- azevedolab.net")
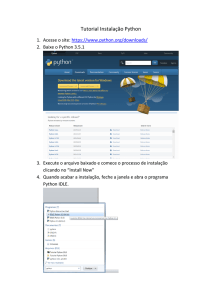
www.python.org
1
© 2015 Dr. Walter F. de Azevedo Jr.
000000000000000000000000000000000000000
000000000000000000000000000000000000000
000000000000111111111110001100000000000
000000000001111111111111111111000000001
000000000111111111111111111111111000000
000000000111111111111111111111111000000
000000000011111111111111111111100000000
000000001111111111111111111111111000000
000011111111111111111111111111111000000
001111111111111111111111111111110000000
111111111111111111111111111110000000000
111111111111111111111111111110000000000
000011111111111111111111111111111110000
001111111111111111111111111111111111000
011111111111111111111111111111111111000
001111111111111111111111111111111111100
000000011111111111111111111111111111110
000000001111111111111111111111111111110
000000000001111111111111111111111111110
000000000000011111111111111111111111110
000000000000000111111111111111111111000
000000000000000000000000001111000000000
000000000000000000000000000000000000000
000000000000000000000000000000000000000
000000000000000000000000000000000000000
Programa: proteinMW2.py
www.python.org
Massa molecular de proteínas (versão 2)
Programa: proteinMW2.py
Resumo
Programa para calcular a massa molecular de proteínas e a porcentagem em
massa de cada aminoácido presente na sequência. O programa lê a sequência
de um arquivo no formato FASTA. O usuário fornecerá o nome do arquivo
FASTA. O programa calcula a massa molecular e a porcentagem em massa dos
aminoácidos, a partir da informação sobre a estrutura primária da proteína. Será
usado um dicionário para armazenar a informação sobre a massa molecular de
cada aminoácido.
2
Programa: proteinMW2.py
www.python.org
Inicialmente atribuímos zero à variável mw, a massa molecular da proteína será
atribuída a esta variável. Depois criamos o dicionário aaMW, com a massa molecular
de cada resíduo de aminoácido. As massas moleculares estão disponíveis em:
http://www.matrixscience.com/help/aa_help.htm .
# Sets initial molecular weight variable (mw) to zero
mw = 0
# Source for residue molecular weights: http://www.matrixscience.com/help/aa_help.html (Accessed
# on May 8th 2015)
# To calculate the mass of a neutral peptide or protein, sum the residue masses plus the masses
# of the terminating
# groups (e.g. H at the N-terminus and OH at the C-terminus).
# Sets dictionary aaMW
Dicionário com a massa molecular
aaMW = {"A": 71.0779,"R": 156.1857,"N": 114.1026,"D": 115.0874,
"C": 103.1429,"E": 129.114,"Q": 128.1292,"G": 57.0513,
"H": 137.1393,"I": 113.1576,"L": 113.1576,"K": 128.1723,
"M": 131.1961,"F": 147.1739,"P": 97.1152,"S": 87.0773,
"T": 101.1039,"W": 186.2099,"Y": 163.1733,"V": 99.1311
}
3
Programa: proteinMW2.py
www.python.org
Em seguida lemos o nome do arquivo de entrada. Depois abrimos o arquivo de
entrada e realizamos a leitura da sequência, como visto em programas anteriores. A
sequência foi atribuída à variável seqIn, que é editada para remoção da primeira linha,
transformação de lista para string e remoção do “\n”. A sequência editada é atribuída à
variável seq.
Leitura e edição da sequência de aminoácidos
# Reads input file name
fastaIn = input("\nGive the input file name => ")
fh = open(fastaIn,'r')
# Opens input file
seqIn = fh.readlines()
# Reads all of the lines in a file and returns them as elements in a list
fh.close()
# Closes input file
# Removes the item at the given position in the list, and return it.
seqIn.pop(0)
# Removes first element of the list (get rid of the first line)
# Transforms list in string, so we will not get error with .replace()
seq=''.join(seqIn)
# Removes all "/n" from the string seq
seq = seq.replace("\n","")
4
Programa: proteinMW2.py
www.python.org
Logo em seguida temos um loop for, que soma o valor (massa molecular) de cada
chave (aminoácido) do dicionário aaMW à variável mw. Em seguida somamos 18.0148
Da à massa molecular, devido aos aminoácidos dos terminais.
# Looping through to calculate molecular weight
for aa in seq:
mw += aaMW[aa]
Loop for para somar as massas dos aminoácidos
mw = mw + 18.0148 # Sums water molecule
5
Programa: proteinMW2.py
www.python.org
Contamos cada tipo de aminoácido presente na sequência, como indicado abaixo.
# Counts number of amino acids
count_A = seq.count("A")
count_R = seq.count("R")
count_N = seq.count("N")
count_D = seq.count("D")
count_C = seq.count("C")
count_E = seq.count("E")
count_Q = seq.count("Q")
count_G = seq.count("G")
count_H = seq.count("H")
count_I = seq.count("I")
count_L = seq.count("L")
count_K = seq.count("K")
count_M = seq.count("M")
count_F = seq.count("F")
count_P = seq.count("P")
count_S = seq.count("S")
count_T = seq.count("T")
count_W = seq.count("W")
count_Y = seq.count("Y")
count_V = seq.count("V")
6
Programa: proteinMW2.py
www.python.org
Por último, mostramos os resultados na tela.
