Notas da Aula 2 - Fundamentos de Sistemas Operacionais
1. Ciclo de Vida de um Processo
Todo processo passa por 3 fases durante sua vida: criação, execução e término. Um processo
pode ser criado por outro processo ou pelo próprio sistema operacional. Por exemplo, quando
um usuário clica em um ícone de um programa em um menu, o processo que implementa o
menu faz uma requisição para a criação de um novo processo (relativo ao programa disparado
pelo usuário). Embora este seja o caso mais comum (um processo criando outro processo),
existem processos especiais no sistema que são criados diretamente pelo kernel do SO. Por
exemplo, no Linux existe o processo init, que é o primeiro processo disparado pelo SO durante
seu carregamento. O processo init, por sua vez, dispara outros processos de acordo com as
configurações do sistema.
Na prática, quem efetivamente cria o processo é sempre o Sistema Operacional. Quando um
processo deseja criar outro processo, ele precisa fazer uma chamada de sistema. Chamadas
de sistema comuns para a criação de novos processos incluem a fork(), a spawn() e a execv().
Ao ser criado, um processo recebe um pid (Process Identifier), um identificador numérico único
que serve para o controle interno do processo pelo SO e para o gerenciamento dos processos
pelos usuários.
A rotina criação de um processo funciona da seguinte forma. O Sistema Operacional recebe
o nome do arquivo que contém o programa a ser executado como parâmetro da chamada
de sistema. O SO verifica se o arquivo realmente existe. Caso exista, o Sistema Operacional
verifica o formato do arquivo. Cada Sistema Operacional utiliza um formato bem definido para
a representação de um programa, que contém, além das instruções a serem executadas, as
definições das variáveis utilizadas no programa (possivelmente incluindo valores iniciais) e
outras informações que possam ser relevantes. Caso o arquivo esteja no formato correto, o SO
aloca uma porção da memória para o novo processo. Esta porção de memória passa a ser o
espaço de endereçamento do processo, algumas vezes denominado de Imagem do Processo
em Memória.
A chamada fork() funciona de uma maneira um pouco diferente. Ao invés de criar um processo
com base nas informações de um arquivo executável, o SO faz uma cópia da imagem do
processo que chamou a função fork() e a coloca em uma outra parte da memória. Em outras
palavras, a imagem do processo que chama a função fork() é duplicada. O novo processo
criado utiliza esta cópia como seu espaço de endereçamento e herda do processo original
todo o estado atual de execução, incluindo os valores dos registradores. O resultado desta
operação, portanto, é a existência de dois processos idênticos (o original e a cópia recémcriada) em memória prontos para execução.
O processo original recebe como valor de retorno da função fork() o pid do processo criado.
Sua execução prossegue imediatamente após à chamada fork(). O processo criado, por sua
vez, começa a ser executado também imediatamente após a função fork(). Porém, para ele o
valor retornado pela chamada fork() é 0. A utilidade da função fork() é a possibilidade de um
processo criar uma cópia idêntica de si mesmo para que esta execute alguma outra tarefa
relacionada ao mesmo programa.
Uma vez que um processo esteja criado, ele passa para a fase de execução. Durante esta
fase, o processo pode executar dois tipos de ação: processamento ou E/S. A primeira ação
de um processo é sempre do tipo processamento, pois para realizar uma operação de E/S é
necessário executar um conjunto mínimo de instruções, especificando o dispositivo desejado,
bem como os parâmetros da operação.
A fase de execução de um processo, portanto, é basicamente uma alternância entre
processamento e E/S. Durante o processamento, um processo pode fazer uma chamada de
sistema, o que o leva a uma ação do tipo E/S. Enquanto esta ação de E/S é executada, uma
interrupção pode ser disparada, informando o fim da operação e fazendo com que o processo
alterne de volta para a ação do tipo processamento.
Existem alguns processos que, teoricamente, não terminam. Processos servidores por exemplo
(e.g., servidores web, servidores de e-mail) são projetados para ficar em um ciclo perpétuo de
execução, no qual eles aguardam requisições, atendem as requisições recebidas e voltam ao
estado original.
Na prática, no entanto, todo processo termina eventualmente. O término de um processo pode
ocorrer pelas seguintes razões:
● Término normal: a tarefa do processo foi concluída.
● Erros: houve algum erro na execução e o processo teve que ser abortado.
● Intervenção de outros processos ou usuários: o usuário ou algum outro processo
deliberadamente requisita ao SO que “mate” o processo.
● Falha de hardware: falta de luz, defeito, etc.
