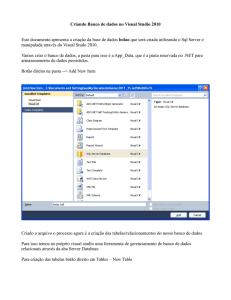
PLANO INTEGRADO DE TRANSPORTE URBANO
DA REGIÃO METROPOLITANA DE CAMPINAS
(PITU – CAMPINAS)
RELATÓRIO 3: BANCO DE DADOS E DIAGNÓSTICO DO SISTEMA
DE TRANSPORTE DA RMC
Volume 1 – Banco de Dados
Dezembro de 2004
Inscrição Estadual: Isento
CNPJ: 054.131.545/0001-66
Rua Abílio Vilela Junqueira, 951 – Guará – Campinas – SP - CEP 13085-040
: (0xx19) 3287-7822 (0xx19) 3287-7575 - e-mail: [email protected]
PLANO INTEGRADO DE TRANSPORTE URBANO DA REGIÃO
METROPOLITANA DE CAMPINAS (PITU – CAMPINAS)
RELATÓRIO 3 – VOLUME 1: BANCO DE DADOS
SUMÁRIO
1
APRESENTAÇÃO..................................................................................................... 2
2
ESQUEMA DO BANCO DE DADOS ..................................................................... 3
3
DICIONÁRIO DE DADOS ....................................................................................... 8
4
3.1
DADOS QUANTITATIVOS .................................................................................... 8
3.2
DADOS DESCRITIVOS ....................................................................................... 11
ARQUITETURA DO SISTEMA ............................................................................ 17
4.1
COMPONENTES DO SISTEMA ............................................................................ 17
4.2
QUESTÕES DE IMPLEMENTAÇÃO ..................................................................... 21
5
VISÕES DOS DADOS ............................................................................................. 22
6
CONCLUSÕES ........................................................................................................ 26
1
O Sistema de Banco de Dados para Suportar o Plano Integrado de Transportes da
Região Metropolitana de Campinas
1
APRESENTAÇÃO
O banco de dados é um componente fundamental para a elaboração do
Plano Integrado de Transportes (PITU) da Região Metropolitana de Campinas
(RMC). Ele armazena dados provenientes de diversas fontes (tais como Pesquisa
Origem-Destino, Censo do IBGE, Censo Escolar, Censo do Ensino Superior,
Pesquisa de Emprego do SEADE, Planos Diretores e Zoneamento Territorial dos
Municípios), em uma estrutura unificada. Além de promover a consistência, a
integridade, a segurança e facilitar o acesso aos dados nele armazenados, esse
banco de dados oferece recursos de software para facilitar a extração e a
formatação dos dados necessários às análises.
O banco de dados do PITU-RMC foi desenvolvido de modo a maximizar a
sua versatilidade, isto é, permitir o seu crescimento incremental, em termos de
fontes de dados a ele conectadas, valores de dados armazenados e software
para manipulação e análise de informação acoplados ao banco de dados. Tal
versatilidade permite ajustes a novos requisitos que sejam identificados ao longo
da elaboração e nas revisões do PITU.
Este documento apresenta a estrutura dos dados e a arquitetura dos
módulos do sistema de banco de dados do PITU-RMC. A Seção 2 apresenta o
esquema do banco de dados, no modelo entidade-relacionamento. A Seção 3
descreve os campos de dados de cada tabela do banco, em um dicionário de
dados. A Seção 4 apresenta a arquitetura geral do sistema e discute algumas
questões tecnológicas relacionadas à sua implementação. A Seção 5 apresenta
alguns extratos de dados obtidos do banco de dados. Finalmente, a Seção 6 faz
algumas considerações finais.
2
2
ESQUEMA DO BANCO DE DADOS
O esquema (estrutura geral) do banco de dados PITU-RMC segue o estilo
de modelagem estrela, próprio dos armazéns de dados (“data warehouses” em
inglês), dada a natureza desse banco, que integra dados de diversas fontes
heterogêneas, visando alimentar processos de análise de dados para subsidiar a
tomada de decisão. Na modelagem em estrela, as tabelas fato armazenam dados
quantitativos e as tabelas dimensão, conectadas às tabelas fato, armazenam
dados descritivos, os quais permitem discriminar os dados quantitativos presentes
nos registros das tabelas fato.
A Figura 1 apresenta o esquema do banco de dados do PITU-RMC no
modelo entidade-relacionamento. As tabelas fato desse diagrama são aquelas
que aparecem dentro de regiões retangulares, as quais indicam as fontes de
dados utilizadas para alimentar essas tabelas fato com os dados quantitativos. As
tabelas dimensão, por outro lado, contém dados qualitativos utilizados para
descrever os registros de dados das tabelas fato. Uma única tabela dimensão
pode discriminar registros de várias tabelas fato na respectiva dimensão. Por
exemplo, as tabelas das dimensões Espaço e Tempo descrevem as partições do
espaço e os períodos de tempo segundo os quais estão organizados os registros
de dados de todas as tabelas fato do diagrama. A referência de registros de
diferentes tabelas fato aos mesmos registros das tabelas dimensão contribui para
a formatação e a manipulação dos dados provenientes de diferentes fontes de
maneira unificada.