print("\nThe protein weighs %8.3f"%mw," Daltons")
if mw>0:
print("\nAmino acid\t\t\tPercentage in mass")
Mostra resultados se mw>0
print("Alanine \t\t\t %8.3f"%(100*count_A*aaMW["A"]/mw))
print("Arginine\t\t\t %8.3f"%(100*count_R*aaMW["R"]/mw))
print("Asparagine\t\t\t %8.3f"%(100*count_N*aaMW["N"]/mw))
print("Aspartate\t\t\t %8.3f"%(100*count_D*aaMW["D"]/mw))
print("Cysteine\t\t\t %8.3f"%(100*count_C*aaMW["C"]/mw))
print("Glutamate\t\t\t %8.3f"%(100*count_E*aaMW["E"]/mw))
print("Glutamine\t\t\t %8.3f"%(100*count_Q*aaMW["Q"]/mw))
print("Glycine
\t\t\t %8.3f"%(100*count_G*aaMW["G"]/mw))
print("Histidine\t\t\t %8.3f"%(100*count_H*aaMW["H"]/mw))
print("Isoleucine\t\t\t %8.3f"%(100*count_I*aaMW["I"]/mw))
print("Leucine
\t\t\t %8.3f"%(100*count_L*aaMW["L"]/mw))
print("Lysine
\t\t\t %8.3f"%(100*count_K*aaMW["K"]/mw))
print("Methionine\t\t\t %8.3f"%(100*count_M*aaMW["M"]/mw))
print("Phenylalanine\t\t\t %8.3f"%(100*count_F*aaMW["F"]/mw))
print("Proline
print("Serine
\t\t\t %8.3f"%(100*count_P*aaMW["P"]/mw))
\t\t\t %8.3f"%(100*count_S*aaMW["S"]/mw))
print("Threonine\t\t\t %8.3f"%(100*count_T*aaMW["T"]/mw))
print("Tryptophan\t\t\t %8.3f"%(100*count_W*aaMW["W"]/mw))
print("Tyrosine\t\t\t %8.3f"%(100*count_Y*aaMW["Y"]/mw))
print("Valine
\t\t\t %8.3f"%(100*count_V*aaMW["V"]/mw))
7
Programa: proteinMW2.py
www.python.org
Usando-se o programa para o arquivo FASTA 1kxy.fasta, obtemos o resultado abaixo.
Give the input file name => 1kxy.fasta
The protein weighs 14312.020
Amino acidPercentage in mass
Alanine
5.960
Arginine
12.004
Asparagine
11.959
Aspartate
4.825
Cysteine
5.765
Glutamate
1.804
Glutamine
2.686
Glycine
4.784
Histidine
0.958
Isoleucine
4.744
Leucine
6.325
Lysine
5.373
Methionine
1.833
Phenylalanine
3.085
Proline
1.357
Serine
6.084
Threonine
4.945
Tryptophan
7.806
Tyrosine
3.420
Valine
4.156
Daltons
8
Programa: proteinMW2a.py
www.python.org
Uma forma alternativa de programarmos, é usar um loop for aplicado diretamente ao
dicionário aaMW, como mostrado abaixo. Nesta solução economizamos uma parte
considerável de linhas de código. Toda ação está concentrada no segundo loop for.
Este loop for é inserido logo após o primeiro loop for, onde é calculada a massa
molecular da proteína (mw). O segundo loop for, aplicado ao dicionário aaMW, tem
como resultado que cada código de uma letra dos aminoácidos é atribuído à variável
res do loop for, o valor retornado para cada chave do dicionário é usado no cálculo da
porcentagem. Esta solução está implementada no programa proteinMW2a.py.
# Shows results
print("\nThe protein weighs",mw," Daltons")
if mw>0:
print("\nAmino acid\t\tPercentage in mass")
# Looping through to show percentage of each amino acid
for res in aaMW:
print(res,"\t\t\t",100*seq.count(res)*aaMW[res]/mw)
Rode o programa proteinMW2a.py e compare os resultados com a versão anterior.
9
Programa: aaHydro.py
www.python.org
Cálculo
da
porcentagem
hidrofóbicos
Programa: aaHydro.py
de
aminoácidos
Resumo
Programa para calcular a porcentagem de resíduos de aminoácidos hidrofóbicos
presentes na proteína. A informação sobre a estrutura primária é lida de um
arquivo no formato FASTA padrão, cujo o nome é fornecido pelo usuário. Os
resultados são mostrados na tela. Além de informações sobre o número total de
aminoácidos na proteína, é mostrada a primeira linha do arquivo FASTA, que
traz a identificação da proteína.
10
Programa: aaHydro.py
www.python.org
No código do programa aaHydro.py, temos que identificar os aminoácidos hidrofóbicos
presentes na sequência lida. O diagrama de Venn abaixo traz a lista dos aminoácidos
hidrofóbicos, para montarmos uma lista com os códigos de uma letra. Por exemplo, a
lista: hydroAA = ["A","L","I","F","M","C","V"] .
Thr
Alifáticos
Gly
Val
Ala
Ile
Leu
Aromáticos
Phe
Gln
Ser
Asn
Trp Tyr
Ácidos
Asp
Com enxofre
Met
Cys
Pro
His
Glu
Lys
Arg
Hidrofóbicos
11
Básicos
Polares
Programa: aaHydro.py
www.python.org
Usamos uma lista (hydroAA) para os códigos de uma letra dos aminoácidos
hidrofóbicos. Atribuímos zero ao contador count_Hydro. A parte inicial do programa é
similar ao programa proteinMW2.py, visto que temos que ler a sequência de um
arquivo FASTA. Depois da edição inicial, temos a sequência atribuída à variável seq.
Usamos seqIn.pop(0) para atribuir a primeira linha à variável firstLine.
