Arquitetura de Sistemas Operacionais
1. Histórico ............................................................................................................
3
2. Tipos de Sistemas Operacionais
.....................................................................
2.1 Sistemas Monoprogramáveis .....................................................................
2.2 Sistemas Multiprogramáveis .....................................................................
2.2.1 Sistemas Batch
.....................................................................
2.2.2 Sistemas de Tempo Compartilhado
........................................
2.2.3 Sistemas de Tempo Real ...........................................................
2.3 Sistemas Multiprocessados .....................................................................
4
4
5
6
7
7
8
3. Sistemas Multiprogramáveis ...............................................................................
3.1 Tratamento de Interrupções e Exceções ..................................................
3.2 Buffer
...................................................................................................
3.3 Spool
...................................................................................................
3.4 Reentrância
.........................................................................................
3.5 Segurança e Proteção do Sistema ............................................................
3.6 Operações de E/S
................................................................................
10
11
12
12
13
14
17
4. Estrutura do Sistema Operacional
......................................................................
4.1 Estrutura do Sistema ................................................................................
4.2 Funções do Sistema ................................................................................
4.3 System Calls
..........................................................................................
4.4 Modos de Acesso
................................................................................
4.5 Arquiteturas: Sistemas monolíticos, em camadas e microkernel ......................
17
17
18
19
20
21
5. PROCESSO
....................................................................................................
5.1 Componentes do processo .......................................................................
5.2 Estados do processo .................................................................................
5.3 Mudanças de estado .................................................................................
5.4 Tipos de processo
.................................................................................
24
24
26
27
28
6. Gerência do Processador
........................................................................................
6.1 Funções .............................................................................................................
6.2 Critérios de Escalonamento .............................................................................
6.3 Escalonamentos Não-Preemptivos e Preemptivos
...................................
29
29
29
30
7. Gerência de Memória / Memória Virtual
...................................................................
7.1 Introdução
...................................................................................................
7.2 Funções ..............................................................................................................
7.3 Alocação Contígua Simples ..............................................................................
7.4 Segmentação de programas ..............................................................................
34
34
34
34
35
1
7.5 Alocação Particionada Estática Absoluta e Relocável ....................................
7.6 Alocação Particionada Dinâmica
...................................................................
7.7 Estratégias de Alocação de Partição
........................................................
7.8 Swapping
...................................................................................................
7.9 Memória Virtual ...................................................................................................
7.10 Algoritmos de substituição de páginas
........................................................
36
38
39
39
40
43
8. Gerência de sistemas de Arquivos ..............................................................................
8.1 Estrutura de diretórios .........................................................................................
8.2 Sistemas de alocação de arquivos ....................................................................
8.3 Gerência de espaço livre
...............................................................................
8.4 Proteção de acesso ..........................................................................................
45
45
45
46
47
9. BIBLIOGRAFIA ...............................................................................................................
48
2
1. Histórico
Antes da década de 50, os computadores eram muito difíceis de serem programados. Era
necessário conhecer totalmente sua arquitetura, e tal operação era efetuada em painéis com
cerca de 6.000 conectores, em linguagem de máquina. Nesta fase os computadores não
possuíam ainda dispositivos para interagir com o usuário, como teclados e monitores.
Na década de 50, já com a utilização de transistores, sucedeu-se um grande avanço
tecnológico, melhorando a velocidade dos processadores e a capacidade dos meios de
armazenamento, em especial a memória e os discos magnéticos.
Por volta de 1953 foi introduzido o primeiro sistema operacional, um programa de
controle que permitia uma interação, mesmo que limitada, entre o operador e a máquina,
otimizando a execução das tarefas. Em 1959 foi criada uma versão de sistema operacional que
já implementava conceitos de memória virtual, conceito este largamente utilizado nos sistemas
atuais.
Na década de 60, a partir do surgimento dos circuitos integrados, foi possível difundir u
uso de sistemas computacionais em empresas, com diminuição de custos e tamanho dos
equipamentos. Além disso, esta década presenciou inúmeras inovações na área de sistemas
operacionais, presentes até hoje, como os ambientes de multitarefa, multiprogramação,
multiprocessamento e time-sharing, tendo o desenvolvimento destas técnicas avançado até o
meado da década de 70, onde também foram implementadas as tecnologias baseadas em
arquitetura VLSI (chips), as primeiras redes de computadores, e o desenvolvimento de diversas
linguagens de programação de alto nível.
A década de 80 foi marcada pela criação dos microcomputadores, baseados em
microprocessadores de uso pessoal. Liderados pela IBM, diversos fabricantes seguiram por essa
linha, porém alguns deles não abandonando a fabricação dos computadores de grande porte,
como foi o caso da própria IBM.
Nota-se que, a partir do meado da década de 80, acontece uma divisão de águas, com a
indústria passando a produzir equipamentos de grande porte e muitos modelos de
microcomputadores, que também precisavam de sistemas operacionais bastante evoluídos.
Foram, então, utilizadas as técnicas modernas já existentes nos ambientes de grande porte na
implementação de sistemas operacionais para os microcomputadores, com versões diversas,
todas inicialmente monousuário/monotarefa (devido à baixa capacidade de armazenamento dos
micros, naquela época). Com o avanço da tecnologia, os micros ganharam discos rígidos e
outros periféricos, possibilitando a criação de sistemas operacionais mais evoluídos nesta
categoria de computadores, quando surgiram os sistemas monousuário/multitarefa, que
executam até hoje.
3
Cronologia
Grande porte (mainframes)
1990
1950
1960
1º Sistema Operacional
Monoprogramável
Monotarefa
1970
Sistemas
Multitarefa
1980
Sistemas
Multiprogramáveis
Multitarefa
Introduzido o
conceito de
Memória Virtual
Microcomputadores
2. Tipos de Sistemas Operacionais
Tipos de
Sistemas Operacionais
Sistemas
Monoprogramáveis/
Monotarefa
2.1
Sistemas
Multiprogramáveis/
Multitarefa
Sistemas
Com Múltiplos
Processadores
Sistemas Monoprogramáveis/Monotarefa
Os primeiros sistemas operacionais eram voltados tipicamente para a execução de um
único programa. Qualquer outra aplicação, para ser executada, deveria aguardar o término do
programa corrente. Neste tipo de sistema, o processador, a memória e os periféricos
permanecem exclusivamente dedicados à execução de um único programa.
Os sistemas monoprogramáveis estão diretamente ligados ao surgimento, na década de
50/60, dos primeiros computadores. Embora os sistemas operacionais já tivessem evoluído com
as tecnologias de multitarefa e multiprogramáveis, os sistemas monoprogramáveis voltaram a
ser utilizados na plataforma de microcomputadores pessoais e estações de trabalho devido à
baixa capacidade de armazenamento destas máquinas, na época.
4
Era muito clara a desvantagem deste tipo de sistema, no que diz respeito à limitação de
tarefas (uma de cada vez), o que provocava um grande desperdício de recursos de hardware.
_______
_______
_______
_______
_______
CPU
Memória
Principal
Dispositivos E/S
Programa/Tarefa
Sistema Monoprogramável/Monotarefa
Comparados a outros sistemas, os monoprogramáveis são de simples implementação,
não existindo muita preocupação com problemas decorrentes do compartilhamento de recursos
como memória, processador e dispositivos de E/S.
2.2
Sistemas Multiprogramáveis/Multitarefa
Constituindo-se uma evolução dos sistemas monoprogramáveis, neste tipo de sistema os
recursos computacionais são compartilhados entre os diversos usuários e aplicações: enquanto
um programa espera por um evento, outros programas podem estar processando neste mesmo
intervalo de tempo. Neste caso, podemos observar o compartilhamento da memória e do
processador. O sistema operacional se incumbe de gerenciar o acesso concorrente aos seus
diversos recursos, como processador, memória e periféricos, de forma ordenada e protegida,
entre os diversos programas.
As vantagens do uso deste tipo de sistema são a redução do tempo de resposta das
aplicações, além dos custos reduzidos devido ao compartilhamento dos recursos do sistema
entre as diferentes aplicações. Apesar de mais eficientes que os monoprogramáveis, os sistemas
multiprogramáveis são de implementação muito mais complexa.
5
_______
_______
_______
_______
_______
_______
_______
_______
_______
_______
CPU
Programa/Tarefa
Programa/Tarefa
Memória
Principal
_______
_______
_______
_______
_______
Dispositivos E/S
_______
_______
_______
_______
_______
Programa/Tarefa
Programa/Tarefa
Sistema Multiprogramável/Multitarefa
Os sistemas multiprogramáveis/multitarefa podem ser classificados de acordo com a
forma com que suas aplicações são gerenciadas, podendo ser divididos em sistemas batch, de
tempo compartilhado e de tempo real, de acordo com a figura abaixo.
Sistemas
Multiprogramáveis/
Multitarefa
Sistemas BATCH
2.2.1
Sistemas de
Tempo Compartilhado
Sistemas de
Tempo Real
Sistemas BATCH
Foram os primeiros sistemas multiprogramáveis a serem implementados na década de 60.
Nesta modalidade, os programas eram submetidos para execução através de cartões perfurados
e armazenados em disco ou fita, para posterior execução. Vem daí o nome batch (lote de
cartões). O processamento em batch tem como característica não exigir interação do usuário
com o sistema ou com a aplicação. Todas as entradas ou saídas são implementadas por meio de
algum tipo de memória secundária, geralmente disco ou fita. Aplicações deste tipo eram
utilizadas em cálculo numérico, compilações, back-ups, etc.
6
Estes sistemas, se bem projetados, podem ser bastante eficientes devido à melhor
utilização do processador, mas podem oferecer tempos de resposta bastante longos.
Atualmente, os sistemas operacionais simulam este tipo de processamento, não havendo
sistemas dedicados a este tipo de execução.
2.2.2
Sistemas de Tempo Compartilhado
Também chamados sistemas de time-sharing, permitem que diversos programas sejam
executados a partir da divisão de tempo do processador em pequenos intervalos, denominados
fatia de tempo (ou time-slice). Caso a fatia de tempo não seja suficiente para a conclusão do
programa, este é interrompido pelo sistema operacional e substituído no processador por outro,
enquanto aguarda nova fatia de tempo. Neste tipo de processamento, cada usuário tem a
impressão de que a máquina está dedicada ao seu programa, como se ele fosse o único usuário
a se utilizar do sistema.
Geralmente permitem interação do usuário com a aplicação através de terminais
compostos por monitor, teclado e mouse. Estes sistemas possuem uma linguagem de controle
que permite ao usuário interagir com o sistema operacional através de comandos. Assim, é
possível verificar arquivos armazenados em disco ou cancelar execução de programas.
Normalmente, o sistema responde em apenas alguns segundos à maioria destes comandos, o
que se levou a chamá-los também de sistemas on-line.
