Universidade Federal do Pará
Instituto de Ciências Exatas e Naturais
Faculdade de Computação
Curso de Especialização em Sistemas de Banco de Dados
Cristiane Neves Kasahara
Fernando Wilson Sousa Conceição
“ANÁLISE DE FERRAMENTAS DE MINERAÇÃO DE DADOS”
Belém - PA
2008
Universidade Federal do Pará
Instituto de Ciências Exatas e Naturais
Faculdade de Computação
Curso de Especialização em Sistemas de Banco de Dados
Cristiane Neves Kasahara
Fernando Wilson Sousa Conceição
“ANÁLISE DE FERRAMENTAS DE MINERAÇÃO DE DADOS”
Monografia apresentada à Universidade Federal do
Pará como requisito parcial para obtenção do grau de
Especialista em Sistemas de Banco de Dados.
Professora Orientadora: MSc. Miriam Lúcia Campos
Serra Domingues.
Belém - PA
2008
ii
Universidade Federal do Pará
Instituto de Ciências Exatas e Naturais
Faculdade de Computação
Curso de Especialização em Sistemas de Banco de Dados
Cristiane Neves Kasahara
Fernando Wilson Sousa Conceição
Monografia apresentada para obtenção do título
de Especialista em Sistemas de Banco de Dados.
Atribuo conceito excelente à Monografia apresentada no dia 25 de abril de 2008, pelos alunos:
Cristiane Neves Kasahara e Fernando Wilson Sousa Conceição, intitulada Análise de
Ferramentas de Mineração de Dados.
Belém, 25 de abril de 2008.
_________________________________________________________
Orientadora: Profª MSc. Miriam Lúcia C. S. Domingues
Belém - PA
2008
iii
SUMÁRIO
1. INTRODUÇÃO ...................................................................................................................................... 10
1.1 MOTIVAÇÃO ....................................................................................................................................... 10
1.2 OBJETIVOS .......................................................................................................................................... 10
1.2.1 Geral .......................................................................................................................................... 10
1.2.2 Específico................................................................................................................................... 10
1.3 DESCRIÇÃO ......................................................................................................................................... 11
2. DESCOBERTA DE CONHECIMENTO EM BASE DE DADOS OU MINERAÇÃO DE DADOS
...................................................................................................................................................................... 12
2.1 CONCEITO DE DCBD.......................................................................................................................... 12
2.2 DEFINIÇÃO DE MINERAÇÃO DE DADOS .............................................................................................. 13
2.3 ETAPAS DO PROCESSO DE MINERAÇÃO DE DADOS OU DCBD............................................................ 14
2.3.1 Identificação do Problema......................................................................................................... 15
2.3.2 Pré-processamento .................................................................................................................... 15
2.3.3 Extração de Padrões.................................................................................................................. 16
2.3.4 Pós-processamento .................................................................................................................... 18
2.3.5 Utilização do conhecimento....................................................................................................... 20
3.
REGRAS ASSOCIATIVAS ............................................................................................................. 21
3.1 ALGORITMO APRIORI .......................................................................................................................... 21
4. FERRAMENTAS ................................................................................................................................... 24
4.1 WEKA ............................................................................................................................................... 24
4.2 TANAGRA........................................................................................................................................ 32
5. ESTUDO DE CASO ............................................................................................................................... 39
5.1 COMPREENSÃO DO DOMÍNIO DA APLICAÇÃO ...................................................................................... 39
5.1.1 Cenário ...................................................................................................................................... 39
5.1.2 Dados gerais da empresa........................................................................................................... 39
5.1.3 Definições dos testes bioquímicos utilizados ............................................................................. 39
5.2 ESCOLHA DAS FERRAMENTAS E TAREFAS UTILIZADAS........................................................................ 43
5.3 DESCRIÇÃO DO PROCESSO DE MINERAÇÃO DE DADOS APLICADO AO PROBLEMA ................................ 43
5.3.1 Identificação do Problema......................................................................................................... 43
5.3.2 Pré-Processamento .................................................................................................................... 43
5.3.3 Extração e Integração................................................................................................................ 44
5.3.4 Transformação........................................................................................................................... 44
5.3.5 Extração de Padrões.................................................................................................................. 45
5.3.6 Escolha da Tarefa ...................................................................................................................... 45
5.3.7 Escolha do Algoritmo ................................................................................................................ 45
5.3.8 Parâmetros Utilizados ............................................................................................................... 45
5.3.9 Resultados.................................................................................................................................. 46
5.4 AVALIAÇÃO DO RESULTADO .............................................................................................................. 50
5.5 COMPARAÇÃO DAS FERRAMENTAS ..................................................................................................... 51
5.5.1 Interface ..................................................................................................................................... 51
5.5.2 Facilidade de uso....................................................................................................................... 53
5.5.3 Apresentação dos Resultados..................................................................................................... 54
5.5.4 Resultados obtidos ..................................................................................................................... 54
6. CONSIDERAÇÕES FINAIS................................................................................................................. 55
REFERÊNCIAS ......................................................................................................................................... 56
iv
LISTAS DE TABELAS
Tabela 4.1 - Opções de Parâmetros.....……………………………………......…........... 21
Tabela 5.1 - Dados coletados……………………………………………….....…........... 35
Tabela 5.2 - Dados modificados…………………………………………....……........... 36
v
LISTA DE FIGURAS
Figura 2.1 - Fases de um processo de Mineração de Dados.............................................. 5
Figura 2.2 - Atividades e tarefas de Mineração de Dados.......................................... ...... 8
Figura 3.1 - Algoritmo Apriori.................................................................................. ...... 13
Figura 4.1 - Tela Inicial do Weka.............................................................................. ...... 15
Figura 4.2 - Pré-processamento................ ............................................................... ....... 16
Figura 4.3 - Abrir arquivo................................................................................................ 17
Figura 4.4 - Base de Dados carregada.............................................................................. 17
Figura 4.5 - Filtros............................................................................................................ 18
Figura 4.6 - Parâmetros de discretização................................................................... ...... 18
Figura 4.7 - Interface do Associate Weka ............................................................... ...... 20
Figura 4.8 - Tela para alteração de parâmetros........................................................ ....... 21
Figura 4.9 - Resultados obtidos do Associate Weka................................................ ....... 22
Figura 4.10 - Tela Inicial Tanagra............................................................................ ...... 23
Figura 4.11 - Abrir um arquivo novo....................................................................... ....... 23
Figura 4.12 - Diretório............................................................................................. ....... 24
Figura 4.13 - Define Status...................................................................................... ....... 24
Figura 4.14 - Define Atributos.................................................................................. ...... 25
Figura 4.15 - a) Botão Adicionar b) Campos transferidos....................................... ....... 25
Figura 4.16 - Executa Definir Status........................................................................ ...... 26
Figura 4.17 - Visualizar os atributos......................................................................... ...... 26
Figura 4.18 - View Dataset…………….……………………...……......….....…..... ...... 27
Figura 4.19 - Define Status 2…………..…………………………….......….….…. ...... 27
Figura 4.20 - 2) Parâmetros 3) definir parâmetros 4) executar 5)Visualizar................... 28
Figura 4.21 - Resultados obtidos............................................................................... ...... 29
Figura 5.1 - Valores de referência.................................................................................... 33
Figura 5.2 - Diferença entre artéria normal e artéria bloqueada................................ ...... 33
Figura 5.3 - Tela de pré-processamento................................................................... ....... 43
Figura 5.4 - Interface do Tanagra............................................................................ ....... 44
vi
LISTA DE ABREVIATURAS E SIGLAS
DCBD - Descoberta de Conhecimento em Bases de Dados
HDL - Colesterol de alta densidade
IPAMB - Instituto de Previdência e Assistência do Município de Belém
LDL - Colesterol de baixa densidade
MD - Mineração de Dados
KDD - Knowledge Discovery in Databases
KNN - K-Nearest Neighbor
URL - Uniforme Resource Locate
VLDL - Colesterol de muito baixa densidade
WEKA - Waikato Environment for Knowledge Analysis
vii
RESUMO
A Mineração de Dados tem sido muito utilizada por diversas empresas e
instituições de pesquisa para obter conhecimento útil de suas bases de dados, que possa
ser de extrema importância na tomada de decisões estratégicas em cada área de atuação.
Para viabilizar este mecanismo, são necessárias ferramentas capazes de realizar tal
procedimento.
Com o propósito de suprir esta demanda, várias ferramentas foram desenvolvidas,
outras estão em processo de desenvolvimento ou em fase de estudo.
A partir dessas informações, resolvemos analisar duas ferramentas de Mineração
de Dados, o Weka e o Tanagra, utilizando uma mesma base de dados, com os mesmos
parâmetros, realizando a comparação da interface, da facilidade de uso, da apresentação
dos resultados e dos resultados obtidos.
O Weka apresentou melhor interface e maior facilidade de uso em relação ao
Tanagra, na análise dos autores. Os resultados obtidos com as duas ferramentas foram
considerados equivalentes.
Palavras-chaves: Descoberta de Conhecimento em Bases de Dados, Mineração
de Dados, Weka, Tanagra, Laboratório de Análises Clínicas.
viii
ABSTRACT
Data Mining has been widely used by various companies and research institutions
to gain useful knowledge from their databases, which may be of extreme importance in
making strategic decision in each area of activity. To facilitate this mechanism, capable
tools are necessary that make such a procedure.
In order to meet this demand, several tools were developed, some still in the
process of development or in study phase.
From this information, we analyze two Data Mining tools, the Weka and Tanagra,
using the same database, with the same parameters, performing a comparison of the
interface, ease of use, the presentation of results and the obtained results.
The Weka presented better interface and ease of use in relation to Tanagra, in the
authors’ analysis. The results obtained with the two tools were considered equivalent.
