CAP5: Amostragem e Distribuição Amostral
O que é uma amostra?
É um subconjunto de um universo (população).
Ex: Amostra de sangue; amostra de pessoas, amostra de objetos, etc
O que se espera de uma amostra?
Que ela represente as características do universo, ou seja, que seja representativa:
Software a ser utilizado: R – para baixar utilize o link:
Amostras aleatórias
Quando os elementos do universo têm a mesma probabilidade de ser selecionado para a amostra, dizemos que
se trata de uma amostra aleatória simples.
O processo de amostragem pode ser com ou sem reposição dos elementos do universo.
Procedimento para obter uma amostra aleatória de tamanho n:
Passo 1: Numere os elementos da população (supondo população finita)
Passo 2: Decida se o sorteio será com reposição (no caso de um elemento ter a possibilidade de ser sorteado
mais de uma vez na mesma amostra) ou sem reposição (no caso de não ser possível repetir elementos da
população)
Passo 3: Utilize um programa computacional para realizar o sorteio da amostra.
Exemplo 5.1
Suponha que a população seja composta de 25 elementos e se deseja obter uma amostra de tamanho n=5.
Programa escolhido: R
Comando para selecionar a amostra com reposição e sem reposição
set.seed(171);sample(1:25,5, replace=T)#comando para sorteio com reposição
Obtém-se os seguintes elementos da população (com reposição): 5 16 15 16 22
set.seed(16);sample(1:25,5) #comando para sorteio sem reposição
Obtém-se os seguintes elementos da população (sem reposição): 18 6 11 24 19
Exemplo 5.2
Um professor quer obter uma amostra aleatória simples sem reposição que seja representativa, de 10%, de uma
população de 200 alunos de uma escola, como deve proceder?
Passo 1: atribuir um número a cada aluno: 1:200;
Passo 2: sorteio sem reposição de 10% de 200. Logo n=20
Passo 3: utilizar um programa para realizar o sorteio. set.seed(16);sample(1:200,20)
Lista com os números sorteados ordenados: set.seed(16);sort(sample(1:200,20))
Amostragem Aleatória Estratificada de um universo finito
Muitas vezes uma população é composta de subpopulações (estratos) bem definidos, havendo maior
homogeneidade entre as unidades amostrais dentro de cada estrato do que entre as unidades amostrais de
estratos diferentes. Sexo, idade, condição sócio-econômica são exemplos típicos. Nestas condições, tais estratos
devem ser levados em consideração e o sorteio da amostra deve ser feito em cada um deles
independentemente; daí o nome de amostragem estratificada.
Há dois métodos de alocação das amostras aos estratos. Suponha que o universo esteja dividido em k estratos
de tal forma que o tamanho de cada estrato seja representado por
tal que a soma seja N. Se a
amostra da população for de tamanho n, é necessário estabelecer o tamanho da amostra em cada estrato, que
denotaremos por
tal que n1+n2+...+nk=n.
Alocação Proporcional
Exemplo5.3: Numa localidade com 150 000 habitantes, 45 000 têm menos de 20 anos de idade, 75 000 têm
idades entre 30 e 50 anos e 30 000 têm mais de 50 anos de idade. Extrair uma amostra de 30 habitantes desta
população pelo processo de amostragem estratificada com alocação proporcional.
Elementos: N=150000; N1=45000; N2=75000; N3=30000 e n=30
Assim,
Alocação Ótima de Neyman
Nesse tipo de alocação, a intensidade de amostragem calculada é distribuída proporcionalmente à variância de
cada estrato.
Este método depende de estimativas para o desvio-padrão de cada estrato. Estas estimativas podem ser obtidas
por variáveis auxiliares que apresentem alta correlação com a variável de interesse; através de conhecimentos
prévios ou por amostras pilotos.
Exemplo5.4: Numa localidade com 150 000 habitantes, 45 000 têm menos de 20 anos de idade, 75 000 têm
idades entre 30 e 50 anos e 30 000 têm mais de 50 anos de idade. Extrair uma amostra de 30 habitantes desta
população pelo processo de amostragem estratificada com alocação ótima de Neyman.
Considere as seguintes estimativas para o desvio padrão da variável de interesse: 1.20; 1.5 e 2.55
Elementos: N=150000; N1=45000; N2=75000; N3=30000 e n=30
Assim,
Estatísticas e Distribuições Amostrais
Estimador é qualquer função dos elementos da amostra e não depende de parâmetros desconhecidos.
Estimativa ou Estatística é a aplicação do estimador para valores obervados em uma amostra.
Parâmetros são números reais fixos e desconhecidos que compõem os modelos de probabilidade.