A maioria das aplicações comerciais atualmente é processada em ambiente de tempo
compartilhado, que oferece tempos baixos de respostas a seus usuários e menores custos, em
função do alto grau de compartilhamento dos diversos recursos do sistema.
2.2.3
Sistemas de Tempo Real
Este tipo de sistema é implementado de forma bastante semelhante ao de tempo
compartilhado. O que caracteriza a diferença entre eles é o tempo exigido no processamento
das aplicações.
Enquanto nos sistemas de tempo compartilhado o tempo de processamento pode variar
sem comprometer as aplicações em execução, nos sistemas de tempo real os tempos de
execução devem estar dentro de limites rígidos, que devem ser obedecidos, caso contrário
poderão ocorrer problemas irreparáveis.
No sistema de tempo real não existe a idéia de fatia de tempo como nos sistemas de
tempo compartilhado. Um programa ocupa o processador o tempo que for necessário ou até
que apareça um outro com um nível de prioridade maior. Esta prioridade de execução é definida
pela própria aplicação e não pelo sistema operacional, como nos sistemas de tempo
compartilhado.
7
Estes sistemas são utilizados em aplicações de controle de processos, como
monitoramento de refinarias de petróleo, controle de tráfego aéreo, de usinas, ou em qualquer
aplicação onde o tempo de processamento é fator fundamental.
2.3
Sistemas com Múltiplos Processadores
Os sistemas com múltiplos processadores caracterizam-se por possuir duas ou mais CPUs
interligadas e trabalhando em conjunto. A vantagem deste tipo de sistema é permitir que
vários programas sejam executados ao mesmo tempo ou que um mesmo programa seja
subdividido em várias partes para serem executadas simultaneamente em mais de um
processador.
Esta técnica permitiu a criação de sistemas computacionais voltados para processamento
científico, prospecção de petróleo, simulações, processamento de imagens e CAD.
Um fator chave no desenvolvimento dos sistemas multiprocessados é a forma de
comunicação entre as CPUs e o grau de compartilhamento da memória e dos dispositivos de
E/S. Em função destes fatores, podemos classificar os sistemas multiprocessados de acordo com
a figura a seguir:
Sistemas
com
Múltiplos
Processadores
Sistemas
Fortemente
Acoplados
Simétricos
Sistemas
Fracamente
Acoplados
Assimétricos
Redes
Distribuídos
Tipos de Sistemas com Múltiplos Processadores
Na figura podemos perceber a divisão dos sistemas multiprocessados em duas categorias
iniciais: sistemas fortemente acoplados e fracamente acoplados. A grande diferença entre
estas duas categorias é que nos sistemas fortemente acoplados existe apenas uma memória
8
a ser compartilhada pelos processadores do conjunto, enquanto que nos fracamente
acoplados cada sistema tem sua própria memória individual. A taxa de transferência entre
processadores e memória em sistemas fortemente acoplados é muito maior que nos
fracamente acoplados.
Nos sistemas fortemente acoplados a memória principal e os dispositivos de E/S são
gerenciados por um único sistema operacional. Quando todos os processadores na
arquitetura são iguais, diz-se que o sistema é simétrico. No entanto, quando os
processadores são diferentes, dá-se à arquitetura a denominação assimétrica.
Nos sistemas fracamente acoplados, como os processadores estão em arquiteturas
diferentes, somente interligados por cabos de interconexão, cada CPU constitui uma máquina
independente, com memória própria, dispositivos de E/S e sistemas operacionais
independentes.
Nesta subdivisão, temos como exemplo as redes e os sistemas distribuídos.
No ambiente de rede, existem dois ou mais sistemas independentes (hosts), interligados
por linhas telefônicas, que oferecem algum tipo de serviço aos demais, permitindo que um
host compartilhe seus recursos, como impressora e diretórios, com os outros hosts da rede.
Enquanto nos sistemas em rede os usuários têm conhecimento dos hosts e seus serviços,
nos sistemas distribuídos os sistema operacional esconde os detalhes dos hosts individuais e
passa a tratá-los como um conjunto único, como se fosse um sistema só, fortemente
acoplado. Os sistemas distribuídos permitem, por exemplo, que uma aplicação seja dividida
em partes e que cada parte seja executada por hosts diferentes na rede. Para os usuários e
suas aplicações é como se não existisse a rede, mas um único sistema centralizado.
Outros exemplos de sistemas distribuídos são os clusters. Em um cluster podem existir
dois ou mais servidores ligados por algum tipo de conexão de alto desempenho, e o usuário
não conhece os nomes dos membros do cluster e nem quantos são. Quando é necessário
algum serviço, basta solicitar ao cluster para obtê-lo, sem se preocupar com quem vai dispor
e oferecer tal serviço. Clusters são muito utilizados em servidores de bancos de dados e
Web.
9
3. Sistemas Multiprogramáveis
Um Sistema Operacional pode ser visto como um conjunto de rotinas que executam
concorrentemente de forma ordenada. A possibilidade de um processador executar instruções
em paralelo com operações de entrada e saída permite que diversas tarefas sejam executadas
concorrentemente. É este conceito de concorrência o princípio fundamental para o projeto e
implementação de sistemas multiprogramáveis.
Os sistemas multiprogramáveis surgiram a partir das limitações dos sistemas
monoprogramáveis onde os recursos computacionais como processador, memória e dispositivos
de E/S eram utilizados de maneira muito pouco eficiente, limitando seu desempenho, com
muitos destes recursos permanecendo ociosos por longos períodos de tempo.
Nos sistemas monoprogramáveis somente um programa pode estar em execução de cada
vez, permanecendo o processador dedicado exclusivamente a uma tarefa, ficando ocioso
enquanto uma operação de leitura em disco é realizada. O tempo de espera é relativamente
longo, já que as operações de E/S são muito lentas se comparadas à velocidade de operação do
processador.
Outro aspecto a ser considerado é a sub-utilização da memória principal, onde um programa
nem sempre ocupa todo o espaço disponível, ficando o restante inutilizado. Nos sistemas
multiprogramáveis vários programas podem ser alocados na memória, concorrendo pelo uso do
processador. Dessa forma, quando um programa solicita uma operação de E/S, outros
programas poderão utilizar o processador, deixando a CPU menos ociosa e tornando o uso da
memória mais eficiente, pois existem vários residentes e se revezando na utilização do
processador.
A utilização concorrente da CPU deve ser feita de maneira que, quando um programa perde
o uso do processador e depois retorna para continuar sua execução, seu estado deve ser
idêntico ao do momento em que foi interrompido. O programa deverá continuar sua execução
exatamente na instrução seguinte àquela onde havia parado, aparentando ao usuário que nada
aconteceu. Em sistemas de tempo compartilhado existe a impressão de que o computador está
inteiramente dedicado ao usuário, ficando esse mecanismo totalmente transparente aos
usuários.
Quanto ao uso dos periféricos, é comum nos sistemas monoprogramáveis é comum termos,
por exemplo, impressoras paradas por um grande período de tempo e discos com acesso
restrito a um único usuário. Esses problemas são minimizados nos sistemas multiprogramáveis,
onde é possível compartilhar os dispositivos de E/S, como impressoras e discos, entre diversos
usuários e aplicativos.
10
3.1
Interrupção e Exceção
Durante a execução de um programa, alguns eventos inesperados podem ocorrer,
ocasionando um desvio forçado no seu fluxo normal de execução. Esses eventos são conhecidos
como interrupção ou exceção, e podem ser resultado de sinalizações de algum dispositivo de
hardware externo ao ambiente memória/processador. A diferença entre interrupção e exceção é
dada pelo tipo de evento ocorrido, embora alguns autores e fabricantes não façam tal distinção.
A interrupção é o mecanismo que permitiu a implementação da concorrência nos
computadores, sendo o fundamento básico dos sistemas multiprogramáveis/multitarefa.
Uma interrupção é sempre gerada por um evento externo ao programa e, sendo assim,
independe da instrução que está sendo executada. Um exemplo de interrupção é quando um
dispositivo avisa ao processador que alguma operação de E/S está completa. Neste caso, o
processador deve interromper o programa para tratar o término da operação.
Ao término de cada instrução a Unidade de Controle (situada dentro do processador)
verifica a ocorrência de algum tipo de interrupção. Desta forma, o programa em execução é
interrompido e seu controle é desviado para uma rotina do sistema responsável por tratar o
evento ocorrido, denominada rotina de tratamento de interrupção. Para que o programa
interrompido possa retornar posteriormente à sua execução é necessário que, no momento da
interrupção, um certo conjunto de informações sobre sua execução seja preservado.
Essas informações consistem basicamente no conteúdo dos registradores internos da
CPU, que deverão ser restaurados para a continuação do programa.
Programa
Salva
Contexto
Identifica
a origem
Interrupção
Trata a
Interrupção
Rotina
de
Restaura
Contexto
Tratamento
Mecanismo de interrupção/exceção
11
Para cada tipo de interrupção existe uma rotina de tratamento associada, para onde o
fluxo do programa é desviado. A identificação do tipo de evento ocorrido é fundamental para
determinar o endereço da rotina adequada ao tratamento da interrupção.
As interrupções podem ser geradas:
- Pelo programa do usuário (entrada de dados pela console ou teclado)
- Pelo hardware (operações de E/S)
- Pelo sistema operacional (ao término da fatia de tempo do processador destinada ao
programa)
As interrupções sempre são tratadas pelo Sistema Operacional.
A exceção é um evento semelhante à interrupção, pois também de fato interrompe um
programa.
A principal diferença é que a exceção é o resultado da execução de uma instrução dentro
do próprio programa, como a divisão por zero ou a ocorrência de um overflow (estouro de
capacidade de um campo) numa operação aritmética.
Na maioria das vezes, a exceção provoca um erro fatal no sistema, causando o término
anormal do programa. Isto se deve ao fato de que a exceção é melhor tratada dentro do
próprio programa, com instruções escritas pelo programador.
3.2
Buffer
A técnica de buffering consiste nua utilização de uma área em memória principal,
denominada buffer, criada e mantida pelo Sistema Operacional, com a finalidade de auxiliar
a transferência de dados entre dispositivos de E/S e a memória. O buffer permite minimizar a
disparidade de velocidade entre o processador e os dispositivos de E/S, e tem como objetivo
principal manter tanto os dispositivos de E/S como o processador ocupados a maior parte do
tempo.
A unidade de transferência do mecanismo de buffering é o registro. O buffer deve
permitir o armazenamento de vários registros, de forma que o processador tenha à sua
disposição dados suficientes para processar sem ter que interromper o programa a cada
leitura/gravação no dispositivo de E/S. Enquanto o processador está ocupado processando,
os dispositivos de E/S estão efetuando operações para outros processos.
3.3
SPOOL
A técnica de spooling foi criada inicialmente para auxiliar a submissão de processos ao
sistema, sendo os processos gravados em fita para posterior leitura e execução.
