CONCEITOS BÁSICOS DE ESTATÍSTICA
Estatística: é uma parte da Matemática Aplicada que fornece métodos para a coleta,
organização, descrição, análise e interpretação de dados e para utilização dos mesmos na
tomada de decisões (CRESPO, 1993). A Estatística divide-se em:
Estatística Descritiva: Coleta, organização e descrição dos dados.
Estatística Indutiva (ou Inferência Estatística): Análise e Interpretação dos dados.
População: Conjunto de elementos que têm, em comum, pelo menos uma característica. A
população podem ser:
- Finita
- Infinita
Ex.: n° de plantas em uma estufa
Ex.: o conjunto de pesagens que podem ser feitas em determinado animal, n°
de determinada espécie de animal em um grande lago
Parâmetro: é a medida usada para descrever uma característica numérica populacional. Exs.:
μ, σ, σ2, π.
Amostra: Todo subconjunto não vazio e com menor número de elementos do que o conjunto
definido como população.
Estatística (Estimador ou Estimativa): é uma característica numérica determinada na amostra.
Exs.: x , s, s2, p.
Amostragem: é o processo de seleção de uma amostra, que possibilita o estudo das
características da população.
A Amostragem pode ser:
- Com Reposição: quando extraímos um objeto de uma urna, e o repomos antes da
próxima extração; este objeto pode aparecer repetidas vezes.
- Sem Reposição: quando extraímos um objeto de uma urna, e não o repomos antes da
próxima extração; o objeto só pode aparecer uma vez.
Para que a amostragem possa ser considerada aleatória, cada “elemento” da população
tem que ter a mesma probabilidade de ser incluído na amostra. Assim, se N for o tamanho da
população, a probabilidade de cada elemento será 1/N. Trata-se do método que garante
cientificamente a aplicação das técnicas estatísticas de inferências. Somente com base em
Amostragens Probabilísticas é que se podem realizar inferências ou induções sobre a
população a partir do conhecimento da amostra.
1
A Amostragem Não-probabilística é aquela em que as amostras representam
especificamente certos segmentos da população. Não é possível generalizar os resultados das
pesquisas para a população, pois as amostras não probabilísticas não garantem a
representatividade da população.
Obs.: A melhor forma de realizar uma amostragem é através de sorteio. Se feitos de forma
correta, não haverá problemas na análise estatística.
Variável: Variável é, convencionalmente, o conjunto de resultados possíveis de um
fenômeno. Ex.: sexo, estado civil, altura, etc. Uma variável pode ser classificada em:
Variável Qualitativa: apresenta como possível resultado uma qualidade ou atributo do ente
pesquisado. Ex.: classificar peixes por tamanho, espécie, cor, ...
Variável Quantitativa: quando é mensurável, isto é, quando é expressa numericamente. As
variáveis quantitativas ainda podem ser classificadas como:
- Discreta: quando uma variável só pode assumir valores pertencentes a um conjunto
enumerável. Em geral, representam inteiros resultantes do processo de contagem. Exs.: n° de
animais, n° de ovos, ...
- Contínua: pode assumir, teoricamente, qualquer valor num certo intervalo de medida,
podendo ser associada ao conjunto dos números reais. Exs: medidas de altura, comprimento,
idade, volume, peso, temperatura, pressão, tempo, espessura, área, velocidade ...
As Escalas de Medidas são:
- Nominal: é caracterizado por dados que consistem apenas em nomes, rótulos ou categorias.
Exs.: espécies de animais, cor, sabor, faixa etária, portador de determinada doença, etc.
Operações admissíveis: contagens de freqüência, moda, teste do 2, distribuição binomial.
“Esses dados não podem ser utilizados em cálculos como média”.
- Ordinal (por Postos): os dados podem ser dispostos em alguma ordem, mas as diferenças
entre os valores dos dados não podem ser determinadas, ou não têm sentido. Exs.: avaliação
clínica: ótima, boa, regular, ruim, classificação por ordem de tamanho do maior ao menor: 1°,
2°, 3°, etc; faixa etária: criança, jovem, adulto, idoso.
Operações admissíveis: mediana. “Esses dados não podem ser utilizados em cálculos como
média e desvio padrão”.
- Intervalar: é análogo ao nível ordinal, todavia pode-se determinar diferenças significativas
entre os dados. Contudo o zero não significa que não há quantidade presente. Pode-se
2
determinar diferenças entre as temperaturas (distância entre os dois valores); contudo, o valor
zero não representa ausência de temperatura. Exs.: temperaturas, anos (zero é arbitrário).
