PONTIFÍCIA UNIVERSIDADE CATÓLICA DE SÃO PAULO
FEA - Faculdade de Economia e Administração
Programa de Estudos Pós-Graduados em Administração
PESQUISA SOCIO-ECONOMICA AO NIVEL MUNICIPAL NO BRASIL
focando principalmente indicadores relacionados a trabalho,
educação, saúde e muito particularmente HABITAÇÃO
MÉTODOS QUANTITATIVOS DA PESQUISA EMPÍRICA
Professor Dr. Arnoldo Jose de Hoyos
Hannah de Carvalho
INTRODUÇÃO
1.1 INTRODUÇÃO
O presente trabalho tem por objetivo efetuar diversas análises dos dados da Pesquisa
Firjan/FGV sobre o Desenvolvimento dos Municípios nos períodos de 2000 e 2010. Iniciamos
com o entendimento dos dados, incluindo a definição dos indivíduos e das variáveis, suas
classificações em variáveis categóricas ou quantitativas, os significados e unidades de medida,
além da apresentação da tabela de dados.
Na seqüência, analisamos cada uma das variáveis separadamente quanto a sua forma de
distribuição, os valores atípicos, medidas de centro e dispersão. Para tal contamos com o
auxílio de gráficos (pie chart, barras, histogramas, gráficos de ramos, box-plot, dot-plot e
curvas de densidade) e de medidas numéricas (média, mediana, quartis, desvio-padrão,
variância, intervalo de confiança e teste de normalidade de Anderson-Darling).
Em seguida faremos comparações entre as diversas variáveis analíticas, utilizando técnicas
como relações entre as variáveis, regressões múltiplas, comparações, amostragem dos dados,
análise multivariada, análise de conglomerados, análise discriminante, regressão logística,
análise de correspondência e arvores de classificação.
Não será possível, a partir destes dados, efetuarmos a análise de tendência pois não existem
séries temporais de dados, requisitos para esta técnica.
O software estatístico utilizado é o MINITAB 14. Este trabalho se concentrará nas diversas
variáveis que compõem a pesquisa ISDM.
ANALISE EXPLORATORIO DE DADOS
1.2-
PREPARAÇÃO DOS DADOS
Antes da análise dos dados, é necessário avaliar se não existe alguma inconsistência ou falha
que possa incorrer em algum erro nas análises futura. Neste caso, como se pode notar no item
1.1, coluna (N*), que indica o número de dados faltantes, em diversas variáveis estão faltando
dados, como exemplo: 304 no IFGF e 22 na Emprego e Renda.
1.2.1
Estatística Descritiva - dados originais
1.2.2
Descriptive Statistics: H; H1; H2; H3; H4; H5; H6; ISDM; ...
Variable
H
H1
H2
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
N*
0
0
0
0
0
0
0
0
71
304
0
0
1
0
22
22
304
Mean
4,3854
69,480
96,182
84,293
29,807
77,076
54,319
4,4325
0,64979
0,53228
85,481
56,304
14,260
24,525
0,74156
0,40414
0,57217
Minimum
0,2800
0,000000000
9,530
4,320
0,000000000
26,770
4,740
0,5500
0,36710
0,08000
45,720
6,400
0,000000000
0,0700
0,37460
0,000000000
0,000000000
Q1
3,7000
52,860
96,820
74,345
0,955
70,200
45,035
3,6000
0,57890
0,43000
79,525
41,275
4,293
8,620
0,66320
0,30630
0,19000
Median
4,4400
73,330
99,010
93,750
16,820
77,390
55,300
4,6400
0,65035
0,55000
87,510
57,420
12,580
19,990
0,74650
0,37610
0,69000
Q3
5,1900
89,220
99,710
98,765
56,250
84,430
64,615
5,3500
0,71673
0,65000
92,530
71,380
20,060
39,480
0,82350
0,47130
0,91000
Maximum
6,4800
100,000
100,000
100,000
99,920
97,500
89,330
6,2800
0,94860
0,97000
100,000
94,910
333,330
78,800
1,00000
1,00000
1,00000
1.3 Estatística Descritiva dos dados originais (N*=0)
Como foi observado no tópico anterior que os indicadores IFDM, IFGF, S1_1, Liquidez,
Educação e Emprego & Renda estão faltando (N* - coluna) usaremos o número referente ao
primeiro quartil para as células vazias.
Descriptive Statistics: H; H1; H2; H3; H4; H5; H6; ISDM; ...
Variable
H
H1
H2
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
E2_4
5565
N*
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Mean
4,3854
69,480
96,182
84,293
29,807
77,076
54,319
4,4325
0,64888
0,52670
85,481
56,304
14,259
24,525
0,74125
0,40375
0,55130
85,481
Minimum
Q1
Median
Q3 Maximum
0,2800
3,7000
4,4400
5,1900
6,4800
0,000000000
52,860
73,330
89,220 100,000
9,530
96,820
99,010
99,710 100,000
4,320
74,345
93,750
98,765 100,000
0,000000000
0,955
16,820
56,250
99,920
26,770
70,200
77,390
84,430
97,500
4,740
45,035
55,300
64,615
89,330
0,5500
3,6000
4,6400
5,3500
6,2800
0,36710 0,57890 0,64890 0,71540 0,94860
0,08000 0,43000 0,53000 0,64000 0,97000
45,720
79,525
87,510
92,530 100,000
6,400
41,275
57,420
71,380
94,910
0,000000000
4,293
12,580
20,050 333,330
0,0700
8,620
19,990
39,480
78,800
0,37460 0,66320 0,74600 0,82310 1,00000
0,000000000 0,30630 0,37580 0,47115 1,00000
0,000000000 0,19000 0,66000 0,91000 1,00000
8,881
45,722
79,528
87,510
92,529
1.4 Estatística Descritiva dos dados (adequação dos indicadores à escala 1-0)
Em seguida, para adequar os dados no estudo e possibilitar avaliações comparativas entre
estes, os indicadores, foram transformados em indicadores que variam de 0 à 1, e para tal
adotou-se à seguinte fórmula:
2.2 – AS VARIÁVEIS
As variáveis desta pesquisa incluem os 3 principais índices sintéticos que são ISDM, IFDM e
IFGF, que são médias ponderadas dos dados analíticos globais da pesquisa, e variáveis
analíticas, referente à educação, saúde, renda, emprego e habitação.
Tabela 1. As Variáveis
Variável
Significado
Tipo
UF
Abreviação de Unidade Federativa (ou Unidade da
Variável
Federação) do Brasil. As UF do Brasil são entidades
Categórica
Unidade de
Medida
N/A
autônomas, com governo e constituição próprias, que
em seu conjunto constituem a República Federativa do
Brasil. (IBGE, 2013)
Município
O município é a divisão administrativa autônoma da
Variável
UF. São as unidades de menor hierarquia dentro da
Categórica
N/A
organização político administrativa do Brasil, criadas
através de leis ordinárias das Assembléias Legislativas
de cada Unidade da Federação e sancionadas pelo
Governador. (IBGE, 2013)
UF2
Apresenta a sigla que representa as Unidades
Federativas (ou Unidades da Federação) do Brasil.
H- Habitação
Indicador do ISDM composto por H1, H2, H3, H4, H5,
H6.
H1- Água
Proporção de pessoas que vivem em domicilio com
Encanada
acesso à água canalizada em pelo menos um cômodo.
H2Esgotamento
Sanitário
H3- Coleta de
Lixo
Proporção de pessoas que vivem em domicilio com
Variável
N/A
Categórica
Variável
Percentual
Quantitátiva
Variável
Percentual
Quantitátiva
Variável
Percentual
esgotamento sanitário do tipo rede geral ou esgoto Quantitátiva
pluvial.
Proporção de pessoas que vivem em domicilio
Variável
atendido por coleta de lixo (realizada por serviço de Quantitátiva
Percentual
limpeza, ou cujo lixo é colocado em caçamba de
serviço de limpeza).
H4- Energia
Elétrica
Proporção de pessoas que vivem em domicilio que tem
Variável
Percentual
acesso à energia elétrica provida por companhia Quantitátiva
distribuidora.
H5Domicilio
Proporção de pessoas que vivem em domicilio próprio
de algum morador (Já pago ou ainda pagando).
Variável
Percentual
Quantitátiva
Próprio
H6-
Percentual de pessoas que vivem em domicilio que tem
Variável
Densidade
densidade de moradores por dormitório inferior à dois.
Quantitátiva
Indicador Social de Desenvolvimento dos Municipios,
Variável
Percentual
por
Dormitório
ISDM
Percentual
calculado pelo Centro de Economia Aplicada da Quantitátiva
Fundação Getulio Vargas (C-Micro-FGV)- pretende
contribuir para o debate de políticas publicas brasileira
fornecendo uma medida sintética de bem-estar dos
municípios
que
considere
algumas
de
suas
caracteristicas importantes relacionadas à dimensão de
Renda, Habitação, Educação, Trabalho, Saude e
Segurança.
IFDM
Indice Firjan de Desenvolvimento Municipal é um
Variável
estudo anual que acompanha o desenvolvimento dos Quantitátiva
0-1
Proporção
5565 municipios do Brasil em três áreas: Emprego e
Renda, Educação e Saúde, variando de 0à 1, sendo que
quanto mais próximo de 1, maior é o desenvolvimento
da localidade.
IFGF
Indice Firjan de Gestão Fiscal, para estimular a cultura
de
responsabilidade
administrativa
para Quantitátiva
aperfeiçoamento das decisões quanto à alocação de
recursos públicos afim de contribuir com uma gestão
eficiente e democrática e maior controle social da
gestão fiscal dos municípios. Indicadores: Receita
própria, pessoal, investimentos, liquidez e custo da
divida.
Variável
0-1
Proporção
E2_4
Percentual de crianças de 7 a 14 anos que estão na
Numérico
série correta segundo a idade
Escala
convertida
para
intervalo
entre 0 e 1.
T1_2-
Taxa de formalização entre os empregados
Numérico
Escala
Formalização
convertida
empregados
para
intervalo
entre 0 e 1.
S1_1-
Taxa de sobrevivência infantil no primeiro ano de vida,
Mortalidade
representada pela diferença entre o número de nascidos
Infantil
Numérico
Escala
convertida
vivos e o número de óbitos até um ano de idade.
para
intervalo
entre 0 e 1.
Numérico
R1- Linha de
Escala
convertida
Pobreza
para
intervalo
entre 0 e 1.
Educação
Média ponderada dos indicadores da dimensão
Numérico
Escala
Educação (E1_1, E1_2, E2_1, E2_2, E2_3, E2_4,
convertida
E2_5, E2_6, E3_1, E3_2 e E3_3) padronizada pela
para
intervalo
média do Brasil.
entre 0 e 1.
Emprego e
Renda
Geração, estoque e salários médios dos empregos
Numérico
formais (IFDM).
Escala
convertida
para
intervalo
entre 0 e 1.
Liquidez
Índice de liquidez dos municípios.
Numérico
Escala
convertida
para
intervalo
entre 0 e 1.
3. ANÁLISE DAS VARIÁVEIS
3.1 Variáveis Categóricas ou qualitativas.
Este tipo de variável indica que o foco de concentração deve ser a análise de gráficos do tipo
pie chart e barras.
3.1.1 Variável: “UF” e “UF2”
Nossa amostra totaliza 26 unidades federativas e 1 distrito federal. As unidades federativas
estão distribuídas em 5 regiões.
Unidades Federativas x Regiões
Norte
7.8%
Centro-Oeste
8.4%
Nordeste
32.2%
Category
Norte
Centro-Oeste
Sul
Sudeste
Nordeste
Sul
21.5%
Sudeste
30.0%
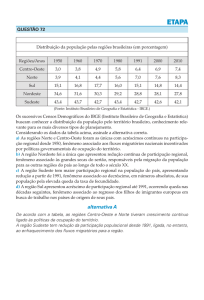
No que diz respeito a relação regiões e cidades pode-se observar no gráfico acima que as
regiões Nordeste (32,2%), Sudeste (30,0%) e Sul (21,5%) concentram 83, 7% dos municípios
do território nacional, enquanto as demais regiões, Norte (7.8%) e Centro-Oeste (8,4%)
somam apenas 16, 2% dos munícipios. Além da concentração dos municípios brasileiros, as
três regiões tem em comum o fato de serem as três regiões banhadas significativamente pelo
oceano Atlântico. Fato este, que nos ajuda a entender a concentração nestas regiões.
3.1.2 Variável: “Munícipios”
Os gráficos abaixo nos ajudam a entender melhor o comportamento desta variável
Cidades X Estados
Other AC AL
TO
AMAP
BA
SP
CE
SE
ES
GO
SC
MA
RS
RR
RO
MG
RN
RJ
PR
MS
MT
PI
.
PE
PB
PA
C ategory
AC
AL
AM
AP
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
O ther
Cidades X Estados
900
800
700
Cidades
600
500
400
300
200
100
0
I
DF RR AP AC RO AM SE E S MS RJ AL TO MT PA RN CE PE MA PB P GO SC PR BA RS SP MG
UF2
Análise:
- O comportamento dos municipios por Unidades Federativas (UF2) não consiste em
igualdade conforme demonstra os gráficos acima, pois enquanto o estado de Minas Gerais
que contém a maior quantidade de municípios brasileiros tem 851 cidades que correspondem
à 15,3 % , Roraima tem apenas 15 municipios que é correspondente à 0,3%.
Portanto Minas Gerais tem 57 vezes mais municípios que Roraima.
A distância aumenta ao considerarmos o Distrito Federal que tem somente uma cidade.
- O Primeiro e o segundo quartil concentram-se nas regiões Norte e Centro-Oeste, de maneira
que tem somente dois estados no Sudeste: Rio de Janeiro e Espirito Santo e no Nordeste
apenas: Alagoas e Sergipe, exclui-se deste contexto Goiás que corresponde ao quarto quartil
Portanto podemos afirmar que nestas regiões concentram-se os estados com menor quantidade
de municípios que totalizam 1.015, ou seja, as Regiões Norte e Centro-Oeste somadas aos
quatro estados descritos acima correspondem 18% do total de municípios brasileiros.
- No terceiro Quartil os estados possuem a quantidade de municípios entre 167 e 223
concentrados na Região Sul e Sudeste, incluindo a Bahia que pertence à região Nordeste ,
exclui-se deste contexto Rio de Janeiro e Espirito Santo.
Este quartil é composto por 1.198 municipios que correspondem à 22% do total de municípios
brasileiros.
-No ultimo Quartil visualizamos os estados que possuem as maiores quantidades de
municípios, com forte concentração na região Nordeste, excluindo-se destes os estados da
Bahia, Alagoas e Sergipe e incluimos Goias correspondente à região centro-oeste.
Deste total temos 3.352 municipios que correspondem à 60% do total de municípios
brasileiros., portanto a Região Nordeste é composta pelos estados que mais contém
municípios.
3.2 Variáveis Quantitativas
A variável quantitativa quando seus valores forem expressos em números, podendo estar
subdivididas em quantitativa discreta e quantitativa continua,de modo que o primeiro caso
refere-se aos valores contidos em um intervalo razoável e a segunda são aquelas cujo valor só
pode pertencer à um conjunto enumerável.
Usaremos neste caso ferramentas de análise tais como; histogramas, gráficos e as informações
numéricas disponíveis.
3.2.1 Variável: “IFGF”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável IFGF.
Summary for IFGF
A nderson-Darling N ormality Test
Histogra
ma e
Box-Plot
0.12
0.24
0.36
0.48
0.60
0.72
0.84
0.96
A -S quared
P -V alue <
14.16
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
0.52670
0.14790
0.02188
-0.220837
-0.400000
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0.08000
0.43000
0.53000
0.64000
0.97000
Medidas
Numéri
95% C onfidence Interv al for M ean
0.52281
0.53058
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tDev
0.53000
9 5 % C onfidence Inter vals
0.14521
0.54000
0.15070
Mean
Median
0.525
0.530
0.535
0.540
As principais observações que podemos fazer são:
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda.
Apresenta um pico decorrente do ajuste feito com informações do primeiro quartil para
preenchimento de valor dos municípios sem dados.
-
Valores Atípicos: Há 5 valores de IFGF atípicos no gráfico. Trata-se de 3 municípios do
Nordeste com valores muito baixos, Ilha Grande/PI (0,08), Buerarema/BA (0,10) e
Conceição/PB (0,11) e dois muito acima Poá/SP (0,96) e Santa Isabel/GO (0,97) conforme
demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos munícipios
têm IFGF menor do que 0,53 e metade IFGF maior do que este valor. O IFGF médio do
dos municípios é de 0,5267, e o desvio-padrão (medida de dispersão) é 0,1479. O IFGF
mínimo é de 0,08, e o máximo 0,97, demonstrando uma grande amplitude. A mediana é
de 0,53, estando muito próxima da média.
3.2.2 Variável: “IFDM”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável IFDM.
Summary for IFDM
A nderson-Darling N ormality Test
Histogra
ma e
Box-Plot
0.40
0.48
0.56
0.64
0.72
0.80
0.88
0.96
A -S quared
P -V alue <
6.01
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
0.64888
0.09580
0.00918
0.150127
-0.363881
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0.36710
0.57890
0.64890
0.71540
0.94860
95% C onfidence Interv al for M ean
0.64637
0.65140
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tDev
0.64450
9 5 % C onfidence Inter vals
0.09405
Mean
Median
0.644
0.646
0.648
0.650
As principais observações que podemos fazer são:
0.652
0.65211
0.09761
Medidas
Numéri
-
Forma: O histograma apresenta uma curva de freqüência simétrica, pois neste caso a
Mediana é igual à Média conforme está descrito no gráfico sumário e ranking acima.
Portanto podemos concluir que existem apenas seis estados com alto desenvolvimento:
22% e por outro lado apenas Alagoas com desenvolvimento regular: 4%, os demais 20
estados que correspondem à 74% tem desenvolvimento regular.
