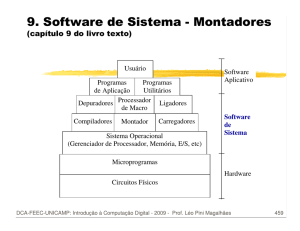
CT 720 Tópicos em Aprendizagem de Máquina e
Classificação de Padrões
2-Teoria Bayesiana de Decisão
ProfFernandoGomide
DCA-FEEC-Unicamp
Conteúdo
1.
2.
3.
4.
5.
6.
7.
8.
9.
ProfFernandoGomide
Introdução
Teoria Bayesiana de decisão: atributos contínuos
Classificação com taxa de erro mínima
Funções de discriminação e classificadores
Densidade normal
Funções de discriminação para densidade normal
Teoria Bayesiana de decisão: atributos discretos
Redes Bayesianas
Resumo
DCA-FEEC-Unicamp
1-Introdução
Teoria Bayesiana de decisão
– abordagem estatística para reconhecimento padrões
– assume problema de decisão formulado probabilisticamente
– todos valores relevantes de probabilidade conhecidos
– identificação de sequências DNA
Este capítulo
– apresenta fundamentos da teoria
– teoria: formaliza procedimentos intuitivos
ProfFernandoGomide
DCA-FEEC-Unicamp
Previsão próximo tipo peixe?
ω = estado : variável aleatória
ω = ω1 sea bass
ω = ω2 salmon
Assumindo
P(ω1): probabilidade a priori próximo tipo é sea bass
P(ω1): probabilidade a priori próximo tipo é salmon
P(ω1) + P(ω2) = 1
ProfFernandoGomide
DCA-FEEC-Unicamp
Decidir tipo próximo peixe
– classificação incorreta: mesmo custo
– informação disponíveis: somente P(ω1) e P(ω2)
Regra de decisão
decidir ω1 se P(ω1) > P(ω2) ; caso contrário decidir ω2
– regra: mesma decisão, mesmo sabendo que existem 2 tipos
– desempenho depende da escolha de P(ω1) e P(ω2)
ProfFernandoGomide
DCA-FEEC-Unicamp
Na prática
– temos mais informação
– e.g. medida luminosidade (x)
– densidade probabilidade condicional de classe p(x/ω)
– função densidade de probabilidade de x dado estado ω
– p(x/ω1) e p(x/ω2) descrevem diferenças de luminosidade
ProfFernandoGomide
DCA-FEEC-Unicamp
ProfFernandoGomide
DCA-FEEC-Unicamp
Supor que conhecemos:
– P(ω1) e P(ω2)
– p(x|ω1) e p(x|ω2)
– medida de luminosidade x
Como x influencia a escolha correta do tipo?
– estimativa correta do estado ?
– como decidir o tipo (classe)
ProfFernandoGomide
DCA-FEEC-Unicamp
Classificação usando luminosidade como atributo
p ( ω j , x ) = P (ω j | x ) p ( x ) = p ( x | ω j ) P (ω j )
P (ω j | x ) =
p( x) =
p ( x | ω j ) P (ω j )
p ( x)
Bayes
2
∑ p ( x | ω j ) P (ω j )
j =1
p (efeito / causa) P (causa)
P (efeito)
likelyhood × prior
posterior =
evidence
P (causa / efeito) =
ProfFernandoGomide
DCA-FEEC-Unicamp
P(ω1) = 2/3
P(ω2) = 1/3
Regra de decisão de Bayes
decidir ω1 se P(ω1| x) > P(ω2| x) ; caso contrário decidir ω2 (*)
ProfFernandoGomide
DCA-FEEC-Unicamp
Regra de Bayes minimiza a probabilidade de erro
P (ω1 | x) se decidimos ω2
P (error | x) =
P (ω2 | x) se decidimos ω1
– para uma observação x minimiza-se a probabilidade de erro:
decidindo ω1 se P(ω1| x) > P(ω2| x); ou ω2 caso contrário
– esta regra minimiza a probabilidade de erro para qualquer x, em média?