2. Tipos de Processos
Processos podem ser classificados de acordo com seu perfil de utilização do hardware. Um
processo é dito Intensivo em CPU (ou CPU Bound) se, em comparação com seu uso de
operações de E/S, seu uso de processador for muito grande. Em outras palavras, um processo
intensivo em CPU passa a maior parte do seu tempo de execução utilizando o processador.
De maneira similar, um processo é dito Intensivo em E/S (ou I/O Bound) caso seu uso de
operações de E/S seja muito maior que seu uso do processador.
Estas definições não são rigorosas, no sentido de que não há um percentual pré-determinado
de utilização de operações de E/S ou CPU que defina exatamente a classificação de um
dado processo. Por exemplo, processos que trabalham com grandes quantidades de cálculos
numéricos geralmente são classificados como CPU Bound, pois uma vez lidos os dados do
problema a ser resolvido, o processo trabalha quase exclusivamente executando instruções
no processador e manipulando dados em memória principal. Por outro lado, um programa que
realiza cópias de arquivos no disco é geralmente considerado I/O Bound, pois a maior parte
do tempo gasto na execução é aguardando que o disco rígido realize operações de leitura
e escrita. Para alguns processos, a classificação pode não ser tão clara, podendo variar de
acordo com o ponto de vista.
Na prática, a diferenciação entre processos CPU Bound e I/O Bound é importante, pois ela
define o que influencia no desempenho do processo. O desempenho de processos CPU Bound
em geral é influenciado quase exclusivamente pela velocidade de acesso à memória principal
e pelas características de desempenho do processador (frequência, tamanho da cache, etc).
Por outro lado, processos do tipo I/O Bound têm seu desempenho ligado a fatores como a
velocidade dos dispositivos de E/S acessados e velocidade dos barramentos do sistema.
3. Relacionamento Entre Processos
Dois processos diferentes podem ser independentes ou dependentes. Processos são ditos
independentes quando não há qualquer ligação entre eles. Processos podem ser dependentes
por dois motivos:
● eles têm um “grau de parentesco”; ou
● eles compartilham recursos.
Processos podem compartilhar recursos através de chamadas de sistema. Por exemplo,
dois processos podem requisitar ao SO uma área comum de memória para que eles se
comuniquem através de variáveis compartilhadas.
O tipo mais comum de relacionamento entre processos, no entanto, é o “grau de parentesco”.
Quando um processo A requisita ao SO que crie um novo processo B, diz-se que A é o
processo pai de B. De maneira análoga, B é um processo filho de A. Outros termos de
parentesco, como processo avó ou processo neto, são muitas vezes empregados.
Este relacionamento de processos pais e processos filhos cria uma organização lógica de
processos em uma hierarquia. No Linux, por exemplo, todo processo é filho de algum outro
processo, exceto pelo init, que é criado diretamente pelo SO. O processo init é responsável
por iniciar todas as aplicações básicas do sistema. Desta forma, no Linux, o init é a raiz da
hierarquia dos processos de aplicação.
Embora esta hierarquia não seja fundamental para o funcionamento do SO, muitos
sistemas procuram mantê-la pois ela pode tornar certas tarefas do sistema mais fáceis (ou
mais “limpas”). Por exemplo, no momento de desligamento da máquina, o sistema pode
percorer a hierarquia dos processos das folhas (processos mais baixos na hierarquia) até
a raiz, avisando os processos do encerramento. Para que esta hierarquia seja mantida, o
SO precisa definir uma política para manutenção para alterar a árvore quando um processo
termina. Se o processo terminado não for uma folha da hierarquia, o SO precisa decidir o que
fazer com os processos filhos. Algumas possíveis soluções incluem matar os processos filhos
e seus descendentes, fazer com que o processo avó “herde” os processos filhos, postergar o
términdo efetivo do processo até que todos os descendentes tenham terminado (o processo
não é executado, mas é mantido nas informações de gerenciamento do SO), ou simplesmente
deixar que os filhos se tornem “órfãos”, caso a hierarquia não seja fundamental para SO.
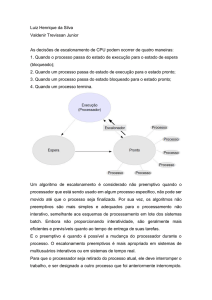
4. Estados de um Processo
Durante a fase de execução de um processo, ele pode alternar entre diversos estados. Em um
sistema multiprogramado, por exemplo, existem processos que estão usando o processador
(um único processo, caso a máquina seja monoprocessada) e existem processos que estão
aguardando a oportunidade de usar o processador. Há ainda processos que estavam utilizando
o processador, porém requisitaram uma operação de E/S e agora se encontram bloqueados,
aguardando o término da operação. Nota-se, portanto, que existem ao menos três estados de
um processo em um sistema:
● Estado executando: processo está atualmente utilizando o processador.
