INCERTEZA EM
BANCOS DE DADOS
Gilene Fernandes
6
LISTA DE FIGURAS
1. Figura 01 - Relações incompletas ensina e matricula....................................28
2. Figura 02 - REP ((ensina, matricula))......................................................29
7
LISTA DE TABELAS
1. Tabela 01 - Relação ensina....................................................................30
2. Tabela 02 - Relação condicional.........................................................30
3. Tabela 03 - Relação Curso-Opcional.....................................................31
4. Tabela 04 - Relação ensina com conjuntos-ou...............................................32
5. Tabela 05 - Relação matricula..................................................................33
6. Tabela 06 - Relação ensina...................................................................34
7. Tabela 07 - Denotando valores nulos universais.................................35
8. Tabela 08 - Relação Rendimentos............................................................36
9. Tabela 09 - Relação que expressa um valor nulo aberto........................................37
10. Tabela 10 - Relação probabilística do tipo-1.........................................38
11. Tabela 11 - Relação probabilística do tipo-2.......................................39
8
SUMÁRIO
1. INTRODUÇÃO ................................................................................................................................ 10
2. TERMINOLOGIA ........................................................................................................................... 11
2.1. SISTEMAS DE BANCO DE DADOS .......................................................................................... 11
2.2. INCERTEZA.................................................................................................................................. 12
3. INCERTEZA DE DESCRIÇÃO ..................................................................................................... 13
3.1. ELEMENTOS AFETADOS PELA INCERTEZA ..................................................................... 13
3.2 CAUSAS DA INCERTEZA ........................................................................................................... 14
3.3. GRAUS DE INCERTEZA ............................................................................................................ 15
3.4. SOLUÇÕES ................................................................................................................................... 16
3.4.1. VALORES NULOS .................................................................................................................... 16
3.4.2. FATORES DE CERTEZA ......................................................................................................... 17
3.4.4. DISTÂNCIAS.............................................................................................................................. 18
3.4.4. PROBABILIDADE .................................................................................................................... 19
3.4.5. COMPLETUDE E CORRETUDE ............................................................................................ 20
4. INCERTEZA DE TRANSAÇÃO E INCERTEZA DE PROCESSAMENTO ............................ 21
4.1. TRANSFORMAÇÕES .................................................................................................................. 21
4.2. MODIFICAÇÕES ......................................................................................................................... 22
4.3. PROCESSANDO ........................................................................................................................... 23
5. OBSTÁCULOS E DESAFIOS ........................................................................................................ 24
5.1. AMBIENTES HETEROGÊNEOS DE BANCO DE DADOS .................................................... 25
5.2. BANCO DE DADOS MULTIMÍDIA .......................................................................................... 25
5.3. IMPUTAÇÃO E DESCOBERTA DO CONHECIMENTO ...................................................... 26
5.4. ADAPTANDO INTELIGÊNCIA ARTIFICIAL PARA BANCO DE DADOS ........................ 27
6. UM ESTUDO DE CASO - INFORMAÇÃO IMPERFEITA EM BANCO DE DADOS
RELACIONAL ................................................................................................................................. 28
6.1. MUNDOS POSSÍVEIS.................................................................................................................. 28
6.2. VALORES EXISTENCIAS .......................................................................................................... 30
6.2.1. VALORES EXISTENCIAS ATÔMICOS ................................................................................ 30
6.2.2. CONJUNTOS DE VALORES EXISTENCIAS ....................................................................... 31
6.2.3. CONJUNTOS-OU ...................................................................................................................... 31
6.3. VALORES INEXISTENTES ........................................................................................................ 33
6.4. BANCO DE DADOS ABERTOS E VALORES NULOS ........................................................... 34
6.4.1. HIPÓTESES CONCLUÍDAS .................................................................................................... 34
6.4.2. VALORES UNIVERSAIS E DEFAULT .................................................................................. 35
6.4.3. VALORES ABERTOS ............................................................................................................... 37
6.5. BANCO DE DADOS PROBABILÍSTICOS ............................................................................... 38
9
7. CONCLUSÃO................................................................................................................................... 40
8. BIBLIOGRAFIA .............................................................................................................................. 41
10
1. INTRODUÇÃO
Os sistemas de bancos de dados (BD) modelam nosso conhecimento do
mundo real1. Esse conhecimento é muitas vezes permeado de incertezas. Portanto, os
sistemas de banco de dados devem ser capazes de lhe dar com incertezas. E,
realmente, a maioria dos sistemas incluem capacidades para lhe dar com alguns tipos
de incertezas - por exemplo, muitos sistemas representam valores desconhecidos com
valores nulos, e a maioria das linguagens de consultas admitem alguma forma de
incerteza.
Apesar dessas capacidades serem poucas em comparação com a variedade e
graus de incertezas que são encontrados na prática. A comunidade de pesquisa tem
mostrado um persistente interesse sobre o assunto, mas a maioria das tentativas não
passam de um protótipo experimental. Além do que, os sistemas de banco de dados
comercias tem sido vagarosos para incorporar capacidades de lhe dar com incertezas.
A seguir mostraremos resultados de incertezas em banco de dados. Definindo
terminologias e classificando os vários tipos de incertezas. Além de apresentar o uso e
a manipulação de informações imperfeitas em bancos de dados relacionais.
1
Usamos o termo sistema de banco de dados, para incluir tipos relacionados de sistemas de
informações como sistemas de recuperação de informações e sistemas espertos (inteligentes).
11
2. TERMINOLOGIA
Nossa discussão sobre incerteza em banco de dados começa com definições de
sistemas de banco de dados e incerteza.