ProfFernandoGomide
DCA-FEEC-Unicamp
– em média a probabilidade do erro é
P (error ) =
∞
∞
−∞
−∞
∫ P(error , x)dx = ∫ P(error | x) p( x)dx
– logo a integral P(error) é mínima se P(error/x) é mínima, isto é, se
decidir ω1 se P(ω1| x) > P(ω2| x); caso contrário decidir ω2
– P(error/x) = min [P(ω1| x) , P(ω2| x) ]
Regra de decisão de Bayes (alternativa)
decidir ω1 se p(x|ω1)P(ω1) > p(x|ω2) P(ω2); caso contrário decidir ω2
ProfFernandoGomide
DCA-FEEC-Unicamp
2-Teoria Bayesiana de decisão: atributos contínuos
Generalização
– uso de vários atributos
– mais de dois estados
– outras decisões e não só classificação
– critério mais geral que probabilidade de erro
ProfFernandoGomide
DCA-FEEC-Unicamp
Notação
x : atributo, x ∈ Rd
Rd : espaço (Euclideano) de atributos
{ω1, ..., ωc}: conjunto (finito) de c estados (categorias)
{α1, ..., αa}: conjunto (finito) de a decisões (ações)
λ(αi, ωj): loss function = custo decisão αi quando em ωj
Regra de Bayes
P (ω j | x ) =
p ( x) =
ProfFernandoGomide
p ( x | ω j ) P (ω j )
p ( x)
c
∑ p ( x | ω j ) P (ω j )
j =1
DCA-FEEC-Unicamp
– supor observação x e ação αi correspondente
– se estado verdadeiro é ωj, então custo associado é λ(αi, ωj)
– valor esperado do custo da ação αi será:
c
R (α i | x ) = ∑ λ ( α i | ω j ) P ( ω j | x )
i =1
Risco condicional
– dado x, que ação αi minimiza o risco condicional, ∀x ?
– solução (ótima): regra de Bayes !
ProfFernandoGomide
DCA-FEEC-Unicamp
Regra (estratégia) de decisão
– α(x): fornece a decisão para cada valor de x
– para cada x, α(x) assume um dos a valores α1, ..., αa
– risco global: risco associado com uma estratégia de decisão
R = ∫ R (α(x) | x) p (x) dx
Risco global
– se α(x) é tal que o valor de R(αi(x)) é o menor possível ∀x,
então risco global é minimizado; isto motiva o seguinte:
ProfFernandoGomide
DCA-FEEC-Unicamp
Regra de Bayes
para minimizar risco global:
1 – calcular
c
R ( α i | x ) = ∑ λ ( α i | ω j ) P ( ω j | x ),
i =1
i = 1,K, a
2 – selecionar ação αi que minimiza R(αi|x)
R* = risco de Bayes
ProfFernandoGomide
DCA-FEEC-Unicamp
Exemplo com duas classes
– α1 : decide que estado verdadeiro é ω1
– α2 : decide que estado verdadeiro é ω2
– λij = λ(αi, ωj) custo quando decisão ⇒ ωi mas verdadeiro é ωj
risco condicional
R(α1 | x) = λ11P (ω1 | x) + λ12 P(ω2 | x)
R(α 2 | x) = λ 21P (ω1 | x) + λ 22 P(ω2 | x)
decidir ω1 se R(α1|x) < R(α2|x)
ProfFernandoGomide
DCA-FEEC-Unicamp
– alternativamente, em termos das probabilidades a posteriori
decidir ω1 se (λ21 – λ11)P(ω1| x) > (λ12 – λ22) P(ω2| x)
– em geral λ21 > λ11 e λ12 > λ22
– utilizando Bayes, probabilidades a priori e densidades condicionais
P (x | ω1 ) (λ12 − λ 22 ) P (ω2 )
>
P (x | ω2 ) (λ 21 − λ11 ) P(ω1 )
ProfFernandoGomide
