Algoritmo Genético para a Descoberta de Regras de Predição
Lorena Morais1, Miriam Domingues1, Roberto Limão de Oliveira1
1
Centro Tecnológico – Universidade Federal do Pará (UFPA)
Caixa Postal 8619 – CEP 66.075-900 – Belém – PA – Brasil
[email protected], [email protected], [email protected]
Abstract. Data Mining (MD) refers to extracting knowledge from large
databases. One of its tasks is classification, a prediction task that uses IFTHEN rules for representation of the joined knowledge. These rules must be of
easy understanding to the users of the system. In this context, a Genetic
Algorithm (AG) is proposed that objectives the induction of simple
classification rules having the lesser condition number in its antecedent, what
make them also more interesting to the user. A comparison between the rules
produced with the proposed AG here and the rules produced with usual
algorithms of MD were carried through to verify the accuracy of the system.
The results seem promising and the idea proposed can be deepened in a new
research.
Resumo. A Mineração de Dados (MD) se refere à extração de conhecimento
de grandes bases de dados. Uma de suas tarefas é a classificação, tarefa de
predição que utiliza regras do tipo SE-ENTÃO para representação do
conhecimento encontrado. Estas regras devem ser de fácil entendimento aos
usuários do sistema. Neste contexto, é proposto um Algoritmo Genético (AG)
que objetiva a indução de regras de classificação simples, que possuam o
menor número de condições em seu antecedente, o que as torna também mais
interessantes ao usuário. Uma comparação entre as regras produzidas com o
AG aqui proposto e as regras produzidas por algoritmos usuais de MD foi
realizada para verificar a acurácia do sistema. Os resultados se mostram
promissores e a idéia proposta pode ser aprofundada em uma nova pesquisa.
1. Introdução
A Mineração de Dados (MD) se refere à extração de conhecimento de grandes bases de
dados. O conhecimento obtido é dado pela identificação de padrões válidos, novos,
potencialmente úteis e facilmente compreensíveis ao usuário [Fayyad, 1996].
A MD é realizada por intermédio de tarefas. Cada tarefa determina o tipo de
conhecimento a ser descoberto. Uma das tarefas mais pesquisadas em MD é a
classificação, que está relacionada à descoberta de regras de predição do tipo SEENTÃO.
Para a extração do conhecimento de bases de dados, são utilizadas ferramentas
de exploração que incorporam técnicas estatísticas e/ou de inteligência artificial (IA)
capazes de fornecer respostas a várias questões [Romão et al., 2000].
2
Na área de IA, os Algoritmos Genéticos (AG’s) têm sido cada vez mais
explorados na solução de problemas envolvendo buscas e otimizações, pela robustez e
simplicidade que oferecem [Bueno, 2005].
Os AG’s são empregados em problemas que objetivam encontrar uma ou uma
série de boas soluções entre um número muito grande de possíveis soluções (espaço de
busca) e podem encontrar a solução ótima ou sub-ótima em problemas com espaços de
busca intratáveis ou problemas de difícil modelagem matemática [Lopes, 1999].
Pesquisas recentes têm demonstrado que os AG’s podem ser utilizados com
sucesso em problemas de extração de conhecimento de dados [Romão et al., 2000].
Nesta pesquisa, o objetivo é investigar uma abordagem de algoritmo genético
(AG) para mineração de dados, que realize a tarefa de classificação pela indução de
regras de predição de bases de dados, para avaliar se é possível extrair regras simples,
que facilitem o entendimento pelo usuário do conhecimento obtido, tornando-o dessa
forma mais interessante e útil.
Para verificar a acurácia da técnica proposta, os resultados encontrados com o
algoritmo genético são comparados com os resultados encontrados por algoritmos
disponibilizados em uma conhecida ferramenta de MD, o Weka [Witten, 2005].1
Este artigo está organizado da seguinte forma: a Seção 2 apresenta uma visão
geral de Mineração de Dados e da tarefa de classificação, respectivamente. Na Seção 3,
são apresentados os conceitos básicos de Algoritmos Genéticos. A seguir, na Seção 4
são apresentados os trabalhos correlatos. Na Seção 5, é apresentada a proposta de AG
para a indução de regras. Na Seção 6, os experimentos realizados e, na Seção 7, a
conclusão do trabalho e sugestões para trabalhos futuros.
2. Mineração de Dados
A MD é definida como o processo de extração de conhecimento de grandes bases de
dados. Basicamente, esta tecnologia considera que grandes bases de dados são fontes
potenciais de conhecimento valioso, útil para a tomada de decisões estratégicas.
A mineração de dados é um campo interdisciplinar, uma vez que abrange a
utilização de diversos tipos de algoritmos derivados das mais diversas áreas de pesquisa,
como por exemplo a estatística, o aprendizado de máquina, reconhecimento de padrões,
dentre outras [Han, 2001].
O conhecimento descoberto pelos algoritmos de MD deve ser novo,
compreensível e útil e deverá trazer algum benefício que possa ser compreendido
rapidamente pelo usuário para tomada de decisão [Romão, 2000].
A MD possui dois objetivos: a descrição e a predição. A descrição se concentra
em encontrar padrões que descrevam os dados, caracterizando as propriedades gerais
desses dados em um banco de dados de forma interpretável pelos usuários. A predição
realiza inferência nos dados correntes para construir modelos que serão utilizados para
predições do comportamento de novos dados [Fayyad, 1996], [Han, 2001].
1
Weka – Ferramenta de mineração de dados, de uso livre, que disponibiliza, dentres outras
funcionalidades, diversos algoritmos para realizar as tarefas de classificação, clustering, associação e
seleção de atributos [Witten, 2005].
3
Para realizar a descrição e a predição, as técnicas de MD são aplicadas pela
realização de tarefas como por exemplo: clustering ou agrupamento, sumarização,
associação (tarefas descritivas); classificação, regressão, modelagem de dependência
(tarefas preditivas), sendo a tarefa de classificação a mais empregada. Neste contexto,
cada tarefa determina o tipo de conhecimento a ser descoberto.
Além das tarefas, a MD emprega diversas outras técnicas disponíveis na
literatura para extrair conhecimento, tais como: indução e/ou extração de regras, redes
neurais, algoritmos evolucionários, técnicas estatística (classificadores e redes
Bayesianas), conjuntos difusos, etc.
Para a escolha mais adequada, é importante conhecer o domínio do problema:
quais os atributos da base de dados, o que significam, suas estatísticas, hipóteses prévias
dos usuários e outras informações relevantes.
2.1. A Tarefa de Classificação
A tarefa de classificação tem como objetivo descobrir um relacionamento entre um
atributo meta (predição para um valor ou classe) e um conjunto de atributos de predição.