● Estado apto: processo está pronto para usar o processador, porém não está atualmente
em execução.
● Estado bloqueado: processo não pode atualmente utilizar o processador pois está
aguardando o término de uma operação de E/S.
Processos podem passar do estado executando para o estado bloqueado ao requisitarem uma
operação de E/S durante a execução. Uma transição do estado executando para o estado
apto pode ocorrer quando o slice de tempo do processo se esgota, por exemplo. Um processo
no estado apto pode passar para o estado executando quando o SO o escolhe para utilizar o
processador. A partir do estado bloqueado, um processo pode passar ao estado apto quando
sua operação de E/S termina. Note que, neste caso, uma transição direta para o estado
executando também seria possível, dependendo da política de escalonamento do SO.
Algumas transições são impossíveis. Por exemplo, um processo no estado apto não pode
passar diretamente para o estado bloqueado. Isso porque para chegar ao estado bloqueado
o processo precisa requisitar uma operação de E/S, o que requer que ele esteja no estado
executando.
Além destes três estados básicos, pode-se considerar também os estados criação e término.
Como discutido anteriormente, a criação de um processo consiste em uma série de etapas.
Logo, existe um tempo não desprezível entre o momento de requisição de criação de um
processo e o instante em que este processo passa a estar apto. Da mesma forma, o término de
um processo é composto por várias etapas, podendo também ser considerado um estado.
Há ainda a possibilidade de um processo não estar em nenhum dos 5 estados já mencionados.
Para um processo estar em execução ou apto para execução, ele necessariamente deve estar
carregado em memória principal (pois o processador precisa buscar as instruções em memória
principal para executá-las). No entanto, pode ocorrer de um processo do sistema não estar em
memória principal. Basicamente, isso ocorre por dois motivos:
1. Não há memória principal suficiente para acomodar o processo que está sendo criado
no momento. Neste caso, o SO pode decidir prosseguir com a criação do processo,
alocando a imagem do processo em uma área de memória secundária.
2. O processo estava em memória principal, mas para liberar memória (por exemplo, para
um novo processo) o SO decide retirá-lo da memória principal e colocá-lo em uma área
da memória secundária. Esta operação é conhecida como swap e será estudada em
detalhes no Capítulo 7.
Em ambos os casos, o processo colocado em memória secundária não pode ser executado.
Logo, ele não está nos estados apto nem executando. No primeiro caso, o processo também
certamente não está no estado bloqueado, já que ele foi recém-criado. Os estados criação e
término também não são opções. Este, portanto, é um novo estado, denominado suspenso.
Em outras palavras, um processo está no estado suspenso quando sua imagem é colocada em
memória secundária.
O estado suspenso às vezes é visto como dois estados separados: o apto suspenso e o
bloqueado suspenso. A diferença entre estes estados é simples. Um processo apto suspenso é
aquele que foi suspenso (colocado em memória secundária) quando estava no estado apto, ou
imediatamente após sua criação (o processo poderia começar a ser executado). Um processo
bloqueado suspenso é aquele que estava no estado bloqueado antes de ser suspenso.
Quando a operação de E/S requisitada por um processo no estado bloqueado suspenso
termina, este processo passa a estar apto suspenso. Por outro lado, é impossível um processo
apto suspenso passar diretamente para o estado bloqueado suspenso, já que seria necessário
que o processo passasse pelo estado executando para requisitar uma operação de E/S.
A utilidade de se dividir o estado suspenso em dois estados está na gerência do SO. Quando
um espaço de memória principal suficientemente grande para alocar um processo fica vago
(e.g., um processo em memória principal terminou sua execução), o SO pode escolher um
processo suspenso e colocá-lo em memória principal. Um critério razoável para escolha seria
evitar processos que estão suspensos porém ainda esperam pelo término de uma operação
de E/S. Um processo nestas condições não estaria apto a utilizar o processador, mesmo se
estivesse em memória principal. Logo, processos aptos suspensos são candidatos melhores a
serem trazidos para memória principal.
A existência ou não de transições entre cada um dos estados depende das necessidades e
capacidades do SO. Algumas transições são obrigatórias, como do estado apto para o estado
executando. Outras são impossíveis, como do estado bloqueado suspenso para o estado
apto. Porém há várias transições que são discutíveis. Ter mais transições significa uma maior
flexibilidade. Ao mesmo tempo, quando maior o número de transições, mais complexo é o
gerenciamento do SO.