Para entender como os dados de diferentes fontes são integrados na
representação unificada e o funcionamento dos mecanismos para recuperação
eficiente de informação, é preciso analisar em detalhes a estrutura e o papel das
tabelas fato e das tabelas dimensão do diagrama ilustrado na Figura 1.
Primeiramente, vamos analisar as tabelas fato desse diagrama:
SocEcoDemo:
Contém
registros
de
dados
socioeconômicos
e
demográficos provenientes da Pesquisa Origem-Destino (Pesquisa OD),
dos Censos do IBGE e da Pesquisa Nacional de Domicílios (PNAD),
entre outras fontes que também poderão ser integradas no futuro. As
variáveis armazenadas nos registros dessa tabela são o número de
pessoas, famílias, domicílios e veículos, além da renda média das
3
famílias e dos chefes de família. Os registros dessa tabela são
organizados de modo a agregar os dados quantitativos (efetuar somas,
médias e cálculos afins com as variáveis da tabela), segundo diferentes
partições do espaço (por exemplo, estado, cidade, bairro, zona de
tráfego e setor censitário), diferentes períodos de tempo, além das
características das pessoas, dos domicílios e dos veículos que essas
pessoas possam possuir.
4
Figura 1
O esquema do banco de dados PITU-RMC
Viagens: Contém registros de viagens dentro da região metropolitana de
Campinas, oriundos da pesquisa origem destino. Esses registros são
organizados na dimensão espaço (notadamente com agregação em
Zona de Tráfego, também conhecida como Zona OD), períodos de
5
tempo em que essas viagens são realizadas (ano, mês, dia do mês, dia
da semana e horário) e modos de transporte utilizados nessas viagens.
Emprego: Contém registros da Pesquisa de Emprego do SEADE, com
número de vagas e salário, organizados nas dimensões tempo, espaço e
setores econômicos (tais como agricultura, indústria, comércio e
serviços, além dos respectivos sub-setores).
MatrículaEscolar: Fornece os números de matrículas, obtidos do Censo
Escolar e do Censo do Ensino Superior, segundo períodos de tempo
(matutino, vespertino e noturno ao longo dos anos), partições do espaço
e nível de ensino (fundamental, médio e superior).
UsoSolo: Descreve o uso do solo nas diversas áreas ao longo do
tempo, fornecendo a área total para cada tipo de uso (por exemplo,
agricultura, indústrias, comércio, residências, áreas de preservação
ambiental, parques e jardins) e o valor médio do metro quadrado de
terreno.
Agora, considere a estrutura e o papel das tabelas dimensão no diagrama
ilustrado na Figura 1. Os campos de cada tabela dimensão descrevem classes ou
hierarquias para discriminar os dados quantitativos contidos nas tabelas fato. Por
exemplo, a tabela dimensão Pessoa contém vários campos (colunas) para
descrever os atributos das pessoas (sexo, raça, faixa etária, faixa de renda
familiar, condição de atividade, vínculo empregatício, setor econômico do
emprego, nível de educação e tipo de domicílio). Como esses atributos são
potencialmente ortogonais (sexo é independente de raça, por exemplo), esses
atributos não definem uma hierarquia para o conjunto de pessoas, mas
simplesmente um conjunto de atributos para caracterizá-las. Na tabela Espaço,
por outro lado, há várias relações de pertinência entre os campos (colunas da
tabela). Por exemplo, uma unidade da federação (UF) inclui diversos municípios,
que por sua vez podem incluir macro zonas, bairros, zonas de tráfego e assim por
diante.
Os campos das tabelas dimensão selecionar e agregar dados quantitativos
dos registros das tabelas fato, de acordo com classes (e.g., determinadas por
atributos das pessoas) e hierarquias (e.g., de Tempo e Espaço). Um exemplo de
consulta que pode ser efetuada utilizando este mecanismo é “Obter da tabela de
dados socioeconômicos e demográficos somente o número de pessoas com
6
renda familiar maior que um certo valor, em cada zona de tráfego de um dado
município”. Os dados quantitativos podem ser alternativamente selecionados e
agregados por outros valores descritivos das tabelas dimensão.
Nas dimensões onde haja hierarquias, tais como espaço e tempo, é
desejável que se mantenha relações de pertinência, para que dados agregados
em níveis mais altos da hierarquia possam ser obtidos a partir de dados
agregados em níveis mais baixos (por exemplo, somar a população de todas as
zonas de tráfego de um município, para obter a população do município).
A existência de um dado campo em uma tabela dimensão associada a uma
dada tabela fato, não significa que tal tabela fato tenha necessariamente dados
até o nível de agregação mínimo definido pela respectiva dimensão. O nível de
agregação
mínimo
para
cada
campo
quantitativo
é
determinado
pela
disponibilidade de informação detalhada na fonte de dados e pelas necessidades
da aplicação.
Finalmente, note que há algumas ligações implícitas entre as tabelas do
diagrama ilustrado na Figura 1. Os campos id_setor_emprego e id_nivel_escolar
da tabela Pessoa são chaves estrangeiras das tabelas SetorEconomico e
NivelEscolar, respectivamente. Analogamente, o campo id_fonte aparece como
chave estrangeira em cada uma das tabelas fato, com o intuito de identificar as
fontes de cada um dos registros de dados quantitativos e a data da última
atualização dessas fontes.