Operações admissíveis: média, desvio-padrão, correlações, teste “t”, teste “F”, etc.
- Razão: é o nível de intervalo modificado de modo a incluir o ponto de partida zero inerente
(onde zero significa nenhuma quantidade presente). Para valores nesse nível, tanto as
diferenças como as razões têm significado. Exs.: peso, idade, altura, tempo, comprimento.
Operações admissíveis: qualquer prova estatística. Além daquelas já mencionadas em escalas
intervalares, pode-se calcular média geométrica e coeficiente de variação (estatísticas que
exigem o conhecimento do ponto zero verdadeiro).
Medidas de Tendência Central
É um valor no centro ou no meio de um conjunto de dados. As principais medidas de
tendência central são:
- Média: somatório de todos os valores dividido pelo n° de valores observados.
- Moda: É o valor mais freqüente de um conjunto de dados. Esse conjunto pode ser unimodal,
amodal ou plurimodal (multimodal).
- Mediana: é o valor central de um rol (valores colocados em ordem crescente ou
decrescente), ou seja, é a medida que divide este conjunto em duas partes iguais. É uma
medida muito utilizada na análise de dados estatísticos, especialmente quando se atribui pouca
importância aos valores extremos da variável.
Obs.1: a mediana depende da “posição” e não dos valores dos elementos na série ordenada.
Essa é uma das diferenças marcantes entre a mediana e a média (que se deixa influenciar, e
muito, pelos valores extremos).
Medidas de Dispersão
Informam sobre o grau de heterogeneidade do grupo.
Variância: s 2
2
x i x
n 1
3
Desvio Padrão: s
2
x i x
- Desvio Padrão
n 1
- Coeficiente de Variação (CV): é uma medida de dispersão relativa que indica a relação
percentual entre o desvio-padrão e a média dos dados. Serve de termo de comparação entre
duas ou mais situações diferentes.
CV
s
100
x
Em ensaios agrícolas de campo, podemos considerá-los:
CV 10% - baixo;
10 < CV 20% - média
20 < CV 30% - alto
CV > 30% - muito altos.
PROBABILIDADE
A teoria das probabilidades objetiva mensurar as chances de ocorrência dos diversos
resultados que um experimento aleatório pode apresentar. Para tanto os métodos mais
utilizados são o clássico e o das freqüências relativas.
No método clássico, as probabilidades são teóricas e determinadas a priori,
independentemente de se realizar o experimento. Nesse caso, a probabilidade de ocorrer
determinado resultado na realização de um experimento é igual ao quociente entre o número
de casos favoráveis ao sucesso e o número de casos possíveis. Isto é:
P ( A)
N ( A)
N (S )
N(A) é o número de elementos de A;
onde:
N(S) é o número de elementos de S.
No método das freqüências relativas, as probabilidades são obtidas após a realização
dos experimentos e a ocorrência dos eventos. Nesse caso, a probabilidade de um evento
ocorrer no futuro tende às freqüências anotadas nos experimentos ou observações passadas.
Isso é:
P(A) = fr (A)
Lei dos Grandes Números
Quando se repete um experimento um grande número de vezes a probabilidade
calculada através da freqüência relativa se aproxima da probabilidade clássica.
4
Por exemplo, se fazemos uma pesquisa entrevistando apenas algumas pessoas, os
resultados podem acusar grande erro, mas se entrevistamos milhares de pessoas selecionadas
aleatoriamente, os resultado amostrais estarão muito mais próximos dos verdadeiros valores
populacionais.
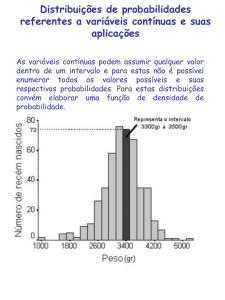
Distribuições de Probabilidades
Há uma variedade de tipos de distribuições de probabilidades na estatística. Cada qual tem
o seu próprio conjunto de hipóteses que definem as condições sob as quais o tipo de
distribuição pode ser utilizada validamente. A essência da análise estatística é confrontar as
hipóteses de uma distribuição de probabilidades com as especificações de determinado
problema.
