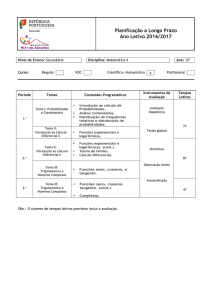
Aderência
Rinaldo Artes
Insper Instituto de Ensino e Pesquisa
2015
Sumário
1. Estatística qui-quadrado ........................................................................................... 2
2. Gráfico de Probabilidades ......................................................................................... 9
3. Teste de Jarque-Bera ............................................................................................. 14
Serão apresentadas técnicas que permitem avaliar se um conjunto de dados pode ter
sido gerado a partir de uma certa distribuição de probabilidades. A primeira técnica
baseia-se na estatística qui-quadrado de Pearson, a segunda em gráficos de
probabilidades, adequados principalmente quando a variável em questão segue uma
distribuição contínua e, por fim, o teste de Jarque-Bera, que a partir dos coeficientes
de assimetria e curtose, verifica se um conjunto de dados pode ter sido gerado por
uma distribuição normal.
1
1. Estatística qui-quadrado
Objetivo: Decidir se um conjunto de dados segue uma determinada distribuição de
probabilidades.
Exemplo 1.1: Uma emissora de TV desconfia da qualidade do método utilizado por
um instituto para medir a audiência de programas de TV. Tal instituto aponta que em
um determinado horário a emissora A tem 37% da audiência, enquanto que a
emissora B tem 30%, a C tem 13% e as demais têm 20%.
A emissora contratou uma empresa de pesquisa de mercado que selecionou uma
amostra de 300 residências. Em cada uma, perguntou-se em qual canal a principal TV
da casa estava sintonizada, na última semana, no horário determinado. Dos 300, 95
declararam estar assistindo a emissora A, 87 a emissora B, 51 a C e 67 uma das
demais emissoras, ou não estava com a TV ligada.
Há evidências de que os dados do instituto estejam errados?
Admita:
: probabilidade da emissora A ser sintonizada,
: probabilidade da emissora B ser sintonizada,
: probabilidade da emissora C ser sintonizada,
: probabilidade de outras emissoras serem sintonizada,
= 95: número de pessoas da amostra que declararam assistir a emissora A,
= 87: número de pessoas da amostra que declararam assistir a emissora B,
= 51: número de pessoas da amostra que declararam assistir a emissora C e
= 67: número de pessoas da amostra que declararam assistir outras emissoras.
Temos
instituto,
categorias de resposta e
= 0,37,
= 0,30,
= 0,13 e
∑
= 0,20.
. Além disso, segundo o
A estatística qui-quadrado busca aferir o quanto os dados são compatíveis com os
valores de probabilidades fornecidos. Sua lógica consiste em comparar os dados
observados com os dados que deveriam ser observados numa amostra de hipotética
(amostra de referência) que obedecesse fielmente às probabilidades fornecidas.
1.1. Amostra de referência
Se a amostra seguisse fielmente a estrutura de probabilidade dada por , quantas
pessoas deveríamos ter observado em cada uma das quatro possíveis categorias de
resposta?
Nesse caso, para a primeira categoria (audiência da emissora A), esperaríamos ter
37% de observações, ou seja, a frequência esperada dessa categoria seria
= 0,37 * 300 =111; para a segunda
= 0,30 * 300 =90,
para a terceira = 0,13 * 300 = 39 e, por fim, para a última = 0,20 * 300 =60.
2
Resultado 1.1: Seja
o valor que seria observado na classe ,
amostra seguisse fielmente a estrutura de probabilidade dada por .
, se a
.
1.2. Estatística qui-quadrado
A estatística qui-quadrado é uma medida da distância entre os valores efetivamente
observados ( ) e os que esperaríamos observar se a amostra seguisse fielmente a
estrutura de probabilidades fornecida ( ). A constrição dessa medida será feita passo
a passo a partir dos dados do Exemplo 1.1.
Na Tabela 1.1, estão dispostos, lado a lado, os valores observados e esperados. Note
que a soma das respectivas colunas é igual ao tamanho da amostra. Isso decorre do
Resultado 1.2.
Resultado 1.2: ∑
Prova: ∑
.
