Estatística Aplicada e
Experimentação
J M Fernandes
Conceitos Básicos
• Definição de estatística:
• Tipos de variáveis
• Distribuição de probabilidades
Conceitos Básicos
• Estatística: A ciência de coletar, organizar
e interpretar dados
– Coleta de dados.
– Análise de dados - organizar e resumir os
dados destacando os pontos mais
importantes e mostrando a estrutura.
– Inferência e teoria da decisão – extrair a
informação embutida nos dados podendo ser
usada como guia nas próximas ações.
Conceitos Básicos
– População: O grupo inteiro de indivíduos que
queremos obter informação.
– Amostra: Uma parte da população que
queremos examinar para obter a informação.
– Tamanho da amostra: número de
observações em uma amostra.
– Inferência estatística: Tirar conclusões sobre
a população considerando a informação
obtida da amostra.
Conceitos Básicos
• Os dados contêm:
– Indivíduos : Objetos descrito pelos dados;
– Variável: qualquer característica de um indivíduo.
Uma variável pode assumir diferentes valores para
diferentes indivíduos.
– Uma variável categórica coloca o indivíduo em um
dos vários grupos de categoria.
– Uma variável quantitativa assume valores numéricos
para os quais é possível realizar operações
aritméticas como soma e média, por exemplo.
Tipos de dados
•
•
•
A interpretação das listas de números a olho é muito difícil. Ao invés disso,
nós deveríamos produzir um resumo verbal ou numérico e/ou usar
métodos gráficos para descrever os pontos principais dos dados.
O método mais apropriado dependerá da natureza dos dados.
Dados qualitativos ou categóricos
– nominais
• sexo: masculino, feminino
• classificação de fósseis
– ordinais
• salinidade: baixa, média, alta
• abundância: dominante, abundante, freqüente, ocasional, raro
•
Dados quantitativos ou numéricos:
– discretos
• número de ovos postos pela tartaruga marinha
• número de ataques de asma no ano passado
– contínuos
• volume, área, peso, massa
• velocidade de corrente
Distribuição das Variáveis
– Uma distribuição de variáveis indica que
valores a variável assume e com que
freqüência.
– Para uma variável categórica, distribuição:
categorias + contagem/percentagem para
cada categoria
– Para uma variável quantitativa, distribuição:
padrão de variação dos seus valores
Examinando a distribuição
• Padrão Geral
– Formato
• Técnicas gráficas para visualizar distribuições
–
–
–
–
Gráfico de Barra
Torta
Ramos e Folhas
Histograma
• Modas: picos na distribuição.
– Unimodal ou Bimodal
• Simétrica ou enviesada (direita/esquerda)?
Examinando a distribuição
– Centro
• Média
–
–
–
–
Fácil de calcular
Fácil de manipular algebricamente
Altamente influenciada por pontos for a do comum
Media não resistente
• Mediana
– Pode tomar tempo para calcular
– Mais resistente a influência de extremos
– robusta
• Moda, Média e Mediana
– Posição relativa para enviesada/simétrica distribuição.
– Qual usar?
Examinando a distribuição
– Dispersão
• Desvio Padrão e Variância
– Definição e cálculo
– Soma sempre 0
– Porque (n-1)?
• Quartils
– Definição e cálculo
– AIQ
– Regra para identificar extremos fora do comum
– Os cinco - números para resumo
– Boxplots (Diagramas de caixa)
– Comparação com histogramas e gráficos de ramos e folhas
Amplitude, AIQ, D.P.
Examinando a distribuição
• Desvios
• Fora do comum: Valores localizados for a do padrão
geral.
– AIQ pode ajudar a identificar pontos for a do comum
– Boxplots modificados
– Estratégias
• Detectar, investigar a causa, corrigir, ou eliminar,
ou dar especial atenção.
• Usar métodos mais resistentes como a mediana
para reduzir a influência de extremos for a do
comum.
Transformação Linear
• forma: X*=a+bX
• Seus efeitos no formato, centro e
dispersão
Análise Exploratória de Dados
• Uma Introdução ao R
Exemplo
y<-c(8,9,3,4,5,5,6,7,11,1,11,20,5,5,6,7,8,9,11,3)
Leitura de um arquivo de dados em formato
texto
Há dois comandos principais para ler uma base de dados
em formato texto: scan e read.table.