A próxima seção descreve em detalhes todos os campos (colunas) das
tabelas do diagrama da Figura 1 e os possíveis valores para esses campos.
7
3
DICIONÁRIO DE DADOS
O dicionário de dados do banco de dados PITU-RMC está dividido em duas
partes: especificações dos dados quantitativos das tabelas fato e especificações
dos dados descritivos das tabelas dimensão. Cada uma dessas seções inclui a
especificação de todos campos (colunas) das respectivas tabelas 1. Para cada
campo de cada tabela, o dicionário de dados define:
Coluna: Nome do campo (coluna) presente na tabela.
Tipo: Tipo de dado do campo.
Chave Primária: A chave primária de uma tabela é um conjunto de
campos que identificam unicamente cada registro (linha) da tabela. Uma
marca (X) no item chave primária para um dado campo de uma tabela
indica que o campo faz parte da chave primária da tabela.
Não Nulo: Uma marca (X) nesse item indica que o banco de dados não
permite o armazenamento de valor nulo para o campo.
Restrições: Pode especificar alguma restrição nos valores possíveis
para o campo, como por exemplo, sem sinal (isto é, maior ou igual a
zero) ou diferente de zero.
Valor pré-definido (default): Prescreve um valor pré-definido para o
sistema de gerenciamento de banco de dados inserir no campo caso o
usuário tente inserir um registro com valor nulo naquele campo.
Descrição: Define o significado, a unidade de medida e/ou os valores
possíveis do campo.
Auto Incremento: Uma marca (X) nesse item instrui o banco de dados a
gerar valores incrementais para o campo.
3.1
DADOS QUANTITATIVOS
A Figura 2 descreve os campos das tabelas fato. Os registros das tabelas
fato fazem referência aos registros das tabelas dimensão aos quais eles se
referem, através de chaves estrangeiras. As chaves primárias das tabelas fato
1
Acentos e termos compostos (separados por espaços) não são utilizados em nomes de tabelas e campos
para evitar problemas na geração física do esquema no catálogo de sistemas de gerenciamento de bancos
de dados.
8
são constituídas dessas chaves estrangeiras, cujos nomes e tipos dos campos
aparecem em negrito. Além da chave primária, as tabelas fato têm um índice
auxiliar para cada chave estrangeira, usado para agilizar o acesso pelo respectivo
campo. As fontes de dados de cada tabela são indicadas em itálico, antes do
nome da tabela.
Figura 2
Especificações dos campos das tabelas fato (dados quantitativos)
Tabelas Fato (Dados Quantitativos)
Pesquisa OD, Censo IBGE, PNAD
DadosSocioEconomicos
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_espaco
INTEGER
X
X
SEM SINAL
(ver tabela Espaço)
id_tempo
INTEGER
X
X
SEM SINAL
(ver tabela Tempo)
id_pessoa
INTEGER
X
X
SEM SINAL
(ver tabela Pessoa)
id_veiculo
INTEGER
X
X
SEM SINAL
(ver tabela Veículo)
id_fonte
INTEGER
X
X
SEM SINAL
(ver tabela FonteDados)
nr_pessoas
FLOAT
Número de pessoas
nr_familias
FLOAT
Número de famílias
nr_domicilios
FLOAT
Número de domicílios
nr_veiculos
FLOAT
Número de veículos
renda_media_familiar
FLOAT
Renda média familiar
renda_media_chefe_familia
FLOAT
Renda media do chefe da
família
Descrição
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_espaco
id_tempo
id_pessoa
id_veiculo
id_fonte
CensoIBGE_FKIndex1
Index
id_pessoa
CensoIBGE_FKIndex2
Index
id_veiculo
CensoIBGE_FKIndex3
Index
id_espaco
CensoIBGE_FKIndex4
Index
id_tempo
DadosSocioEconomicos_FKIndex5
Index
id_fonte
Auto
Incremento
9
Pesquisa OD
Viagens
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_origem
INTEGER
X
X
SEM SINAL
(id_espaco da tabela
Espaço)
id_destino
INTEGER
X
X
SEM SINAL
(id_espaco da tabela
Espaço)
id_tempo
INTEGER
X
X
SEM SINAL
(ver tabela Tempo)
id_pessoa
INTEGER
X
X
SEM SINAL
(ver tabela Pessoa)
id_modo_transp
INTEGER
X
X
SEM SINAL
(ver tabela ModoTransp)