∑
∑
Na quinta coluna da tabela são apresentadas as diferenças entre os valores
observados e os valores esperados. Caso a estrutura de probabilidades fornecida seja
de fato seguida pelos dados, espera-se que esses valores sejam próximos de zero. A
estatística qui-quadrado baseia-se na distância quadrática entre os valores
)
observados e esperados dada por: (
Voltando à Tabela 1.1, nota-se uma distância de 256 para a primeira categoria de
resposta e 144 para a terceira. Será que de fato, em termos qualitativos, a
discrepância na categoria 1 é mais importante do que a observada na categoria 3?
Tabela 1.1: Determinação da estatística qui-quadrado para os dados do Exemplo
1.1.
Categoria
( - )
( - )
( - )
1
0,37
95
111,0
-16,0
256,00
2,31
2
0,30
87
90,0
-3,0
9,00
0,10
3
0,13
51
39,0
12,0
144,00
3,69
4
0,20
67
60,0
7,0
49,00
0,82
Total
1,00
300
300
0,0
6,92
3
Na categoria 1, esperávamos encontrar 111 pessoas e na categoria 3, 39. Ao se fazer
a razão entre a distância e os valores esperados para essas duas categorias, temos,
respectivamente, 2,31 e 3,69. Isso indica que, em termos relativos, o afastamento
observado na categoria 3 é mais importante do que na categoria 1. A estatística quiquadrado é construída com base nesse raciocínio.
Definição 1.1: Seja
a probabilidade hipotética de uma observação pertencer á
categoria de resposta,
, com ∑
. Seja
o número de indivíduos
classificados na categoria e
seu respectivo valor esperado, conforme definido no
Resultado 1.1,
. Define-se a estatística qui-quadrado como
∑
(
)
Em suma a estatística qui-quadrado nada mais é do que a distância quadrática entre
os valores da amostra e da amostra de referência, ponderada pelos valores esperados
sob a hipótese de que a estrutura de probabilidades fornecida é correta. Quanto
maior o valor dessa estatística, maior é a evidência de que os dados não seguem
a estrutura de probabilidades fornecida.
Para o Exemplo 1.1,
.
Exemplo 1.2: A Tabela 1.2 descreve o número de reclamações diárias observado em
100 dias de funcionamento de um biblioteca. Um analista desconfia que uma
distribuição de Poisson poderia ser utilizada para descrever o comportamento dessa
variável. Com base nos dados apresentados na Tabela 1.2, pode-se concluir que ele
tem razão?
O primeiro passo para a determinação da estatística qui-quadrado é o cálculo da
probabilidade de ocorrência de cada categoria da variável em questão. Aventa-se a
hipótese de que a distribuição de Poisson é adequada para modelar este fenômeno,
no entanto, não foi fornecido o valor do parâmetro da distribuição. Desse modo, é
necessário estimá-lo a partir dos dados. Como o parâmetro da Poisson é a média da
distribuição, decidiu-se estimá-lo por 1,49, a média aritmética dos dados.
Tabela 1.2: Número de reclamações diárias observadas em 100 dias de atividade
Número de reclamações
Dias
0
25
1
35
2
18
3
13
4
6
5
3
4
Total
100
A Tabela 1.3 traz as probabilidades de cada categoria, obtidas a partir de uma
distribuição de Poisson com média 1,49. Note que essas probabilidades não somam
100%, condição estabelecida para o cálculo da estatística qui-quadrado. Para
contornar esse problema, e para levar em conta que há poucas observações na última
categoria de resposta, decidiu-se reorganizar os dados conforme a Tabela 1.4.
Tabela 1.3: Probabilidades associadas aos dados da Tabela 1.2.
Número de reclamações
Dias
Probabilidade
0
25
0,2254
1
35
0,3358
2
18
0,2502
3
13
0,1243
4
6
0,0463
5
3
0,0138
Total
100
0,9957
Tabela 1.4: Número de reclamações diárias observadas em 100 dias de atividade
e probabilidades associadas ás categorias de resposta
Número de reclamações
Dias
Probabilidade
0
25
0,2254
1
35
0,3358
2
18
0,2502
3
13
0,1243
≥4
9
0,0644
Total
100
1,0000
Para os dados do Exemplo 1.2, obteve-se
. A Tabela 1.5 resume o cálculo
dessa estatística. Note que os valores esperados não são números inteiros. Isso é
uma ocorrência comum que não deve ser corrigida, uma vez que os valores esperado
constituem apenas pontos de referência.