Word-keys: Knowledge Discovery in Databases, Data Mining, Weka, Tanagra,
Laboratory of Clinics Analysis.
ix
1. INTRODUÇÃO
A Mineração de Dados (MD) consiste na exploração e análise de dados, por
meios automáticos e semi-automáticos, em grandes quantidades de dados, com o objetivo
de descobrir regras ou padrões interessantes (descoberta de conhecimento) implícitos
nesses dados. Pode ser aplicada nas mais diversas áreas do conhecimento. Neste estudo, a
Mineração de Dados foi utilizada não somente para fornecer uma solução para um
problema em um laboratório de análises clínicas, mas também para testar a performance
das ferramentas em questão.
1.1 Motivação
O avanço tecnológico e a evolução da computação proporcionaram um aumento
na capacidade de armazenamento e processamento de dados, assim como o
desenvolvimento de inúmeros softwares capazes de extrair padrões interessantes dessas
bases de dados.
Com os avanços das pesquisas para se construir ferramentas cada vez mais
habilitadas para a obtenção de conhecimento útil, torna-se possível fazer a comparação
das mesmas, utilizando-se uma mesma base de dados.
1.2 Objetivos
1.2.1 Geral
O objetivo geral é conhecer, estudar e comparar duas ferramentas de MD,
mostrando suas funcionalidades e diferenças, vantagens e desvantagens.
1.2.2 Específico
Os objetivos específicos são: comparar a interface, a facilidade de uso, a
apresentação dos resultados e os resultados obtidos, utilizando para isso a tarefa de regras
associativas em uma mesma base de dados: a base de dados do Instituto de Previdência e
Assistência do Município de Belém (IPAMB), a qual contém dados de pacientes que são
considerados de risco, de acordo com as alterações de testes bioquímicos que podem
levar a um possível infarto.
10
1.3 Descrição
O trabalho está dividido em seis capítulos:
Neste capítulo, é apresentada uma introdução ao tema a ser abordado, a
motivação, os objetivos do texto e uma breve descrição da disposição dos capítulos.
O segundo capítulo é composto por uma fundamentação teórica sobre Descoberta
de Conhecimento e Mineração de Dados.
O terceiro capítulo trata da tarefa de Mineração de Dados utilizada nesta pesquisa,
que é a tarefa de Regras Associativas realizada com o algoritmo Apriori.
No quarto capítulo são apresentadas as ferramentas Weka e Tanagra, utilizadas
durante o processo de MD, onde são abordadas suas características, forma de uso, etc.
O quinto capítulo traz o estudo de caso realizado com os dados coletados no
Laboratório de Análises Clínicas do IPAMB, com o propósito de comparar as
ferramentas.
No sexto capítulo são apresentadas as considerações finais da pesquisa.
11
2. DESCOBERTA DE CONHECIMENTO EM BASE DE DADOS OU
MINERAÇÃO DE DADOS
Frente à grande demanda de informações geradas e armazenadas em diversos
repositórios distribuídos e distintos, a Descoberta de Conhecimento em Bases de Dados DCBD (Knowledge Discovery in Databases – KDD), surge como uma solução para o
bom aproveitamento de tanta informação, a qual precisa ser utilizada e propagada.
Alguns autores consideram os termos DCBD e MD referentes a processos
distintos, já que o segundo termo faz parte de um processo maior (DCBD). Porém a
expressão Mineração de Dados é mais popular e muitas vezes utilizada como sinônimo
de DCDB.
2.1 Conceito de DCBD
O termo DCBD, formalizado em 1989, se refere ao amplo conceito de procurar
conhecimento a partir de bases de dados. O principal objetivo de um processo de
Descoberta de Conhecimento de Base de Dados foi resumido em um conceito proposto
em 1996, que é aceito por diversos pesquisadores, em que a extração de conhecimento de
base de dados é o processo utilizado para identificar padrões válidos, novos,
potencialmente úteis e compreensíveis embutidos nos dados (Fayyad et al.,1996). Para
melhor esclarecimento, será dada a definição de cada item citado acima:
• Dados: Conjunto de fatos ou casos em um repositório de dados. Como exemplo, os
dados correspondem aos valores dos campos de um resultado de um exame
laboratorial.
• Padrões: Por intermédio de um subconjunto dos dados, denota-se alguma abstração
em alguma linguagem descritiva de conceitos.
• Processo: Refere-se às diversas etapas para a extração de conhecimento de bases de
dados, como a preparação dos dados, busca por padrões e avaliação do
conhecimento.
12
• Válidos: Os padrões descobertos devem satisfazer funções ou limiares que
garantam que os exemplos cobertos e os casos relacionados ao padrão encontrado
sejam aceitáveis, ou seja, devem possuir algum grau de certeza.
• Novos: Novas informações sobre os dados utilizados devem ser fornecidas pelo
padrão encontrado. O padrão encontrado deve ser novo ou inédito e isto é
determinado pelo grau de novidade, que pode ser medido por meio de
comparações entre as mudanças ocorridas nos dados ou no conhecimento
anterior.
• Úteis: Os padrões descobertos no processo de extração de conhecimento devem ser
incorporados para serem utilizados em ações de processos de tomada de decisões
estratégicas.
• Compreensíveis: Encontrar padrões compreensíveis significa encontrá-los em
alguma linguagem que pode ser compreendida pelos usuários permitindo, desta
forma, uma análise mais profunda dos dados.
• Conhecimento: O conhecimento depende da área de estudo em questão e está
relacionado fortemente com medidas de utilidade, originalidade e compreensão.
2.2 Definição de Mineração de Dados
No presente estudo, a definição adotada está conforme Mount (2001), a qual
define Mineração de Dados como uma técnica, cujo objetivo é proporcionar ao usuário
final suporte à tomada de decisão, uma vez que se tem uma grande base de dados, mas
impossível, ao analista humano, tomar por si só, uma decisão. Esse é um processo
interativo entre homem e máquinas, no qual um precisa do outro, ou seja, após a
mineração precisa-se de um especialista do domínio para fazer análise dos dados válidos,
estabelecendo uma interdependência.
13
2.3 Etapas do Processo de Mineração de Dados ou DCBD
A partir deste tópico, o termo DCBD será substituído por Mineração de Dados,
uma vez que é o mais utilizado entre os autores e pesquisadores do ramo, como já citado
acima.
Não existe uma convenção que determine a quantidade exata de etapas do
processo de mineração de dados. Os primeiros estudos, como o de Fayyad et al. (1996),
descrevem o processo formado por nove etapas, outros descrevem cinco etapas (Mount,
2001) e outros em quatro fases (Weiss, 1998).
As fases de Mineração de Dados que serão abordadas a seguir, terão como base
Rezende (2003), que define o processo dividido em três grandes etapas – préprocessamento, extração de padrões e pós-processamento (Figura 2.1). São incluídas
nessa divisão uma fase anterior ao processo, que se refere ao conhecimento do domínio e
identificação do problema e uma fase posterior, que se refere à utilização do
conhecimento obtido.
Utilização do Conhecimento
COCOCCOCONHECI
Conhecimento
Pós-Processamento
Extração de Padrões
Escolha da Tarefa
Escolha do Algoritmo
Extração de Padrões
Pré-Processamento
Seleção
Extração e Integração
Transformação
Banco
de
Dados
?
Seleção e Redução de dados
Identificação do problema
Figura 2.1 Fases de um processo de Mineração de Dados
14
2.3.1 Identificação do Problema
Antes de iniciar as tarefas do processo de descoberta, é de fundamental
importância adquirir conhecimento a respeito do domínio. Por este motivo, o especialista
do domínio é um ponto chave para o processo de extração de conhecimento e no apoio
aos analistas em seu objetivo de encontrar padrões.
Conhecer o domínio é crucial para fornecer subsídios para todas as etapas do
processo de extração e aos analistas, pois entendê-lo é um pré-requisito para extrair algo
útil. Nesta fase é interessante analisar as principais metas do processo; os critérios de
desempenho importantes; o conhecimento extraído, se é compreensível a seres humanos
ou não; a relação entre a simplicidade e a precisão do conhecimento extraído.
2.3.2 Pré-processamento
Nesta fase, aplicam-se métodos para tratamento, limpeza e redução do volume de
dados, antes de iniciar a etapa de extração de padrões, já que os dados disponíveis para
análise nem sempre estão em um formato adequado e podem apresentar problemas em
razão de limitações de memória ou tempo de processamento dos computadores, muitas
vezes não sendo possível a aplicação direta dos algoritmos de mineração de dados.
A realização dessas modificações deverá ser feita com base nos objetivos do
processo de extração. Essas alterações que podem ser efetuadas na etapa de préprocessamento são: extração e integração, transformação, limpeza, seleção e redução de
dados. É válido ressaltar que nem todas essas modificações são necessárias.
2.3.2.1 Extração e Integração
Na extração e integração, os dados disponíveis irão passar por um processo de
unificação, já que os mesmos podem estar dispostos em diferentes fontes, como:
arquivos-texto, arquivos no formato de planilhas, banco de dados ou Data Warehouses,
sendo então essencial que esses dados sejam transformados para uma única fonte de
dados no formato atributo-valor que será utilizada como entrada para os algoritmos de
extração de padrões.
15
2.3.2.2 Transformação
Após a fase de extração e integração dos dados, algumas transformações comuns
podem ser aplicadas aos dados, a fim de que se tornem adequados para serem utilizados
nos algoritmos de extração de padrões, e dentre elas tem-se: resumo, transformação de
tipo e normalização de atributos contínuos, tornando assim os dados no formato
apropriado para o processo de mineração.
