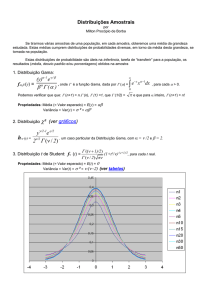
86
VARIÁVEIS ALEATÓRIAS CONTÍNUAS
Vamos agora estudar algumas variáveis aleatórias contínuas
e respectivas propriedades, nomeadamente:
•
•
•
•
•
•
uniforme
exponencial
normal
qui-quadrado
t-student
F
DISTRIBUIÇÃO UNIFORME
Considere-se que a função densidade de probabilidade de
uma v.a. contínua X, é constante num dado intervalo limitado
[a, b] e nula fora desse intervalo. Nestas condições, a
probabilidade de X tomar valores num dado sub-intervalo de
[a, b] é a mesma para sub-intervalos de igual amplitude.
Diz-se que a v.a. contínua X tem distribuição uniforme no
intervalo [a, b], e escreve-se: X ~ U(a,b) se a sua função
densidade de probabilidade for dada por:
1
b−a
fX ( x ) =
0
a≤x≤b
outros valores
87
Os parâmetros que caracterizam esta distribuição são a e b e
satisfazem − ∞ < a < b < + ∞ .
A função de distribuição de X, FX ( x ) , é dada por:
0
FX ( x ) = ∫ f u ( u ) du = ( x − a ) / ( b − a )
−∞
1
x
x<a
a≤x≤b
x>b
Graficamente temos então que:
O valor esperado e a variância para esta v.a. são facilmente
obtidos a partir da definição e são dados por:
+∞
b
−∞
a
E ( X ) = ∫ x ⋅ f X ( x ) dx = ∫ x ⋅
( )
E X
2
+∞
1
a+b
dx = ... =
b−a
2
1
b3 − a 3
= ∫ x ⋅ f X ( x ) dx = ∫ x ⋅
dx = ... =
b
−
a
3⋅ ( b − a )
−∞
a
2
( )− [ E( X )]
Var ( X ) = E X
2
b
2
2
=
( b − a )2
12
88
Relativamente à função geradora de momentos temos que:
( )=
GX ( t ) = E e
t⋅x
+∞
∫ e
−∞
e b⋅t − e a ⋅t
=
( b − a )⋅ t
t ⋅x
b
1
f X ( x ) dx =
⋅ ∫ e t ⋅ x dx
(b − a ) a
(t≠0) ∧ G X ( 0 ) = 1
DISTRIBUIÇÃO EXPONENCIAL
A distribuição exponencial está intimamente relacionada com
a distribuição de Poisson. Efectivamente, admitindo que λ é
o parâmetro da distribuição de Poisson que descreve o
número de ocorrências por unidade de tempo (ou de
distância), a variável tempo (ou distância) entre ocorrências
sucessivas segue uma distribuição exponencial com
parâmetro λ.
Diz-se que a v.a. contínua X tem distribuição exponencial e
escreve-se: X ~ E(λ) se a sua função densidade de
probabilidade for dada por:
λ ⋅e −λ⋅x
fX ( x ) =
0
x≥0
x<0
O parâmetro que caracteriza esta distribuição é λ (λ>0).
89
A função de distribuição de X, FX ( x ) , é dada por:
1 − e −λ⋅x
FX ( x ) = ∫ f u ( u ) du =
0
0
x
x≥0
x<0
O valor esperado e a variância para esta v.a. são facilmente
obtidos a partir da definição e são dados por:
+∞
+∞
−∞
0
E ( X ) = ∫ x ⋅ f X ( x ) dx = ∫ x ⋅ λ ⋅ e − λ ⋅ x dx = ... =
( )=
E X
2
+∞
+∞
1
λ
2
−λ⋅x
dx = ... =
∫ x ⋅ f X ( x ) dx = ∫ x ⋅ λ ⋅ e
2
−∞
0
( )
Var ( X ) = E X 2 − [ E ( X ) ] 2 =
2
λ2
1
λ2
Relativamente à função geradora de momentos temos que:
( )=
GX ( t ) = E e
t⋅x
+∞
∫ e
−∞
t⋅x
+∞
f X ( x ) dx = ∫ λ ⋅ e − x ⋅ ( λ − t ) dx
0
+∞
λ
= −
⋅ e − x ⋅( λ − t )
λ−t
0
=
λ
λ−t
, t<λ
90
A distribuição exponencial apresenta uma propriedade
particular que é a de “ não possuir memória”, isto é, dados
s,t>0, quaisquer:
P ( X > s + t ) e − λ ⋅( s + t )
− λ⋅t
P ( X >s + t X >s ) =
=
=
e
P( X >s )
e − λ ⋅s
= P( X >t )
DISTRIBUIÇÃO NORMAL
A distribuição normal (ou distribuição de Gauss) é a que se
utiliza mais frequentemente para descrever fenómenos que se
traduzem por variáveis aleatórias contínuas. A razão para
este facto, prende-se com o enunciado do teorema do limite
central, como veremos mais adiante.