O sistema deve descobrir este relacionamento a partir de exemplos com uma classe
conhecida. O relacionamento descoberto será usado para prever o valor do atributo meta
(ou a classe) para novos exemplos apresentados ao sistema [Fertig et al., 1999].
Na aplicação deste artigo, no Experimento 2, que utiliza a base de dados Creche,
a classificação pode ser definida como sendo a tarefa de prever corretamente a classe de
pessoas que apresentam determinadas características para que seus filhos sejam aceitos
em uma creche, a partir de atributos de predição, cujos valores são conhecidos. Uma das
possibilidades é a descoberta de regras que representem as correlações entre os atributos
que definem “a qualidade da família da criança” (p. ex., saúde, condição social,
condições de moradia e outros).
Portanto, a classificação constitui um procedimento para ser aplicado em um
banco de dados onde as classes são pré-definidas e cada novo dado deve ser associado a
uma destas classes. Segundo Romão (2000), este processo é conhecido como
reconhecimento de padrões, discriminação, aprendizagem supervisionada ou
classificação. Na literatura de estatística, a aprendizagem supervisionada usualmente é
referenciada como discriminação.
Existem diversas formas de representar o conhecimento em um sistema de
aprendizagem. Na tarefa de classificação, o conhecimento descoberto é expresso como
um conjunto de regras do tipo SE-ENTÃO na forma mostrada abaixo, uma vez que este
tipo de representação do conhecimento é intuitivo para o usuário [Carvalho e Freitas,
2000].
SE
<algumas condições são satisfeitas>
ENTÃO < predizer o valor de alguns atributos metas>.
Regras do tipo SE-ENTÃO são também chamadas regras de produção e
constituem uma forma de representação simbólica. A parte SE é o antecedente da regra
e a parte ENTÃO é o conseqüente. O antecedente é formado por expressões
condicionais envolvendo atributos do domínio da aplicação existentes nos bancos de
dados. O conseqüente é formado por expressões que indicam a previsão de algum valor
4
para um atributo meta, obtido em função dos valores encontrados nos atributos que
compõem o antecedente [Romão, 2000].
As regras SE-ENTÃO deste trabalho, apesar de voltadas para a classificação,
seguem o modelo de regras de associação, que representam o conhecimento na tarefa de
associação de MD. Uma regra de associação é um relacionamento da forma X Y,
onde X e Y são conjuntos de itens e a interseção deles é o conjunto vazio. As regras de
associação configuram um problema típico conhecido na literatura como “Problema da
Cesta de Compras” e significam que se X ocorre em uma transação do banco de dados,
Y ocorre também. O motivo de serem empregadas na modelagem proposta neste
trabalho está relacionado ao fato de que cada regra está associada a um fator de
confiança ou acurácia, cuja Fórmula 2.1 mostrada abaixo é útil para avaliar cada regra
encontrada.
conf
NúmeroderegistroscomXeY
NúmeroderegistroscomX
(2.1)
3. Algoritmos Genéticos
Os AG’s são algoritmos de busca ou otimização inspirados na seleção natural e
reprodução genética que combinam processos naturais, necessários à evolução dos mais
aptos, com troca de informação estruturada, porém randômica, para formar um
algoritmo de busca baseado na habilidade inovadora da busca humana [Goldberg,
1989].
Os AG’s vêem o aprendizado como uma competição numa população de
soluções evolutivas, candidatas para o problema. A pressão seletiva, que na natureza é
exercida pelo ambiente, é simulada pela aplicação de uma função objetivo, que avalia a
aptidão de cada solução candidata (cada indivíduo da população) para decidir se esta
contribuirá para a próxima geração de soluções. Então, através de operações análogas à
transferência de genes na reprodução sexual, o algoritmo cria uma nova população de
soluções candidatas [Luger, 2004], [Bueno et al., 2005].
Cada indivíduo ou solução candidata que se encontra no espaço de busca do
problema é representado, univocamente, por uma cadeia de símbolos chamada
cromossomo [Bueno, 2005}. Um cromossomo contém a codificação (genótipo) de uma
possível solução do problema (fenótipo). Estes cromossomos costumam ser
implementados na forma de listas de atributos ou vetores, onde cada atributo é
conhecido como gene. Os possíveis valores que um determinado gene pode assumir são
ditos alelos [Von Zuben, 2005]. Partindo de uma população inicial de indivíduos, são
aplicados os operadores genéticos, que originam novas gerações de indivíduos
artificiais, os quais trazem características dos mais adaptados das gerações anteriores
[Bueno, 2005].
Os AG’s são chamados de adaptativos, pois as futuras possíveis soluções são
influenciadas pelas soluções atuais. Também são ditos paralelos, pois várias soluções
são consideradas a cada momento. Desta forma, exploram novos pontos de busca com a
expectativa de desempenho crescente.
A estrutura de um algoritmo genético pode ter a seguinte forma [Michalewicz,
1996 apud Von Zuben, 2005]:
5
Durante a iteração t, um algoritmo genético mantém uma população de
soluções potenciais (indivíduos, cromossomos, lista de atributos ou vetores)
P(t)={xt1, ..., xtn};
cada solução xti é avaliada e produz uma medida de sua adaptação, ou fitness;
uma nova população (iteração t + 1) é então formada privilegiando a
participação dos indivíduos mais adaptados;
alguns membros da nova população passam por alterações, por meio de
crossover e mutação, para formar novas soluções potenciais;
este processo se repete até que um número pré-determinado de iterações seja
atingido, ou até que um nível de adaptação esperado seja alcançado.
Um AG para um problema particular deve ter os seguintes componentes:
Uma representação genética para soluções candidatas ou potenciais
(processo de codificação);
uma maneira de criar uma população inicial de soluções candidatas ou
potenciais;
uma função de avaliação que faz o papel da pressão ambiental, classificando
as soluções em termos de sua adaptação ao ambiente (ou seja, sua
capacidade de resolver o problema);
operadores genéticos;
valores para os diversos parâmetros usados pelo algoritmo genético
(tamanho da população, probabilidades de aplicação dos operadores
genéticos, etc.).
Em um algoritmo genético simples, os principais operadores genéticos são:
Seleção: baseia-se probabilisticamente no valor da aptidão de um gene:
quanto mais alta a aptidão do gene, maior probabilidade este tem de se
reproduzir.
Reprodução: envolve a seleção dos genes pais da população corrente com
base na aptidão. Para isso, costumam ser utilizados os operadores de:
o Cruzamento ou crossover ou recombinação: combina dois ou mais
indivíduos. O cruzamento é realizado segundo uma probabilidade de
cruzamento fixa que é atribuída aos indivíduos da população. Esta
designa ponto(s) de cruzamento randômico resultando em filhos
construídos pela troca de pedaços dos genes dos pais selecionados.
o Mutação: modifica aleatoriamente um ou mais genes de um cromossomo
de acordo com uma taxa de mutação, com o objetivo de criar uma
variabilidade extra, necessária para a diversidade genética da população.
