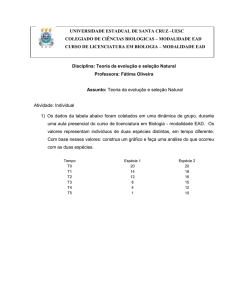
Estatística Descritiva
Profª Maria Eliane
MEDIDAS DE POSIÇÃO
CONCEITO
São medidas denominadas de estatísticas, que dão uma idéia condensada
de todo o conjunto de dados. Também são conhecidas como medidas de
localização, e em conjunto com as medidas de dispersão formam as
medidas resumo.
UTILIDADE
Fornecer uma descrição resumida sobre o comportamento de um
determinado fenômeno; caracterizar um grupo como um todo, através de
um valor único.
Ex.: Quanto é o gasto médio mensal da família brasileira com alimentação?
Qual o tipo sangüíbneo mais comum?
Qual o valor que divide um lote de produtos, em produtos de qualidade
superior e de qualidade inferior?
TIPOS
Abordaremos os aspectos mais importantes de seis medidas de posição,
para dados isolados. Essas medidas são:
Média
Mediana
Moda
•
Quartil
•
Decil
•
Percentil
Medidas de Tendência Central:
assim chamadas porque estão no
valor central de um conjunto de
dados ordenado, ou o mais próximo
dele.
Separatrizes: assim chamadas porque
separam, dividem um conjunto de dados
ordenado em partes percentuais iguais.
Medidas de Tendência Central para Dados Isolados (dados que não estão em intervalos ou faixas)
1. Média
É o valor que pode substituir todos os valores da variável, isto é, é o valor que a variável teria se em vez
de variável ela fosse constante. A média torna todos os valores de um conjunto de dados iguais a um
único valor, que é resultante da operação de cálculo.
Existem vários tipos de médias: aritmética, geométrica e harmônica. Estudaremos a média aritmética
simples.
Média Aritmética: é o resultado da soma de todos os valores dos dados dividido pelo número de dados.
É a mais utilizada e geralmente quando se menciona o termo média, refere-se à aritmética.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
46
Estatística Descritiva
Profª Maria Eliane
n
x=
O modelo de cálculo da média amostral é dado por:
∑x
i =1
i
n
Onde,
Σxi= somatório dos valores de xi
i = índice que varia de 1 a n elementos da amostra ou
n= tamanho da amostra em estudo.
Exemplo→
→ a pesagem individual de uma amostra dos componentes de um grupo de macacos (adultos)
em uma área de proteção ambiental (APA), apresentou os seguintes valores em quilograma:
5
6
4
5
7
8
A amostra tem 6 elementos (seis macacos), então n=6. Significa que i= macaco 1, 2, 3, 4, 5 e 6 ou seja,
x= peso em Kg de macacos adultos é a variável a ser conhecida, será representada individualmente pelo
peso de cada macaco da amostra (x1
x2
x3
x4
x5
e
x6). Desse modo,
5
x1
6
x2
4
x3
5
x4
7
x5
8
x6
6
Colocando os valores no modelo de cálculo da média temos x =
x=
∑x
i =1
i
6
x1 + x2 + x3 + x4 + x5 + x6 5 + 6 + 4 + 5 + 7 + 8 35
=
=
= 5,83Kg
6
6
6
Significa que o grupo de macacos da APA pesam em média 5,83Kg. Todos os macacos terão esse valor
para representar o seu peso.
Verifique que, ao ordenar os dados de forma crescente, o valor da média encontrada estará no centro dos
valores do conjunto de dados. Por esse motivo a média é uma medida chamada de tendência central:
4
5
5
5,83
Centro
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
6
7
8
47
Estatística Descritiva
Profª Maria Eliane
Mas é preciso ter cuidado ao utilizar a média em pesquisas, pois é uma medida que sofre a influência de
valores muito pequenos ou muito grandes presentes em um conjunto de dados. Isso faz com que haja
uma distorção nos resultados. Falaremos desse assunto após conhecermos as outras medidas de
tendência central.
2. Mediana
É o valor central dos valores ordenados (de forma crescente ou decrescente), que estabelece um limite
que separa os dados em metade superior (50%) e metade inferior a ele (50%). É simbolizado pela sigla
x.
Me ou por ~
Mediana
Valor mínimo
Valor máximo
50%
50%
50% dos valores do conjunto de dados estão abaixo do valor da Me
50% dos valores do conjunto de dados estão acima do valor da Me
Exemplo:
3
4
5
6
7
↑é o valor mediano desse conjunto de dados, observe que está no centro.
Por isso é uma medida de tendência central.
Para encontrar a posição do elemento mediano em um conjunto de dados com número ímpar de
elementos usamos o seguinte modelo matemático:
PEMe =
n +1
2
Onde PEMe = Posição do Elemento Mediano
n= número de elementos que compõem o conjunto de dados (população ou amostra)
Exemplo: suponha que a amostra do grupo de macacos pesquisado na APA, fosse de 5 elementos. O
elemento que será o peso mediano é:
PEMe =
n +1 5+1 6
=
= = 3 a posição ,
2
2
2
com os pesos ordenados de forma crescente:
4
5
5
6
7
↑esta é a 3ª posição
Portanto, o peso mediano desse grupo de maçados é de 5Kg. Significa que 50% dos macacos do grupo
possuem peso igual ou abaixo de 5Kg, e 50% dos macacos do grupo possuem peso acima de 5Kg.