Razão de verosimilhança
DCA-FEEC-Unicamp
3-Classificação com taxa de erro mínima
0 i = j
λ (α i | ω j ) =
1 i ≠ j
i, j = 1,K, c
c
R (α i | x ) = ∑ λ ( α i | ω j ) P (ω j | x )
i =1
=
∑ P(ω j | x)
i≠ j
= 1 − P(ωi | x)
ProfFernandoGomide
DCA-FEEC-Unicamp
Regra Bayes para taxa de erro mínima
– minimizar risco: selecionar ação que minimiza risco condicional
– minimizar taxa de erro de classificação:
decidir ωi se P(ωi | x) > P(ωj | x)
ProfFernandoGomide
∀ i, j
(ver *)
DCA-FEEC-Unicamp
4-Funções discriminação e classificadores
Função discriminação
gi(x), i = 1,..., c
classificador atribui classe ωi a x se gi(x) > gi(x) ∀ j ≠ i
Exemplos:
ProfFernandoGomide
gi(x) = – R(αi|x)
risco condicional mínimo
gi(x) = P(ωi | x)
erro classificação mínimo
DCA-FEEC-Unicamp
Estrutura funcional de classificadores estatísticos
ProfFernandoGomide
DCA-FEEC-Unicamp
Propriedades
– funções discriminação não são únicas
– transformações: f(gi(x)), f monotônica crescente
– simplificação analítica e computacional
– exemplos de classificadores (erro classificação mínimo):
gi (x) = P (ωi | x) =
p( x | ωi ) P (ωi )
c
∑ p ( x | ω j ) P (ω j )
j =1
gi (x) = p( x | ωi ) P (ωi )
gi (x) = ln p (x | ωi ) + ln P(ωi )
ProfFernandoGomide
DCA-FEEC-Unicamp
– formas funções diferentes, mas regras de decisão equivalentes
– efeito: dividir o espaço de atributos em c regiões distintas
se gi(x) > gi(x) ∀ j ≠ i então x ∈ R i
– Ri∩ Rj = ∅
– R 1 ,..., R c formam uma partição do espaço de atributos
ProfFernandoGomide
DCA-FEEC-Unicamp
– exemplo: duas categorias (classes)
atribuir ω1 a x se g1(x) > g2(x) ∀ j ≠ i
g (x) = g1(x) – g2(x)
atribuir ω1 a x se g(x) > 0
(***)
g (x) = P (ω1 | x) − P (ω2 | x)
g (x) = ln
p (x | ω1 )
P(ω1)
+ ln
p (x | ω2 )
P(ω2 )
(**)
ProfFernandoGomide
DCA-FEEC-Unicamp
5-Densidade normal
p ( x) =
1
t −1
exp
(
x
µ
)
Σ
(
x
µ
)
−
−
−
2
(2π)d / 2 | Σ |1/ 2
µ = E[x] =
1
∞
∫ x p(x)dx ,
−∞
Σ = E[(x − µ)(x − µ) ] =
t
µi = E[ xi ]
∞
t
(
x
−
µ
)(
x
−
µ
)
p (x)dx
∫
−∞
[ ]
Σ = σij , σij = E[( xi − µi )( x j − µ j )], Σ > 0
ProfFernandoGomide
DCA-FEEC-Unicamp
( x − µ)t Σ −1( x − µ) = cte
ProfFernandoGomide
DCA-FEEC-Unicamp
λ2
γ1
γ2
µ
λ1
(x − µ)t Σ −1(x − µ) = 1
ProfFernandoGomide
DCA-FEEC-Unicamp
Transformações lineares
– combinações lineares de variáveis aleatórias normais são normais
p(x) = N(µ
µ, ∑)
A (d × k)
y = Atx (k × 1)
p(y) = N(Atµ, At∑A)
– se A = a (d × 1), k = 1, ||a|| = 1 então
y = atx (escalar que representa projeção de x ao longo de a)
at ∑a variância da projeção de x ao longo de a
ProfFernandoGomide
DCA-FEEC-Unicamp
ProfFernandoGomide
DCA-FEEC-Unicamp
Observações
ProfFernandoGomide
r 2 = (x − µ)t Σ −1( x − µ)
Distância de Mahalanobis
V = Vd | Σ |1/ 2 r d
Volume hiperelipsóide
πd / 2 /(d / 2)!
