Conceitos BDs, SBDs e SGBDs
Banco de dados é um conjunto de dados inter-relacionados, ordenados ou não, sobre um
determinado domínio. Os dados persistentes são aqueles que devem ir para o BD. Os
dados voláteis são só usados em programas. Quando tenho um procedimento para
acessar um banco de dados então tenho um Sistema de Banco de dados (ambiente para
recuperação e armazenamento de informações). Quando quero colocar esse sistema no
computador, então tenho um software que é o SGBD, que permite a definição de
estruturas para armazenamento de informações e fornecimento de mecanismos para
manipulação de dados.
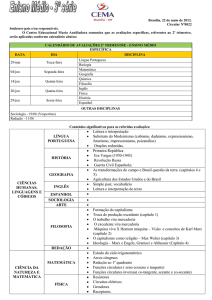
Contexto Horário de aula
Para a entidade aluno temos os atributos: RA (primary key), nome e ano de ingresso na
Universidade. A entidade disciplina têm os seguintes atributos: nome, número, horário,
professor, departamento e número máximo de faltas que um aluno pode ter.
O relacionamento entre eles (Aluno-Disciplina) possui cardinalidade 1 para n, partindo
do contexto de que se trata de um horário acadêmico um aluno, portanto um aluno pode
ter uma ou várias disciplinas (n).
Este relacionamento pode ter certos atributos, dependendo do contexto. Se estivermos
olhando o contexto de um ano letivo, podemos ter os atributos nota e número de faltas,
ou seja, os dois fatores relevantes para aprovação ou reprovação do aluno. Se
estivermos olhando o contexto do histórico escolar do aluno na Universidade, é
necessário um atributo ano, do qual podemos saber quais disciplinas foram feitas em
cada ano letivo.
A entidade disciplina têm um relacionamento com a entidade turma, que contém o
atributo número, (cada turma de uma respectiva matéria têm um número de
identificação), este então é a primary key. Este relacionamento possui um atributo sala,
pois para a mesma disciplina podem ter diferentes turmas e cada turma é alojada em
uma sala diferente, em um bloco diferente.
O relacionamento entre eles (Disciplina-Turma) possui cardinalidade n para 1, partindo
do contexto de que uma disciplina pode ter uma ou várias turmas e uma turma diz
respeito à somente uma disciplina.
Por fim temos o relacionamento entre aluno, disciplina e o curso ao qual eles estão
vinculados. O relacionamento Aluno-Curso possui cardinalidade 1 para n, onde um
aluno pode fazer parte de apenas um curso e um curso pode ter vários alunos, partindo
do contexto de que estamos falando de uma Universidade pública, como a Uem, que
não permite que um aluno faça mais de um curso ao mesmo tempo. O relacionamento
Disciplina-Curso tem cardinalidade n para n, ou seja, uma disciplina pode estar na
ementa de um ou mais cursos e um curso pode conter uma ou mais disciplinas.
Visões do Banco de Dados
a - Visão Interna - É aquela vista pelo responsável pela manutenção e desenvolvimento
do SGBD. Existe a preocupação com a forma de recuperação e manipulação dos
dados dentro do Banco de Dados.
b - Visão Conceitual - É aquela vista pelo analista de desenvolvimento e pelo
administrador das bases de dados. Existe a preocupação na definição de normas e
procedimentos para manipulação dos dados, para garantir a sua segurança e
confiabilidade, o desenvolvimento de sistemas e programas aplicativos e a
definição no banco de dados de novos arquivos e campos. Na visão conceitual,
existem 2 (duas) linguagens de operação que são:
a) Linguagem de definição dos dados (DDL) - Linguagem que define as aplicações,
arquivos e campos que irão compor o banco de dados (comandos de criação e
atualização da estrutura dos campos dos arquivos).
b) Linguagem de manipulação dos dados (DML) - Linguagem que define os
comandos de manipulação e operação dos dados (comandos de consulta e
atualização dos dados dos arquivos).
c - Visão Externa - É aquela vista pelo usuário que opera os sistemas aplicativos,
através de interfaces desenvolvidas pelo analista (programas), buscando o
atendimento de suas necessidades.
NORMALIZAÇÃO DE DADOS
Consiste em definir o formato lógico adequado para as estruturas de dados
identificados no projeto lógico do sistema, com o objetivo de minimizar o espaço
utilizado pelos dados e garantir a integridade e confiabilidade das informações.
A normalização é feita, através da análise dos dados que compõem as estruturas
utilizando o conceito chamado "Formas Normais (FN)". As FN são conjuntos de
restrições nos quais os dados devem satisfazê-las. Exemplo, pode-se dizer que a
estrutura está na primeira forma normal (1FN), se os dados que a compõem
satisfizerem as restrições definidas para esta etapa.
