Janete Pereira Amador
1
1 Introdução
Muitas situações cotidianas podem ser usadas como experimento que dão
resultados correspondentes a algum valor, e tais situações podem ser descritas por uma
variável aleatória. A palavra aleatória indica que só conhecemos aquele valor depois do
experimento ter sido realizado. Desta forma, defini-se variável aleatória como sendo uma
função que associa números reais aos eventos de um espaço amostral, ou seja, os
resultados do experimento aleatório são dados numéricos.
Usa-se as letras maiúscula (X, Y, Z....) para designar as variáveis aleatórias, e
minúsculas (x, y, z.....) para indicar particulares valores dessas variáveis.
As variáveis aleatórias podem ser discreta e contínuas e o seu comportamento pode
ser descrito por uma distribuição de probabilidade. No caso discreto, a distribuição de
probabilidade pode ser caracterizada por uma função de probabilidade, que indica
diretamente as probabilidades associada a cada valor. No caso contínuo, a distribuição é
caracterizada pela função densidade de probabilidade.
Uma Variável Aleatória é uma variável (geralmente representada por X) que tem um valor
numérico único (determinado aleatoriamente) para cada resultado de um experimento
2 Variáveis Aleatórias Discretas (VAD)
Uma variável aleatória tem comportamento discreto quando ela admite um número
finito de valores ou tem uma quantidade enumerável de valores (admite apenas valores
inteiros).
A definição de uma VAD só fica completa a partir do momento em que se define a
função de probabilidade da variável aleatória X. Uma função de probabilidade é a função
que associa a cada valor assumido pela variável aleatória a probabilidade do evento
correspondente, ou seja:
Seja X uma variável aleatória discreta. Portanto, o contradomínio de X será
formado por um número finito ou enumerável de valores x1; x2;.........A cada possível
resultado xi, associaremos um número p(xi) = P(X = xi), i = 1; 2; 3;......, denominado
probabilidade de xi. Ou seja
Os números p(xi) devem satisfazer às seguintes condições:
a) p( xi ) 0, i ;
n
b) p ( xi ) 1
i 1
Dessa forma função p, definida acima, é denominada função de probabilidade da
variável aleatória X e a coleção de pares [xi; p(xi)] i = 1; 2;..........., é denominada
distribuição de probabilidade de X.
Uma distribuição de probabilidades é uma distribuição de freqüências relativas para os
resultados de um espaço amostral; mostra a proporção das vezes em que a variável
aleatória tende a assumir cada um dos diversos valores.
Janete Pereira Amador
2
Ex1: Lançam-se dois dados. Seja a v.a. X: soma das faces. Determinar a distribuição de
probabilidade da variável aleatória X.
a) O espaço amostral do experimento corresponde a:
b) O contradomínio de X é dado por:
c)A distribuição de probabilidade de X é dado por:
d) A representação gráfica desta distribuição de probabilidade equivale a:
2.1 Grandezas Características
As variáveis aleatórias podem ser caracterizadas por uma grandeza de tendência
central (média, moda, mediana) e outra de dispersão. A medida caracterizada como
grandeza de tendência central é uma média ponderada que recebe o nome particular de
esperança matemática (ou valor esperado); as grandezas de dispersão são a variância e o
desvio- padrão.
2.1.1 Valor esperado – E(X)
Seja X uma VAD, seja p(xi) = P(X=xi) onde p é a função de probabilidade de X.
Defini-se valor esperado ou esperança matemática de X anotado por E(X) da seguinte
forma.
n
E(X) xi p ( xi )
i 1
E(X) é a média ponderada dos valores de X, onde as ponderações são as
probabilidades de cada xi.
Diz-se também que E(X) é a media da distribuição de probabilidade da variável
aleatória X, algumas vezes anotada por . Se X puder assumir “n” valores igualmente
prováveis.
Ex2: Considere a variável aleatória definida no Ex1. Calcule a E(X).