id_fonte
INTEGER
X
X
SEM SINAL
(ver tabela FonteDados)
nr_viagens
FLOAT
Número de viagens
Tempo_médio_viagens
FLOAT
Tempo médio de viagem
custo_viagens
FLOAT
Custo das viagens
Descrição
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_origem
id_destino
id_tempo
id_modo_transp
id_fonte
PesquisaOD_FKIndex1
Index
id_origem
PesquisaOD_FKIndex2
Index
id_destino
PesquisaOD_FKIndex3
Index
id_tempo
Viagens_FKIndex4
Index
id_modo_transp
Viagens_FKIndex5
Index
id_fonte
Auto
Incremento
Pesquisa SEADE
Emprego
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_espaco
INTEGER
X
X
SEM SINAL
(ver tabela Espaço)
id_tempo
INTEGER
X
X
SEM SINAL
(ver da tabela Tempo)
id_setor
INTEGER
X
X
SEM SINAL
(ver tabela
SetorEconômicoo)
id_fonte
INTEGER
X
X
SEM SINAL
(ver tabela FonteDados)
nr_vagas
FLOAT
Número de vagas
salario
FLOAT
Salário pago
Descrição
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_espaco
id_tempo
id_setor
id_fonte
PesqEmpresas_FKIndex1
Index
id_tempo
PesqEmpresas_FKIndex2
Index
id_setor
PesqEmpresas_FKIndex3
Index
id_espaco
Emprego_FKIndex4
Index
id_fonte
Auto
Incremento
10
Censo Escolar, Censo do Ensino Superior
MatriculaEscolar
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_tempo
INTEGER
X
X
SEM SINAL
(ver tabela Tempo)
id_nivel_escolar
INTEGER
X
X
SEM SINAL
(ver da tabela
NívelEscolar)
id_fonte
INTEGER
X
X
SEM SINAL
(ver tabela FonteDados)
nr_matriculas
FLOAT
Descrição
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_espaco
id_tempo
id_nivel_escolar
id_fonte
CensoEscolar_FKIndex2
Index
id_tempo
MatriculaEscolar_FKIndex2
Index
id_espaco
MatriculaEscolar_FKIndex3
Index
id_nivel_escolar
MatriculaEscolar_FKIndex4
Index
id_fonte
Auto
Incremento
Planos Diretores, Zoneamento, Mercado Imobiliário
UsoSolo
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_espaco
INTEGER
X
X
SEM SINAL
(ver tabela Espaço)
id_tempo
INTEGER
X
X
SEM SINAL
(ver da tabela Tempo)
id_tipo_uso
INTEGER
X
X
SEM SINAL
(ver tabela TipoUsoSolo)
id_fonte
INTEGER
X
X
SEM SINAL
(ver tabela FonteDados)
area
FLOAT
Área em metros quadrados
valor_medio_do_m2
FLOAT
Valor médio do metro
quadrado de terreno em
reais
Descrição
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_espaco
id_tempo
id_tipo_uso
id_fonte
UsoSolo_FKIndex1
Index
id_espaco
UsoSolo_FKIndex2
Index
id_tempo
UsoSolo_FKIndex3
Index
id_fonte
UsoSolo_FKIndex4
Index
id_tipo_uso
3.2
Auto
Incremento
DADOS DESCRITIVOS
As tabelas dimensão mantêm os dados descritivos utilizados para
discriminar, selecionar e agregar dados quantitativos armazenados nas tabelas
11
fato. Cada tabela dimensão tem uma chave primária para identificar unicamente
cada um de seus registros. Utiliza-se auto-incremento nas chaves primárias das
tabelas fato para facilitar a inserção de registros. Os campos descritivos devem
assumir valores bem definidos, descritos abaixo na Figura 3.
Figura 3
Especificações dos campos das tabelas dimensão (dados descritivos)
Tabelas Dimensão (Dados Descritivos)
Espaco
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
Descrição
Auto
Incremento
id_espaco
INTEGER
X
X
SEM SINAL
Identificador de registro
AI
UF
CHAR(2)
X
e.g. SP
T=Total
municipio
VARCHAR
X
e.g. Campinas
T=Total
macro_zona
VARCHAR
X
e.g. Barão Geraldo
T=Total
bairro
VARCHAR
X
e.g. Cidade Universitária
T=Total
zona_trafego
VARCHAR
X
Equivalente a Zona_OD
T=Total
area_ponderacao
VARCHAR
X
T=Total
setor_censitario
VARCHAR
X
T=Total
CEP
CHAR(8)
X
T=Total
endereco
VARCHAR
X
Nome da rua + número +
complemento
T=Total
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_espaco
Obs: Seqüências de pontos geográficos delimitando as parcelas ou regiões são associadas a cada valor dos campos desta
tabela de partições do espaço no banco de dados geográfico.