# Sets list for hydrophobic amino acids
hydroAA = ["A","L","I","F","M","C","V"]
# Sets initial value for counter of hydrophobic amino acids
Leitura e edição da sequência de aminoácidos
count_Hydro = 0
# Reads input file name
fastaIn = input("\nGive the input file name => ")
fh = open(fastaIn,'r')
# Opens input file
seqIn = fh.readlines()
# Reads all of the lines in a file and returns them as elements in a list
fh.close()
# Closes input file
# Removes the item at the given position in the list, and assigns it to firstLine.
firstLine = seqIn.pop(0)
# Removes first element of the list (get rid of the first line)
# Transforms list in string, so we will not get error with .replace()
seq=''.join(seqIn)
# Removes all "/n" from the string seq
seq = seq.replace("\n","")
12
Programa: aaHydro.py
www.python.org
Agora temos um loop for para varremos a sequência de aminoácidos. Dentro do loop
temos um condicional if. No condicional testamos se o aminoácido, atribuído à variável
aa, está na lista hydroAA, em caso afirmativo somamos “1” ao contador count_Hydro.
Por último, mostramos o resultado na tela. Teste o programa para as sequências das
cadeias beta de hemoglobina.
Loop for para contar aminoácidos hidrofóbicos
for aa in seq:
if aa in hydroAA:
count_Hydro += 1
totalAA = len(seq)
# Shows results
Mostra resultados na tela
print("FASTA identification: ",firstLine)
if totalAA > 0:
print("\nPercentage of hydrophobic amino acids: %8.3f"%(100*count_Hydro/totalAA) )
else:
print("\nError, no amino acids in the structure.")
13
Programa: aaHydro.py
www.python.org
Usando-se o programa para o arquivo FASTA Hb9.fasta, obtemos o resultado abaixo.
Give the input file name => Hb9.fasta
FASTA identification: >HB5:B|PDBID|CHAIN|SEQUENCE
Percentage of hydrophobic amino acids:
43.151
Para as outras sequências de hemoglobina, temos uma percentagem menor, o que
indica que a cadeia da mutante Glu->Val é a sequência Hb9.fasta .
14
Programa: beerLambert3.py
www.python.org
Lei de Beer Lambert (versão 3)
Programa: beerLambert3.py
Resumo
Programa para calcular a concentração e a massa de proteína dissolvida num
tampão, a partir da Lei de Beer-Lambert. Os dados de entrada são absorbância
para o comprimento de onda de 280 nm, o volume da amostra (L) e o nome do
arquivo FASTA com a sequência da proteína. A quantidade de cada aminoácido
será lida a partir do arquivo FASTA. A massa molecular da proteína, bem como o
coeficiente de extinção molecular, serão calculados a partir da informação lida do
arquivo FASTA. A massa é calculada em gramas e a concentração em mol. A
abordagem usada para dosar amostras proteínas foi descrita em: Pace CN,
Vajdos F, Fee L, Grimsley G, Gray T. How to measure and predict the molar
15
absorption coefficient of a protein. Protein Sci. 1995; 4(11):2411-23.
Programa: beerLambert3.py
www.python.org
Inicialmente atribuímos zero à variável molWeight e definimos o dicionário aaMW,
como visto no programa proteinMW2.py.
# Sets initial molecular weight variable (molWeight) to zero
molWeight = 0
# Source for residue molecular weights: http://www.matrixscience.com/help/aa_help.html (Accessed
on May 8th 2015)
# To calculate the mass of a neutral peptide or protein, sum the residue masses plus the masses
of the terminating
# groups (e.g. H at the N-terminus and OH at the C-terminus).
# Sets dictionary aaMW
Dicionário com a massa molecular
aaMW = {"A": 71.0779,"R": 156.1857,"N": 114.1026,"D": 115.0874,
"C": 103.1429,"E": 129.114,"Q": 128.1292,"G": 57.0513,
"H": 137.1393,"I": 113.1576,"L": 113.1576,"K": 128.1723,
"M": 131.1961,"F": 147.1739,"P": 97.1152,"S": 87.0773,
"T": 101.1039,"W": 186.2099,"Y": 163.1733,"V": 99.1311
}
16
Programa: beerLambert3.py
www.python.org
Agora lemos o nome do arquivo FASTA de entrada (fastaIn), bem como a absorbância
(absorbance) e o volume da amostra (sampleVol). Procedemos com a edição da
sequência lida (seqIn), como visto no programa proteinMW2.py. A sequência editada é
atribuída à variável seq.
Leitura e edição da sequência de aminoácidos
# Reads input file name
fastaIn = input("\nGive the input file name => ")
fo = open(fastaIn,'r')
# Opens input file
seqIn = fo.readlines()
# Reads all of the lines in a file and returns them as elements in a list
fo.close()
# Closes input file
# Read input data
absorbance = float(input("\nType absorbance => "))
sampleVol = float(input("\nType sample volume (liter) => "))
# Removes the item at the given position in the list, and return it.
seqIn.pop(0)
# Removes first element of the list (get rid of the first line)
# Transforms list in string
seq=''.join(seqIn)
# Removes all "/n" from the string seq
seq = seq.replace("\n","")
17
Programa: beerLambert3.py
www.python.org
Contamos a ocorrência de tripofanos, tirosinas e cisteínas com o método .count(). Em
seguida temos um loop for, para que o valor (massa molecular do aminoácido) de
cada chave (código de uma letra do aminoácido) seja somado à variável molWeight.
Depois é somado 18.0148 Da à variável molWeight.