2.1.2 Variância – V(X)
A variância de uma VAD pode ser definida como a média ponderada das diferenças
ao quadrado entre cada resultado possível e sua média aritmética, sendo os pesos as
probabilidades de cada um dos respectivos resultados. Assim a variância da variável
aleatória discreta X pode ser expressa da seguinte maneira:
n
V ( X ) ( xi ) 2 P( xi ) onde :
I 1
X = variável aleatória discreta de interesse
xi = iésimo resultado de x
P(xi) = probabilidade de ocorrência do iésimo resultado de x
i= 1,2,3......,n
Janete Pereira Amador
3
A formula mais usual
2
V ( X ) xi . p i E ( X ) 2 .
para
se
calcular
a
variância
corresponde
a:
Algumas vezes a V(X) é anotada por 2 . A raiz quadrada positiva da variância é
denominada desvio padrão e é anotado por ( X ) V ( X ) .
Ex3: Considere a variável aleatória definida no Ex2. Calcule a V(X) e o (X )
Exercícios:
1. A empresa Equilibrada S:A vende três produtos, cujos lucros e as probabilidades de
venda estão anotadas a seguir:
Produto
Lucro unitário (US$)
Probabilidade de venda
(%)
A
15
20
B
20
30
C
10
50
Pede-se calcular:
a) o lucro médio por unidade vendida:
b) o desvio padrão:
2. Um empreiteiro faz as seguintes estimativas para o prazo de execução de uma obra:
Prazo de execução (dias)
Probabilidade de execução (%)
10
30
15
20
22
50
O prazo esperado para execução da obra e o desvio padrão, de acordo com estas
estimativas são:
3. Um investidor julga que tem 0,40 de probabilidade de ganhar $ 25.000,00 e 0, 60 de
probabilidade de perder $ 15.000,000 num investimento . Seu ganho esperado é:
4. Se jogarmos um dado equilibrado qual o valor esperado numa jogada?
5. Achar a esperança e variância das seguintes distribuições:
X
fi
X
-5
2
2
-4
4
3
1
8
11
2
7
fi
1/3
1/2
1/6
Janete Pereira Amador
4
2.2 Distribuições de Probabilidades para VAD
Quando estudamos fenômenos observáveis o que se verifica é se este se
adapta as condições de determinado modelo probabilístico conhecido, desta forma torna-se
bem mais fácil descrever o comportamento do fenômeno. Assim nesta seção irmos estudar
alguns desses modelos, procurando enfatizar as condições em que eles aparecem, sua
função de probabilidade, parâmetros e como encontrar as probabilidades. Alguns modelos
são mais importantes devido ao seu maior uso. No caso de variáveis aleatórias discretas as
distribuições mais importantes são:
a) a distribuição de Bernoulli;
b) a distribuição Binomial;
c) a distribuição de Poisson;
d) a distribuição geométrica;
e) a distribuição hipergeométrica.
2.2.1 Distribuição Binomial
Consideramos n tentativas independentes, de um experimento aleatório. Cada
tentativa admite dois resultados: sucesso com probabilidade p (quando ocorre o evento
que estamos interessados) e fracasso com probabilidade q (quando o evento não ocorre),
logo a probabilidade total de fracasso ou sucesso p q 1 sendo assim:
a probabilidade de fracasso q 1 p
Um experimento binomial deve satisfazer as seguintes condições:
1) O experimento deve comportar um número fixo de provas
2) As provas devem ser independentes, isto é, o resultado de qualquer prova não afeta as
probabilidades das outras provas.
3) Cada prova deve ter todos os resultados classificados em duas categorias.
4) As probabilidades devem permanecer constantes para cada prova
A probabilidade de ocorrer k sucessos em n provas será:
P(X = k) =
C nk =
C nk
pk qn-k
sendo k = 0, 1, 2, 3, …, n
n!
, que é a fórmula do Binômio de Newton (p + q)n, daí o nome Binomial.
k! n k
Desta forma tem-se:
n!