-
Valores Atípicos: Há 4 valores de IFDM atípicos, 2 que apresentam resultados abaixo de
0,37, e 2 que representam dados acima de 0,97, ou seja: Alagoas, Amapá, São Paulo e
Paraná respectivamente conforme demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem IFDM menor do que 0,64887. O IFDM médio é de 0,64888, bastante próximo da
média o que nos confirma a simetria. O desvio-padrão (medida de dispersão) é de
0,09580, que implica em uma dispersão grande da população e uma variação grande entre
os diversos municípios do Brasil.
3.2.3 Variável: “ISDM”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável ISDM.
Summary for ISDM
A nderson-D arling N ormality Test
Histogra
A -S quared
P -V alue <
75.79
0.005
ma e
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
4.4325
1.0929
1.1944
-0.541129
-0.522519
5565
Box-Plot
0.8
1.6
2.4
3.2
4.0
4.8
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
5.6
0.5500
3.6000
4.6400
5.3500
6.2800
95% C onfidence Interv al for M ean
4.4037
4.4612
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
4.5900
9 5 % C onfidence Inter vals
1.0729
Mean
Median
4.40
4.45
4.50
4.55
4.60
Com base neste quadro-resumo, concluímos:
4.65
4.70
4.7000
1.1136
Medidas
Numéri
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
demonstrando que muitos municípios possuem um nível médio de desenvolvimento ou
um nível baixo de desenvolvimento e poucas possuem um alto nível de desenvolvimento
Existem duas corcovas no gráfico que nos mostra que existem duas realidades diferentes
dentro dos dados analisados, ou seja, existem tipicamente dois tipos de municípios dentro
do Brasil, e cada tipo está em um estágio diferente de desenvolvimento.
-
Valores Atípicos: Há 3 valores de ISDM atípicos, que apresentam resultados abaixo de
0,8, que são os municípios de Chaves, PA; Amajari, RR e Melgaço, PA, conforme
demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem ISDM menor do que 4,64446. O ISDM médio é de 4,4324 , mas o desvio-padrão
(medida de dispersão) é de 1,0929, que implica em uma dispersão grande da população e
uma variação grande entre os diversos municípios do Brasil.
3.2.4 Variável: “H- Habitação”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável
“Habitação”.
Summary for H
A nderson-Darling N ormality Test
Histogra
ma e
Box-Plot
0.9
1.8
2.7
3.6
4.5
5.4
6.3
A -S quared
P -V alue <
20.89
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
4.3854
1.0228
1.0462
-0.441043
-0.208759
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0.2800
3.7000
4.4400
5.1900
6.4800
Medidas
Numéri
95% C onfidence Interv al for M ean
4.3585
4.4123
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
4.4100
9 5 % C onfidence Inter vals
1.0042
4.4700
1.0422
Mean
Median
4.350
4.375
4.400
4.425
4.450
4.475
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
demonstrando que muitos municípios possuem um nível médio de desenvolvimento ou
um nível baixo de desenvolvimento e poucas possuem um alto nível de desenvolvimento.
-
Valores Atípicos: Há 4 valores de Habitação atípicos, que apresentam resultados abaixo
de 0,9 que são os municípios de Canaã, PA; Maracanã, PA; Pacaraima RR e Wenceslau,
MG conforme demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de habitação menor do que 4,44. O índice de habitação médio é de 4,3854 ,
mas o desvio-padrão (medida de dispersão) é de 1,0228, que implica em uma dispersão
grande da população e uma variação grande entre os diversos municípios do Brasil.
3.2.5 Variável: “H1- Água Canalizada”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H1-Água
canalizada”.
Summary for H1
A nderson-D arling N ormality Test
Histogra
A -S quared
P -V alue <
88.44
0.005
ma e
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
69.480
22.520
507.164
-0.567641
-0.594060
5565
Box-Plot
0
14
28
42
56
70
84
98
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0.000
52.860
73.330
89.220
100.000
Medidas
Numéri
95% C onfidence Interv al for M ean
68.888
Intervalo
70.072
95% C onfidence Interv al for M edian
72.409
de
74.381
95% C onfidence Interv al for S tD ev
9 5 % C onfidence Inter vals
22.110
22.947
Mean
Median
69
70
71
72
73
74
75
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
demonstrando que na maior parte dos municípios as pessoas vivem em domicilio com
acesso à água canalizada em pelo menos um cômodo e poucos municípios não possuem
água canalizada, conforme pesquisa realizada em julho de 2008 pela Unesp conclui-se que
72% da população recebe água canalizada, ratificando nossos dados acima:
http://www.unesp.br/aci/jornal/235/agua.php
-
Valores Atípicos: Não há conforme demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de água canalizada menor do que 73.33. O índice de água canalizada médio é
de 69.480 , mas o desvio-padrão (medida de dispersão) é de 22.520, que implica em uma
dispersão grande da população e uma variação grande entre os diversos municípios do
Brasil.
3.2.6 Variável: “H2- Esgotamento Sanitário”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H2Esgotamento Sanitário”.
Summary for H2
A nderson-D arling N ormality Test
Histogra
ma e
Box-Plot
14
28
42
56
70
84
98
A -S quared
P -V alue <
958.66
0.005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
96.182
8.190
67.075
-4.3274
23.1906
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
9.530
96.820
99.010
99.710
100.000
Medidas
Numéri
95% C onfidence Interv al for M ean
95.967
96.397
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tDev
98.960
9 5 % C onfidence Inter vals
8.041
99.060
8.345
Mean
Median
96.0
96.5
97.0
97.5
98.0
98.5
99.0
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
demonstrando que na maior parte dos municípios as pessoas há uma alta taxa de pessoas
vivem em domicilio com esgotamento Sanitário do tipo rede ou esgoto pluvial, as baixas
taxas demonstram que existem cidades pouco desenvolvidas.
-
Valores Atípicos: Há muitos valores atípicos que apresentam resultados abaixo de 92.18
que são as cidades com esgotamento sanitário do tipo rede ou fluvial, significa portanto
que para estas cidades 6.82 % não são possuem esgotamento do tipo rede ou esgoto
pluvial.
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de esgotamento sanitário menor do que 99.010. O índice de esgotamento
sanitário médio é de 96.182 , mas o desvio-padrão (medida de dispersão) é de 8.190, que
implica em uma dispersão grande da população e uma variação grande entre os diversos
municípios do Brasil.
3.2.7 Variável: “H3- Coleta de Lixo”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H3“Coleta de lixo”.
Summary for H3
A nderson-D arling N ormality Test
Histogra
ma e
Box-Plot
14
28
42
56
70
84
98
A -S quared
P -V alue <
403.83
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
84.293
19.162
367.188
-1.40894
1.29274
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
4.320
74.345
93.750
98.765
100.000
Medidas
Numéri
95% C onfidence Interv al for M ean
83.789
84.796
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
93.020
9 5 % C onfidence Inter vals
18.813
94.301
19.525
Mean
Median
85.0
87.5
90.0
92.5
95.0
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
demonstrando que na maior parte dos municípios as pessoas vivem em domicilio com
Coleta de lixo.
-
Valores Atípicos: Há muitos valores atípicos que apresentam resultados abaixo de 37.67.
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de coleta de lixo menor do que 93.750. O índice de coleta de lixo médio é de
84.293 , mas o desvio-padrão (medida de dispersão) é de 19.162, que implica em uma
dispersão grande da população e uma variação grande entre os diversos municípios do
Brasil.
3.2.8 Variável: “H4- Energia elétrica”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H4Energia Elétrica”.
Summary for H4
A nderson-D arling N ormality Test
Histogra
ma e
Box-Plot
0
14
28
42
56
70
84
98
A -S quared
P -V alue <
339.06
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
29.807
31.679
1003.580
0.682199
-0.989971
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0.000
0.955
16.820
56.250
99.920
Medidas
Numéri
95% C onfidence Interv al for M ean
28.975
30.640
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
14.989
9 5 % C onfidence Inter vals
31.102
18.514
32.279
Mean
Median
15.0
17.5
20.0
22.5
25.0
27.5
30.0
-
Forma: O histograma apresenta uma curva de freqüência com assimetria positiva, pois
neste caso a Mediana é menor que a Média, a cauda é assimétrica à direita.
-
Valores Atípicos: Não há conforme demonstra o Box-plot..
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de energia elétrica menor do que 16.820. O índice de energia elétrica médio
é de 29.807 , mas o desvio-padrão (medida de dispersão) é de 31.679, que implica em uma
dispersão grande da população e uma variação grande entre os diversos municípios do
Brasil.
3.2.9 Variável: “H5- Domicilio Próprio”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H5Domicilio Próprio”.
Summary for H5
A nderson-D arling N ormality Test
Histogra
ma e
Box-Plot
30
40
50
60
70
80
A -S quared
P -V alue <
11.85
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
77.076
9.503
90.311
-0.265859
-0.271570
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
90
26.770
70.200
77.390
84.430
97.500
Medidas
Numéri
95% C onfidence Interv al for M ean
76.826
77.325
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
77.029
9 5 % C onfidence Inter vals
9.330
77.730
9.683
Mean
Median
76.8
77.0
77.2
77.4
77.6
77.8
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda
-
Valores Atípicos: Existem muitos valores atípicos que apresentam resultados abaixo de
48.61.
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de domicilio próprio menor do que 77.390 O índice de domicilio próprio
médio é de 77.076 , mas o desvio-padrão (medida de dispersão) é de 9.53, que implica em
uma dispersão grande da população e uma variação grande entre os diversos municípios
do Brasil.
3.2.10 Variável: “H6- Densidade por dormitório”
Segue abaixo quadro contendo Histograma, Curva de Densidade, Box-Plot, Intervalo de
confiança da média e mediana, além das medidas numéricas como média, desvio-padrão,
variância, quantidade de observações, valores mínimos, máximos, informações dos quartis e o
teste de normalidade de Anderson-Darling (A-Squared e P-Value), para a variável “H6Densidade por dormitório”.
Summary for H6
A nderson-D arling N ormality Test
Histogra
ma e
Box-Plot
12
24
36
48
60
72
A -S quared
P -V alue <
15.83
0.005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
54.319
13.553
183.680
-0.400633
-0.053847
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
84
4.740
45.035
55.300
64.615
89.330
Medidas
Numéri
95% C onfidence Interv al for M ean
53.963
54.675
Intervalo
95% C onfidence Interv al for M edian
de
95% C onfidence Interv al for S tD ev
54.879
9 5 % C onfidence Inter vals
13.306
55.794
13.809
Mean
Median
54.0
54.5
55.0
55.5
56.0
-
Forma: O histograma apresenta uma curva de freqüência com assimetria negativa, pois
neste caso a Mediana é maior que a Média, a cauda é assimétrica à esquerda.
-
Valores Atípicos: Existem muitos valores atípicos que apresentam resultados abaixo de
15.09
-
Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios
tem o índice de densidade por dormitório menor do que 0.59765. O índice densidade por
dormitório médio é de 0.59610 , mas o desvio-padrão (medida de dispersão) é de 0.16020,
que implica em uma dispersão grande da população e uma variação grande entre os
diversos municípios do Brasil.
3.2.11 VARIÁVEL EDUCAÇÃO
Summary for Educação
A nderson-Darling N ormality Test
0,45
0,54
0,63
0,72
0,81
0,90
0,99
A -S quared
P -V alue <
8,14
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,74065
0,11324
0,01282
-0,187656
-0,492979
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,37460
0,66200
0,74600
0,82310
1,00000
95% C onfidence Interv al for M ean
0,73767
0,74363
95% C onfidence Interv al for M edian
0,74218
0,75052
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,11118
0,11539
Mean
Median
0,738
0,740
0,742
0,744
0,746
0,748
0,750
As principais observações que podemos fazer são:
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição que tende a ser
simétrica cujo pico concentra-se no centro, o que é comum para variáveis que indiquem
desempenho regular. A curva apresenta várias corcovas, o que indica que temos diversas
realidades sobre a questão da variabilidade sobre Educação nos municípios do Brasil. Os
dados se dispersam muito, não existe um padrão na questão e pode-se concluir que existe
muita diversidade entre os dados.
- Valores Atípicos: Há muitos valores atípicos de Educação, que apresentam resultados
abaixo de 0,07636. O desempenho Educação é considerado médio nos municípios do Brasil.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
Educação menor do que 0,59467. A Educação média é 0,58679 e o desvio-padrão (medida de
dispersão) é de 0,17984, que implica em uma dispersão média para a questão.
3.2.12 VARIÁVEL EMPREGO E RENDA
Summary for Emprego e Renda
A nderson-Darling N ormality Test
0,00
0,14
0,28
0,42
0,56
0,70
0,84
0,98
A -S quared
P -V alue <
105,67
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,40375
0,15527
0,02411
0,88830
1,32099
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,30560
0,37580
0,47118
1,00000
95% C onfidence Interv al for M ean
0,39966
0,40783
95% C onfidence Interv al for M edian
0,37174
0,37960
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,15243
0,15821
Mean
Median
0,37
0,38
0,39
0,40
0,41
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição fortemente
assimétrica tendendo para a esquerda, o que é comum para variáveis que indiquem
desempenho baixo e menores números dentro de toda a distribuição dos dados. Esta
conclusão está comprovada pelo teste de normalidade de Anderson-Darling que indica que a
distribuição não pode ser considerada uma Normal. A maior parte das cidades possui valores
baixos de EMPREGO E RENDA. Muitas cidades possuem um nível médio de EMPREGO E
RENDA e poucas possuem um nível alto de EMPREGO E RENDA. Existe apenas uma
corcova no gráfico.
- Valores Atípicos: Há alguns valores atípicos de EMPREGO E RENDA atípicos, que
apresentam resultados abaixo de 0,4742, e muitos valores atípicos acima da curva (0,72208).
Esta informação nos diz que existem municípios no Brasil que apresentam Taxas de
EMPREGO E RENDA acima da curva e alguns abaixo da curva.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
EMPREGO E RENDA menor do que 0.37608. O EMPREGO E RENDA médio é de 0,40414
e o desvio-padrão (medida de dispersão) é de 0,15543, que implica em uma dispersão alta do
índice de EMPREGO E RENDA.
3.2.13 VARIÁVEL LIQUIDEZ
O indicador demonstra se o município possui recursos financeiros suficientes para fazer frente
ao montante de restos a pagar. Se o município apresentar mais restos a pagar do que ativos
financeiros disponíveis a pontuação será zero. Na leitura dos resultados, quanto mais próximo
de 1,00, menos o município está postergando pagamentos para o exercício seguinte sem a
devida cobertura
Summary for Liquidez
A nderson-Darling N ormality Test
0,00
0,14
0,28
0,42
0,56
0,70
0,84
0,98
A -S quared
P -V alue <
257,92
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,55136
0,37352
0,13952
-0,32322
-1,46949
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,19000
0,66000
0,91000
1,00000
95% C onfidence Interv al for M ean
0,54154
0,56118
95% C onfidence Interv al for M edian
0,63000
0,67000
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,36671
0,38059
Mean
Median
0,550
0,575
0,600
0,625
0,650
0,675
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição totalmente
assimétrica tendendo levemente para a direita, o que é comum para variáveis que indiquem
desempenho baixo e menores números dentro de toda a distribuição dos dados. Esta
conclusão está comprovada pelo teste de normalidade de Anderson-Darling que indica que a
distribuição não pode ser considerada uma Normal. Os valores de LIQUIDEZ se espalham
por todo o gráfico, não tendo um pico dos dados.
- Valores Atípicos: Não existem valores atípicos de LIQUIDEZ visto que a variabilidade dos
dados é tão alta que se distribui uniformemente por todo o gráfico. Não existe um padrão
nesta variável.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
LIQUIDEZ menor do que 0.66000. O LIQUIDEZ médio é de 0,55130 e o desvio-padrão
(medida de dispersão) é de 0,37328, que implica em uma dispersão absoluta do índice de
LIQUIDEZ.
3.2.14 VARIÁVEL R1 - Pessoas com renda domiciliar per capita abaixo da linha de
pobreza (R$ 140,00)
Summary for R1
A nderson-Darling N ormality Test
0
12
24
36
48
60
A -S quared
P -V alue <
154,09
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
24,528
17,698
313,220
0,512476
-0,932091
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
72
0,070
8,630
19,995
39,480
78,800
95% C onfidence Interv al for M ean
24,063
24,993
95% C onfidence Interv al for M edian
19,064
20,990
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
17,375
18,033
Mean
Median
19
20
21
22
23
24
25
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição que tende a ser
levemente assimétrica cujo pico concentra-se à esquerda, o que é comum para variáveis que
indiquem desempenho baixo. A curva apresenta algumas corcovas, sendo duas altamente
acentuadas, a primeira com maior pico e localizada fortemente à esquerda do gráfico. Indica
que o comportamento atípico da variabilidade sobre os dados de R1. Os dados se dispersam
bastante, e podemos afirmar que a variável R1 tem alta dispersão em relação aos municípios
do Brasil.
- Valores Atípicos: Não existem valores atípicos de R1.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
R1 menor do que 0.25299. O R1 médio é de 0.31059 e o desvio-padrão (medida de dispersão)
é de 0.22480, que implica em uma dispersão alta para R1.
3.2.15 VARIÁVEL T1_2 - Taxa de formalização entre os empregados
Summary for T1_2
A nderson-Darling N ormality Test
12
24
36
48
60
72
84
96
A -S quared
P -V alue <
41,06
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
56,299
18,233
332,425
-0,132243
-0,992998
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
6,400
41,273
57,415
71,380
94,910
95% C onfidence Interv al for M ean
55,820
56,778
95% C onfidence Interv al for M edian
56,580
58,206
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
17,900
18,578
Mean
Median
56,0
56,5
57,0
57,5
58,0
58,5
As principais observações que podemos fazer são:
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição simétrica,
embora o gráfico apresente várias corcovas na sua distribuiçõ. Indica que trata-se de um
desempenho regular. Esta conclusão está comprovada pelo teste de normalidade de AndersonDarling que indica que a distribuição pode ser considerada uma Normal. Muitas cidades
possuem um baixo nível de desenvolvimento, muitas cidades possuem um nível médio de
desenvolvimento e muitas possuem um nível alto de desenvolvimento. Existem várias
corcovas no gráfico que nos mostra que existem N realidades nos dados analisados, ou seja,
existem vários tipos de municípios dentro do Brasil em relação à formalização dos empregos.