12
Com o aparecimento dos terminais para acesso ao sistema, esta técnica teve sua função
adaptada para armazenar o resultado da impressão dos programas em execução.
Isto é conseguido através da criação e manutenção, pelo Sistema Operacional de uma
grande área em disco, com a finalidade de simular uma impressora. Desta forma, todos os
usuários e seus programas imprimem, na verdade, para este arquivo em disco, liberando a
associação dos dispositivos de impressão diretamente aos programas que estão executando.
O usuário consegue visualizar o resultado de seus programas na tela dos terminais,
gerando assim mais eficiência e economia de papel e fita de impressão. À proporção que vão
sendo gerados no SPOOL, os relatórios vão sendo liberados para impressão pelo operador do
sistema, de forma ordenada e seqüencial. Para cada usuário, é como se ele tivesse uma
impressora associada para si.
3.4
Reentrância
É comum, em sistemas multiprogramáveis, vários usuários utilizarem os mesmos
aplicativos simultaneamente, como editores de texto, compiladores e outros utilitários. Nesta
situação, se cada usuário que utilizasse um destes aplicativos trouxesse o código executável
para a memória, haveria então diversas cópias de um mesmo programa ocupando espaço na
memória, o que causaria um grande desperdício de espaço.
Reentrância é a capacidade de um código executável (código reentrante) ser
compartilhado por vários usuários, exigindo apenas uma cópia do programa em memória. A
reentrância permite que cada usuário esteja executando um trecho diferente do código
reentrante, manipulando dados próprios, exclusivos de cada usuário.
Normalmente códigos reentrantes são utilizados em utilitários do sistema, como editores,
compiladores e linkers, promovendo um uso mais eficiente da memória e um desempenho
maior do sistema. Alguns sistemas operacionais permitem a possibilidade de se implementar
o conceito de reentrância em aplicações desenvolvidas pelo próprio usuário, mas não é
comum.
3.5
Segurança e Proteção do Sistema
A eficiência proporcionada por um ambiente multiprogramável implica em maior
complexidade do sistema operacional, já que alguns problemas de proteção surgem como
decorrência deste tipo de implementação.
Considerando-se que diversos usuários estão compartilhando os mesmos recursos,
como memória, processador e dispositivos de E/S, faz-se então necessário existir
mecanismos de proteção para garantir a confiabilidade e a integridade dos dados e
programas dos usuários, além do próprio sistema operacional.
13
Como vários programas ocupam a memória principal simultaneamente, cada usuário
possui uma área reservada onde seus programas e dados são armazenados durante o
processamento. O sistema operacional deve possuir mecanismos de proteção a essas áreas,
de forma a preservar as informações nela contidas. Caso um programa tente acessar uma
posição de memória fora de sua área, um erro indicando a violação de acesso deve ocorrer,
sendo responsabilidade do sistema operacional o controle eficiente do compartilhamento dos
recursos e a sincronização da comunicação, evitando problemas de consistência.
Semelhante ao compartilhamento da memória, um disco também armazena arquivos
de diferentes usuários. Novamente o sistema operacional deve garantir a integridade e
confiabilidade dos dados de cada usuário.
Todo o controle da segurança do sistema é implementado pelo sistema operacional, a
partir de mecanismos como grupos de usuários, perfis de usuários e direitos de acesso.
A proteção começa geralmente no procedimento de login, quando o usuário faz a
conexão inicial ao sistema, através de nome do usuário e senha. A partir daí, toda uma
estrutura de controle é iniciada, em função da identificação do usuário, no sentido de
proteger as áreas alocadas em memória, em disco, e até mesmo o uso do processador.
A proteção e segurança do sistema pode ser implementada também a nível do
programa do usuário, com a inserção de rotinas específicas dentro do programa para
controlar o acesso de usuários ao aplicativo, além de controlar internamente quais telas e
funções tal usuário pode acessar.
3.6
Operações de Entrada e Saída
Nos primeiros sistemas computacionais, a comunicação entre o processador e os
periféricos era direta, sendo o processador responsável por efetuar as operações de
leitura/gravação nos dispositivos.
O surgimento do controlador de E/S permitiu ao processador agir de maneira
independente dos dispositivos de E/S. Com esse novo elemento, o processador não mais se
comunicava diretamente com os periféricos, mas sim via controlador.
Passou a existir então três maneiras básicas de se implementar operações de E/S:
-
por programa: o processador sincronizava-se com o periférico e iniciava a
transferência de dados, ficando permanentemente testando o estado do periférico
para saber quando a operação chegaria ao seu final. O processador ficava ocupado
até o término da operação de E/S.
14
-
por interrupção: evoluindo o processo anterior, após o início da transferência de
dados o processador passou a ficar livre para realizar outras tarefas. Assim, em
determinados intervalos de tempo o sistema operacional deveria testar o estado dos
periféricos para saber se a operação de E/S tinha terminado. Este tipo de operação
permitiu um certo grau de paralelismo, já que um programa poderia ser processado
enquanto uma operação de leitura/gravação em periférico estava sendo efetuada.
Isto permitiu a implementação dos primeiros sistemas multiprogramáveis.
Memória
Principal
CPU
Controlador
Dispositivos de E/S
-
A necessidade de se transmitir cada vez um volume maior de informações trouxe
uma evolução significativa nas operações de E/S. Em vez de o processador ser
interrompido várias vezes para interrogar os dispositivos para saber do resultado das
operações, o que diminuía sua eficiência devido ao excesso de interrupções, foi
criado um dispositivo de transferência de dados chamado de DMA – Direct Memory
Access. Esta técnica permite que um bloco de dados seja transferido entre a
memória e os dispositivos de E/S sem a intervenção do processador, a não ser no
início (quando a operação é solicitada) e no final da transferência (quando o
processador é notificado sobre o término da operação). Na figura a seguir, podemos
ver a implementação do canal de E/S gerenciando vários controladores e, ligados a
estes, vários periféricos.
15
O canal de E/S funciona então como uma interface entre os controladores e a CPU,
como mostra a figura a seguir:
Memória
Principal
CPU
Canal de E/S
Controlador
Dispositivos de E/S
Controlador
Dispositivos de E/S
16
4. Estrutura do Sistema Operacional
4.1
Estrutura do Sistema
USUÁRIO
UTILITÁRIOS
NÚCLEO
DO SISTEMA
HARDWARE
Hierarquia do Sistema Operacional
O sistema operacional é formado por um conjunto de rotinas que oferecem serviços
essenciais aos usuários, às suas aplicações, e também ao próprio sistema. A esse conjunto
de rotinas dá-se o nome de núcleo do sistema ou kernel.
É fundamental não se confundir o núcleo do sistema com aplicações, utilitários ou o
interpretador de comandos, que acompanham o sistema operacional. As aplicações são
utilizadas pelos usuários de maneira transparente, escondendo todos os detalhes da
interação com o sistema. Os utilitários, como os compiladores, editores de texto e
interpretadores de comandos permitem aos usuários, desenvolvedores e administradores de
sistema uma interação amigável com o sistema.
Existe uma grande dificuldade em compreender a estrutura e o funcionamento do sistema
operacional, pois ele não é executado como uma aplicação tipicamente seqüencial, com
início, meio e fim. Os procedimentos do sistema são executados concorrentemente sem uma
ordem específica ou predefinida, com base em eventos dissociados do tempo. Muitos desses
eventos estão relacionados ao hardware e a tarefas internas do próprio sistema operacional.
17
4.2
Funções do Sistema
As principais funções do núcleo encontradas na maioria dos sistemas comerciais são as
seguintes:
-
Tratamento de interrupções e exceções: já explicados anteriormente, em detalhes;
-
Criação e eliminação de processos: função responsável por alocar em memória todos os
recursos necessários à execução do processo. É esta função que aloca em memória, além
do executável, o contexto do processo, o buffer de leitura/gravação (se necessário), além
de listas e estruturas de controle utilizadas pelo sistema operacional. Nesta função
também são estabelecidos vínculos físicos a arquivos em disco, fitas e outros periféricos
que serão usados no processamento. Quando do fim da execução do programa, é esta
função que desaloca todos os espaços em memória ocupados pelo processo, liberando-os
para futuras alocações a outros processos;
-
Escalonamento e controle de processos: função responsável por organizar a fila de
acesso ao processador. Utiliza parâmetros do sistema e do perfil do usuário para
estabelecer a ordem em que os processos permanecerão à espera pela liberação da CPU,
para então entrarem em execução;
-
Gerência de memória: função responsável por fornecer à função de criação/eliminação de
processos os endereços em memória disponíveis para alocação;
-
Gerência de sistemas de arquivos: responsável pelo gerenciamento dos arquivos, bem
como seu compartilhamento pelos diversos usuários, implementando mecanismos de
controle da segurança e direitos de acesso às áreas utilizadas pelos usuários nos diversos
dispositivos;
-
Gerência de dispositivos de E/S: responsável por gerenciar os dispositivos, prestando
auxílio à criação/eliminação de processos e á gerência de sistemas de arquivos no que diz
respeito ao endereçamento e associação de arquivos em periféricos;
-
Suporte a redes e teleprocessamento: é esta função que executa todos os serviços de
rede, fazendo o empacotamento das mensagens vindas dos terminais para a CPU central
e vice-versa, além de controlar e confirmar o envio e recebimento de todas as mensagens
que trafegam pela rede;
-
Contabilização de uso do sistema: responsável por contabilizar o uso de todos os
recursos do sistema consumidos pelos usuários e suas aplicações. São registrados: tempo
de CPU, tempo corrido, quantidade de área alocada em memória, em disco, linhas
impressas, páginas de papel, entre outros. Isto se faz necessário para servir de subsídio
para análise de performance, estatísticas de gastos com material de consumo e também
para definição de custos de processamento.;
18
-
Auditoria e segurança do sistema: função extremamente importante, pois detecta e
registra (num arquivo especial de LOG) todas as ocorrências de erro e violação de direitos
de acesso ao sistema, aos arquivos, à memória e a todos os recursos do sistema. O
arquivo de LOG é usado pela gerência de sistemas, com o intuito de verificar e
aperfeiçoar os mecanismos de segurança e proteção ao sistema.
A estrutura do sistema, a maneira como ele é organizado e o inter-relacionamento entre
seus diversos componentes pode variar conforme a concepção do projeto do sistema.
4.3
System Calls
Uma grande preocupação no projeto de sistemas operacionais se refere à implementação de
mecanismos de proteção ao núcleo do sistema e também o controle de acesso aos serviços
oferecidos pelo sistema. Caso uma aplicação que tenha acesso ao núcleo realize alguma
operação que altere sua integridade, todo o sistema poderá ficar comprometido e inoperante.