Exemplo5.5: Uma variável aleatória X com distribuição normal tem como parâmetros desconhecidos
que
representam a média e o desvio padrão desta variável aleatória.
As funções
representam estimadores para os valores observados de determinada amostra. Ao
selecionarmos a amostra e avaliarmos os valores obtidos em tais funções, obtendo o que chamamos de
estimativas ou estatísticas.
Valores observados da amostra: 3, 4, 8
O estimador diz como devo combinar os valores da amostra para obter as estimativas ou estatísticas
Estatísticas:
Parâmetros, o estimador
tem distribuição normal com parâmetro
.
Exemplo5.6: Observe que nem sempre a média e o desvio padrão de uma distribuição são os valores dos
parâmetros desta distribuição. Veja o caso da distribuição exponencial cujo parâmetro é , e, no entanto, a
média e o desvio padrão para esta distribuição é
. Nesta caso, o estimador
é o estimador de .
No caso da distribuição binomial, os parâmetros são
, enquanto que a média e o desvio padrão é
. Neste caso, o estimador de será dado pela proporção de sucessos na amostra, .
Supondo que a amostra 3,4,8 tenha sido retirada de uma população com distribuição exponencial, a estimativa
do parâmetro ,
(quando nos referimos a estimativas de um parâmetro, é usual colocar o acento ^
para se fazer a distinção entre estimativa e parâmetro).
Agora, se uma amostra apresenta 4 sucessos em 10 tentativas (distribuição binomial), a estimativa do parâmetro
,
.
Para se aprofundar mais neste assunto você poderá pesquisar sobre estimadores de máxima verossimilhança, ajustes de parâmetros para distribuições de
probabilidade.
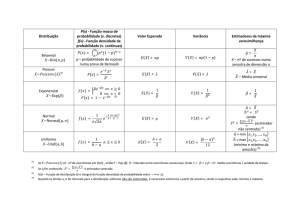
Distribuições Amostrais
É a função de densidade de probabilidade que descreve o comportamento probabilístico do estimador em
amostras aleatórias simples.
Distribuição Amostral de
Se
então
Se
então
para
Como regra geral,
já fornece boa aproximação da normalidade para o estimador média amostral.
Se a amostra apresenta boa simetria, a aproximação se dá para ,
No caso de assimetria, que pode ser avaliada pelo coeficiente de assimetria , a regra empírica muito utilizada é
No R,
pode ser calculado com o comando library(fBasics); skewness(x)
Exemplo 5.7
Considere a seguinte amostra piloto sobre a variável de interesse:
5.7 6.2 8.7 12.8 0.9 2.1 5.7 11.0 1.1 3.3 0.5 1.4 2.1 3.6 2.2 5.1 0.9 11.7 2.7 6.1
Avalie a simetria dos dados utilizando um ramo e folhas ou histograma. Trata-se de uma distribuição assimétrica.
Para esta amostra obtemos
Assim, a regra sugere que o tamanho da amostra para utilizarmos adequadamente a aproximação normal para o
estimador é
Erro Padrão
O erro padrão de uma estatística é o desvio padrão de sua distribuição amostral.
O erro padrão de é
.
Se não conhecemos , então, utilizamos como estimativa o valor de , desse modo teremos a estimativa para o
erro padrão de :
.
Exemplo 5.8
Considere a amostra do exemplo anterior cujas estatísticas são:
Estatísticas:
O erro padrão estimado de é
Intervalo de Confiança
Formado por duas estatísticas I e S que estabelecem limites para o parâmetro de interesse , tal que
O intervalo de I a S é chamado de intervalo de
de confiança para o parâmetro desconhecido .
Veja a seguir o formulário para se obter as estatística I e S do intervalo:
É aconselhável ao aluno consultar a bibliografia para maiores detalhes. (Montgomery, Prob e Est na Eng)
Exemplo 5.9
Considere a amostra do exemplo 5.7. Se desejarmos estimar a média da variável de interesse, consultando a
tabela 10.5, vemos que se trata da terceira situação.
Já temos as estatísticas da amostra (exemplo 5.8)
Em geral utiliza-se
. Para obter
deve-se consultar a tabela da distribuição t. e obter 2.093.
No R, utilize
qt(0.025,19)
[1] -2.093024 #valor da cauda inferior
qt(0.975,19)
[1] 2.093024 #valor da cauda superior; é o simétrico do valor anterior!
Para utilizar a tabela observe o grau de liberdade (19) e a probabilidade acumulada em t (0.975).