12
Tempo
Valor prédefinido
(default)
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_tempo
INTEGER
X
X
SEM SINAL
ano
CHAR(4)
X
mes
CHAR(2)
X
SEM SINAL
T=Total
dia_mes
CHAR(2)
X
SEM SINAL
T=Total
SEM SINAL
1=domingo
2=segunda-feira
3=terça-feira
4=quarta-feira
5=quinta-feira
6=sexta-feira
7=sábado
T=Total
dia_sem
CHAR(1)
X
horario
VARCHAR
X
Descrição
Auto
Incremento
Identificador de registro
X
T=Total
e.g., 7:00 às 8:00 horas
T=Total
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_tempo
Pessoa
Coluna
Tipo
Chave
Primária
Não
Nulo
id_pessoa
INTEGER
X
sexo
raca
CHAR
CHAR
Valor prédefinido
(default)
Descrição
Auto
Incremento
X
Chave primária
X
X
M = Masculino
F = Feminino
T = Total
X
2 = branca
4 = preta
6 = amarela
8 = parda
0 = indígena
9 = ignorada
T = Total
Restrições
e.g,
faixa_etaria
VARCHAR
X
até 3 anos,
4 a 6 anos,
7 a 10 anos,
11 a 14 anos,
15 a 17 anos,
18 a 22 anos,
23 a 29 anos,
30 a 39 anos,
40 a 49 anos,
50 a 59 anos,
60 anos ou mais
T = Total
e.g.,
faixa_renda_familiar
VARCHAR
até R$ 480
maior que R$ 480
e até R$ 960
maior que R$ 960
e até R$ 1920
maior que R$
1920 e até R$
3600
maior que R$
3600 e até R$
7200
maior que R$
7200
não declarado
X
T = Total
condicao_atividade
VARCHAR
X
e.g.,
13
tem trabalho
faz bico
em licença
aposentado /
pensionista
sem trabalho
nunca trabalho
dona de casa
estudante
T = Total
e.g.,
vinculo_emprego
VARCHAR
X
id_setor_emprego
INTEGER
X
SEM SINAL
id_nivel_escolar
INTEGER
X
SEM SINAL
tipo_domicilio
CHAR
X
assalariado com
carteira
assalariado sem
carteira
funcionário público
autônomo
empregador
profissional liberal
trabalhador
doméstico com
carteira
trabalhador
doméstico sem
carteira
dono de negócio
familiar
trabalhador
familiar
não se aplica
T = Total
(ver tabela
SetorEconomico)
(ver tabela NivelEscolar)
P = Particular
C = Coletivo
F = Favela
T = Total
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_pessoa
Pessoa_FKIndex1
Index
id_setor_emprego
Pessoa_FKIndex2
Index
id_nivel_escolar
Veiculo
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_veiculo
INTEGER
X
X
SEM SINAL
Valor prédefinido
(default)
Descrição
Auto
Incremento
Identificador de registro
X
e.g.,
tipo
CHAR
P = Passeio
C = Coletivo
O = Outros
X
T = Todos
e.g.,
combustivel
CHAR
X
G = Gasolina
A = Álcool
D = Diesel
F = Flexível (álcool
ou gasolina)
O = Outros
T = Todos
nr_passageiros
INTEGER
X
Capacidade do veículo em
número de passageiros
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_veiculo
14
ModoTransporte
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_modo_transp
INTEGER
X
X
SEM SINAL
Valor prédefinido
(default)
Descrição
Auto
Incremento
X
e.g.,
nome_modo_transp
VARCHAR
X
ônibus,
fretado,
escolar,
automóvel
(dirigindo),
automóvel
(passageiro),
táxi,
lotação,
moto,
bicicleta,
a pé,
outros
T = Todos
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_modo_transp
SetorEconomico
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_setor
INTEGER
X
X
SEM SINAL
nivel_setor
CHAR
X
Valor prédefinido
(default)
Descrição
Auto
Incremento
Identificador de registro
AI
1 = Primário
2 = Secundário
3 = Terciário
T = Todos
e.g.,
nome_setor
VARCHAR
X
agricultura
indústria
comércio
serviços
T = Todos
e.g.,
sub_setor
VARCHAR
X
serviços de
transporte de
carga
serviços de
transporte de
passageiros
serviços creditícios
/ financeiros
serviços pessoais
serviços de
alimentação
serviços de saúde
serviços de
educação
serviços
especializados
serviços de
administração
pública
outros
T = Todos
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_setor
15
NivelEscolar
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_nivel_escolar
INTEGER
X
X
SEM SINAL
Valor prédefinido
(default)
Descrição
Auto
Incremento
Identificador de registro
X
e.g.,
nome_nivel_escolar
VARCHAR
Analfabeto ou 1o.
grau incompleto
1º. grau completo
ou 2º. grau
incompleto
Ensino médio
completo ou
superior
incompleto
Superior completo
X
T = Todos
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_nivel_escolar
TipoUsoSolo
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_tipo_uso
INTEGER
X
X
SEM SINAL
Valor prédefinido
(default)
Descrição
Auto
Incremento
Identificador de registro
X
e.g.,
nome_tipo_uso
INTEGER
X
Agricultura
Equipamentos
industriais
Equipamentos
comerciais
Equipamentos de
serviços
Área residencial
Áreas de
preservação
ambiental
Parques e jardins
SEM SINAL
T = Todos
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_tipo_uso
FonteDados
Coluna
Tipo
Chave
Primária
Não
Nulo
Restrições
id_fonte
INTEGER
X
X
SEM SINAL
Valor prédefinido
(default)
Descrição
Auto
Incremento
Identificador de registro
X
e.g.,
nome_fonte
VARCHAR
descr_fonte
VARCHAR
data_atualizacao
DATE
X
Pesquisa OD 2003
Censo IBGE 2001
Descrição da fonte de
dados
X
Data da última atualização
dos dados da fonte
Nome do Índice
Tipo do Índice
Colunas
PRIMARY
PRIMARY
id_fonte
16
4
ARQUITETURA DO SISTEMA
A arquitetura geral do sistema de banco de dados do PITU-RMC, ilustrada
na Figura 4, mostra os principais módulos deste sistema e como eles se interrelacionam, em termos de fluxo de informação. A concepção dessa arquitetura, da
mesma forma que o esquema do banco de dados enfatiza a flexibilidade do
sistema para se ajustar aos requisitos do projeto PITU-RMC, ao longo de sua
evolução, desde os primeiros experimentos com o Tranus até as revisões
periódicas do plano. A flexibilidade e a generalidade do banco de dados e do
sistema como um todo, além de contribuir para alcançar os objetivos do PITU com
eficiência e qualidade, permite que outros projetos e aplicações venham a se
beneficiar deste esforço de coleta, organização e integração de dados.