2.3.2.3 Limpeza
Os dados utilizados para a extração de padrões podem apresentar problemas
oriundos do processo de coleta, que podem ser erros de digitação ou erro na leitura dos
dados coletados. Nesta fase, é feita uma análise de integridade e consistência dos dados,
removendo-se entradas espúrias e erros, preenchendo-se valores ausentes e solucionandose inconsistências entre as bases, de forma a gerar uma base única. A técnica de limpeza
garante a qualidade dos dados, fator extremamente importante, já que o resultado do
processo de extração, provavelmente, será utilizado em um processo de tomada de
decisão.
2.3.2.4 Seleção e Redução de Dados
A seleção e a redução de dados vêm solucionar o problema da inviabilidade da
utilização de algoritmos de extração de padrões, devido o número de exemplos e
atributos disponíveis ser inviáveis para análise, em virtude das restrições de espaço em
memória ou tempo de processamento. Para isso, é necessária a aplicação de alguns
métodos tais como redução do número de exemplos, do número de atributos ou do
número de valores de um atributo, para diminuir a quantidade de dados antes de iniciar a
busca pelos padrões.
2.3.3 Extração de Padrões
Esta etapa tem como finalidade o cumprimento dos objetivos definidos na
identificação do problema, compreendendo a escolha da tarefa de Mineração de Dados a
ser empregada, a escolha do algoritmo a ser utilizado e a extração dos padrões
propriamente dita. Por ser um processo iterativo, pode ser necessário que seja executada
diversas vezes para ajustar o conjunto de parâmetros, tendo em vista a obtenção de
16
resultados mais adequados aos objetivos preestabelecidos. É nesta etapa que se
submetem as bases de dados aos algoritmos de mineração escolhidos para extração dos
padrões embutidos nos dados.
2.3.3.1 Escolha da Tarefa
Segundo Rezende (2003), a escolha da tarefa depende dos objetivos desejáveis
para a solução a ser encontrada e essas tarefas podem ser agrupadas em Atividades
Preditivas e Descritivas. A Figura 2.2, abaixo mostra em como se divide estas atividades.
Figura 2.2 Atividades e tarefas de Mineração de Dados
- Atividades Preditivas
“...consistem na generalização de exemplos ou experiências passadas
com respostas conhecidas em uma linguagem capaz de reconhecer a classe de
um novo exemplo. Os dois principais tipos de tarefas para predição são
classificação e regressão. A classificação consiste na predição de um valor
categórico como, por exemplo, predizer se o cliente é bom ou mau pagador. Já
na regressão, o atributo a ser predito consiste em um valor contínuo como, por
exemplo, predizer o lucro ou perda em um empréstimo.” (Rezende, 2003).
- Atividades Descritivas
17
Consistem na identificação de comportamentos intrínsecos do conjunto de dados,
que não possuem uma classe especificada. Algumas das tarefas de descrição são
clustering, regras associativas e sumarização.
Após a escolha da tarefa, será realizada a definição do algoritmo de extração e a
posterior configuração de seus parâmetros.
2.3.3.2 Escolha do Algoritmo
Segundo Rezende (2003): “A escolha do algoritmo é realizada de forma
subordinada à linguagem de representação dos padrões a serem encontrados”. Essa
escolha está diretamente relacionada às tarefas de MD, citadas acima, que serão
utilizadas para a extração de padrões.
Um ponto importante é a complexidade da solução encontrada pelo algoritmo de
extração, diretamente relacionada à capacidade de representação do conceito embutido
nos dados. Se o modelo resultante tiver uma precisão boa para o conjunto de treinamento,
porém um desempenho ruim para novos exemplos, isso significa que os parâmetros do
algoritmo estão ajustados para encontrar soluções mais complexas que o conceito
efetivamente existente nos dados. Conclui-se então que o modelo é especifico para o
conjunto de treinamento, ocorrendo overfitting1 (Rezende, 2003).
Em contra partida ocorrerá underfitting2, se a solução que está sendo buscada não
for suficiente para adequar o conceito representado nos dados, podendo não ser, portanto,
o modelo induzido representativo. Nesse caso, é provável que o modelo encontrado não
tenha bom desempenho, tanto nos exemplos disponíveis para o treinamento, como para
novos exemplos. Devido a estes fatos, a configuração dos parâmetros do algoritmo deve
ser feita de forma criteriosa (Rezende, 2003).
2.3.4 Pós-processamento
Segundo Rezende (2003) na maioria das vezes, o conhecimento extraído é
utilizado na resolução de problemas da vida real, tanto por meio de um sistema
1
Overfiting (Mount, 2001): ocorre quando o erro (ou outra medida de desempenho) em um conjunto de
treinamento evidencia um desempenho ruim de hipótese.
2
Underfiting (Mount, 2001): quando é possível induzir hipóteses que apresentem uma melhora muito
pequena de desempenho no conjunto de treinamento, assim como em um conjunto de teste.
18
inteligente como por um ser humano, auxiliando algum processo de tomada de decisão. É
necessário, portanto, verificar se os dados extraídos por um sistema computacional
representam o conhecimento do especialista, visto que o mesmo pode diferir dos dados
extraídos e em que parte o conhecimento do especialista está correto.
Levando-se em consideração que os algoritmos podem gerar grandes quantidades
de padrões, pode acontecer deles não serem importantes, em sua maioria, para o usuário
final. Como não é viável e nem produtivo fornecer ao usuário final uma grande
quantidade de padrões, torna-se de extrema importância desenvolver algumas técnicas de
apoio no sentido de fornecer a eles apenas os padrões mais interessantes, já que,
normalmente, procuram apenas uma pequena lista de padrões que sejam relevantes.
Existem medidas para avaliação de conhecimento que têm por finalidade auxiliar
o usuário no entendimento e na utilização do conhecimento adquirido, podendo ser
divididas em dois tipos: medidas de qualidade e medidas de desempenho.
Para o processo de extração de conhecimento, a compreensibilidade é um aspecto
de máxima importância, relacionada à facilidade de interpretação dessas regras por um
ser humano, uma vez que um dos principais objetivos desse processo são a compreensão
e utilização do conhecimento descoberto.
Uma maneira de avaliar a qualidade, na tentativa de estimar-se o quanto de
conhecimento interessante existe, é a interessabilidade e deve realizar a combinação de
fatores que venham refletir como o especialista julga o padrão. As medidas de
interessabilidade baseiam-se em vários aspectos, principalmente, na utilidade que as
regras representam para o usuário final, divididas em objetivas e subjetivas.
As medidas objetivas estão relacionadas apenas com a estrutura dos padrões e do
conjunto de dados de teste, sem levar em consideração as especificidades do usuário nem
do conhecimento do domínio, para avaliar o padrão. Enquanto que as medidas subjetivas
são fundamentais quando os usuários finais manifestam diferentes graus de interesse para
um determinado padrão, pois estas medidas determinam que fatores específicos do
conhecimento do domínio e de interesse dos usuários devem ser tratados ao selecionar
um conjunto de regras interessantes aos usuários.
19
2.3.5 Utilização do conhecimento
Após a análise do conhecimento, na etapa de Pós-Processamento, este
conhecimento pode ser utilizado em um sistema inteligente ou como apoio em processos
de tomada de decisão. Caso este não venha suprir as necessidades do usuário final, não
cumprindo, portanto com os objetivos propostos, é necessário que o processo de extração
seja repetido, ajustando-se assim os parâmetros ou melhorando o processo de escolha dos
dados para obter resultados que realmente venham ser úteis numa próxima iteração.
20
3. REGRAS ASSOCIATIVAS
As Regras Associativas são utilizadas para representar um padrão de
relacionamento entre itens de dados do domínio da aplicação, que ocorrem com uma
determinada freqüência na base de dados. Por exemplo, em um banco de dado que
comporta milhares de itens, como aqueles existentes em grandes lojas de varejo, desejase descobrir associações importantes entre os itens comercializados, tal que a presença de
alguns deles em uma transação (compra e venda) implique na presença de outros na
mesma transação.
O objetivo da tarefa de regras associativas é encontrar todas as regras que
ofereçam informações relevantes, entre os itens W (antecedentes) e Z (conseqüentes) e
que estes itens sejam significativos e freqüentes, ou seja, devem estar dispostos em
quantidade no conjunto de dados com suporte acima de determinado valor e que
caracterizem bem a associação, tendo bom grau de confiança. Assim conclui-se que as
regras geradas devem atender a um suporte e confiança mínimos (Agrawal, 1993).
A freqüência com que ocorrem os padrões por toda base para conjuntos de itens é
chamada de suporte, ou seja, o número de transações que contêm esse conjunto de itens.
Enquanto que a medida da força da regra é chamada de confiança, que é a precisão da
regra.
O suporte mínimo (minsup) é a fração das transações que satisfaz a união dos
itens de Z com os de W, de forma que existam z % das transações no banco de dados. A
confiança mínima (minconf) garante que ao menos w % das transações que satisfaçam W
das regras também satisfaçam Z das regras.
3.1 Algoritmo Apriori
O algoritmo Apriori proposto por Agrawal (1994) tem o objetivo de fazer a
mineração de regras associativas em grandes e complexas bases de dados, sendo um dos
algoritmos mais conhecidos quando o assunto é extrair relacionamentos importantes de
tais bases de dados. É a partir dele que surgem todos os outros algoritmos de associação.
A vantagem de se utilizar o Apriori está na simplicidade original em que foi
desenvolvido e a versatilidade em minerar bases de dados robustas.
21
Antes de dar início ao processo de mineração, é necessário realizar a alteração de
alguns parâmetros referentes ao algoritmo e essa parametrização é realizada pela
atribuição dos percentuais de suporte mínimo e confiança mínima desejados.