# Count amino acids
nTrp = seq.count("W")
nTyr = seq.count("Y")
nCys = seq.count("C")
nCis = int(nCys/2)
Loop para calcular a massa molecular
# Looping through to calculate molecular weight
for aa in seq:
molWeight += float(aaMW[aa])
molWeight = molWeight + 18.0148 # Sums water molecules
18
Programa: beerLambert3.py
www.python.org
Calculamos o coeficiente de extinção molar (epsilon), a concentração da amostra
(sampleConc) e a massa da proteína (protMass). Os resultados são mostrados na tela
usando-se notação científica na função print(). Para usarmos notação científica,
usamos %8.3e dentro da função print(), o que indica três casas após o ponto decimal.
# Calculates extinction coefficient (epsilon) following formula described by Page et al., 1995.
epsilon= 5500*nTrp +1490*nTyr + 125*nCis
Calcula epsilon
# Tests if epsilon > 0
if epsilon > 0:
Calcula a massa e concentração se épsilon>0
# calculates protein concentration and protein mass using BeerLambert's law
sampleConc = absorbance/epsilon
protMass = sampleConc*molWeight*sampleVol
# Shows results
print("\nMolar extinction coefficient = %8.3e"%epsilon,"M-1cm-1" )
print("Protein concentration = %8.3e"%sampleConc," M" )
print("Protein mass = %8.3e"%protMass," g" )
else:
# Shows error message
print("Error! Molar extinction coefficient should be > 0!" )
19
Programa: beerLambert3.py
www.python.org
Rodando-se o programa para a sequência 1kxy.fasta, absorbância de 0.175 e volume
de 0.001 L, temos os seguintes resultados em notação científica.
Give the input file name => 1kxy.fasta
Type absorbance => 0.175
Type sample volume (liter) => 0.001
Molar extinction coefficient = 3.797e+04 M-1cm-1
Protein concentration = 4.609e-06 M
Protein mass = 6.596e-05 g
20
Programa: beerLambert4.py
www.python.org
Lei de Beer Lambert (versão 4)
Programa: beerLambert4.py
Resumo
Programa para calcular a concentração e a massa de proteína dissolvida num
tampão, a partir da Lei de Beer-Lambert. Os dados de entrada são absorbância
para o comprimento de onda de 280 nm, o volume da amostra (L) e os nomes do
arquivo FASTA e saída de dados. A quantidade de cada aminoácido será lida a
partir do arquivo FASTA. A massa molecular da proteína, bem como o coeficiente
de extinção molecular, serão calculados a partir da informação lida do arquivo
FASTA. A massa é calculada em gramas e a concentração em mol e escrita num
arquivo de saída. A abordagem usada para dosar amostras proteínas foi descrita
em: Pace CN, Vajdos F, Fee L, Grimsley G, Gray T. How to measure and predict
the molar absorption coefficient of a protein. Protein Sci. 1995; 4(11):2411-23. 21
Programa: beerLambert4.py
www.python.org
A versão 4 do programa não tem grandes novidades, basicamente temos que ler o
nome do arquivo de saída e escrevermos o resultado neste arquivo. Assim vamos
mostrar só as novidades, indicadas em vermelho. O código completo está no arquivo
beerLambert4.py. Para a leitura do nome do arquivo de saída e a abertura deste,
usamos as seguintes linhas de código.
# Reads output file name
dataOut = input("\nGive the output file name => ")
fOut = open(dataOut,"w")
# Opens output file
22
Programa: beerLambert4.py
www.python.org
No final temos que escrever no arquivo de saída, indicado em vermelho abaixo:
if epsilon > 0:
# calculates protein concentration and protein mass dissolved
sampleConc = absorbance/epsilon
protMass = sampleConc*molWeight*sampleVol
# Shows
and writes results
print("\nMolar extinction coefficient = ",epsilon,"M-1cm-1" )
strOut = "Molar extinction coefficient = "+str(epsilon)+"M-1cm-1\n"
fOut.write(strOut)
# Writes information into output file
print("Protein concentration = ", sampleConc," M" )
strOut = "Protein concentration = "+str(sampleConc)+" M\n"
fOut.write(strOut)
# Writes information into output file
print("Protein mass = ", protMass," g" )
strOut = "Protein mass = "+str(protMass)+" g\n"
fOut.write(strOut)
# Writes information into output file
fOut.close()
# Closes output file
else:
print("Error! Molar extinction coefficient should be > 0!" )
23
Protein Data Bank
www.python.org
Vimos nas últimas aulas diversos programas em Python para a manipulação de
arquivos FASTA. Podemos dizer, que a informação armazenada em tais arquivos,
apresenta complexidade unidimensional, temos a estrutura primária de ácidos
nucleicos e proteínas. Por outro lado, informações sobre a estrutura tridimensional de
macromoléculas biológicas podem ser armazenadas em arquivos no formato protein
data bank (PDB). Na aula de hoje, bem como nas próximas, discutiremos diversos
programas para a manipulação da informação contida nos arquivos PDB.
24
Protein Data Bank
www.python.org
Um arquivo PDB tem basicamente dois tipos de informação. A primeira, indicada pelo
início da linha com as palavras-chaves REMARK, HEADER, TITLE, CRYST1 e
COMPND entre outras. São comentários sobre detalhes da estrutura depositada,
como autores, detalhes sobre a técnica usada para resolução da estrutura, bem como
informações sobre a qualidade estereoquímica da molécula armazenada no arquivo. O
outro tipo de informação, são as coordenadas atômicas. Esta informação é a de maior
importância, pois indica as coordenadas x, y e z de cada átomo da estrutura
depositada, são iniciadas pelas palavras-chaves ATOM ou HETATM.
25
Protein Data Bank
www.python.org
Vejamos como fazer o download da estrutura da cyclin-dependente kinase 2 em
complexo com o fármaco roscovitine depositada com o código 2A4L. Inicialmente
digitamos o código da proteína que desejamos baixar, no caso 2A4L, e clicamos na
lupa, como indicado abaixo.