Normalmente, usa-se o comando scan quando a base de
dados contém os valores de uma única variável.
Para bases de dados multivariadas, contendo diversas
variáveis, o comando read.table é mais adequado pois
a estrutura dos dados lidos será a de uma matriz onde as
colunas representarão cada variável da base.
Exemplo
• dados<-read.table(“c:/stat_2007/dados/estatura.txt”,header=T)
• O argumento header=T, no comando acima,
serve para informar que o tipo de informação
que será lida tem um cabeçalho com o nome
das variáveis.
• Problema: Descrever estes dados numa tabela
de freqüências e representá-los graficamente
usando o R.
Comando sort
• Você pode ordenar a informação na base dados
usando o comando sort que rearruma as
informações de maneira ordenada. No caso
destes dados ele usa a ordem alfabética como
chave.
• Você ainda pode escolher se deseja ordem
crescente (default) ou decrescente,
acrescentando o argumento decreasing=T.
• sort(dados)
Salvando a área de trabalho do R
• Você pode salvar sua área de trabalho, caso
ainda vá trabalhar nela.
• Vamos fechar esta primeira aula salvando nosso
trabalho em um disquete.
• save.image(“a:/aulaR1.RData")
• Assim na próxima seção do R onde os mesmos
dados serão trabalhados, bastará executar o
comando
load(“a:/aulaR1.RData")
Distribuições Probabilísticas
Histograma
•
Um dos método mais comum de apresentação de dados numéricos é o histograma,
relacionado com o gráfico de barras para dados categóricos. As áreas dos
retângulos resultantes devem ser proporcionais à freqüência.
10
20
30
40
x <-rnorm(345,165,10)
hist(x, col="red",ylab="Frequência",main="Distribuição de altura entre os alunos")
0
Frequência
50
60
70
Distribuição de altura entre os alunos
130
140
150
160
170
x
180
190
200
Terminologia
• Um processo estocástico é descrito por
variáveis aleatórias e as suas distribuições
probabilísticas.
Variáveis aleatórias
O termo aleatório infere incerteza
Sejam E um experimento e S o espaço associado ao experimento.
Uma função X, que associe a cada elemento s S um número real
X(s) é denominada variável aleatória.X Variável Aleatórias X(s)SR
S
X
R
s
Variável
Aleatória
X(s)
Exemplo : E: lançamento de duas moedas;
X: nº de caras obtidas nas duas moedas;
S={(c,c), (c,r), (r,c),(r,r)}
X=0 corresponde ao evento (r,r) com probabilidade ¼
X=1 corresponde ao evento (r,c), (c,r) com probabilidade 2/4
X=2 corresponde ao evento (c,c) com probabilidade ¼.
Variáveis aleatórias
• Uma variável aleatória X, é uma etiqueta associada a
um evento aleatório A.
• Uma variável aleatória pode ser usada para descrever o
processo de rolar um dado não viciado e os possíveis
resultados (1,2,3,4,5,6). Uma outra variável aleatória
poderia descrever os possíveis resultado de escolher
uma pessoa ao acaso e determinar a altura.
• Diferente de variáveis matemáticas, uma variável
aleatória não pode ter designado um valor. É uma
função que traduz as possíveis saídas como números.
• Variáveis aleatórios tem a notação (X,Y,Z...)
• Valores específicos ou instâncias das variáveis
aleatórias assumem a notação (x,y,z....).