Se não fosse utilizado o fator de correção +1, a posição do elemento seria: 5/2= 2,5aposição. Observe
que para esta posição o valor do elemento estaria deslocado do centro do conjunto de dados, não iria
representar uma divisão exatamente ao meio com 50% para cada lado em relação ao valor.
Observe que o cálculo feito apenas encontra a posição do elemento mediano, e não o seu valor. O valor
é encontrado por meio da visualização do conjunto ordenado, onde identificamos qual é o valor que está
na posição encontrada no cálculo. Cuidado para não confundir a posição com o valor do dado mediano.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
48
Estatística Descritiva
Profª Maria Eliane
Para encontrar a posição do elemento mediano em um conjunto de dados com número par de
elementos usamos o mesmo modelo matemático. Assim, considerando a amostra do peso de seis
macacos:
PEMe =
n +1 6+1 7
=
= = 3,5 a posição. O valor do peso mediano está entre a 3ª e a 4ª posição
2
2
2
com os pesos ordenados de forma crescente:
4
5
5
↑
3ª
6
↑
4ª
7
8
O valor da mediana corresponderá à média aritmética entre os valores encontrados nas posições:
5 + 6 11
Me =
=
= 5,5 Kg .
2
2
3. Moda
É o valor que apresenta a maior frequência no fenômeno estudado. É a única medida de tendência
central que pode ser aplicada a todos os níveis de medida (nominal, ordinal, intervalar e racional). É
r
simbolizado pela sigla Mo ou por x .
Exemplo→ para a amostra do peso de seis macacos:
4
5
5
6
7
8
O peso modal é 5Kg, porque é o peso que aparece com maior freqüência (2 vezes). O conjunto de dados
com uma única moda é chamado de UNIMODAL.
Numa série ou conjunto de dados pode ocorrer que:
• A moda seja dois números:
4
5
5
6
6
7
8
, Mo= 5 e 6
• A moda seja mais de números:
4
5
5
6
6
7
7
8
, Mo= 5; 6 e 7 (MULTIMODAL)
• Não existir valor modal: 4
5
6
7
8
, (AMODAL)
(BIMODAL)
A moda (para dados isolados) é estimada pela simples inspeção dos dados, observando-se qual o valor
onde há maior número de freqüência. Não há cálculo.
Observe que o valor modal tende a ser um número central ou o mais próximo do centro do conjunto de
dados, por isso a moda também é uma medida de tendência central.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
49
Estatística Descritiva
Profª Maria Eliane
Cuidado ao utilizar a média
Voltemos a falar sobre o cuidado ao utilizar a média em pesquisas, pois é uma medida que sofre a
influência de valores muito pequenos ou muito grandes presentes em um conjunto de dados. Isso faz
com que haja uma distorção nos resultados.
Para ilustrar, suponha um estudo realizado em três regiões geográficas diferentes, para estimar o número
de uma espécie de pássaro. Em cada região foram selecionadas cinco áreas, onde o número de pássaros
foi contado, obtendo-se os seguintes resultados:
Medidas de Tendência central
Média Mediana Moda
Região
Área 1
Área 2
Área 3
Área 4
Área 5
A
1
1
2
3
3
2
2
1e3
B
1
2
2
3
4
2,4
2
2
C
1
2
3
3
31
8
3
3
Observe que o valor da média de pássaros da região C ( x = 8) foi muito influenciada pelo valor da
contagem da área 5 (n=31), que é bem maior que os demais valores do conjunto de dados dessa região.
A idéia que esse resultado passa é que em toda a região C o número de pássaros é maior que nas demais
regiões, o que não é verdade porque apenas uma área da região C apresentou alta contagem de número
de pássaros.
Quando em uma amostra ou dado da pesquisa encontramos um valor muito elevado ou muito pequeno
em relação aos demais valores do conjunto de dados estudados, dizemos que é um valor discrepante,
também chamado de valor extremo ou outlier. É o que ilustra bem o valor n=31 da área 5 em relação
aos demais valores de contagens de pássaro das outras áreas da região C. E para todo o conjunto das
regiões, este valor também é valor extremo.
Sobre cuidados ao utilizar e interpretar as medidas de tendência central (média, mediana e moda), leia a
crítica de Ubaldo Ribeiro no texto complementar da p.54.
SEPARATRIZES
Existem diversas situações nas quais o interesse principal é a posição relativa de um elemento no grupo,
e não o desempenho do grupo como um todo. A interpretação de um resultado isoladamente é
impossível, sendo necessário indicar a posição específica que um determinado resultado ocupa no grupo
através de medidas que possibilita interpretar o seu significado.
Essas medidas são denominadas de separatrizes, pois separam a distribuição em partes percentualmente
iguais. As mais utilizadas são:
Quartil: divide o conjunto de dados ordenados em 4 partes iguais, de 25% cada parte . Os valores são
identificados por Q1 (25% dos dados estão abaixo do valor do 1ºquartil); Q2 (50% dos dados estão
abaixo do valor do 2ºquartil, observe que o Q2 é a mediana) e Q3 (75% dos dados estão abaixo do valor
do 3ºquartil). Não existe Q4.