26
Protein Data Bank
www.python.org
Agora temos acesso à estrutura. Para fazer download, clicamos na opção “Download
File>PDB File(Text)”. Assim podemos escolher a pasta onde salvar o arquivo PDB.
27
Protein Data Bank
www.python.org
Os arquivos PDB são arquivos texto simples, poderíamos abrir com qualquer editor de
texto para ver seu conteúdo. Abaixo temos as primeiras linhas do arquivo 2A4L.pdb.
Veja que o PDB tem uma estrutura fixa, à esquerda no início de cada linha temos uma
palavra-chave que identifica o tipo de informação contida na linha. Por exemplo,
HEADER identifica a molécula armazenada, no caso uma transferase. Temos,
também, a data do depósito da estrutura. Em seguida temos a palavra-chave TITLE,
que identifica a molécula depositada. Nas próximas linhas temos a palavra-chave
COMPND, que detalha a(s) molécula(s) contida(s) no arquivo. Não iremos identificar
todas as palavras-chaves do PDB neste primeiro contato. Vamos nos concentrar nas
coordenadas atômicas.
HEADER
TITLE
COMPND
COMPND
COMPND
COMPND
COMPND
COMPND
TRANSFERASE
29-JUN-05
2A4L
HUMAN CYCLIN-DEPENDENT KINASE 2 IN COMPLEX WITH ROSCOVITINE
MOL_ID: 1;
2 MOLECULE: HOMO SAPIENS CYCLIN-DEPENDENT KINASE 2;
3 CHAIN: A;
4 SYNONYM: CDK2;
5 EC: 2.7.1.37;
6 ENGINEERED: YES
28
Protein Data Bank
www.python.org
Abaixo temos a primeira linha com coordenadas atômicas do arquivo 2A4L.pdb.
Temos dois tipos de palavras-chaves usadas para linhas de coordenadas atômicas,
uma é a palavra-chave ATOM, que é usada para identificar coordenadas atômicas
para proteína. A outra é a palavra-chave HETATM, que traz a parte não proteica da
estrutura, pode ser um inibidor ligado à estrutura da proteína, cofatores, íons ou outras
moléculas que aparecem em complexo com a proteína.
ATOM
1
N
MET A
1
101.710 112.330
93.759
1.00 48.54
N
29
Protein Data Bank
www.python.org
Veremos em breve como fazer a leitura de um arquivo PDB em Python, mas antes
veremos o formato das linhas de coordenadas atômicas. Vamos considerar que lemos
uma linha de um arquivo PDB e temos a informação atribuída à variável line. Uma
string em Python pode ser fatiada em colunas, por exemplo, line[0:6] representa as
seis primeiras posições da string atribuída à variável line. Assim teríamos “ATOM “ em
line[0:6], veja que sempre iniciamos na posição zero, assim line[0] é “A”, line[1]” é “T” e
assim sucessivamente. Usando tal funcionalidade do Python, podemos dividir uma
linha do PDB em diferentes fatias. Cada linha de um arquivo PDB tem 81 colunas, ou
seja, uma string com 81 caracteres.
ATOM
1
N
MET A
1
101.710 112.330
93.759
1.00 48.54
N
30
Protein Data Bank
www.python.org
Como já destacamos, as informações sobre as coordenadas atômicas estão em linhas
que iniciam com ATOM ou HETATM. Abaixo temos a indicação dos campos de uma
linha, com informações sobre o conteúdo de cada parte num arquivo PDB.
ATOM
1
N
MET A
1
101.710 112.330
93.759
1.00 48.54
N
Colunas 57-60 para a ocupação, é atribuída à variável line[56:60]
Colunas 32-53 para as coordenadas atômicas, são atribuídas às variáveis
line[30:38], line[38:46], line[46:54]
Colunas 23-26 para o número do resíduo, é atribuída à variável line[22:26]
Coluna 22 para o identificador da cadeia, é atribuída à variável line[21:22]
Colunas de 18-20 para o nome do aminoácido (ou ligante, ou HOH), é atribuída à variável line[17:20]
Colunas de 14-15 para o nome do átomo, é atribuída à variável line[13:15]
Colunas de 7-11 para a ordem do átomo, é atribuída à variável line[6:11]
Colunas de 1-6 para string com ATOM ou HETATM, é atribuída à variável line[0:6]
31
Protein Data Bank
www.python.org
As informações sobre as últimas colunas.
ATOM
1
N
MET A
1
101.710 112.330
93.759
1.00 48.54
N
Colunas 62-65 para o fator de vibração térmica, é atribuída à variável line[61:65]
Colunas 77-77 para o elemento químico, é atribuída à variável line[76:77]
Além das informações indicadas anteriormente, há o
identificador de segmento (colunas 73-76), atribuído à
variável line[72:76]. Temos, também, a carga elétrica do
átomo (colunas 79-80), atribuída à variável line[78:80].
Vamos ilustrar com um programa para leitura de arquivos PDB.
32
Programa: readPDB1.py
www.python.org
Leitura de arquivos PDB (versão 1)
Programa: readPDB1.py
Resumo
Programa para leitura de arquivo de coordenadas atômicas no formato protein
data bank (PDB). Após a leitura do arquivo PDB, o programa mostra as
coordenadas atômicas da parte proteica na tela. O usuário digita o nome do
arquivo PDB de entrada. As colunas 32-53 são usadas para as coordenadas
atômicas x, y e z, e serão atribuídas às variáveis line[30:38], line[38:46] e
line[46:54], respectivamente.