2.1. SISTEMAS DE BANCO DE DADOS
Um sistema de banco de dados é um modelo computacional de alguma porção
do mundo real. Geralmente, tais modelos incluem um componente declarativo para
descrever o mundo real e um componente operacional para manipular essa descrição.
Manipulações típicas são (1) modificações da descrição; (2) transformações da
descrição.
Então, um sistema de banco de dados pode ser abstraído como uma descrição
D do mundo real, uma seqüência de modificações e transformações. Como exemplo,
em um sistema de banco de dados relacional uma descrição é o conjunto de tabelas
(i.e., um banco de dados); uma modificação pode afetar tanto a definição ou o
conteúdo das tabelas (i.e., reestruturar ou alterar); e uma transformação reduz o
conjunto de tabelas dentro de uma única tabela (i.e., avaliação de consulta).
12
2.2. INCERTEZA
Assumimos que a incerteza permeia nossos modelos do mundo real e não o
próprio mundo real. Em outras palavras, o mundo real é sempre certo, é o nosso
conhecimento sobre ele que as vezes é incerto. Nós usamos o termo incerteza para
referenciar algum elemento do modelo que não pode ser afirmado com certeza. Em
particular, incerteza pode ser esperada (1) em descrições do mundo real, (2) em
modificações e transformações dessa descrição, e (3) na execução dessas operações.
Portanto, observamos vários tipos de incerteza:2
Incerteza - Não é possível determinar se uma declaração no modelo é
verdadeira ou falsa. Por exemplo, poderá existir incerteza no seguinte fato
do banco de dados, “A idade de João é 38”. Você não sabe se é verdadeira
ou falsa, pois existem informações perdidas nesta declaração, por exemplo
de que João estamos falando?
Imprecisão - A informação disponível no modelo não é tão específica como
poderia ser. Por exemplo, quando um valor distinto é requerido, a
informação disponível é uma variação (ex.: “A idade de João está entre 37
e 43 anos”), disjuntiva (ex.: “A idade de João é 37 ou 43 anos”); negativa
(ex.: “A idade de João não é 37 anos”), ou desconhecida (geralmente se
refere a incompletude).
Vaguesa - O modelo inclui elementos (i.e., predicados ou quantificadores)
que são inerentemente vagos; por exemplo, “João é o mais novo do meio”.
Uma formalização particular de vaguesa é baseado no conceito de fuzziness.
Insconsistência - O modelo contém duas ou mais declarações que não
podem ser verdadeiras ao mesmo tempo; por exemplo, “A idade de João
está entre 37 e 43 anos” e “A idade de João é 35 anos”.
Ambigüidade - Alguns elementos do modelo necessitam de semântica
completa, levando à várias possíveis interpretações. Por exemplo, “Não
está bem claro se os salários fixados são por mês ou por ano”.
2
Um desses tipos específicos será o próprio termo incerteza; Assim, dependendo do contexto, este
termo poderá ser usado tanto genericamente ou especificamente.
13
O objetivo de um sistema de BD é prover os seus usuários de informações que
eles precisem. O resultado t(D), onde t(D) é a transformação da descrição D, pode ser
incerta porque D é incerta, ou porque t é incerta, ou porque a aplicação de t em D
envolve incertezas.
Nós nomeamos essa categorias de incertezas, respectivamente, incerteza de
descrição, incerteza de transação, e incerteza de processamento. Estas categorias
servem como estrutura para classificar o trabalho que vem sendo feito na área de
sistemas de banco de dados.
3. INCERTEZA DE DESCRIÇÃO
Nossa discussão sobre incerteza de descrição começa considerando três
resultados: os diferentes elementos da descrição que devem ser afetados pela
incerteza, as diferentes causas de incerteza, e os diferentes graus de incerteza.
3.1. ELEMENTOS AFETADOS PELA INCERTEZA
Dependendo do modelo usado, descrições podem atingir diferentes formas, e a
incerteza pode afetar cada uma delas. Considere, por exemplo, um banco de dados
relacional. A estrutura do modelo relacional admite diferentes tipos de incertezas.
O primeiro tipo de incerteza é a nível dos valores de dados; por exemplo,
alguns valores de Hora_Saída na relação VÔO (Número_Voo, Hora_Saída) podem
ser incertos. O segundo tipo envolve incerteza a nível de tupla; por exemplo, deve
haver incerteza com relação aos membros de algumas tuplas da relação
CONECÇÃO_DIRETA (Origem, Destino). Um terceiro tipo envolve incerteza a
nível de relação (estrutura); por exemplo, poderá haver incerteza se o vôo tiver mais
de um destino, e portanto qual será a descrição deste relacionamento [Borgida 1985].
Considere outro exemplo, onde um sistema inteligente modela o conhecimento
do mundo real com fatos e regras expressados em lógica. Poderá haver incertezas
sobre os esses fatos e sobre as regras.
14
3.2 CAUSAS DA INCERTEZA
Excluído a possibilidade que a própria realidade está sujeita a incertezas.
Podemos assumir que a descrição perfeita de algum objeto do mundo real sempre
existe. Então, a existência de descrições incertas é devido unicamente a
indisponibilidade de uma descrição perfeita. Ainda dentro desta indisponibilidade
genérica, nós observamos vários tipos específicos de incertezas [Kwan et al. 1992].
Incerteza pode resultar do uso de informações de origens incertas, como falta
de instrumentos de leitura, ou entrada de formulários que foram preenchidos
incorretamente. Em outro casos, de erros do sistema, incluindo transmissões de
barulhos, imperfeições do sistema de software, atraso no processamento de transações
de alteração e corrupção dos dados devido falhas ou sabotagens.