. p x .q n x para x = 1, 2, .................., n
n x ! x!
com
n número de provas
x
número de sucessos em n provas
p probabilidade de sucesso em qualquer prova
q
probabilidade de falha (fracasso) em qualquer prova ( q 1 p )
Parâmetros da distribuição:
Média, Variância e Desvio padrão da distribuição binomial
Média ou valor esperado E(X)= n. p
Variância V(X)= 2 n. p.q
Px
Janete Pereira Amador
5
Desvio padrão n. p.q
Ex: Dado que 10% população são canhotos, suponha que se queira achar a probabilidade
de obter exatamente três estudantes canhotos em uma turma de 15 estudantes. Isso se deve
ao fato que algumas carteiras são adaptadas para estudantes canhotos, e a probabilidade
resultante poderia afetar o número de tais carteiras a serem encomendadas para as salas de
aulas. Calcule também a E(X), V(X) e o .
Solução:
Satisfazendo as condições para ocorrência de um experimento binomial verifica-se que:
1. O número de provas é fixo 15.
2. As provas são independentes, porque o fato de um estudante ser canhoto ou destro
não afeta a probabilidade de outro estudante ser canhoto.
3. Cada prova tem duas categorias de resultado: o estudante é canhoto ou não é.
4. A probabilidade de um estudante ser canhoto (sucesso) é 0,1 e, assim, p =0,1
5. A probabilidade de falha (não-canhoto) é 0,9, logo q = 0,9.
Calculando a probabilidade de 3 estudantes canhotos:
Exercícios
1. A probabilidade de um cliente aleatoriamente escolhido faça uma compra é 0,20. Se
um vendedor visita seis clientes, a probabilidade de que ele fará exatamente quatro
compras será.
R:0,01536
2. Sabe-se que a probabilidade de um estudante que entrar na Universidade se formar é
0,3. Determine de que dentre 6 estudantes escolhidos aleatoriamente:
a) Nenhum se forme R: 0,11765
b) Exatamente 4 se formem R: 0,0595
c) Pelo menos 3 se formem R: 0,2555
3. Numa criação de coelhos, 40% são machos. Qual a probabilidade de que nasçam pelo
menos 2 coelhos machos em num dia em que nasceram 20 coelhos.
R:0,99948
4. Sabe-se que 20% dos animais submetidos a um certo tratamento não sobrevivem. Se
esse tratamento foi aplicado em 20 animais e se X é o número de não sobreviventes:
a) Calcular a E (X) e a V(X) R: 4 e 3,2
b) Calcular P (2<X 4) R: 0,42356
c) Calcular P (X 2) R: 0,93082
5. A probabilidade de um atirador acertar no alvo num único tiro é 1 / 4 . O atirador atira
20 vezes no alvo. Qual a probabilidade de acertar:
a) Exatamente 5 vezes R: 0,20233
b) No máximo 4 vezes R: 0,41485
Janete Pereira Amador
6
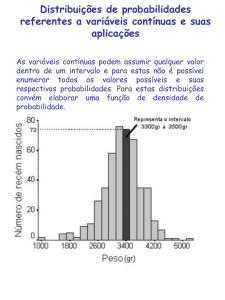
2 Variável Aleatória Contínua (VAC)
Quando uma variável aleatória apresenta um grande número de resultados
possíveis, ou quando a variável aleatória em questão é continua (pode assumir qualquer
valor dentro de um intervalo definido de valores), não se pode usar distribuições discretas
como a de Poisson ou Binomial para obter probabilidades. Como uma variável contínua
inclui, em seus resultados, valores tanto inteiros como não inteiros, não pode ser
adequadamente descrita por uma distribuição discreta. Sendo assim, abordagem mais
conveniente é construir uma função densidade de probabilidade, ou curva de
probabilidade, baseada na função matemática correspondente.
Definição: É aquela que pode tomar qualquer valor em um determinado intervalo. Diz-se
que X é uma VAC, se existir uma função f(x), denominada função densidade de
probabilidade (fdp) de x que satisfaça às seguintes condições:
a) f(x) 0 para todo o x;
b)
f ( x) dx 1;
Observações:
Seja X uma variável aleatória contínua com função densidade de probabilidade f(x).