3.1. Algoritmos Genéticos para Mineração de Dados
Para a tarefa de classificação de registros em MD, os modelos de AG’s geram regras de
fácil interpretação que exprimem uma realidade do domínio da aplicação. Estas regras
6
são modeladas na forma de regras de associação, do tipo SE-ENTÃO, entre os atributos
de predição e o atributo objetivo ou atributo-classe.
Os trabalhos sobre o uso de AG’s para classificação tratam de problemas que
apresentam diferentes formas de representação dos indivíduos, de operadores genéticos
e de funções de aptidão ou definem diferentes objetivos quanto ao tipo de regra que se
deseja encontrar, conforme se exemplifica na Seção 4 de trabalhos correlatos.
Com relação à representação dos indivíduos, algumas abordagens básicas
utilizadas são as abordagens de Pittsburg e Michigan, que receberam os nomes das
universidades onde foram desenvolvidas.
Na abordagem de Pittsburg, a codificação é complexa, conforme o exemplo
mostrado na Figura 1, sendo necessário o uso de operadores mais complexos, visto que
cada indivíduo irá corresponder a um conjunto de regras solução para o problema
[Romão et al., 2000].
Tit = “Dr”
Idade > 40
Sexo = “M”
outras
condições
outras
regras
Figura 1. Cromossomo representando um conjunto de regras
[Romão et al., 2000, p. 6].
Na abordagem de Michigan, a codificação dos indivíduos é facilitada (Figura 2),
permitindo a construção de indivíduos mais simples e pequenos, porém com o problema
de que é mais difícil lidar com interações entre regras [Romão et al., 2005].
Artigos public > 10
Tit = “Mestre”
outras condições
Figura 2. Cromossomo representando uma regra
[Romão et al., 2000, p. 6].
A abordagem de Michigan é utilizada nos trabalhos de Lopes (1999) e Junior
Tenório (2002), em que um cromossomo representa uma regra de associação da forma
SE (A1 e A2 e ... An), ENTÃO P. O conjunto (A1 e A2 e ... An) representa os atributos de
predição e P, o valor da classe meta. Os atributos podem ser categóricos ou
quantitativos. Os primeiros representam um conjunto finito de valores ou valores
mapeados num conjunto de números inteiros (discretos) e só podem assumir um único
valor em um dado registro. Os segundos, também chamados de contínuos, constituem
um subconjunto de números reais. Dessa forma, o cromossomo do modelo desenvolvido
possui a representação mostrada na Figura 3 [Lopes, 1999].
7
Atributo 1
Atributo 2
mín
mín
máx
máx
Atributo N
= = = =
mín
máx
Limite superior
Valor máximo
Limite inferior
Valor mínimo
Figura 3. Representação do cromossomo para a tarefa de classificação
[Lopes, 1999, p. 69].
Conforme se observa na Figura 3, um gene representa um atributo de predição.
Cada gene possui dois campos: um valor mínimo e um valor máximo, que representam
os limites inferiores e superiores da faixa em que um atributo de predição contínuo está
inserido. No caso de atributos categóricos, o valor máximo não tem utilidade. Com essa
representação, as regras têm a seguinte forma:
SE [ (Atributo 1 min 1) e (Atributo 1 máx 1)
e (Atributo 2 min 2) e (Atributo 2 máx 2)
e (Atributo 3 = mín 3) ...
e (Atributo N min N) e (Atributo N máx N) ]
ENTÃO Atributo objetivo = P.
O atributo 3 é categórico, por isso não possui limite superior.
4. Trabalhos Correlatos
Os trabalhos envolvendo o uso de AG em MD têm sido voltados para as tarefas de
classificação e descrição de registros em bases de dados, para a seleção de atributos ou
modelagem de dependências e também para melhorar o desempenho em algoritmos de
clustering. A seguir, são relacionados alguns trabalhos que propõem abordagens do uso
de AG’s no processo de classificação em registros de bases de dados:
Lopes (1999) investiga a utilização de AG’s em MD partindo do princípio que o
processo de classificação no contexto de AG’s consiste na evolução de regras de
associação que melhor caracterizem, através da acurácia e abrangência, um determinado
grupo de registros do banco de dados. O autor define um modelo de AG para mineração
de dados e implementa uma ferramenta de MD (o Rule-Evolver) que fornece ao usuário
10 alternativas de funções de avaliação, além da escolha de operadores genéticos, dentre
outras facilidades. Diversos estudos de casos são realizados e são feitas análises
comparativas com outros métodos de extração de regras. A viabilidade da utilização de
AG em MD é comprovada, mas foi verificado que não há uma melhor função de
avaliação para um caso genérico, uma vez que esta é dependente do tipo de dados, isto
é, da aplicação em que se está trabalhando.
Carvalho e Freitas (2000) utilizam uma solução híbrida de AG e árvore de
decisão em um problema de MD, que se refere à presença de pequenas disjunções, isto
8
é, regras que cobrem um pequeno número de exemplos. Essas regras geralmente são
propensas a erros e contribuem para diminuir a acurácia de predição do sistema. Apesar
de cada pequena disjunção cobrir poucos exemplos da base de dados, o conjunto de
todas elas pode cobrir um grande número de exemplos, fato que foi constatado em
várias bases de dados. A solução consiste em classificar exemplos pertencentes a
grandes disjunções por regras produzidas pelo algoritmo de árvores de decisão C4.5,
enquanto que exemplos pertencentes a pequenas disjunções são classificados pelo AG
desenvolvido especificamente para esse fim. Os resultados demonstram que a acurácia
obtida pelo AG foi superior à obtida por três versões do C4.5.
Romão et al. (2004) propõem um AG projetado especificamente para a
descoberta de regras de predição difusas interessantes no sentido de serem novas e
surpreendentes para o usuário. A técnica consiste na adaptação de uma outra técnica
pouco explorada na literatura, baseada nas impressões gerais definidas pelo usuário
(conhecimento subjetivo), de maneira que uma regra de predição é considerada
interessante ou surpreendente não apenas por que é desconhecida ao usuário, mas
também contradiz suas hipóteses originais. Um protótipo implementa o AG proposto, o
qual foi aplicado sobre uma base real de dados de ciência e tecnologia. Este foi avaliado
e comparado com o algoritmo J4.8 de MD, uma variante do C4.5. Os resultados indicam
que a acurácia de predição obtida pelo AG proposto é similar à obtida pelo J4.8, mas no
primeiro caso, em geral, as regras descobertas possuem poucas condições, levando a
uma maior compreensibilidade do conhecimento descoberto. As regras encontradas pelo
AG foram consideradas mais interessantes pelos usuários.