Hoje em dia, as incertezas provém de resultados inevitáveis de métodos de
agrupamento de informações que requerem estimação ou critérios. Por exemplo,
representação digital de um fenômeno contínuo, e a representação de um fenômeno
que varia constantemente.
Em outros casos, incertezas provém de resultados de restrições impostas pelo
modelo. Por exemplo, se um esquema de um banco de dados permite o
armazenamento de mais de duas ocupações por empregado, então a descrição da
ocupação poderá exibir incertezas.
15
3.3. GRAUS DE INCERTEZA
A discussão seguinte sobre os graus de incerteza independe de uma estrutura
particular que seja afetada pela incerteza e como podemos reduzi-los. Assumimos que
um elemento e da descrição modela um objeto o do mundo real. O elemento e pode
ser um valor, um fato, uma regra, uma tupla e assim por diante.
A incerteza é alta quando a mera existência de algum objeto do mundo real é
duvidosa. Um solução simples é ignorar tais objetos totalmente. Esta solução, no
entanto, não é aceitável se o modelo segue abordagem do mundo fechado (i.e.,
objetos não modelados, não existem).
A incerteza é reduzida quando consideramos os seguintes pontos:
Elementos do modelo podem ter seus valores designados em uma faixa
prescrita para indicar a certeza que os objetos modelados existem. Logo, assumimos
que a existência é certa, mas algumas ou todas das informações com que cada modelo
descreve os objetos são desconhecidas. Tais informações são referenciadas
(classificadas) como incompletas, perdidas ou indisponíveis.
2. A informação que descreve um objeto é conhecida e vem de um conjunto
limitado de alternativas (possivelmente um faixa de valores). Esta incerteza é
referenciada como uma informação disjuntiva.
3. Cada alternativa é acompanhada por um número que descreve a
probabilidade que ela é realmente a descrição verdadeira (e o somatório destes
números para o conjunto de entradas é 1). Neste caso, a informação incerta é
probabilística.
16
3.4. SOLUÇÕES
Consideraremos aqui quatro abordagens cada uma diferente da outra para
acomodar o problema de incertezas em descrições.
3.4.1. VALORES NULOS
Uma abordagem mínima que admite descrição incompleta é ignorar todas as
informações parciais sobre as partes incertas da descrição que pode estar pronta e
modelá-las com uma pseudo-descrição, chamada de null (nulo), denotando incerteza.
Uma vez que valores nulos foram admitidos dentro das descrições, o modelo
deve determinar o comportamento das transformações e modificações na presença
desses valores. Isto não é uma tarefa simples.
Na seção 6, no qual falaremos de informações imperfeitas em bancos de dados
relacionais, veremos o uso e a manipulação dos vários tipos existentes de valores
nulos.
17
3.4.2. FATORES DE CERTEZA
Os fatores de certeza denotam segurança em vários elementos da descrição.
Eles oferecem uma ferramenta simples para representar incerteza e tem sido aplicado
tanto em sistemas de recuperação de informação quanto em sistemas espertos
(inteligentes).
Em sistemas de recuperação de informação os fatores de certeza, também
chamados de weights (pesos), tem sido usados para denotar a certeza com que uma
palavra chave específica descreve um documento dado (ou alternativamente, denotar a
força com que esta palavra chave aplica-se ao documento) [van Rijsbergen 1979;
Salton e McGill 1983; Turtle e Croft 1992]. Métodos tem sido desenvolvidos para
computar os fatores de certeza automaticamente, examinado cuidadosamente
documentos e aplicando técnicas para contar as palavras chaves. A manipulação
desses fatores é relativamente simples, pois eles são facilmente acomodados em
modelos de espaços vetoriais que são freqüentemente usados em recuperação de
informações.
Em sistemas espertos, fatores de certeza tem sido usados para denotar certeza
com que fatos e regras são estabelecidos dentro da descrição dos objetos do mundo
real. Tais fatores são geralmente declarados por engenheiros de conhecimento como
parte do processo de aquisição do conhecimento, mas eles podem ser derivados
automaticamente como parte do processo de descobrimento do conhecimento
[Piatetsky-Shapiro 1991]. A manipulação destes fatores é muitas vezes direta. Por
exemplo, assumindo os fatores de certezas neste intervalo [0, 1], quando uma regra
com certeza p é aplicada a um fato com certeza q, então o fato gerado é assinalado
com fator de certeza p.q.
18
3.4.4. PROBABILIDADE
A teoria de conjuntos fuzzy oferecem um compreensiva abordagem para
modelar incertezas em sistemas de informações.
Um conjunto fuzzy F é um conjunto de elementos onde cada elemento está
associado a um valor no intervalo [0, 1] que denota o grau dos seus membros no
conjunto. Por exemplo, o conjunto de pessoas idosas é representado da seguinte
maneira I = {..., 35/0.6, 45/0.7, 50/0.8, 55/0.9, 60/1.0, ...}, onde o grau com que um
homem de 35 anos faça parte desse conjunto é de 0.6.
Sendo uma relação um subconjunto do produto de vários domínios, uma
abordagem é definir relações como subconjuntos fuzzy do produto de vários
domínios. Desde que cada relação é um conjunto fuzzy, cada uma de suas tuplas é
associado com o grau de seus membros.
Considere agora, relações padrões (não fuzzy), mas assuma que os elementos
dos domínios são valores do conjunto fuzzy. Esta definição admite incerteza a nível
de valores de dados. Então, existe casos onde um valor pode ser um dos quatro tipos:
1. Um conjunto ou intervalo - por exemplo, o valor do DEPARTAMENTO
pode ser {exportação, importação}, ou o valor do SALÁRIO pode ser R$
40,000-50,000 respectivamente. Note que a interpretação de cada conjunto
ou intervalo é puramente disjuntiva.