A normalização completa dos dados é feita, seguindo as restrições das quatro
formas normais existentes, sendo que a passagem de uma FN para outra é feita tendo
como base o resultado obtido na etapa anterior, ou seja, na FN anterior.
Para realizar a normalização dos dados, é primordial que seja definido um campo
chave para a estrutura, campo este que permite irá identificar os demais campos da
estrutura. Formas Normais existentes:
Primeira Forma Normal (1FN)
Consiste em retirar da estrutura os elementos repetitivos, ou seja, aqueles dados que
podem compor uma estrutura de vetor. Podemos afirma que uma estrutura está
normalizada na 1FN, se não possuir elementos repetitivos. Exemplo:
Estrutura original:
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Cod. do Cliente, Nome do
cliente, Endereço do cliente, CGC do cliente, Relação das mercadorias vendidas (onde
para cada mercadoria temos: Código da Mercadoria, Descrição da Mercadoria,
Quantidade vendida, Preço de venda e Total da venda desta mercadoria) e Total Geral
da Nota)
Analisando a estrutura acima, observamos que existem várias mercadorias em uma
única Nota Fiscal, sendo portanto elementos repetitivos que deverão ser retirados.
Estrutura na primeira forma normal (1FN):
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Código do Cliente, Nome
Cliente, Endereço do cliente, CGC do cliente e Total Geral da Nota)
Arquivo de Vendas (Num. NF, Código da Mercadoria, Descrição da Mercadoria,
Quantidade vendida, Preço de venda e Total da venda desta mercadoria)
Obs. Os campos sublinhados identificam as chaves das estruturas.
Como resultado desta etapa ocorre um desdobramento dos dados
estruturas, a saber:
em duas
- Primeira estrutura (Arquivo de Notas Fiscais): Dados que compõem a estrutura
original, excluindo os elementos repetitivos.
- Segundo estrutura (Arquivo de Vendas): Dados que compõem os elementos
repetitivos da estrutura original, tendo como chave o campo chave da estrutura original
(Num. NF) e o campo chave da estrutura de repetição (Código da Mercadoria).
Segunda Forma Normal (2FN)
Consiste em retirar das estruturas que possuem chaves compostas (campo chave
sendo formado por mais de um campo), os elementos que são funcionalmente
dependente de parte da chave. Podemos afirmar que uma estrutura está na 2FN, se ela
estiver na 1FN e não possuir campos que são funcionalmente dependente de parte da
chave. Exemplo:
Estrutura na primeira forma normal (1FN):
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Código do Cliente, Nome
do cliente, Endereço do cliente, CGC do cliente e Total Geral da Nota)
Arquivo de Vendas (Num. NF, Código da Mercadoria, Descrição da Mercadoria,
Quantidade vendida, Preço de venda e Total da venda desta mercadoria)
Estrutura na segunda forma normal (2FN):
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Código do Cliente, Nome
do cliente, Endereço do cliente, CGC do cliente e Total Geral da Nota)
Arquivo de Vendas (Num. NF, Código da Mercadoria, Quantidade vendida e Total
da venda desta mercadoria)
Arquivo de Mercadorias (Código da Mercadoria, Descrição da Mercadoria, Preço de
venda)
Como resultado desta etapa, houve um desdobramento do arquivo de Vendas (o
arquivo de Notas Fiscais, não foi alterado, por não possuir chave composta) em duas
estruturas a saber:
- Primeira estrutura (Arquivo de Vendas): Contém os elementos originais, sendo
excluídos os dados que são dependentes apenas do campo Código da Mercadoria.
- Segundo estrutura (Arquivo de Mercadorias): Contém os elementos que são
identificados apenas pelo Código da Mercadoria, ou seja, independentemente da Nota
Fiscal, a descrição e o preço de venda serão constantes.
Terceira Forma Normal (3FN)
Consiste em retirar das estruturas os campos que são funcionalmente dependentes
de outros campos que não são chaves. Podemos afirmar que uma estrutura está na 3FN,
se ela estiver na 2FN e não possuir campos dependentes de outros campos não chaves.
Exemplo:
Estrutura na segunda forma normal (2FN):
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Código do Cliente,
Nome do cliente, Endereço do cliente, CGC do cliente e Total Geral da Nota)
Arquivo de Vendas (Num. NF, Código da Mercadoria, Quantidade vendida e
Total da venda desta mercadoria)
Arquivo de Mercadorias (Código da Mercadoria, Descrição da Mercadoria, Preço
de venda)
Estrutura na terceira forma normal (3FN):
Arquivo de Notas Fiscais (Num. NF, Série, Data emissão, Código do Cliente e
Total Geral da Nota)
Arquivo de Vendas (Num. NF, Código da Mercadoria, Quantidade vendida e
Total da venda desta mercadoria)
Arquivo de Mercadorias (Código da Mercadoria, Descrição da Mercadoria, Preço
de venda)
Arquivo de Clientes (Código do Cliente, Nome do cliente, Endereço do cliente e
CGC do cliente)
Como resultado desta etapa, houve um desdobramento do arquivo de Notas
Fiscais, por ser o único que possuía campos que não eram dependentes da chave
principal (Num. NF), uma vez que independente da Nota Fiscal, o Nome, Endereço e
CGC do cliente são inalterados. Este procedimento permite evitar inconsistência nos
dados dos arquivos e economizar espaço por eliminar o armazenamento freqüente e
repetidas vezes destes dados. A cada nota fiscal comprada pelo cliente, haverá o
armazenamento destes dados e poderá ocorrer divergência entre eles.