5. Algoritmo Genético Proposto para a Descoberta de Regras em Mineração
de Dados
Nesta Seção, é proposto um AG para a descoberta de regras de predição em bases de
dados. Diferente dos trabalhos citados, em que cada indivíduo representa uma regra de
predição, aqui cada indivíduo representa um registro do banco de dados, de maneira
similar ao que é realizado pelas ferramentas de MD. Um dos problemas que pode
ocorrer neste caso diz respeito ao custo computacional da execução do AG para bases
de dados volumosas.
5.1. Representação do Indivíduo
Em MD, o algoritmo genético aplicado à tarefa de classificação pode ter seus indivíduos
representando apenas os antecedentes das regras de classificação. Neste caso, o AG será
executado para cada atributo meta do problema (o conseqüente da regra). Esta é a opção
adotada neste trabalho.
A Figura 4 ilustra a estrutura do cromossomo projetada nesta pesquisa. A
representação é binária e os atributos são todos categóricos. Se houver atributos
contínuos, estes devem ser discretizados.
9
Atributo 1
Atributo 2
Atributo N
valor1 valor2 valor3 valor1 valor2
1
0
0
0
1
valorN1
valorN2
1
0
= = =
Figura 4. Representação do cromossomo para a tarefa de classificação
pelo AG proposto.
Nessa representação, o alelo de um determinado gene recebe o bit “1” se o
atributo possuir um determinado valor e “0” se não possuir esse valor.
Exemplo 5.1. A base de dados Tempo, que armazena registros com dados
classificados contendo informações das condições do tempo para saber se uma pessoa
joga ou não joga futebol, possui os seguintes atributos de predição e seus respectivos
valores: estado do tempo (ensolarado, nublado, chuvoso), temperatura (quente, média e
fria), umidade (alta, normal), está ventando? (falso, verdadeiro). O atributo classe é:
joga? (sim, não). A codificação dos 14 registros dessa base de dados é mostrada na
Figura 5, sendo que os bits do atributo classe não serão codificados nos experimentos do
problema aqui tratado.
atributo
classe
atributos de predição
estado do tempo
temperatura
ensola- nubla- chuvoquente
rado
do
so
umidade
ventando?
média
fria
alta
normal
falso
verdadeiro
joga?
sim
não
1
0
0
1
0
0
1
0
1
0
0
1
1
0
0
1
0
0
1
0
0
1
0
1
0
1
0
1
0
0
1
0
1
0
1
0
0
0
1
0
1
0
1
0
1
0
1
0
0
0
1
0
0
1
0
1
1
0
1
0
0
0
1
0
0
1
0
1
0
1
0
1
0
1
0
0
0
1
0
1
0
1
1
0
1
0
0
0
1
0
1
0
1
0
0
1
1
0
0
0
0
1
0
1
1
0
1
0
0
0
1
0
1
0
0
1
1
0
1
0
1
0
0
0
1
0
0
1
0
1
1
0
0
1
0
0
1
0
1
0
0
1
1
0
0
1
0
1
0
0
0
1
1
0
1
0
0
0
1
0
1
0
1
0
0
1
0
1
Figura 5. Representação dos cromossomos da base de dados Tempo.
No problema desta pesquisa, parte-se da idéia que, se os registros da base de
dados forem vistos como regras, então, inicialmente, cada atributo representa uma
condição da regra. Desta forma, no Exemplo 5.1, o primeiro registro da base de dados é
lido da seguinte maneira:
10
SE o
e
e
e
tempo está ensolarado
a temperatura está quente
a umidade está alta
não está ventando,
ENTÃO a pessoa não joga.
Porém, nas regras extraídas pelas ferramentas de MD, vê-se que nem todos os
atributos aparecem como condições nas partes SE da regras obtidas, uma vez que nem
todos os atributos contribuem para o poder de predição de uma regra. Por exemplo, uma
regra encontrada por um algoritmo de MD pode ser:
SE o tempo está nublado
ENTÃO a pessoa joga.
Segundo os resultados obtidos no trabalho de Romão (2002), foi constatado que
regras com mais de três condições no antecedente tornam-se difíceis de serem
interpretadas pelos usuários. É o que costuma ocorrer na geração de regras de
decisões/árvores de decisão (produzidas pela tarefa de classificação) em muitos
algoritmos de MD, em que o grande número de regras geradas torna o conhecimento
bastante complexo para ser compreendido pelo usuário final do sistema. Um exemplo
disso é o resultado da mineração de dados mostrada no Anexo deste artigo.
Este fato motivou a modelagem do AG deste trabalho, cuja função de aptidão é
descrita a seguir.
5.2. Função de Aptidão
De acordo com o exposto na Seção 5.1, para obter regras com menos condições no
antecedente, é necessário minimizar esse número de condições, de forma a obter regras
mais simples.
Assim, em um primeiro estágio de pesquisa, este trabalho parte da idéia que a
aptidão de um indivíduo f(x) para o AG proposto é dada simplesmente pela somatória
do número de atributos de predição da base de dados (fórmula 5.1),
f(x) = no._atributos
(5.1)
significando que no início do processo uma regra possui o número máximo de
condições em seu antecedente. Portanto, todos os indivíduos iniciam com a mesma
aptidão, a qual vai sendo minimizada a cada geração. Dessa forma, os indivíduos, no
decorrer do processo, ao serem submetidos aos operadores do AG, vão apresentar
atributos que não possuem o bit “1” em nenhum valor para um dado atributo,
significando que esse atributo não é relevante para que o conseqüente da regra seja de
determinada classe. O melhor indivíduo do AG será aquele que obtiver o valor mínimo
de aptidão. Este valor mínimo muitas vezes vai chegar a zero, mas só interessa como
regra o indivíduo que obtiver o valor mínimo igual a 1 (um).
Segundo a função de aptidão proposta, no exemplo da base de dados Tempo,
todos os indivíduos têm aptidão igual a 4 e iniciam com a mesma probabilidade de
serem selecionados. No experimento 1, são apresentadas as regras encontradas para
esses dados.
11
5.3. Seleção de Indivíduos
O método de seleção adotado nesta pesquisa foi a seleção estocástica, uma vez que esta
apresentou bons resultados no trabalho de Morais e Domingues (2005), em um AG
desenvolvido para um problema com codificação binária.
No método de seleção estocástico, os indivíduos são mapeados em segmentos
contínuos em uma linha, em que cada indivíduo corresponde a um segmento de
tamanho proporcional à sua aptidão. O número de indivíduos é representado por
ponteiros distribuídos em uma linha e igualmente espaçados. A posição do primeiro é
dada pelo número aleatório gerado na faixa [0,1/Nponteiro] [Thomaz, 2005].