2. Um valor fuzzy - por exemplo, o valor da idade pode ser jovem.
3. Um valor nulo.
4. Um valor simples (sem incerteza).
Para manipular banco de dados fuzzy, os operadores da álgebra relacional
padrão devem ser extendidos para relações fuzzy. A definição de um banco de dados
probabilístico é similar a definição de banco de dados fuzzy: relações padrões mas
com valores de domínio que, em geral, são funções de distribuição de probabilidade,
cujo conceito é o seguinte: uma função de distribuição de probabilidade de uma
variável X sobre um domínio D designa cada valor d D como um valor entre 0 e 1,
com a probabilidade que X = d.
19
3.4.4. DISTÂNCIAS
Uma abordagem para incertezas que vem sendo aplicada com sucesso tanto em
sistemas de banco de dados como em sistemas de recuperação de informação trata a
incerteza com distância. A idéia básica é modelar o mundo real com uma descrição
aparentemente certa e contar com as definições de distâncias entre descrições que
criam vizinhanças de descrições.
Assim, alguma incerteza sobre um objeto do mundo real o é ignorada, e uma
descrição aparentemente certa e deste objeto é armazenada. É esperado que esta
negligência seja compensada por ter e em algum lugar da vizinhança da descrição
verdadeira. Quando um pedido de informação especifica esta descrição verdadeira, e
será recuperado juntamente com os outros vizinhos da descrição verdadeira.
Por exemplo, considere sistemas de banco de dados relacionais. Cada sistema
descreve objetos com tuplas, e freqüentemente existe incerteza com relação ao valor
de algum atributo em uma determinada tupla. É possível estabelecer a distância entre
os elementos do domínio deste atributo. Então, quando uma consulta especifica o
valor deste atributo, todas as tuplas serão recuperadas cujo valor para aquele atributo
está na vizinhança do valor especificado.
Nós assumimos aqui que as descrições estão sujeitas a incertezas (o que é
ignorado) e pedidos estão certos. A mesma solução aplica-se quando descrições são
certas e pedidos estão sujeitos a incertezas. Um refinamento deste método é admitir
fatores de certezas nas descrições e nos pedidos.
20
3.4.5. COMPLETUDE E CORRETUDE
Em vez de modelar imperfeições na informação (i.e., incertezas), nós
sugerimos declarar porções do banco de dados que são modelos perfeitos do mundo
real.
Esta abordagem interpreta certeza, com o termo integridade, como sendo a
combinação de completude e corretude. Uma descrição é correta (íntegra) se ela inclui
unicamente informação que ocorre no mundo real; uma descrição é completa se ela
inclui todas as informações que ocorrem no mundo real. Portanto, uma descrição tem
integridade se ela inclui toda a verdade (completude) e nada mas que a verdade
(corretude).
Assim, para declarar as porções do banco de dados ou as porções de uma
resposta íntegra esta abordagem utiliza-se de mecanismos de visões. O conceito de
completude de visões é similar a hipótese que uma visão correta do banco de dados
faz parte do mundo fechado [Reiter 1978]; a noção de corretude de visões é mostrado
como sendo uma generalização de restrições de integridade de um banco de dados
padrão.
21
4. INCERTEZA DE TRANSAÇÃO E INCERTEZA DE PROCESSAMENTO
Nesta seção discutiremos brevemente resultados e soluções que associam
incerteza na definição de transformações (i.e., consultas) e modificações (i.e.,
alterações ou operações de restruturação), e no processamento de cada transação.
4.1. TRANSFORMAÇÕES
Transformações são operações que derivam novas descrições de descrições
armazenadas. O tipo mais freqüente de transformação é a requisição de informação
por parte dos usuários (consulta). Pedidos incertos podem ocorrer por diferentes
razões.
Hoje em dia, usuários de sistemas de banco de dados não tem conhecimento
suficiente do banco de dados nem do sistema que eles estão utilizando, não tendo uma
idéia clara das informações disponíveis (ou como elas estão organizadas), bem como
não sabem formular seus pedidos (consultas) com as ferramentas que o sistema
provém. Um exemplo disto, é um usuário que procura o significado de uma palavra no
dicionário mas não pode soletrá-la corretamente.
Resumindo, nós distinguimos entre (1) incerteza sobre a informação
disponível (ou como ela está organizada), (2) incerteza sobre informação necessária
(ou como denotá-la em termos aceitáveis para o sistema), e (3) incerteza sobre as
linguagens e ferramentas do sistema que são usados para formular pedidos.
Ferramentas de acessos alternativos tem sido desenvolvidas para uso dos
usuários, como: Browsers de acesso a informações;
construtores interativos de
consultas que conduzem os usuários do sistema a formulações satisfatórias de seus
pedidos. Entretanto, mesmo depois que um pedido de informação (consulta) tenha
sido aceito pelo sistema e sua resposta entregue ao usuário, a incerteza ainda persiste,
pois nem sempre é possível verificar se o pedido alcançou de fato a intenção do
usuário.
22
4.2. MODIFICAÇÕES
Modificações (alterações e restruturações) são operações que afetam as
descrições armazenadas em sistemas de informações. Como transformações,
modificações são definidas pelos usuários, e aqui também distinguimos entre três
principais causas de incertezas: (1) conhecimento insuficiente do sistema, (2)
conhecimento insuficiente do banco de dados específico que está sendo modificado, e
(3) incerteza sobre a informação embutida na modificação.