33
Programa: readPDB1.py
www.python.org
Com 6 linhas de código conseguimos o programa para leitura do arquivo PDB. Na
primeira linha lemos o nome do arquivo de entrada, que é atribuído à variável
pdbFileIn. Em seguida, o arquivo é aberto com a função open() e o conteúdo atribuído
ao objeto arquivo fo. Cada elemento do objeto arquivo é uma linha do arquivo PDB. A
partir de um loop for, podemos varrer o objeto arquivo fo. Dentro do loop for testamos
se a string atribuída à variável line[0:6] é igual “ATOM “. Caso seja, mostramos as
coordenadas atômicas atribuídas às variáveis line[30:38], line[38:46], line[46:54]. Por
último, fechamos o arquivo com close(). O código está mostrado abaixo.
pdbFileIn = input("\nType the PDB file name => ")
fo = open(pdbFileIn,"r")
for line in fo:
if line[0:6] == "ATOM
":
print(line[30:38], line[38:46], line[46:54])
fo.close()
34
Programa: readPDB1.py
www.python.org
Ao rodarmos o programa para o arquivo 2A4L.pdb, temos o seguinte resultado. Só
as primeiras linhas são mostradas abaixo, visto que o arquivo PDB tem milhares de
linhas com coordenadas atômicas.
Type the PDB file name => 2a4l.pdb
101.710 112.330
93.759
102.732 113.140
94.479
103.199 114.420
93.762
102.995 114.577
92.561
103.933 112.272
94.785
104.548 112.540
96.126
106.336 112.671
95.934
106.542 114.250
95.159
103.906 115.275
94.503
104.085 116.695
94.178
105.065 117.015
93.046
104.918 118.030
92.386
104.531 117.459
95.428
103.464 117.597
96.515
......
35
Programa: readPDB2.py
www.python.org
Leitura de arquivos PDB (versão 2)
Programa: readPDB2.py
Resumo
Programa para leitura de arquivo de coordenadas atômicas no formato protein
data bank (PDB). Após a leitura do arquivo PDB, o programa mostra na tela as
linhas referentes à parte não-proteica da estrutura, identificadas com a palavrachave “HETATM”. O usuário digita o nome do arquivo PDB de entrada.
36
Programa: readPDB2.py
www.python.org
O programa redPDB2.py é similar à versão 1, lemos o nome do arquivo PDB,
abrimos o arquivo PDB e atribuímos seu conteúdo ao objeto arquivo fo. Temos uma
função print() para exibir uma mensagem, indicando que os átomos a serem
mostrados são para parte não-proteica da estrutura. Usamos um loop for para
mostrar as linhas que iniciam com a palavra-chave “HETATM”. Esta palavra é
reservada para os átomos de ligantes não-proteicos e moléculas de água. Veja que
na função print() do loop temos a impressão da linha completa. Outro detalhe, como
lemos toda a linha, a sequência de escape “\n” vem junto, assim ao mostrar a linha
na tela com a função print() teríamos pulado duas linhas, visto que a função print() já
tem um pulo de linha. Como a opção end=“” no final da função print(), só teremos
uma linha pulada.
pdbFileIn = input("\nType the PDB file name => ")
fo = open(pdbFileIn,"r")
print("\nNon-protein atoms in the structure: ",pdbFileIn)
for line in fo:
if line[0:6] == "HETATM":
print(line,end="")
fo.close()
37
Programa: readPDB2.py
www.python.org
Iremos usar como entrada o mesmo arquivo PDB, o 2A4L.pdb. Só as primeiras
linhas são mostradas abaixo, visto que o arquivo PDB tem centenas de linhas com
coordenadas atômicas para a parte não-proteica.
Type the PDB file name => 2a4l.pdb
Non-protein atoms in the structure: 2a4l.pdb
HETATM 2310 OAP RRC A 300
96.941 98.398
HETATM 2311 CAQ RRC A 300
97.820 99.316
HETATM 2312 CAR RRC A 300
99.303 99.060
HETATM 2313 CAK RRC A 300
99.580 97.539
HETATM 2314 CAI RRC A 300
100.869 97.070
HETATM 2315 NAS RRC A 300
99.689 99.675
HETATM 2316 CAT RRC A 300
100.605 100.579
HETATM 2317 NAU RRC A 300
101.580 100.731
HETATM 2318 CAV RRC A 300
102.566 101.608
HETATM 2319 NAW RRC A 300
103.671 101.870
HETATM 2320 CAZ RRC A 300
103.942 101.208
HETATM 2321 CAY RRC A 300
104.143 99.692
HETATM 2322 CBA RRC A 300
102.750 101.454
HETATM 2323 CAX RRC A 300
104.385 102.795
HETATM 2324 CAN RRC A 300
102.627 102.352
HETATM 2325 NAO RRC A 300
103.798 103.097
HETATM 2326 NAL RRC A 300
100.613 101.293
HETATM 2327 CAM RRC A 300
101.582 102.198
HETATM 2328 NAJ RRC A 300
101.479 102.793
HETATM 2329 CAD RRC A 300
100.239 102.485
HETATM 2330 CAE RRC A 300
99.608 103.832
HETATM 2331 CAG RRC A 300
100.439 104.891
HETATM 2332 CAH RRC A 300
99.883 106.112
HETATM 2333 CAF RRC A 300
98.498 106.229
HETATM 2334 CAC RRC A 300
97.648 105.173
HETATM 2335 CAB RRC A 300
98.224 103.961
HETATM 2336 O
HOH A 301
111.986 88.707
HETATM 2337 O
HOH A 302
110.056 107.739
HETATM 2338 O
HOH A 303
105.915 75.710
.....