As estruturas alteradas foram pelos motivos, a saber:
- Primeira estrutura (Arquivo de Notas Fiscais): Contém os elementos originais,
sendo excluído os dados que são dependentes apenas do campo Código do Cliente
(informações referentes ao cliente).
- Segundo estrutura (Arquivo de Clientes): Contém os elementos que são
identificados apenas pelo Código do Cliente, ou seja, independente da Nota Fiscal, o
Nome, Endereço e CGC dos clientes serão constantes.
Após a normalização, as estruturas dos dados estão projetadas para eliminar as
inconsistências e redundâncias dos dados, eliminando desta forma qualquer problema de
atualização e operacionalização do sistema. A versão final dos dados poderá sofrer
alguma alteração, para atender as necessidades específicas do sistema, a critério do
analista de desenvolvimento durante o projeto físico do sistema.
A Álgebra Relacional
É uma linguagem de consulta procedural. Os operadores da álgebra relacional recebem
uma ou duas relações como operandos e produzem uma nova relação como resultado.
Operações fundamentais da álgebra relacional são:
• seleção;
• projeção;
• produto cartesiano;
• união;
• diferença entre conjuntos.
Com estas operações fundamentais é possível exprimir qualquer consulta em álgebra
relacional.
Seleção
Seleciona tuplas (linhas) que satisfazem um dado predicado (uma condição lógica) nos
valores dos atributos.
Projeção
Copia a relação dada como argumento, deixando alguns atributos (colunas) de lado.
Pode ser entendida como uma operação que filtra as colunas de uma tabela. Por operar
sobre apenas um conjunto de entrada, a projeção é classificada como uma operação
unária.
Produto Cartesiano
Permite combinar informações de duas relações.Exemplo: Fornecedor X Produto:
O esquema resultante é a concatenação dos esquemas das duas relações
fornecidas como argumento.
(Cod_Forn,Nome,Cidade,Estado) C (Cod_Prod,Nome,Qualidade) = (
Fornecedor.Cod_Forn, Fornecedor.Nome, Fornecedor.Cidade, Fornecedor.Estado,
Produto.Cod_Prod, Produto.Nome, Produto.Qualidade )
As linhas são obtidas combinando-se cada linha da primeira tabela com
todas as linhas da segunda tabela.
União
Requer que as duas relações fonecidas como argumento tenham o mesmo esquema.
Resulta em uma nova relação, com o mesmo esquema, cujo conjunto de linhas é a união
os conjuntos de linhas das relações dadas como argumento.
Intersecção: A intersecção com B
Esta é uma operação adicional que produz como resultado uma tabela que contém, sem
repetições, todos os elementos que são comuns às duas tabelas fornecidas como
operandos. As tabelas devem ser união-compatíveis.
Diferença de Conjuntos
Requer que as duas relações fonecidas como argumento tenham o mesmo esquema.
Resulta em uma nova relação, com o mesmo esquema, cujo conjunto de linhas é o
conjunto de linhas da primeira relação menos as linhas existentes na segunda.
Junção: A |X| B
É uma operação que produz uma combinação entre as linhas de uma tabela com as
linhas correspondentes de outra tabela, sendo em princípio correspondente a uma
seleção pelos atributos de relacionamento sobre um produto cartesiano dessas tabelas:
Renomeação: r<novo_nome> ( A )
Esta operação unária, redefine o nome de uma tabela em um determinado contexto. É
útil para auto-relacionamentos, onde precisamos fazer a junção de uma tabela com ela
mesma, e nesse caso cada versão da tabela precisa receber um nome diferente da outra.
Divisão: A ¸ B
É uma operação adicional que produz como resultado a projeção de todos os elementos
da primeira tabela que se relacionam com todos os elementos da segunda tabela.
Ex.: queremos saber os nomes dos departamentos que possuem todos os cargos:
NmDepto, CdCargo ( depto |x| funcionário ) CdCargo ( cargo )
Atribuição: variável A
Permite que o conteúdo de uma tabela seja atribuído (colocado) em uma variável
especial, oferecendo a possibilidade de um tratamento até certo ponto algorítmico para
algumas seqüências de operações.