5
Tabela 1.5: Determinação da estatística qui-quadrado para os dados da Tabela
1.4.
( - ) ( - )
Categoria
( - )
0
0,2254
25
22,54
2,46
6,07
0,27
1
0,3358
35
33,58
1,42
2,01
0,06
2
0,2502
18
25,02 -7,02
49,25
1,97
3
0,1243
13
12,43
0,57
0,33
0,03
>3
0,0644
9
6,44
2,56
6,56
1,02
Total
1,0000
100
100
0,00
3,34
Exemplo 1.3: Uma empresa pode ser multada se emitir poluentes acima de níveis
tolerados. Especula-se que o nível de emissão de certo poluente segue uma
distribuição normal. Os dados da Tabela 5 reproduzem os níveis de emissão em 284
dias. Há evidências de que a emissão segue uma distribuição normal?
Assim como no Exemplo 1.2, não foram fornecidos os parâmetros da distribuição de
probabilidades. Sua determinação a partir da média e desvio-padrão amostral dos
dados resultou numa média de 44,3 e desvio-padrão de 4,15. Teoricamente, a
distribuição normal pode assumir qualquer valor real, desse modo é necessário fazer
alterações nas categorias de resposta para fazer com que a soma de suas
probabilidades de ocorrência atinja 100%. Conforme pode ser visto na Tabela 1.7, a
primeira categoria foi considerada como “Inferior a 34,5” e a última “49,5 ou mais”.
Tabela 1.6: Emissões diárias de poluentes de uma empresa
Emissão
Dias
30,0
a
34,5
4
34,5
a
37,5
8
37,5
a
40,5
32
40,5
a
43,5
84
43,5
a
46,5
74
46,5
a
49,5
42
49,5
a
52,5
40
Total
284
6
Tabela 1.7: Determinação da estatística qui-quadrado para os dados da Tabela
1.6.
( - )
Emissão
( - )
-
a
34,5
0,0091
4
2,585
1,415
0,775
34,5
a
37,5
0,0416
8
11,801
-3,801
1,224
37,5
a
40,5
0,1293
32
36,712
-4,712
0,605
40,5
a
43,5
0,2436
84
69,196
14,804
3,167
43,5
a
46,5
0,2784
74
79,070
-5,070
0,325
46,5
a
49,5
0,1929
42
54,787
-12,787
2,985
49,5
a
0,1051
40
29,849
10,151
3,452
284
284,000
0,000
12,533
Total
A partir dos dados chega-se a
.
A lógica de análise da estatística qui-quadrado é bastante simples: valores muito
distantes de zero indicam que a distribuição de probabilidades não segue a
distribuição de probabilidades considerada no problema. A dificuldade é sabe se o
valor observado está distante o suficiente de zero para se tirar essa conclusão.
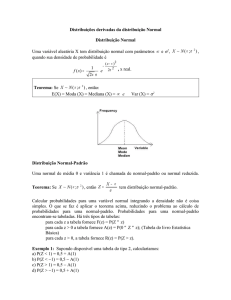
1.3 Distribuição de
Pode-se construir um teste de hipóteses para verificar se os dados seguem a
distribuição em consideração que utiliza
como estatística de teste. Nesse caso,
temos
H0: os dados seguem a distribuição em consideração.
H1: os dados não seguem a distribuição em consideração.
Prova-se, sob a hipótese de que os dados seguem a distribuição de probabilidades em
consideração e para grandes amostras, que a distribuição de pode ser aproximada
por uma distribuição qui-quadrado1 com
graus, sendo o número de
parâmetros estimados a partir dos dados.
Desse modo, a conclusão final pode ser feita a partir da probabilidade de se observar
um valor tão grande ou maior do que o observado (valor p); quanto menor o valor,
maior a evidência de que os dados não seguem a distribuição em consideração.