O algoritmo percorre várias vezes a base de dados a fim de selecionar todos os
conjuntos de itens freqüentes, denominados itemsets freqüentes (Lk), sendo que, para
cada passo é gerado, primeiramente, um conjunto de itens candidatos (Ck) e então
determina se os candidatos satisfazem o suporte mínimo estabelecido por parâmetro.
Após este procedimento, ocorre a podagem do conjunto de itens candidatos e a contagem
do suporte, então os itens que poderão passar para a próxima passagem serão aqueles
com suporte acima do estabelecido.
A primeira passagem corresponde a k=1 e sendo k=2, k só será incrementado
enquanto o conjunto obtido na passagem anterior não for vazio e consequentemente os
itens retornados pela função Apriori-gen serão recebidos pelo conjunto candidato.
O Apriori faz uso de duas funções: a função Apriori_gen, para gerar os candidatos
e eliminar aqueles que não são freqüentes, e a função Genrules, utilizada para extrair as
regras associativas.
O funcionamento do algoritmo Apriori, utilizando a função Apriori_gen está
resumidamente ilustrado na Figura 3.1.
Figura 3.1 Algoritmo Apriori
22
O algoritmo Apriori gera inicialmente L1 que é o conjunto de grupos com
somente um elemento. Na seqüência, em um laço com k passos, serão desenvolvidas
duas tarefas basicamente: a primeira utiliza a função Apriori-gen para a geração do grupo
de itens candidatos Ck, através dos itens gerados no passo anterior (conjunto de Lk-1). A
segunda tarefa executada no laço k é a função Subset, que consisti num outro laço para
contagem do suporte dos itens (c) do grupo candidato Ck, onde cada transação da base de
dados é analisada. Neste momento, o Apriori utiliza uma função, estruturada na forma de
uma hash-tree, onde cada nodo folha contém uma lista de itens ou o endereçamento para
uma tabela hash, assim é possível encontrar todos os candidatos contidos na transação t
de forma ágil. Cada candidato c terá ao final o seu suporte computado, e no próximo
passo k, os itens que não obtiveram o suporte mínimo estabelecido são excluídos.
A Função Apriori-gen apresenta duas finalidades descritas a seguir:
A primeira consiste em formar a união dos conjuntos freqüentes, e então gerar o
conjunto candidato Ck, assim os itens do conjunto candidato formado estarão ordenados
lexicograficamente, eliminando aqueles que possuírem itens iguais.
A segunda finalidade da função Apriori-gen é fazer a podagem do conjunto de
itens candidatos, usando o princípio de que cada subconjunto de um conjunto de itens
freqüente também deve ser freqüente. Esta regra é utilizada para reduzir o número de
candidatos a serem comparados com cada transação na base de dados. Todos os
candidatos gerados que contenham algum subconjunto que não seja freqüente são
podados pela Apriori-gen.
23
4. FERRAMENTAS
As ferramentas escolhidas para realizar a tarefa de mineração de dados foram o
WEKA (Witten & Frank, 2005) e o TANAGRA (Rakotomalala, 2005).
4.1 WEKA
O WEKA (Waikato Environment for Knowledge Analysis) é um ambiente gráfico
que utiliza uma coleção de algoritmos de aprendizado de máquina e as tarefas de
mineração de dados: classificação, agrupamento e regras associativas e apresenta uma
interface gráfica bastante amigável para o usuário.
Foi desenvolvido e implementado em Java, pelo Departamento de Ciência da
Computação da Universidade de Waikato, na Nova Zelândia, constituindo-se como um
software com código aberto (opensource). Devido à portabilidade da linguagem Java, o
Weka pode ser executado em diversas plataformas. Por ser também uma linguagem
orientada a objetos, Java proporcionou ao software vantagens como modularidade,
polimorfismo, encapsulamento, reutilização de código entre outras.
A
ferramenta
Weka
está
disponível
para
download
em
http://www.cs.waikato.ac.nz/ml/weka. A versão estável mais recente é a 3.4.12. Nesse
endereço, se encontram também tutoriais, listas de discussões, informações sobre os
autores e o código das classes implementadas para gerar essa ferramenta.
Serão apresentadas a seguir as principais funcionalidades da ferramenta que se
refere ao módulo utilizado em nossa pesquisa (Explorer), conforme Figura 4.1.
Figura 4.1 tela inicial do Weka
24
•
•
O botão Simple CLI executa os algoritmos do Weka através de linha de comando.
O botão Explorer executa o modulo gráfico para utilização dos algoritmos e será
detalhado mais adiante.
•
O botão Experimenter permite ao usuário criar, rodar, modificar e analisar
experiências de uma maneira mais conveniente.
•
O botão KnowledgeFlow é uma ferramenta gráfica que permite o planejamento
de ações, na construção de um fluxo de processos de Mineração de Dados.
Com o botão Explorer, a janela do módulo Explorer é aberta, a qual fornece as
opções para iniciar o processo de mineração de dados no modo gráfico (Figura 4.2).
Figura 4.2 – Pré-processamento
Por exemplo, para abrir um arquivo na ferramenta Weka no formato arff basta
clicar no Open File e selecioná-lo, conforme a Figura 4.3 abaixo, podendo-se fazer
alterações de várias formas, como discretizar atributos numéricos e também modificar
valores do filtro de discretização.
25
Figura 4.3 – Abrir arquivo
Após ser selecionado o arquivo, a base de dados que será trabalhada no processo
de MD é carregada na ferramenta (Figura 4.4).
Figura 4.4 – Base de dados carregada
Na Figura 4.5 abaixo, podemos selecionar os tipos de filtros a serem utilizados na
preparação de dados.
26
Figura 4.5 – Filtros
Na Figura 4.6 abaixo, podemos escolher os atributos a serem utilizados no filtro
de discretização.
Figura 4.6 – Parâmetros de discretização
27
Cada aba do Weka será detalhada a seguir para melhor se entender a interface da
ferramenta.
Na aba Preprocess, encontram-se as opções para carregar a base de dados que
será submetida aos algoritmos de mineração:
Open file: apresenta uma caixa de diálogo que permite selecionar o arquivo
especificado, dentro do disco rígido, nos formatos binary serialized instances, C45 name
files, CSV (separado por vírgula) e o arquivo exclusivo do Weka, Arff.
Open URL: apresenta uma caixa de diálogo que permite selecionar o arquivo
especificado através de um endereço URL (Uniforme Resource Locator).
Open BD: apresenta uma caixa de diálogo através da qual se pode fazer a ligação
com um banco de dados, permitindo carregar os dados usando JDBC.
O quadro Current Relation mostra as informações sobre o conjunto de dados:
•
Relation: informa nome da relação (nome da base de dados).
•
Instances: informa a quantidade de instâncias (linhas ou registros da base
de dados).
•
Atributes: informa o número de atributos existente do conjunto de dados.
Ao selecionar um atributo em Attributes, o quadro Selected attribute fornece as
informações sobre esse atributo, como o nome do atributo (Name); seu tipo (Type),
podendo ser categórico (nominal) ou numérico; o número e a porcentagem de instâncias
nos dados que possuem dados ausentes para este atributo (Missing); o número de valores
diferentes que os dados possuem para este atributo (Distinct); e finalmente, o número e
porcentagem de instâncias que possuem valores para este atributo que não se repetem em
nenhuma outra instância (Unique).
As abas que disponibilizam os algoritmos de mineração de dados são as
seguintes:
•
A aba Classify, que consiste no esquema de treinamento de aprendizado
que executa os algoritmos de classificação ou regressão.
28
•
A aba Cluster, com os algoritmos de agrupamento.
•
A aba Associate, com os algoritmos para a descoberta de regras
associativas.
Além dessas, a aba Select Attributes permite selecionar os atributos mais
pertinentes no conjunto de dados. E a última opção, a aba Visualize, fornece
visualizações de gráficos de duas dimensões dos dados.
Detalhando a aba Associate, que contém o algoritmo usado neste trabalho, temos
que com o botão Choose, é possível escolher um algoritmo capaz de gerar regras de
associação (Figura 4.7).
Figura 4.7 – Interface do Associate Weka
As principais opções de parâmetros para a extração de regras associativas com o
algoritmo Apriori, no Weka, são mostradas na Tabela 4.1 a seguir:
29
Tabela 4.1 Opções de Parâmetros
Opção
Função
t <training file>
especifica o treinamento do arquivo
N <requered number of rules>
especifica o número exigido de regras
C <minimum confidence of a rule>
D <delta for minimum support>
especifica a confiança mínima de uma regra
especifica delta para diminuição de suporte mínimo
M <lower bound for minimum support>
especifica pequeno salto para suporte mínimo
Após escolher o algoritmo, é possível alterar os parâmetros através da janela
Weka.gui.GenericObjectEditorI (Figura 4.8).
Figura 4.8 – Tela para alteração de parâmetros
Na Figura 4.9 é apresentado o resultado da descoberta de regras associativas
utilizando o algoritmo Apriori.
A leitura de uma regra associativa se dá da seguinte forma:
30
Como exemplo, a regra 3 da Figura 4.9: SE pacientes do sexo feminino
apresentam ldl entre 108.6 a 131.4 (26 casos), ENTÃO apresentam situação normal (26
casos). Esta regra possui confiança de 100%.
Figura 4.9 – Resultado obtido do Associate Weka
31
4.2 TANAGRA
A tela inicial do Tanagra apresenta uma série de algoritmos de préprocessamento, mineração de dados e pós-processamento. Recursos como a visualização
dos dados a serem minerados e outros dispositivos referentes à ferramenta são
encontrados no campo chamado components. Ao clicar em cada botão de components, é
possível acessar seus recursos (Figura 4.10).
Figura 4.10 - Tela Inicial
No menu file, a opção new permite carregar na ferramenta os dados a serem
minerados, conforme a Figura 4.11.