Distribuição Normal
Quando uma variável aleatória discreta apresenta um grande número de resultados
possíveis, ou quando a variável aleatória é contínua, não se podem usar distribuições discretas
como a de Poisson ou a Binomial para obter probabilidades. A análise das variáveis contínuas
tende a focalizar a probabilidade de uma variável aleatória tomar um valor num determinado
intervalo.
A Distribuição Normal é uma distribuição teórica, podendo ser aplicada em grande
número de fenômenos. Exs.: altura, peso, volume, área, ...
Suas principais características são:
1.
2.
3.
4.
5.
6.
A curva normal tem forma de sino;
É simétrica em relação à média;
Prolonga-se de - a +;
Há uma distribuição normal distinta para cada combinação de média e desvio-padrão;
A área total sob a curva normal é considerada como 100%;
A área sob a curva entre dois pontos é a probabilidade de uma variável normalmente
distribuída tomar um valor entre esses dois pontos;
7. Como há um número ilimitado de valores no intervalo de - a +, a probabilidade de
uma variável aleatória normalmente distribuída tomar exatamente determinado valor é
aproximadamente zero. Assim, as probabilidades se referem sempre a intervalos de
valores;
8. A área sob a curva entre a média e um ponto arbitrário é função do número de desvios
padrões entre a média e aquele ponto.
Inferência Estatística
Trata-se do processo de obter informações sobre uma população a partir de resultados
observados na amostra. Objetiva formular afirmações sobre características ou propriedades de
uma população, baseando-se em resultados de uma amostra.
5
Comparação de Médias
Pode-se comparar duas médias utilizando-se testes de hipóteses. O objetivo desses
testes é decidir se determinada afirmação sobre um parâmetro populacional é verdadeira.
Assim, os testes de hipóteses servem para distinguir entre resultados que podem ocorrer
facilmente e os que dificilmente ocorrem.
Para tomar-se uma decisão, se formulam as hipóteses:
H0 (Hipótese Nula): é a hipótese conservadora. É uma afirmação sobre o parâmetro
populacional.
H1 (Hipótese Alternativa): é a hipótese que contraria a hipótese H0 de alguma maneira que
interesse ao pesquisador. É a afirmação que deve ser verdadeira se a hipótese nula é falsa.
Tem uma probabilidade pequena de ser provada.
Obs.: Como se está investigando uma parcela da população, pode-se inferir para a população
desde que se associe ao resultado uma medida de incerteza (probabilidade), também chamado
de nível de significância.
Quando um teste de comparação de médias não dá resultado significativo, isto não
prova que as médias sejam iguais, pois não existe nenhum teste estatístico capaz de
comprovar a igualdade de médias. A conclusão correta de um teste que não se revelou
significativo é apenas de que não se comprovou diferença significativa entre as médias.
Tal diferença pode ser nula, mas, quase sempre é pequena e não nula; pequena tendo em vista
a imprecisão das estimativas, medida pelo erro padrão da média. Na verdade, não há nenhum
teste estatístico de comparação de médias que possa comprovar a igualdade delas. E o
mesmo vale para os testes estatísticos em geral, nos termos em que se realizam.
Pode-se utilizar o Teste de Student (“t”):
x x2
t 1
s x1 x 2
Ex..:
H0: 1 = 2
Ha : 1 > 2
“p” pequeno (p 0,05), então 1 > 2
“p” grande (p > 0,05), então 1 = 2
Obs.: Esses valores servem de referência. Analisar cada caso e usar o bom senso!!!
Para o caso de mais de duas médias, pode-se utilizar o teste “t” se compararmos as
médias duas a duas. Nesse caso, têm-se associado a cada comparação uma probabilidade de
erro. Dessa forma, o erro será muito maior que 5%.
6
Por exemplo, supondo que se deseja testar a igualdade entre 5 médias usando
comparações par a par. Existem 10 possíveis pares, e se a probabilidade de aceitar
corretamente a hipótese nula é de 1 - = 0,95, então a probabilidade de aceitar corretamente a
hipótese nula para todos os dez testes é 0,9510=0,60 se os testes são independentes. Assim, o
erro tipo I aumenta substancialmente. Nesses casos, utiliza-se, então ANÁLISE DE
VARIÂNCIA.
Na Análise de Variância, ao se analisar várias amostras, considera-se a variação
DENTRO de cada uma das amostras como devido ao acaso, se todos os cuidados no momento
da realização do experimento foram tomados. A variação ENTRE as amostras pode ser
devido ao fator que distingue as duas amostras. O pesquisador testa essa hipótese com o
auxílio da Inferência Estatística.
7