81.701
82.399
82.125
82.113
82.813
80.771
80.397
81.285
81.000
81.769
83.053
82.820
84.012
81.053
79.851
79.918
79.240
78.895
77.721
76.983
76.581
76.236
75.870
75.864
76.188
76.550
61.335
80.142
86.645
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
44.09
42.38
40.92
37.94
32.82
39.58
36.82
35.03
35.80
36.76
31.93
33.96
36.26
33.13
35.38
34.99
36.74
35.57
35.54
36.45
36.74
39.36
40.58
40.67
39.86
34.98
12.31
9.52
32.44
O
C
C
C
C
N
C
N
C
N
C
C
C
C
C
N
N
C
N
C
C
C
C
C
C
C
O
O
O
38
Programa: readPDB3.py
www.python.org
Leitura de arquivos PDB (versão 3)
Programa: readPDB3.py
Resumo
Programa para leitura de arquivo de coordenadas atômicas no formato protein
data bank (PDB). Após a leitura do arquivo PDB, o programa mostra na tela as
linhas referentes à parte das moléculas de água, identificadas com a palavrachave “HETATM” e com as colunas 18-20 iguais à “HOH”. O restante das linhas,
iniciadas com “HETATM”, serão mostradas como ligantes. O usuário digita o
nome do arquivo PDB de entrada.
39
Programa: readPDB3.py
www.python.org
O programa redPDB3.py é similar à versão 2, lemos o nome do arquivo PDB,
abrimos o arquivo PDB e atribuímos seu conteúdo ao objeto arquivo fo. Temos uma
função print() para exibir uma mensagem, indicando que os átomos a serem
mostrados são para moléculas de água. Usamos um loop for para mostrar as linhas
que iniciam com a palavra-chave “HETATM” e que tem as colunas 18-20 (line[17:20])
igual a “HOH”. Temos uma função print() no loop for, para mostrar as linhas
selecionadas. Depois fechamos o arquivo e reabrimos o arquivo. Procedemos assim,
pois todas as linhas já foram lidas no primeiro loop for. Assim, necessitamos ainda
identificar as linhas para os outros “HETATM”. Antes do segundo loop for, temos uma
função print() para indicar que mostraremos os átomos para os ligantes. No segundo
loop for temos um condicional seleciona os “HETATM” que não são moléculas de
água.
O código está no próximo slide.
40
Programa: readPDB3.py
www.python.org
Os loops estão indicados entre retângulos vermelhos. O primeiro loop for identifica as
moléculas de água. O segundo loop for identifica os ligantes não-proteicos.
pdbFileIn = input("\nType the PDB file name => ")
fo = open(pdbFileIn,"r")
print("\nWater molecules in the structure: ",pdbFileIn)
for line in fo:
if line[0:6] == "HETATM" and line[17:20] == "HOH":
print(line,end="")
print("\nLigand atoms in the structure: ",pdbFileIn)
fo.close()
fo = open(pdbFileIn,"r")
for line in fo:
if line[0:6] == "HETATM" and line[17:20] != "HOH":
print(line,end="")
fo.close()
41
Programa: readPDB3.py
www.python.org
Iremos usar como entrada o mesmo arquivo PDB, o 2A4L.pdb. Só as primeiras
linhas das moléculas de água são mostradas abaixo.
Type the PDB file name => 2a4l.pdb
Water molecules in the structure: 2a4l.pdb
HETATM 2336 O
HOH A 301
111.986 88.707
HETATM 2337 O
HOH A 302
110.056 107.739
....
Ligand atoms in the structure: 2a4l.pdb
HETATM 2310 OAP RRC A 300
96.941 98.398
HETATM 2311 CAQ RRC A 300
97.820 99.316
HETATM 2312 CAR RRC A 300
99.303 99.060
HETATM 2313 CAK RRC A 300
99.580 97.539
HETATM 2314 CAI RRC A 300
100.869 97.070
HETATM 2315 NAS RRC A 300
99.689 99.675
HETATM 2316 CAT RRC A 300
100.605 100.579
HETATM 2317 NAU RRC A 300
101.580 100.731
HETATM 2318 CAV RRC A 300
102.566 101.608
HETATM 2319 NAW RRC A 300
103.671 101.870
HETATM 2320 CAZ RRC A 300
103.942 101.208
HETATM 2321 CAY RRC A 300
104.143 99.692
HETATM 2322 CBA RRC A 300
102.750 101.454
HETATM 2323 CAX RRC A 300
104.385 102.795
HETATM 2324 CAN RRC A 300
102.627 102.352
HETATM 2325 NAO RRC A 300
103.798 103.097
HETATM 2326 NAL RRC A 300
100.613 101.293
HETATM 2327 CAM RRC A 300
101.582 102.198
HETATM 2328 NAJ RRC A 300
101.479 102.793
HETATM 2329 CAD RRC A 300
100.239 102.485
HETATM 2330 CAE RRC A 300
99.608 103.832
HETATM 2331 CAG RRC A 300
100.439 104.891
HETATM 2332 CAH RRC A 300
99.883 106.112
HETATM 2333 CAF RRC A 300
98.498 106.229
HETATM 2334 CAC RRC A 300
97.648 105.173
HETATM 2335 CAB RRC A 300
98.224 103.961
61.335
80.142
1.00 12.31
1.00 9.52
O
O
81.701
82.399
82.125
82.113
82.813
80.771
80.397
81.285
81.000
81.769
83.053
82.820
84.012
81.053
79.851
79.918
79.240
78.895
77.721
76.983
76.581
76.236
75.870
75.864
76.188
76.550
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
1.00
O
C
C
C
C
N
C
N
C
N
C
C
C
C
C
N
N
C
N
C
C
C
C
C
C
C
44.09
42.38
40.92
37.94
32.82
39.58
36.82
35.03
35.80
36.76
31.93
33.96
36.26
33.13
35.38
34.99
36.74
35.57
35.54
36.45
36.74
39.36
40.58
40.67
39.86
34.98
42
Programa: readANDwritePDB1.py
www.python.org
Leitura e escrita de arquivos PDB (versão 1)
Programa: readANDwritePDB1.py
Resumo
Programa para leitura e escrita de arquivo de coordenadas atômicas no formato
protein data bank (PDB). Após a leitura do arquivo PDB, o programa divide o
arquivo de entrada em três arquivos de saída. Um com os átomos da parte
proteica, outro com os átomos dos ligantes e o último com os átomos das
moléculas de água. A parte proteica é escrita no arquivo de saída protein.pdb, a
parte dos ligantes no arquivo lig.pdb e as moléculas de água no arquivo
water.pdb.