d par
Vd = d ( d −1) / 2
(d − 1 / 2)!/ d! d impar
2 π
Volume hiperesfera
DCA-FEEC-Unicamp
6-Funções discriminação p/ densidade normal
gi (x) = ln p (x | ωi ) + ln P (ωi )
p (x | ωi ) ~ N (µi , Σi )
1
d
1
gi (x) = − (x − µ)t Σ −1 (x − µ) − ln 2π − ln | Σi | + ln P(ωi )
2
2
2
Caso 1: ∑i = σ2I
g i ( x) = −
g i ( x) = −
x − µi
2σ
1
2σ
2
+ ln P (ωi )
2
t
t
t
[
x
x
−
2
µ
x
+
µ
i µ i ] + ln P (ωi )
2
termo quadrático é o mesmo ∀ i
gi (x) = w ti x + wio
wi =
1
σ
µ ,
2 i
wio =
Máquina linear
−1
2σ
t
µ
µ + ln P(ωi )
2 i i
Limiar (bias) para i-ésima classe
g i ( x) − g j ( x) = 0
w t (x − xo ) = 0
Hiperplano separa R i e R j
passa por xo e é ortogonal
à reta que une as médias
w = µi − µ j
1
σ2
xo = (µi + µ j ) −
2
µi − µ j
ln
2
P(ωi )
(µ i − µ j )
P (ω j )
1
P (ωi ) = P (ω j ) ⇒ xo = (µi + µ j )
2
P(ωi) ≠ P(ωj)
xo se afasta da média mais provável
P(ωi) = P(ωj), ∀i, j termo
g i ( x) = x − µ i
2
ln P(ωi) irrelevante
Classificador distância mínima
Caso 2: ∑i = ∑
independente de i
1
d
1
gi (x) = − ( x − µ)t Σ −1( x − µ) − ln 2π − ln | Σi | + ln P(ωi )
2
2
2
1
gi (x) = − ( x − µ)t Σ −1( x − µ) + ln P (ωi )
2
se P(ωi) = P(ωj), ∀i, j termo
1
gi (x) = (x − µ)t Σ −1( x − µ)
2
ln P(ωi) irrelevante, logo:
Classificador distância (Mahalanobis) mínima
1
d
1
gi (x) = − (x − µ)t Σ −1 (x − µ) − ln 2π − ln | Σi | + ln P(ωi )
2
2
2
eliminando xt ∑–1x da expansão de (x – µ)t ∑–1 (x – µ) (independe de i)
gi (x) = w ti x + wio
w i = Σ −1µi
Máquina linear
1
wio = − µti Σ −1µi + ln P(ωi )
2
se R i e R j são contíguas, a superfície de decisão é um hiperplano
w t (x − xo ) = 0
w = Σ −1 (µi − µ j )
ln[ P (ωi ) / P (ω j )]
1
xo = (µi + µ j ) −
(µi − µ j )
t −1
2
(µi − µ j ) Σ (µi − µ j )
– hiperplano separa R i e R j não é ortogonal à reta que une as médias
– hiperplano intercepta esta reta em xo
– se P(ωi) = P(ωj), ∀i, j então está no meio das médias
– se P(ωi) ≠ P(ωj), então hiperplano se afasta da média mais provável
Caso 3: ∑i = arbitrária
único termo independente de i
1
d
1
gi (x) = − ( x − µ)t Σ −1( x − µ) − ln 2π − ln | Σi | + ln P(ωi )
2
2
2
expandindo
gi (x) = xt Wi x + w ti x + wio
1
Wi = − Σi−1
2
w i = Σi−1µi
1
1
wio = − µti Σi−1µi − ln | Σi−1 | + ln P (ωi )
2
2
Classificador quadrático
– caso com duas classes
– superfícies de decisão são hiperquadráticas
• hiperplanos
• hiperesferas
• hiperelipsóides
• hiperparabolóides
– regiões (decisão) não necessariamente conectadas
Quatro classes
Exemplo: região de decisão, dados Gaussianos
x2
3
1 / 2 0
µ1 = Σ1 =
6
0
2
10
8
µ1
6
3
2 0
µ2 = Σ2 =
− 2
0 2
4
2
-2
P(ω1) = P(ω2 ) = 0.5
2
-2
µ2
4
6
8
10
x1
g1 (x) = xt W1x + w1t x + w10
g1 (x) = xt W1x + w1t x + w10
g1 (x) = g 2 (x)
x2
10
x2 = 3.514 − 1.125 x1 + 0.1875 x12
8
µ1
6
4
2
-2
2
-2
µ2
4
6
8
10
x1
7-Teoria Bayesiana de decisão: atributos discretos
x ∈ {v1, ...., vm}
P (ω j | x ) =
P ( x) =
P ( x | ω j ) P (ω j )
P ( x)
Regra de Bayes
c
∑ P ( x | ω j ) P (ω j )
j =1
α* = arg min R (αi | x)