As system calls podem ser entendidas como uma porta de entrada para acesso ao núcleo do
sistema e aos seus serviços. Sempre que um usuário ou uma aplicação necessita de algum
serviço do sistema, é realizada uma chamada a uma de suas rotinas através de uma system call.
Através dos parâmetros fornecidos na system call, a solicitação é processada e uma
resposta é enviada à aplicação juntamente com um estado de conclusão indicando o sucesso ou
não da operação. Para cada serviço disponível existe uma system call associada, e cada sistema
operacional possui seu próprio conjunto de chamadas, com nomes, parâmetros e formas de
ativação específicos. Isto explica por que uma aplicação desenvolvida utilizando serviços de um
determinado sistema operacional não pode ser diretamente portada para um outro sistema.
Aplicação
System Call
Biblioteca
Núcleo do
Sistema
Operacional
Hardware
19
4.4
Modos de Acesso
Existem certas instruções que não podem ser colocadas diretamente à disposição das
aplicações, pois a sua utilização indevida poderia ocasionar sérios problemas à integridade do
sistema. Imagine que uma aplicação atualize um arquivo em disco. O programa, por si só, não
pode especificar diretamente as instruções que acessam seus dados no disco pois, como o disco
é um recurso compartilhado, sua utilização deve ser gerenciada unicamente pelo sistema
operacional. Tal procedimento evita que a aplicação possa ter acesso a qualquer área do disco
indiscriminadamente, o que poderia comprometer a segurança e a integridade do sistema de
arquivos.
Assim, fica claro que existem certas instruções que só podem ser executadas pelo sistema
operacional ou sob sua supervisão. As instruções que têm o poder de comprometer o sistema
são chamadas de instruções privilegiadas, enquanto as instruções que não comprometem o
funcionamento do sistema chamam-se instruções não-privilegiadas.
Para que uma aplicação possa executar uma instrução privilegiada, é preciso que haja um
mecanismo de proteção no processador, chamado modos de acesso. Existem basicamente dois
modos de acesso ao processador: modo usuário e modo kernel. Quando o processador trabalha
no modo usuário, somente instruções não-privilegiadas podem ser executadas, tendo assim
acesso a um número limitado de instruções do processador. Já no modo kernel (ou supervisor),
a aplicação pode ter acesso ao conjunto total de instruções do processador.
A melhor maneira de controlar o acesso às instruções privilegiadas é permitir que apenas o
sistema operacional tenha acesso a elas. Sempre que uma aplicação necessita executar uma
instrução privilegiada, a solicitação deve ser feita através de uma system call, que altera o modo
de acesso ao processador do modo usuário para o modo kernel. Ao término da execução da
rotina do sistema, o modo de acesso retorna para o modo usuário.
20
4.5
-
Arquiteturas: Sistemas monolíticos, em camadas e microkernel
Arquitetura monolítica: é caracterizada por possuir seus módulos compilados
separadamente mas linkados formando um único e enorme programa executável. Onde
os módulos podem interagir livremente. Os primeiros sistemas operacionais foram
desenvolvidos com base nesta arquitetura, o que tornava seu desenvolvimento e,
principalmente, sua manutenção muito difíceis. Como vantagens desta arquitetura
podemos citar a rapidez de execução e simplicidade de implementação. Como
desvantagens, a limitação quanto a inovações futuras e a dificuldade de manutenção.
Aplicação
Aplicação
Modo Usuário
Modo Kernel
System call
Núcleo
do
Sistema
Hardware
Arquitetura monolítica
21
-
Arquitetura em camadas: com o aumento do tamanho do código dos sistemas
operacionais, técnicas de programação estruturada e modular foram incorporadas em seu
projeto.Na arquitetura em camadas, o sistema é dividido em níveis sobrepostos. Cada
camada oferece um conjunto de funções que podem ser utilizadas somente pelas
camadas superiores. Neste tipo de implementação as camadas mais internas são mais
privilegiadas que as camadas mais externas. A vantagem da estruturação em camadas é
o isolamento das funções do sistema, facilitando sua manutenção. Uma desvantagem é o
desempenho, comprometido devido às várias mudanças de estado do processador
provocado pela mudança de camadas. A figura a seguir mostra esta arquitetura.
Camada Usuário
Camada Supervisor
Camada Executivo
Kernel
Arquitetura em camadas
-
Arquitetura microkernel (cliente x servidor): uma tendência nos sistemas operacionais
modernos é tornar o núcleo do sistema o menor e o mais simples possível. Para
implementar esta idéia, os serviços do sistema são disponibilizados através de processos,
onde cada um é responsável por oferecer um conjunto específico de funções, como
gerência de arquivos, gerência de processos, gerência de memória e escalonamento.
Sempre que uma aplicação deseja algum serviço, é realizada uma solicitação ao processo
responsável. Neste caso, a aplicação que está solicitando o serviço é chamada de cliente,
enquanto o processo que responde à solicitação é chamado de servidor. Um cliente, que
pode ser uma aplicação do usuário ou um outro componente do sistema operacional,
solicita um serviço enviando uma mensagem para o servidor. O servidor responde ao
cliente através de uma outra mensagem. A principal função do núcleo é realizar a
comunicação, ou seja, a troca de mensagens entre o cliente e o servidor. A utilização
22
deste modelo permite que os servidores operem em modo usuário, não tendo acesso
direto a certos componentes do sistema. Apenas o núcleo do sistema, responsável pela
comunicação entre clientes e servidores, executa em modo kernel. Como conseqüência,
se ocorrer um erro em algum servidor,este poderá parar, mas o sistema não ficará
inteiramente comprometido, aumentando assim a sua disponibilidade. Como os
servidores se comunicam através de trocas de mensagens, não importa se os clientes e
servidores processam em um sistema com um único processador, com vários
processadores ou ainda em um ambiente de sistema distribuído. A arquitetura
microkernel permite isolar as funções do sistema operacional por diversos servidores
pequenos e dedicados a serviços específicos, tornando o núcleo menor, mais fácil de
depurar (procurar e solucionar erros) e, com isso, aumentando a sua confiabilidade.
Apesar de todas as vantagens deste modelo, sua implementação é muito difícil. A
começar pelo desempenho, comprometido devido às várias trocas de modo de acesso a
cada troca de mensagens entre cliente e servidor. Outro problema é que certas funções
do sistema operacional, como operações de E/S, exigem acesso direto ao hardware.
Assim, o núcleo do sistema, além de promover a comunicação entre clientes e servidores,
passa a incorpora funções críticas do sistema, como escalonamento, tratamento de
interrupções e gerência de dispositivos.
Servidor
Servidor
Rede
Servidor
Memória
Arquivo
Servidor
Impressão
Servidor
Processo
Modo Usuário
Modo Kernel
Microkernel
Hardware
23
5. PROCESSO
O conceito de processo é a base para a implementação de um sistema multiprogramável. O
processador é projetado apenas para executar instruções, não sendo capaz de distinguir qual
programa se encontra em execução.A gerência de um ambiente multiprogramável é função
exclusiva do sistema operacional, que deve controlar a execução dos diversos programas e o
uso concorrente do processador.
A gerência do processador é uma das principais funções de um sistema operacional. Através
dos processos, um programa pode alocar recursos, compartilhar dados e trocar informações.
5.1
Componentes do processo
Um processo pode ser entendido inicialmente como um programa em execução, que tem
suas informações mantidas pelo sistema operacional.
Num sistema multiusuário, cada usuário tem a impressão de possuir o processador e todos
os demais recursos reservados exclusivamente para si, mas isto não é verdade. Todos os
recursos estão sendo compartilhados, inclusive a CPU. Neste caso, o processador executa o
processo do usuário por um intervalo de tempo e, no instante seguinte, poderá estar
processando um outro programa, do mesmo ou de outro usuário.
Para que a troca de processos possa ser feita sem problemas, é necessário que todas as
informações do programa que está sendo interrompido sejam guardadas, para que ele possa
retornar à CPU exatamente do ponto em que parou, não lhe faltando nenhuma informação vital
à sua continuação. Todas as informações necessárias à execução de um programa fazem parte
do processo.
Um processo também pode ser definido como o ambiente onde o programa é executado.
Este ambiente, além das informações sobre a execução, possui também a quantidade de
recursos do sistema que o programa pode utilizar,como espaço de endereçamento, tempo do
processador e área em disco.
Um processo é formado por três partes: contexto de software, contexto de hardware e
espaço de endereçamento, que juntas mantêm todas as informações necessárias à execução de
um programa.
24
Estrutura do processo:
Contexto de
Software
________
________
________
Programa
Contexto de
Hardware
Espaço de
endereçamento
•
Contexto de Software: neste contexto são especificadas características e limites
dos recursos que podem ser alocados pelo processo, como número máximo de arquivos
abertos, prioridade de execução, número máximo de linhas impressas, etc. Muitas destas
características são criadas no momento da criação do processo, quando da sua alocação.
O sistema operacional obtém, a partir do cadastro de usuários e do cadastro de
contas no sistema, as informações e características que valerão para o processo.
O contexto de software é composto por tr?es grupos de informações:
-
Identificação: neste grupo são guardadas informações sobre o usuário que criou o
processo, e, em função disso, suas áreas de atuação no sistema.
-
Quotas: são os limites de recursos do sistema que um processo pode alocar, como
área utilizada em disco, em memória, limite de linhas impressas, número máximo
de arquivos abertos, número máximo de operações de E/S pendentes, tempo
limite de CPU, etc.
-
Privilégios: diz respeito principalmente às prioridades assumidas pelo processo
durante sua execução.
•
Contexto de Hardware: armazena o conteúdo dos registradores gerais da
CPU, além dos registradores de uso específico. Quando um processo está em execução, o
seu contexto de hardware está armazenado nos registradores da CPU. No momento em
que o processo perde a utilização da CPU, o sistema salva as informações no contexto de
hardware do processo.
A troca de um processo por outro no processador, comandada pelo sistema
operacional, é denominada troca de contexto, que consiste em salvar o conteúdo dos
registradores do processo que está deixando a CPU e carrega-los com os valores
25
referentes ao do novo processo que irá executar. Essa operação resume-se em substituir
o contexto de hardware de um processo pelo de outro.
•
Espaço de endereçamento: é a área de memória pertencente a um processo onde
as instruções e os dados do programa são armazenados para execução. Cada processo
possui seu próprio espaço de endereçamento, que deve ser devidamente protegido do
acesso dos demais processos. Os contextos de software e de hardware não fazem parte
do espaço de endereçamento .
•
Bloco de controle do processo: é a estrutura de dados que compõe o processo,
contendo os contextos de software e de hardware e o espaço de endereçamento. O BCP
reside em memória, numa área reservada ao sistema operacional.