A distribuição normal desempenha também um papel muito
importante na inferência estatística.
Diz-se que a v.a. contínua X tem distribuição normal e
escreve-se: X ~ N(µ, σ 2 ) se a sua função densidade de
probabilidade for dada por:
fX ( x ) =
1
⋅e
2 π ⋅σ
x −µ
− 1 ⋅
2 σ
2
,
−∞ < x < +∞
Os parâmetros que caracterizam esta distribuição são µ e σ 2 e
satisfazem: − ∞ < x < + ∞ e σ > 0.
91
Pode demonstrar-se que:
• f X ( x ) é uma função densidade de probabilidade, isto
+∞
é:
∫ f X ( x ) dx = 1
(demonstração...)
−∞
• A função densidade de probabilidade de uma v.a.
X~N(µ, σ 2 ) tem a forma de sino, é simétrica em relação
ao eixo x = µ (ponto de máximo) e tem pontos de
inflexão em x = µ ± σ.
•
A função densidade de probabilidade genérica da
distribuição normal representa uma família de
distribuições em que cada elemento específico dessa
família é representado por determinados valores dos
parâmetros µ e σ.
Neste caso temos distribuições normais com a mesma
média µ e diferentes valores do desvio padrão
(σ1>σ2>σ3).
92
Na figura acima temos distribuições normais com o
mesmo desvio padrão σ, mas com médias diferentes
(µ1>µ2>µ3).
Neste último caso as distribuições têm diferentes
valores para a média (µ1>µ2>µ3) e para o desvio padrão
(σ1>σ2>σ3).
x
• A função de distribuição FX ( x ) = ∫ f ( u ) du não é
−∞
integrável analiticamente, só podendo ser calculada por
processos numéricos.
93
O valor esperado e a variância para esta v.a. podem ser
obtidos a partir da definição e são dados por:
E( X ) =
+∞
1
∫ x⋅ e
2 π ⋅σ − ∞
x −µ
− 1 ⋅
2 σ
2
dx
fazendo z = (x - µ)/σ temos que dx = σdz e substituindo
no integral anterior vem que:
E( X ) =
1
2π
+∞
− 1 ⋅z2
⋅e 2
∫ ( σ⋅z + µ )
−∞
dz
+∞
+ ∞ − ⋅z
− ⋅z
1
1
⋅σ⋅ ∫ z ⋅ e 2
dz + µ ⋅
⋅ ∫ e 2
dz
2π
2
π
−∞
−∞
1 2
=
1 2
=0
=1
O primeiro integral é nulo pois o integrando é uma função
ímpar. O segundo integral assinalado é igual à unidade
porque representa a área total sob a fdp de uma v.a. normal
com valor médio nulo e desvio padrão unitário.
Então podemos concluir que:
E( X ) = µ
Seguindo um procedimento análogo temos agora:
( )=
E X
2
+∞
1
2
∫ x ⋅e
2 π ⋅σ −∞
x −µ
− 1 ⋅
2 σ
2
dx
94
+ ∞ − ⋅z
1 + ∞ 2 − 2 ⋅z
1
2
2
=σ ⋅
dz + µ ⋅
⋅ ∫ e 2
dz +
∫ z ⋅e
2 π −∞
2π −∞
1 2
=1
1 2
=1
− ⋅z
1 +∞
dz
+ 2⋅ µ⋅ σ⋅
∫ z⋅ e 2
2 π −∞
1 2
=0
= σ2 + µ 2
( )
Var ( X ) = E X 2 − [ E ( X ) ] 2 = σ2
Constatamos assim que os dois parâmetros que caracterizam
a distribuição normal são o valor esperado e a variância de X.