Q1
25%
Q2
25%
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
Q3
25%
25%
50
Estatística Descritiva
Profª Maria Eliane
Para o cálculo da posição do Quartil: PEQ i =
i×n
4
Onde, i = quartil que se deseja obter (i=1,2,3)
n = quantidade de elementos observados, ou
tamanho da amostra
Decil: divide o conjunto de dados ordenados em 10 partes iguais, cada parte com 10% dos valores do
conjunto de dados. Os valores são identificados por D1, D2, D3,..., D9. Não existe D10.
D1
10%
D2
10%
D3
10%
Para a posição do Decil: PEDi =
D4
10%
i ⋅n
10
10%
D5
10%
D6
D7
10%
10%
D8
10%
D9
10%
Onde, i = decil que se deseja obter (i=1,2,3,...,9)
Centil ou Percentil: divide o conjunto de dados ordenados em 100 partes iguais, cada parte com 1%
dos valores do conjunto de dados. Os valores são identificados por P1, P2, P3,..., P99.
Para a posição do percentil: PEPi =
i ⋅n
100
Onde, i = centil que se deseja obter (i=1,2,3,...,99)
Exemplo de uso das separatrizes: suponha que um entomologista selecionou 50 exemplares de uma
espécie de inseto, de mesma ninhada e período de eclosão dos ovos. Submeteu os insetos às mesmas
condições ambientais e nutricionais, para estimar o tempo de vida (longevidade) da espécie. Ao final do
experimento, o pesquisador obteve os seguintes dados de longevidade (em dias de sobrevivência para
cada exemplar).
16
22
27
36
45
17
23
27
36
46
18
23
28
37
47
18
24
29
38
50
18
24
30
38
52
20
25
31
41
53
20
25
31
42
59
21
26
33
42
61
21
26
33
43
65
21
27
34
45
70
Determinando-se o 1º e 3º quartis:
1 x 50
PEQ 1 =
= 12,5ª posição , o valor está entre os valores da 12ª e 13ª posição dos elementos
4
ordenados de forma crescente (23 e 23 respectivamente). Assim, Q1= 23 dias.
Significa que 25% dos insetos tiveram um tempo de vida igual ou menor que 23 dias, e 75% período de
vida igual ou maior que 23 dias.
3 x 50
= 37,5ª posição , o valor está entre os valores da 37ª e 38ª posição dos elementos
4
ordenados de forma crescente (42 e 42 respectivamente). Assim, Q3= 42 dias.
PEQ 3 =
Significa que 75% dos insetos tiveram um tempo de vida igual ou menor que 42 dias, e 25% período de
vida igual ou maior que 23 dias.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
51
Estatística Descritiva
Profª Maria Eliane
Construindo um intervalo com estes valores observamos:
Q1=23
25%
25%
Q3=42
25%
25%
Entre 23 e 42 dias é o período de tempo que viveram 50% dos insetos, excluindo-se 25% dos menores
períodos e 25% dos maiores períodos de longevidade.
Outros exemplos de uso das separatrizes
Exemplo 1
É muito comum o uso das separatrizes na área da Economia, principalmente em estudos de séries de
tempo, pois o fracionamento percentual dos dados facilita observar se houve mobilidade ou
permanência de valores de um fenômeno econômico.
Rendimento Real Trimestral Máximo e Mínimo dos Ocupados e dos Assalariados no Trabalho Principal (1)
Região Metropolitana de Salvador
2010
Rendimento Real Trimestral
Ocupados (2)
Trimestres
10% Mais
Pobres
Ganham Até
25% Mais
Pobres
Ganham Até
50% Mais
25% Mais
10% Mais
Pobres
Ricos Ganham Ricos Ganham
Ganham Até
Acima de
Acima de
Assalariados (3)
10% Mais
Pobres
Ganham Até
25% Mais
Pobres
Ganham Até
50% Mais
Pobres
Ganham Até
Jan-2010
314
492
677
1.256
2.161
492
534
785
Fev
312
528
680
1.177
2.123
492
534
780
Mar
311
529
680
1.244
2.223
529
534
777
Abr
310
525
676
1.210
2.274
525
530
743
Mai
309
523
694
1.230
2.384
523
528
747
Jun
308
522
699
1.230
2.370
522
525
771
Jul
308
523
718
1.237
2.389
523
526
783
Ago
309
526
718
1.237
2.268
524
526
809
Set
308
525
719
1.238
2.272
525
526
805
Out
308
523
703
1.237
2.160
523
525
801
Nov
305
519
712
1.231
2.257
519
526
814
Dez
304
518
711
1.231
2.298
517
528
812
Fonte: PED-RMS – Convênio SEI, Setre, Dieese, Seade, MTE/FAT.
(1) Inflator utilizado: IPC - SEI; valores em reais de janeiro de 2011.
(2) Excluem os assalariados e os empregados domésticos assalariados que não tiveram remuneração no mês, os trabalhadores familiares sem
remuneração salarial e os trabalhadores que ganharam exclusivamente em espécie ou benefício.
(3) Excluem os assalariados que não tiveram remuneração no mês.