5.2
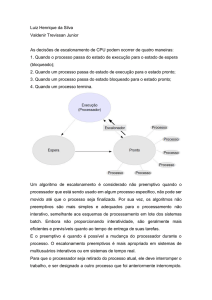
Estados do processo
Num sistema multiprogramável, um processo não deve alocar a CPU com exclusividade,
de forma que possa existir um compartilhamento no uso do processador. Os processos
passam por diferentes estados ao longo do processamento, em função de eventos gerados
pelo sistema operacional, pelo hardware, ou pelo próprio programa. São estados possíveis de
um processo:
-
Criação: neste estado o processo está sendo alocado na memória, sendo criado no
sistema. Todos os recursos necessários à execução do processo são reservados
durante a passagem do processo por este estado, o que acontece uma única vez.
Vários processos podem estar neste estado, ao mesmo tempo.
-
Pronto: é o estado onde os processos, depois de criados ou quando retornam do
tratamento de uma interrupção, permanecem aguardando a liberação da CPU para
que possam iniciar ou continuar seu processamento. É como se fosse uma fila,
gerenciada pelo sistema operacional, que se incumbe de organizar os processos de
acordo com as informações contidas no contexto de software (identificação,
quotas e privilégios). Vários processos podem estar neste estado, ao mesmo
tempo.
-
Execução: é onde o processo efetivamente utiliza a CPU. Ele permanece no
processador até que seja interrompido ou termine sua execução. Neste estado,
somente um processo pode permanecer de cada vez, já que existe apenas um
processador.
-
Espera: neste estado estão todos os processos que sofreram algum tipo de
interrupção de E/S, onde permanecem até que a intervenção seja resolvida. Vários
processos podem estar neste estado, ao mesmo tempo.
26
5.3
Saída: é o estado final do processo, quando este termina seu processamento.
Vários processos podem estar neste estado, ao mesmo tempo.
Mudanças de estado do processo
Um processo muda de estado diversas vezes durante sua permanência no sistema,
devido aos eventos ocorridos durante sua execução. São mudanças possíveis:
-
Criação Pronto: o processo foi criado, tem seus recursos alocados, e está apto a
disputar o uso da CPU.
-
Pronto Execução: o processo é o primeiro da fila de pronto e a CPU fica
disponível. Neste momento o processo passa a ocupar a CPU, permanecendo em
execução até que seja interrompido ou termine sua execução.
-
Execução Pronto: o processo foi interrompido por fatia de tempo ou por
prioridade. Ainda precisa de mais tempo na CPU para terminar sua execução, não
tem nenhuma intervenção pendente, por isso volta à fila de pronto para disputar
novamente o uso da CPU.
-
Execução Espera: esta transição acontece quando o processo foi interrompido
por E/S. Significa que deve permanecer no estado de espera até que a interrupção
seja tratada pelo sistema. Neste estado o processo fica impedido de disputar o uso
da CPU.
-
Espera Pronto: Após o término do tratamento da interrupção, o processo volta à
fila de pronto para disputar novamente o uso da CPU.
-
Execução Saída: o processo terminou, e não mais disputará o uso da CPU.
A seguir, a figura mostra as mudanças possíveis de estado de um processo.
Pronto
Execução
Mudanças de estado de um
processo
27
5.4
Tipos de processos
Além dos processos do usuário, a CPU também executa processos do sistema. São aqueles
que oferecem os serviços do sistema operacional aos usuários, como criação/eliminação de
processos, tratamento de interrupção e todos aqueles correspondentes às funções do sistema já
estudadas. Estes executam sempre, com certa prioridade, concorrendo com os processos do
usuário.
Os processos em execução, do usuário, podem assumir dois tipos diferentes, de acordo com
suas características de uso de CPU e periféricos:
Processo CPU-bound: é aquele processo que utiliza muito a CPU. Ele ganha
uma fatia de tempo e a utiliza por inteiro, sem desperdiçar nenhum tempo. É o caso de
programas científicos, de cálculo numérico, estatística, matemática, e também na área de
simulação. Normalmente fazem pouca ou nenhuma entrada de dados, e muito
processamento.
Processo I/O-bound: é o tipo de processo que utiliza muito mais E/S do que
CPU. Aplicações em Banco de Dados, onde se faz consultas e atualizações constantes em
arquivos em disco são um bom exemplo deste tipo de processo. De acordo com essas
características, podemos dizer que este tipo de processo permanece mais tempo em
espera (tratando interrupções) do que propriamente em execução, ocupando a CPU por
períodos mínimos de tempo.
28
6. Gerência do Processador
6.1
Funções
Com o surgimento dos sistemas multiprogramáveis, onde múltiplos processos poderiam
permanecer na memória e disputar o uso de um único processador, a gerência do processador
tornou-se uma das atividades mais importantes em um sistema operacional.
A partir do momento em que vários processos podem estar no estado de pronto, devem
ser estabelecidos critérios para definir qual processo será escolhido para fazer uso do
processador. Tais critérios compõem a política de escalonamento, que é a base da gerência do
processador e da multiprogramação em um sistema operacional.
Dentre as funções da gerência do processador, podemos citar: manter o processador
ocupado a maior parte do tempo. balancear o uso da CPU entre processos, privilegiar a
execução de aplicações críticas, maximizar o throughput e oferecer tempos de resposta
razoáveis aos usuários interativos.
Cada sistema operacional possui sua política de escalonamento adequada ao seu
propósito e às suas características. Sistemas de tempo compartilhado, por exemplo, possuem
requisitos de escalonamento distintos dos sistemas de tempo real.
6.2
Critérios de escalonamento
-
Utilização do processador: corresponde a uma taxa de utilização, que na maioria dos
sistemas varia entre 30 e 90%. Uma utilização abaixo dos 30% indicaria um sistema
ocioso, com carga de processamento baixa, enquanto uma taxa de utilização acima dos
90% pode indicar um sistema bastante carregado, próximo da sua capacidade máxima
(em alguns casos tal situação pode levar a um crash – travamento do sistema).
-
Throughput: é o número de processos executados em um determinado intervalo de
tempo. Quanto maior o throughput, maior o número de tarefas executadas em função do
tempo. A maximização do throughput é desejada na maioria dos sistemas.
-
Tempo de Processador: é o tempo que um processo leva no estado de execução,
durante seu processamento. As políticas de escalonamento não interferem neste
parâmetro, sendo este tempo função apenas do código executável e da entrada/saída de
dados.
-
Tempo de Espera (pela CPU): é todo o tempo que o processo permanece na fila de
pronto, aguardando a liberação da CPU para ser executado. A redução deste tempo de
espera é desejada pela maioria das políticas de escalonamento.
29
-
Tempo de Turnaround: é o tempo total que o processo permaneceu no sistema, desde
sua criação até o momento em que é encerrado. São contados os tempos de alocação
de memória, espera na fila de pronto e interrupção (E/S).
-
Tempo de Resposta: é o tempo decorrido entre uma requisição ao sistema e o instante
em que a resposta começa a ser exibida. Em sistemas interativos, como aplicações online ou acesso à Web, os tempos de resposta devem ser da ordem de apenas poucos
segundos.
6.3
Escalonamentos Não-Preemptivos e Preemptivos
Escalonamentos do tipo não-preemptivos são aqueles onde o sistema operacional não
pode interromper o processo em execução para retirá-lo da CPU. Assim sendo, se nenhum
evento externo ocorresse durante a execução do processo, este permanecia na CPU até
terminar ou então alguma instrução do próprio programa o desviasse para o estado de espera
(operação de E/S).
Já os escalonamentos preemptivos são caracterizados pela possibilidade de o sistema
operacional interromper o processo em execução para retirá-lo da CPU e dar lugar a outro.
Neste caso o processo retirado da CPU volta ao estado de pronto, onde permanece
aguardando nova oportunidade de ocupar a CPU. Com o uso da preempção, é possível ao
sistema priorizar a execução de processos, como no caso de aplicações em tempo real. Outro
benefício é a possibilidade de implementar políticas de escalonamento que compartilhem o
processador de uma maneira mais uniforme, balanceando o uso da CPU entre os processos.
São escalonamentos não-preemptivos:
-
FIFO: o processo que chegar primeiro à fila de pronto é selecionado para execução, e
permanece utilizando o processador até terminar sua execução ou ser interrompido por
E/S. Neste caso, o próximo processo da fila de pronto é selecionado para execução.
Todo processo que chega à fila de pronto entra no final desta fila, conservando a ordem
de chegada na fila, até ser escalonado novamente. Apesar de simples, este
escalonamento apresenta algumas deficiências, principalmente no que diz respeito à
dificuldade de se prever o início da execução de um processo, já que a ordem de
chegada á fila de pronto deve ser observada à risca. Outro problema é quanto aos tipos
de processo, onde os CPU-bound levam vantagem no uso do processador em relação
aos do tipo I/O-bound, pois o sistema não trata este tipo de diferença. O escalonamento
FIFO foi inicialmente implementado em sistemas monoprogramáveis, sendo ineficiente
se aplicado em sistemas interativos de tempo compartilhado.
30
Abaixo, um exemplo de escalonamento utilizando o método FIFO: a ordem de chegada
dos processos (A, B, C) na fila de pronto foi obedecida, e, não tendo sido interrompidos por
E/S, os processos executaram inteiramente até terminar, de acordo com seus tempos
necessários para execução.
0
10
Processo A
10 u.t.
-
18
Processo B
8 u.t.
27
Processo C
9 u.t.
SJF (Shortest Job First): este escalonamento seleciona o processo que tiver o menor
tempo de processador ainda por executar. Desta forma, o processo que estiver na fila de
pronto com menor necessidade de tempo de CPU para terminar o seu processamento
será o escolhido para ocupar a CPU. Funciona com um parâmetro passado ao sistema
via contexto de software, onde o tempo estimado para o processo é informado
baseando-se em estatísticas de execuções anteriores.
Como exemplo, vamos utilizar os mesmos processos executados no
escalonamento FIFO acima, com seus respectivos tempos de execução em u.t.
(unidades de tempo): processo A com 10 u.t., processo B com 8 u.t, e o processo C com
9 u.t. Como neste escalonamento o que importa é o tempo de execução, a nova ordem
de escalonamento para utilização da CPU será B, C e A, como segue:
0
8
Processo B Processo C
-
17
27
Processo A
Cooperativo: este escalonamento busca aumentar o grau de concorrência no
processador. Neste caso, um processo em execução pode voluntariamente liberar o
processador retornando à fila de pronto, possibilitando que um novo processo seja
escalonado, permitindo melhor distribuição do tempo do processador. A liberação da
CPU é uma tarefa exclusiva do programa em execução, que de maneira cooperativa
libera o processador para um outro processo. Neste mecanismo, o processo em
execução verifica periodicamente uma fila de mensagens para saber se existem outros
processos na fila de pronto. Porém, como a interrupção do processo não depende do
sistema operacional, situações indesejáveis podem ocorrer, como por exemplo, se um
programa em execução não verificar a fila de mensagens, os demais programas não
terão chance de executar enquanto a CPU não for liberada. As primeiras versões do
Windows chegaram a utilizar este tipo de escalonamento.