1
Uma regra empírica diz que a amostra é suficientemente grande para utilizar a distribuição
)
qui-quadrado quando
e (
, para todo
. Quando a regra não for
satisfeita, recomenda-se redefinir as categorias de resposta, agrupando as que a violarem.
7
Na Tabela 1.8 são apresentados os valores p associados aos resultados dos
exemplos 1, 2 e 3. A partir desses valores podemos concluir que há evidências fortes
para rejeitar a hipótese de normalidade dos dados do Exemplo 1.3, alguma evidência
contrária à distribuição apresentada no Exemplo 1.1 e evidências muito fracas com a
hipótese de que os dados do Exemplo 1.2 seguem uma distribuição de Poisson.
Tabela 1.8: Valor p associados à análise dos exemplos 1, 2 e 3.
Exemplo
1
2
3
Valor p
6,92
3,34
12,53
4
5
7
0
1
2
3
3
4
0,0745
0,3421
0,0138
Comando excel para
cálculo do valor p
DIST.QUIQUA.CD(6,92;3)
DIST.QUIQUA.CD(3,34;3)
DIST.QUIQUA.CD(12,53;3)
8
2. Gráfico de Probabilidades
Objetivo: Verificar se um conjunto de dados pode ter sido gerado a partir de
uma específica distribuição de probabilidades contínua.
Exemplo 2.1: Os dados abaixo se referem aos retornos da Petr4 observados
em 20 dias. Há evidências de que esses dados seguem uma distribuição
normal?
A lógica da construção desse tipo de gráfico é comparar os dados observados
(x) com os dados que esperaríamos ter observado caso eles seguissem a
distribuição de probabilidades. Caso fosse possível criar uma coluna (y) com
esses valores esperados e se dispuséssemos os pontos (x,y) num eixo
cartesiano esperaríamos, casos os dados de fato tivessem sido gerados pela
distribuição de probabilidades proposta, que os pontos se distribuíssem
aleatoriamente ao redor da reta da reta de 45º.
O Resultado 2.1 fundamenta a obtenção dos valores esperados.
Resultado 2.1: Seja X uma variável aleatória contínua com função distribuição
( ), então
( ).
acumulada dada por F(x). Então, se
Note que a observação 0,129 é menor ou igual a 70% dos dados amostrais.
Desse modo, se a distribuição dos dados fosse de fato uma normal,
esperaríamos que 0,129 estivesse próximo ao percentil 70 de uma normal com
média -0,584 e desvio-padrão 1,643 (valores obtidos a partir da amostra). Esse
raciocínio poderia ser aplicado para obtenção da coluna de valores esperados.
No entanto, teríamos um problema com o valor 3,045. Esse valor é menor ou
igual a 100% dos dados. Seria impossível obter o valor esperado de uma
normal que deixasse 100% as observações abaixo dele. Assim foi sugerida
uma pequena alteração na determinação do percentil amostral. Essa alteração
denomina-se Função distribuição acumulada empírica.
Definição 2.1. Função distribuição acumulada empírica (FDAE). Seja i a iésima observação ordenada de uma amostra de tamanho n. Então o valor
FDAE para esse valor é dado por
̂( )
9
Tabela 2.1: Retornos compostos da Petr4 observados entre 22/03 e 19/04
de 2012.
Data
X: Retorno (%)
22/03/2012
-1,294
23/03/2012
-0,421
26/03/2012
2,129
27/03/2012
-1,708
28/03/2012
-1,738
29/03/2012
-0,300
30/03/2012
0,129
02/04/2012
-0,515
03/04/2012
-2,971
04/04/2012
-3,566
05/04/2012
1,097
09/04/2012
-1,881
10/04/2012
-1,87
11/04/2012
0,752
12/04/2012
3,045
13/04/2012
-1,557
16/04/2012
-0,741
17/04/2012
0,325
18/04/2012
0,831
19/04/2012
-1,435
Média
-0,584
DP
1,643
A partir da definição acima, temos que o valor esperado, associado à i-ésima
observação ordenada, é dado por
̂
(
)
Voltando ao exemplo, temos que
é a distribuição acumulada de uma
distribuição normal com média -0,584 e desvio-padrão 1,643.
