Faculdade de Engenharia da Universidade do Porto
Mestrado Integrado em Engenharia Informática e Computação
Programação Distribuída e Paralela
Trabalho I
Eficiência do produto de matrizes por blocos
Autor
Daniel Botelho
[email protected]
2007
Índice
1 - Introdução.....................................................................................................................1
2 - Algoritmos.....................................................................................................................1
a) Multiplicação de Matrizes (Normal).............................................................................1
b) Multiplicação de Matrizes por blocos..........................................................................1
c) Multiplicação de Matrizes usando algoritmo paralelo..................................................2
3 – Testes e Resultados.......................................................................................................2
a) Multiplicação de Matrizes (Normal).............................................................................2
b) Algoritmo de Multiplicação por blocos........................................................................2
c) Multiplicação de Matrizes usando algoritmo paralelo..................................................3
4 - Análise de resultados.....................................................................................................3
5 - Bibliografias & Referências............................................................................................4
Appendix.............................................................................................................................5
LogBook..........................................................................................................................5
Tempo despendido......................................................................................................5
Detalhes.....................................................................................................................5
Eficiência do produto de matrizes por blocos
1 - Introdução
O objectivo deste trabalho é testar a eficiência do algoritmo de produto de matrizes por
blocos, comparando-o com outros algoritmos. Para testar isso, vou comparar o produto de
matrizes por blocos com o produto “normal” de matrizes e com um algoritmo SIMD1.
2 - Algoritmos
Nesta secção, vou apresentar os algoritmos que usei para fazer os testes.
a) Multiplicação de Matrizes (Normal)
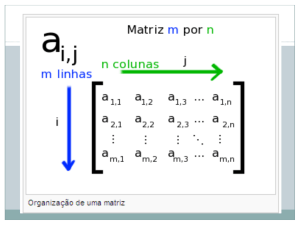
for(i=0; i<mdiag.m_Arows; i++)
{
for(j=0; j<mdiag.m_Brows; j++)
{
temp = 0;
for(k=0; k<mdiag.m_Arows; k++)
{
temp += A(i,k) * B(k,j);
}
C(i,j, temp);
}
}
b) Multiplicação de Matrizes por blocos
N = mdiag.m_Arows / mdiag.m_block;
Bsize = mdiag.m_block;
for(i=0; i<N; i++)
{
for(j=0; j<N; j++)
{
iBase = i*Bsize;
jBase = j*Bsize;
for(k=0; k<N; k++)
{
kBase = k*Bsize;
for(w=0; w<Bsize;w++)
for(e=0; e<Bsize; e++){
temp=0;
for(q=0; q<Bsize; q++){
temp+=A(iBase+w,kBase+q) *
1 A sigla SIMD significa Single Instruction, Multiple Data,ou seja, fluxo único de instruções e múltiplos de
dados. Esse tipo de máquina opera múltiplos conjuntos de dados aplicando uma mesma instrução
simultaneamente a todos eles.
Programação Distribuída e Paralela - 1
Eficiência do produto de matrizes por blocos
B(kBase+q,jBase + e);
}
C(iBase + w,jBase + e,temp);
}
}
}
}
c) Multiplicação de Matrizes usando algoritmo
paralelo
Algoritmo baseado no Applet mostrado neste site:
http://carbon.cudenver.edu/csprojects/CSC5809S01/Simd/parmult.html
for(j=0; j<mdiag.m_Arows; j++)
{
for(i=0; i<mdiag.m_Brows; i++)
for(k=0; k<mdiag.m_Arows; k++)
{
temp = C(k,j) + A(i,j)*B(k,i);
C(k,j,temp);
}
}
}
3 – Testes e Resultados
Nesta secção vou apresentar os resultados obtidos com os diferentes algoritmos.