4.1
COMPONENTES DO SISTEMA
O sistema de banco de dados do PITU-RMC possui dois módulos de
gerenciamento de dados: um Sistema de Banco de Dados Relacional (SGBD) e
um Sistema de Informação Geográfica (SIG). O SGBD relacional mantém dois
repositórios de dados: o Catálogo de Metadados e o Armazém de Dados (cujo
esquema foi descrito nas Seções 2 e 3 desse documento). As funções desses
repositórios são catalogar as fontes de dados e prover acesso unificado aos
dados mais utilizados, respectivamente. O SIG, que por requisitos do Tranus é o
MapInfo, também inclui dois repositórios de dados: Dados Tabulares e Dados
Geográficos. Dados Tabulares podem ser importados do Armazém de Dados ou
de fontes diversas, incluindo outros SIGs. Dados Geográficos incluem mapas e
imagens de satélites.
17
Figura 4
A arquitetura geral do sistema de Banco de Dados do PITU-RMC
Aplicações e Projetos
Projeto
XYZ
Usuário
DemEcon
Pesquisa de Fontes
e Metadados
Catálogo de
Fontes e
Metadados
Tranus
Usuário
MapInfo
Relatórios e Análises On-Line
PITU
Consultas Geográficas
Dados
Tabulares
Armazém
de Dados
Data Marts
Dados
Gráficos
Sistema de Gerenciamento de Banco de Dados - SGBD
Sistema de Informação
Geográfica - SIG
(MapInfo)
Catalogação, extração, limpeza, transformação, carga e renovação
Conversão
Censo
IBGE
Pesq.
OD
Pesq.
SEADE
Censo . . .
Escolar
base
XYZ
fontes de dados integradas ao sistema
outras fontes
outros SIGs
Os dados das fontes externas precisam passar por processos de
transformação para serem incorporados aos repositórios do SGBD relacional e do
SIG. Uma vez colocados nesses repositórios, tais dados podem ser recuperados
e analisados utilizando o ferramental acoplado a cada um dos repositórios:
Pesquisa de Fontes e Metadados, Relatórios e Análise On-Line e Consultas
Geográficas. Esses módulos permitem que o PITU e outros projetos futuros se
beneficiem da integração e facilidades para efetuar consultas sobre os dados
integrados. Isso não impede que os dados sejam também acessados diretamente
das fontes, quando essas apresentarem formatação e recursos de acesso
adequados aos projetos. Isso é representado pela seta saindo da coleção de
fontes de dados (retângulo na porção inferior da Figura 4) e em direção às
aplicações e projetos (retângulo na porção superior da mesma figura). Os
resultados de (uma fase de) um projeto podem ser empacotados, catalogados e
feitos disponíveis para reutilização, como fontes de dados para outros projetos, de
modo a garantir o fechamento do ciclo de coleta, transformação e análise de
dados necessários para subsidiar processos decisórios. Isso é representado pela
seta saindo de projetos e aplicações para realimentar as fontes de dados.
18
A definição e o papel de cada um dos componentes do sistema de banco
de dados do PITU-RMC são detalhados a seguir.
4.1.1 Fontes de Dados
As Fontes de Dados socioeconômicos, demográficos, de uso do solo e de
transportes necessárias para alimentar as análises do PITU-RMC são muito
variadas tanto em termos de conteúdo quanto de estrutura. Por exemplo, dados
socioeconômicos e demográficos podem ser obtidos dos Censos do IBGE e das
estimativas apuradas na Pesquisa Origem-Destino (Pesquisa OD). Embora essas
fontes tenham sobreposição, existem dados que só aparecem em uma delas,
como, por exemplo, os dados de viagens, que só aparecem na Pesquisa OD.
Além disso, fontes distintas podem cobrir diferentes períodos de tempo e porções
do território.
Os dados de algumas fontes, tais como a Pesquisa OD e os Censos do
IBGE, dada a sua importância e uso freqüente, passam por um processo de
transformação para carga no armazém de dados, a fim de facilitar os acessos
posteriores aos mesmos. Outras fontes menos importantes, menos utilizadas ou
cujo trabalho de transformação resulte em custos superiores aos benefícios de ter
seus dados com fácil acesso facilitado pelo armazém de dados serão apenas
catalogadas, para permitir sua identificação e localização. O acesso a essas
bases não integradas ao armazém de dados é feito através de conexão direta
com as aplicações ou projetos que as utilizam. Dados geográficos oriundos de
outros SIGs podem ser incorporados aos repositórios do MapInfo através de
processos de conversão.