Figura 4.11 - Abrir um arquivo novo
32
Na Figura 4.12 abaixo, após clicar em new aparece uma janela que permite
escolher o diretório em que estão os dados.
Figura 4.12 - Diretório
Na Figura 4.13, ao clicar no botão indicado pela seta a janela «Define attributes
Statuses», é aberta (Figura 4.14.) e permite definir parâmetros relativos à seleção dos
atributos da base de dados carregada que serão utilizados na mineração.
Figura 4.13 - Define attributes Statuses
33
Figura 4.14 - Define Atributos
Depois de selecionados os atributos, conforme mostra a Figura 4.15, clica-se no
botão adicionar para transferir os atributos de interesse no processo. Atributos discretos
ou nominais ou categóricos se caracterizam pela letra “D” e atributos numéricos ou
contínuos, pela letra “C”. Por exemplo, em uma tarefa de discretização, é possível
selecionar apenas os atributos contínuos. A seleção é confirmada ao clicar-se no botão
OK.
a)
b)
Figura 4.15 - a) Botão Adicionar b) Campos transferidos
34
No Tanagra, como no Weka, o algoritmo Apriori aceita somente atributos
nominais (discretos) para a descoberta de regras associativas; se os atributos forem
contínuos, é necessário torná-los nominais.
A Figura 4.16, abaixo, mostra que após escolher os parâmetros do campo «Define
Status», é possível processar esse comando (1).
1
Figura 4.16 – Executa Definir Status
A opção view (2) permite visualizar como estão dispostos os atributos (3),
conforme a Figura 4.17.
2
3
Figura 4.17 – Visualizar os atributos
35
O recurso Data Visualization permite visualizar os dados da tabela arrastando-se
o ícone View dataset até o «Define Status 1» (4), conforme a Figura 4.18.
4
Figura 4.18 - View Dataset
A Figura abaixo (4.19) mostra a utilização de um outro estado «Define Status 2»,
em que serão repetidos os passos já citados nas Figuras 4.17 e 4.18.
1
Figura 4.19 - Define Status 2
36
Após a realização dos passos anteriores, no campo components é escolhida a
tarefa de mineração de regras associativas, por exemplo, arrastando-se o ícone do
algoritmo escolhido, que neste exemplo foi o Apriori, até o «Define Status 2» (1).
A Figura 4.20 mostra que um clique com o botão direito do mouse sobre o ícone
do algoritmo escolhido abre um menu com as opções parameters, execute e view (2); ao
selecionar a opção parameters, é possível informar em uma janela os parâmetros
desejados, com a finalidade de dar início à mineração (3). Logo após, com a opção
execute (4), os dados são minerados e com a opção view (5) os resultados são
visualizados.
3
2
4
5
Figura 4.20 - 2) Parâmetros 3) definir parâmetros 4) executar 5) Visualizar
A Figura 4.21, a seguir, mostra a disposição dos resultados que estão divididos
em três partes: na primeira, os parâmetros escolhidos; na segunda, os valores dos
resultados obtidos e na terceira, as regras obtidas.
37
Figura 4.21 - Resultados obtidos
38
5. ESTUDO DE CASO
A realização deste estudo de caso teve como principal objetivo abordar o
funcionamento das ferramentas de mineração Weka e Tanagra, citadas no capítulo 4,
tendo como base a situação dos pacientes do Laboratório de Análises Clínicas do
Instituto de Previdência e Assistência do Município de Belém (IPAMB) com o intuito de
avaliar a qualidade dos padrões minerados.
5.1 Compreensão do domínio da aplicação
5.1.1 Cenário
O trabalho foi realizado com uma pequena amostra dos dados laboratoriais do
Laboratório de Análises Clínicas do IPAMB. Um especialista do domínio do setor da
bioquímica, onde são realizados os exames e lançados no sistema, prestou auxílio na
avaliação das ferramentas e na interpretação dos padrões encontrados, devido a sua
experiência nesse domínio.
5.1.2 Dados gerais da empresa
A Instituição presta serviços de previdência e assistência a todos os servidores do
município de Belém e seus dependentes, sem fins lucrativos, disponibilizando assistência
médica, odontológica e laboratorial, com postos de coleta em Mosqueiro e Icoaraci. A
instituição também mantém convênio com vários hospitais e clínicas da rede privada.
5.1.3 Definições dos testes bioquímicos utilizados
5.1.3.1 Colesterol Total e Frações
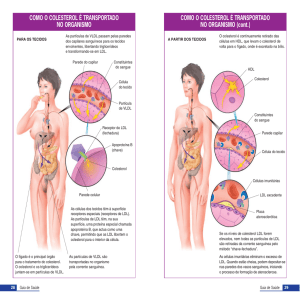
O colesterol é um tipo de gordura produzida pelo fígado e pelo intestino e enviada
para o sangue, que se encarrega de transportá-la para todo o organismo. Existem três
espécies de colesterol (também chamados lipoproteínas) na corrente sanguínea: o
colesterol de alta densidade (HDL), o colesterol de baixa densidade (LDL) e o colesterol
de muito baixa densidade (VLDL). O HDL é chamado de "bom colesterol", porque ele
impede que o colesterol se acumule nas artérias, funciona como um “detergente”. O LDL
39
é o "mau colesterol", pois em altos níveis pode aumentar seu risco de um ataque cardíaco
ou derrame porque o LDL se deposita nas paredes das artérias, o que leva à formação de
placas de gordura que impedem o fluxo sanguíneo. De acordo com Farell (1995) o LDL a
nível sérico é um dos principais indicadores de risco cardiovascular. Hoje, os
especialistas costumam dizer que o aumento de seu risco não se deve aos índices de seu
colesterol total, e sim à alta proporção de colesterol "ruim" em relação ao "bom"
colesterol.
O colesterol é fundamental para a vida. Ele é utilizado na construção e reparo de
células, na produção de hormônios sexuais como o estrógeno e a testosterona, e é
convertido em ácidos biliares para auxiliar na digestão de alimentos, sendo encontrado
em grande quantidade no cérebro e no tecido nervoso. O fígado produz quantidades
suficientes de colesterol para realizar estas funções.
A preocupação em relação ao colesterol ocorre quando a ingestão através de
alimentos como a carne, particularmente de vísceras como o fígado e o rim, ovos,
laticínios e outras fontes animais excede os níveis recomendados.
O colesterol não está presente em alimentos vegetais como frutas, verduras e
óleos vegetais. O colesterol não pode ser transportado livremente na corrente sangüínea.
Na verdade, ele é transportado associado a proteínas especiais chamadas lipoproteínas.
O HDL é o colesterol "bom", pois altas concentrações no sangue estão associadas
com um baixo risco de ataque cardíaco. O HDL contém mais proteínas que triglicerídeos
ou colesterol, ajudando a remover o colesterol das células do organismo para o fígado,
para ser reutilizado, convertido em ácidos biliares ou descartado na bile.
O LDL é o "mau" colesterol, estando associado com maior risco de doenças
cardíacas. O LDL é oxidado e depositado na parede das artérias, dando início ao processo
chamado "aterosclerose" (endurecimento das artérias). Este fenômeno é responsável por
500.000 ataques cardíacos por ano.
Segundo Roppa (2005) o excesso do colesterol LDL pode dar início à formação
de placa nas paredes internas das coronárias. Com o passar do tempo essa excrescência
endurecida e cheia de sedimentos, estreita a artéria e permite a formação de um coágulo,
capaz de bloquear gravemente o fluxo sanguíneo.
40
Além da dislipidemia (nome técnico para o colesterol elevado) temos outros
fatores que podem agravar ainda mais a situação do indivíduo como a hereditariedade, a
pressão alta (hipertensão arterial), o tabagismo, obesidade, uso de medicamentos que
elevam a pressão arterial e a associação com outras doenças como o diabetes mellitus, a
insuficiência renal crônica, etc.
5.1.3.2 Triglicerídeos
A principal maneira de armazenar os lipídeos no tecido adiposo é sob a forma de
triglicérides. São também os tipos de lipídeos mais abundantes na alimentação. Podem
ser definidos como compostos formados pela união de três ácidos graxos com glicerol.
Os triglicerídeos sólidos em temperatura ambiente são conhecidos como gorduras,
enquanto os líquidos são os óleos. As gorduras geralmente possuem uma alta proporção
de ácidos graxos saturados de cadeia longa, já os óleos normalmente contêm mais ácidos
graxos insaturados de cadeia curta.
A inatividade, o excesso de peso e uma dieta rica em carboidratos refinados
(álcool, doces, massas, pão branco) podem fazer disparar a taxa de triglicérides do
sangue.
Pesquisadores identificaram nos altos níveis de triglicerídeos de pessoas com
problemas cardíacos mais um forte indicador de derrames cerebrais, mesmo quando o
nível de colesterol desses pacientes é baixo.
Segundo Moriguchi (2008), os triglicerídeos são um dos componentes gordurosos
do sangue e sua elevação está relacionada, também, com doenças cardiovasculares
(angina, infarto), cerebrovasculares (derrame) e doenças digestivas (pancreatite).
5.1.3.3 Valores de Referência
Como não é viável para o homem enxergar através do corpo como está a situação
de suas artérias, é de máxima importância que sejam realizados exames para a dosagem
bioquímica, a fim de se ter o conhecimento da quantidade dessas substâncias no
organismo, já que na maioria dos casos não apresentam sintomas quando alterados.