31
São escalonamentos preemptivos:
Circular: é um tipo de escalonamento projetado especialmente para sistemas em tempo
compartilhado. É muito semelhante ao FIFO (obedece a ordem de chegada á fila de
PRONTO), mas quando um processo passa para o estado de execução há um limite de
tempo para o uso contínuo do processador, chamado fatia de tempo (time-slice) ou
quantum. Assim, toda vez que um processo é selecionado para execução uma nova fatia
de tempo lhe é concedida. Caso esta fatia de tempo expire, o sistema operacional
interrompe o processo, salva seu contexto e o direciona para a fila de PRONTO. Este
mecanismo é conhecido como preempção por tempo. A principal vantagem deste
escalonamento é não permitir que um processo monopolize a CPU. Outrossim, uma
desvantagem é que os processos CPU-bound são beneficiados no uso do processador
em relação aos processos I/O-bound, pois tendem a utilizar totalmente a fatia de tempo
recebida. A figura a seguir mostra o escalonamento circular com 3 processos, onde a
fatia de tempo é igual a 2 u.t. No exemplo não estão sendo levados em consideração
tempos de troca de contexto entre os processos, nem o tempo perdido em operações de
E/S. Os processos A, B e C, gastam 10 u.t, 6 u.t e 3 u.t., respectivamente.
-
A
B
C
2
-
4
6
8
10 11
17
u.t.
Por Prioridades: funciona com base num valor associado a cada processo, denominado
prioridade de execução. O processo com maior prioridade na fila de PRONTO é sempre
o escolhido para ocupar o processador, sendo os processos com prioridades iguais
escalonados pelo critério FIFO. Neste escalonamento o conceito da fatia de tempo não
existe. Como conseqüência disto, um processo em execução não pode sofrer preempção
por tempo. Neste escalonamento a perda do uso do processador somente ocorrerá no
caso de uma mudança voluntária para o estado de espera (interrupção por E/S), ou
quando um outro processo de prioridade maior passa (ou chega) para o estado de
pronto. Neste caso o sistema operacional interrompe o processo em execução, salva seu
contexto e o coloca na fila de pronto, dando lugar na CPU ao processo prioritário. Este
mecanismo é chamado de preempção por prioridade. A figura a seguir mostra a
execução dos processos A, B e C, com tempos de execução de 10, 4 e 3 u.t.
respectivamente, e valores de prioridades de 2, 1 e 3, também respectivamente. Na
32
maioria dos sistemas, valores menores correspondem à MAIOR prioridade. Assim, a
ordem de execução será invertida para B, A e C.
A
B
C
4
14
17
u.t.
A prioridade de execução faz parte do contexto de software do processo, e pode ser
estática (quando não pode ser alterada durante a existência do processo) ou dinâmica
(quando pode ser alterada durante a existência do processo). Este escalonamento é
muito usado em sistemas de tempo real, com aplicações de controle de processos,
controle de tráfego (sinais de trânsito, de trens/metrô, aéreo), robótica, entre outros.
-
Escalonamento Circular com Prioridades: implementa o conceito de fatia de tempo e de
prioridade de execução associada a cada processo. Neste escalonamento, um processo
permanece no estado de execução até que termine seu processamento, ou
voluntariamente passe para o estado de espera (interrupção por E/S), ou sofra uma
preempção por tempo ou prioridade. A principal vantagem deste escalonamento é
permitir um melhor balanceamento no uso do processador, com a possibilidade de
diferenciar o grau de importância dos processos através da prioridade (o Windows utiliza
este escalonamento).
-
Por Múltiplas Filas: Este escalonamento implementa várias filas de pronto, cada uma
com prioridade específica. Os processos são associados às filas de acordo com
características próprias, como importância da aplicação, tipo de processamento ou área
de memória necessária. Assim, não é o processo que detém a prioridade, mas sim a fila.
O processo em execução sofre preempção caso um outro processo entre em uma fila de
maior prioridade. O sistema operacional só pode escalonar processos de uma fila
quando todas as outras filas de maior prioridade estejam vazias. Os processos sempre
voltam para a mesma fila de onde saíram.
-
Por Múltiplas Filas com Realimentação: semelhante ao anterior, porém permitindo ao
processo voltar para uma outra fila de maior ou menor prioridade, de acordo com seu
comportamento durante o processamento. O sistema operacional identifica
dinamicamente o comportamento de cada processo e o redireciona para a fila mais
conveniente ao longo de seu processamento. É um algoritmo generalista, podendo ser
implementado na maioria dos sistemas operacionais.
7. Gerência de Memória / Memória Virtual
33
7.1
Introdução
Historicamente, a memória principal sempre foi vista como um recurso escasso e caro.
Uma das maiores preocupações dos projetistas foi desenvolver sistemas operacionais que não
ocupassem muito espaço de memória e, ao mesmo tempo, otimizassem a utilização dos
recursos computacionais. Mesmo atualmente, com a redução do custo e o aumento considerável
da capacidade da memória principal, seu gerenciamento é dos fatores mais importantes no
projeto e implementação dos sistemas operacionais.
Enquanto nos sistemas monoprogramáveis a gerência de memória não é muito complexa,
nos sistemas multiprogramáveis essa gerência se torna crítica, devido à necessidade de se
maximizar o número de usuários e aplicações utilizando eficientemente o espaço da memória
principal.
7.2
Funções
Geralmente, os programas são armazenados em memórias secundárias, de uso
permanente e não voláteis, como discos ou fitas. Como o processador somente executa o que
está na memória principal, o sistema operacional deve sempre transferir programas da memória
secundária para a principal antes de serem executados.Como o tempo de acesso às memórias
secundárias é muito superior ao tempo de acesso à memória principal, o sistema operacional
deve buscar reduzir o número de operações de E/S (acessos à memória secundária) a fim de
não comprometer o desempenho do sistema.
A gerência de memória deve tentar manter na memória principal o maior número de
processos residentes, permitindo maximizar o compartilhamento do processador e demais
recursos computacionais. Mesmo não havendo espaço livre, o sistema deve permitir que novos
processos sejam aceitos e executados. Outra preocupação na gerência de memória é permitir a
execução de programas maiores do que a memória física disponível.
Em um ambiente de multiprogramação o sistema operacional deve proteger as áreas de
memória ocupadas por cada processo, além da área onde reside o próprio sistema. Caso um
programa tente realizar algum acesso indevido à memória, o sistema deve, de alguma forma,
impedir o acesso.
7.3
Alocação Contígua Simples
Este tipo de alocação foi implementado nos primeiros sistemas operacionais, embora
ainda nos dias de hoje esteja presente em alguns sistemas monoprogramáveis. Nesse modelo, a
memória principal é dividida em duas partes, uma para o sistema operacional e a outra para o
programa do usuário. Dessa forma, o programador deve desenvolver suas aplicações
preocupado apenas em não ultrapassar o espaço de memória disponível.
34
Neste esquema o usuário tem total controle sobre toda a memória, exceto naquela área
onde reside o sistema operacional, cujo endereçamento é protegido por um registrador,
impedindo acesso indevido pelo usuário.
Sistema
Operacional
X
registrador
Área
para
programas
Proteção na alocação contígua simples
Apesar de simples implementação e código reduzido, a alocação contígua simples não
permite a utilização eficiente dos recursos do sistema, pois apenas um usuário pode dispor
destes recursos. Há inclusive um desperdício de espaço de memória, caso o programa não
venha a ocupar toda a área reservada para ele.
Sistema
Operacional
Programa do
Usuário
Área livre
Sub-utilização da memória principal
7.4
Segmentação de Programas
Na alocação contígua simples todos os programas estão limitados ao tamanho da
memória principal disponível para o usuário. Uma solução encontrada para o problema é dividir
o programa em módulos, de modo que seja possível a execução independente de cada módulo,
utilizando a mesma área de memória. A esta técnica dá-se o nome de segmentação ou overlay.
Consideremos um programa que tenha três módulos: um principal, um de cadastramento
e outro de impressão, sendo os módulos de cadastramento e impressão independentes. A
independência significa que quando um módulo estiver na memória para execução, o outro não
35
necessariamente precisa estar presente.O módulo principal é comum aos outros dois, logo,
precisa estar na memória durante todo o tempo da execução do programa.
Na figura a seguir, a memória é insuficiente para armazenar todo o programa, que
totaliza 9 KB. A técnica de overlay utiliza uma área de memória comum para armazenar o
módulo principal do programa e uma outra área na mesma memória, chamada área de overlay,
que será compartilhada entre os módulos de cadastramento e impressão. Assim, sempre que
um dos módulos for referenciado no módulo principal, o sistema o carregará da memória
secundária para a área de overlay, sobrepondo o módulo antigo na memória.
Memória Principal
2 KB
3 KB
4 KB
1 KB
Sistema
Operacional
Cadastramento
Módulo
Principal
Área de
Overlay
4 KB
Impressão
Área livre
2 KB
2 KB
Técnica de Overlay
A definição das áreas de overlay é função do programador, através de comandos
específicos da linguagem de programação utilizada.
A grande vantagem da utilização desta técnica consiste em se poder executar programas
maiores do que a memória física disponível.
7.5
Alocação Particionada Estática
Os sistemas operacionais evoluíram no sentido de proporcionar melhor aproveitamento
dos recursos disponíveis. Nos sistemas monoprogramáveis o processador permanece grande
parte do tempo ocioso e a memória principal é sub-utilizada. Os sistemas multiprogramáveis já
são muito mais eficientes no uso do processador, necessitando que vários processos estejam na
memória principal ao mesmo tempo e que novas formas de gerência de memória sejam
implementadas.
36
Nos primeiros sistemas multiprogramáveis a memória era dividida em blocos de tamanho
fixo, chamados partições.O tamanho dessas partições, estabelecido em tempo de inicialização
do sistema, era definido em função do tamanho dos programas que executariam no
ambiente.Sempre que fosse necessária a alteração do tamanho de uma partição, o sistema
deveria ser inicializado novamente com uma nova configuração.
Sistema
Operacional
Partição 1
2 KB
Partição 2
5 KB
Partição 3
8 KB
Inicialmente, os programas só podiam ser carregados e executados em apenas uma
partição específica, mesmo que as outras estivessem disponíveis. Esta limitação se devia aos
compiladores e linkeditores, que geravam apenas código absoluto. No código absoluto, todas as
referências a endereços no programa são posições físicas na memória, ou seja, o programa só
poderia ser carregado a partir do endereço de memória especificado no seu próprio código. A
esse tipo de alocação de memória chamou-se alocação particionada estática absoluta.