4.1.2 Catálogo de Fontes e Metadados
O Catálogo de Fontes e Metadados armazena descrições das fontes de
dados e seus conteúdos, para suportar a identificação e a localização de fontes e
resultados de projetos que possam ser úteis ao PITU-RMC e outros projetos
futuros. Para cada fonte são armazenados os seguintes descritores:
Nome da fonte de dados
Palavras chave para busca
Autor(es) ou instituição responsável, incluindo dados para contato
Descrição da fonte
19
Conjunto de variáveis disponíveis
Cobertura temporal e espacial dos dados
Formato dos dados e unidades de medida
Software utilizado para ler os dados
Localização física e lógica (e.g., URL) da fonte de dados
Indicadores da qualidade dos dados (tais como correção e precisão)
A gerência desses dados é feita através de um Sistema de Gerenciamento
de Banco de Dados (SGBD). Uma interface de consulta permite aos usuários
realizar suas buscas sobre esse catálogo com facilidade.
4.1.3 Armazém de Dados
A Armazém de Dados é o repositório que permite acesso unificado aos
dados mais utilizados, de acordo com o esquema de banco de dados descrito em
detalhes nas Seções 2 e 3 deste documento. Esses dados provêm de fontes
diversas e heterogêneas. Portanto, precisam passar por um processo de
extração, transformação e limpeza para serem carregados no armazém de dados,
o qual constitui uma visão materializada e integrada de diversas fontes de dados.
Os dados do armazém são gerenciados por um SGBD (o mesmo que gerencia os
dados do Catálogo de Fontes e Metadados). Consultas ao armazém de dados
podem ser feitas utilizando a linguagem SQL, relatórios previamente preparados,
um gerador de relatórios ou processamento analítico on-line (OLAP – On-Line
Analytical Processing).
4.1.4 Sistema de Informação Geográfica
O
Sistema
de
Informação
Geográfica
(SIG) é
responsável pela
manipulação de dados tabulares georreferenciados, mapas e imagens de satélite,
além de ser uma importante interface de comunicação com o Tranus. O SIG
utilizado no sistema de banco de dados do PITU-RMC é o MapInfo (requisito do
próprio Tranus).
4.1.5 Aplicações e Projetos
O PITU-RMC é o cliente primário do sistema de banco de dados aqui
descrito. Toda a especificação desse sistema está voltada para o atendimento
20
das necessidades do PITU-RMC. Todavia, outros projetos e aplicações futuros,
que requeiram dados socioeconômico, demográficos, de transportes e de uso do
solo, podem se beneficiar da disponibilidade do Catálogo de Fontes e Metadados
e do Armazém de Dados construídos para o PITU-RMC.
4.2
QUESTÕES DE IMPLEMENTAÇÃO
O Sistema de Gerenciamento de Banco de Dados (SGBD) utilizado para
gerenciar os dados do Catálogo de Fontes e Metadados e do Armazém de Dados,
na primeira versão do sistema de banco de dados do PITU-RMC, é o Access. No
entanto, dado o grande volume de dados e a necessidade de efetuar consultas
pesadas, já está sendo providenciado um servidor mais possante e uma licença
do SQL-Server, que inclui software para processamento analítico on-line. Assim,
deve-se aumentar a eficiência e a interatividade das consultas. Uma vez que os
esquemas de bancos de dados foram desenvolvidos com técnicas e ferramental
adequado, inclusive ferramentas CASE, a migração de plataforma será facilitada.
A escolha de uma plataforma proprietária se deve unicamente à cultura já
estabelecida na instituição responsável pela operação do banco de dados. Esta
opção visa preservar o investimento já realizado pela instituição em software,
equipamentos e treinamento da equipe de suporte, além de promover a operação
e a manutenção adequadas do sistema dentro da realidade da instituição.
21
5
VISÕES DOS DADOS
O banco de dados do PITU-RMC permite manipular os dados provenientes
de diversas fontes em uma estrutura unificada, de modo a permitir manipulação e
análises desses dados em conjunto. Esta seção apresenta algumas visões de
dados (resultados de consultas) obtidas do banco de dados PITU-RMC, com a
finalidade de ilustrar o tipo de informação que pode ser recuperada. Cabe
salientar que essas visões dos dados podem ser obtidas com muita facilidade e
flexibilidade, através de consultas SQL, geração de relatórios ou processamento
analítico on-line, sobre o banco de dados cujo esquema foi descrito nas Seções 2
e 3 deste documento. As figuras abaixo ilustram algumas visões obtidas do banco
de dados do PITU-RMC.
Tabela 1
Uma visão dos dados socioeconômicos - renda versus instrução por município
Município
Grau de Instrução
Renda
Média
Familiar
Popul.
R$ 1.490
Fundam.
Incompl.
Fundam.
Completo
188.470
50,83%
R$ 925
30.916
Campinas
R$ 1.405
Cosmópolis
Médio
Sup.