Muitas das abordagens dirigidas que tem aliviado os problemas de de
incertezas nas transformações (seção 2.5.1.) são também aplicadas as modificações.
Contudo, poucas ferramentas tem sido desenvolvidas para lhe dar com as
modificações. Entretanto, sabemos que os usuários que modificam o banco de dados
tem uma boa familiaridade com o mesmo e com o próprio sistema.
Com relação a terceira abordagem de incerteza, ou seja, modificações vagas ou
imprecisas temos como exemplo um pedido para adicionar informação incerta - “O
novo gerente do banco é um do dois, Paulo ou João”. Entretanto, este tipo de incerteza
não é diferente da incerteza de descrição que foi o assunto da seção 2.3.
23
4.3. PROCESSANDO
Ainda quando a descrição D e a transformação t estão livres de incertezas, o
resultado t(D) pode ser incerto por causa dos métodos usados pelo sistema para
processar os pedidos. Em certas aplicações, um sistema de informação pode alocar
recursos computacionais limitados para processar o pedido [Imielinsky 1987]. Por
exemplo, uma consulta recursiva a um banco de dados genealógico para listar todos os
ancestrais de um indivíduo específico pode terminar depois de um período
predeterminado de tempo (presumivelmente o número de ancestrais recuperados pelo
sistema deve ser suficiente).
24
5. OBSTÁCULOS E DESAFIOS
Os sistemas comerciais de banco de dados tem caminhado lentamente para
incorporar capacidades de incertezas. Enquanto soluções baseadas na teoria dos
conjuntos fuzzy vem aumentando suas aceitações em várias tecnologias, sistemas
comerciais de banco de dados não tem aceitado ainda esta solução.
Examinando as possíveis razões dessa baixa aceitação, temos: Primeiro, os
sistemas profissionais de banco de dados estão preocupados primeiramente com suas
performances. Aqui muitos dos algoritmos para casar dados incertos ou para processar
pedidos incertos são altamente complexos e ineficientes.
Os sistemas profissionais de banco de dados estão também preocupados com a
compatibilidade, já que as várias implementações distintas de capacidades de
incertezas não foram bem sucedidas. Isto pode ter causado um grande efeito nas outras
implementações.
Outro obstáculo para sistemas de banco de dados com capacidades para
incertezas podem existir nas expectativas dos usuários. Um princípio fundamental dos
sistemas de banco de dados é que consultas e respostas nunca expõe interpretações
subjetivas, e os usuários esperam suas consultas serem interpretadas sem
ambigüidades e suas respostas com completa precisão.
Recentemente, as novas aplicações que surgiram requerem sistemas de banco
de dados com capacidades de incerteza. Várias destas aplicações serão descritas a
seguir.
25
5.1. AMBIENTES HETEROGÊNEOS DE BANCO DE DADOS
Em um ambiente heterogêneo multi-banco de dados, a integração e a troca de
informações requerem protocolos para traduzir informações entre os diferentes tipos
de modelos. A possibilidade de ter sistemas de banco de dados baseados em diferentes
formalismos de incertezas introduz um desafio adicional: desenvolver protocolos para
encontrar formalismos de incertezas comuns para que a informação incerta possa ser
integrada com mínima perda de informação.
5.2. BANCO DE DADOS MULTIMÍDIA
A recuperação de informação em banco de dados tradicionais baseia-se no
casamento exato (exact matching). Onde um pedido (consulta) de um determinado
dado faz com que o banco de dados recupere o dado que case exatamente com o dado
requerido.
Hoje em dia, o gerenciamento de imagens em grandes banco de dados segue o
mesmo paradigma: enquanto as imagens são armazenada (digitalizadas) em grandes
bancos de dados, a recuperação é executada em cima de descrições textuais destas
imagens que são armazenadas juntamente com suas próprias imagens.
Como ilustração, temos a abordagem de Consultas por Conteúdo de Imagem
(Query By Image content - QBIC) da IBM, que recupera imagens que casam com uma
imagem dada. Técnicas de casamentos de imagens utilizam algoritmos do melhor
casamento (best-matching).
26
5.3. IMPUTAÇÃO E DESCOBERTA DO CONHECIMENTO
Em várias aplicações, notadamente em projetos científicos e estatísticos, é
necessário estimar dados desconhecidos (valores nulos) de outros dados disponíveis.
Este processo, usualmente é conhecido como imputação, onde as informações são
produzidas de vários graus de incertezas. O gerenciamento desta informação não pode
ser feita por técnicas tradicionais de banco de dados, requerendo portanto o uso de
técnicas de incertezas. A inferência de valores desconhecidos dentro de seu contexto
está relacionada com o resultado da descoberta de novos conhecimentos em grandes
bancos de dados.
27
5.4. ADAPTANDO INTELIGÊNCIA ARTIFICIAL PARA BANCO DE DADOS
Um clássico problema envolve a modelagem de sistemas de banco de dados.
Por um lado, queremos um modelo rico e poderoso como possível, e por outro lado,
sistemas de banco de dados que suportam restrições cruciais de simplicidade e
eficiência, de suas descrições e de suas manipulações de descrições.
Como sistemas de banco de dados, a área de inteligência artificial (IA) tem se
preocupado com respeito a modelagem exata do nosso conhecimento do mundo real.
Inúmeras teorias de incertezas tem sido desenvolvidas; a maioria tem fundamentos na
lógica não clássica, na teoria da probabilidade, nas funções de crença, ou na teoria da
possibilidade [Lea Sombe 1991; Motro e Smets 1992; Smets e Clarke 1991; Smets e
Motro 1993].