Variáveis aleatórias
• As variáveis aleatórias podem ser
categóricas ou discretas ou contínuas
• Uma variável discreta -> Distribuição de
probabilidade
• Uma variável contínua -> Função de
distribuição de probabilidades
Variáveis aleatórias e Distribuição
de Probabilidades
• Registrando todas as possibilidades de variável aleatória
X resulta na probabilidade de distribuição de X
Distribuição de Probabilidade
A distribuição de probabilidade de uma variável discreta
X é uma função que calcula a probabilidade p(xi)que a
variável aleatória seja igual a xi, para cada valor de xi:
p(xi)=P(X=xi)
Fx(X)
probabilidade da variável aleatória X assumir o valor de xi
Conceito de Probabilidade
Proporção de tempo onde espera-se que o
resultado seja conforme o desejado, antes
de realizar o experimento
Probabilidade de um evento=
Ocorrências/ total possível de ocorrências
Freqüência relativa
Proporção de tempo que um evento do
mesmo tipo irá ocorrer ao longo prazo
Probabilidade da variável aleatória
assumir um valor no intervalo
• Se y é discreto
Probabilidade Y assumir valores no
Intervalo de a e b
• Se y é contínuo
Densidade de probabilidade no
Intervalo de a e b
Distribuição Cumulativa de
Probabilidades
Se Y for discreto
Se Y for contínuo
Probabilidade de Y assumir qualquer valor menor
ou igual a y, para cada valor de y
Distribuição Cumulativa e Função
de Distribuição de Probabilidades
Exemplo:
Exemplo
• Caso discreto:
Distribuição de Probabilidade
xi
P(xi)
0
1/32
1
5/32
2
3
4
10/32 10/32 5/32
5
1/32
Distribuição Cumulativa de Probabilidade
xi
P(xi)
0
1/32
1
6/32
2
3
4
5
16/32 26/32 31/32 32/32
Exemplo
par(mfrow=c(2,1))
# DP
x1 <-c(1,5,10,10,5,1)
x1 <-x1/32
z <-barplot(x1,ylim=c(0,max(x1)*1.2),
col="red")
text(z,x1+.02,x1)
# FDP
x2 <-c(1,6,16,26,31,32)
x2 <-x2/32
z2 <-plot(x2,ylim=c(0,1),type="l",lwd=3,
col="red")
Esperança matemática de uma
variável aleatória
• As distribuições de probabilidade é geralmente
caracterizada um pequeno número de
parâmetros.
• Em geral é suficiente conhecer a “média”. Esta
pode ser obtida pelo conceito de esperança
matemática com a notação de E(X).
• Esperança matemática (ou simplesmente
média) - E (x) – é um número real, é também
uma média aritmética.
Esperança matemática de uma
variável aleatória
Média de um distribuição de probabilidades
Se as probabilidades de obter as quantidades
a1,a2,a3,..an são p1,p2,p3...pn
Então a esperança matemática é:
E(A)=a1p1+a2p2+a3p3...anpn
Uma média ponderada - onde os pesos são os
valores da probabilidade
Esperança matemática de uma
variável aleatória
Esperança matemática para o número de
caras obtida em três tentativas de rolar
uma moeda
As probabilidades de 0,1,2,3 caras são:
1/8,3/8,3/8,1/8
μ= 0*(1/8)+(1*3/8)+(2*3/8)+(3*1/8)=3/2
Esperança matemática de uma
variável aleatória
Discreto
Contínuo
Variância da distribuição de
probabilidade
A variância de uma variável aleatória (ou de
uma distribuição) é uma medida estatística da
dispersão, indicando como os possíveis valores
estão distribuídos ao redor do valor esperado.
Var(X)=E((X-E(X))2
O desvio padrão de uma variável aleatória ou
de uma distribuição de probabilidades é a raiz
quadrada de Var(X).
Enviezamento
Uma medida de assimetria da distribuição de
probabilidade.