18,37%
23,75%
7,05%
68,08%
16,10%
12,43%
3,39%
943.572
48,87%
18,06%
23,92%
9,15%
R$ 1.068
45.238
63,27%
17,46%
16,55%
2,72%
R$ 758
7.168
76,27%
12,03%
9,81%
1,90%
R$ 1.162
3.847
53,82%
16,73%
18,18%
11,27%
R$ 875
169.561
58,92%
20,09%
19,50%
1,48%
Indaiatuba
R$ 1.381
133.989
54,63%
18,76%
20,98%
5,63%
Itatiba
R$ 1.147
70.455
60,70%
15,89%
18,23%
5,18%
Jaguariúna
R$ 1.163
23.048
49,68%
14,24%
25,63%
10,44%
Monte Mor
R$ 810
32.245
64,48%
19,06%
13,86%
2,59%
Nova Odessa
R$ 1.191
40.457
52,64%
22,69%
22,69%
1,98%
Paulínia
R$ 1.018
15.027
55,91%
23,32%
18,85%
1,92%
Pedreira
R$ 1.143
29.478
59,08%
20,20%
16,62%
4,09%
Sta Bárbara D'Oeste
R$ 1.153
172.291
55,11%
20,33%
21,14%
3,41%
Sto Antônio de Posse
R$ 1.111
15.275
68,84%
13,04%
11,96%
6,16%
Sumaré
R$ 1.057
234.858
60,06%
18,91%
18,31%
2,71%
Valinhos
R$ 1.217
75.387
55,64%
16,91%
22,30%
5,15%
Vinhedo
R$ 1.511
49.443
53,87%
17,51%
20,37%
8,25%
Americana
Artur Nogueira
Engº Coelho
Holambra
Hortolândia
22
A Tabela 1 apresenta a relação dos municípios da Região Metropolitana de
Campinas, com a renda média familiar, a população e o percentual da população
com diferentes níveis de instrução para cada um desses municípios. Esta tabela é
obtida mediante a execução de uma consulta SQL sobre o esquema de banco de
dados ilustrado na Figura 1. Tal consulta utiliza a tabela fato SocEcoDemo (dados
socioeconômicos e demográficos) para extrair todos os valores de dados
quantitativos apresentados. A tabela dimensão Pessoa é utilizada para gerar os
dados descritivos das faixas de renda que aparecem no cabeçalho da tabela da
Tabela 1 e agrupar os dados quantitativos nas respectivas colunas. A tabela
dimensão Espaço é utilizada para agregar os dados por município.
23
Tabela 2
Viagens por modalidade e faixa de renda na RMC
Faixa de Renda (em reais)
Modo Principal
Ônibus
até 480
480,01 a
960
960,01 a
1920
1920,01 a
3600
3600,01 a
7200
> 7200
Não
Declarada
Total
52.592
135.829
179.080
63.828
13.129
1.964
260.829
707.252
Ônibus Fretado
5.367
26.271
48.079
21.526
2.788
104
60.329
164.464
Escolar
7.185
18.703
24.360
15.015
5.178
358
44.339
115.138
Dirigindo Auto
16.556
55.648
136.862
131.260
61.302
15.235
305.881
722.743
Passageiro Auto
18.171
38.153
62.419
57.389
21.449
5.737
121.791
325.109
446
272
466
884
521
263
839
3.690
Lotação/ Perua
4.489
8.146
8.665
2.773
515
74
12.388
37.049
Moto
2.659
12.578
26.714
13.682
2.695
29.015
87.345
Bicicleta
8.144
27.634
36.704
8.982
295
112
41.463
123.334
171.522
298.282
311.036
88.951
23.243
4.869
393.707
1.291.611
1.494
4.691
5.647
3.355
658
8.656
24.502
288.626
626.207
840.031
407.645
131.774
1.279.237
3.602.236
Táxi
A Pé
Outros
Total
28.717
24
A Tabela 2 apresenta o número de viagens realizadas por indivíduos de
diversas faixas de renda, utilizando diferentes modos de transporte. Esta tabela
também é obtida através de uma consulta SQL sobre o esquema de banco de
dados ilustrado na Figura 1. Tal consulta utiliza a tabela Viagens para extrair os
dados quantitativos apresentados, a tabela Pessoa para discriminar as faixa de
renda e a tabela ModoTransporte para agregar os dados quantitativos por modo
de locomoção. As células vazias indicam ausência de dados para os
discriminantes (rótulos das respectivas linhas e colunas).
Consultas correlacionando dados quantitativos de mais de uma tabela fato
também podem ser realizadas com facilidade e tempo de execução um pouco
maior.
25
6
CONCLUSÕES
O banco de dados PITU-RMC tem por objetivo integrar dados de diferentes
fontes em uma representação unificada, de modo a permitir a máxima flexibilidade
e eficiência na recuperação de informação, em diferentes níveis de agregação. A
arquitetura do sistema permite a implementação de experimentos em ciclos
fechados, onde os resultados obtidos podem servir como novas entradas, ou
como feedback para ajustar os dados e análises, de modo a aperfeiçoar todo o
processo ao longo de algumas repetições.
A possibilidade de migrar o banco de dados para plataformas
computacionais mais atualizadas, possantes e robustas ao longo da sua
evolução, aliada à eventual inserção e modificação de módulos para manipulação
e análise de dados, permitem o desenvolvimento incremental do sistema. Assim,
o banco de dados PITU-RMC poderá ser redimensionado e rearranjado
periodicamente, de modo a acompanhar a dinâmica dos processos de tomada de
decisão aos quais se destina, procurando sempre compatibilizar os custos com os
benefícios do sistema.
26