Tradicionalmente, pesquisas em IA tem enfatizado modelos ricos e poderosos,
esforçando-se para modelar precisamente todas as sutilezas da realidade. Por outro
lado, pesquisas em sistemas de bancos de dados tem enfatizado representações
econômicas com baixa expressividade mas com uma baixa representação de overhead
e um processamento altamente eficiente.
Temos como exemplo: Os modelos semânticos de dados; as redes semânticas;
e recentemente, sistemas de banco de dados ricos em conhecimento que incorporam
regras de inferência expressadas em lógica matemática [Ullman 1988; Ullman 1989;
Ceri et al. 1990]. Um importante impulso foi dado entre os pesquisadores de banco de
dados que trabalham nesta área tem sido o desenvolvimento de técnicas de inferências
altamente eficientes para uma classe limitada de regras.
As teorias de incertezas desenvolvidas para IA tem sido adaptadas para
trabalhar com técnicas de banco de dados, tornando-se um desafio importante para o
pesquisadores da área.
28
6. UM ESTUDO DE CASO - INFORMAÇÃO IMPERFEITA EM BANCO DE
DADOS RELACIONAL
6.1. MUNDOS POSSÍVEIS
Como sabemos, um banco de dados modela alguma parte do mundo real. Se a
informação disponível é completa ou correta, então há uma clara correspondência
entre o banco de dados e o mundo real. Contudo, quando o conhecimento sobre o
mundo é incompleto ou incerto, vários cenários ou estados com conhecimento
completo e correto podem ser possíveis, mas não se sabe qual deles representa o
estado real do mundo.
Assim, um banco de dados que contém informação incompleta ou incerta
implicitamente representa um conjunto de estados ou mundos possíveis. Um mundo
possível é um estado hipotético do mundo que pode ser representado por um banco de
dados usual com informação completa ou correta.
A semântica de um banco de dados com informação incompleta ou incerta
designa para cada relação R, o valor da função de representação REP(R), que é o
conjunto de mundos possíveis.
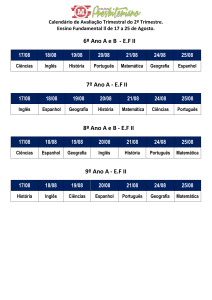
Considere, por exemplo, as relações ensina (professor, curso) e matricula
(estudante, curso) ilustrada na figura 01, onde as variáveis x e y representam valores
desconhecidos ou, mais precisamente, valores nulos do tipo “valor existe, mas é
desconhecido”.
ENSINA
PROFESSOR
CURSO
Martin
Física
x
Álgebra
MATRICULA
ESTUDANTE
CURSO
Paul
Física
Peter
y
Figura 01 - Relações incompletas ensina e matricula
29
Os mundos possíveis da função de representação REP(ensina, matricula) do
exemplo acima estão na figura 02.
M1:
ensina = {(Martin, Física), (Martin, Álgebra)},
matricula = {(Paul, Física), (Peter, Álgebra)}
M2:
ensina = {(Martin, Física), (Martin, Álgebra)},
matricula = {(Paul, Física), (Peter, Cálculo)}
M3:
ensina = {(Martin, Física), (Annie, Álgebra)},
matricula = {(Paul, Física), (Peter, Álgebra)}
M4:
ensina = {(Martin, Física), (Annie, Álgebra)},
matricula = {(Paul, Física), (Peter, Cálculo)}
Figura 02 - REP ((ensina, matricula))
30
6.2. VALORES EXISTENCIAS
6.2.1. VALORES EXISTENCIAS ATÔMICOS
Valores existenciais atômicos modelam uma situação em que o valor de um
atributo existe, mas o valor definido é desconhecido. Um valor existencial é atômico
quando o atributo desconhecido tem exatamente um valor possível. Considere por
exemplo, a seguinte relação ilustrada na tabela 01.
ENSINA
PROFESSOR
CURSO
SALA
Marc
Banco de Dados
AX210
Pierre
x
H1309
Thomas
Mecânica
y
Thomas
Línguas
z
Tabela 01 - Relação ensina
As variáveis representam valores nulos, onde duas variáveis diferentes podem
ou não representar a mesma constante. Assim, o curso ensinado por Pierre na sala
H1309 e as salas nas quais Thomas ensina possuem valores desconhecidos.
Temos ainda as relações condicionais (ou C-Relations), nas quais são obtidas
pela inclusão de uma coluna nas relações com condições locais compostas de
igualdades e desigualdades. Por exemplo,
ENSINA
PROFESSOR
CURSO
SALA
CONDIÇÃO
Marc
Banco de Dados
AX210
Pierre
x
H1309
Thomas
Mecânica
y
x = Física
Thomas
Línguas
y
x Física
Tabela 02 - Relação condicional
Neste exemplo, Thomas ensina Mecânica se Pierre ensina Física; caso
contrário Thomas ensina Línguas.
31
6.2.2. CONJUNTOS DE VALORES EXISTENCIAS
Considere a seguinte relação curso-opcional ilustrada na tabela 03 abaixo.
CURSO-OPCIONAL
ESTUDANTE
CURSO-OPCIONAL
Dominique
Línguas
Anne-Marie
{x}
Martin
{y}
Jean-Pierre
z
Banco de Dados {x}
Tabela 03 - Relação Curso-Opcional
Aqui, {x}, {y} denota conjuntos de valores existenciais, significando que
Anne-Marie e Martin tem pelo menos um curso enquanto Jean-Pierre tem exatamente
um. Além do que o curso Banco de dados não está entre os cursos de Annie-Marie.