25% Mais
10% Mais
Ricos Ganham Ricos Ganham
Acima de
Acima de
1.323
1.270
1.258
1.248
1.253
1.302
1.345
1.363
1.358
1.340
1.334
1.339
2.390
2.329
2.420
2.409
2.395
2.389
2.563
2.466
2.479
2.377
2.383
2.441
Os 10% mais pobres é o D1
Os 10% mais ricos é o D9
Os 25% mais pobres é o Q1
Os 25% mais ricos é o Q3
Os 50% mais pobres é o Q2 , é a mediana.
Observe que houve pouca mobilidade econômica para os trabalhadores. A melhoria salarial não é
significativa, pois a tendência revela decrescimento, ou seja perda de rendimentos.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
52
Estatística Descritiva
Profª Maria Eliane
Exemplo 2
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
53
Estatística Descritiva
Profª Maria Eliane
QUAL MEDIDA DE POSIÇÃO USAR ?
A decisão sobre qual medida empregar envolve a consideração de uma série de fatores:
•
nível de mensuração (se a variável é qualitativa ou quantitativa);
•
formas de distribuição (simétrica, assimétrica ou uniforme);
•
exatidão requerida (uma medida central mais exata ou mais empírica);
•
estabilidade da medida;
•
manipulação subseqüente (se os resultados servirão para outros cálculos e para inferência);
•
objetivo da pesquisa (apurar os resultados de forma mais sofisticada ou comunicá-los de forma mais
simples).
A média é preferível especialmente em distribuições aproximadamente simétricas, devido à sua maior
estabilidade e à manipulações estatísticas posteriores.
A mediana é mais apropriada quando a assimetria é acentuada; os valores (limites) extremos da primeira
e última classes não são definidos, e quando o nível de mensuração é ordinal.
A moda é empregada em situações em que uma estimativa rápida e grosseira da medida central é
suficiente; os dados atingem apenas o nível nominal ou o caso típico é desejado.
Além dessas regras, deve-se examinar cada distribuição de dados e o objetivo específico do estudo. O
ideal não é optar entre as medidas, mas usá-las todas, quando o nível de mensuração permite, pois cada
uma fornece uma visão parcial dos dados e elas se complementam umas às outras.
BIBLIOGRAFIA CONSULTADA:
AKAMINE, Carlos e YAMAMOTO, Roberto. Estatística descritiva. São Paulo: Érica, 1998, p.139-80.
BUNCHAFT, Guenia. Estatística sem mistério. Petropólis, RJ: Vozes, 1998, p.107-53.
FRANCISCO, Valter de. Estatística. São Paulo: Atlas, 1982, p.20-28.
PEREIRA, Wilson e TANAKA, Oswaldo. Estatística. São Paulo: Mc-Graw Hill do Brasil, 1990, p.73120.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
54
Estatística Descritiva
Profª Maria Eliane
Texto complementar
Artigo do jornal "O Estado de São Paulo" de 28/09/2008
Domingo, 28 de setembro de 2008
João Ubaldo Ribeiro
NÃO SOMOS TODOS BURROS
"Às vezes fico meio sem jeito para tratar de certos assuntos aqui, achando que vou chover no
molhado ou repetir coisas que todo mundo sabe. Mas, em outras ocasiões, me bate sensação oposta, a de
que a maioria não sabe. Hoje, por exemplo. Fico lendo os jornais, ouvindo comentários e sendo alvejado
por declarações pomposas não contestadas por ninguém e penso que de fato conseguiram fazer um
Brasil virtual, distinto do real. Aí corro o risco de provocar tédio nos que de fato já sabem como somos
tapeados, e pouca serventia virá a ter a coluna de hoje. Mas faz parte, vamos lá.
Fala-se muito mal da Estatística. De um lado, constitui grande injustiça para com uma ciência
sem a qual hoje talvez nem sobrevivêssemos direito. De outro, trata-se da compreensível reação contra a
maneira pela qual a Estatística é usada e abusada para "provar" o duvidoso e manipular a chamada
realidade objetiva. Compreendo o sujeito que disse, como já lembrei aqui antes, que a Estatística é a arte
de mentir com precisão, porque de fato o seu uso inescrupuloso e falsário equivale a isso.
Começo lembrando a famosa média. Em grande parte dos casos em que ela é empregada em
indicadores sociais e econômicos, não quer dizer nada, ou melhor, quer dizer muito pouco. Se Bill Gates
passasse a ser residente da cidade de Itaparica, teríamos talvez a renda per capita mais alta do planeta
ou com certeza uma das mais altas, sem que um itaparicano sequer passasse a ganhar mais um centavo.
Isso porque a renda per capita é uma média aritmética e, por conseguinte, sensível em excesso aos
valores extremos. Então, numa população em que um ganha por mês um milhão de borodongas e os
outros cinco borodongas cada, falar em renda per capita é ridículo.
Precisamos, portanto, saber da mediana. Talvez por às vezes revelar-se incomodativa, não é
muito mencionada, notadamente em estatísticas oficiais. A mediana dá mais peso e significado à média.