i
Regra de decisão mínimo risco
Regra de Bayes para taxa de erro mínima
decidir ωi se P(ωi | x) > P(ωj | x)
Funções de discriminação
gi (x) = P (ωi | x) =
P( x | ωi ) P(ωi )
c
∑ P ( x | ω j ) P (ω j )
j =1
gi (x) = P (x | ωi ) P (ωi )
gi (x) = ln P (x | ωi ) + ln P(ωi )
∀ i, j
(ver *)
Exemplo: atributos binários independentes
– duas categorias (classes)
– cada componente é um valor binário
– componentes são independentes
x = ( x1,K, xd )t , xi ∈{0,1}
pi = Pr[ xi = 1 | ω1 )
qi = Pr[ xi = 1 | ω2 )
d
P(x | ω1 ) = ∏ pixi (1 − pi )1− xi
i =1
d
P(x | ω2 ) = ∏ qixi (1 − qi )1− xi
i =1
– Razão de verosimilhança
P (x | ω1 ) d pi
= ∏
P (x | ω2 ) i =1 qi
g (x) = ln
xi
1− xi
1 − pi
1 − qi
P ( x | ω1 )
P (ω1 )
+ ln
P ( x | ω2 )
P (ω2 )
p
1 − pi
P (ω1)
g (x) = ∑ xi ln i + (1 − xi ) ln
ln
+
qi
1 − qi
P (ω2 )
i =1
d
(**)
Linear em xi
d
g (x) = ∑ wi xi + w0
i =1
wi = ln
pi (1 − qi )
,
qi (1 − pi )
d
w0 = ∑ ln
i =1
i = 1,K, d
(1 − qi )
P (ω1 )
+ ln
(1 − pi )
P (ω2 )
lembrar: decidir ω1 se g(x) > 0 e ω2 se g(x) ≥ 0
(***)
Análise
– g(x) é uma combinação linear (ponderada) das componentes de x
– valor de wi é a relevância de uma resposta xi = 1 na classificação
– se pi = qi então valor de xi é irrelevante (wi = 0)
– se pi > qi então (1 – pi) < (1 – qi), wi > 0 e xi = 1 ⇒ wi votos para ω1
– se pi < qi então (1 – pi) > (1 – qi), wi < 0 e xi = 1 ⇒ |wi|votos para ω2
Exemplo: dados binários 3-d
– duas categorias (classes)
– cada componente é um valor binário
– componentes são independentes
P(ω1 ) = P(ω2 ) = 0.5
pi = 0.5, qi = 0.8, i = 1,2,3
wi = ln
pi (1 − qi )
,
qi (1 − pi )
i = 1,K, d
(1 − qi )
P (ω1 )
w0 = ∑ ln
+ ln
(
1
−
p
)
P (ω2 )
i
i =1
d
wi = ln
0.8(1 − 0.5)
= 1.3863 i = 1,K,3
0.5(1 − 0.8)
3
w0 = ∑ ln
i =1
(1 − 0.8)
0.5
+ ln
= −1.75
(1 − 0.5)
0.5
x3
x3
0
0
1
1
1
1
x2
0
x1
x2
0
0
1
pi = 0.8 qi = 0.5
i = 1,2,3
x1
0
1
pi = 0.8 qi = 0.5, i = 1,2
p3 = q3
8-Redes Bayesianas
Conhecimento sobre distribuições
– parâmetros de distribuições
– dependência/independência estatística
– relações causais entre variáveis
Redes Bayesianas
– explora informação estrutural no raciocínio com variáveis
– usa relações probabilísticas entre variáveis
– assume relações causais
estados de A {a1, a2,...} ≡ a
P(a)
B
A
P(b) estados de B {b1, b2,...} ≡ b
arco
nó
P(d|a,c)
C
D
P(c|b)
pai
E
P(e|d)
filho
Regra de Bayes + probabilidades condicionais
⇓
probabilidade conjunta de qualquer configuração de variáveis
P(b)
P(a)
P(a1)
P(a2)
P(a3)
P(a4)
0.25
0.25
0.25
0.25
P(x1|ai,bj)
P(x|a,b)
a1 = winter
a2 = spring
a3 = summer
a4 = autumn
A
season
B
locale
b1 = north Atlantic
b2 = south Atlantic
P(b1)
P(b2)
0.6
0.4
P(x2|ai,bj)
a1, b1
0.5
0.5
a1, b2
0.7
0.3
a2, b1
0.6
0.4
a2, b2
0.8
0.2
a3, b1
0.4
0.6
a3, b2
0.1
0.9
a4, b1
0.2
0.8
a4, b2
0.3
0.7
X
fish
x1 = salmon
x2 = sea bass
P(d|x)
P(c|x)
P(c1|xk)
P(c1|xk)
P(c1|xk)
x1
0.6
0.2
0.2
x2
0.2
0.3
0.5
c1 = light
c2 = medium
c3 = dark
C
light
D
tick