6.2.3. CONJUNTOS-OU
Conjuntos-ou
(ou
conjuntos
disjuntivos)
generalizam
valores
nulos
existencias. Um valor existencial representa um atributo cujo valor atual está no
domínio do banco de dados. Um conjunto-ou representa um atributo cujo valor é um
conjunto explícito, pequeno.
Quando um conjunto-ou aparece em uma tupla da relação, o valor atual do
atributo é um dos elementos do conjunto-ou. Um valor atômico usual pode ser visto
como um conjunto-ou cujo valor é um único elemento. Um valor existencial
corresponde a um conjunto-ou contendo o domínio do atributo de entrada. Conjuntosou podem também conter um valor especial para representar a possibilidade de não
existir valor. Seja o exemplo na tabela 04 abaixo.
32
ENSINA
PROFESSOR
CURSO
Marc
Física
Thomas
{Física, Química, Biologia}
{Susan, Martha, }
Álgebra
Tabela 04 - Relação ensina com conjuntos-ou
Nesta relação ensina (professor, curso) ilustrada na tabela acima, a segunda
tupla representa que Thomas ensina um dos cursos do conjunto {Física, Química,
Biologia}. A terceira tupla representa que Susan ou Martha ensina Álgebra ou
ninguém ensina Álgebra.
Conjuntos-ou não são poderosos o suficiente para representar algumas
variedades de informações incompletas. Por esta razão, Michalewicz e Groves [52]
propuseram os conjuntos-ou generalizados, cujo valor atual é entendido para ser
algum subconjunto não vazio do conjunto armazenado. Se o valor atual pode ser
vazio, o valor especial é incluído no conjunto armazenado. Por exemplo,
interpretando a tupla da relação descrita anteriormente {Susan, Martha, } como um
conjunto-ou generalizado temos o seguinte: Álgebra pode ser ensinada tanto por
Susan ou Martha, ou ambas, ou pode não ser oferecida.
Michalewicz e Groves [52] ainda estudaram os conjuntos-e. Um conjunto-e de
um atributo A de uma tupla t representa que o valor atual do atributo é precisamente
todos os valores especificados no conjunto.
33
6.3. VALORES INEXISTENTES
Valores inexistentes, denotado por , permite representar um atributo que é
inaplicável. Por exemplo, considere a relação matricula(estudante, departamento,
curso):
MATRICULA
ESTUDANTE
DEPARTAMENTO
CURSO
Pierre
Física
Cálculo
Jean
Probabilidade
Tabela 05 - Relação matricula
A segunda tupla representa que Jean matriculou-se em probabilidade sem estar
registrado em nenhum departamento.
34
6.4. BANCO DE DADOS ABERTOS E VALORES NULOS
6.4.1. HIPÓTESES CONCLUÍDAS
Com a Hipótese do Mundo Fechado (Closed World Assumption - CWA), todas
as informações não explicitamente representadas no banco de dados são supostamente
falsas. Assim, para a relação ensina (professor, curso, departamento), segundo o
CWA temos que não existem professores, nem outros cursos, e nem outros
departamentos a não ser os que aparecem na relação.
Com a Hipótese do Mundo Aberto (Open World Assumption - OWA), a
hipótese anterior não é mantida, desde que possa existir outras tuplas na relação.
Adicionalmente, com a OWA as informações negativas devem estar explicitamente
estabelecidas, ao contrário do mundo fechado, por exemplo
ENSINA
PROFESSOR
DEPARTAMENTO
CURSO
Componente Positivo
Pierre
Física
Cálculo
Componente Positivo
Marc
Química
Cálculo
Marc
Física
Álgebra
Componente Negativo
Tabela 06 - Relação ensina
Isto representa que Marc não ensina Álgebra no departamento de Física.
O operador de diferença implicitamente assume a CWA, portanto uma
expressão relacional que não contém operadores de diferenças produzem os mesmos
resultados tanto para a CWA quanto para a OWA.
35
6.4.2. VALORES UNIVERSAIS E DEFAULT
Sobre a OWA, duas outras categorias de valores nulos naturalmente aparecem:
os valores universais e default.
Suponha que “Jean ensina biologia em todos os departamentos”, se a relação
for interpretada sob o CWA, o fato descrito pode ser representado pela inclusão de um
conjunto de tuplas da forma (Jean, biologia, dept) na relação, uma para cada
departamento dept do banco de dados.
Com relação a OWA, a situação é completamente diferente. O fato descrito
acima é representado da seguinte maneira: desde que nem todos os departamentos são
necessariamente conhecidos, então não é preciso a inclusão de todas as tuplas da
forma (Jean, biologia, dept). O fato deve ser representado com um valor nulo
universal denotado por :
ENSINA
PROFESSOR
CURSO
DEPARTAMENTO
Pierre
Cálculo
Física
Jean
Biologia
Marc
Cálculo
Química
Tabela 07 - Denotando valores nulos universais
36
Os valores nulos default formam outra categoria de valores nulos necessários
quando a OWA é aplicada há um banco de dados. Suponha que a renda dos
professores universitários é representada pela relação
ANO
PROFESSOR
RENDA
1990
Jean
19,000
1990
Marc
20,00
Tabela 08 - Relação rendimentos
Sem mais informações, suponha que é estimado por default que todo professor
não explicitamente representado ganha $ 22,000 em 1990. Dentro da OWA, desde que
nem todos os professores são conhecidos, nós precisamos introduzir na relação a tupla
(1990, *, 22,000), onde * denota um valor nulo default.
A introdução de informação default em banco de dados é muito importante.