Assim, 2.91
6.47
Exemplo 5.10
Para avaliar a proporção de itens defeituosos de um lote observou-se uma amostra de 50 itens dos quais 2
apresentaram defeito. Obtenha a estimativa por intervalo da proporção de itens defeituosos produzidos.
Consultando a tabela 10.5, vemos que se trata da penúltima situação.
Em geral utiliza-se
. Para obter
(atenção,
sempre associará
A estatística de p = 2/50 = 0.04
Assim, 0.014
0.094
deve-se consultar a tabela da distribuição normal e obter 1.96.
)
Escolha do tamanho da amostra para estimar
com Erro estabelecido
O pesquisador estabelece um limite de afastamento aceitável . Para um nível de significância , o tamanho da
amostra para se avaliar a média é dado por:
Exemplo 5.11
Para avaliar a condutividade térmica média do ferro Armco, o pesquisador estabelece um erro na estimativa de
no máximo 0.05 Btu/h-ft-oF, com 95% de confiança. Suponha que seja conhecido
. O tamanho amostral
necessário para este erro é:
O tamanho da amostra para se avaliar a proporção
é dado por:
O tamanho amostral para esta situação é máximo quando
. Desse modo, é sempre possível estabelecer
uma cota superior para n.
Exemplo 5.12
Para avaliar a proporção de peças com defeito, o pesquisador estabelece um erro na estimativa de no máximo
0.05, com 95% de confiança. Suponha que uma amostra piloto de 75 itens; 12 tinham algum defeito. O tamanho
amostral necessário para este erro é:
Veja que se não tivemos informação sobre a amostra piloto, poderíamos utilizar a cota superior:
Exercícios:
1. No jogo da mega sena são sorteados 6 números sem reposição entre os números de 1 a 60.
a. Simule um jogo com 6 números.
b. Simule um jogo com 10 números.
c. Simule o sorteio da mega sena. Se as apostas foram as do item a e b, quantos acertos ocorreram?
2. Obtenha o valor de
, para
.
3. Um engenheiro está analisando a força de compressão do concreto. Sabe-se que esta força se distribui
normalmente com
? Quantas amostras devem ser analisadas para se obter um intervalo de 95% de
confiança para a força média, estabelecendo um erro máximo de 3psi.
4. Suponha que o engenheiro da questão 2 conseguiu uma amostra de tamanho 8 com os seguintes valores:
3205, 3201, 3195, 3200, 3205, 3191, 3192, 3202
Obtenha o intervalo de 95% de confiança para a média.
5. Um gerente está planejando um experimento para testar a durabilidade de duas marcas de pneus (em km).
Suponha que o erro máximo estabelecido para um intervalo de 95% de confiança seja de 1000 km. Sabe-se
que o desvio padrão de cada marca é estimado em
a. Estabeleça o tamanho da amostra para cada marca:
b. Supondo que o tamanho amostral do experimento seja
e que há um universo de 10.000
pneus para cada marca. Calcule o tamanho da amostra em cada estrato definido pela marca do pneu
com base na alocação proporcional.
c. Repita o item c, utilizando a alocação ótima de Neyman.
6. Um estudo pretende estimar a proporção de veículos sem seguro em duas cidades A e B. Estudos
preliminares estimam que 20% dos veículos destas cidades não possuem seguro. Estabeleça o tamanho da
amostra considerando um erro máximo de 0.03 para estimar um intervalo de 95% de confiança para a
proporção.
7. Supondo que o tamanho amostral do estudo da questão anterior seja e que há um universo de 100.000
veículos na cidade A e 500.000 veículos na cidade B. Calcule o tamanho da amostra em cada cidade com
base na alocação proporcional.
8. Num levantamento realizado em certa cidade, de uma amostra de 120 veículos, 30 não possuíam seguro.
Estime o intervalo de 95% de confiança para a proporção de veículos sem seguro.
Resposta
1 Sugestão de solução: a)set.seed(1); sort(sample(1:60,6)); b) set.seed(1); sort(sample(1:60,10)); c)
set.seed(1); sort(sample(1:60,6)) (com a mesma semente ambas as apostas são vencedoras. Experimente mudar
a semente!
2.qt(0.025,5:15);
valores:
-2.570582
-2.446912
-2.364624
2.178813 -2.160369 -2.144787 -2.131450. Atenção que a notação
3 11
4
data: x
t = 1633.046, df = 7, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
3194.243 3203.507
sample estimates:
mean of x
3198.875
5 a 16 e 21 b 20 e 20 c 19 e 21
6 683
7 114 e 569
8 0.247 e 0.253
-2.306004
-2.262157
-2.228139
-2.200985
-
refere-se ao simétrico destes valores.