É o valor que se encontra exatamente no meio dessa coletividade. Ou seja, não é bastante saber que a
renda média é 1.000. É preciso saber também (estou simplificando e peço desculpas a estatísticos e
matemáticos em geral) o valor que divide esses indivíduos pela metade, ou seja, o ponto em relação ao
qual exatamente a metade ganha menos e a metade ganha mais. Quando a média é próxima da mediana,
isso significa que a distribuição é mais ou menos simétrica. Quando não, a distribuição é tortinha. Logo,
a mediana pode, por exemplo, desmoralizar a renda per capita, se demonstrar que metade da população
ganha muito abaixo desta e a outra metade muito acima. Mas ninguém fala na mediana.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
55
Estatística Descritiva
Profª Maria Eliane
Também tem, desculpem, a moda. Não a moda fora da qual estou, mas a moda estatística
mesmo, ou seja, o valor mais freqüente, o que mais ocorre numa população determinada. Assim, se a
renda média dos habitantes da próspera comunidade de Lulalápolis, é R$ 1.000 por mês, mas a mediana
é 100 e/ou a moda é oitentinha, já vemos bem como podemos (e somos) ser engabelados. É por isso que
até a Bethânia, que não é de sair por aí falando ou fazendo manifestações, se revelou na imprensa um
pouco irritada com esse país maravilhoso (virtual, estatisticamente siliconado, digo eu) a que ela não
consegue chegar.
Também convivemos acriticamente com uma porção de chutes que desonram e desmerecem a
Estatística, tais como a conversão de coexistência numa relação de causa e efeito. É como o torcedor do
Flamengo achar que a causa da vitória do time dele foi ter entrado um urubu em campo, logo antes do
jogo. Não vamos discutir com torcedor, tudo bem. Mas coisas boas que acontecem são vinculadas a
outras de maneira absolutamente arbitrária e aí, em propaganda comercial por exemplo, para esquecer
um pouco a política, acabamos acreditando em afirmações que não passam de reformulações de
vigarices como "todos os que morreram de enfarte do miocárdio no ano passado faziam uso de água".
Verdade, mas claro que não prova que tomar banho faz mal ao coração. Com espertas artes, porém, nos
enrolam muito nessa linha.
E as categorias? O sujeito enche a boca e diz: "Depois de tantos anos de meu governo, o número
de ricos cresceu em 20% e o de pobres diminuiu em 32%." Além dos probleminhas de média, mediana e
moda, que sempre estão rondando, é muito fácil (e é isso que se faz) dizer que rico é quem ganha mais
de R$2.000 por mês. Fico até admirado por não haverem proposto R$ 1.500, porque o número de ricos
ia bombar. Até a felicidade é quantificada e lemos a sério, como parvos, que o povo tal tem o maior
índice de felicidade do mundo ou semelhantes despautérios.
E a coleta dos dados? Desde antes da definição das categorias e das perguntas, desde o início do
planejamento, um dos maiores problemas que o estatístico sério encontra é a feitura de uma coleta de
dados "neutra", que não influencie as respostas. Em rigor, impossível, porque até condições
meteorológicas podem influir nas respostas. As próprias perguntas podem induzir a determinado tipo de
resposta. A roupa, o sexo, a idade, o sotaque, o local, a época, a hora, as palavras e expressões usadas, a
ordem das perguntas, o tamanho do questionário, e centenas de outros fatores podem, mesmo nas
pesquisas mais honestas e cientificamente orientadas, levar à distorção de resultados. Há até, em
confusão com esses e outros fatores, o perigo de o entrevistado querer responder o que acredita que se
espera dele e não o que de fato pensa.
Há muito mais, um dia desses falo mais. Enche mesmo o saco nos tratarem como a uma tropa de
burros, que não somos. Somos, sim, otários, comodistas, coniventes e subservientes, mas isso já é outro
problema."■
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
56
Estatística Descritiva
Profª Maria Eliane
MEDIDAS DE DISPERSÃO OU DE VARIABILIDADE
Em nosso estudo sobre as medidas de posição observamos que é preciso tomar cuidado com o
uso da média e sua interpretação, pois como é influenciada por valores extremos esconderá muitos
aspectos métricos sobre o conjunto de dados. Observemos mais um exemplo, para entendermos porque
a média necessita de outras medidas estatísticas que auxiliem em seu uso e interpretação.
Suponha que em duas regiões geográficas diferentes subdivididas em cinco áreas, o número de
uma espécie de planta encontrada por área foi:
Região A:
4
5
6
7
8
Número médio de plantas = 6unidades
Região B:
2
4
6
8
10
Número médio de plantas = 6unidades
Se considerarmos apenas o número médio de plantas encontradas, diríamos que as duas regiões
são iguais em relação à ocorrência do número dessa planta. Contudo, pela contagem individual em cada
área verificamos que há diferenças de dispersão e concentração do número de plantas em cada área das
duas regiões. Por esse motivo precisamos medir o padrão de dispersão do conjunto de contagem de cada
região.
É o que faz as medidas de dispersão, também como forma de resumir as informações presentes
em um conjunto de dados. As medidas de dispersão de uma distribuição são os valores que indicam o
grau de afastamento dos valores da variável em relação à média do conjunto de dados.