- Valores Atípicos: Não existem valores atípicos de T1_2.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
T1_2 menor do que 0.57642. O T1_2 médio é de 0.56380, e o desvio-padrão (medida de
dispersão) é de 0.20600, que implica em uma dispersão grande da população de T1_2.
3.2.16 VARIÁVEL S1_1 - Taxa de mortalidade infantil, por mil nascidos vivos.
Summary for S1_1
A nderson-Darling N ormality Test
0
45
90
135
180
225
270
315
A -S quared
P -V alue <
160,55
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
14,261
14,283
204,007
4,2572
59,4151
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,000
4,278
12,575
20,080
333,330
95% C onfidence Interv al for M ean
13,885
14,636
95% C onfidence Interv al for M edian
12,294
12,916
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
14,023
14,554
Mean
Median
12,0
12,5
13,0
13,5
14,0
14,5
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição fortemente
assimétrica tendendo para a esquerda, o que é comum para variáveis que indiquem
desempenho baixo e menores números dentro de toda a distribuição dos dados. Esta
conclusão está comprovada pelo teste de normalidade de Anderson-Darling que indica que a
distribuição não pode ser considerada uma Normal. A maior parte das cidades possui valores
baixos de S1_1. Pouca cidades possuem um nível médio de S1_1 e quase nenhuma possuem
um nível alto de S1_1. Existem duas corcovas visíveis no gráfico. Como trata-se de nascido
vivos, o número baixo é bom porque a maioria dos nascidos vivos sobrevivem após um ano
de vida.
- Valores Atípicos: Há alguns valores atípicos de S1_1, que apresentam resultados acima de
0,13514. Esta informação nos diz que existem municípios no Brasil que apresentam Taxas de
S1_1 acima da curva, ou seja, que o índice de mortalidade é alto.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
S1_1 menor do que 0.03774. O S1_1 médio é de 0.04278 e o desvio-padrão (medida de
dispersão) é de 0.04285, que implica em uma dispersão baixa do índice de S1_1.
3.2.17 VARIÁVEL E2_4 – Crianças entre 7 e 14 anos que estudam na série correta
segundo sua idade
Summary for E2_4
A nderson-Darling N ormality Test
48
56
64
72
80
88
A -S quared
P -V alue <
95,36
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
85,480
8,882
78,889
-0,834909
0,263000
5564
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
96
45,720
79,523
87,510
92,530
100,000
95% C onfidence Interv al for M ean
85,246
85,713
95% C onfidence Interv al for M edian
87,164
87,880
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
8,720
9,050
Mean
Median
85,0
85,5
86,0
86,5
87,0
87,5
88,0
- Forma: O Histograma nos permite verificar que trata-se de uma distribuição fortemente
assimétrica tendendo para a direita, o que é comum para variáveis que indiquem desempenho
alto e taxas elevadas. Esta conclusão está comprovada pelo teste de normalidade de
Anderson-Darling que indica que a distribuição não pode ser considerada uma Normal. A
curva apresenta várias corcovas, o que indica que temos diversas realidades sobre a questão
da série correta dos alunos. Os dados se dispersam muito, não existe um padrão na questão e
pode-se concluir que existe muita diversidade entre a questão do grau correto de idade e
escolaridade nos municípios.
- Valores Atípicos: Há muitos valores atípicos de E2_4 atípicos, que apresentam resultados
abaixo de 0,25933 que são as cidades cujas crianças que estão na série correta.
- Centro e Dispersão: A mediana nos indica que aproximadamente metade dos municípios tem
E2_4 menor do que 0.76989. O E2_4 médio é de 0.73250 e o desvio-padrão (medida de
dispersão) é de 0.16363, que implica em uma dispersão grande para a questão.
RELAÇÃO ENTRE AS VARIÁVEIS
4
RELAÇÃO ENTRE VARIÁVEIS: CORRELAÇÃO, REGRESSÃO E TESTE QUIQUADRADO.
4.1
Gráficos de dispersão com LINHAS DE TENDÊNCIAS
Gráficos de dispersão devem ser inicialmente analisados quanto a seu padrão geral e seus
desvios relativos ao padrão. A descrição do padrão geral pode ser feita pela verificação de sua
forma, direção e intensidade.
4.2 GRÁFICOS DE DISPERSÃO entre variáveis Habitação e Emprego e Renda
GRAFH >> SCATTERPLOT >> SIMPLE
A quantidade de dados analisados é muito grande, são 5565 municípios, o que causa uma
“mancha” no gráfico e dificulta a visualização. Uma forma de contornar esta situação seria
selecionar os dados por amostragem, mas neste caso não é aplicado, pois não existem critérios
específicos que garantiriam a fidelidade da amostra em relação à população.
Scatterplot of Emprego e Renda vs H
1,0
Emprego e Renda
0,8
0,6
0,4
0,2
0,0
0,0
0,2
0,4
0,6
H
0,8
1,0
Gráficos de dispersão devem ser inicialmente analisados quanto a seu padrão geral e seus
desvios relativos ao padrão. A descrição do padrão geral pode ser feita pela verificação de sua
forma, direção e intensidade.
Direção: Da análise das correlações acima percebemos que quase todas possuem associações
positivas, ou seja, o crescimento de uma variável é acompanhado do crescimento da outra. O
que nos parece é que não há nenhuma associação negativa, ao menos de evidência visual.
Intensidade: O gráfico acima parece indicar a existência de relações lineares, embora no ponto
mais alto do gráfico os pontos tendem a decair, e perde a característica de uma reta.
Forma: O gráfico apresenta conglomerados que sugerem relações lineares, embora
prejudicado pelo excesso de dados da população (5565 linhas).
Valores Atípicos: Todos os gráficos indicam a existência de valores atípicos, ou seja,
indivíduos ou municípios que possuem seus indicadores de Habitação e Emprego e Renda
fora da curva.
4.3 LINHAS DE TENDÊNCIAS entre Habitação e Emprego e Renda
GRAFH >> SCATTERPLOT >> WITH REGRESSION
Scatterplot of H vs Emprego e Renda
1,0
0,8
H
0,6
0,4
0,2
0,0
0,0
0,2
0,4
0,6
Emprego e Renda
0,8
1,0
Para se verificar qual o tipo de relação (linear, quadrática, cúbica, exponencial, etc.) existente
entre as variáveis, adicionamos em cada gráfico de dispersão uma linha de tendência.
O gráfico analisado neste caso contém a variável Habitação em relação Emprego e Renda.
Podemos afirmar que os pontos estão muito próximos da linha e são ascendentes, o que nos
aponta que o tipo de relação entre as variáveis é linear, embora existam valores atípicos
distribuídos por toda a extensão da reta.
4.4 LINHAS DE TENDÊNCIAS entre Educação e H6 (Proporção de pessoas que vivem
em domicílio que tem densidade de moradores por dormitório inferior a 2)
Scatterplot of Educação vs H6
1,0
0,9
Educação
0,8
0,7
0,6
0,5
0,4
0,3
0,0
0,2
0,4
0,6
0,8
1,0
H6
O segundo gráfico compara a tendência entre as variáveis Educação com H6. Se
compararmos com o gráfico anterior, podemos constatar que a “nuvem de pontos” está mais
concentrada na parte superior que o gráfico anterior. As duas linhas são crescentes, e concluíse que quando aumenta o índice de Educação, cresce o Emprego e Renda e melhora a questão
da habitação.
4.5 CORRELAÇÃO LINEAR
A matriz de correlação incluí o teste de significância p-value. Para a correlação foi utilizado o
índice de Pearson. Vale ressaltar que o índice de correlação entre as variáveis não requer que
exista uma relação de causa-efeito entre ambas.
Esta primeira visão exibe a correlação entre todas as variáveis utilizadas no trabalho.
STAT >> BASIC STATISTICS >> CORRELATION
Correlations: H; H1; H2; H3; H4; H5; H6; ISDM;...
H
0,829
0,000
H1
H2
0,829
0,000
1,000
*
H3
0,831
0,000
0,684
0,000
0,684
0,000
H4
0,769
0,000
0,543
0,000
0,543
0,000
0,404
0,000
H5
-0,443
0,000
-0,515
0,000
-0,515
0,000
-0,481
0,000
H6
0,644
0,000
0,384
0,000
0,384
0,000
0,688
0,000
ISDM
0,916
0,000
0,808
0,000
0,808
0,000
0,869
0,000
IFDM
0,723
0,000
0,672
0,000
0,672
0,000
0,673
0,000
IFGF
0,309
0,000
0,284
0,000
0,284
0,000
0,367
0,000
E2_4
0,648
0,000
0,527
0,000
0,527
0,000
0,696
0,000
T1_2
0,672
0,000
0,682
0,000
0,682
0,000
0,642
0,000
S1_1
-0,102
0,000
-0,085
0,000
-0,085
0,000
-0,115
0,000
R1
-0,807
0,000
-0,738
0,000
-0,738
0,000
-0,837
0,000
Educação
0,710
0,000
0,592
0,000
0,592
0,000
0,664
0,000
Emprego e Re
0,475
0,000
0,521
0,000
0,521
0,000
0,385
0,000
Liquidez
0,197
0,000
0,185
0,000
0,185
0,000
0,255
0,000
H4
-0,434
0,000
H5
H6
ISDM
H6
0,209
0,000
-0,205
0,000
ISDM
0,583
0,000
-0,501
0,000
0,695
0,000
IFDM
0,464
0,000
-0,432
0,000
0,522
0,000
0,815
0,000
IFGF
0,104
0,000
-0,127
0,000
0,327
0,000
0,420
0,000
E2_4
0,329
-0,394
0,613
0,764
H1
H5
H2
H3
0,000
0,000
0,000
0,000
T1_2
0,405
0,000
-0,375
0,000
0,449
0,000
0,806
0,000
S1_1
-0,026
0,054
0,040
0,003
-0,115
0,000
-0,147
0,000
R1
-0,431
0,000
0,514
0,000
-0,709
0,000
-0,951
0,000
Educação
0,488
0,000
-0,454
0,000
0,552
0,000
0,782
0,000
Emprego e Re
0,354
0,000
-0,261
0,000
0,211
0,000
0,525
0,000
Liquidez
0,017
0,194
-0,051
0,000
0,260
0,000
0,276
0,000
IFDM
0,446
0,000
IFGF
E2_4
T1_2
E2_4
0,705
0,000
0,420
0,000
T1_2
0,737
0,000
0,429
0,000
0,599
0,000
S1_1
-0,182
0,000
-0,066
0,000
-0,128
0,000
-0,112
0,000
R1
-0,801
0,000
-0,455
0,000
-0,768
0,000
-0,782
0,000
Educação
0,810
0,000
0,386
0,000
0,765
0,000
0,609
0,000
Emprego e Re
0,778
0,000
0,330
0,000
0,363
0,000
0,586
0,000
Liquidez
0,282
0,000
0,766
0,000
0,263
0,000
0,302
0,000
S1_1
0,140
0,000
R1
Educação
-0,122
0,000
-0,753
0,000
Emprego e Re
-0,077
0,000
-0,509
0,000
0,377
0,000
Liquidez
-0,049
0,000
-0,308
0,000
0,234
0,000
IFGF
R1
Cell Contents: Pearson correlation
P-Value
Educação Emprego e Re
0,197
0,000
4.6
Regressão dos mínimos quadrados
A correlação mede a direção e a intensidade da relação linear (linha reta) entre duas variáveis
quantitativas. Se um diagrama de dispersão mostra uma relação linear, é interessante
resumirmos esse padrão geral traçando uma reta no diagrama de dispersão. Uma reta de
regressão resume a relação entre duas variáveis, mas somente em um contexto específico:
quando uma das variáveis ajuda a explicar ou a predizer a outra, ou seja, a regressão descreve
uma relação entre uma variável explanatória e uma variável resposta.
A regressão linear assume sempre a forma de uma equação linear:
Y = a + bx, sendo:
Y= Variável dependente;
a = uma constante, o intercepto;
b = a inclinação na reta;
x = variável independente ou explicativa.
O “b”, ou seja, a declividade é dada pela multiplicação do índice de correlação pela divisão
dos desvios-padrão entre as variáveis x e y. E “a” é dado pela média de “Y” menos a
multiplicação de “b” pela média de “x”. Assim, percebe-se muito claramente que a regressão
depende da correlação entre as variáveis, além de medidas de centro de cada uma das
variáveis.
Segue abaixo o resultado da regressão entre as variáveis R1 e H3.
Regression Analysis: R1 versus H3
The regression equation is
R1 = 1,10 - 0,940 H3
Predictor
Constant
H3
Coef SE Coef
1,09630
0,00707
-0,939997 0,008224
S = 0,122858
R-Sq = 70,1%
T
155,10
-114,30
P
0,000
0,000
R-Sq(adj) = 70,1%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
1
5563
5564
SS
197,19
83,97
281,16
MS
197,19
0,02
F
13064,11
P
0,000
A tabela acima exibe o resultado da fórmula entre as variáveis R1 e H3(Coleta de Lixo). Se
substituísse o valor de H3 se chegaria ao valor de R1 esperado. A é a expressão numérica da
reta de tendência que vimos nos itens acima. Esta equação tem um poder explicativo de
70,18%, que é o R-Quadrado. O valor da constante 1,10 significa que, se o H3 fosse zero, o
valor da R1 seria 1,10.
4.7
Dendrograma
Dendrogram with Single Linkage and Correlation Coefficient Distance
Similarity
48,71
65,80
82,90
100,00
H
DM
IS
H3
H1
H2
o _2 da H4 _4
DM ã
IF caç T1 Ren
E2
u
d
e
E
o
eg
pr
Em
Variables
z
H6 FGF ide
I
u
q
Li
Gráfico 1 - Dendrograma das 13 variáveis
Cluster Analysis of Variables: H; H1; H2; H3; H4; H5; H6; ISDM;...
Correlation Coefficient Distance, Single Linkage
Amalgamation Steps
Step
1
2
3
4
5
6
Number
of
clusters
16
15
14
13
12
11
Similarity
level
100,000
95,795
93,435
91,442
90,744
90,476
Distance
level
0,00000
0,08409
0,13130
0,17117
0,18512
0,19048
Clusters
joined
2
3
1
8
1
4
1
2
1
9
1
15
New
cluster
2
1
1
1
1
1
Number
of obs.
in new
cluster
2
2
3
5
6
7
H5
R1 1_1
S
7
8
9
10
11
12
13
14
15
16
10
9
8
7
6
5
4
3
2
1
90,318
88,922
88,444
88,304
88,263
84,756
75,721
72,322
57,016
48,707
0,19363
0,22157
0,23113
0,23393
0,23474
0,30487
0,48558
0,55356
0,85969
1,02585
1
1
1
10
1
1
6
1
6
1
12
16
5
17
11
7
14
10
13
6
1
1
1
10
1
1
6
1
6
1
8
9
10
2
11
12
2
14
3
17
ANÁLISE DE REGRESSÃO E STEPWISE
5
REGRESSÕES MULTIPLAS
5.1
Regressão Stepwise
Stepwise Regression: ISDM versus H; H1;...
Alpha-to-Enter: 0,15
Alpha-to-Remove: 0,15
Response is ISDM on 15 predictors, with N = 5565
Step
Constant
R1
T-Value
P-Value
1
0,9282
2
0,5117
3
0,4391
4
0,3839
5
0,3592
6
0,3352
-0,8069
-229,28
0,000
-0,5153
-148,50
0,000
-0,4463
-117,94
0,000
-0,4125
-97,91
0,000
-0,4070
-96,31
0,000
-0,3907
-85,20
0,000
0,4923
104,12
0,000
0,4760
109,57
0,000
0,4707
110,69
0,000
0,4606
105,54
0,000
0,4390
88,21
0,000
0,1098
33,33
0,000
0,1103
34,31
0,000
0,1095
34,30
0,000
0,1124
35,26
0,000
0,0654
16,66
0,000
0,0480
11,04
0,000
0,0415
9,48
0,000
0,0579
9,09
0,000
0,0641
10,07
0,000
H
T-Value
P-Value
T1_2
T-Value
P-Value
E2_4
T-Value
P-Value
Educação
T-Value
P-Value
H3
T-Value
P-Value
S
R-Sq
R-Sq(adj)
Step
Constant
R1
T-Value
P-Value
H
0,0381
8,86
0,000
0,0590
90,43
90,43
0,0344
96,76
96,75
0,0314
97,30
97,29
0,0306
97,42
97,42
0,0304
97,46
97,46
7
0,3387
8
0,3404
9
0,3426
10
0,3410
-0,3891
-85,24
0,000
-0,3902
-85,25
0,000
-0,3912
-85,02
0,000
-0,3898
-83,70
0,000
0,4399
0,4382
0,4399
0,4336
0,0302
97,50
97,49
T-Value
P-Value
88,86
0,000
87,97
0,000
87,13
0,000
72,16
0,000
T1_2
T-Value
P-Value
0,1122
35,39
0,000
0,1133
35,52
0,000
0,1155
34,24
0,000
0,1144
33,41
0,000
E2_4
T-Value
P-Value
0,0408
9,37
0,000
0,0413
9,48
0,000
0,0411
9,45
0,000
0,0421
9,61
0,000
Educação
T-Value
P-Value
0,0631
9,97
0,000
0,0632
10,00
0,000
0,0626
9,89
0,000
0,0630
9,95
0,000
H3
T-Value
P-Value
0,0380
8,88
0,000
0,0386
9,02
0,000
0,0374
8,64
0,000
0,0381
8,78
0,000
S1_1
T-Value
P-Value
-0,0748
-7,87
0,000
-0,0748
-7,88
0,000
-0,0750
-7,90
0,000
-0,0753
-7,94
0,000
-0,0034
-2,96
0,003
-0,0033
-2,89
0,004
-0,0032
-2,82
0,005
-0,0065
-2,00
0,045
-0,0074
-2,24
0,025
Liquidez
T-Value
P-Value
Emprego e Renda
T-Value
P-Value
H2
T-Value
P-Value
S
R-Sq
R-Sq(adj)
5.2
0,0066
1,92
0,055
0,0300
97,52
97,52
0,0300
97,53
97,52
0,0300
97,53
97,53
0,0300
97,53
97,53
Regressão Múltiplas
O Próximo passo é calcular a formula utilizando as variáveis demonstradas pela função
Stepwise como sendo as que mais explicam Habitação.