Porque muitas aplicações trabalham com um grande número de parâmetros
desconhecidos.
37
6.4.3. VALORES ABERTOS
Um valor nulo aberto expressa um atributo de uma tupla que deve ser
interpretado dentro da Hipótese do Mundo Aberto: o valor do atributo pode não
existir, pode ter exatamente um valor ou vários valores. Em outras palavras, nenhuma
hipótese pode ser feita sobre os valores dos atributos. Na relação seguinte, o valor
nulo aberto expressa que a relação é fechada, exceto para o atributo estudante:
ESTUDANTE
DEPARTAMENTO
CURSO
Pierre
Biologia
Cálculo
Química
Álgebra
Tabela 09 - Relação que expressa um valor nulo aberto
Os seguintes fatos podem ser inferenciados: (1) existem apenas os
departamentos de Biologia e Química; (2) existem somente os cursos de Cálculo e
Álgebra; (3) o único estudante do departamento de biologia que estuda Cálculo é
Pierre; (4) podem existir um, vários ou nenhum estudante registrado no departamento
de Química que estuda Álgebra. Nenhum outro fato é verdadeiro nesta relação.
38
6.5. BANCO DE DADOS PROBABILÍSTICOS
Dois tipos diferentes de dados probabilísticos podem ser incluídos numa
relação: informação probabilística sobre associação de valores e informações
probabilísticas sobre valores de dados. Estes dois tipos de informações são
representadas com relações probabilísticas do tipo-1 e tipo-2.
Relações Probabilísticas do Tipo-1: Generaliza as relações clássicas com um
atributo suplementar WR(t) indicando a probabilidade que a tupla t pertence a relação
R. A probabilidade atribuída para uma tupla é independente de outras tuplas. Por
exemplo, seja a relação estuda ilustrada na tabela 10, cuja interpretação é a seguinte:
Martin realmente estuda Física, e a probabilidade dele estudar Biologia é 0.9. Assim, a
probabilidade de Martin estudar Biologia é de 0.1. Com a hipótese do mundo fechado,
qualquer par (estudante, curso) não explicitamente expressado na relação tem
probabilidade 0.
ESTUDANTE
CURSO
WR
Martin
Física
1.0
Martin
Biologia
0.9
John
Física
0.6
Tabela 10 - Relação probabilística do tipo-1
As relações do tipo-1 permite representar incertezas sobre os valores de dados
associados, suas capacidades de capturar incertezas em valores de dados é limitada.
Por esta razão a noção de conjunto probabilístico é necessário. Um conjunto
probabilístico em um universo U de discurso é definido com uma função de
distribuição de probabilidade WF [0, 1] satisfazendo u U WF(u) 1. Um conjunto
probabilístico F é escrito da forma:
F = {u1/W(u1), u2/W(u2), ..., un/W(un)}, onde cada un representa o valor do atributo da
relação e cada W(un) a probabilidade de un,
39
Por exemplo, se o curso estudado por John é representado pelo conjunto
probabilístico Cursos = {Álgebra/0.5, Cálculo/0.4}, então John é registrado em
Álgebra com probabilidade 0.5 e em Cálculo com probabilidade 0.4. Desde que o
somatório das probabilidades é igual a 0.9, então John não é registrado em nenhum
curso com probabilidade 0.1.
Relações Probabilísticas do Tipo-2: Estas relações tem atributos chaves que
são determinísticos, como nas relações clássicas. Assim cada tupla representa uma
entidade conhecida ou um relacionamento. Os outros atributos podem ser
determinísticos ou estocásticos. Estes últimos são descritos com ajuda dos conjuntos
probabilísticos. Um exemplo de uma relação probabilística pode ser vista na tabela 11.
ESTUDANTE
CURSO
John
Cálculo/0.4
Álgebra/0.5
Anne
Física/0.5
Cálculo/0.5
Tabela 11 - Relação probabilística do tipo-2
A semântica das relações probabilísticas do tipo-2 pode ser expressa em
termos de mundos possíveis como segue. Na tabela 11, a primeira tupla representa três
possibilidades: John estuda cálculo, John estuda álgebra, ou John não estuda curso
nenhum. A segunda tupla, desde que o somatório das probabilidades foi igual a 1,
então Annie estuda cálculo ou física.
40
7. CONCLUSÃO
Atualmente, os sistemas de banco de dados não estão designados a gerenciar
informações que são permeadas com incertezas. Dados incertos são armazenados
como valores nulos ou simplesmente excluídos do banco de dados, e usuários com
pedidos incertos podem usar consultas com modelos simples ou devem caminhar no
banco de dados para encontrar suas respostas.
Para prover soluções satisfatórias para as novas aplicações, como integração
de informação em ambientes multi-banco de dados, recuperação de imagens ou
inferência de valores desconhecidos, os sistemas de banco de dados do futuro deverão
incluir grandes capacidades para lhe dar com incertezas.
41
8. BIBLIOGRAFIA
KIM, Won
Modern Database Systems
Editora Addison Wesley, 1995
HULL, Richard; ABITEBOUL, Serge; VIANU, Serge
Foundations of Databases
Editora Addison-Wesley Publishing Company
ZANIOLO,
Carlo;
CERI,
Stefano;
FALOUTSOS,
Christos;
SNODGRASS, Richard T.; SUBRAHMANIAN, V. S.; ZICARI, Roberto
Advanced Database Systems
Editora Morgan Kaufmam Publishers, Inc.
MOTRO, Amihai; SMETS, Philippe
Gerenciamento de Incertezas em Sistemas de Banco de dados
Editora Kluwer Academic Publishers
42