Sejam a < b, dois números reais. Define-se:
, isto é, a probabilidade de que X assuma valores entre os
números “a” e “b” é a área sob o gráfico de f(x) entre os pontos x = a e x = b.
Neste caso, tem-se também:
(a) P(X = a) = 0, isto é, a probabilidade de que uma variável aleatória contínua assuma um
valor isolado é igual a zero. Para variáveis contínuas só faz sentido falar em probabilidade
em um intervalo, uma vez, que a probabilidade é definida como sendo a área sob o gráfico.
f(x) não representa nenhuma probabilidade. Somente quando ela for integrada entre dois
limites produzirá uma probabilidade. P(c < x < d) representa a área sob a curva, como
exemplificado na figura abaixo da f.d.p. f, entre x = c e x = d.
Janete Pereira Amador
7
(b) Se a < b são dois números reais então:
Neste caso a f(x) será uma função densidade de
probabilidade.
Ex: Seja X uma variável aleatória contínua. Com a seguinte função densidade de
2 x para 0 x 1
f ( x)
probabilidade
verificar se a função é uma
0 para quisquer outros valores
fdp da variável X.
1. f(x) 0
1
x2
12 0 2
2
2. f ( x ) dx 2 xdx 2
1
2 0
2
2
0
Como vemos f(x) é uma um fdp satisfazendo as condições.
1
3.1 Distribuições Contínuas de Probabilidade
Em muitos problemas se torna matematicamente mais simples considerar um espaço
amostral “idealizado” para uma variável X, no qual todos os números reais ( em algum
intervalo específico ) passam ser considerados como resultados possíveis. Desta maneira
somos levados as variáveis aleatórias contínuas, principalmente quando as observações
referem-se a medidas como comprimento, peso, temperatura, etc.
Janete Pereira Amador
8
Entende-se por distribuição contínua de probabilidade a distribuição que estiver
associada a uma variável aleatória contínua – VAC. Assim se uma variável puder assumir
um conjunto contínuo de valores de um certo conjunto de dados, então a distribuição de
probabilidade P(X) é dita de probabilidade contínua. Desta forma, a seguir estudarmos as
seguintes distribuições de probabilidade:
Distribuição Normal
Distribuição “t” de Student.
Distribuição Qui-quadrado ( x2
Distribuição F de Snedecor
3.1.2 Distribuição Normal
É mais importantes distribuição de probabilidade contínua, sendo aplicada em
inúmeros fenômenos e utilizada para o desenvolvimento teórico da inferência estatística. A
distribuição normal serve também como aproximação para um grande número de
distribuições.
A variável aleatória X que tome todos os valores reais X , tem
distribuição normal com parâmetros e 2 se sua função densidade de probabilidade for
dada por:
f ( x)
x
1
1/ 2
e ,
2
X
A equação da curva Normal é especificada usando 2 parâmetros: a média
populacional , e o desvio padrão populacional, ou equivalentemente a variância
populacional 2 e devem satisfazer as seguintes condições:
a)
b) 2 > 0
Denotamos
Quando uma variável aleatória X tiver distribuição normal anotaremos.
X N ( , 2)
A distribuição normal é simétrica em torno da média o que implica que e média, a
mediana e a moda são todas coincidentes.
A distribuição Normal possui as seguintes características:
1. forma campanular, isto é, possui forma de sino, sendo simétrica em relação a média;
2. a variável aleatória pode assumir qualquer valor real;
Janete Pereira Amador
9
3. a área total sob a curva é 1; porque essa área corresponde à probabilidade da variável
aleatória assumir qualquer valor real;
4. é uma curva assintótica;
5. possui dois pontos de inflexão;
A configuração da curva é dada por dois parâmetros: a média e a variância.
Mudando a média, muda a posição da distribuição no sentido horizontal. Mudando a
variância, muda a dispersão da distribuição fazendo com que o gráfico mais achatado ou
mais alongado. Tias configurações estão representadas na figura a seguir:
Na prática desejamos calcular probabilidades para diferentes valores de e .