5.2.1 Regression Analysis: H versus H1; H2;...
H = - 0,128 + 0,239 H1 + 0,245 H3 + 0,228 H4 + 0,157 H5 + 0,216 H6 + 0,131
ISDM
+ 0,0143 E2_4 - 0,0209 T1_2 - 0,00458 S1_1 + 0,0680 R1 + 0,00621
Educação
+ 0,00177 Emprego e Renda - 0,00240 Liquidez
Predictor
Coef
SE Coef
T
P
Constant
H1
H3
H4
H5
H6
ISDM
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
S = 0,0150090
-0,127748
0,239218
0,245164
0,227765
0,156784
0,216409
0,131165
0,014288
-0,020865
-0,004577
0,067980
0,006205
0,001771
-0,0023983
0,004308
0,001751
0,002245
0,001053
0,001991
0,002191
0,006489
0,002233
0,001890
0,004783
0,003603
0,003243
0,001671
0,0005811
R-Sq = 99,2%
-29,65
136,60
109,23
216,34
78,73
98,77
20,21
6,40
-11,04
-0,96
18,87
1,91
1,06
-4,13
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,339
0,000
0,056
0,289
0,000
R-Sq(adj) = 99,2%
5.2.2 Regression Analysis: H versus H1; H2; .
Na Segunda tentativa, expurgando os dados da última análise que não faziam parte dos
indicadores de Habitação, basicamente, mantivemos o mesmo nível explicativo da equação
(99,2%).
The regression equation is
H = - 0,129 + 0,238 H1 + 0,245 H3 + 0,228 H4 + 0,158 H5 + 0,215 H6 + 0,131 ISDM
+ 0,0232 IFDM - 0,0188 IFGF + 0,0154 E2_4 - 0,0217 T1_2 + 0,0674 R1
+ 0,00250 Liquidez
Predictor
Constant
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
R1
Liquidez
Coef
-0,129300
0,237785
0,245424
0,227529
0,157617
0,215249
0,130615
0,023152
-0,018815
0,015373
-0,021663
0,067412
0,0024954
S = 0,0148949
SE Coef
0,004408
0,001726
0,002220
0,001031
0,001967
0,002170
0,006345
0,003921
0,002316
0,002085
0,001849
0,003588
0,0008441
R-Sq = 99,2%
T
-29,33
137,78
110,54
220,67
80,14
99,21
20,59
5,90
-8,12
7,37
-11,71
18,79
2,96
P
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,000
0,003
R-Sq(adj) = 99,2%
Analysis of Variance
Source
Regression
Residual Error
Total
DF
12
5552
5564
COMPARAÇÕES
SS
150,194
1,232
151,426
MS
12,516
0,000
F
56415,64
P
0,000
6
COMPARAÇÕES - ANOVA
6.1
Variável ISDM por Região
Boxplot of ISDM by Região
1,0
0,8
ISDM
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior ISDM do país, o que indica que esta é a região com melhor
desenvolvimento dos municípios do Brasil, segundo a pesquisa. A região Sul e Centro Oeste
encontram-se próxima a região Sudeste, e ocupam, em ordem decrescente, o segundo e
terceiro lugar. Seguidas pela região Norte e, por último, com o pior desempenho, pela região
Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Norte, a maior variabilidade de quando comparo com os dados das
demais regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O Pvalue = 0 nos indica que a informação é confiável e não existe chance deste valor ser
diferente.
One-way ANOVA: ISDM versus Região
Source
Região
Error
Total
DF
4
5560
5564
SS
127,5665
74,8397
202,4062
MS
31,8916
0,0135
F
2369,30
P
0,000
S = 0,1160
R-Sq = 63,02%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
Mean
0,7235
0,4993
0,4806
0,8221
0,7988
R-Sq(adj) = 63,00%
StDev
0,0916
0,1245
0,1709
0,1123
0,0875
Individual 95% CIs For Mean Based on
Pooled StDev
---+---------+---------+---------+-----(*)
(*
(*)
*)
(*)
---+---------+---------+---------+-----0,50
0,60
0,70
0,80
Pooled StDev = 0,1160
6.2
Variável H por Região
Boxplot of H by Região
1,0
0,8
H
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior Habitação do país, o que indica que esta é a região com
melhor desenvolvimento de Habitação nos municípios do Brasil, segundo a pesquisa. A
região Sul e Centro Oeste encontram-se próxima a região Sudeste, e ocupam, em ordem
decrescente, o segundo e terceiro lugar. Seguidas pela região Norte e, por último, com o pior
desempenho, pela região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Norte, a maior variabilidade de quando comparo com os dados das
demais regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O P-
value = 0 nos indica que a informação é confiável e não existe chance deste valor ser
diferente.
One-way ANOVA: H versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1122
SS
81,4322
69,9939
151,4261
MS
20,3581
0,0126
R-Sq = 53,78%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
F
1617,15
P
0,000
R-Sq(adj) = 53,74%
Mean
0,6383
0,5501
0,4479
0,8053
0,7198
StDev
0,0938
0,1284
0,1392
0,1058
0,0873
Individual 95% CIs For Mean Based on
Pooled StDev
------+---------+---------+---------+--(*)
(*)
(*)
(*
(*)
------+---------+---------+---------+--0,50
0,60
0,70
0,80
Pooled StDev = 0,1122
6.3
Variável H1 por Região
Boxplot of H1 by Região
1,0
0,8
H1
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de ÁGUA ENCANADA-H1 do país, o que indica que
esta é a região com melhor no Brasil neste quesito, segundo a pesquisa. A região Sul e Centro
Oeste encontram-se próxima a região Sudeste, e ocupam, em ordem decrescente, o segundo e
terceiro lugar. Seguidas pela região Norte e, por último, com o pior desempenho, pela região
Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Nordeste, a maior variabilidade de quando comparo com os dados das
demais regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O Pvalue = 0 nos indica que a informação é confiável e não existe chance deste valor ser
diferente.
One-way ANOVA: H1 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1948
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
71,2868
210,8990
282,1858
MS
17,8217
0,0379
R-Sq = 25,26%
N
468
1790
447
1669
1191
Mean
0,7459
0,5624
0,5460
0,8117
0,7657
Pooled StDev = 0,1948
F
469,84
P
0,000
R-Sq(adj) = 25,21%
StDev
0,1560
0,2136
0,1981
0,1793
0,1982
Individual 95% CIs For Mean Based on
Pooled StDev
----+---------+---------+---------+----(-*-)
(*)
(-*--)
(*-)
(-*)
----+---------+---------+---------+----0,560
0,640
0,720
0,800
6.4
Variável H2 por Região
Boxplot of H2 by Região
1,0
0,8
H2
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de ESGOTAMENTO SANITÁRIO- H2 do país, o
que indica que esta é a região com melhor desempenho no Brasil neste quesito, segundo a
pesquisa. A região Sul e Centro Oeste encontram-se próxima a região Sudeste, e ocupam, em
ordem decrescente, o segundo e terceiro lugar. Seguidas pela região Norte e, por último, com
o pior desempenho, pela região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Nordeste, a maior variabilidade de quando comparo com os dados das
demais regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O Pvalue = 0 nos indica que a informação é confiável e não existe chance deste valor ser
diferente.
One-way ANOVA: H2 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1948
Level
SS
71,2868
210,8990
282,1858
MS
17,8217
0,0379
R-Sq = 25,26%
N
Mean
F
469,84
P
0,000
R-Sq(adj) = 25,21%
StDev
Individual 95% CIs For Mean Based on
Pooled StDev
----+---------+---------+---------+-----
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
468
1790
447
1669
1191
0,7459
0,5624
0,5460
0,8117
0,7657
0,1560
0,2136
0,1981
0,1793
0,1982
(-*-)
(*)
(-*--)
(*-)
(-*)
----+---------+---------+---------+----0,560
0,640
0,720
0,800
Pooled StDev = 0,1948
6.5
Variável H3 por Região
Boxplot of H3 by Região
1,0
0,8
H3
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sul possui o maior índice de COLETA DE LIXO- H3do país, o que indica que esta é
a região com melhor desempenho no Brasil neste quesito, segundo a pesquisa. A região
Sudeste e Centro Oeste encontram-se próxima a região Sul, e ocupam, em ordem decrescente,
o segundo e terceiro lugar. Seguidas pela região Norte e, por último, com o pior desempenho,
pela região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sul possui a menor e o da
região Nordeste, a maior variabilidade de quando comparo com os dados das demais regiões.
A região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos
indica que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: H3 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1356
SS
120,9263
102,2424
223,1687
MS
30,2316
0,0184
R-Sq = 54,19%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
F
1644,01
P
0,000
R-Sq(adj) = 54,15%
Mean
0,9244
0,6664
0,6205
0,9530
0,9724
StDev
0,0877
0,1921
0,2160
0,0757
0,0439
Individual 95% CIs For Mean Based on
Pooled StDev
---------+---------+---------+---------+
(*-)
(*
(*)
*)
(*)
---------+---------+---------+---------+
0,70
0,80
0,90
1,00
Pooled StDev = 0,1356
6.6
Variável H4 por Região
Boxplot of H4 by Região
1,0
0,8
H4
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de ENERGIA ELÉTRICA- H4 do país, o que indica
que esta é a região com melhor desempenho no Brasil neste quesito, segundo a pesquisa. A
região Nordeste e Sul encontram-se próxima a região Sudeste, e ocupam, em ordem
decrescente, o segundo e terceiro lugar. Seguidas pela região Centro-Oeste e, por último, com
o pior desempenho, pela região Norte.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Norte possui a menor e o da
região Sudeste, a maior variabilidade de quando comparo com os dados das demais regiões. A
região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos indica
que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: H4 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,2228
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
283,3035
275,9829
559,2864
MS
70,8259
0,0496
R-Sq = 50,65%
N
468
1790
447
1669
1191
Mean
0,1054
0,1885
0,0357
0,6372
0,1628
F
1426,87
P
0,000
R-Sq(adj) = 50,62%
StDev
0,1862
0,2263
0,0777
0,2572
0,2152
Individual 95% CIs For Mean Based on
Pooled StDev
---------+---------+---------+---------+
(-*)
(*
(*-)
(*
(*)
---------+---------+---------+---------+
0,16
0,32
0,48
0,64
Pooled StDev = 0,2228
6.7
Variável H5 por Região
Boxplot of H5 by Região
1,0
0,8
H5
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Norte possui o maior índice de DOMICILIO PRÓPRIO- H5 do país, o que indica
que esta é a região com melhor desempenho no Brasil neste quesito, segundo a pesquisa. A
região Nordeste e Sul encontram-se próxima a região Norte, e ocupam, em ordem
decrescente, o segundo e terceiro lugar. Seguidas pela região Sudeste e, por último, com o
pior desempenho, pela região Centro-Oeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Norte, a maior variabilidade de quando comparo com os dados das
demais regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O Pvalue = 0 nos indica que a informação é confiável e não existe chance deste valor ser
diferente.
One-way ANOVA: H5 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1168
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
24,5395
75,9035
100,4431
MS
6,1349
0,0137
R-Sq = 24,43%
N
468
1790
447
1669
1191
Mean
0,5885
0,7744
0,7754
0,6430
0,7360
Pooled StDev = 0,1168
F
449,39
P
0,000
R-Sq(adj) = 24,38%
StDev
0,1122
0,1142
0,1262
0,1209
0,1132
Individual 95% CIs For Mean Based on
Pooled StDev
----+---------+---------+---------+----(-*-)
(*)
(-*-)
(*)
(*)
----+---------+---------+---------+----0,600
0,660
0,720
0,780
6.8
Variável H6 por Região
Boxplot of H6 by Região
1,0
0,8
H6
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sul possui o maior índice de DENSIDADE POR DORMITÓRIO- H6 do país, o que
indica que esta é a região com melhor desempenho no Brasil neste quesito, segundo a
pesquisa. A região Sudeste e Centro-Oeste encontram-se próxima a região Sul, e ocupam, em
ordem decrescente, o segundo e terceiro lugar. Seguidas pela região Nordeste e, por último,
com o pior desempenho, pela região Norte.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sudeste possui a menor e o
da região Norte, a maior variabilidade de quando comparo com os dados das demais regiões.
A região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos
indica que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: H6 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1117
SS
73,4685
69,3587
142,8273
MS
18,3671
0,0125
R-Sq = 51,44%
F
1472,36
P
0,000
R-Sq(adj) = 51,40%
Individual 95% CIs For Mean Based on
Pooled StDev
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
Mean
0,6321
0,4774
0,3725
0,6421
0,7331
StDev
0,1147
0,1044
0,1728
0,1065
0,0983
----+---------+---------+---------+----(*)
(*
(*)
*)
*)
----+---------+---------+---------+----0,40
0,50
0,60
0,70
Pooled StDev = 0,1117
6.9
Variável E2_4 por Região
Boxplot of E2_4 by Região
1,0
0,8
E2_4
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de CRIANÇAS NA SÉRIE CORRETA- E2_4 do
país, o que indica que esta é a região com melhor desempenho no Brasil neste quesito,
segundo a pesquisa. A região Sul e Centro-Oeste encontram-se próxima a região Sudeste, e
ocupam, em ordem decrescente, o segundo e terceiro lugar. Seguidas pela região Norte e, por
último, com o pior desempenho, pela região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sul possui a menor e o da
região Norte, a maior variabilidade de quando comparo com os dados das demais regiões. A
região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos indica
que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: E2_4 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1139
SS
76,7860
72,1743
148,9604
MS
19,1965
0,0130
R-Sq = 51,55%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
Mean
0,8011
0,5882
0,5969
0,8245
0,8445
F
1478,82
P
0,000
R-Sq(adj) = 51,51%
StDev
0,0887
0,1298
0,1841
0,1017
0,0711
Individual 95% CIs For Mean Based on
Pooled StDev
-------+---------+---------+---------+-(*-)
(*)
(*-)
(*)
(*)
-------+---------+---------+---------+-0,630
0,700
0,770
0,840
Pooled StDev = 0,1139
6.10 Variável T1_2 por Região
Boxplot of T1_2 by Região
1,0
0,8
T1_2
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sul possui o maior índice de FORMALIZAÇÃO DE EMPREGADOS- T1
_2 do país, o que indica que esta é a região com melhor desempenho no Brasil neste quesito,
segundo a pesquisa. A região Sudeste e Centro-Oeste encontram-se próxima a região Sul, e
ocupam, em ordem decrescente, o segundo e terceiro lugar. Seguidas pela região Norte e, por
último, com o pior desempenho, pela região Nordeste
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Centro-Oeste possui a
menor e o da região Sudeste a maior variabilidade de quando comparo com os dados das
demais regiões. O P-value = 0 nos indica que a informação é confiável e não existe chance
deste valor ser diferente.