A Tabela 2.3 descreve o processo de obtenção dos valores esperados para os
dados do Exemplo 2.1.
O próximo passo é dispor os pares ordenados (x,y) num eixo cartesiano e
comparar a disposição dos pontos com a reta de 45º. A Figura 2.1 traz esse
gráfico.
10
Tabela 2.2: Amostra ordenada
i:Observação
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Média
DP
x: dados
ordenados
-3,566
-2,971
-1,881
-1,87
-1,738
-1,708
-1,557
-1,435
-1,294
-0,741
-0,515
-0,421
-0,300
0,129
0,325
0,752
0,831
1,097
2,129
3,045
-0,584
1,643
Note que, na Figura 2.1, os pontos parecem estar aleatoriamente distribuídos
ao redor da reta de 45º. Isso nos leva a concluir que a distribuição normal pode
ser uma boa candidata a distribuição geradora desses dados. No entanto, esse
método é puramente descritivo e deve ser utilizado com cuidado.
Um cuidado a ser tomado é com o tamanho amostral. São necessárias muitas
observações para que esse tipo de técnica seja realmente eficaz. A Figura 2.2,
traz informações sobre os mesmos retornos, só que no período entre
20/04/2011 e 19/04/2012 (250 observações). Analisando-se esse gráfico,
somos levados a concluir que a distribuição normal não é adequada para
descrever esse conjunto de dados.
Essa técnica pode ser utilizada para verificar a aderência de um conjunto de
dados a qualquer distribuição de probabilidades. Basta para isso, utilizar a
função distribuição acumulada correspondente. Além disso, sugere-se que os
parâmetros da distribuição sejam estimados a partir dos dados.
11
Vários pacotes estatísticos e econométricos já trazem opções para a
construção de gráficos semelhantes aos aqui apresentados. Variações desse
método surgem com os nomes: Gráficos QQ, Gráficos de quantis, Gráficos PP,
etc.
A planilha GraficodeProbabilidade.xlsx traz a memória de cálculo associada a
este texto.
Tabela 2.3: Obtenção dos valores esperados para os dados do Exemplo.
̂
(
i
x (amostra ordenada)
1
-3,566
0,025
-3,805
2
-2,971
0,075
-2,950
3
-1,881
0,125
-2,475
4
-1,87
0,175
-2,120
5
-1,738
0,225
-1,826
6
-1,708
0,275
-1,567
7
-1,557
0,325
-1,330
8
-1,435
0,375
-1,108
9
-1,294
0,425
-0,895
10
-0,741
0,475
-0,687
11
-0,515
0,525
-0,481
12
-0,421
0,575
-0,274
13
-0,300
0,625
-0,061
14
0,129
0,675
0,161
15
0,325
0,725
0,398
16
0,752
0,775
0,657
17
0,831
0,825
0,951
18
1,097
0,875
1,306
19
2,129
0,925
1,781
20
3,045
0,975
2,636
)
12
Gráfico de probabilidade normal
4
3
y: valor esperado
2
-4
1
0
-3
-2
-1
-1 0
1
2
3
4
-2
-3
-4
-5
x: valor observado
Figura 2.1: Gráfico de probabilidade normal
Gráfico de probabilidade normal
0,080
Valores esperados
0,060
-0,100
0,040
0,020
-0,080
-0,060
-0,040
0,000
-0,020
-0,0200,000
0,020
0,040
0,060
-0,040
-0,060
-0,080
-0,100
Valores observados
Figura 2.2: Gráfico de probabilidade normal para 250 observações (dados
de 1 ano)
13
3. Teste de Jarque-Bera
O teste de aderência de Jarque-Bera pode ser utilizado para verificar se um conjunto
de dados segue uma distribuição normal. A estatística do teste é dada por
[
]
sendo
∑
∑
respectivamente, os coeficientes de assimetria e curtose, com
∑
(
̅)
(variância). Sob a hipótese de normalidade dos dados
̅
√
e
segue uma
distribuição qui-quadrado com dois graus de liberdade. Quanto maior for o valor dessa
estatística, menor a evidência de que a distribuição é de fato normal.
Este teste baseia-se no fato de numa distribuição normal espera-se observar valores
de e
iguais a zero.
14