Curtose
Uma medida de achatamento da
distribuição de probabilidade
Distribuições empíricas de
probabilidade
Um estimativa empírica de uma
distribuição de probabilidades é obtida da
amostragem dos dados
Distribuição teórica de probabilidades
Distribuição de Bernoulli
A distribuição de Bernoulli assume o valor
1 com probabilidade p e o valor 0 com
probabilidade q=1-p
População descrita por único parâmetro p
Descreve-se X~Be(p)
Distribuição Binomial
Uma distribuição discreta de probabilidades do número de sucessos
em uma seqüência de n eventos independentes do tipo sim/não, onde o
sucesso de cada um é determinado por uma probabilidade p
Premissas
Tem apenas duas possibilidades
A probabilidade de sucesso é mesma a cada tentativa
Existem n tentativas e n é uma constante
As n tentativas são independentes
p é a probabilidade de sucesso
1-p é a probabilidade de falha
Descreve-se X~Bin(n,p)
Distribuição Binomial
A esperança matemática é:
E(X)=np
A variância é:
Var(X)=np(1-p)
Para um valor elevado
de n, a distribuição Binomial
Se aproxima da distribuição
Normal
Distribuição Binomial
x<-0:10
y<-dbinom(0:10,10,0.16)
data.frame("Prob"=y,row.names=x)
Prob
0 1.749012e-01
1 3.331452e-01
2 2.855530e-01
3 1.450428e-01
4 4.834760e-02
5 1.105088e-02
6 1.754108e-03
7 1.909233e-04
8 1.363738e-05
9 5.772436e-07
10 1.099512e-08
plot(0:10,dbinom(0:10,10,0.16),,type='h',xlab="“,
ylab="Probabilidade", sub="Número de crianças
com olhos azuis")
Distribuição de Poisson
Expressa a probabilidade que um número de eventos
venham a ocorrer em um determinado período fixo de
tempo.
A probabilidade que existam exatamente m ocorrências
(m inteiro e positivo) é:
е a base do logaritmo natural (2,71828..), λ é um
número real positivo, equivalente ao número
esperado de ocorrências durante um certo intervalo.
Distribuição de Poisson
A esperança matemática de uma variável
aleatória na distribuição de Poisson é igual
a λ e, também a sua variância.
E(X)= λ
Var(X)= λ
Descreve-se X~Poisson(λ)
Distribuição de Poisson
A distribuição de Poisson surge com os
processos de Poisson
Vários fenômenos discretos que podem ocorrer 0,1,2,3
....vezes em um certo intervalo
• Número de carros que passam no pedágio
• Número de ligações telefônicas por hora
• Número de acessos no servidor por minuto
• Número de acidentes por unidade de comprimento da
estrada
• Número de chamadas no corpo de bombeiros
Distribuição de Poisson
Encontre a possibilidade de x sucessos
durante um intervalo de tempo T
Divida o intervalo em n partes de
comprimento Δt de maneira que:
T=n* Δt
Distribuição de Poisson
A medida que a média aumenta a distribuição
desloca-se para a direita e espalha-se
Distribuição de Poisson
# Distribuição de Poisson Lambda=2
x<-0:10
y<-dpois(0:10,0.2)
data.frame("Prob"=y,row.names=x)
Prob
0 8.187308e-01
1 1.637462e-01
2 1.637462e-02
3 1.091641e-03
4 5.458205e-05
5 2.183282e-06
6 7.277607e-08
7 2.079316e-09
8 5.198290e-11
9 1.155176e-12
10 2.310351e-14
plot(0:10, dpois(0:10,0.2), type='h',
xlab="Sequência de Erros",
ylab="Probabilidade")
plot(0:10,ppois(0:10,0.2),xlab="# Sequência de
Erros", ylab="Prob. Cumulativa", type='s')
Distribuição de Poisson
par(mfrow=c(2,2))
plot(0:10,dpois(0:10,0.5),xlab="",ylab="Prob”,
type='h',main="Lambda 0.5")
plot(0:10,dpois(0:10,1),xlab="",ylab="Prob",ty
pe='h',main="Lambda 1")
plot(0:10,dpois(0:10,2),xlab="",ylab="Prob",ty
pe='h',main="Lambda 2")
plot(0:10,dpois(0:10,5),xlab="",ylab="Prob",ty
pe='h',main="Lambda 5")
Distribuição Uniforme
Uma variável aleatória tem a mesma
probabilidade de assumir qualquer valor no
intervalo de a e b.
Descreve-se X~U(a,b)
Variável Aleatória Contínua
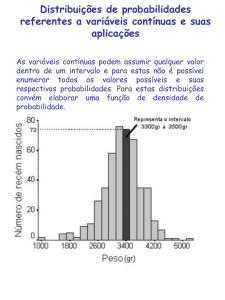
• Uma variável aleatória cujos valores são expressos em
uma escala contínua é dita uma variável aleatória
contínua.
• Podemos construir modelos teóricos para v.a.’s
contínuas escolhendo adequadamente a função de
densidade de probabilidade (f.d.p.), que é uma função
indicadora da probabilidade nos possíveis valores de X.
