Medidas de Localização - 2. Média
DADOS SIMPLES
A média amostral ou simplesmente média, que se representa por é uma medida de
localização do centro da amostra, e obtém-se a partir da seguinte expressão:
onde x1, x2, ..., xn representam os elementos da amostra e n a sua dimensão.
DADOS AGRUPADOS TABELA
Se as observações se encontram agrupadas, então um valor aproximado para a média é dado
pela seguinte expressão:
onde:
k é o número de classes do agrupamento
ni é a frequência absoluta da classe i
yi é o ponto médio da classe i, o qual é considerado como elemento representativo da classe
Particularidade
A média goza de uma particularidade interessante e que consiste no seguinte:
se calcularmos os desvios de todas as observações relativamente à
média e somarmos esses desvios o resultado obtido é igual a zero.
Medidas de Localização - 3. Moda
Pág. 14 de 23
Para um conjunto de dados, define-se moda como sendo:
o valor que surge com mais frequência se os dados são
discretos, ou, o intervalo de classe com maior frequência se
os dados são contínuos.
Assim, da representação gráfica dos dados, obtém-se
imediatamente o valor que representa a moda ou a classe modal
Esta medida é especialmente útil para reduzir a informação
de um conjunto de dados qualitativos, apresentados sob a
forma de nomes ou categorias, para os quais não se pode
calcular a média e por vezes a mediana (se não forem
susceptíveis de ordenação).
Medidas de Localização - 4. Mediana
Pág. 14 de 23
A mediana, m, é uma medida de localização do centro da distribuição dos dados, definida do
seguinte modo:
Ordenados os elementos da amostra, a mediana é o valor (pertencente ou não à amostra)
que a divide ao meio, isto é, 50% dos elementos da amostra são menores ou iguais à
mediana e os outros 50% são maiores ou iguais à mediana
Para a sua determinação utiliza-se a seguinte regra, depois de ordenada a amostra de n
elementos:
Se n é ímpar, a mediana é o elemento médio.
Se n é par, a mediana é a semi-soma dos dois elementos médios.
Se se representarem os elementos da amostra ordenada com a seguinte notação:
X2:n , ... , Xn:n
então uma expressão para o cálculo da mediana será:
X1:n ,
Como medida de localização, a
mediana é mais robusta do que a
média, pois não é tão sensível aos
dados !
Média ou Mediana ?
Consideremos o seguinte exemplo:
um aluno do 10º ano obteve as seguintes
notas: 10, 10, 10, 11, 11, 11, 11, 12
A média e a mediana da amostra anterior são
respectivamente
=10.75 e
=11
Admitamos que uma das notas de 10 foi
substituída por uma de 18. Neste caso a
mediana continuaria a ser igual a 11, enquanto
que a média subiria para 11.75 !
Média ou
Mediana ?
Dado um histograma é fácil obter a posição da mediana, pois esta está na posição em que
passando uma linha vertical por esse ponto o histograma fica dividido em duas partes com
áreas iguais.
Como medida de localização, a mediana é mais resistente do que a média, pois não é tão
sensível aos dados.
1- Quando a distribuição é simétrica, a média e a mediana coincidem.
2- A mediana não é tão sensível, como a média, às observações que são muito maiores ou
muito menores do que as restantes (outliers). Por outro lado a média reflecte o valor de
todas as observações.
Assim, não se pode dizer em termos absolutos qual destas medidas de localização é
preferível, dependendo do contexto em que estão a ser utilizadas.
Como já vimos a média, ao contrário da mediana, é uma medida muito pouco resistente, isto
é, é muito influenciada por valores "muito grandes" ou "muito pequenos", mesmo que estes
valores surjam em pequeno número na amostra. Estes valores são os responsáveis pela má
utilização da média em muitas situações em que teria mais significado utilizar a mediana.
Resumindo, como a média é influenciada quer por valores muito grandes, quer por valores
muito pequenos, se a distribuição dos dados:
1. for aproximadamente simétrica, a média aproxima-se da mediana
2. for enviesada para a direita (alguns valores grandes como "outliers"), a média tende a
ser maior que a mediana
3. for enviesada para a esquerda (alguns valores pequenos como "outliers"), a média
tende a ser inferior à mediana.
Representando as ditribuições dos dados (esta observação é válida para as representações
gráficas na forma de diagramas de barras ou de histograma) na forma de uma mancha,
temos, de um modo geral:
Medidas de Localização - 5. Quantis
Pág. 22 de 23
Generalizando ainda a expressão para o cálculo da mediana, temos uma expressão
análoga para o cálculo dos quantis:
Qp =
onde representamos por [a], o maior inteiro contido em a.
Aos quantis de ordem 1/4 e 3/4 , damos respectivamente o nome de 1º quartil e 3º
quartil
Medidas de Dispersão - 2. Variância
Pág. 4 de 16
Define-se a variância, e representa-se por s2, como sendo a medida que se obtém
somando os quadrados dos desvios das observações da amostra, relativamente à
sua média, e dividindo pelo número de observações da amostra menos um:
Quais as razões que nos levam a considerar aquela definição para a
variância ?
A partir da definição de variância, pode-se deduzir sem dificuldade uma expressão mais
simples, sob o ponto de vista computacional, para calcular ou a variância ou o desvio
padrão e que é a seguinte:
Medidas de Dispersão - 3. Desvio Padrão
Pág. 6 de 16
Uma vez que a variância envolve a soma de quadrados, a unidade em que se exprime não
é a mesma que a dos dados. Assim, para obter uma medida da variabilidade ou dispersão
com as mesmas unidades que os dados, tomamos a raiz quadrada da variância e
obtemos o desvio padrão:
O desvio padrão é uma medida que só pode assumir valores não negativos e quanto
maior for, maior será a dispersão dos dados.
Algumas propriedades do desvio padrão, que resultam imediatamente da definição, são:
o desvio padrão é sempre não negativo e será tanto maior, quanta mais
variabilidade houver entre os dados.
se s = 0, então não existe variabilidade, isto é, os dados são todos iguais.
Medidas de Dispersão - 4. Amplitude
Pág. 14 de 16
Uma medida de dispersão que se utiliza por vezes, é a amplitude amostral r,
definida como sendo a diferença entre a maior e a menor das observações:
r = xn:n - x1:n
onde representamos por x1:n e xn:n, respectivamente o menor e o maior valor da
amostra (x1, x2, ..., xn), de acordo com a notação introduzida anteriormente,
para a amostra ordenada.
Exercícios:
http://alea-estp.ine.pt/html/nocoes/html/cap7_2_1.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_3_2.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_3_3.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_3_4.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_3_5.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_4_1.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_4_2.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_6_1.html
http://alea-estp.ine.pt/html/nocoes/html/cap7_6_2.html
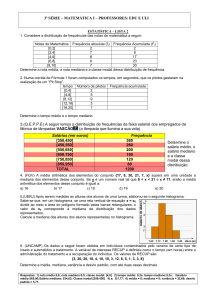
Tabelas de Frequências:
x/y
x1
x2
x3
fi
a
b
c
∑fi=n=a+b+c
fri
fri 1= a/n
fri 2= b/n
fri 3= c/n
Fi
a
a+b
a+b+c
Fi 3= n
Fri
fri 1
fri 1+ fri 2
fri 1+ fri 2+ fri 3
Fri 3= 1 ou 100%
Com x/y intervalos devemos calcular a marca da classe que servirá de fi:
[145, 150[
145+150= 147,50 (Marca da classe)
2