Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Objetivos:
- QUANTIFICAR OS ERROS COMETIDOS NA CLASSIFICAÇÃO
- MEDIR A QUALIDADE DO TRABALHO FINAL
- AVALIAR A APLICABILIDADE OPERACIONAL DA CLASSIFICAÇÃO
Fontes de erro das classificações temáticas
Os erros se devem a alguma das seguintes características:
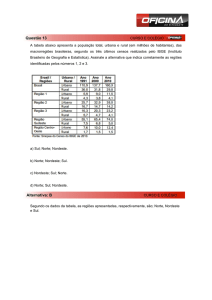
Erro de omissão: se produz quando ainda pertencendo a uma determinada classe o
pixel não é designado a esta classe (erro do tipo I).
Erro de comissão: se produz quando os pixels são classificados em determinada classe
não pertencendo realmente a ela (erro do tipo II).
Observação: se existissem apenas duas classes as definições acima as definições acima
seriam iguais com redação diferente, mas isso não acontece na realidade e por isso são
diferentes.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Fontes de erro das classificações temáticas
Entre os fatores que influem a incorreta classificação dos pixels ocupa uma posição
relevante a estrutura territorial da imagem estudada.
Se a fragmentação é grande (áreas homogêneas pequenas) teremos um aumento
considerável de bordas e em consequência uma grande quantidade de mistura espectral
(pixels “mistos”).
Outros fatores são: a forma das parcelas, as declividades, a orientação e o contraste
espectral de áreas contínuas.
A confecção da legenda afeta o nível de erro das classificações:
- Legenda muito genérica: erro de classificação muito pequeno mas teremos um mapa
temático pobre.
- Legenda com muitas classes: aumento do erro da classificação porque as distâncias
espectrais entre as classes será menor e consequentemente poderemos ter maiores erros de
omissão e comissão.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Medidas de confiança
Depois da classificação deveremos avaliar a qualidade da classificação de maneira que o
usuário possa conhecer a proporção das designações às classes incorretas e o nível de
confiança que proporciona o trabalho realizado.
Excluindo-se a visita a campo a todos os pixels classificados da imagem existem duas
maneiras de estimar o erro cometido na classificação:
- Comparando os resultados com outras fontes analógicas (por exemplo, mapas de uso
do solo) ou tabelados (por exemplo, estatísticas agrárias)
Procedimento não muito interessante já que os documentos utilizados geralmente
já são produto de uma amostragem ou generalização de outros dados.
Além disso geralmente a data de obtenção dos documentos utilizados é mais
antiga que a imagem a ser analisada.
- Realizando uma campanha de campo sobre uma amostra de pixels da imagem.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Amostragem para a verificação
A composição da amostra deve ser suficientemente representativa da população
para permitir que se estimem os parâmetros necessários a verificação da classificação.
Além dos fatores espaciais (abaixo) o custo econômico relacionado as rotas que
serão necessárias para levantar a verdade terreno deverá ser levado em conta.
Tipos de amostragem:
Aleatório Simples: consiste em estabelecer “ao azar” os pixels que vão ser visitados a
campo, sem nenhum outro aspecto.
A seleção de um elemento não condiciona a seleção dos
seguintes.
Todos os pixels tem a mesma probabilidade de serem
selecionados o qual é uma vantagem do ponto de vista estatístico.
Método difícil ou muito caro de ser executado, já que os
pixels selecionados não levam em conta a estrutura espacial da área
em estudo (ex., estradas).
A variabilidade espacial de certas classes pode não ser
contemplado por este método de seleção da amostra.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Aleatório estratificado: se divide o espaço amostral em diversas subpopulações, cada
uma das quais se aplica a amostragem aleatória simples.
Cada divisão do espaço amostral se chama estrato e para sua
obtenção utilizamos algum critério que tenha relação com o
processo de classificação, quer dizer, os estratos devem ter
homogeneidade interna.
Exemplo: na classificação de cultivos agrícolas poderíamos
utilizar os seguintes tipos de estratos – orientação norte e
orientação sul, diferentes altitudes, tipos de solos diferentes, etc.
Este método minimiza os inconvenientes do método anterior
adaptando-se de forma mais eficiente as particularidades da
população.
Sistemático: a partir de um ponto qualquer, se selecionam os pontos amostrais
equidistantes nas coordenadas x e y da imagem.
Possui a vantagem de explorar espacialmente toda a extensão
da imagem.
No entanto desconhece a priori a distribuição das classes
podendo infravalorizar a presença de alguma(s) das classes.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Sistemático não alinhado: o ponto de partida desta amostragem é uma quadrícula
sistemática sobre a imagem e a obtenção aleatória do ponto amostral dentro de cada
quadrícula.