As principais medidas de dispersão são:
1. variância
2. desvio padrão
3. coeficiente de variação
1. Variância:
é o desvio quadrático médio dos dados em relação à média. Expressa a variabilidade dos dados como
uma grandeza elevada ao quadrado (exemplo: altura2). Por esse motivo é uma medida de difícil
interpretação universal.
n
A variância possui o seguinte modelo de cálculo:
s2 =
2
(xi − x )
∑
i 1
=
n −1
Onde:
s2 = símbolo da variância amostral
Σ = somatório dos valores da diferença entre os valores individuais e a média amostral
xi = valor de cada elemento da amostra
x = símbolo da média amostral
n -1= graus de liberdade, que é uma correção para o valor do cálculo na amostra
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
57
Estatística Descritiva
Profª Maria Eliane
Calculemos a variância para o exemplo da contagem do número de uma espécie de plantas em
duas regiões, anteriormente descrito:
Região A
Região B
( xi − x )
( xi − x ) 2
( xi − x )
( xi − x ) 2
4 – 6 = -2
4
2 – 6 = -4
16
5 – 6 = -1
1
4 – 6 = -2
4
6–6=0
0
6–6=0
0
7–6=1
1
8–6=2
4
8–6=2
4
10 – 6 = 4
16
Σ
10
Σ
40
Variância região A:
Variância região B:
n
s2 =
s2 =
n
∑(x i − x )2
i =1
s2 =
n −1
10
= 2 ,5 plantas
5 −1
2
s2 =
2
(x i − x )
∑
i 1
=
n −1
40
= 10 plantas
5 −1
2
2. Desvio Padrão: de todas as medidas de dispersão esta é a mais utilizada, e é definida como a raiz
quadrada da variância. Ela exprime o resultado na mesma medida da variável em estudo, ao contrário da
variância. Por esse motivo é mais utilizada, permite uma interpretação universal do resultado.
n
Modelo para o cálculo do desvio padrão: s =
2
(x i − x)
∑
i 1
=
n −1
= s2
Para o nosso exemplo do número de uma espécie de plantas por região temos os seguintes desvios
padrão por região:
Desvio padrão região A:
Desvio padrão região B:
n
s =
s =
∑(x i − x )2
i =1
n −1
10
= 1,58 plantas
5 −1
n
s=
s =
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
2
(x i − x )
∑
i 1
=
n −1
40
= 3,16 plantas
5 −1
58
Estatística Descritiva
Profª Maria Eliane
Estes resultados indicam que em torno do número médio da espécie de planta existente na região A a
variabilidade de plantas é de 1,58 plantas; já em torno da média da região B é de 3,16plantas. A região B
tem maior dispersão de número de plantas, é o dobro da dispersão encontrada na região A.
Esses resultados são expressos na forma de um intervalo de valores em torno da média, pois a dispersão
pelo desvio padrão indicará quantos elementos estão abaixo e acima da média encontrada. Assim,
Região A:
x ± s = 6±1,58
Em torno da média 6plantas, o número de plantas da região A pode
variar de 4,42plantas (6-1,58) a 7,58plantas (6+1,58), para 68% das
contagens.
Região B:
x ± s = 6±3,16
Em torno da média 6plantas, o número de plantas da região B pode
variar de 2,84plantas (6-3,16) a 9,16plantas (6+3,16) ), para 68%
das contagens.
3. Coeficiente de Variação: indica a proporção do desvio padrão em relação à média, expresso em
percentagem. Pode ser usada para comparar a dispersão de dois conjuntos de dados, sem que eles
estejam necessariamente na mesma unidade de medida.
Modelo para o cálculo do: CV =
s
× 100
x
Para o nosso exemplo do número de uma espécie de plantas por região, a dispersão do número de
plantas em torno da média por região, em termos percentuais é de:
Região A:
CV A =
sA
1,58
× 100 =
× 100 = 26,33%
xA
6
Região B:
CVB =
sB
3,16
× 100 =
× 100 = 52,67%
xB
6
Percentualmente, confirma-se que a dispersão da espécie de plantas na região B é o dobro da dispersão
da região A. Portanto, a região A possui uma distribuição mais homogênea do número dessa espécie do
que a região B. A ocorrência da espécie nessas regiões não é igual, como levaria a acreditar o valor
apenas da média calculada.
Em relação à variância e o desvio padrão, o coeficiente de variação tem a vantagem de possibilitar
comparar a dispersão de dados que estejam em unidades de medida diferentes, por exemplo:
a) comparar altura (em cm) e peso (em g);
b) comparar valor monetário (em R$) e peso (em Kg);
c) comparar volume (em cm3) e quantidade (em unidades).
Observação: tratamos a comparação entre médias e medidas de variabilidade de modo bem simples.
Porém, estatisticamente, é preciso fazer testes mais apurados para comparar e detectar as diferenças, o
que é feito por meio dos testes de hipóteses de médias (que serão vistos no capítulo de probabilidade), e
teste de variância por ANOVA.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
59
Estatística Descritiva
Profª Maria Eliane
Gráficos especiais para avaliar a variabilidade de um conjunto de dados:
1. Box-plot ou Desenho Esquemático
Este é um gráfico mais elaborado do que o dot-plot, usando algumas medidas obtidas dos dados, a saber:
mediana, 1°quartil, 3°quartil, valor máximo e valor mínimo. Colocamos sobre a reta essas cinco
medidas e traçamos um retângulo com extremos em Q1 e Q3, marcondo dentro dele o lugar
correspondente à mediana. Em seguida marcamos sobre a reta dos valores (Q1 – 1,5(Q3-Q1))
e
(Q1 + 1,5 (Q3-Q1)). Os valores dos dados que estiverem acima ou abaixo desses dois valores calculados
serão considerados como valores extremos (outliers).