Para isso, a variável X cuja distribuição é N ( , 2) é transformada numa forma
padronizada
com distribuição N (0, 1) (distribuição normal padrão) pois tal
distribuição é tabelada. Nesse caso a função densidade de probabilidade é dada por:
1
z2
1
f ( z)
.e 2 .
2
Teorema: Se X tiver uma distribuição normal com média e variância 2 e se Z
x
então Z terá distribuição normal padronizada.
X
X N ( , 2) ==> Z
N (0,1)
Esse teorema é usado da seguinte forma:
P( x1 < X < x2 ) = P(z1 < Z < z2), onde:
x1
x
z2 2
Desta forma a variável aleatória X transforma-se em variável normal reduzida Z,
como podemos ver graficamente a seguir:
z1
Janete Pereira Amador
10
68,27%
95,45%
99,73%
Vê-se que a nova origem é 0 e o desvio padrão é a unidade de medida. Essa
transformação não altera a forma da distribuição, apenas refere-se a uma nova escala.
A tabela da distribuição normal fornece a probabilidade de Z tomar um valor não
superior a Z0: P(Z Z0). Tal probabilidade é representada pela área hachurada na figura a
seguir:
A importância da distribuição normal padronizada reside no fato de que ela encontrase tabelada, facilitando o cálculo.
Ex1: Determinar área sob a curva normal padronizada à esquerda de 1,72.
Consultando a tabela, vemos que z = 1,72
corresponde área (probabilidade) 0,9573,
ou seja, 95,73% da área sob a curva e acima
do eixo da v.a. reduzida estão à esquerda de
Z = 1,72. é o mesmo que dizermos que a
probabilidade de Z ser menor que 1,72 é
0,9573: P(Z <1,72) = 0,9573.
Ex2: Determinar a área sob a curva normal padronizada abaixo de Z= - 0,53.
Na tabela, a Z = -0,53 corresponde a área
(probabilidade) 0,2981: P(Z < 0,53) =
0,2981, isto é 29,81% da área sob a curva e
acima do eixo da v.a. reduzida Z estão
abaixo do valor z = -0,53.
Janete Pereira Amador
11
Ex3: A concentração de um poluente em água liberada por uma fábrica tem distribuição
N(8,1.5). Qual a chance, de que num dado dia, a concentração do poluente exceda o limite
regulatório de 10 ppm?
A solução do problema resume-se em determinar a proporção da distribuição que
está acima de 10 ppm, isto é P(X>10). Usando a estatística z temos:
Portanto, espera-se que a água liberada pela fábrica exceda os limites regulatórios
cerca de 9% do tempo.
Ex4: Sabe-se que as alturas das plantas de milho de uma certa variedade se distribuem
normalmente com média de 2,20m e desvio padrão de 0,20m. Qual a percentagem
esperada de plantas com altura compreendida entre 2,30 e 2,35m?
X = altura das plantas;
X = N (2,20 ; 0,202);
P (2,30 < X < 2,35) = P (z1 < Z < z2)
2,30 2,20 0,10
2,35 2,20
z1 =
0,5
e
z2 =
0,75 então;
0,2
0,2
0,2
P (2,30 < X < 2,35 ) = P (0,5 < X < 0,75) = 0,0819 ou 8,19% corresponde a percentagem
de plantas que espera –se alcançar as alturas de 2,30 a 2,35m.
Exercícios
1. Suponha que a temperatura média do mês de julho em Santa Maria seja normalmente
distribuída com média igual a 11 graus e variância de 9 graus. Calcular a probabilidade da
temperatura:
a) Ser inferior a 6,7 graus
b) Ser superior a 5 graus
c) Estar entre 8,8 e 13,2 graus.