Coma evolução dos compiladores, linkeditores, montadores e loaders, o código gerado
deixou de ser absoluto e passou a ser relocável . No código relocável, todas as referências a
endereços no programa são relativas ao início do código e não a endereços fixos na memória.
Desta forma, os programas puderam ser alocados em qualquer partição livre, independente do
endereço inicial e da partição para a qual o código foi criado. A esse tipo de alocação deu-se o
nome de alocação particionada estática relocável.
Tanto nos sistemas de alocação absoluta como nos de alocação relocável, os programas,
normalmente, não ocupam totalmente as partições onde são alocados, deixando algum espaço
livre dentro das partições. Este tipo de problema, decorrente do esquema de alocação fixa de
partições, é chamado fragmentação interna.
A figura a seguir mostra um gráfico representando o particionamento estático de uma
memória e sua fragmentação interna.
Memória Principal
Sistema
37
Operacional
Programa C
1 KB
Programa A
3 KB
Fragmentação
interna
Programa E
5 KB
Alocação particionada estática com fragmentação interna
7.6
Alocação Particionada Dinâmica
A alocação particionada estática deixou clara a necessidade de uma nova forma de
gerência de memória principal, onde o problema da fragmentação interna fosse reduzido e,
conseqüentemente, o grau de compartilhamento da memória aumentado.
Na alocação particionada dinâmica, foi eliminado o conceito de partições de tamanho fixo.
Nesse esquema, cada programa, ao ser carregado, utilizaria o espaço necessário à sua
execução, tornando esse espaço a sua partição. Assim, como os programas utilizam apenas o
espaço de que necessitam, no esquema de alocação particionada dinâmica o problema da
fragmentação interna deixa de existir.
Porém, com o término de alguns programas e o início de outros, passam a existir na
memória blocos cada vez menores na memória, não permitindo o ingresso de novos programas.
A este tipo de problema dá-se o nome de fragmentação externa.
Para resolver o problema da fragmentação externa, os fabricantes tentaram duas
soluções:
- reunião de todos os blocos livres adjacentes, formando uma grande área livre, que se
transforma em uma nova partição;
-
realocação de todas as partições ainda ocupadas para a parte inicial da memória,
eliminando os blocos livres entre elas, formando uma grande área livre no final da
memória, que podia ser distribuída entre os processos ainda por executar. A este tipo
de compactação de espaços livres foi dado o nome de alocação particionada dinâmica
com realocação.
38
Estas soluções ajudaram a diminuir os problemas da fragmentação (tanto interna como
externa), mas, devido á complexidade dos algoritmos, nem todos os sistemas operacionais
as utilizaram.
7.7
Estratégias de Alocação de Partição
Os sistemas operacionais implementam basicamente três estratégias para determinar em
qual área livre um programa será alocado para execução. Essas estratégias tentam evitar ou
diminuir o problema da fragmentação.
A melhor estratégia a ser adotada por um sistema depende de uma série de fatores,
sendo o mais importante o tamanho dos programas executados no ambiente.
Independentemente do algoritmo utilizado, o sistema possui uma lista das áreas livres,
com endereço e tamanho de cada área.
São estratégias de alocação:
-
Best-fit: é escolhida a melhor partição, ou seja, aquela que deixa o menor espaço sem
utilização. Uma grande desvantagem desta estratégia é que, como são alocados
primeiramente as partições menores, deixando pequenos blocos, a fragmentação
aparece mais rapidamente.
-
Worst-fit: aloca o programa na pior partição, ou seja, aquela que deixa o maior espaço
livre. Esta técnica, apesar de aproveitar primeiro as partições maiores, acaba deixando
espaços livres grandes o suficiente para que outros programas utilizem esses espaços,
permitindo que um número maior de processos se utilizem da memória, diminuindo
ou retardando a fragmentação.
-
First-fit: esta estratégia aloca o programa na primeira partição que o couber,
independente do espaço livre que vai deixar. Das três estratégias, esta é a mais
rápida, consumindo menos recursos do sistema.
7.8
Swapping
É uma técnica aplicada à gerência de memória que visa dar maior taxa de utilização à
memória principal, melhorando seu compartilhamento. Visa também resolver o problema da
falta de memória principal num sistema.
Toda vez que um programa precisa ser alocado para execução e não há espaço na
memória principal, o sistema operacional escolhe entre os processos alocados que não tem
previsão de utilizar a CPU nos próximos instantes (quase sempre entre aqueles que estão em
39
interrupção de E/S ou no final da fila de pronto), e “descarrega” este processo da memória para
uma área especial em disco, chamada arquivo de swap, onde o processo fica armazenado
temporariamente. Durante o tempo em que o processo fica em swap, o outro que necessitava
de memória entra em execução ocupando o espaço deixado pelo que saiu. Pouco antes de
chegar a vez do processo armazenado em swap utilizar a CPU, o sistema escolhe um outro
processo para descarregar para swap e devolve o anterior da área de swap para a memória
principal, para que este possa ser executado novamente. E vai trabalhando assim até que os
processos vão terminando. O problema dessa técnica é que pode provocar um número
excessivo de acesso à memória secundária (disco), levando o sistema a uma queda de
desempenho.
7.9
Memória Virtual
Anteriormente foram apresentadas diversas técnicas de gerenciamento de memória que
evoluíram no sentido de maximizar o número de processos residentes na memória principal e
reduzir o problema da fragmentação, porém os esquemas vistos se mostraram muitas vezes
ineficientes. Além disso, o tamanho dos programas e de suas estruturas de dados estava
limitado ao tamanho da memória disponível. Como vimos, a utilização da técnica de overlay para
contornar este problema é de difícil implementação na prática e nem sempre uma solução
garantida e eficiente.
Memória virtual é uma técnica sofisticada e poderosa de gerência de memória onde as
memórias principal e secundária são combinadas, dando ao usuário a impressão de que existe
muito mais memória do que a capacidade real de memória principal.
O conceito de memória virtual baseia-se em não vincular o endereçamento feito pelo
programa aos endereços físicos da memória principal. Desta forma, o programa e suas
estruturas de dados deixam de estar limitados ao tamanho da memória física disponível, pois
podem possuir endereços vinculados à memória secundária, que funciona como uma extensão
da memória principal.
Outra vantagem desta técnica é permitir um número maior de processos compartilhando
a memória principal, já que apenas partes de cada processo estarão residentes. Isto leva a uma
utilização mais eficiente do processador, além de minimizar (ou quase eliminar) o problema da
fragmentação.
A seguir, os conceitos que envolvem a gerência de memória virtual, incluindo a
paginação:
- espaço de endereçamento virtual: é o conjunto de endereços virtuais que um
processo pode endereçar.
-
Espaço de endereçamento real: analogamente, é o conjunto de endereços reais que
um processo pode endereçar.
40
-
Mapeamento: como o espaço de endereçamento virtual não tem nenhuma relação
com o espaço de endereçamento real, um programa pode fazer referência a um
endereço virtual que esteja fora dos limites da memória principal (real), ou seja, os
programas e suas estruturas de dados não estão mais limitados ao tamanho da
memória física disponível. Quando um programa é executado, apenas uma parte do
seu código fica residente na memória principal, permanecendo o restante na memória
virtual até o momento de ser referenciado. Este esquema de endereçamento virtual é
ignorado pelo programador no desenvolvimento das aplicações. Cabe ao compilador e
ao linkeditor gerar códigos executáveis em função do endereçamento virtual, e o
sistema operacional se incumbe de administrar os detalhes durante a sua execução. O
processador apenas executa instruções e referencia dados residentes no espaço de
endereçamento real. Portanto, deve existir um mecanismo que transforme os
endereços virtuais em endereços reais. Este mecanismo é o que chamamos de
mapeamento, e consiste em permitir a tradução do endereço virtual em endereço real.
Como conseqüência, um programa não mais precisa estar necessariamente em
endereços contíguos na memória real para ser executado.
-
Tabela de endereçamento de páginas: estrutura mantida pelo sistema para armazenar,
entre outras informações, o mapeamento. É única e exclusiva para cada processo,
relacionando os endereços virtuais do processo ás suas posições na memória real.
-
Memória virtual por paginação: é a técnica de gerência de memória onde o espaço de
endereçamento virtual e o espaço de endereçamento real são divididos em blocos do
mesmo tamanho chamados páginas. As páginas do espaço virtual são chamadas
páginas virtuais, enquanto as páginas do espaço real são chamadas páginas reais ou
frames.
-
Page fault: é a falha de página. Sempre que o processo referencia um endereço
virtual, o sistema verifica se a página correspondente já está carregada na memória
real. Se não estiver, acontece o page fault. Neste caso, o sistema deve transferir a
página virtual para um endereço na memória real. Esta transferência é chamada de
paginação. O número de page faults gerados por um processo em um determinado
intervalo de tempo é chamado de taxa de paginação do processo. Se esta taxa atingir
valores elevados, pode haver um comprometimento do desempenho do sistema. Um
page fault provoca uma interrupção no processo, pois há a necessidade de acessar
operações de E/S. Assim, sempre que acontece a paginação, uma interrupção de E/S
fará com que o processo em execução seja interrompido e colocado em estado de
espera até que sua intervenção de E/S seja realizada, quando então o processo
voltará à fila de pronto e entrará em execução de acordo com o escalonamento
normal. Enquanto o sistema trata a interrupção deste processo, um outro ocupará a
CPU.
41
-
Working-set: é o conjunto de páginas de um processo, em memória real, em um
determinado instante. Este conceito surgiu com o objetivo de reduzir o problema do
thrashing e está relacionado ao princípio da localidade. Existem dois tipos de
localidade que são observados durante a execução da maioria dos programas. A
localidade espacial é a tendência de que, após uma referência a um endereço de
memória, sejam realizadas novas referências a endereços próximos ou adjacentes. A
localidade espacial é a tendência de que, após a referência a uma posição de
memória, esta mesma posição seja referenciada novamente num curto intervalo de
tempo. A partir desse princípio de localidade, o processador tenderá a concentrar suas
referências a um conjunto de páginas do processo durante um determinado período
de tempo. Imagine um loop principal de um programa que ocupe três páginas. A
tendência é que estas três páginas tenham um alto índice de referências durante a
execução do programa.
-
Thrashing: é o efeito causado pelo excesso de page faults durante a execução de um
processo. Pode acontecer a nível de programa ou de sistema. A nível de programa,
pode ser provocado por um programa mal escrito, com desvios incondicionais
espalhados por seu código (desobedecendo portanto aos princípios da localidade), ou
por um limite de working-set muito pequeno (que não comporte o loop principal do
programa, por exemplo). A solução para estes casos é reescrever o programa ou
aumentar o limite do working-set. No caso de thrashing de sistema, significa que há
mais páginas sendo requeridas na memória real do que ela pode realmente suportar.
A solução é aumentar o tamanho da memória física.