Por exemplo, para selecionar 6 indivíduos, a distância entre os ponteiros é de 1/6
= 0.167. Na Figura 6, observa-se a escolha de um número randômico com valor 0.1 no
intervalo [0, 0.167], indicando o primeiro indivíduo selecionado. A partir daí, verificase os outros indivíduos selecionados: 1, 2, 3, 4, 6 e 8.
Figura 6. Seleção estocástica.
Fonte: Thomaz et al., 2005, p. 9.
5.4. Cruzamento
Nesta etapa, partes de dois cromossomos genitores são trocadas a partir de uma posição
escolhida aleatoriamente (ponto de corte), produzindo dois indivíduos filhos. A
proporção de pais submetidos ao cruzamento durante uma geração é controlada pela
probabilidade de cruzamento, que determina a freqüência que o cruzamento é invocado.
Como técnica de cruzamento, adotou-se o cruzamento de um ponto, ilustrado na
Figura 7.
Antes do cruzamento
ponto de corte
Pai 1
1
0
1
0
0
1
1
1
0
1
Pai 2
0
1
1
1
0
1
0
1
1
0
Após o cruzamento
ponto de corte
Pai 1
0
1
1
1
0
1
1
1
0
1
Pai 2
1
0
1
0
0
1
0
1
1
0
Figura 7. Cruzamento de um ponto.
12
5.5. Mutação
A mutação é o processo randômico, em que um gene é trocado por outro para produzir
um novo indivíduo a partir de um único pai. Costuma ser aplicada com uma taxa de
probabilidade baixa (p. ex., 0.08).
A Figura 8 ilustra o processo de mutação.
ponto de mutação
0
1
1
1
0
1
1
1
0
1
1
0
1
0
1
1
0
1
1
0
Figura 8. Mutação.
5.6. Outras técnicas utilizadas no AG
5.6.1. Normalização linear
Esta técnica é utilizada quando a população está muito achatada, isto é, a média da
população está bem próxima do melhor e do pior indivíduo. Com esta técnica, os
indivíduos são colocados em ordem decrescente de avaliação e depois são numerados de
cima para baixo, da seguinte forma: o indivíduo com a menor aptidão recebe um valor
mínimo que é somado a uma taxa de incremento, crescendo linearmente até o valor
máximo. Depois, os valores que cada indivíduo recebeu são somados. Para o cálculo da
probabilidade de seleção de cada indivíduo, estes valores individuais são divididos pelo
valor da soma destes.
5.6.2. Reprodução por Estado Estacionário
A Reprodução por Estado Estacionário ou Steady State consiste na substituição parcial
de indivíduos a cada geração, resultando em uma técnica mais elitista: os bons
indivíduos são preservados garantindo maiores chances de reprodução. O parâmetro
GAP é utilizado para informar ao algoritmo a fração da população que é trocada.
5.7. Ferramenta utilizada para a construção do AG
Para a fase de programação do algoritmo genético, utilizou-se a ferramenta Matlab 6.5
[The Mathworks, Inc, 2002]. Este software possui diversas funções que facilitam
sobremaneira a programação de AG’s.
Algumas ferramentas (toolboxes) estão disponíveis na Web, implementando uma
variedade de métodos para os AG’s. Dentre estas, foram utilizadas neste trabalho, como
auxílio na geração do código-fonte, as toolboxes: Genetic Algorithm Toolbox
[Chipperfield et al., 2005] e AGBIN [Thomas et al., 2005].
6. Experimentos Realizados
Foram realizados dois experimentos com o AG proposto neste artigo. Ambos utilizaram
dados públicos. O primeiro utiliza os dados do arquivo Weather (aqui chamado de
Tempo), o qual já foi mostrado na Seção 5.1 deste trabalho, que é fornecido como
exemplo didático na ferramenta Weka de mineração de dados. O segundo utiliza a base
13
de dados pública Nursey (aqui chamada de Creche), obtida do repositório de dados
públicos disponível em www.ics.uci.edu/~mlearn/MLSummary.html.
6.1. Experimento 1: Base de dados Tempo
A base de dados Tempo possui as seguintes características: 14 instâncias, 4 atributos de
predição com os seguintes valores: estado do tempo (ensolarado, nublado, chuvoso),
temperatura (quente, média, fria), umidade (alta, normal), está ventando? (falso,
verdadeiro) e um atributo classe ou atributo meta: joga? com as classes: sim, não.
6.1.1. Resultados obtidos com o AG
Este experimento foi realizado para a indução de regras da classe sim. O AG para
minerar a base de dados Tempo foi configurado com os seguintes parâmetros:
Número de indivíduos = 9
Comprimento do cromossomo = 10
Número máximo de gerações (critério de parada) = 30
GAP entre gerações = 0.8
Probabilidade de cruzamento = 0.8
Probabilidade de mutação = 0.01
As regras mais simples encontradas são caracterizadas pelos melhores
indivíduos das 30 gerações de cada experimento realizado. Abaixo, serão listadas as
regras que apareceram com maior freqüência nos experimentos, as quais contém no
máximo duas condições e a classe desejada é a classe sim. A confiança da regra é
calculada com a utilização da fórmula 2.1:
SE estado do tempo=nublado e está ventando?=falso,
ENTÃO joga=sim. (conf = 50%)
SE estado do tempo=nublado, ENTÃO joga=sim. (conf = 100%)
SE estado do tempo=nublado e umidade=normal, ENTÃO joga=sim.
(conf = 50%)
6.1.2. Resultados obtidos com o algoritmo ID3 de MD
A mineração de dados realizada com o algoritmo ID3 na ferramenta Weka, gerou uma
árvore de decisão com as regras abaixo. Nas regras obtidas pelo ID3, aparece a
classificação para as duas classes da base de dados. Nesta mineração, dois registros
foram classificados errados, um de cada classe. Para efeito de comparação com o
resultado do AG, o valor da confiança para a classe sim apresentado é calculado com a
utilização da fórmula 2.1:
SE estado do tempo = ensolarado
| E umidade=alta ENTÃO joga=não
| E umidade=normal ENTÃO joga=sim (conf = 40%)
SE estado do tempo=nublado ENTÃO joga=sim (conf = 100%)
SE estado do tempo=chuvoso
| está ventando?=verdadeiro ENTÃO joga=não
| está ventando?=falso ENTÃO joga=sim (conf = 75%)
14
Os resultados mostram que nas duas situações avaliadas, foi encontrada uma
regra com 100% de confiança ou acurácia. O AG encontrou duas regras com 50% de
confiança e o ID3 encontrou uma regra com confiança de 40% e outra com confiança de
75%. Como a base de dados é muito pequena, é preciso realizar experimentos em uma
base maior, para se obter conclusões mais precisas.