d1 = wide
d2 = thin
P(d1|xk)
P(d2|xk)
x1
0.3
0.7
x2
0.6
0.4
P(a3 , b1, x2 , c3 , d 2 ) = P(a3 ) P (b1 ) P( x2 | a3 , b1 ) P(c3 | x2 ) P(d 2 | x2 ) = 0.25 × 0.6 × 0.4 × 0.5 × 0.4 = 0.012
Redes Bayesianas formalmente
– grafo acíclico
– nó: variável aleatória (atributo)
– arco: efeito, causa (A afeta B → B condicionado a A)
– cada nó condicionalmente independente dos não descendentes
– representa probabilidade conjunta das variáveis
x2
x1
P(xi|x1,x2)
x3
xi
xj
xn
n
P( x1,K, xn ) = ∏ P( xi | PaiDe( xi ))
i =1
Exemplo
P(a)
P(b|a)
P(c|b)
P(d|c)
A
B
C
D
P(a, b, c, d) = P(a) P(b | a) P(c | b) P(d | c)
P(d) = ∑ P(a, b, c, d)
a,b,c
=
∑ P(a) P(b | a) P(c | b) P(d | c)
a,b,c
= ∑ P(d | c)∑ P(c | b)∑ P(b | a) P(a)
c
b
a
P(b)
P(c)
P(d)
– em geral: dados os valores de algumas variáveis (evidência: e)
qual é o valor de uma configuração das outras variáveis (x) ?
P ( x | e) =
P(x, e)
= αP (x, e)
P(e)
Exemplo: salmon and sea bass
– probabilidade peixe veio do Atlântico Norte (b1)
– sabendo que é primavera (spring a2)
– peixe é salmão (salmon x1) claro (light c1)
P(b1 | a2 , x1, c1 ) ?
Em classificação (erro mínimo): salmon or sea bass ?
– sabe-se que
• peixe é claro (c1)
• origem é Atlântico Norte (b2)
– não se sabe:
• estação do ano
• espessura
– problema de classificação:
P( x1 | c1, b2 ) ?
P( x2 | c1, b2 ) ?
P( x1 | c1, b2 ) =
P( x1, c1, b2 )
= α ∑ P( x1, a, b2 , c1, d)
P (c1, b2 )
a,d
= α ∑ P (a) P (b2 ) P ( x1 | a, b2 )P(c1 | x1 ) P(d | x1 )
a,d
= αP(b2 ) P(c1 | x1 ) ∑ P (a) P( x1 | a, b2 ) ∑ P(d | x1 )
a
d
= αP(b2 ) P(c1 | x1 )
× [ P(a1 ) P( x1 | a1, b2 ) + P(a2 ) P( x1 | a2 , b2 )
+ P (a3 ) P ( x1 | a3 , b2 ) + P (a4 ) P( x1 | a4 , b2 )]
× [ P(d1 | x1 ) + P (d 2 | x1 )]
=1
P( x1 | c1, b2 ) = α(0.4)(0.6)[(0.25)(0.7) + (025)(0.8)
+ (0.25)(0.1) + (0.25)(0.3)]1.0
P( x1 | c1, b2 ) = α 0.114
P( x2 | c1, b2 ) = α 0.066
classificação: salmon !
Naive Bayes
– relações de dependência entre atributos desconhecidas
– neste caso assume-se independência condicional
P ( x | a, b ) = P ( x | a ) P ( x | b )
9-Resumo
Teoria Bayesiana de decisão é simples
Regras de decisão
– minimizar risco: ação que minimiza risco condicional
– minimizar Pr[erro]: estado que maximiza densidade a posteriori P(ωj |x)
Superfícies decisão hiperquadráticas no caso Gaussiano
Redes: relações dependência/independência entre variáveis
Observação
Este material refere-se às notas de aula do curso CT 720 Tópicos Especiais
em Aprendizagem de Máquina e Classificação de Padrões da Faculdade de
Engenharia Elétrica e de Computação da Unicamp e do Centro Federal de
Educação Tecnológica do Estado de Minas Gerais. Não substitui o livro
texto, as referências recomendadas e nem as aulas expositivas. Este material
não pode ser reproduzido sem autorização prévia dos autores. Quando
autorizado, seu uso é exclusivo para atividades de ensino e pesquisa em
instituições sem fins lucrativos.
ProfFernandoGomide
DCA-FEEC-Unicamp