• Assim, a área sob a f.d.p. entre dois pontos a e b nos dá
a probabilidade da variável assumir valores entre a e b,
P(a<X<b)
a
b
Variável Aleatória Contínua
Portanto, podemos escrever:
b
P(a X b) f ( x)dx
a
Da relação entre a probabilidade e a área
sob a função, a inclusão ou não dos
extremos a e b na expressão acima não
afetará os resultados. Assim, iremos admitir
Teoricamente, qualquer função f(x) que seja
não negativa e cuja área total sob a curva
seja igual à unidade, ou seja,
caracterizará uma v.a. contínua.
Dada a v.a. contínua X, assumindo os
valores no intervalo entre a e b, chamamos
valor médio ou esperança matemática de
X ao valor
P ( a X b) P ( a X b) P ( a X b) P ( a X b)
f ( x)dx 1
b
E ( X ) x f ( x)dx
a
Variável Aleatória Contínua
Chamamos variância de
X ao valor
Var ( X ) E ( X 2 ) [ E ( X )]2
onde
b
E ( X ) x 2 f ( x)dx
2
a
e de desvio padrão de X
a
Se X é uma v.a. contínua
com f.d.p. f(x) definimos a
sua função de
distribuição acumulada
F(x) como:
DP( X ) Var( X )
x
F ( x) P( X x)
f (t )dt
Distribuição Normal
– formato
• Simétrica ao redor da média;
• Unimodal;
• Formato de sino.
– centro e dispersão
– A regra 68-95-99.7
Distribuição Normal
• Padronização e Escore-z
– Efeitos da padronização
• Padronização é uma transformação linear.
• Os valores padronizados de uma distribuição tem
média igual a zero e desvio padrão 1.
• Efeitos no formato, centro e dispersão.
– Transformação Linear: normal em normal.
Distribuição Normal
• Distribuição Normal Padrão
X
Z
• Tabela de Escores-z
• Cálculo da probabilidade
Distribuição Normal
A distribuição normal ou gaussiana é extremamente
importante para vários ramos da ciência. Representa uma
família de distribuições com um formato similar variando
nos parâmetros média (localização) e desvio padrão
(forma).
Descreve-se X~N(μ,σ)
Distribuição Normal
A distribuição normal é a mais importante das distribuições de probabilidades.
Conhecida como a “curva em forma de sino”, a distribuição normal tem sua origem
associada aos erros de mensuração. É sabido que, quando se efetuam repetidas
mensurações de determinada grandeza com um aparelho equilibrado, não se chega
ao mesmo resultado todas as vezes; obtém-se, ao contrário, um conjunto de valores
que oscilam, de modo aproximadamente simétrico, em torno do verdadeiro valor.
Construindo-se o histograma desses valores, obtém-se uma figura com forma
aproximadamente simétrica. Gauss deduziu matematicamente a distribuição normal
como distribuição de probabilidade dos erros de observação, denominando-a então
“lei normal dos erros”.
Inicialmente se supunha que todos os fenômenos da vida real devessem ajustar-se a
uma curva em forma de sino; em caso contrário, suspeitava-se de alguma
anormalidade no processo de coleta de dados. Daí a designação de curva normal.
A observação cuidadosa subseqüente mostrou, entretanto, que essa pretensa
universalidade da curva, ou distribuição normal, não correspondia à realidade. De
fato, não são poucos os exemplos de fenômenos da vida real representados por
distribuições não normais, curvas assimétricas, por exemplo. Mesmo assim, a
distribuição normal desempenha papel preponderante na estatística, e os processos
de inferência nela baseados têm larga aplicação.
Distribuição Normal
x<-seq(-10,10,
length=100)
plot(x,dnorm(x,0,1),
xlab="x", ylab="f(x)",
type='l', main="FDP
Normal")
Distribuição Normal
x<-seq(-10,10, length=100)
par(mfrow=c(2,1))
plot(x,dnorm(x,0,2),xlab="x“,
ylab="f(x)", type='l',
main="Normal FDP,scale 2")
plot(x,dnorm(x,0,5),xlab="x",
ylab="f(x)",type='l',
main="Normal FDP,scale 5")