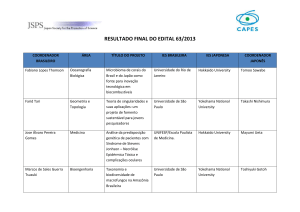
Técnicas Modernas de Data Mining em CRM Analítico
Um Curso Introdutório
Coordenação: Prof. Dr. Geraldo Barbieri
Docentes: Dr. Cláudio Paiva
Prof. Dr. Eduardo Raul Hruschka
Prof. Dr. Estevam R. Hruschka Jr.
Datas: Dias 03, 04 e 05 de Julho de 2013 das 09h00 as 18h00.
Apresentação:
A Extensão da Faculdade FIPECAFI, mantida pela Fundação Instituto de Pesquisas
Contábeis, Atuariais e Financeiras, trata de temas relevantes e atuais oferecendo a
oportunidade de contato com profissionais e especialistas reconhecidos em suas áreas de
atuação no universo da Contabilidade, Auditoria, Controladoria, Atuária, Mercado de Capitais
e Finanças e áreas correlatas. Os programas tem duração variada e apresentam como
diferencial a disponibilização completa do material didático e de apoio para a expansão sobre
o tema.
Objetivo
Capacitar analistas de dados e profissionais de modelagem de dados a trabalhar com
aplicações que envolvem grandes quantidades de dados e que requerem elevada eficiência
computacional, através de técnicas modernas de data mining, com ênfase em problemas de
CRM Analítico. As técnicas serão apresentadas de uma maneira acessível mas consistente,
enfatizando os aspectos práticos.
Conteúdo Programático:
1. Visão de CRM Analítico que motiva as aplicações de data mining do curso:
a. Segmentação de clientes
b. Análise de abandono/retenção de clientes
c. Customer Lifetime Value
2. Dados para aplicações em CRM
3. Introdução aos modelos preditivos e descritivos
a. Significância (p-value), tamanho do efeito (effect size), tamanho de amostra
4. Ponto de partida: Modelos Lineares Generalizados (GLM)
a. Análise de dados transversais e longitudinais
b. Regressão linear
c. Regressão logística
d. Pontos de atenção e limitações de GLM
5. Exemplos de problemas práticos de CRM que envolvem regressão e análise de
sobrevivência
a. Análise crítica de artigos recentes (churn, segmentação e LTV)
6. Uma visão moderna de Data Mining – 15h
a. Classificação
i. Classificador Naive Bayes com seleção automática de atributos
ii. Aplicação de Regressão Logística para classificação
iii. Árvores de Decisão para classificação (Algoritmos ID3 e C4.5)
iv. Classificadores baseados em vizinhos mais próximos (k-NN)
v. Super-ajuste (overfitting) e validação cruzada
vi. Introdução à combinação de modelos (Ensembles).
b. Agrupamento de Dados
i. Métodos Hierárquicos (Single/Average/Complete Linkage).
ii. Métodos Particionais
1. k-means
2. Visão geral do Expectation Maximization (EM) para Modelos de Misturas de Gaussianas
iii. Validação de agrupamentos e estimativa automática do número de grupos.
iv. Calibração prática de algoritmos de agrupamento
c. Análise de Associações
i. Algoritmo Apriori (para identificar correlações entre produtos/serviços adquiridos
concomitantemente)
7. Tópicos especiais – visão geral
a. “Text mining”
b. “Social CRM”
c. “Geomarketing”
Metodologia: Aulas expositivas com exemplos ao longo de todo o material e discussões
sobre aspectos práticos de aplicação das técnicas
Público-alvo
Profissionais que atuam em áreas de CRM, Marketing, Modelagem de Dados e, em geral,
profissionais interessados na utilização de métodos modernos de data mining. O pré-requisito
mínimo para este curso é uma boa formação em ciências exatas, recomendável
conhecimentos de estatística.
Outras Informações:
Horário das aulas: das 9h às 13h e das 14h às 18h, sendo a duração total de 24 horas-aula.
As aulas serão ministradas na nova sede da FIPECAFI: Rua Maestro Cardim, 1170 - Bela
Vista - São Paulo/SP. (Próximo a Avenida Paulista e às estações Paraíso e Vergueiro do
Metrô)
Investimento
O investimento total é de R$ 1.980,00à vista, ou em até 3 parcelas no cartão de crédito ou
boleto.
A FIPECAFI reserva o direito de alterar ou cancelar o curso em função de não atingir o
número mínimo de alunos por turma.
Docentes
Cláudio Paiva: Sócio-Diretor da Analitix. Atua desde 1997 em gestão integrada de riscos,
engenharia financeira e modelagem matemática em finanças, com passagens pela
Algorithmics do Brasil e pela Universidade de São Paulo, onde foi Professor-Doutor de
Matemática por 12 anos. Formação acadêmica em Física (Bacharel e Mestre), Ph.D. em
Matemática Aplicada pela Goethe Universität Frankfurt e realizou pós-doutoramento no
Courant Institute of Mathematical Sciences da New York University.
Eduardo Raul Hruschka: Professor Livre-Docente do Instituto de Ciências Matemáticas e de
Computação (ICMC) da Universidade de São Paulo. Pesquisador avançado (Nível 1-D) do
Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq). Atua na área de
mineração de dados há mais de 15 anos, tendo experiência prática com detecção automática
de fraudes e com modelos descritivos para computação forense. Graduado em Engenharia
Civil pela UFPR em 1995, concluiu mestrado e doutorado no Programa Interdisciplinar de
Computação de Alto Desempenho da COPPE/UFRJ em 1998 e 2001 respectivamente.
Realizou pós-doutoramento na University of Texas at Austin, USA, entre 2010-2012, onde
trabalhou no Laboratório IDEAL (Intelligent Data Exploration and Analysis Lab). É editor
associado da revista Information Sciences (Elsevier) e tem também participado de comitês
científicos de conferências internacionais sobre mineração de dados.
Estevam R. Hruschka Jr.: pesquisador e professor associado da Universidade Federal de
São Carlos. Foi jovem pesquisador FAPESP e atualmente é pesquisador CNPq (PQ-2). Atua
na área de mineração de dados há mais de 15 anos, tendo desenvolvido projetos de
cooperação científica nacional e internacional (com universidades como Carnegie Mellon
University (EUA), Stanford University (EUA), University of Washington (EUA), Oregon State
university (EUA), University of Waterloo (CAN)) e empresas (como Google Inc. (EUA), Yahoo!
Inc. (EUA), BBN Inc. (EUA), CYC Corp. (EUA), E-BIZ Solutions (Brasil)). Graduado em
Ciências da Computação pela Universidade Estadual de Londrina (1994), concluiu mestrado
em Ciência da Computação pela Universidade de Brasília (1997) e doutorado no Programa
Interdisciplinar de Computação de Alto Desempenho da COPPE/UFRJ (2003). Realizou pósdoutoramento na Carnegie Mellon University entre 2008-2012, onde trabalhou e atualmente é
professor colaborador/visitante no grupo de Aprendizado de Máquina responsável pelo
desenvolvimento do primeiro sistema computacional de “aprendizado sem fim” da história da
computação (http://rtw.ml.cmu.edu). É editor da revista Intelligent Data Analysis (IOS Press) e
tem também participado de comitês científicos de conferências internacionais sobre
aprendizado de máquina e mineração de dados.