Este método mantém as vantagens do método sistemático e
introduz a aleatoriedade das amostras.
Por conglomerados: se trata de uma amostragem aleatória em que ao invés de utilizar
apenas um pixel no ponto “sorteado” selecionam-se um grupo deles para formar a
amostra, seguindo sempre o mesmo padrão de forma.
Tamanho da Amostra
O tamanho da amostra depende de dois fatores fundamentais:
Devemos levar em consideração o nível de confiança que queremos outorgar a
estimativa. Se quisermos 100% de confiança devermos fazer com que n tenda ao infinito
(n→∞), ou seja, o tamanho da amostra tende a ser do tamanho da população.
O tamanho da amostra dependerá do grau de informação prévia já temos sobre a
população, porque isso permitirá reduzir o tamanho da amostra sem reduzir o nível de
confiança da estimativa.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Matriz de confusão
O próximo passo da verificação dos resultados obtidos na classificação consiste em obter
de cada pixel da amostra a sua verdadeira ocupação (verdade terreno) e compará-la
com a proposta do classificador.
Esta comparação entre os resultados da classificação e os da amostragem (verdade
terreno) realiza-se a confecção de uma matriz quadrada em que nas colunas temos as
classes propostas pelo algoritmo de classificação e as linhas a ocupação real Æ Matriz de
confusão.
Cada elemento da matriz estará ocupado com um número que representará a
quantidade de pixels da amostra analisada, que pertencendo na imagem classificada a
classe que marca a sua coluna realmente a amostragem demonstrou que pertence a
classe que indica a sua linha.
A diagonal principal da matriz de confusão estará ocupada pelo número de pixels
corretamente classificada para cada classe da legenda.
Por outro lado, os elementos fora da diagonal principal correspondem a erros de
classificação.
Os elementos dentro da mesma linha pertenciam a uma determinada classe mas não
foram classificados corretamente. Este erro é do tipo I e se denomina erro de omissão.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Matriz de confusão
Os elementos fora da diagonal principal pertencentes a uma mesma coluna representam
os pixels da amostra que, foram classificados dentro de uma determinada classe mas
realmente pertencem a outra. Se trata de um erro tipo II ou seja erro de comissão.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Análise da Matriz de confusão
Medidas Globais de Confiança: a matriz de confusão é um modelo de uma tabela de
contingência a partir da qual podemos extrair informação quantitativa a respeito da
verificação da classificação.
A confiança global da imagem classificada se estima pela razão existente entre o número
de pixels corretamente classificados e o total de pixels amostrados.
Ou seja a confiança global é o quociente entre a soma dos pixels existentes na diagonal
principal da matriz de confusão e a soma de todos os elementos da matriz.
A este valor deveremos atribuir um intervalo de erro (±ε), calculado segundo a expressão
abaixo, para um determinado intervalo de confiança (1-α), obtendo-se:
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Análise da Matriz de confusão
Risco do usuário e do produtor: a soma dos resíduos por linhas constitui o
denominado erro de omissão, cujo cálculo para a classe i em termos relativos fica
definido como:
Da mesma maneira a soma dos resíduos por
colunas constitui o erro de comissão:
A expressão de ambos erros em termos percentuais se denominam risco do produtor e
risco do usuário, respectivamente.
Risco do produtor é a probabilidade de erro que o analista está cometendo em
consequência da não inclusão de alguns pixels em suas classes correspondentes
(omissão).
Risco do usuário é a probabilidade de um pixel classificado pelo usuário como sendo de
uma classe mas na realidade ele pertence a uma classe diferente (comissão).
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Análise da Matriz de confusão
Risco do usuário e do produtor:
Os complementares a 100 de ambos riscos serão as respectivas confianças, ou seja,
confiança do produtor:
confiança do usuário:
Análise categórico multivariante:
A classificação, supervisionada ou automática, estabelecerá uma designação de pixels a
cada classe da legenda de forma lógica e deverá produzir uma matriz de confusão com
maior confiança que aquela obtida por uma classificação aleatória ou ao azar.
Um dos índices mais utilizados na avaliação da qualidade da classificação é o kappa ()
que quantifica o nível de acerto explicado pelo método de classificação seguido, em
relação àquele obtido meramente pelo “azar” ou aleatório.
Colégio Politécnico da UFSM – DPADP0033 : Classificação Digital de Imagens (Prof. Dr. Elódio Sebem)
FERRAMENTAS ESTATÍSTICAS PARA ANÁLISE DA CLASSIFICAÇÃO
Análise da Matriz de confusão
Análise categórico multivariante:
Sendo:
O índice kappa se define como:
Este estimador adotará valores tanto mais próximos da unidade quanto maior seja o
ajuste seja significativamente melhor que aquele obtido por uma classificação aleatória.