibliográfica
– Estudo piloto
A considerar
• Qual o erro que toleramos na conclusão
de que existe um efeito/uma diferença
quando na realidade ele(a) não existe?
– Estamos a falar do alfa, α, nível de
significância
• É usual usar-se 5%
A considerar
• Qual a magnitude do efeito a detectar?
– Unidades (pontos) percentuais
– Diferença das médias
A considerar
• Qual a certeza com que queremos
detectar o efeito/diferença?
– Estamos a falar da potência
• São usuais valores de 90%,
• Não é invulgar o uso de 80%
– Maior potência = maior tamanho da amostra
Fórmula simples para determinar a
dimensão da amostra
• Para uma média
2
4s
n= 2
d
• s é o desvio padrão
• d é a diferença que se pretende ser capaz de
detectar
exemplo
• Um investigador procura determinar o QI médio
em indivíduos do 3ºCiclo de uma determinada
área urbana com um intervalo de confiança de
+-6 pontos
• Um estudo anterior determinou que o desvio
padrão do QI do mesmo tipo de indivíduos
numa cidade semelhante era 15 pontos.
• Determine o tamanho de amostra necessário
para cumprir os objectivos do investigador com
um nível de confiança de 95%.
Exemplo (continuação)
2
4 ×15
n=
= 25
2
6
• São necessários pelo menos 25 indivíduos
Fórmula simples para determinar a
dimensão da amostra
• Para uma proporção/prevalência
4 p(1 − p)
n=
2
d
• Esta fórmula é idêntica à da média com s^2=p(1-p)
• d é a diferença que se pretende ser capaz de detectar
exemplo
• Um investigador pretende determinar a
sensibilidade de um novo teste de diagnóstico
para um determinado cancro.
• Com base em informação dum estudo piloto,
espera que 80% dos pacientes com esse cancro
tenham teste positivo.
• Quantos pacientes são necessários para
estimar um intervalo de confiança de 95% para
a sensibilidade do teste na forma 0,80+-0,05?
Exemplo (continuação)
4 × 0,8 × 0,2
n=
=
256
2
0,05
• São necessários pelo menos 256
pacientes
Exemplo (continuação)
4 × 0,8 × 0,2
n=
=
64
2
0,1
4 × 0,8 × 0,2
n=
=
6400
2
0,01
Nota: precisão 4 x maior = tamanho da amostra 16 x maior
Como dimensionar uma amostra?
Considere-se d a precisão absoluta:
d=z
1−
α
()
× V θˆ
2
Para uma População Infinita (Amostragem Com Reposição):
Estimação de
µ
:
n=
z 21− α2 × σ 2
d2
z 2 α × p(1 − p )
Estimação de
p
:
n=
1−
2
d2
• Usando as fórmulas rigorosas no exemplo
anterior (proporção) fixando o size effect
em 0,05
• O Tamanho amostral seria 246 para alfa
5%
• seria 173 para alfa 10%
• seria 425 para alfa 1%
• Usando as fórmulas rigorosas no exemplo
anterior (para a média) fixando alfa em 5%
• O Tamanho amostral seria 24 para effect
size 0,05
• seria 61 para effect size 0,1
• seria 6146 para effect size 0,01
Fórmula simples para determinar a
dimensão da amostra
• Para comparar duas proporções
16 p (1 − p )
n=
2
( p0 − p1 )
p=
p0 + p1
2
exemplo
• Em duas regiões, A e B, fez-se uma
estimativa da percentagem de
Rhipicephalus sanguineus e que as
estimativas apontaram para uma
proporção de 30% no conjunto de todas
as carraças encontradas na região A, na
região B a mesma proporção foi de 25%.
Qual devia ser o tamanho amostral para
que fosse possível averiguar se estas
duas populações são distintas?
Exemplo (continuação)
p0 = 0,3
p1 = 0,25
p = 0,275
16 × 0,275 × (1 − 0,275)
n=
= 1276
2
0,05
É necessário amostrar pelo menos 1276 carraças em cada região
Exemplo (continuação)
Suponhamos que as prevalência estimadas são 50% e 45% repectivamente
p0 = 0,5
p1 = 0,45
p = 0,475
16 × 0,475 × (1 − 0,475)
n=
= 1596
2
0,05
É necessário amostrar pelo menos 1596 carraças em cada região
• Usando as fórmulas rigorosas no exemplo
anterior os resultados análogos seriam
• 1246
• 1562
Voltando aos exemplos iniciais
Exemplo 1
• Existe diferença na eficácia do Salbutamol e do
ipratropium no tratamento da Asma?
• O investigador delineou um ensaio aleatorizado do efeito destes
fármacos na FEV1 (Forced Experatory Volume durante um
segundo) apó uma semana do tratamento.
• Um estudo anterior relatou que a média do FEV1 em pessoas com
asma tratadas 2.0 litros, com desvio padrão de 1.0 litros.
• O investigador pretende ser capaz de detectar uma dierença de
10% ou mais na média de FEV1 esntre is dois grupos de
tratamento.
• Quantos pacientes são necessários em cada grupo (Salbutamol e
ipratropium ) para alfa (bi-caudal) de 5% e uma potência de 80%?
Variáveis
• Que variáveis estão envolvidas neste
problema?
• de que tipo são estas variáveis?
• Como é usual estudar (estatisticamente)
este problema, qual é o teste usado?
Hipóteses
• Qual a hipótese em estudo?
• Qual a hipótese nula?
• Qual a hipótese alternativa?
Exemplo 2
• Fumadores idosos têm maior incidência de
cancro da pele do que os não fumadores?