41
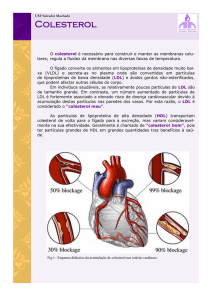
Tais substâncias apresentam os seguintes valores de referência, Figura 5.1:
Colesterol Total (mg/dL)
Ótimo Limítrofe Elevado
< 200 200 a 239
≥ 240
Colesterol HDL (mg/dL)
Ótimo Limítrofe Indesejável
> 45 35 a 45
< 35
Colesterol LDL (mg/dL)
Ótimo Sub-Ótimo Limítrofe
Elevado Muito Elevado
< 100 100 a 129 130 a 159 106 a 189
> 189
Triglicerídeos (mg/dL)
Ótimo Limítrofe Elevado
< 150 150 a 199
> 200
Figura 5.1 – Valores de Referência
O valor do VLDL depende do triglicerídeos e o seu valor referencial é de 0 a 30.
Sendo utilizado como unidade o mg/dL.
Observa-se na Figura 5.2 abaixo, a diferença da estrutura das artérias quando se
encontram normais e quando estão obstruídas ou entupidas por placas de gorduras
provocadas pela alteração dessas substâncias e como foi dito anteriormente não
provocam sintomas na maioria dos casos, caracterizando-se como uma enfermidade
silenciosa e perigosa, podendo ser descoberta através da realização de exames de rotina.
Figura 5.2 – Diferença entre artéria normal e artéria bloqueada
42
5.2 Escolha das ferramentas e tarefas utilizadas
As ferramentas escolhidas para fazer a mineração foram o Weka e o Tanagra. A
tarefa que melhor se enquadrou para resolver o problema foi a tarefa de regras
associativas.
A mineração de dados teve a participação do especialista do domínio, que deu
auxílio no decorrer de todo o processo.
5.3 Descrição do processo de mineração de dados aplicado ao problema
5.3.1 Identificação do Problema
Em um laboratório de análises clínicas a rotina diária é muito grande, então
fazendo um breve estudo dos dados, notou-se que a maioria dos pacientes continha uma
série de testes bioquímicos solicitados pelos médicos. Desses, para este trabalho foram
selecionados somente os dados dos pacientes que tinham a solicitação médica para os
respectivos testes: Colesterol total, Triglicerídeos, HDL, VLDL e LDL, os quais estão
diretamente ligados às doenças cardíacas e ao derrame cerebral, pois os resultados dos
quatro primeiros testes citados acima irão influenciar o resultado do LDL, o qual é obtido
por um cálculo realizado por profissional do setor de bioquímica (Bioquímico,
Biomédico ou Técnico em Biodiagnóstico).
Juntamente com esses dados, foram coletados também as idades, o sexo e o valor
de cada paciente (ótimo, sub-ótimo, limítrofe, elevado e muito elevado) de cada paciente.
Para realizar a análise dos resultados, a proposta foi de verificar quais pacientes
dentro desta pequena amostra estão incluídos no grupo de risco, ou seja, indivíduos que
possuem grandes probabilidades de ter um infarto do miocárdio devido aos valores do
colesterol LDL (colesterol ruim) estarem muito elevados.
5.3.2 Pré-Processamento
Os dados foram coletados do próprio equipamento que realiza os testes, o
LABMAX 240, em que foram selecionados apenas os atributos referentes ao colesterol
total e suas frações, juntamente com o nome dos pacientes que foram identificados com p
e o número da linha que segue. A situação corresponde à referência de cada valor do
LDL (ótimo, sub-ótimo, limítrofe, elevado e muito elevado).
43
A Tabela 5.1 mostra os dados utilizados para este trabalho.
Tabela 5.1 – Dados coletados
Pacientes
Idade
Sexo
RESULTADOS_BIOQUIMICOS
Colesterol Total Triglicerideos HDL
VLDL
LDL
Situação
P1
20
f
199
123
45
25
129
Sub-otimo
P2
32
f
190
145
41
29
120
Sub-otimo
P3
61
m
218
144
51
29
138
Limítrofe
P4
59
f
115
78
36
16
63
Ótimo
P5
30
f
239
245
39
49
151
Limítrofe
P6
65
m
163
67
52
13
98
Ótimo
P7
41
f
226
228
37
46
143
Limítrofe
P8
68
m
256
112
53
22
181
Elevado
P9
71
f
202
179
55
36
111
Sub-otimo
P10
51
m
157
93
54
19
84
Ótimo
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
5.3.3 Extração e Integração
Para este estudo, foi coletada uma pequena amostra de dados de quatro dias de
trabalho, escolhendo 260 pacientes que continham o resultado do LDL, para dar início ao
processo de extração de padrões. Os dados coletados foram integrados em um arquivo
Arff para o Weka e txt separados por tabulação para o Tanagra.
5.3.4 Transformação
Para os pacientes que apresentam valores de referencia ótimo e sub-ótimo foram
substituídos por grupo_normal, já os que apresentavam valores elevado e muito elevado
foram alterados para grupo_de_risco, enquanto os pacientes com LDL limítrofe e que
estavam no grupo normal, foram transformados em grupo intermediário, já que este
resultado não é elevado, porém não é o resultado ideal, Tabela 5.2 a seguir exibe os
resultados obtidos.
44
Tabela 5.2 – Dados modificados
RESULTADOS_BIOQUIMICOS
Pacientes
Idade
Sexo
Colesterol Total
Triglicerídeos
p1
20
f
199
123
HDL VLDL
p2
32
f
190
145
41
29
120
grupo_normal
p3
61
m
218
144
51
29
138
grupo_intermediário
p4
59
f
115
78
36
16
63
grupo_normal
p5
30
f
239
245
39
49
151
grupo_intermediário
p6
65
m
163
67
52
13
98
grupo_normal
p7
41
f
226
228
37
46
143
grupo_intermediário
p8
68
m
256
112
53
22
181
grupo_de_risco
45
25
LDL
Situação
129
grupo_normal
p9
71
f
202
179
55
36
111
grupo_normal
p10
51
m
157
93
54
19
84
grupo_normal
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
5.3.5 Extração de Padrões
A mineração sobre os dados em questão foi realizada com o objetivo de extrair
padrões relevantes com as ferramentas Weka e Tanagra.
5.3.6 Escolha da Tarefa
Como mencionado em capítulos anteriores, a tarefa escolhida para este estudo de
caso foi a tarefa de Regras Associativas, com o objetivo de descobrir associações da
situação dos pacientes de acordo com a idade e sexo, utilizando para isso o valor do
LDL.
5.3.7 Escolha do Algoritmo
O algoritmo escolhido como citado anteriormente é o Apriori. Já que o objetivo é
comparar duas ferramentas, decidimos utilizá-lo por estar presente em ambas e por ser o
algoritmo mais difundido em regras associativas.
5.3.8 Parâmetros Utilizados
Os parâmetros escolhidos para a extração de regras associativas foram os seguintes:
suporte mínimo de 5% e confiança mínima de 70%. Os dados foram discretizados em
quatro (4) intervalos. Esses intervalos foram gerados através dos recursos disponíveis em
cada
ferramenta:
no
Weka,
através
da
aba
iris45
weka.filters.unsupervised.attribute.Discretize-B3-M-1.0-Rfirst-last, com a alteração do
bins, já no Tanagra com o Feature contruction, que disponibiliza vários algoritmos para
tal tarefa, foi escolhido o algoritmo EqWidth, em que o parâmetro principal é o número
de intervalos. Esse algoritmo tem o objetivo de transformar o atributo contínuo em
atributo discreto ordenado, onde o tamanho de cada intervalo é o mesmo, assim como no
Weka.
Os parâmetros citados acima foram utilizados tanto para a ferramenta Weka,
quanto para a ferramenta Tanagra.
5.3.9 Resultados
5.3.9.1 Regras Associativas Obtidas
Ao todo, foram extraídas 29 regras associativas para o Weka e 29 regras
associativas para o Tanagra, em que serão analisadas as regras cujos pacientes fazem
parte do grupo de risco, do grupo normal e do grupo intermediário. Porém, utilizamos
apenas 26 regras de cada ferramenta, devido as 3 restantes não apresentarem informações
relevantes. Por meio dessa análise, será feita a comparação dos resultados das
ferramentas utilizadas.
Os intervalos de discretização para os atributos idade e LDL ficaram desta forma:
Idade:
Intervalo 1: inferior a 31,5
Intervalo 2: superior a 31,5 – igual a 54
Intervalo 3: superior a 54 – igual a 76,5
Intervalo 4: superior a 76,5.
LDL:
Intervalo 1: inferior a 114,75
Intervalo 2: superior a 114,75 – igual a 173,5
Intervalo 3: superior a 173,5 – igual a 232,25
Intervalo 4: superior a 232,25.
Os valores da idade acima de 76,5 e do LDL acima de 232,25 não apareceram nas
regras devido a pouca freqüência desses valores.
5.3.9.2 Regras geradas para pacientes pertencentes ao grupo de risco
O primeiro modelo gerado (Modelo 1) apresenta as regras associativas
encontradas que envolvem pacientes que apresentam LDL elevado ou muito elevado
sobre o relacionamento dos atributos ldl e situaçao.
46
5.3.9.2.1 Para o Weka
1. sexo=f ldl='(173.5-232.25]' 37 ==> situacao=grupo_de_risco 37
conf:(1)
2. idade='(31.5-54]' ldl='(173.5-232.25]' 25 ==> situacao=grupo_de_risco 25
3. sexo=m ldl='(173.5-232.25]' 22 ==> situacao=grupo_de_risco 22
conf:(1)
conf:(1)
4. idade='(54-76.5]' ldl='(173.5-232.25]' 18 ==> situacao=grupo_de_risco 18
conf:(1)
5. idade='(31.5-54]' sexo=f ldl='(173.5-232.25]' 16 ==> situacao=grupo_de_risco 16
conf:(1)
6. idade='(-inf-31.5]' ldl='(173.5-232.25]' 15 ==> situacao=grupo_de_risco 15
conf:(1)
7. idade='(54-76.5]' situacao=grupo_de_risco 24 ==> ldl='(173.5-232.25]' 18
conf:(0.75)
Leitura da regra, exemplo: regra 5.