One-way ANOVA: T1_2 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1549
SS
102,6914
133,4452
236,1366
MS
25,6729
0,0240
R-Sq = 43,49%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
Mean
0,5931
0,3929
0,4486
0,6581
0,7204
F
1069,66
P
0,000
R-Sq(adj) = 43,45%
StDev
0,1337
0,1510
0,1542
0,1782
0,1321
Individual 95% CIs For Mean Based on
Pooled StDev
-+---------+---------+---------+-------(*-)
*)
(-*)
(*)
(*)
-+---------+---------+---------+-------0,40
0,50
0,60
0,70
Pooled StDev = 0,1549
6.11 Variável S1_1 por Região
Boxplot of S1_1 by Região
1,0
0,8
S1_1
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A semelhança em todas as regiões dá-se pelo motivo que a saúde é de péssima qualidade em
todo o Brasil, e que a taxa de Mortalidade Infantil é de forma semelhante com uma leve
acentuação na Região Norte e Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Nordeste possui a menor e o
da região Sudeste, a maior variabilidade de quando comparo com os dados das demais
regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0
nos indica que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: S1_1 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,04249
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
0,17433
10,03992
10,21426
MS
0,04358
0,00181
R-Sq = 1,71%
N
468
1790
447
1669
1191
Mean
0,04258
0,04741
0,05346
0,04080
0,03467
Pooled StDev = 0,04249
F
24,14
P
0,000
R-Sq(adj) = 1,64%
StDev
0,05075
0,03271
0,04539
0,04173
0,05104
Individual 95% CIs For Mean Based on
Pooled StDev
----+---------+---------+---------+----(-----*----)
(--*--)
(----*-----)
(--*--)
(---*--)
----+---------+---------+---------+----0,0350
0,0420
0,0490
0,0560
6.12 Variável R1 por Região
Boxplot of R1 by Região
1,0
0,8
R1
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Norte possui o maior índice de LINHA DE POBREZA-R1 do país, o que indica que
esta é a região no Brasil onde existem mais pessoas que ganham renda domiciliar per capita
abaixo de R$140,00o, segundo a pesquisa. A região Nordeste encontra-se próxima a região
Norte, e ocupando o segundo lugar. Seguidas pela região Sudeste , Centro-Oeste e, por
último, com o melhor desempenho, pela região Sul.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sul possui a menor e o da
região Norte, a maior variabilidade de quando comparo com os dados das demais regiões. A
região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos indica
que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: R1 versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1313
Level
SS
185,3335
95,8256
281,1591
MS
46,3334
0,0172
R-Sq = 65,92%
N
Mean
F
2688,36
P
0,000
R-Sq(adj) = 65,89%
StDev
Individual 95% CIs For Mean Based on
Pooled StDev
+---------+---------+---------+---------
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
468
1790
447
1669
1191
0,1926
0,5388
0,5027
0,1778
0,1281
0,1171
0,1346
0,1928
0,1339
0,0940
(*)
(*
(*)
(*
(*
+---------+---------+---------+--------0,12
0,24
0,36
0,48
Pooled StDev = 0,1313
6.13 Variável Educação por Região
Boxplot of Educação by Região
1,0
0,9
Educação
0,8
0,7
0,6
0,5
0,4
0,3
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de Educação do país, o que indica que esta é a região
com melhor desempenho no Brasil neste quesito, segundo a pesquisa. A região Sul e CentroOeste encontram-se próxima a região Sudeste, e ocupam, em ordem decrescente, o segundo e
terceiro lugar. Seguidas pela região Nordeste e, por último, com o pior desempenho, pela
região Norte.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sul possui a menor e o da
região Sudeste, a maior variabilidade de quando comparo com os dados das demais regiões. A
região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos indica
que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: Educação versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,07869
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
35,82821
34,42415
70,25236
MS
8,95705
0,00619
R-Sq = 51,00%
N
468
1790
447
1669
1191
Mean
0,75299
0,65090
0,63739
0,83427
0,78106
F
1446,69
P
0,000
R-Sq(adj) = 50,96%
StDev
0,07162
0,08127
0,08599
0,08138
0,07021
Individual 95% CIs For Mean Based on
Pooled StDev
-----+---------+---------+---------+---(*-)
*)
(*)
(*)
(*)
-----+---------+---------+---------+---0,660
0,720
0,780
0,840
Pooled StDev = 0,07869
6.14 Variável Emprego e Renda por Região
Boxplot of Emprego e Renda by Região
1,0
Emprego e Renda
0,8
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sudeste possui o maior índice de Emprego e Renda do país, o que indica que esta é a
região com melhor desempenho no Brasil neste quesito, segundo a pesquisa. A região CentroOeste e Sul encontram-se próxima a região Sudeste, e ocupam, em ordem decrescente, o
segundo e terceiro lugar. Seguidas pela região Norte e, por último, com o pior desempenho,
pela região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Nordeste possui a menor e o
da região Sudeste, a maior variabilidade de quando comparo com os dados das demais
regiões. A região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0
nos indica que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: Emprego e Renda versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,1446
SS
17,7960
116,2982
134,0942
MS
4,4490
0,0209
R-Sq = 13,27%
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
N
468
1790
447
1669
1191
Mean
0,4173
0,3348
0,3415
0,4490
0,4620
F
212,70
P
0,000
R-Sq(adj) = 13,21%
StDev
0,1389
0,1288
0,1419
0,1681
0,1345
Individual 95% CIs For Mean Based on
Pooled StDev
--------+---------+---------+---------+(--*---)
(-*)
(--*---)
(*-)
(-*--)
--------+---------+---------+---------+0,360
0,400
0,440
0,480
Pooled StDev = 0,1446
6.15 Variável Liquidez por Região
Boxplot of Liquidez by Região
1,0
Liquidez
0,8
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
A região Sul possui o maior índice de Liquidez do país, o que indica que esta é a região com
melhor desempenho no Brasil neste quesito, segundo a pesquisa. A região Centro-oeste e
Norte encontram-se próxima a região Sul, e ocupam, em ordem decrescente, o segundo e
terceiro lugar. Seguidas pela região Sudeste e, por último, com o pior desempenho, pela
região Nordeste.
Pelo tamanho da caixa do BloxPlot podemos visualizar a amplitude da variância, ou seja, a
partir da análise gráfica, podemos afirmar que os dados da região Sul possui a menor e o da
região Norte, a maior variabilidade de quando comparo com os dados das demais regiões. A
região que possui menor variabilidade dos dados é a Centro-Oeste. O P-value = 0 nos indica
que a informação é confiável e não existe chance deste valor ser diferente.
One-way ANOVA: Liquidez versus Região
Source
Região
Error
Total
DF
4
5560
5564
S = 0,3489
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
99,409
676,864
776,273
MS
24,852
0,122
R-Sq = 12,81%
N
468
1790
447
1669
1191
Mean
0,6540
0,3822
0,5408
0,5719
0,7402
F
204,15
P
0,000
R-Sq(adj) = 12,74%
StDev
0,3420
0,3592
0,3850
0,3565
0,3085
Individual 95% CIs For Mean Based on
Pooled StDev
---+---------+---------+---------+-----(--*---)
(*-)
(--*--)
(*-)
(-*-)
---+---------+---------+---------+-----0,40
0,50
0,60
0,70
Pooled StDev = 0,3489
AMOSTRAGEM
7.1 AMOSTRAGEM
Neste estudo, realizou-se uma amostragem aleatória por meio do software Minitab14 de um
universo de 5565 indivíduos, obtendo-se uma amostra de 50 indivíduos e outra de 100
indivíduos. A partir dessas amostras se estabeleceu comparações entre o universo e as
amostras de 50 e 100 para as variáveis T1_2( Formalização entre empregados), Emprego e
Renda e H4(Energia Elétrica). Por meio de duas ferramentas estatísticas: Estatística
Descritiva e Analise de Variância (ANOVA), Observou-se um comportamento muito próximo
tanto nas médias, como nas curvas de distribuição. E, apesar de um “p” médio (entre 4% e
9%) em todos os casos, nota-se que trabalhar com amostragem é viável em todos os casos.
Boxplot of H4; H4 100; H4 50
1,0
0,8
Data
0,6
0,4
0,2
0,0
H4
H4 100
H4 50
One-way ANOVA: H4; H4 100; H4 50
Source
Factor
Error
Total
DF
2
5712
5714
S = 0,3169
Level
H4
H4 100
H4 50
N
5565
100
50
SS
0,025
573,719
573,744
MS
0,013
0,100
R-Sq = 0,00%
F
0,13
Mean
0,2983
0,3057
0,2784
Pooled StDev = 0,3169
P
0,882
StDev
0,3170
0,3044
0,3277
R-Sq(adj) = 0,00%
Individual 95% CIs For Mean Based on
Pooled StDev
--+---------+---------+---------+------(-*)
(-----------*------------)
(-----------------*----------------)
--+---------+---------+---------+------0,200
0,250
0,300
0,350
Boxplot of T1_2; T1_2 50; T1_100
1,0
0,8
Data
0,6
0,4
0,2
0,0
T1_2
T1_2 50
T1_100
One-way ANOVA: T1_2; T1_2 50; T1_100
Source
Factor
Error
Total
DF
2
5712
5714
S = 0,2058
SS
0,0743
241,9604
242,0347
Level
T1_2
T1_2 50
T1_100
MS
0,0372
0,0424
N
5565
50
100
R-Sq = 0,03%
Mean
0,5638
0,5300
0,5769
Pooled StDev = 0,2058
F
0,88
P
0,416
R-Sq(adj) = 0,00%
StDev
0,2060
0,1810
0,2064
Individual 95% CIs For Mean Based on
Pooled StDev
--+---------+---------+---------+------(*)
(-------------*--------------)
(---------*---------)
--+---------+---------+---------+------0,480
0,520
0,560
0,600
Boxplot of Emprego e Renda; E&R 100; E&R 50
1,0
0,8
Data
0,6
0,4
0,2
0,0
Emprego e Renda
E&R 100
E&R 50
One-way ANOVA: Emprego e Renda; E&R 100; E&R 50
Source
Factor
Error
Total
DF
2
5712
5714
S = 0,1551
SS
0,0019
137,4109
137,4129
MS
0,0010
0,0241
R-Sq = 0,00%
Level
Emprego e Renda
E&R 100
E&R 50
N
5565
100
50
Pooled StDev = 0,1551
F
0,04
P
0,961
R-Sq(adj) = 0,00%
Mean
0,4038
0,3998
0,4008
StDev
0,1552
0,1612
0,1232
Individual 95% CIs For Mean Based on
Pooled StDev
-------+---------+---------+---------+-(-*)
(-----------*-----------)
(----------------*-----------------)
-------+---------+---------+---------+-0,375
0,400
0,425
0,450
7.2 Quadro Resumo: Amostragem H4
Summary for H4
A nderson-Darling N ormality Test
0,00
0,14
0,28
0,42
0,56
0,70
0,84
0,98
A -S quared
P -V alue <
339,06
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,29831
0,31705
0,10052
0,682199
-0,989971
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,00956
0,16833
0,56295
1,00000
95% C onfidence Interv al for M ean
0,28998
0,30664
95% C onfidence Interv al for M edian
0,15001
0,18529
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,31126
0,32305
Mean
Median
0,150
0,175
0,200
0,225
0,250
0,275
0,300
Summary for H4 100
A nderson-D arling N ormality Test
0,0
0,2
0,4
0,6
0,8
A -S quared
P -V alue <
4,82
0,005
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
0,30570
0,30436
0,09264
0,584829
-0,995870
100
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
1,0
0,00000
0,01176
0,24144
0,54591
0,95727
95% C onfidence Interv al for M ean
0,24530
0,36609
95% C onfidence Interv al for M edian
0,07543
0,37922
95% C onfidence Interv al for S tD ev
9 5 % C onfidence Inter vals
0,26723
0,35357
Mean
Median
0,10
0,15
0,20
0,25
0,30
0,35
0,40
Summary for H4 50
A nderson-Darling N ormality Test
0,0
0,2
0,4
0,6
A -S quared
P -V alue <
4,30
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,27842
0,32768
0,10738
0,901698
-0,775578
50
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,8
0,00000
0,01218
0,09828
0,56055
0,93124
95% C onfidence Interv al for M ean
0,18530
0,37155
95% C onfidence Interv al for M edian
0,03075
9 5 % C onfidence Inter vals
0,27372
Mean
Median
0,0
0,1
0,2
0,29070
95% C onfidence Interv al for S tDev
0,3
0,4
0,40833
7.3 Quadro Resumo: Amostragem Emprego e Renda
Summary for Emprego e Renda
A nderson-Darling N ormality Test
0,00
0,14
0,28
0,42
0,56
0,70
0,84
0,98
A -S quared
P -V alue <
105,84
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,40375
0,15524
0,02410
0,88857
1,32259
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,30630
0,37580
0,47115
1,00000
95% C onfidence Interv al for M ean
0,39967
0,40783
95% C onfidence Interv al for M edian
0,37169
0,37960
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,15241
0,15818
Mean
Median
0,37
0,38
0,39
0,40
0,41
Summary for E&R 100
A nderson-Darling N ormality Test
0,0
0,2
0,4
0,6
0,8
A -S quared
P -V alue <
1,96
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,39983
0,16123
0,02600
0,99362
2,27390
100
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,30178
0,37720
0,47080
0,90170
95% C onfidence Interv al for M ean
0,36784
0,43182
95% C onfidence Interv al for M edian
0,35370
0,41808
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,14156
0,18730
Mean
Median
0,36
0,38
0,40
0,42
0,44
Summary for E&R 50
A nderson-D arling N ormality Test
0,2
0,3
0,4
0,5
0,6
A -S quared
P -V alue
0,28
0,619
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
0,40075
0,12315
0,01517
0,260132
-0,107875
50
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,7
0,12640
0,32158
0,38715
0,49415
0,70630
95% C onfidence Interv al for M ean
0,36575
0,43575
95% C onfidence Interv al for M edian
0,34388
9 5 % C onfidence Inter vals
0,10287
Mean
Median
0,34
0,36
0,38
0,40
0,42996
95% C onfidence Interv al for S tD ev
0,42
0,44
0,15347
7.4 Quadro Resumo: Amostragem T1_2
Summary for T1_2
A nderson-Darling N ormality Test
0,00
0,14
0,28
0,42
0,56
0,70
0,84
0,98
A -S quared
P -V alue <
41,12
0,005
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,56382
0,20601
0,04244
-0,132466
-0,993228
5565
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,00000
0,39402
0,57643
0,73415
1,00000
95% C onfidence Interv al for M ean
0,55841
0,56923
95% C onfidence Interv al for M edian
0,56694
0,58537
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,20225
0,20991
Mean
Median
0,560
0,565
0,570
0,575
0,580
0,585
Summary for T1_100
A nderson-Darling N ormality Test
0,15
0,30
0,45
0,60
0,75
A -S quared
P -V alue
1,11
0,006
M ean
S tDev
V ariance
S kew ness
Kurtosis
N
0,57688
0,20641
0,04260
0,01291
-1,11250
100
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,90
0,17297
0,38465
0,54226
0,75051
0,96000
95% C onfidence Interv al for M ean
0,53592
0,61783
95% C onfidence Interv al for M edian
0,50906
0,64668
95% C onfidence Interv al for S tDev
9 5 % C onfidence Inter vals
0,18123
0,23978
Mean
Median
0,500
0,525
0,550
0,575
0,600
0,625
0,650
Summary for T1_2 50
A nderson-D arling N ormality Test
0,2
0,4
0,6
A -S quared
P -V alue
0,69
0,067
M ean
S tD ev
V ariance
S kew ness
Kurtosis
N
0,52997
0,18104
0,03278
0,220433
-0,439521
50
M inimum
1st Q uartile
M edian
3rd Q uartile
M aximum
0,8
0,09694
0,40156
0,49079
0,63939
0,92611
95% C onfidence Interv al for M ean
0,47852
0,58142
95% C onfidence Interv al for M edian
0,42252
0,15123
Mean
Median
0,40
0,45
0,50
0,55
0,60718
95% C onfidence Interv al for S tD ev
9 5 % C onfidence Inter vals
0,60
0,22560
ANÁLISE MULTIVARIADA – COMPONENTES PRINCIPAIS
8 ANÁLISE MULTIVARIADA – COMPONENTES PRINCIPAIS
Esta parte do estudo efetuará analisa as correlações e os componentes principais (análise
multivariada) dos dados quantitativos Habitação e de Desenvolvimento dos Municípios do
Brasil.
8.1 Dendograma
8.1.1
Cluster Analysis of Variables: H; H1; H2; H3; H4; H5; H6; ISDM; ...
Correlation Coefficient Distance, Single Linkage
Amalgamation Steps
Step
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Number
of
clusters
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Similarity
level
100,000
95,795
93,435
91,442
90,744
90,476
90,318
88,922
88,444
88,304
88,263
84,756
75,721
72,322
57,016
48,707
Distance
level
0,00000
0,08409
0,13130
0,17117
0,18512
0,19048
0,19363
0,22157
0,23113
0,23393
0,23474
0,30487
0,48558
0,55356
0,85969
1,02585
Clusters
joined
2
3
1
8
1
4
1
2
1
9
1
15
1
12
1
16
1
5
10
17
1
11
1
7
6
14
1
10
6
13
1
6
New
cluster
2
1
1
1
1
1
1
1
1
10
1
1
6
1
6
1
Number
of obs.
in new
cluster
2
2
3
5
6
7
8
9
10
2
11
12
2
14
3
17
Final Partition
Cluster
H H1
Cluster
H5
Cluster
H6
Cluster
IFGF
Cluster
S1_1
Cluster
R1
1
H2
H3
2
3
4
Liquidez
5
6
H4
ISDM
IFDM
E2_4
T1_2
Educação
Emprego e Renda
Dendrogram with Single Linkage and Correlation Coefficient Distance
48,71
Similarity
65,80
82,90
100,00
H
DM
IS
H3
H1
H2
o _2 da
DM ã
IF caç T1 Ren
u
e
Ed
o
eg
r
p
Em
H4 2_4
E
z
H6 FGF ide
I
u
q
Li
H5
R1 1_1
S
Variables
Nota-se Erro! Fonte de referência não encontrada.- que houve uma divisão em dois
grupos, com similaridades muito próximas, em torno de 80%, a saber: Gestão Fiscal (IFGF e
Liquidez) e Habitação e Desenvolvimento dos munícipios (H, ISDM, H3, H1, H2, IFDM,
Educação, T1_2, Emprego e Renda, H4, E2_4 e H6). Os indicadores H5, R1 e S1_1 ficaram
isolados e com um nível de similaridade pouco expressiva.