O Box plot pode ser desenhado em palno horizontal ou vertical.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
60
Estatística Descritiva
Profª Maria Eliane
Exemplo de uso do Box plot:
Sobrevivência em dias da Coytiera pertusa
Sobrevivência em dias da Coytiera pertusa
100
11
80
60
40
20
0
N=
8
8
8
8
1
2
3
4
Nível de maturação das folhas de Theobroma cacao
Fonte: Terra e Sousa, 2004. Sobrevivência de Coytiera pertusa e de Percolapsis ornata segundo a ontogênese das folhas de
cacau (Theobroma cacao) e de ingá (Inga ebulis) usadas na alimentação em cativeiro.
2. Dot-plot: representa na reta todos os dados de um conjunto, com as repetições necessárias.
BIBLIOGRAFIA CONSULTADA:
AKAMINE, Carlos e YAMAMOTO, Roberto. Estatística descritiva. São Paulo: Érica, 1998.
BOTTER, Denise et alli. Noções de Estatística. São Paulo:EDUSP, 1996.
BUNCHAFT, Guenia. Estatística sem mistério. Petropólis, RJ: Vozes, 1998.
FRANCISCO, Valter de. Estatística. São Paulo: Atlas, 1982.
PEREIRA, Wilson e TANAKA, Oswaldo. Estatística. São Paulo: Mc-Graw Hill do Brasil, 1990.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
61
Estatística Descritiva
Profª Maria Eliane
INTRODUÇÃO AO ESTUDO DE PROBABILIDADE
PROBABILIDADE
É o estudo dos fenômenos aleatórios que, a princípio, define a
possibilidade de ocorrência de um evento.
PROVA, OBSERVAÇÃO
OU EXPERIMENTO
É todo fenômeno ou ação que geralmente pode ser repetido, cujo resultado
é casual ou aleatório, por exemplo: o lançamento de um dado. Se
estabelecermos todos os possíveis resultados de um experimento teremos
um espaço amostral.
ESPAÇO AMOSTRAL
É o conjunto universo denotado por (Ω), (U) ou (S), ou seja, é o conjunto
de todos os resultados possíveis de acontecer em uma observação.
Ex.: O espaço amostral do lançamento de um dado é (U)={1,2,3,4,5,6}
EVENTO:
É cada subconjunto do espaço amostral (U). É representado por letras
arábicas maiúsculas:A, B, C... Pode ser classificado como:
•evento simples: formado por um único elemento do espaço amostral.
•evento composto: formado por mais de um elemento do espaço amostral.
•evento certo: ocorre em qualquer realização do experimento aleatório.
•evento impossível: não ocorre em qualquer realização do experimento
aleatório.
•eventos mutuamente exclusivos ou disjuntos ou incompatíveis: quando
dois eventos a e b não puderem ocorrer simultaneamente, i. e., a interseção
entre a e b é um conjunto vazio.
•eventos dependentes: a ocorrência de um evento depende da ocorrência
previa de um outro evento b.
•eventos independentes: quando eles não exercem ações reciprocas, ou
seja, o acontecimento de um não interfere no acontecimento do(s) outro(s).
•evento complementar: é constituído pela parte do espaço amostral que
não contém o evento desejado.
•eventos condicionados: há vínculos entre eles, ou seja, a ocorrência de
um dos eventos é afetada pelo fato de um outro ter ou não acontecido.
DEFINIÇAO DE PROBABILIDADE: Dado um experimento aleatório (E) e (S) o espaço amostral,
probabilidade de um evento (A) denotada como P(A), é uma função definida em S que associa a cada
evento um numero real, satisfazendo os seguintes axiomas:
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
62
Estatística Descritiva
1.
Profª Maria Eliane
Para todo o evento A, a probabilidade de sua ocorrência será sempre um valor compreendido
entre 0 e 1: 0<P(A)<1 . Significa que o resultado do cálculo de uma probabilidade não pode
ser negativo, e pode ser escrito de modo percentual como de 0% a 100% de ocorrer.
2. P(A) = 0 (quando for um evento impossível de acontecer)
3. P(A) = 1 (quando for um evento certo de ocorrer)
4. Se Ā é o evento complementar de A, então,
P(Ā) = 1 - P(A)
e
P(A) + P(Ā) = 1
5. P(S) = 1 (todo o espaço amostral tem soma igual a 1). Ex.: no lance de uma moeda o espaço
amostral S= {Cara;Coroa}, como a probabilidade de ocorrer cara ou coroa é de ½, então:
P(S)= P(Cara) + P(Coroa) = ½ + ½ = 1.
6. Se A e B forem eventos mutuamente exclusivos ( A∩B = Ø ), então, P( A U B) = P(A) + P(B)
Representando pelo diagrama de Venn:
S
A
B
7. Se A e B forem eventos não mutuamente exclusivos, então, P( A U B) = P(A) + P(B) - P(A∩B)
Representando pelo diagrama de Venn:
A∩B
8. Se A e B são independentes P(A∩B) = P(A) * P(B)
9.Probabilidade condicional: P(AB) =
P( A ∩ B)
P( B)
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
63
Estatística Descritiva
Profª Maria Eliane
NOÇÕES DE ANÁLISE COMBINATÓRIA
Exemplo: considere três pares de cromossomos homólogos com seus centrômeros identificados por
A/a, B/b e C/c. Quantos tipos diferentes de produtos meióticos este indivíduo pode produzir?