6.2. Experimento 2: Base de dados Creche
A base de dados Creche (Nursery Database) foi criada por Vladislav Rajkovic et al. em
junho de 1997 e pertence a Marko Bohanec e Blaz Zupan [Olave et al. 1989]. Os dados
fazem parte de uma pesquisa que os utilizou para selecionar crianças para serem
admitidas em uma creche nos anos 80, na Ljubljna, Slovenia.
Possui as seguintes características:
Número de instâncias: 12.960 (estas instâncias cobrem completamente o
espaço de atributos)
Número de atributos: 8
Valor dos atributos:
parents
usual, pretentious, great_pret
has_nurs
proper, less_proper, improper, critical, very_crit
form
complete, completed, incomplete, foster
children
1, 2, 3, more
housing
convenient, less_conv, critical
finance
convenient, inconv
social
non-prob, slightly_prob, problematic
health
recommended, priority, not_recom
Atributos ausentes: nenhum
Distribuição dos valores do atributo classe (número de instâncias por classe)
Classe
N
N[%]
---------------------------------------------------------------not_recom
4320
(33.333 %)
recommend
2
( 0.015 %)
very_recom
328
( 2.531 %)
priority
4266
(32.917 %)
spec_prior
4044
(31.204 %)
6.2.1. Resultados obtidos com o AG
Inicialmente, os dados foram separados conforme a classe, para que o AG descobrisse
regras para dados de cada classe, separadamente.
Não foi possível realizar o processamento do AG para as classes com mais de
4.000 registros, dado a lentidão do sistema no Matlab. Assim, procedeu-se o
experimento somente para a classe very_recom que possui 328 registros.
O AG para minerar a base de dados Creche foi configurado com os seguintes
parâmetros:
Número de indivíduos = 328
Comprimento do cromossomo = 27
15
Número máximo de gerações (critério de parada) = 30
GAP entre gerações = 0.8
Probabilidade de cruzamento = 0.8 / 0.65 (foram testados os dois valores)
Probabilidade de mutação = 0.01
As regras mais simples encontradas são as listadas abaixo, que possuem no
máximo três condições no antecedente da regra e a classe desejada é a classe
very_recom. A confiança da regra é calculada com a utilização da fórmula 2.1:
SE has_nurs=less_proper e finance=convenient e health=recommend,
ENTÃO class=very_recom. (conf = 66%)
SE social=non_prob e health=recommend, ENTÃO class=very_recom.
(conf = 100%)
SE form=complete, ENTÃO class=very_recom.( conf = 100%)
SE finance=convenient, ENTÃO class=very_recom. (conf = 100%)
SE housing=critical e finance=inconv e health=recommend, ENTÃO
class=very_recom. (conf = 50%)
SE parents=usual e children=1, ENTÃO class=very_recom. (conf
= 59%)
SE children=1, ENTÃO class=very_recom. (conf = 100%)
SE finance=convenient, ENTÃO class=very_recom. (conf = 100%)
SE parents=usual e social=slightly_prob, ENTÃO class=very_recom.
(conf = 59%)
SE parents=pretentious e social==slightly_prob, ENTÃO
class=very_recom. (conf = 50%)
SE parents=usual, ENTÃO class=very_recom. (conf = 100%)
6.2.2. Resultados obtidos com o algoritmo J48 de MD
Para essa base de dados, a mineração de dados foi realizada com o algoritmo J48 do
Weka, o qual permite informar como parâmetro um grau de confiança maior, de forma a
se obter só as regras de maior acurácia. Mesmo assim, o número de regras geradas foi
enorme, conforme se vê no Anexo deste trabalho. A árvore de decisão encontrada é de
difícil interpretação para um usuário comum.
Para a classe very_recom, 290 registros foram classificados corretamente e 38
registros foram classificados incorretamente. O resultado geral teve uma taxa de erro de
apenas 1.2114 % e uma taxa de acerto de 98.7886 %.
Os resultados deste experimento são mais complexos de se analisar, porém
algumas das regras encontradas com o AG estão de acordo com as da árvore de decisão
gerada pelo J48. Para uma melhor avaliação, é importante que se tenha a opinião do
usuário ou especialista dos dados analisados, pois a avaliação subjetiva muitas vezes
conta mais do que a avaliação objetiva em problemas de mineração de dados.
16
7. Conclusões e Sugestões para Trabalhos Futuros
Esta pesquisa investigou o uso de AG para a indução de regras de predição simples em
problemas de mineração de dados.
O algoritmo proposto pode ser considerado bem sucedido, no sentido de que é
um passo inicial para uma futura pesquisa na área, visto que os resultados encontrados
pelo menos não se revelaram absurdos.
O maior problema encontrado, e que já era esperado, foi o alto custo
computacional requerido pelo AG programado em Matlab que inviabilizou o
processamento de grandes quantidades de dados.
Como sugestões para trabalhos futuros, ficam:
A realização de novos experimentos em uma ferramenta de AG que seja
mais escalável, como por exemplo o Rule Evolver [Lopes, 1999] ou a
construção de uma nova ferramenta de AG adequada para a questão de
grande quantidade de dados, característica principal dos problemas de
mineração de dados;
a codificação do cromossomo de maneira que todas as classes possam ser
avaliadas ao mesmo tempo, o que facilitará a utilização do sistema;
a realização de novos experimentos que aprofundem a proposta aqui descrita
para que se tenha uma idéia mais clara de sua viabilidade ou não.
Referências
Bueno, R., Traina, A. J. M. e Traina Jr, C. (2005). Algoritmos Genéticos para Consultas
por
Similaridade
Aproximadas.
Disponível
em:
<http://www.sbbdsbes2005.ufu.br/arquivos/artigo-13-BuenoTraina.pdf >.
Carvalho, D.R.; Freitas, A.A. (2000). A hybrid decision tree/genetic algorithm for
coping with the problem of small disjuncts in data mining. Proc. Genetic and
Evolutionary Computation (GECCO-2000), 1061-1068, Las Vegas, NV, USA.
Chipperfield, A., Fleming, P., Pohlheim; H., Fonseca, C. Genetic Algorithm Toolbox –
For Use with Matlab – User’s Guide. Department of Automatic Control and Systems
Engineering
of
The
University
of
Sheffield.
Disponível
em
<http://www.shef.ac.uk/acse/research/ecrg/gat.html>.
Fayyad, Usama M., Piatetsky-Shapiro, Gregory and Smyth, Padhraic. (1996). From
Data Mining to Knowledge Discovery: An Overview. In: Fayyad, Usama M.,
Piatetsky-Shapiro, Gregory, Smyth, Padhraic and Uthurusamy, Ramasamy.
Advances in Knowledge Discovery and Data Mining. MIT Press, 611 p. p. 1-34.