8.2 Componentes Principais
Principal Component Analysis: H; H1; H2; H3; H4; H5; H6; ISDM; E2_4; T1_2; S1_1
Eigenanalysis of the Correlation Matrix
Eigenvalue
Proportion
Cumulative
8,4477
0,563
0,563
1,3430
0,090
0,653
0,9842
0,066
0,718
0,9695
0,065
0,783
0,7069
0,047
0,830
0,6573
0,044
0,874
0,5914
0,039
0,913
Eigenvalue
Proportion
Cumulative
0,3163
0,021
0,963
0,2254
0,015
0,978
0,1940
0,013
0,991
0,1073
0,007
0,998
0,0200
0,001
1,000
0,0058
0,000
1,000
0,0000
0,000
1,000
Variable
H
H1
H2
H3
H4
H5
H6
ISDM
PC1
0,320
0,296
0,296
0,299
0,210
-0,196
0,229
0,337
PC2
-0,111
-0,263
-0,263
0,139
-0,434
0,288
0,436
0,049
PC3
0,111
-0,142
-0,142
0,155
0,133
-0,196
0,285
0,044
PC4
-0,021
0,042
0,042
-0,067
0,025
-0,005
-0,129
-0,008
PC5
0,183
0,001
0,001
0,005
0,049
0,758
0,237
0,080
PC6
-0,322
0,002
0,002
0,046
-0,606
-0,293
-0,065
-0,012
0,4313
0,029
0,942
PC7
0,058
0,426
0,426
0,216
-0,399
0,072
0,116
0,024
PC8
-0,083
0,220
0,220
-0,215
-0,107
0,356
-0,450
-0,023
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
0,269
0,279
-0,050
-0,322
0,279
0,199
0,104
0,267
0,027
-0,217
-0,145
0,108
-0,159
0,434
0,165
-0,282
-0,057
-0,024
0,174
-0,548
-0,586
-0,060
0,026
-0,964
0,030
-0,033
0,119
-0,156
-0,050
0,111
0,080
0,001
-0,094
0,290
-0,461
0,199
0,210
0,101
-0,160
0,013
0,319
-0,464
-0,304
-0,057
-0,027
-0,037
-0,389
-0,399
0,009
0,368
0,142
0,018
0,074
0,455
-0,375
-0,027
Scree Plot of H; ...; Liquidez
9
8
7
Eigenvalue
6
5
4
3
2
1
0
1
2
3
4
5
6
7
8
9
10
Component Number
11
12
13
14
15
Loading Plot of H; ...; Liquidez
0,6
IFGF
Liquidez
Second Component
0,4
H5
0,2
H6
E2_4
T1_2
IFDM
Educação
H3 Emprego e Renda
ISDM
0,0
H
-0,2
R1
S1_1
H1
H2
H4
-0,4
-0,4
-0,3
-0,2
-0,1
0,0
First Component
0,1
0,2
0,3
8.2.1
3D Scatterplot
3D Scatterplot of CP1 vs CP2 vs CP3
Região
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
10
5
CP1
0
-5
-2
0
CP3
2
4
-4
-2
0
2
CP2
Com base nos gráficos trabalhados neste capítulo é perceptível que os dados podem ser
reduzidos em 3 variáveis, o que facilita o trabalho por gerarem números mais fáceis e
práticos de serem manuseados.
ANÁLISE DE CONGLOMERADOS
9 ANÁLISE DE CONGLOMERADOS (DENDROGRAMA E ANOVA)
O Dendrograma permite uma análise do grau de similaridade dos dados para uma
determinada variável. Neste estudo, gerou-se o Dendrograma da média dos indicadores
de Gestão Fiscal e de Desenvolvimento dos municípios, agrupado por Estado e,
também, do índice de disparidade das mesmas variáveis. Os resultados de ambos
foram ilustrados no mapa do Brasil, cujo objetivo foi representar os agrupamentos por
similaridade.
9.1 Dendrograma das médias por UF (-DF)
O Dendrograma permite uma análise do grau de similaridade dos dados para uma
determinada variável. Em seguida geramos o Dendrograma da média de
desenvolvimento dos municípios, agrupado por Estado.
Cluster Analysis of Observations: Hm; H1m; H2m; H3m; H4m; H5m; H6m;
isdmm; ...
Euclidean Distance, Single Linkage
Amalgamation Steps
Step
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Number
of
clusters
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Similarity
level
92,6846
92,4590
89,8937
89,5162
88,6488
86,1268
85,7356
84,6869
84,5305
84,3960
84,1926
83,9296
83,9243
82,0200
81,9514
81,9179
81,7714
81,4183
79,7382
79,0678
78,4024
77,6901
77,6526
77,5888
77,5263
Distance
level
0,126996
0,130912
0,175445
0,181999
0,197058
0,240839
0,247630
0,265836
0,268551
0,270885
0,274417
0,278983
0,279074
0,312133
0,313324
0,313905
0,316449
0,322579
0,351746
0,363383
0,374935
0,387299
0,387952
0,389059
0,390143
Clusters
joined
11
12
22
23
8
17
14
15
5
14
1
21
5
6
5
19
1
9
1
16
5
24
8
11
1
13
7
10
8
22
8
20
2
5
2
4
8
26
1
3
2
8
1
2
1
7
18
25
1
18
New
cluster
11
22
8
14
5
1
5
5
1
1
5
8
1
7
8
8
2
2
8
1
2
1
1
18
1
Final Partition
Number of clusters: 5
Cluster1
Cluster2
Cluster3
Cluster4
Cluster5
Number of
observations
6
16
2
1
1
Cluster Centroids
Within
cluster
sum of
squares
0,32401
3,01576
0,04871
0,00000
0,00000
Average
distance
from
centroid
0,226281
0,421869
0,156066
0,000000
0,000000
Maximum
distance
from
centroid
0,326849
0,638243
0,156066
0,000000
0,000000
Number
of obs.
in new
cluster
2
2
2
2
3
2
4
5
3
4
6
4
5
2
6
7
7
8
8
6
16
22
24
2
26
Variable
Hm
H1m
H2m
H3m
H4m
H5m
H6m
isdmm
ifdmm
ifgfm
E2_4m
T1_2m
S1_1m
R1m
Educm
E&Rm
Liqm
Cluster1
0,388488
0,449434
0,449434
0,508402
0,042981
0,839379
0,302965
0,385899
0,542276
0,482672
0,541325
0,390555
0,050421
0,611445
0,612696
0,331846
0,450332
Cluster2
0,606518
0,676830
0,676830
0,800743
0,155823
0,708223
0,543387
0,624078
0,624891
0,510638
0,702107
0,538783
0,045276
0,363646
0,702590
0,387100
0,566419
Cluster3
0,761238
0,733851
0,733851
0,951826
0,516776
0,634427
0,668042
0,768325
0,684604
0,563561
0,785974
0,567280
0,040973
0,222080
0,813836
0,418193
0,628765
Cluster4
0,796897
0,921303
0,921303
0,947466
0,581921
0,657602
0,527920
0,827035
0,715058
0,610326
0,661271
0,699856
0,040763
0,162310
0,784391
0,531726
0,705000
Cluster5
0,854425
0,918161
0,918161
0,979218
0,777565
0,582818
0,606302
0,889343
0,764647
0,596507
0,901396
0,775951
0,037844
0,095891
0,904423
0,522036
0,614930
Cluster4
1,36598
0,73206
0,39851
0,00000
0,38906
Cluster5
1,60748
0,97073
0,51573
0,38906
0,00000
Distances Between Cluster Centroids
Cluster1
Cluster2
Cluster3
Cluster4
Cluster5
Cluster1
0,00000
0,72274
1,18013
1,36598
1,60748
Cluster2
0,722742
0,000000
0,526162
0,732058
0,970733
Cluster3
1,18013
0,52616
0,00000
0,39851
0,51573
Grand
centroid
0,584962
0,647425
0,647425
0,757409
0,197850
0,726043
0,499319
0,598218
0,619262
0,515392
0,677549
0,522085
0,045673
0,391899
0,701312
0,387493
0,551621
Dendrogram with Single Linkage and Euclidean Distance
Similarity
77,53
85,02
92,51
100,00
I
E P
B E E
L
S T S
J P
S
AC RR MA P PA AM A BA P P C RN S A GO PR M M R SC RO T O E MG R S
Observations
9.2 Dendrograma dos índices de variabilidade por UF (-DF)
Cluster Analysis of Observations: Hid; H1id; H2id; H3id; H4id; H5id; H6id; ...
Euclidean Distance, Single Linkage
Amalgamation Steps
Step
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Number
of
clusters
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Similarity
level
94,9794
94,8957
94,4487
94,1697
93,8431
93,7617
93,5848
93,5312
93,4836
92,9122
92,5035
92,1973
90,9246
90,1791
89,9688
89,3954
89,1940
88,9281
87,2166
86,4019
82,2076
81,4769
79,7045
79,6804
63,5314
Distance
level
0,85447
0,86872
0,94479
0,99227
1,04787
1,06171
1,09183
1,10095
1,10905
1,20629
1,27586
1,32796
1,54457
1,67145
1,70725
1,80484
1,83911
1,88436
2,17565
2,31431
3,02814
3,15251
3,45416
3,45826
6,20672
Clusters
joined
4
21
11
24
1
4
9
16
12
26
3
11
6
19
2
6
1
20
2
12
3
7
14
15
2
14
1
3
1
18
1
2
1
13
1
9
1
8
1
23
1
17
1
5
1
25
1
22
1
10
New
cluster
4
11
1
9
12
3
6
2
1
2
3
14
2
1
1
1
1
1
1
1
1
1
1
1
1
Number
of obs.
in new
cluster
2
2
3
2
2
3
2
3
4
5
4
2
7
8
9
16
17
19
20
21
22
23
24
25
26
Final Partition
Number of clusters: 5
Cluster1
Cluster2
Cluster3
Cluster4
Cluster5
Number of
observations
22
1
1
1
1
Within
cluster
sum of
squares
178,816
0,000
0,000
0,000
0,000
Average
distance
from
centroid
2,58047
0,00000
0,00000
0,00000
0,00000
Maximum
distance
from
centroid
5,87112
0,00000
0,00000
0,00000
0,00000
Cluster Centroids
Variable
Hid
H1id
H2id
H3id
H4id
H5id
H6id
isdmID
ifdmID
ifgfID
E2_4ID
T1_2ID
S1_1ID
Cluster1
1,08287
1,92813
1,92813
1,43034
1,75605
1,12145
0,95114
1,16687
0,67379
1,36604
1,09600
1,49269
0,40308
Cluster2
2,34944
3,97135
3,97135
3,16608
5,21949
2,12978
1,94323
2,26964
1,28988
2,53834
2,47165
3,05444
0,63478
Cluster3
3,4865
5,6676
5,6676
2,8110
7,6694
3,6087
2,6208
3,5939
2,0284
3,5576
2,6468
5,1336
1,3387
Cluster4
1,97810
4,83060
4,83060
0,98280
4,66749
2,02570
2,33558
1,98395
1,40011
2,15384
1,71582
2,94328
1,45400
Cluster5
1,69715
1,98125
1,98125
0,75242
4,72141
2,18001
2,72980
1,51586
1,72150
3,23234
1,33300
2,67145
1,01627
Grand
centroid
1,28209
2,26422
2,26422
1,50692
2,34272
1,33139
1,17517
1,34748
0,81782
1,59750
1,24151
1,79392
0,51198
R1ID
EducID
E&R ID
LiqID
1,33352
0,72089
1,49579
3,72756
2,46886
1,38028
2,61685
7,38057
4,3149
1,8126
4,0689
10,3491
2,06070
1,71907
2,99663
4,80378
1,73252
1,29262
4,25983
9,10798
Cluster4
6,27740
3,92588
8,13891
0,00000
6,23384
Cluster5
7,58415
4,90913
8,14168
6,23384
0,00000
1,53517
0,84862
1,80191
4,37106
Distances Between Cluster Centroids
Cluster1
Cluster2
Cluster3
Cluster4
Cluster5
Cluster1
0,0000
7,1164
13,0078
6,2774
7,5842
Cluster2
7,11638
0,00000
6,20672
3,92588
4,90913
Cluster3
13,0078
6,2067
0,0000
8,1389
8,1417
Indices de Variabilidade
Similarity
63,53
75,69
87,84
100,00
B E
T
S E S J L E
P
AC A RR RO AM M S E R A C RN M TO P P PA MA
Observations
PI GO S C PR BA SP RS MG
Para se chegar ao índice de variabilidade (disparidade), utilizou-se do seguinte cálculo:
ID= Índice de Disparidade
s= Desvio Padrão da Média (do Estado)
n= Número de Indivíduos (Munícipios do Estado)
One-way ANOVA: H4 versus Região
Source
Região
Error
Total
DF
4
5543
5547
S = 0,2229
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
282,4797
275,3817
557,8615
MS
70,6199
0,0497
R-Sq = 50,64%
N
467
1790
431
1669
1191
Mean
0,1040
0,1885
0,0355
0,6372
0,1628
F
1421,47
P
0,000
R-Sq(adj) = 50,60%
StDev
0,1837
0,2263
0,0772
0,2572
0,2152
Individual 95% CIs For Mean Based on
Pooled StDev
---------+---------+---------+---------+
(*-)
(*
(*-)
(*
(*)
---------+---------+---------+---------+
0,16
0,32
0,48
0,64
Pooled StDev = 0,2229
One-way ANOVA: Emprego e Renda versus Região
Source
Região
Error
Total
DF
4
5543
5547
S = 0,1445
Level
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
SS
17,8157
115,7805
133,5962
MS
4,4539
0,0209
R-Sq = 13,34%
N
467
1790
431
1669
1191
Mean
0,4175
0,3348
0,3400
0,4490
0,4620
F
213,23
P
0,000
R-Sq(adj) = 13,27%
StDev
0,1390
0,1288
0,1404
0,1681
0,1345
Individual 95% CIs For Mean Based on
Pooled StDev
--------+---------+---------+---------+(--*---)
(-*)
(--*--)
(*-)
(-*--)
--------+---------+---------+---------+0,360
0,400
0,440
0,480
Pooled StDev = 0,1445
One-way ANOVA: T1_2 versus Região
Source
Região
Error
Total
DF
4
5543
5547
S = 0,1549
Level
Centro-Oeste
Nordeste
Norte
Sudeste
SS
102,8399
133,0327
235,8725
MS
25,7100
0,0240
R-Sq = 43,60%
N
467
1790
431
1669
Mean
0,5925
0,3929
0,4448
0,6581
F
1071,24
P
0,000
R-Sq(adj) = 43,56%
StDev
0,1333
0,1510
0,1544
0,1782
Individual 95% CIs For Mean Based on
Pooled StDev
-+---------+---------+---------+-------(*-)
*)
(*-)
(*)
Sul
1191
0,7204
0,1321
(*)
-+---------+---------+---------+-------0,40
0,50
0,60
0,70
Pooled StDev = 0,1549
One-way ANOVA: H4 versus UF2
Source
UF2
Error
Total
DF
25
5538
5563
S = 0,2033
SS
330,2354
228,8095
559,0449
Level
AC
AL
AM
AP
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
MS
13,2094
0,0413
N
22
101
62
16
416
184
78
247
217
852
78
142
142
222
185
223
399
92
167
52
15
497
295
75
647
138
R-Sq = 59,07%
Mean
0,0537
0,1524
0,0582
0,0422
0,2544
0,1596
0,4829
0,1318
0,0184
0,5506
0,1020
0,0568
0,0170
0,2729
0,3921
0,0201
0,1971
0,5819
0,1796
0,0239
0,0905
0,1541
0,1311
0,2035
0,7776
0,0398
StDev
0,1045
0,2105
0,0902
0,0935
0,2559
0,1493
0,2048
0,2167
0,0494
0,2627
0,1459
0,1201
0,0443
0,2197
0,2119
0,0585
0,2489
0,2314
0,2302
0,0700
0,1400
0,2094
0,1640
0,1987
0,1856
0,0808
F
319,71
P
0,000
R-Sq(adj) = 58,89%
Individual 95% CIs For Mean Based on
Pooled StDev
--+---------+---------+---------+------(--*---)
(*-)
(-*-)
(---*---)
(*)
(*-)
(*-)
(*)
(*)
(*)
(-*-)
(*-)
(-*)
(*)
(*)
(*)
(*)
(*-)
(*)
(-*-)
(---*---)
(*)
(*)
(-*-)
(*)
(-*)
--+---------+---------+---------+------0,00
0,25
0,50
0,75
Pooled StDev = 0,2033
One-way ANOVA: Emprego e Renda versus UF2
Source
UF2
Error
Total
DF
25
5538
5563
S = 0,1380
Level
AC
AL
AM
AP
N
22
101
62
16
SS
28,6671
105,4175
134,0847
MS
1,1467
0,0190
R-Sq = 21,38%
Mean
0,3717
0,3174
0,3027
0,3807
StDev
0,1183
0,1295
0,1306
0,1789
F
60,24
P
0,000
R-Sq(adj) = 21,02%
Individual 95% CIs For Mean Based on
Pooled StDev
------+---------+---------+---------+--(------*-------)
(---*--)
(---*---)
(--------*-------)
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
416
184
78
247
217
852
78
142
142
222
185
223
399
92
167
52
15
497
295
75
647
138
0,3515
0,3189
0,4520
0,4052
0,2890
0,3844
0,4369
0,4284
0,3741
0,3211
0,3862
0,3064
0,4383
0,5317
0,3391
0,3976
0,3471
0,4664
0,4865
0,4251
0,5220
0,2941
0,1283
0,1271
0,1380
0,1432
0,1309
0,1394
0,1334
0,1333
0,1506
0,1101
0,1366
0,1167
0,1268
0,1923
0,1088
0,1289
0,1740
0,1344
0,1398
0,1385
0,1675
0,1188
(-*-)
(--*-)
(--*---)
(-*-)
(-*-)
(*)
(---*--)
(--*-)
(--*--)
(-*-)
(-*--)
(-*--)
(-*)
(--*---)
(-*--)
(----*---)
(-------*--------)
(*-)
(-*-)
(---*---)
(*-)
(--*--)
------+---------+---------+---------+--0,320
0,400
0,480
0,560
Pooled StDev = 0,1380
One-way ANOVA: T1_2 versus UF2
Source
UF2
Error
Total
DF
25
5538
5563
S = 0,1393
Level
AC
AL
AM
AP
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
N
22
101
62
16
416
184
78
247
217
852
78
142
142
222
185
223
399
92
167
52
15
497
295
75
647
138
SS
128,5377
107,5197
236,0573
MS
5,1415
0,0194
R-Sq = 54,45%
Mean
0,4947
0,4900
0,3269
0,5490
0,3797
0,3475
0,5615
0,5624
0,3400
0,5730
0,6569
0,6095
0,3851
0,3801
0,4389
0,3615
0,6756
0,6999
0,4483
0,5845
0,4352
0,7143
0,7910
0,4928
0,7760
0,4998
StDev
0,0864
0,1590
0,1450
0,1099
0,1498
0,1318
0,1688
0,1260
0,1279
0,1759
0,1156
0,1400
0,1499
0,1346
0,1829
0,1112
0,1228
0,1184
0,1350
0,1078
0,1123
0,1320
0,1141
0,1790
0,1050
0,1214
F
264,82
P
0,000
R-Sq(adj) = 54,25%
Individual 95% CIs For Mean Based on
Pooled StDev
-+---------+---------+---------+-------(---*---)
(-*)
(--*-)
(----*---)
(*)
(*-)
(-*-)
(*-)
(-*)
*)
(-*-)
(-*)
(-*)
(*-)
(*-)
(*)
(*)
(-*-)
(-*)
(--*-)
(----*----)
(*
(*)
(-*-)
(*
(*-)
-+---------+---------+---------+--------
0,30
0,45
0,60
Pooled StDev = 0,1393
9.3.1 Resumo dos Boxplot
Boxplot of H4 by Região
1,0
0,8
H4
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
Boxplot of Emprego e Renda by Região
1,0
Emprego e Renda
0,8
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
0,75
Boxplot of T1_2 by Região
1,0
0,8
T1_2
0,6
0,4
0,2
0,0
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
Boxplot of H4 by UF2
1,0
0,8
H4
0,6
0,4
0,2
0,0
R S C E P
B E I R J
S
E S
P
L
A C A A M A BA C E GO M A MG M MT PA P P P P R RN RO R R S S S T O
UF2
Boxplot of Emprego e Renda by UF2
1,0
Emprego e Renda
0,8
0,6
0,4
0,2
0,0
R S C E P
B E I R J
S
E S
P
L
A C A A M A BA C E GO M A MG M MT PA P P P P R RN RO R R S S S T O
UF2
Boxplot of T1_2 by UF2
1,0
0,8
T1_2
0,6
0,4
0,2
0,0
R S C E P
B E I R J
S
E S
P
L
A C A A M A BA C E GO M A MG M MT PA P P P P R RN RO R R S S S T O
UF2
ANÁLISE DISCRIMINANTE LINEAR
10 ANÁLISE DISCRIMINANTE LINEAR POR REGIÃO
Neste estudo avaliaremos a análise discriminante linear em três grupos: primeiro pelas
regiões politicas do Brasil (Norte, Nordeste, Centro-Oeste, Sudeste e Sul), segundo pelo
agrupamento dos estados por similaridades de médias (5 Brasis M) e, por fim, o
agrupamento dos estados por similaridade de variabilidade (5 Brasis Id), como
explicado no tópico anterior.