“Pacientes com idade entre 31,5 e 54 anos do sexo feminino que apresentam ldl
entre 173,5 e 232,25 (16 casos) estão incluídos nos pacientes que pertencem ao grupo de
risco de ter um infarto (16 casos). Essa hipótese apresenta confiança de 100%.”
5.3.9.2.2 Para o Tanagra
8. Situação=grupo_de_risco – d_eqw_idade_1=54_=<_m_<_76,5 ==>
d_eqw_ldl_1=173,5_=<_m_<_232,25 lift(3,390), support(0,077), conf(0,769)
9. d_eqw_idade_1=31,5_=<_m_<_54 - d_eqw_ldl_1=173,5_=<_m_<_232,25 ==>
Situação=grupo_de_risco lift(2,796), support(0,088), conf(1).
10. d_eqw_idade_1=m_<_31,5 - d_eqw_ldl_1=173,5_=<_m_<_232,25 ==>
Situação=grupo_de_risco lift(2,796), support(0,058), conf(1).
11. Sexo=f - d_eqw_ldl_1=173,5_=<_m_<_232,25 ==> Situação=grupo_de_risco lift(2,796),
support(0,142), conf(1).
12. Sexo=m - d_eqw_ldl_1=173,5_=<_m_<_232,25 ==> Situação=grupo_de_risco lift(2,796),
support(0,085), conf(1).
13. d_eqw_ldl_1=173,5_=<_m_<_232,25 - d_eqw_idade_1=54_=<_m_<_76,5 ==>
Situação=grupo_de_risco lift(2,796), support(0,077), conf(1).
14. Sexo=f - d_eqw_idade_1=31,5_=<_m_<_54 - d_eqw_ldl_1=173,5_=<_m_<_232,25 ==>
Situação=grupo_de_risco lift(2,796), support(0,062), conf(1).
Leitura da regra, exemplo: regra 8.
“Pacientes que pertencem ao grupo de risco, com idade entre 54 e 76,5 anos
apresentam ldl entre 173,5 e 232,25. Essa hipótese foi dada em mais ao menos 8% dos
casos, com uma confiança de 77% e o antecedente está correlacionado com o
conseqüente da regra positivamente em 3,39%.”
47
5.3.9.3 Regras geradas para pacientes que não pertencem ao grupo de risco
5.3.9.3.1 Para o Weka
15. sexo=m ldl='(-inf-114.75]' 44 ==> situacao=grupo_normal 44
conf:(1)
16. idade='(-inf-31.5]' ldl='(-inf-114.75]' 39 ==> situacao=grupo_normal 39
17. sexo=f ldl='(-inf-114.75]' 34 ==> situacao=grupo_normal 34
conf:(1)
conf:(1)
18. idade='(31.5-54]' ldl='(-inf-114.75]' 29 ==> situacao=grupo_normal 29
conf:(1)
19. idade='(-inf-31.5]' sexo=m ldl='(-inf-114.75]' 24 ==> situacao=grupo_normal 24
conf:(1)
20. idade='(31.5-54]' sexo=m ldl='(-inf-114.75]' 16 ==>
21. idade='(-inf-31.5]' sexo=f ldl='(-inf-114.75]' 15 ==> situacao=grupo_normal 15
conf:(1)
22. idade='(31.5-54]' sexo=f ldl='(-inf-114.75]' 13 ==> situacao=grupo_normal 13
conf:(1)
23. idade='(-inf-31.5]' sexo=m situacao=grupo_normal 29 ==> ldl='(-inf-114.75]' 24
24. idade='(31.5-54]' sexo=f situacao=grupo_normal 17 ==> ldl='(-inf-114.75]' 13
25. sexo=m situacao=grupo_normal 58 ==> ldl='(-inf-114.75]' 44
conf:(0.83)
conf:(0.76)
conf:(0.76)
26. idade='(-inf-31.5]' ldl='(114.75-173.5]' situacao=grupo_normal 20 ==> sexo=f 15
27. idade='(31.5-54]' situacao=grupo_normal 39 ==> ldl='(-inf-114.75]' 29
conf:(0.75)
conf:(0.74)
28. idade='(31.5-54]' sexo=m situacao=grupo_normal 22 ==> ldl='(-inf-114.75]' 16
conf:(0.73)
Leitura da regra, exemplo: a regra 23.
“Pacientes com idade inferior a 31,5 anos do sexo masculino, que não pertencem
ao grupo de risco (29 casos) apresentam ldl inferior a 114,75 (24 casos). Essa hipótese
apresenta confiança de 83%.”
5.3.9.3.2 Para o Tanagra
29. sexo=m - Situação=grupo_normal - d_eqw_idade_1=m_<_31,5 ==>
d_eqw_ldl_1=m_<_114,75 lift(2,759), support(0,092), conf(828).
30. sexo=f - Situação=grupo_normal - d_eqw_idade_1=31,5_=<_m_<_54 ==>
d_eqw_ldl_1=m_<_114,75 lift(2,549), support(0,050), conf(0,765).
31. sexo=m - Situação=grupo_normal ==> d_eqw_ldl_1=m_<_114,75 lift(2,549), support(0,169),
conf(0,759).
32. Situação=grupo_normal - d_eqw_idade_1=31,5_=<_m_<_54 ==> d_eqw_ldl_1=m_<_114,75
lift(2,479), support(0,112), conf(0,744).
33. sexo=m - Situação=grupo_normal - d_eqw_idade_1=31,5_=<_m_<_54 ==>
d_eqw_ldl_1=m_<_114,75 lift(2,424), support(0,062), conf(0,727).
48
34. d_eqw_idade_1=m_<_31,5 - d_eqw_ldl_1=m_<_114,75 ==> Situação=grupo_normal
lift(2,261), support(0,150), conf(1).
35. d_eqw_idade_1=31,5_=<_m_<_54 - d_eqw_ldl_1=m_<_114,75 ==> Situação=grupo_normal
lift(2,261), support(0,112), conf(1).
36. Sexo=f - d_eqw_idade_1=31,5_=<_m_<_54 - d_eqw_ldl_1=m_<_114,75 ==>
Situação=grupo_normal lift(2,261), support(0,050), conf(1).
37. Sexo=m - d_eqw_idade_1=31,5_=<_m_<_54 - d_eqw_ldl_1=m_<_114,75 ==>
Situação=grupo_normal lift(2,261), support(0,062), conf(1).
38. Sexo=f - d_eqw_idade_1=m_<_31,5 - d_eqw_ldl_1=m_<_114,75 ==>
Situação=grupo_normal lift(2,261), support(0,058), conf(1).
39. Sexo=m - d_eqw_idade_1=m_<_31,5 - d_eqw_ldl_1=m_<_114,75 ==>
Situação=grupo_normal lift(2,261), support(0,092), conf(1).
40. Sexo=m - d_eqw_ldl_1=m_<_114,75 ==> Situação=grupo_normal lift(2,261), support(0,169),
conf(1).
41. Sexo=f - d_eqw_ldl_1=m_<_114,75 ==> Situação=grupo_normal lift(2,261), support(0,131),
conf(1).
42. d_eqw_ldl_1=114,75_=<_m_<_173,5 – situação=grupo_normal – d_eqw_idade_1=m_<_31,5
==> Sexo=f lift(1,413), support(0,058), conf(0,750).
Leitura da regra, exemplo: regra 38.
“Pacientes do sexo feminino, com idade inferior a 31,5 anos com ldl inferior a
114,75 não se enquadram no grupo de pacientes de risco. Essa hipótese foi dada em
mais ao menos 6% dos casos, com uma confiança de 100% e o antecedente está
correlacionado com o conseqüente da regra positivamente em pouco mais de 2,2%.”
5.3.9.4 Regras geradas para pacientes que pertencem ao grupo intermediário
5.3.9.4.1 Para o Weka
43. sexo=m situacao=grupo_intermediario 30 ==> ldl='(114.75-173.5]' 30
conf:(1)
44. idade='(31.5-54]' situacao=grupo_intermediario 19 ==> ldl='(114.75-173.5]' 19
conf:(1)
45. idade='(-inf-31.5]' situacao=grupo_intermediario 17 ==> ldl='(114.75-173.5]' 17
conf:(1)
46. sexo=f situacao=grupo_intermediario 22 ==> ldl='(114.75-173.5]' 21
conf:(0.95)
47. idade='(54-76.5]' situacao=grupo_intermediario 15 ==> ldl='(114.75-173.5]' 14
conf:(0.93)
Leitura da regra, exemplo: regra 44.
49
“Pacientes com idade entre 31,5 e 54 anos, que fazem parte do grupo
intermediário (19 ocorrências), apresentam ldl entre 114,75 e 173,5 (19 casos). Essa
hipótese apresenta confiança de 100%.”
5.3.9.4.2 Para o Tanagra
48. Sexo=m – situação=grupo_intermediario ==> d_eqw_ldl=114,75_=<_m_<_173,5 lift(2,185),
support(0,115), conf(1).
49. d_eqw_idade_1=31,5_=<_m_<_54 - situação=grupo_intermediario ==>
d_eqw_ldl=114,75_=<_m_<_173,5 lift(2,185), support(0,073), conf(1).
50. d_eqw_idade_1=m_<_31,5 - situação=grupo_intermediario ==>
d_eqw_ldl=114,75_=<_m_<_173,5 lift(2,185), support(0,065), conf(1).