2. As alturas dos alunos de uma determinada escola são normalmente distribuídos com
=1,60 m e = 0,30 m. Encontre a probabilidade de 1 aluno medir:
a) Entre 1,50 e 1,80 m R: 0,3747
b) Mais de 1,75 m R: 0,3085
c) Menos de 1,48m R: 0,3446
d) Qual deve ser a medida mínima para escolhermos 10% dos mais altos. R: 1,98 m
3. Os salários dos diretores das empresas de São Paulo distribuem-se normalmente com
média de R$ 8000,00 e desvio padrão de R$ 5000,00. Qual a percentagem de diretores que
recebem.
a) Menos de R$ 6470,00 R: 0,001107
b) Entre R$ 8920, 00 e R$ 9380,00. R: 0,02994
Janete Pereira Amador
12
3.1.3 Distribuição “t” de Student
A distribuição “t” ou Student foi estudada por Gosset em 1908 e se refere a pequenas
amostras, isto é, quando n < 30. Sua curva representativa é bem semelhante a curva
normal, sendo também simétrica em relação a ordenada máxima, mas apresentando as
extremidades com maior comprimento e mais elevadas, fato este que determina uma
variância maior do que a distribuição normal.
Na distribuição normal verificamos que ela depende dos parâmetros e . Mas na
maioria das vezes, a variância populacional não é conhecida e as investigações ou análises
são feitas a partir de amostras retiradas dessa população.
A distribuição t de Student é aplicada em testes de hipóteses e intervalos de
confiança para médias de distribuições normais, quando a variância é desconhecida,
partindo-se do fato de que:
T
X
S
n
t(n-1) , onde S é o desvio padrão estimado a partir de
uma amostra de tamanho n.
Se T tiver uma distribuição “t” de Student com n graus de liberdade, anota-se por T tn
E(T) = 0
V(T) =
, 2
2
A média da distribuição “t” corresponde a zero e sua função de densidade é dada por:
1
f (t ) K
n/2
t2
1
n 1
onde:
a) - < t < +;
b) K é a constante para cada valor de n;
A área submetida a curva é igual a 1 e = n - 1 e corresponde aos graus de
liberdade da distribuição. A medida que aumenta t Z, observando que ao ultrapassar
30 graus de liberdade já é possível usar a distribuição normal, pois a diferença entre os
resultados será bastante pequena. A figura abaixo ilustra, comparativamente, as
distribuições Z e t, na qual verifica-se que o gráfico de t tem a forma da normal, embora
seja mais "achatada" (menos leptocúrtica).
Janete Pereira Amador
13
A tabela para a distribuição “t” segue uma metodologia um pouco diferente da
normal padrão. Como existem muitas distribuições de t - Student, uma para cada tamanho de
amostra, não seria possível tabelá-las da mesma forma que a da normal padrão. Assim cada
linha de uma tabela representa uma distribuição diferente e cada coluna representa um valor
de confiança que poderá ser “ “ ou “ /2”, isto é, a tabela poderá ser unilateral ou bilateral.
A linha de cada tabela fornece a distribuição “t” com parâmetro “n - 1” denominado de
graus de liberdade, isto é, o grau de liberdade = n 1 = linha da tabela..
Ou seja P( t t 0 ) 1
Propriedades
A distribuição t de Student é diferente, conforme o tamanho da amostra;
A distribuição tem a mesma forma geral simétrica (forma de sino) que a
distribuição normal, mas reflete a maior variabilidade (com distribuição mais amplas)
que é esperada em pequenas amostras;
A distribuição tem média t = 0, tal como a distribuição normal padronizada, com
média z = 0.
O desvio padrão da distribuição varia com o tamanho da amostra, mas é superior a 1
ao contrario da distribuição normal padronizada, em que 1 .
Na medida em que aumenta o tamanho “n” da amostra, a distribuição t de Student
aproxima-se da distribuição norma padronizada. Para valores n>30, as diferenças são
tão pequenas que podem utilizar os valores críticos Z.
Ex: Achar o valor de 2 pra n =7 e =1 =0,01
n 1 6 1 5
t n 1, = t 6;0, 01 =3,143 corresponde ao valor tabelado de t