10.1 Cinco Regiões Brasileiras – Mapa Político
Discriminant Analysis: Região versus H; H1; ...
Linear Method for Response: Região
Predictors: H; H1; H3; H4; H5; H6; ISDM; E2_4; T1_2; S1_1; R1; Educação;
Emprego e Renda; Liquidez
Group
Count
Centro-Oeste
467
Nordeste
1790
Norte
447
Sudeste
1669
Sul
1191
Summary of classification
Put into Group
Centro-Oeste
Nordeste
Norte
Sudeste
Sul
Total N
N correct
Proportion
N = 5564
Centro-Oeste
369
5
26
28
39
467
369
0,790
True Group
Nordeste Norte
39
105
1528
67
138
265
62
2
23
8
1790
447
1528
265
0,854 0,593
N Correct = 4454
Sudeste
103
88
9
1413
56
1669
1413
0,847
Sul
212
3
1
96
879
1191
879
0,738
Proportion Correct = 0,801
Este agrupamento, por regiões politicas, obteve o nível de acerto, 80,10%
Discriminant Analysis: 3 Regioes versus H; H1; ...
Linear Method for Response: 3 Regioes
Predictors: H; H1; H3; H4; H5; H6; ISDM; E2_4; T1_2; S1_1; R1; Educação;
Emprego e Renda; Liquidez
Group
Count
COSS
3327
Nordeste
1790
Norte
447
Summary of classification
Put into Group
COSS
Nordeste
Norte
Total N
N correct
Proportion
True Group
Nordeste Norte
72
86
1582
77
136
284
1790
447
1582
284
0,884 0,635
COSS
3143
121
63
3327
3143
0,945
N = 5564
N Correct = 5009
Proportion Correct = 0,900
Squared Distance Between Groups
COSS
Nordeste
Norte
COSS
0,0000
12,2550
12,8316
Nordeste
12,2550
0,0000
6,9204
Norte
12,8316
6,9204
0,0000
Este agrupamento, por similaridade de médias, obteve o melhor nível de acerto, 90%.
10.2 Brasis – Similaridade nas médias
Discriminant Analysis: 5BrasisM versus H; H1; ...
Linear Method for Response: 5BrasisM
Predictors: H; H1; H3; H4; H5; H6; ISDM; IFDM; IFGF; E2_4; T1_2; S1_1; R1;
Educação; Emprego e Renda; Liquidez
Group
Count
B1
681
B2
3214
B3
930
B4
92
B5
647
Summary of classification
Put into Group
B1
B2
B3
B4
B5
Total N
N correct
Proportion
N = 5564
B1
552
118
3
8
0
681
552
0,811
True Group
B3
B4
13
0
100
3
645
5
63
79
109
5
930
92
645
79
0,694 0,859
B2
295
2472
307
108
32
3214
2472
0,769
N Correct = 4326
B5
0
7
39
23
578
647
578
0,893
Proportion Correct = 0,777
Este agrupamento, por regiões politicas, obteve o nível de acerto: 77,7%
10.3 Brasis – similaridade nos índices de “variabilidade”
Discriminant Analysis: 5BrasisId versus H; H1; ...
Linear Method for Response: 5BrasisId
Predictors: H; H1; H3; H4; H5; H6; ISDM; IFDM; IFGF; E2_4; T1_2; S1_1; R1;
Educação; Emprego e Renda; Liquidez
Group
Count
D1
3152
D2
416
D3
647
D4
497
D5
852
Summary of classification
Put into Group
D1
D2
D3
D4
D5
Total N
N correct
Proportion
N = 5564
D1
2122
278
93
420
239
3152
2122
0,673
True Group
D3
D4
12
29
0
6
601
0
1
441
33
21
647
497
601
441
0,929 0,887
D2
32
355
1
10
18
416
355
0,853
N Correct = 4164
D5
76
17
88
26
645
852
645
0,757
Proportion Correct = 0,748
Este agrupamento, por regiões politicas, obteve o nível de acerto, 74,8%
REGRESSÃO LOGISTICA
11 REGRESSÃO LOGISTICA
11.1Regressão – REGIÃO
Nominal Logistic Regression: Região versus H; H1; ...
Response Information
Variable
Região
Value
Sul
Sudeste
Norte
Nordeste
Centro-Oeste
Total
Count
1191
1669
447
1790
467
5564
(Reference Event)
Logistic Regression Table
Predictor
Logit 1: (Sudeste/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Logit 2: (Norte/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Logit 3: (Nordeste/Sul)
Constant
H
H1
H3
Coef
SE Coef
Z
P
Odds Ratio
6,23744
-56,6839
10,7302
1,20917
19,8233
4,32957
2,80532
26,4816
-48,8047
1,44525
-6,68713
-13,5059
-2,22107
15,2296
41,1244
15,1414
-1,07238
2,82954
19,3761
4,76000
5,17201
4,66108
3,39874
4,09754
3,11088
4,21782
0,974899
1,12462
0,949077
1,70880
1,81540
2,30316
1,54193
0,348725
2,20
-2,93
2,25
0,23
4,25
1,27
0,68
8,51
-11,57
1,48
-5,95
-14,23
-1,30
8,39
17,86
9,82
-3,08
0,027
0,003
0,024
0,815
0,000
0,203
0,494
0,000
0,000
0,138
0,000
0,000
0,194
0,000
0,000
0,000
0,002
0,00
45716,84
3,35
4,06579E+08
75,91
16,53
3,16826E+11
0,00
4,24
0,00
0,00
0,11
4112817,17
7,24572E+17
3765689,25
0,34
35,2315
-63,8405
20,3912
-1,52122
9,20677
2,68083
-4,87956
13,7511
-43,4694
1,12035
-6,31280
-12,3198
-2,00469
8,54337
19,2478
13,6499
-0,142274
3,21122
18,8336
4,67610
5,06297
4,58518
3,39872
4,02644
3,86957
4,89089
1,22374
1,29905
1,11777
2,26631
2,17556
2,72791
1,79141
0,432456
10,97
-3,39
4,36
-0,30
2,01
0,79
-1,21
3,55
-8,89
0,92
-4,86
-11,02
-0,88
3,93
7,06
7,62
-0,33
0,000
0,001
0,000
0,764
0,045
0,430
0,226
0,000
0,000
0,360
0,000
0,000
0,376
0,000
0,000
0,000
0,742
0,00
7,17406E+08
0,22
9964,31
14,60
0,01
937638,25
0,00
3,07
0,00
0,00
0,13
5132,59
2,28672E+08
847371,79
0,87
27,9040
-4,63930
8,75985
-15,6400
3,04977
18,8828
4,67352
5,04756
9,15
-0,25
1,87
-3,10
0,000
0,806
0,061
0,002
0,01
6373,18
0,00
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Logit 4: (Centro-Oeste/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Predictor
Logit 1: (Sudeste/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Logit 2: (Norte/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
5,03137
-5,29891
-6,42545
3,25415
-22,9628
-4,42685
-9,47684
-13,3409
-4,34848
16,7093
15,5491
10,3364
-0,204856
4,53351
3,35067
4,00293
3,57370
4,58376
1,11434
1,21351
1,03242
2,31348
2,03047
2,51270
1,67408
0,392057
1,11
-1,58
-1,61
0,91
-5,01
-3,97
-7,81
-12,92
-1,88
8,23
6,19
6,17
-0,52
0,267
0,114
0,108
0,363
0,000
0,000
0,000
0,000
0,060
0,000
0,000
0,000
0,601
153,14
0,00
0,00
25,90
0,00
0,01
0,00
0,00
0,01
18060985,86
5660934,44
30836,32
0,81
30,0825
-80,1878
23,4449
6,21413
17,2415
0,738412
11,1085
4,01233
-26,7127
-2,35311
-1,53485
-10,3345
-0,192529
0,523419
12,2838
9,65067
0,685106
2,83694
18,5696
4,61022
5,00628
4,47468
3,26462
3,95645
2,89846
4,04762
0,926583
1,15973
0,887599
1,50831
1,73505
2,13439
1,49246
0,329283
10,60
-4,32
5,09
1,24
3,85
0,23
2,81
1,38
-6,60
-2,54
-1,32
-11,64
-0,13
0,30
5,76
6,47
2,08
0,000
0,000
0,000
0,215
0,000
0,821
0,005
0,166
0,000
0,011
0,186
0,000
0,898
0,763
0,000
0,000
0,037
0,00
1,52054E+10
499,76
30753966,38
2,09
66739,04
55,28
0,00
0,10
0,22
0,00
0,82
1,69
216162,73
15532,12
1,98
95% CI
Lower
Upper
0,00
4,06
0,00
43807,70
0,10
0,01
7,12499E+08
0,00
0,63
0,00
0,00
0,00
117176,57
7,93589E+15
183367,88
0,17
0,00
5,15072E+08
84652,61
3,77346E+12
59343,34
50843,58
1,40882E+14
0,00
28,68
0,01
0,00
3,09
1,44357E+08
6,61556E+19
77333148,11
0,68
0,00
75056,73
0,00
1,25
0,02
0,00
476,64
0,00
0,28
0,00
0,00
0,00
72,19
1089355,71
0,00
6,85709E+12
4456,88
79695182,21
11410,75
20,33
1,84450E+09
0,00
33,75
0,02
0,00
11,44
364934,08
4,80016E+10
Emprego e Renda
Liquidez
Logit 3: (Nordeste/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
Logit 4: (Centro-Oeste/Sul)
Constant
H
H1
H3
H4
H5
H6
ISDM
IFDM
IFGF
E2_4
T1_2
S1_1
R1
Educação
Emprego e Renda
Liquidez
25304,16
0,37
28376321,26
2,02
0,00
0,67
0,00
0,02
0,00
0,00
0,02
0,00
0,00
0,00
0,00
0,00
337574,43
41118,15
1158,93
0,38
1,14433E+14
60609324,13
0,00
1106864,33
3,56
4,14
28527,15
0,00
0,11
0,00
0,00
1,20
9,66303E+08
7,79368E+08
820476,35
1,76
0,00
1810096,74
0,03
4775,05
0,00
28,61
0,19
0,00
0,02
0,02
0,00
0,04
0,06
3295,75
833,35
1,04
0,00
1,27730E+14
9124207,72
1,98072E+11
1257,73
1,55660E+08
16208,74
0,00
0,58
2,09
0,00
15,86
50,61
14177740,84
289491,71
3,78
Log-Likelihood = -2324,984
Test that all slopes are zero: G = 11669,733, DF = 64, P-Value = 0,000
Goodness-of-Fit Tests
Method
Pearson
Deviance
Chi-Square
138246
4650
DF
22188
22188
P
0,000
1,000
ANÁLISE DE CORRESPONDÊNCIA
12 ANÁLISE DE CORRESPONDÊNCIA DOS ÍNDICES HABITAÇÃO E DE
DESENVOLVIMENTO
Análise de correspondência é uma técnica de análise exploratória de dados adequada
para analisar tabelas de duas entradas ou tabelas de múltiplas entradas, levando em
conta algumas medidas de correspondência entre linhas e colunas. Consiste na
conversão de uma matriz de dados não negativos em um tipo particular de representação
gráfica em que as linhas e colunas da matriz são simultaneamente representadas em
dimensão reduzida, isto é, por pontos no gráfico. Este método permite estudar as
relações e semelhanças existentes entre as categorias de linhas e entre as categorias de
colunas de uma tabela de contingência ou o conjunto de categorias de linhas e o
conjunto categorias de colunas.
A análise de correspondência mostra como as variáveis dispostas em linhas e colunas
estão relacionadas e não somente se a relação existe. Embora seja considerada uma
técnica descritiva e exploratória, esta análise simplifica dados complexos e produz
análises exaustivas de informações que suportam conclusões a respeito das mesmas.
Possui diversos aspectos que a distingue de outras técnicas de análise de dados. A sua
natureza multivariada permite revelar relações que não seriam detectadas em
comparações aos pares das variáveis. É altamente flexível quanto a pressuposições
sobre os dados: o único requisito é o de uma matriz retangular com entradas não
negativas. É possível transformar qualquer característica quantitativa em qualitativa,
realizando-se uma partição de seu domínio de variação em classes. A análise de
correspondência é mais efetiva se a matriz de dados é bastante grande, de modo que a
inspeção visual ou análise estatística simples não consegue revelar sua estrutura.
Nesta análise serão trabalhados os estados e as médias de desenvolvimento por estado.
Na análise de correspondência será gerado um mapa contendo quais estados estão mais
próximos e quais variáveis tem a ver entre si. O comando para gerar o gráfico é:
STAT >> MULTIVARIATE >> SIMPLE CORRESPONDENCE ANALISYS
12.1 Todas as variáveis do projeto observa-se seu alinhamento no centro dos quadrantes
com tendência para os inferiores , sendo no primeiro composto pelos Estados: SP, MG
RJ, ES e PE bem próximo das variáveis de habitação e desenvolvimento e apesar de
compor o mesmo quadrante distante da variável H4, no segundo quadrante composto
pelos Estados: PB, BA, RN, SE, AL, AC, PA, RR, MA e AM com alta proximidade
com a variável S1_1, H5 e apesar de compor o mesmo quadrante baixa proximidade da
variável R1.
No terceiro quadrante composto pelos Estados: PR, GO, RS, SC, MS e MT é bastante
próximo das variáveis de gestão fiscal: IFGF e Liquidez.
E no ultimo quadrante composto pelos Estados: RO, TO, AP e PI próximo de todas as
demais variáveis de Desenvolvimento e Habitação.
Nota-se que há um distanciamento muito grande de R1 e H4 dos demais pontos e, por
esta razão, optou-se por refazer a análise excluindo estas variáveis.
.