51. Sexo=f – situação=grupo_intermediario ==> d_eqw_ldl=114,75_=<_m_<_173,5 lift(2,143),
support(0,081), conf(0,955).
52. d_eqw_idade_1=54_=<_m_<_76,5 - situação=grupo_intermediario ==>
d_eqw_ldl=114,75_=<_m_<_173,5 lift(2,039), support(0,054), conf(0,933).
Leitura da regra, exemplo: regra 51.
“Pacientes do sexo feminino, que fazem parte do grupo intermediário apresentam
ldl entre 114,75 e 173,5. Essa hipótese foi dada em mais ao menos 8% dos casos, com
uma confiança de 95% e o antecedente está correlacionado com o conseqüente da regra
positivamente em pouco mais de 2,1%.”
5.4 Avaliação do Resultado
Tanto para a ferramenta Weka quanto para o Tanagra, o número de mulheres na
situação de risco devido ao elevado nível do LDL, na faixa de 173,5 a 232,25, no sangue,
é maior que nos homens com ênfase na faixa etária de 31,5 a 54 anos, as regras geradas
para esta conclusão são: 1, 3 e 5 (Weka) e 11, 12 e 14 (Tanagra). E a faixa etária onde o
problema é mais evidente, segundo as regras 2 (Weka) e 9 (Tanagra), é a faixa entre 31,5
a 54 anos, independente do sexo.
Dos pacientes que fazem parte do grupo normal, prevalecem os do sexo
masculino com idade inferior a 31,5 anos. As regras que evidenciam esta hipótese são as
regras 15 e 19 (Weka) e 39 e 40 (Tanagra).
Para os pacientes que se enquadram no grupo intermediário, prevalece os do sexo
masculino que apresentam o valor do LDL entre 114,75 a 173,75. As regras em que essa
50
informação foi extraída são: 43 (Weka) e 48 (Tanagra).
Com isso, levanta-se a hipótese que, dos dias em que os dados foram coletados,
os pacientes do sexo feminino com idade entre 31,5 a 54 anos, com LDL elevado ou
muito elevado apresentam grandes riscos de ter um infarto do miocárdio.
Os resultados da mineração de dados foram levados à especialista do
conhecimento, farmacêutica bioquímica, Bernadete Oliveira, que concluiu que as
informações extraídas não forneceram algo novo, mas vieram confirmar as recentes
pesquisas por acerca deste assunto, já que a mulher, além dos processos hormonais e
genéticos, apresenta também os reflexos sofridos após a entrada no mercado de trabalho
devido às jornadas duplas, triplas que na maioria das vezes precisa enfrentar.
Segundo a especialista a prevenção da doença ao invés de seu tratamento é
inegavelmente de suma importância, não só para a qualidade de vida, mas porque reduz
os gastos dos sistemas de saúde com o tratamento de patologias que podem ser evitadas
através de medidas preventivas adequadas.
As medidas preventivas em saúde, para serem adotadas devem estar baseadas em
levantamentos de estudos, dados epidemiológicos, etc.
As ferramentas utilizadas identificaram os grupos com maiores ou menores riscos
de hipercolesterolemia. O que vem demonstrar que as mesmas podem ser de suma
utilidade na identificação dos mais variados grupos e dos potenciais riscos a que estão
expostos. Em conseqüência disso, podem ser utilizadas em estudos de levantamentos
futuros colaborando nas tomadas de decisões das medidas preventivas que podem ser
adotadas.
5.5 Comparação das Ferramentas
Para a comparação das ferramentas, serão considerados itens como interface,
facilidade de uso, apresentação de resultados e resultados obtidos.
5.5.1 Interface
5.5.1.1 Weka
Em relação à interface, o Weka apresenta maior vantagem, pois interage melhor
com o usuário devido à facilidade de uso e entendimento que ela proporciona, já que na
51
tela de pré-processamento observam-se as inúmeras informações que a ferramenta
fornece.
A seguir é feita uma breve descrição das informações que a tela de préprocessamento contém, de acordo com a Figura 5.3:
3
1
2
5
4
Figura 5.3 – Tela de pré-processamento
1 - Informa os atributos envolvidos, onde através do botão Remove é possível
remover aqueles que estão marcados e que não interessam para a extração de padrões.
2 - Informa o nome do atributo selecionado em 1, os valores desse atributo e a
quantidade de registros para cada valor; informa ainda o tipo, se há valores ausentes,
quantos valores distintos e finalmente, o número e porcentagem de instâncias que
possuem valores para este atributo que não se repetem em nenhuma outra instância
(unique).
3 – O botão Choose possibilita alterar os filtros para a aplicação de métodos
supervisionados e não supervisionados sobre os atributos e instâncias.
4 - Com o botão Visualize All é possível obter os gráficos dos dados a serem
minerados.
5 – Informa a quantidade de instâncias (registros) e atributos.
52
5.5.1.2 Tanagra
Já o Tanagra oferece uma interface simples, desprovida de muitas informações,
como mostra a Figura 5.4 abaixo:
1
2
3
Figura 5.4 – Interface do Tanagra
1 – Informa o número de atributos envolvidos e a quantidade de registros.
2 – Informam quais são os atributos, a categoria a que pertencem e o número de
dados semelhantes.
3 – Mostra as tarefas disponibilizadas pela ferramenta.
5.5.2 Facilidade de uso
Em relação à utilização, a ferramenta Weka se mostrou mais fácil de se manipular
do que a ferramenta Tanagra. Esta última mostrou-se um pouco mais complicada de se
desenvolver uma tarefa devido à interface gráfica da ferramenta, como citado
53
anteriormente e pela pouca quantidade de documentos e tutoriais na Internet para
pesquisa.
5.5.3 Apresentação dos Resultados
Existem poucas diferenças na representação do conhecimento extraído pelas duas
ferramentas, que foram observadas na forma e na ordem como são dispostas: o Weka
mostra os resultados em ordem decrescente de confiança, já o Tanagra mostra em ordem
decrescente de Lift e Suporte.
5.5.4 Resultados obtidos
Através da análise dos resultados das duas ferramentas utilizando a mesma base
de dados, o mesmo algoritmo, os mesmos parâmetros foram possíveis concluir que
ambas as ferramentas obtiveram o mesmo resultado.
54
6. CONSIDERAÇÕES FINAIS
Atualmente, devido à necessidade de se obter conhecimento relevante e útil a
partir de grandes bases de dados e tendo em vista a importância de se obter vantagem
competitiva em varias áreas de atuação, muitas novas tecnologias de informação têm
surgido nos últimos anos e a Mineração de Dados é uma delas. Com isso, o
desenvolvimento de ferramentas que utilizam algoritmos capazes de extrair informações
e conhecimento se faz necessário.
Nesta pesquisa foi utilizado o mesmo algoritmo, no caso o Apriori, e os mesmos
parâmetros para avaliação do comportamento das ferramentas Weka e Tanagra. Com isso
foi possível concluir que ambas conseguem fazer a mineração dos dados selecionados,
fornecendo resultados equivalentes, apesar de algumas poucas diferenças encontradas.
Através dos testes realizados foi verificado que o Weka apresenta melhor
interface e facilidade de uso em relação ao Tanagra, pois interage melhor com o usuário e
há uma grande quantidade de documentos e tutoriais de fácil acesso, possibilitando um
estudo abrangente da ferramenta.
55
REFERÊNCIAS
Agrawal, R., Imielinski, T., Swami, A. Mining association rules between sets of items in
large databases. Proc. of the ACM SIGMOD Conference. Washington, DC, USA,
p.
207-216,
maio
1993.
Disponível
em:
http://rakesh.agrawal-
family.com/papers/sigmod93assoc.pdf.
Agrawal, R., Srikant, R. Fast algorithms for mining association rules in large databases.
In: Proc. of the International Conference on Very Large Data Bases, VLDB, 20.,
1994, Santiago. Morgan Kaufmann.
Farrell, D.J. The problems and practicalities of producing an omega (n-3 fortified egg).
In: EUROPEAN SYMPOSIUM ON THE QUALITY OF EGGS AND EGG
PRODUCTS, 6. 1995, Zaragoza, Spain. Proceedings... Zaragoza, Spain, 1995.
Fayyad, U., Piatetsky-Shapiro, G., Smyth, P. From Data Mining to Knowledge
Discovery: An Overview. In: Fayyad, U.; Piatetsky-Shapiro, G., Smyth, P.,
Uthurusamy, R. Advances in Knowledge Discovery and Data Mining. Menlo
Park: MIT Press, 1996. 611 p. p. 1-34.
Moriguchi, E. ABC da Saúde. Disponível em: http://www.abcdasaude.com.br/ artigo
.php?673. Acesso em: 22/03/2008.
Mount, D. Bioinformatics: Sequence and Genome Analysis (Genome Analysis). New
York: CSHL PRESS, 2001.
Rakotomalala, R. TANAGRA: a free software for research and academic purposes, in
Proceedings of EGC'2005, RNTI-E-3, vol. 2, pp.697-702, 2005, Lyon – France.
Disponível em: http://eric.univ-lyon2.fr/~ricco/tanagra/en/tanagra.html.
Rezende, S. Sistemas Inteligentes: Fundamentos e Aplicações. 1ª Edição. Barueri –
SP: Manole, 2003.
Roppa, L. Atualização sobre os níveis de Colesterol, Gordura e Calorias da Carne
Suína. EMBRAPA, 2005.
Weiss, S. M. & N. Indurkhya. Predictive Data Mining: A Practical Guide. Morgan
Kaufmann Publishers. Inc., San Francisco, CA (1998).
56
Witten, H., Frank, E. Data Mining: Practical machine learning tools and techniques, 2nd
Edition, Morgan Kaufmann, San Francisco, 2005.
57