Fertig, C.S., Freitas, A.A., Arruda, L.V.R., Kaestner, C. (1999). A Fuzzy Beam-Search
Rule Induction Algorithm. Principles of Data Mining and Knowledge Discovery:
Proc. 3rd European Conf. (PKDD-99) Lecture Notes in Artificial Intelligence 1704,
341- 347. Springer-Verlag.
Han, Jiawei and Kamber, Micheline. (2001). Data mining: concepts and techniques.
Morgan Kaufmann Publishers.
17
Junior Tenório, N. N. e Barreto, J.M. (2002). Algoritmos Genéticos para extração da
qualidade de serviços prestados por clinicas odontológicas. I2TS’2002 –
International Information Technology Symposium, Florianópolis, SC. Disponível
em: <http://www.inf.ufsc.br/~barreto/artigos/Junior02.pdf>.
Lopes, Carlos Henrique P. (1999). Classificação de Registros em Banco de Dados por
Evolução de Regras de Associação utilizando Algoritmos Genéticos. Dissertação de
Mestrado. PUC /Rio, Rio de Janeiro.
Luger, George F. (2004). Inteligência Artificial: estruturas e estratégias para a solução
de problemas complexos. Bookmann. Porto Alegre.
Morais, L. e Domingues, M. (2005). Algoritmo Genético para maximização da Função
F6. Trabalho apresentado na disciplina de Computação Evolucionária.
PPGEE/UFPA, Belém PA.
Olave, M., Rajkovic, V. e Bohanec, M.(1989). An application for admission in public
school systems. In (I. Th. M. Snellen and W. B. H. J. van de Donk and J.-P.
Baquiast, editors) Expert Systems in Public Administration, pages 145-160. Elsevier
Science Publishers (North Holland)}, 1989.
Romão, W., Freitas, A. A. e Pacheco, R. C. S. (2000). Uma revisão de abordagens
genético-difusas para descoberta de conhecimento em banco de dados. Revista Acta
Scientiarum. ISSN 1415-6814. Pró-Reitoria de Pesquisa e Pós-Graduação,
Universidade Estadual de Maringá. Volume 22, Number 5, 1347-1359. Disponível
em: <http://www.cs.kent.ac.uk/people/staff/aaf/pub_papers.dir/Acta-Scientiarum.pdf
>.
Romão, W., Freitas, A. A. and Gimenes, I. M. S. (2004). Discovering Interesting
Knowledge from a Science & Technology Database with a Genetic Algorithm.
Disponível em: <http://www.cs.kent.ac.uk/people/staff/aaf/pub_papers.dir/AppliedSoft-Comp-J-Wesley-2004.pdf>.
Romão, W., Freitas, A. A. e Pacheco, R. C. S. (2002). Descoberta de Conhecimento
Relevante em Banco de Dados sobre Ciência e Tecnologia. Tese de doutorado.
UFSC/Florianópolis, Santa Catarina.
The Mathworks, Inc. (2002). Matlab. The language of technical computing. Version
6.5.0.1. 18091 3a Release 13.
Thomaz, A., Ferreira, B., Lobo Jr., H., Barbosa, L., Leone Filho, M., Silva, M., Quispe,
N.
(2005).
Tutorial
Toolbox
AGBIN.
Disponível
em
<ftp://ftp.dca.fee.unicamp.br/pub/docs/vonzuben/ia707_1s04/projetos/binario.zip>.
Witten, Ian H. and Frank, Eibe. (2005). Data Mining: Practical machine learning tools
and techniques, 2nd Edition, Morgan Kaufmann, San Francisco.
Anexo
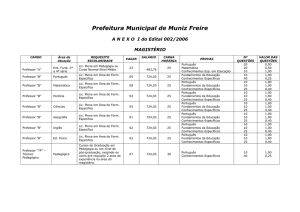
Resultado da mineração dos dados da base Creche com o algoritmo J48 do Weka:
=== Run information ===
Scheme:
Relation:
Instances:
Attributes:
Test mode:
weka.classifiers.trees.J48 -C 0.7 -M 2
nursery
12960
9
parents
has_nurs
form
children
housing
finance
social
health
class
10-fold cross-validation
=== Classifier model (full training set) ===
J48 pruned tree
-----------------health = recommended
|
has_nurs = proper
|
|
parents = usual
|
|
|
social = nonprob
|
|
|
|
housing = convenient
|
|
|
|
|
finance = convenient: very_recom (16.0/1.0)
|
|
|
|
|
finance = inconv
|
|
|
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
|
|
children = 3.0: priority (4.0)
|
|
|
|
|
|
children = more: priority (4.0)
|
|
|
|
housing = less_conv
|
|
|
|
|
children = 1.0
|
|
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
|
|
form = incomplete: very_recom (2.0)
|
|
|
|
|
|
form = foster: priority (2.0)
|
|
|
|
|
children = 2.0
|
|
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
|
|
form = foster: priority (2.0)
|
|
|
|
|
children = 3.0: priority (8.0)
|
|
|
|
|
children = more: priority (8.0)
|
|
|
|
housing = critical
|
|
|
|
|
form = complete
|
|
|
|
|
|
children = 1.0: very_recom (2.0)
|
|
|
|
|
|
children = 2.0: priority (2.0)
|
|
|
|
|
|
children = 3.0: priority (2.0)
|
|
|
|
|
|
children = more: priority (2.0)
|
|
|
|
|
form = completed: priority (8.0)
|
|
|
|
|
form = incomplete: priority (8.0)
|
|
|
|
|
form = foster: priority (8.0)
|
|
|
social = slightly_prob
|
|
|
|
housing = convenient
|
|
|
|
|
finance = convenient: very_recom (16.0/1.0)
|
|
|
|
|
finance = inconv
|
|
|
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
|
|
children = 3.0: priority (4.0)
|
|
|
|
|
|
children = more: priority (4.0)
|
|
|
|
housing = less_conv
|
|
|
|
|
children = 1.0
19
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: very_recom (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 2.0
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 3.0: priority (8.0)
|
|
|
children = more: priority (8.0)
|
|
housing = critical
|
|
|
form = complete
|
|
|
|
children = 1.0: very_recom (2.0)
|
|
|
|
children = 2.0: priority (2.0)
|
|
|
|
children = 3.0: priority (2.0)
|
|
|
|
children = more: priority (2.0)
|
|
|
form = completed: priority (8.0)
|
|
|
form = incomplete: priority (8.0)
|
|
|
form = foster: priority (8.0)
|
social = problematic: priority (96.0)
parents = pretentious
|
social = nonprob
|
|
housing = convenient
|
|
|
finance = convenient: very_recom (16.0)
|
|
|
finance = inconv
|
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
children = 3.0: priority (4.0)
|
|
|
|
children = more: priority (4.0)
|
|
housing = less_conv
|
|
|
children = 1.0