Symmetric Plot
H4
0,50
Component 2
0,25
SP
0,00
PE
PB
MG
BA
RJ
RN
H5
SE CE
RRMA
ES HH2
AL S1_1
PA
AM
H1E&R
Educ
AC
ifdm
PI
AP
isdm
E2_4ifgf
H3
H6T1_2
PR
TO
GO
RS
MS
MTLiq
SC
RO
R1
-0,25
-0,50
-0,75
-0,75
-0,50
-0,25
0,00
0,25
Component 1
0,50
Column Plot
H4
0,50
R1
Component 2
0,25
HH2
H1E&R
Educ
ifdm
isdm
E2_4
H3
H6T1_2 ifgf
0,00
H5
S1_1
Liq
-0,25
-0,50
-0,75
-0,75
-0,50
-0,25
0,00
0,25
Component 1
0,50
Row Plot
0,4
0,3
Component 2
0,2
0,1
PE
SP
PB
BA
RN
SE
MG
RJ
ES
CE
AL
0,0
-0,1
-0,2
AP
PR
GO
RSMSMT
SC
RR MA
PA
AM
AC
PI
TO
RO
-0,3
-0,4
-0,4 -0,3 -0,2 -0,1 0,0 0,1
Component 1
0,2
0,3
0,4
Simple Correspondence Analysis: Hm_1; H1m_1; H2m_1; H3m_1; H4m_1;
H5m_1; H6m_1;
Analysis of Contingency Table
Axis
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Total
Inertia
0,0322
0,0134
0,0036
0,0023
0,0012
0,0008
0,0004
0,0003
0,0002
0,0001
0,0001
0,0000
0,0000
0,0000
0,0000
0,0546
Proportion
0,5895
0,2451
0,0661
0,0425
0,0223
0,0151
0,0065
0,0049
0,0028
0,0021
0,0015
0,0008
0,0005
0,0002
0,0001
Cumulative
0,5895
0,8346
0,9007
0,9433
0,9655
0,9806
0,9871
0,9921
0,9948
0,9970
0,9985
0,9993
0,9997
0,9999
1,0000
Histogram
******************************
************
***
**
*
Row Contributions
ID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Name
AC
AL
AM
AP
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
Qual
0,851
0,626
0,775
0,502
0,553
0,566
0,861
0,789
0,901
0,939
0,919
0,960
0,857
0,796
0,930
0,809
0,864
0,860
0,295
0,831
0,836
0,922
0,939
0,276
0,951
0,789
Mass
0,032
0,036
0,031
0,035
0,036
0,035
0,045
0,042
0,030
0,044
0,041
0,041
0,030
0,035
0,037
0,032
0,044
0,047
0,037
0,039
0,032
0,046
0,046
0,039
0,050
0,038
Inert
0,041
0,016
0,088
0,034
0,016
0,019
0,042
0,027
0,066
0,054
0,025
0,023
0,043
0,018
0,032
0,043
0,025
0,069
0,013
0,035
0,048
0,033
0,039
0,008
0,127
0,015
Component
Coord
Corr
0,243 0,851
0,118 0,556
0,343 0,768
0,161 0,489
0,040 0,065
0,103 0,371
-0,206 0,826
-0,117 0,386
0,325 0,889
-0,216 0,701
-0,080 0,195
-0,044 0,064
0,256 0,840
0,033 0,038
-0,024 0,012
0,243 0,809
-0,140 0,616
-0,246 0,755
0,031 0,053
0,018 0,006
0,258 0,805
-0,110 0,313
-0,121 0,319
0,034 0,096
-0,329 0,775
0,079 0,281
1
Contr
0,059
0,015
0,114
0,029
0,002
0,012
0,059
0,018
0,099
0,064
0,008
0,002
0,061
0,001
0,001
0,059
0,027
0,088
0,001
0,000
0,066
0,017
0,021
0,001
0,167
0,007
Component
Coord
Corr
0,006 0,001
0,042 0,070
0,031 0,006
-0,026 0,013
0,109 0,488
0,075 0,194
0,042 0,035
-0,119 0,403
0,037 0,012
0,126 0,237
-0,155 0,723
-0,165 0,896
0,037 0,017
0,148 0,758
0,211 0,919
-0,004 0,000
-0,089 0,248
0,092 0,105
0,067 0,242
-0,201 0,825
0,051 0,031
-0,154 0,609
-0,169 0,619
0,046 0,180
0,157 0,176
-0,106 0,508
2
Contr
0,000
0,005
0,002
0,002
0,032
0,015
0,006
0,045
0,003
0,052
0,074
0,083
0,003
0,057
0,121
0,000
0,026
0,030
0,012
0,118
0,006
0,081
0,099
0,006
0,091
0,032
Inert
0,015
0,018
0,018
0,021
0,295
0,095
0,052
0,022
0,003
0,018
0,016
Component
Coord
Corr
-0,093 0,676
-0,058 0,249
-0,058 0,249
-0,084 0,505
-0,614 0,508
0,241 0,892
-0,129 0,326
-0,124 0,845
0,035 0,451
0,059 0,207
-0,006 0,003
1
Contr
0,017
0,007
0,007
0,018
0,254
0,144
0,028
0,031
0,003
0,006
0,000
Component
Coord
Corr
0,033 0,086
0,017 0,021
0,017 0,021
-0,048 0,163
0,589 0,467
0,052 0,042
-0,070 0,097
-0,039 0,084
0,005 0,010
-0,069 0,285
-0,044 0,170
2
Contr
0,005
0,002
0,002
0,014
0,563
0,016
0,020
0,008
0,000
0,020
0,011
Column Contributions
ID
1
2
3
4
5
6
7
8
9
10
11
Name
H
H1
H2
H3
H4
H5
H6
isdm
ifdm
ifgf
E2_4
Qual
0,762
0,270
0,270
0,668
0,974
0,934
0,423
0,929
0,462
0,492
0,173
Mass
0,064
0,071
0,071
0,083
0,022
0,080
0,055
0,066
0,068
0,057
0,075
12
13
14
15
16
17
T1_2
S1_1
R1
Educ
E&R
Liq
0,506
0,695
0,993
0,311
0,003
0,500
0,058
0,005
0,043
0,077
0,043
0,061
0,022
0,007
0,318
0,006
0,007
0,068
-0,065
0,233
0,588
0,032
-0,001
-0,000
0,205
0,685
0,860
0,265
0,000
0,000
0,008
0,008
0,464
0,003
0,000
0,000
-0,079
0,028
0,231
0,013
-0,005
-0,175
0,301
0,010
0,133
0,046
0,003
0,500
0,027
0,000
0,172
0,001
0,000
0,139
12.2 Todas as variáveis do projeto estão bem distribuídas entre os quatro quadrantes,
sendo no primeiro composto pelos Estados: RO,MS, MT, RS, SC, ES e RJ, bem
próximo das variáveis de T1_2, no segundo quadrante composto pelos Estados: TO,
AL, AP, AC, RR e AM com alta proximidade com as variáveis IFGF e Emprego e
Renda e apesar de compor o mesmo quadrante distante da variável de Liquidez, No
terceiro quadrante composto pelos Estados: SP, GO, PR, MG é bastante próximo das
variáveis de Desenvolvimento e Habitação; H6, ISDM, H3, H2, H1 e H. E no ultimo
quadrante composto pelos Estados: RN, PE, PB, BA, CE, SE, PI, PA e MA próximo
das variáveis : IFDM e Educação, somente a variável MA é próxima das variáveis S1_1
e H5, distante de todas as demais como demosntra estudos anteriores.
Symmetric Plot
0,3
Liq
0,2
Component 2
RO
0,1
0,0
ifgf
MSRS
T1_2 TO
SCMT
ES
ACRR
AL
AP
RJ
E2_4
E&R
isdm
GO
S1_1
PRH3
SP
ifdm
MA
Educ
PI
H6
H1
H2
SE
MG
H5
H
PA
BACE
-0,1
-0,2
-0,2
AM
PB
RN
PE
-0,1
0,0
0,1
Component 1
0,2
0,3
Column Plot
0,3
Liq
Component 2
0,2
0,1
ifgf
T1_2
E2_4
E&R
ifdm
Educ
isdmH3
0,0
H6
H1
H2
S1_1
H5
H
-0,1
-0,2
-0,2
-0,1
0,0
0,1
Component 1
0,2
0,3
Row Plot
0,3
0,2
Component 2
RO
0,1
MS
RS
MT
SC
ES
AM
TO
AL
RJ
0,0
GOPR
SP
MG
SE
BA CE
-0,1
ACRR
AP
MA
PI
PA
PB
RN
PE
-0,1
0,0
0,1
Component 1
0,2
0,3
Todas as variáveis do projeto exceto (R1 e H4) ,assim como no anterior, observa-se um
comportamento semelhante quanto a divisão das regiões, em direita e esquerda, porém o
centro da escala da componente 1 não é mais a referência que divide os grupos. No
grupo da esquerda, é distinta a separação das regiões Norte predominantemente no
quadrante inferior e a Nordeste no quadrante superior.
Simple Correspondence Analysis: Hm_1; H1m_1; H2m_1; H3m_1; H5m_1;
H6m_1; isdmm_
Analysis of Contingency Table
Axis
1
2
3
4
5
6
7
8
9
10
11
12
13
Total
Inertia
0,0107
0,0051
0,0030
0,0013
0,0007
0,0004
0,0002
0,0002
0,0001
0,0001
0,0001
0,0000
0,0000
0,0220
Proportion
0,4866
0,2321
0,1380
0,0575
0,0335
0,0192
0,0098
0,0073
0,0054
0,0047
0,0038
0,0016
0,0004
Cumulative
0,4866
0,7186
0,8567
0,9142
0,9477
0,9669
0,9766
0,9839
0,9893
0,9941
0,9979
0,9996
1,0000
Histogram
******************************
**************
********
***
**
*
Row Contributions
ID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Name
AC
AL
AM
AP
BA
CE
ES
GO
MA
MG
MS
MT
PA
PB
PE
PI
PR
RJ
RN
RO
RR
RS
SC
SE
SP
TO
Qual
0,816
0,129
0,926
0,277
0,441
0,504
0,772
0,866
0,753
0,820
0,883
0,866
0,837
0,889
0,930
0,487
0,877
0,387
0,888
0,748
0,817
0,718
0,727
0,186
0,683
0,360
Mass
0,031
0,035
0,030
0,035
0,035
0,035
0,045
0,043
0,029
0,043
0,043
0,042
0,030
0,034
0,035
0,032
0,045
0,047
0,037
0,040
0,031
0,048
0,049
0,038
0,049
0,038
Inert
0,055
0,010
0,134
0,056
0,026
0,028
0,029
0,029
0,074
0,026
0,027
0,016
0,048
0,024
0,029
0,045
0,024
0,041
0,030
0,050
0,067
0,025
0,027
0,018
0,048
0,014
Component
Coord
Corr
0,174 0,788
0,024 0,088
0,268 0,732
0,097 0,271
0,014 0,012
0,036 0,070
-0,096 0,658
-0,113 0,857
0,202 0,737
-0,089 0,618
-0,079 0,452
-0,052 0,329
0,151 0,640
0,012 0,009
0,004 0,001
0,119 0,452
-0,100 0,859
-0,085 0,378
-0,007 0,003
-0,020 0,015
0,195 0,793
-0,062 0,333
-0,076 0,469
0,001 0,000
-0,120 0,667
0,014 0,023
1
Contr
0,089
0,002
0,202
0,031
0,001
0,004
0,039
0,052
0,111
0,032
0,025
0,011
0,064
0,000
0,000
0,042
0,042
0,032
0,000
0,002
0,110
0,017
0,026
0,000
0,066
0,001
Component
Coord
Corr
0,033 0,028
0,016 0,041
0,138 0,194
0,014 0,006
-0,084 0,430
-0,089 0,434
0,040 0,114
-0,011 0,008
-0,030 0,016
-0,051 0,201
0,077 0,431
0,067 0,538
-0,084 0,197
-0,118 0,879
-0,130 0,929
-0,033 0,035
-0,014 0,017
0,013 0,009
-0,125 0,885
0,141 0,733
0,034 0,024
0,067 0,384
0,056 0,258
-0,043 0,186
-0,019 0,016
0,052 0,337
2
Contr
0,007
0,002
0,112
0,001
0,048
0,053
0,014
0,001
0,005
0,022
0,050
0,037
0,041
0,091
0,117
0,007
0,002
0,002
0,113
0,158
0,007
0,042
0,030
0,014
0,003
0,021
Inert
0,041
0,046
Component
Coord
Corr
-0,079 0,477
-0,042 0,133
1
Contr
0,040
0,013
Component
Coord
Corr
-0,067 0,344
-0,044 0,148
2
Contr
0,060
0,029
Column Contributions
ID
1
2
Name
H
H1
Qual
0,821
0,280
Mass
0,069
0,076
3
4
5
6
7
8
9
10
11
12
13
14
15
H2
H3
H5
H6
isdm
ifdm
ifgf
E2_4
T1_2
S1_1
Educ
E&R
Liq
0,280
0,700
0,965
0,507
0,908
0,732
0,822
0,009
0,367
0,683
0,560
0,073
0,939
0,076
0,089
0,086
0,059
0,071
0,073
0,061
0,080
0,062
0,005
0,083
0,046
0,065
0,046
0,042
0,291
0,121
0,044
0,016
0,046
0,037
0,044
0,021
0,023
0,019
0,163
-0,042
-0,085
0,263
-0,147
-0,112
0,051
0,081
0,003
-0,046
0,244
0,049
0,025
0,013
0,133
0,697
0,925
0,477
0,905
0,555
0,400
0,001
0,135
0,681
0,388
0,071
0,003
0,013
0,060
0,554
0,119
0,082
0,018
0,037
0,000
0,012
0,030
0,019
0,003
0,001
-0,044
-0,006
-0,055
-0,037
-0,006
-0,029
0,083
0,009
0,060
-0,013
-0,033
-0,004
0,227
0,148
0,003
0,040
0,030
0,003
0,178
0,422
0,008
0,232
0,002
0,172
0,002
0,936
0,029
0,001
0,050
0,016
0,001
0,012
0,083
0,001
0,044
0,000
0,017
0,000
0,656
ÁRVORE DE CLASSIFICAÇÃO
13 ÁRVORE CLASSIFICATÓRIA
13.1. ÁRVORES DE CLASSIFICAÇÃO DAS VARIÁVEIS HABITAÇÃO POR
REGIÃO
Este resultado se refere à variável dependente REGIÃO e as variáveis independente:
ISDM, H, H1, H2, H3, H4, H5, H6,
Resumo do modelo
Método de crescimento
CHAID
Variável dependente
VAR00002
Variáveis independentes
Especificações
Validação
VAR00001, VAR00003, VAR00004, VAR00005,
VAR00006, VAR00007, VAR00008, VAR00009
Nenhum
Profundi00dade de árvore
3
máxima
Casos mínimos em nó pai
2
Casos mínimos em nó filho
1
Variáveis independentes
VAR00003
incluídas
Resultados
Número de nós
7
Número de nós de terminal
6
Profundidade
1
Posto
Observado
Previsto
Centro-Oeste
Nordeste
Norte
Região
Sudeste
Sul
Porcentagem
Correta
0
0
16
0
0
0
0
0.0%
Centro-Oeste
0
3
465
0
0
0
0
0.6%
Nordeste
0
0
1790
0
0
0
0
100.0%
Norte
0
0
426
5
0
0
0
1.2%
Região
0
0
0
0
1
0
0
100.0%
Sudeste
0
0
1669
0
0
0
0
0.0%
Sul
0
0
1187
0
0
0
4
0.3%
0.0%
0.1%
99.8%
0.1%
0.0%
0.0%
0.1%
32.4%
Porcentagem global
Método de crescimento: CHAID
Variável dependente: VAR00002
Risco
Estimativas
Modelo padrão
.676
.006
Método de crescimento: CHAID
Variável dependente: VAR00002
13.2
ÁRVORES DE CLASSIFICAÇÃO DAS VARIÁVEIS HABITAÇÃO
POR 3 BRASIS.
Este resultado se refere à variável dependente 3 BRASIS e as variáveis
independente: ISDM, H, H1, H2, H3, H4, H5, H6,
Resumo do modelo
Método de crescimento
CHAID
Variável dependente
VAR00010
Variáveis independentes
Especificações
Validação
VAR00001, VAR00003, VAR00004, VAR00005,
VAR00006, VAR00007, VAR00008, VAR00009
Nenhum
Profundidade de árvore
3
máxima
Casos mínimos em nó pai
2
Casos mínimos em nó filho
1
Variáveis independentes
VAR00003
incluídas
Resultados
Número de nós
5
Número de nós de terminal
4
Profundidade
1
Risco
Estimativas
Modelo padrão
.483
.007
Método de crescimento: CHAID
Variável dependente: VAR00010
Posto
Observado
Previsto
3 Brasis
Centro-Oeste
Nor
Su
Porcentagem
Correta
0
0
0
0
16
0.0%
3 Brasis
0
1
0
0
0
100.0%
Centro-Oeste
0
0
3
0
465
0.6%
Nor
0
0
0
16
2205
0.7%
Su
0
0
0
0
2860
100.0%
0.0%
0.0%
0.1%
0.3%
99.6%
51.7%
Porcentagem global
Método de crescimento: CHAID
Variável dependente: VAR00010
13.3. ÁRVORES DE CLASSIFICAÇÃO DAS VARIÁVEIS HABITAÇÃO POR 2
BRASIS.
Este resultado se refere à variável dependente 2 BRASIS e as variáveis independente:
ISDM, H, H1, H2, H3, H4, H5, H6,
Resumo do modelo
Método de crescimento
CHAID
Variável dependente
VAR00011
Variáveis independentes
Especificações
Validação
VAR00001, VAR00003, VAR00004, VAR00005,
VAR00006, VAR00007, VAR00008, VAR00009
Nenhum
Profundidade de árvore
3
máxima
Casos mínimos em nó pai
2
Casos mínimos em nó filho
1
Variáveis independentes
VAR00003
incluídas
Resultados
Número de nós
4
Número de nós de terminal
3
Profundidade
1
Posto
Observado
Previsto
2 Brasis
Centro-Oeste
SSNN
Porcentagem
Correta
0
0
0
1
0.0%
2 Brasis
0
1
0
0
100.0%
Centro-Oeste
0
0
3
467
0.6%
SSNN
0
0
0
5094
100.0%
Porcentagem global
0.0%
0.0%
0.1%
99.9%
91.6%
Método de crescimento: CHAID
Variável dependente: VAR00011
Risco
Estimativas
Modelo padrão
.084
.004
Método de crescimento: CHAID
Variável dependente: VAR00011
Conclusão:
Entre as três variáveis categóricas apresentadas, observou-se um índice de
previsibilidade na dos 2 Brasis (Variável 11), que alcançou 91,6 % de acerto, contra 3
Brasis (Variável 10), que alcançou 51,7 e 32,4 % das Regiões (Variável 2).
13.4 ÁRVORES DE CLASSIFICAÇÃO DAS VARIÁVEIS COMPARTILHADAS
POR 3 BRASIS
Resumo do modelo
Método de crescimento
CHAID
Variável dependente
VAR00002
VAR00006, VAR00007, VAR00008, VAR00009,
VAR00010, VAR00011, VAR00012, VAR00013,
Variáveis independentes
VAR00014, VAR00015, VAR00016, VAR00017,
VAR00018, VAR00019, VAR00020, VAR00021,
Especificações
VAR00022
Validação
Nenhum
Profundidade de árvore
3
máxima
Casos mínimos em nó pai
2
Casos mínimos em nó filho
1
Variáveis independentes
VAR00006
incluídas
Resultados
Número de nós
3
Número de nós de terminal
2
Profundidade
1
osto
Observado
Previsto
3 BRASISM
B123
B4
B5
Porcentagem
Correta
3 BRASISM
1
0
0
0
100,0%
B123
0
4825
0
0
100,0%
B4
0
92
0
0
0,0%
B5
0
647
0
0
0,0%
0,0%
100,0%
0,0%
0,0%
86,7%
Porcentagem global
Método de crescimento: CHAID
Variável dependente: VAR00002