• Uma revisão da literatura científica pré existente
sugere que a incidência 5 anos de cancro da
pele é cerca de 0,20 nos não fumadores idosos.
• A um nível de alfa de 5% (bi-caudal) e uma
potência de 80%, quantos fumadores e não
fumadores é necessário estudar para
determinar se a incidência 5 anos de cancro da
pele é pelo menos 0,30 nos fumadores?
Variáveis
• Que variáveis estão envolvidas neste
problema?
• de que tipo são estas variáveis?
• Como é usual estudar (estatisticamente)
este problema, qual é o teste usado?
Hipóteses
• Qual a hipótese em estudo?
• Qual a hipótese nula?
• Qual a hipótese alternativa?
Fundamentos para a
determinação do tamanho
amostral
Paulo Nogueira
Medição de variáveis primárias
• O investigador tem de decidir que
variáveis serão incluídas nos cálculos
– E.g. o uso de uma variável dicotómica, como
o género/sexo, como primária resultará numa
amostra maior do que se for usada uma
escala de 7 pontos
Medição de variáveis primárias
• Um método de determinar o tamanho
amostral (TA) é especificar as margens de
erro para os itens que são tidos como
vitais para o inquérito/estudo
• É necessária uma estimação do TA para
cada um desses itens
Medição de variáveis primárias
• Uma vez completos esses cálculos, teremos
– N menores para variáveis numéricas, continuas
– N maiores para variáveis categoriais e dicotómicas
• Se os n são todos muito próximos escolher o
maior
• Se os n variam substancialmente pode ser difícil
escolher o maior
– Orçamento
– Excesso de precisão
• Considerar o relaxamento de algum dos objectivos
• Desistir de alguns itens
Estimação do erro
• Cochran (1997) usa dois factores chave:
1. O risco que o investigador está disposto a
aceitar – a margem de erro –
2. O nivel, alfa, o nível de risco que o
investigador está disposto a aceitar de que a
verdadeira margem de erro exceda a margem
de erro aceitável (erro tipo 1)
–
Nas fórmulas de cochran o alfa está integrado no t
Margem de erro aceitável
• Dados categoriais 5%
• Dados contínuos 5%
Estimação da variância
•
•
•
A estimação da variância para as variáveis primárias é
um elemento vital para na determinação do cálculo do
TA
O investigador não controla e esta tem de ser
incorporada nas fórmulas
Soluções
1.
2.
3.
4.
Fazer amostragem em dois passos
Usar dados de um estudo piloto
Usar dados de estudos anteriores da mesma população ou de
populações semelhantes
Estimar ou adivinhar a estrutura da população usando a ajuda
lógica de alguns resultados matemáticos
Estimação da variância (cont)
• Racionais que podem ser usados:
– Variáveis categoriais usar 50%
– Variáveis numéricas ou contínuas
• Limites esperados dividir por 6 (número de desvios
padrão onde recaem aproximadamente 99% dos
valores)
Determinação do tamanho
amostral - básico
• Dados
numéricos/contíuos
• Exemplo
–
–
–
–
Alfa = 0,05
Escala de 7 pontos
Erro aceitável 3%
Estimativa do desvio
padrão 7/6 = 1.167
t 2 × s2
no =
d2
1.96 2 × 1.167 2
no =
= 118
2
(7 * 0.03)
Determinação do tamanho
amostral – básico (cont)
• Supondo que o
tamanho da
população é
conhecido N=1679
• O valor obtido n =118
excede 5% da
população
• 1679*0,05 = 84
• Deve corrigir-se o TA
final
n0
n=
n0
1+
N
118
n=
= 111
118
1+
1679
Determinação do tamanho
amostral – básico (cont)
•
Considerar oversampling
–
Correio acrescentar 40-50%
•
•
Oneroso mas necessário
Métodos que podem ser usados para
antecipar a taxa de resposta
1.
2.
3.
4.
Fazer amostragem em dois passos
Usar resultados de estudos piloto
Usar taxas de resposta de estudos anteriores semelhantes
Estimar a taxa de resposta (outros investigadores,
literatura, etc)
Determinação do tamanho
amostral – básico (cont)
• Dados categoriais
• Exemplo
– Alfa = 0,05
– Erro aceitável 5%
– Estimativa do desvio
padrão da escala 0,5
2
t × p(1 − p)
no =
d2
1.96 2 × 0.5 × 0.5
no =
= 384
2
0.05
Determinação do tamanho
amostral – básico (cont)
• Supondo que o
tamanho da
população é
conhecido N=1679
• O valor obtido n =118
excede 5% da
população
• 1679*0,05 = 84
• Deve corrigir-se o TA
final
n0
n=
n0
1+
N
384
n=
= 313
384
1+
1679
Outras considerações sobre o
cálculo amostral
• Análise de regressão
– Para usar a regressão linear múltipla a razão para o
número de variáveis independentes não deve ser
nunca abaixo de 5.
• Caso contrário existe elevado risco de overfitting “resultado
demasiado específicos da amostra e pouco generalizáveis
para a população”
– Uma razão mais conservativa de 10 observações
para cada variável é apontada como ideal pela
literatura
– Estas razões são críticas para regressões que usam
variáveis contínuas, onde em regra é necessário
menor TA
Outras considerações sobre o
cálculo amostral (cont)
• Exemplo
– População N=1679
– TA dados categoriais n=111
– TA dados contínuos n=313
Tipo
variável
Contínuo
Categorial
Número de regressores
5 para 1
22
62
10 para 1
11
31
Análise Factorial
• Mesmo racional que para a regressão
linear
• Não fazer com menos de 100
observações
• Aumentar a amostra torna loads mais
baixos significativos