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: very_recom (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 2.0
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 3.0: priority (8.0)
|
|
|
children = more: priority (8.0)
|
|
housing = critical
|
|
|
form = complete
|
|
|
|
children = 1.0: very_recom (2.0)
|
|
|
|
children = 2.0: priority (2.0)
|
|
|
|
children = 3.0: priority (2.0)
|
|
|
|
children = more: priority (2.0)
|
|
|
form = completed: priority (8.0)
|
|
|
form = incomplete: priority (8.0)
|
|
|
form = foster: priority (8.0)
|
social = slightly_prob
|
|
housing = convenient
|
|
|
finance = convenient: very_recom (16.0)
|
|
|
finance = inconv
|
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
children = 3.0: priority (4.0)
|
|
|
|
children = more: priority (4.0)
|
|
housing = less_conv
|
|
|
children = 1.0
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: very_recom (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 2.0
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
form = foster: priority (2.0)
|
|
|
children = 3.0: priority (8.0)
|
|
|
children = more: priority (8.0)
|
|
housing = critical
20
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
form = complete
|
|
|
|
|
children = 1.0: very_recom (2.0)
|
|
|
|
|
children = 2.0: priority (2.0)
|
|
|
|
|
children = 3.0: priority (2.0)
|
|
|
|
|
children = more: priority (2.0)
|
|
|
|
form = completed: priority (8.0)
|
|
|
|
form = incomplete: priority (8.0)
|
|
|
|
form = foster: priority (8.0)
|
|
social = problematic: priority (96.0)
|
parents = great_pret
|
|
social = nonprob: priority (96.0)
|
|
social = slightly_prob: priority (96.0)
|
|
social = problematic
|
|
|
housing = convenient
|
|
|
|
finance = convenient: priority (16.0)
|
|
|
|
finance = inconv
|
|
|
|
|
children = 1.0: priority (4.0/1.0)
|
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
|
children = 3.0: spec_prior (4.0)
|
|
|
|
|
children = more: spec_prior (4.0)
|
|
|
housing = less_conv
|
|
|
|
children = 1.0
|
|
|
|
|
form = complete: priority (2.0)
|
|
|
|
|
form = completed: priority (2.0)
|
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
|
form = foster: spec_prior (2.0)
|
|
|
|
children = 2.0
|
|
|
|
|
form = complete: priority (2.0)
|
|
|
|
|
form = completed: priority (2.0)
|
|
|
|
|
form = incomplete: spec_prior (2.0)
|
|
|
|
|
form = foster: spec_prior (2.0)
|
|
|
|
children = 3.0: spec_prior (8.0)
|
|
|
|
children = more: spec_prior (8.0)
|
|
|
housing = critical
|
|
|
|
form = complete
|
|
|
|
|
children = 1.0: priority (2.0)
|
|
|
|
|
children = 2.0: spec_prior (2.0)
|
|
|
|
|
children = 3.0: spec_prior (2.0)
|
|
|
|
|
children = more: spec_prior (2.0)
|
|
|
|
form = completed: spec_prior (8.0)
|
|
|
|
form = incomplete: spec_prior (8.0)
|
|
|
|
form = foster: spec_prior (8.0)
has_nurs = less_proper
|
parents = usual
|
|
social = nonprob
|
|
|
housing = convenient
|
|
|
|
finance = convenient: very_recom (16.0)
|
|
|
|
finance = inconv
|
|
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
|
|
children = 3.0: priority (4.0)
|
|
|
|
|
children = more: priority (4.0)
|
|
|
housing = less_conv
|
|
|
|
children = 1.0
|
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
|
form = incomplete: very_recom (2.0)
|
|
|
|
|
form = foster: priority (2.0)
|
|
|
|
children = 2.0
|
|
|
|
|
form = complete: very_recom (2.0)
|
|
|
|
|
form = completed: very_recom (2.0)
|
|
|
|
|
form = incomplete: priority (2.0)
|
|
|
|
|
form = foster: priority (2.0)
|
|
|
|
children = 3.0: priority (8.0)
|
|
|
|
children = more: priority (8.0)
|
|
|
housing = critical
|
|
|
|
form = complete
|
|
|
|
|
children = 1.0: very_recom (2.0)
|
|
|
|
|
children = 2.0: priority (2.0)
|
|
|
|
|
children = 3.0: priority (2.0)
|
|
|
|
|
children = more: priority (2.0)
|
|
|
|
form = completed: priority (8.0)
|
|
|
|
form = incomplete: priority (8.0)
|
|
|
|
form = foster: priority (8.0)
21
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
social = slightly_prob
|
housing = convenient
|
|
finance = convenient: very_recom (16.0)
|
|
finance = inconv
|
|
|
children = 1.0: very_recom (4.0/1.0)
|
|
|
children = 2.0: priority (4.0/2.0)
|
|
|
children = 3.0: priority (4.0)
|
|
|
children = more: priority (4.0)
…………………………seccionado………………………………………
|
has_nurs = very_crit
|
|
form = complete
|
|
|
children = 1.0
|
|
|
|
housing = convenient
|
|
|
|
|
finance = convenient: priority (9.0)
|
|
|
|
|
finance = inconv: spec_prior (9.0)
|
|
|
|
housing = less_conv: spec_prior (18.0)
|
|
|
|
housing = critical: spec_prior (18.0)
|
|
|
children = 2.0: spec_prior (54.0)
|
|
|
children = 3.0: spec_prior (54.0)
|
|
|
children = more: spec_prior (54.0)
|
|
form = completed: spec_prior (216.0)
|
|
form = incomplete: spec_prior (216.0)
|
|
form = foster: spec_prior (216.0)
health = not_recom: not_recom (4320.0)
Number of Leaves
:
Size of the tree :
680
944
Time taken to build model: 6.41 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances
Incorrectly Classified Instances
Kappa statistic
Mean absolute error
Root mean squared error
Relative absolute error
Root relative squared error
Total Number of Instances
12803
157
0.9823
0.0051
0.0596
1.8847 %
16.1206 %
12960
98.7886 %
1.2114 %
=== Detailed Accuracy By Class ===
TP Rate
0
0.982
1
0.884
0.99
FP Rate
0
0.009
0
0.003
0.004
Precision
0
0.981
1
0.871
0.992
Recall
0
0.982
1
0.884
0.99
F-Measure
0
0.982
1
0.877
0.991
=== Confusion Matrix ===
a
b
c
0
0
0
0 4191
0
0
0 4320
0
38
0
0
42
0
d
e
2
0
41
34
0
0
290
0
0 4002
|
|
|
|
|
<-- classified as
a = recommend
b = priority
c = not_recom
d = very_recom
e = spec_prior
Class
recommend
priority
not_recom
very_recom
spec_prior