43
Programa: readANDwritePDB1.py
www.python.org
A parte da abertura e leitura do arquivo PDB de entrada é similar aos programas
anteriores. A novidade está na escrita. A parte inicial do programa está mostrada
abaixo. Temos a função open() para a abertura dos arquivos protein.pdb, lig.pdb e
water.pdb, indicadas em vermelho. Em seguida temos três funções print() para
indicar que as coordenadas serão escritas nos arquivos citados acima.
pdbFileIn = input("\nType the PDB file name => ")
fo = open(pdbFileIn,"r")
f_protein = open("protein.pdb","w")
f_lig = open("lig.pdb","w")
f_water = open("water.pdb","w")
print("\nProtein atoms in the structure: ",pdbFileIn, "to be written in protein.pdb")
print("\nLigand atoms in the structure: ",pdbFileIn, "to be written in lig.pdb")
print("\nWater atoms in the structure: ",pdbFileIn, "to be written in water.pdb")
44
Programa: readANDwritePDB1.py
www.python.org
Usamos condicionais no loop for que varre o arquivo de entrada, para selecionarmos
as diferentes fatias de átomos do arquivo PDB. Inicialmente selecionamos a parte
proteica, depois a parte dos ligantes e, por último, a parte das moléculas de água. O
loop for está indicado em vermelho. Por último, fechamos todos os arquivos.
for line in fo:
if line[0:6] == "ATOM
":
f_protein.write(line)
elif line[0:6] == "HETATM" and line[17:20] != "HOH":
f_lig.write(line)
elif line[0:6] == "HETATM" and line[17:20] == "HOH":
f_water.write(line)
fo.close()
f_protein.close()
f_lig.close()
f_water.close()
45
Programa: readANDwritePDB1.py
www.python.org
Ao rodarmos o programa, criamos três novos arquivos: protein.pdb, lig.pdb e
water.pdb . Abaixo temos o resultado de rodarmos o programa para o arquivo
2A4L.pdb.
Type the PDB file name => 2a4l.pdb
Protein atoms in the structure:
2a4l.pdb to be written in protein.pdb
Ligand atoms in the structure:
2a4l.pdb to be written in lig.pdb
Water atoms in the structure:
2a4l.pdb to be written in water.pdb
46
Programa: readANDwritePDB2.py
www.python.org
Leitura e escrita de arquivos PDB (versão 2)
Programa: readANDwritePDB2.py
Resumo
Programa para leitura e escrita de arquivo de coordenadas atômicas no formato
protein data bank (PDB). Após a leitura do arquivo PDB, o programa divide o
arquivo de entrada em três arquivos de saída. Um com os átomos da parte
proteica, outro com os átomos dos ligantes e o último com os átomos das
moléculas de água. Os nomes dos arquivos de saída são fornecidos pelo
usuário. O programa mostra quantos átomos de cada tipo foram escritos nos
arquivos de saída.
47
Referências
www.python.org
-BRESSERT, Eli. SciPy and NumPy. Sebastopol: O’Reilly Media, Inc., 2013. 56 p.
-DAWSON, Michael. Python Programming, for the absolute beginner. 3ed. Boston: Course Technology, 2010. 455 p.
-HETLAND, Magnus Lie. Python Algorithms. Mastering Basic Algorithms in the Python Language. Nova York: Springer
Science+Business Media LLC, 2010. 316 p.
-IDRIS, Ivan. NumPy 1.5. An action-packed guide dor the easy-to-use, high performance, Python based free open source
NumPy mathematical library using real-world examples. Beginner’s Guide. Birmingham: Packt Publishing Ltd., 2011. 212 p.
-KIUSALAAS, Jaan. Numerical Methods in Engineering with Python. 2ed. Nova York: Cambridge University Press, 2010. 422
p.
-LANDAU, Rubin H. A First Course in Scientific Computing: Symbolic, Graphic, and Numeric Modeling Using Maple, Java,
Mathematica, and Fortran90. Princeton: Princeton University Press, 2005. 481p.
-LANDAU, Rubin H., PÁEZ, Manuel José, BORDEIANU, Cristian C. A Survey of Computational Physics. Introductory
Computational Physics. Princeton: Princeton University Press, 2008. 658 p.
-LUTZ, Mark. Programming Python. 4ed. Sebastopol: O’Reilly Media, Inc., 2010. 1584 p.
-MODEL, Mitchell L. Bioinformatics Programming Using Python. Sebastopol: O’Reilly Media, Inc., 2011. 1584 p.
-TOSI, Sandro. Matplotlib for Python Developers. Birmingham: Packt Publishing Ltd., 2009. 293 p.
Última atualização em 23 de maio de 2015.
48
 - azevedolab.net")