Relativamente à função geradora de momentos temos que:
( )=
GX ( t ) = E e
t ⋅x
µ ⋅ t + 1 ⋅ ( t ⋅ σ )2
2
=e
( demonstração ...)
+∞
1
t⋅x
∫ e ⋅e
2 π ⋅σ −∞
x −µ
− 1 ⋅
2 σ
2
dx
95
TEOREMA: Se X ~ N(µ, σ ) e se Y = a ⋅ X + b , então a v.a.
2
Y terá distribuição N(aµ + b, a 2 σ 2 ).
(demonstração:...)
X−µ
, então a v.a.
σ
COROLÁRIO: Se X ~ N(µ, σ ) e se Y =
2
Y terá distribuição N(0,1).
Se X tiver distribuição N(0,1), diz-se que X é uma variável
normal reduzida (ou padronizada). Neste caso a sua fdp é
dada por:
f X ( x ) = ϕX ( x ) =
1
− ⋅x
1
⋅e 2
2π
2
−∞ < x < +∞
,
então:
P(a ≤ X ≤ b ) =
1
2
1 b − 2⋅x
dx
∫ e
2π a
porém este integral não pode ser calculado analiticamente,
pelo que se tem que recorrer a métodos de integração
numérica. Contudo, a função de distribuição da v.a. normal
reduzida, habitualmente representada por Φ X ( x ) está
tabelada, pelo que pode ser utilizada para calcular a
probabilidade pretendida.
96
Efectivamente:
ΦX ( u ) =
pelo que:
1
2
u − ⋅x
1
dx
∫ e 2
2 π −∞
P ( a ≤ X ≤ b ) = ΦX ( b ) − ΦX ( a )
É também evidente da definição de Φ X ( x ) , que:
ΦX ( − x ) = 1 − ΦX ( x )
A importância da distribuição normal reduzida resulta de ser
possível utilizar a sua função de distribuição (tabelada), para
calcular probabilidades associadas a uma qualquer variável
aleatória com distribuição normal N(µ, σ 2 ).
X−µ
De facto, se X ~ N(µ, σ 2 ) então fazendo Z =
, temos
σ
que Z~N(0,1) e então:
a −µ
b−µ
P ( a ≤ X ≤ b ) = P
≤Z≤
σ
σ
b−µ
a −µ
= φ Z
− φZ
σ
σ
97
Finalmente, vamos calcular P ( µ − k ⋅ σ ≤ X ≤ µ + k ⋅ σ ) sendo
X ~ N(µ, σ 2 ) e k ≥ 0:
X−µ
P ( µ − k ⋅ σ ≤ X ≤ µ + k ⋅ σ ) = P − k ≤
≤ k
σ
= ΦZ ( k ) − ΦZ ( − k ) = 2⋅ΦZ ( k ) − 1
Esta probabilidade é independente de µ e de σ, isto é, a
probabilidade de que uma v.a. com distribuição N(µ, σ 2 )
tome valores até k desvios padrões do valor esperado,
depende somente de k e pode ser calculada pela expressão
anterior.
Na figura acima estão indicados valores aproximados para a
probabilidade indicada anteriormente para k = 1,2,3.
98
COMBINAÇÃO LINEAR V.A. NORMAIS INDEPENDENTES
A distribuição Normal tem uma importante propriedade que
se traduz no teorema seguinte.
TEOREMA: Sejam n variáveis aleatórias independentes X i ,
i=1,2,...,n em que:
(
X i ~ N µi , σi2
)
então, a v.a. T definida como:
n
T = ∑ a i ⋅ Xi
i =1
terá a seguinte distribuição:
n
T ~ N ∑ a i ⋅ µi ;
i =1
2 2
a
∑ i ⋅ σi
i =1
n
A demonstração deste teorema pode fazer-se recorrendo à
função geradora de momentos e afirma que: qualquer
combinação linear de v.a. Normais independentes é ainda
uma v.a. com distribuição Normal.
RELAÇÃO ENTRE DISTRIBUIÇÃO NORMAL E BINOMIAL
Quando foi estudada a distribuição binomial constatou-se
que para p = 0,5 , a distribuição era simétrica, qualquer que
fosse o valor de n. Verificou-se também que , mesmo para
valores de p≠0,5 , se o valor de n fosse grande, a distribuicão