-
Tamanho da página: deve estar entre 512 bytes e 128KB, aproximadamente. Páginas
menores promovem maior compartilhamento da memória, permitindo que mais
programas possam ser executados. Páginas maiores diminuem o grau de
compartilhamento da memória, com menos programas disputando o processador.
Assim conclui-se que quanto menor o tamanho da página, MAIOR é o grau de
compartilhamento da memória e da CPU.
-
Políticas de busca de páginas: definem como as páginas serão carregadas da memória
virtual para a memória real. A política por demanda estabelece que uma página
somente será carregada quando for referenciada. Este mecanismo é conveniente, pois
leva para a memória real somente as páginas realmente necessárias à execução do
programa, ficando as outras na memória virtual. A outra política, chamada paginação
antecipada, funciona carregando antecipadamente várias páginas da memória virtual
para a principal, na tentativa de economizar tempo de E/S. Nem sempre o sistema
acerta na antecipação, mas o índice de acertos é quase sempre maior que o de erros.
Políticas de alocação de páginas: determinam quantos frames cada processo pode
manter na memória real. A política de alocação fixa determina um limite de workingset igual para todos os processos, e pode ser vista como uma política injusta, na
medida em que processos maiores normalmente necessitam de um working-set maior.
A outra política é a variável, que define um limite de working-set diferente e variável
-
42
para cada processo, em função de seu tamanho, taxa de paginação ou até mesmo da
taxa de ocupação da memória principal.
-
Políticas de substituição de páginas: definem onde serão trocadas as páginas, quando
se fizer necessária uma substituição. Na política local, somente as páginas do
processo que gerou o page fault são candidatas a serem substituídas.Já na política
global, todas as páginas alocadas na memória principal são candidatas à substituição,
independente do processo que gerou o page fault. Como uma página de qualquer
processo pode ser escolhida, pode ser que este processo sofra um aumento
temporário da taxa de paginação em função da diminuição das suas páginas alocadas
em memória.
7.10 Algoritmos de substituição de páginas
O maior problema na gerência de memória virtual por paginação não é decidir quais
páginas carregar para a memória real, mas sim quais páginas liberar. Quando há a necessidade
de carregar uma página, o sistema deve selecionar entre as diversas páginas alocadas na
memória qual delas deverá ser liberada pelo processo.
Os algoritmos de substituição de páginas têm o objetivo de selecionar os frames que
tenham as menores chances de serem referenciados num futuro próximo. Caso contrário, o
frame poderia retornar diversas vezes para a memória real, provocando excesso de page faults.
São algoritmos de substituição de páginas:
-
algoritmo ótimo: impossível de ser implementado, pois o processador não consegue
prever com segurança qual frame não será mais referenciado durante a execução do
programa. Tal fato deve-se à lógica do programa e aos dados que ele manipula,
desconhecidos pelo processador.
-
Algoritmo aleatório: escolhe qualquer página, entre as alocadas na memória, para
fazer a substituição. Em função de sua baixa eficiência, este algoritmo não muito
utilizado, embora consuma poucos recursos do sistema.
-
Algoritmo FIFO (first in, first out): escolhe a página que está há mais tempo na
memória principal para fazer a troca. É um algoritmo de simples implementação, mas
corre o risco de retirar uma página que, embora tenha sido carregada há mais tempo,
esteja sendo muito utilizada. Por essa razão não é muito usado.
Algoritmo LFU (least frequently used): elege a página menos freqüentemente usada
para efetuar a troca. Através de um contador, armazenado na tabela de
endereçamento de páginas, mo sistema identifica quantas referências cada página
teve e utiliza esta informação para escolher a página.
-
43
-
Algoritmo LRU (least recently used): elege a página menos recentemente usada para
fazer a troca. O sistema mantém na tabela de endereçamento de páginas um campo
onde são armazenadas a data e a hora da última referência de cada página, e com
base nestas informações faz a seleção.
-
Algoritmo NRU (not recently used): elege a página menos recentemente usada para
efetuar a troca. O sistema exclui da decisão a página mais recente e escolhe entre as
outras, pelo método FIFO, qual página deve sair.
44
8. Gerência de Sistemas de Arquivos
8.1
Estrutura de Diretórios
É como o Sistema organiza logicamente os arquivos. Contém entradas associadas aos
arquivos, com as informações de localização, nome, organização e outros atributos:
•
Nível único: é a implementação mais simples de uma estrutura de diretórios, onde
existe um único diretório contendo todos os arquivos do disco. É muito limitado, não
permitindo a criação de arquivos com o mesmo nome.
•
Diretório pessoal: Evolução do modelo anterior, permite a cada usuário ter ser
“diretório” particular, sem a preocupação de conhecer os outros arquivos do disco. Neste
modelo há um diretório “master” que indexa todos os diretórios particulares dos usuários,
provendo o acesso a cada um.
•
Múltiplos níveis (ÁRVORE): É o modelo utilizado hoje em dia em quase todos os
Sistemas Operacionais. Nesta modalidade cada usuário pode criar vários níveis de
diretórios (ou sub-diretórios), sendo que cada diretório pode conter arquivos e subdiretórios. O número de níveis possíveis depende do Sistema Operacional.
8.2
Sistemas de alocação de arquivos
•
FAT: sistema criado no MS-DOS e depois utilizado no Windows. Usa listas
encadeadas, tem um limite de área utilizável em partições de 2 GB, caracteriza-se por um
baixo desempenho no acesso e armazenamento.
•
FAT32: igual ao FAT no que diz respeito a organização e desempenho, mas pode
trabalhar com partições de até 2TB.
•
NTFS: NT File System, original da plataforma Windows NT/2000/XP. Opera com
uma estrutura em árvore binária, oferecendo alto grau de segurança e desempenho:
-
•
nomes de arquivo com até 255 caracteres, podendo conter maiúsculas, minúsculas
e espaços em branco;
dispensa ferramentas de recuperação de erros;
bom sistema de proteção de arquivos;
criptografia;
suporta discos de até 264 bytes.
UNIX: Usa diretório hierárquico, com um raiz e outros diretórios subordinados.
Neste Sistema Operacional todos os arquivos são considerados apenas como uma
“seqüência” de bytes, sem significado para o Sistema. É responsabilidade da aplicação
45
controlar os métodos de acesso aos arquivos. O UNIX utiliza também alguns diretórios
padronizados, de exclusividade do Sistema.
8.3
Gerência de espaço livre
São três as formas de se implementar estruturas de espaços livres. Uma delas é através
de uma tabela denominada mapa de bits, onde cada entrada da tabela é associada a um bloco
do disco representado por um bit, que estando com valor 0 indica que o espaço está livre, e
com valor 1 representa um espaço ocupado. Gasta muita memória, pois para cada bloco do
disco há uma entrada na tabela.
A segunda forma é utilizando uma lista encadeada dos blocos livres do disco. Desse
modo, cada bloco possui uma área reservada para armazenar o endereço do próximo bloco
livre. Apresenta problemas de lentidão no acesso, devido às constantes buscas seqüenciais na
lista.
A terceira forma é a tabela de blocos livres. Nesta, leva em consideração que blocos
contíguos de dados geralmente são alocados/liberados simultaneamente. Desta forma, pode-se
enxergar o disco como um conjunto de segmentos de blocos livres. Assim, pode-se manter uma
tabela com o endereço do primeiro bloco de cada segmento e o número de blocos contíguos
que se seguem.
-
Alocação contígua: armazena o arquivo em blocos seqüencialmente dispostos no
disco. O arquivo é localizado através do endereço do primeiro bloco de sua
extensão em blocos. O principal problema neste tipo de alocação é a existência de
espaço livre para novos arquivos, que deve ser contígua. Utiliza as estratégias
best-fit, worst-fit e first-fit (já conhecidas) para definir onde o arquivo será
alocado. Causa alto índice de fragmentação no disco.
-
Alocação encadeada: nesta modalidade o arquivo é organizado como um conjunto
de blocos ligados logicamente no disco, independente de sua localização física,
onde cada bloco possui um ponteiro para o bloco seguinte. A fragmentação não
representa problemas na alocação encadeada, pois os blocos livres para alocação
do arquivo não necessariamente precisam estar contíguos. O que acontece é a
quebra do arquivo em vários pedaços, o que aumenta o tempo de acesso. Neste
tipo de alocação só se permite acesso seqüencial aos blocos do arquivo, sendo
esta uma das principais desvantagens da técnica. Outra desvantagem é a perda de
espaço nos blocos com o armazenamento dos ponteiros.
-
Alocação indexada: esta técnica soluciona a limitação da alocação encadeada, no
que diz respeito ao acesso, pois permite acesso direto aos blocos do arquivo. Isso
é conseguido mantendo-se os ponteiros de todos os blocos do arquivo em uma
única estrutura chamada bloco de índice. Este tipo de alocação, além de permitir
acesso direto aos blocos, não utiliza informações de controle nos blocos de dados.
46
8.4
Proteção de acesso
Considerando-se que os meios de armazenamento são compartilhados por vários
usuários, é fundamental que mecanismos de proteção sejam implementados para garantir a
integridade e proteção individual dos arquivos e diretórios:
-
Senha de acesso: mecanismo de simples implementação, mas apresenta duas
desvantagens: não é possível determinar quais os tipos de operação podem ser
efetuadas no arquivo, e, se este for compartilhado, todos os usuários que o
utilizam devem conhecer a senha de acesso.
-
Grupos de usuário: é muito utilizada em muitos Sistemas Operacionais. Consiste
em associar cada usuário a um grupo. Os grupos são organizados logicamente
com o objetivo de compartilhar arquivos e diretórios no disco. Este mecanismo
implementa três níveis de proteção: OWNER (dono), GROUP (grupo) e ALL
(todos). Na criação do arquivo o usuário especifica se o arquivo pode ser acessado
somente pelo seu criador, pelo grupo ou por todos os usuários, além de definir que
tipos de acesso podem ser realizados (leitura, escrita, execução e eliminação)
-
Lista de controle de acesso: é uma lista associada ao arquivo onde são
especificados quais os usuários e os tipos de acesso permitidos. O tamanho
dessa estrutura pode ser bastante extenso se considerarmos que um arquivo
pode ser compartilhado por vários usuários. Além deste problema, há o
inconveniente de se fazer acesso seqüencial à lista toda vez que um acesso é
solicitado. Em determinados sistemas de arquivos pode-se utilizar uma
combinação de proteção por grupos de usuários ou por listas de acesso,
oferecendo assim maior flexibilidade ao mecanismo de proteção de arquivos e
diretórios.
47
9. BIBLIOGRAFIA
Arquitetura de Sistemas Operacionais
Francis B. Machado
Ed. LTC
Sistemas Operacionais: Conceitos e Aplicações
Abraham Silberschatz
Ed. Campus
Sistemas Operacionais Modernos
A.S. Tanenbaum
Ed. Campus
48