a) Multiplicação de Matrizes (Normal)
Máquina: Pentium IV 1.4 GHz 512 Ram Windows XP
N
400×400
T
16.384
1200×1200 454.314
S
7812500
7607073.5
2000×2000 2110.755 7580226
b) Algoritmo de Multiplicação por blocos
Programação Distribuída e Paralela - 2
Eficiência do produto de matrizes por blocos
Máquina: Pentium IV 1.4 GHz 512 Ram Windows XP
N=16
400×400
T
16.894
1200×1200 453.031
2000×2000 2109.043
N=64
400×400
T
14.581
1200×1200 390.932
2000×2000 2005.834
N=256
400×400
T
4.456
1200×1200 281.224
2000×2000 1524.592
c) Multiplicação de Matrizes usando algoritmo
paralelo
Máquina: Pentium IV 1.4 GHz 512 Ram Windows XP
400×400
31.816
1200×1200 874.547
2000×2000 4068.280
4 - Análise de resultados
Da análise dos resultados obtidos para cada um dos algoritmos, posso concluir que o
algoritmo mais eficiente é sem dúvida o “b) Algoritmo de Multiplicação por blocos”. Se
verificarmos, para N=16, o algoritmo (b) tem quase a mesma eficiência que o algoritmo
(a), mas se o tamanha do bloco aumentar, o (b) torna-se muito mais eficiente. Analisando
o algoritmo (c), este leva praticamente o dobro do tempo que leva o algoritmo (a).
Programação Distribuída e Paralela - 3
Eficiência do produto de matrizes por blocos
5 - Bibliografias & Referências
•
•
•
•
•
•
•
•
•
Block algorithms: Matrix Multiplication as an Example
http://www.netlib.org/utk/papers/autoblock/node2.html
Block Matrix Multiplication
http://discolab.rutgers.edu/classes/cs528/lectures/lecture7/sld004.htm
[PS] Computational Physics, Spring 2002 Homework Assignment # 7
Agenda ...
http://people.ccmr.cornell.edu/~muchomas/P480/2002/Psets/ps7/ps7.ps
Lecture 2: Implementation and Optimization of Matrix Multiplication
http://www.cs.drexel.edu/~jjohnson/2006-07/fall/cs680/lectures/lec2.html
Imagem a explicar a multiplicação por blocos
http://www.cs.albany.edu/~sdc/csi504/gifs/matrixblockmult.gif
4.6 Case Study: Matrix Multiplication
http://www-unix.mcs.anl.gov/dbpp/text/node45.html
Parallel Matrix Multiplication
http://carbon.cudenver.edu/csprojects/CSC5809S01/Simd/parmult.html
[eBook] Designing and Building Parallel Programs (Online)
http://www-unix.mcs.anl.gov/dbpp/text/book.html
Wikipedia :: SIMD
http://pt.wikipedia.org/wiki/SIMD
Programação Distribuída e Paralela - 4
Eficiência do produto de matrizes por blocos
Appendix
LogBook
Tempo despendido
Tempo Aulas Tempo Aulas Tempo Extra Tempo Extra Tempo Total
Previsto
Usado
Previsto
Usado
Usado
PDPA 3:00
3:00
4:00
12:06
15:06
Detalhes
•
24/03/07 Sábado
• [12:00-13:00](1hm) PDPA :: Terminar o relatorio
•
23/03/07 Sexta
• [11:00-12:00](1hm) Correr os Algoritmos para PDPA
• [22:00-24:00](2h) PDPA:: Fazer relatorio e calculos
22/03/07 Quinta
• [10:20-12:00](1h40m) Trabalhar para PDPA!!
• [12:30-13:30](1h) Trabalhar para PDPA!!
• [14:00-15:00](1h) Trabalhar para PDPA!!
• [16:30-17:00](30m) Reuniao com prof Jorge Barbosa para tirar dúvidas!!
21/03/07 Quarta
• [10:00-12:40](2h40m) Trabalhar para PDPA!!
20/03/07 Terça
• [17:00-20:00](3h) Aula de PDPA..
19/03/07 Segunda
• [22:22-22:38](16m) Ler os acetatos de PDPA
•
•
•
•
Programação Distribuída e Paralela - 5