Cada cromossomo representa os estados da natureza:
Cada centrômero representa as ações possíveis:
n
N
Como o crescimento é multiplicativo geométrico, temos Nn
Pela restrição da diferença de produtos (os produtos meióticos devem ser diferentes) N=2
Então: Nn = 23 = 8 combinações diferentes possíveis.
Ilustrando-se pela árvore de probabilidade temos:
B
A
b
B
a
b
C
c
C
c
C
c
C
c
ABC
Abc
AbC
Abc
aBC
aBc
abC
abc
Observe que a árvore de probabilidade lembra o heredograma.
VARIÁVEIS ALEATÓRIAS
Em nossas aulas introdutórias, vimos que os resultados de uma característica, que se tem o
interesse
em
pesquisar,
podem
ser classificados
segundo
duas
categorias:
qualitativa e
quantitativamente. Vimos também que, como essa característica de interesse fornece resultados variados
de elemento para elemento do conjunto pesquisado, ela é denominada de variável. E esboçamos o
seguinte esquema de classificação e exemplificação:
Variável Qualitativa: ordinal e nominal;
Variável Quantitativa: discreta e contínua.
Estamos interessados, em nossos estudos de Estatística, em medidas quantitativas.
Das noções de probabilidade, vimos o que é experimento, evento, espaço amostral,
possibilidades e probabilidade. Realizamos alguns cálculos simples através das quais associamos um
número real a todo elemento do espaço amostral. Através destas noções básicas poderemos, agora,
iniciar o estudo sobre variável aleatória.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
64
Estatística Descritiva
Profª Maria Eliane
Definição 1: variável aleatória (v.a.) é uma função numérica X, que associa a cada elemento do espaço
amostral (ω ∈ Ω) um número real X(ω).
Exemplo 1- No lance de uma moeda temos:
Ω = {Cara, Coroa}
X(ω) sejam os valores: 0 se for cara, e 1 se for coroa
Então, o domínio de X(ω)= {Cara, Coroa} e o contradomínio {0,1}, ou seja, X(ω)=xi ⇒ xi=0,1.
O termo aleatório indica que a cada possível valor da variável atribui-se uma probabilidade de
ocorrência, por isso também é chamada de variável estocástica. Podemos nos referir à v.a. também
como uma função aleatória ou função estocástica.
Denota-se uma variável aleatória por uma letra latina maiúscula, como X, Y, Z, W,... . O mais
usual é a utilização da letra X.
Através da definição 1 trabalharemos o conceito de variável aprendido nas noções de estatística,
reelaborando o conceito de variável quantitativa discreta e contínua à luz dessa definição.
Variável aleatória discreta (v.a.d.)
Definição 2: uma v.a.d. real X, em um espaço de probabilidade (Ω, A, P), é uma função real X(ω) cujo
domínio é Ω e cujo contradomínio é um subconjunto finito ou infinito enumerável {x1, x2, x3,...} dos
números reais ℝ , tal que {ω:X(ω) = xi} é um evento para todo i. Diz-se que os eventos da v.a.d. são
unitários νX= { xi , i=1,2,3,...}.
Variável aleatória contínua (v.a.c.)
Definição 3: uma v.a.c. real X, em um espaço de probabilidade (Ω, A, P), é uma função real X(ω), ω ∈
Ω, tal que {ωX(ω) ≤ x} é um evento para -∞<x<∞.
Em outras palavras, uma v.a.c. é aquela que toma um número infinito (não-enumerável) de valores. O
contradomínio de X é um intervalo, ou uma coleção de intervalos.
Funções da variável aleatória discreta
Seja X uma v.a.d. com x1, x2, x3,..., seus diferentes (possíveis) valores.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
65
Estatística Descritiva
Profª Maria Eliane
Definição 4: a função que atribui a cada valor (x1, x2, x3,...) da v.a.d. sua probabilidade é denominada de
função de probabilidade (f.p.). É denotada por:
P(X= xi ) = p (xi ),
i = 1,2,3,…
ou P(X= xi ) = f (x)
Como é uma função, p(⋅), deve satisfazer às seguintes propriedades:
i)
0≤ p(xi ) ≤1, para todo xi
ii)
∑ p( x ) = 1
i
x
Definição 5: a soma das probabilidades dos valores xi menores ou iguais a x, em um ponto x, é a função
acumulada de probabilidades ou função de distribuição acumulada (f.d.a. ou f.d.). É denotada por:
FX ( x ) = P( X ≤ x )
FX ( x ) = ∑ p ( xi )
xi ≤ x
Em fenômenos da realidade algumas v.a.’s são muito notórias, sendo explicadas através de seus
modelos de distribuição.
Diante disso, as distribuições de probabilidade são úteis para investigação, pesquisa e observação
de problemas com variáveis aleatórias discretas ou contínuas, facilitando a análise e interpretação dos
dados para conclusão por dedução. Ou seja, servem para explicar fenômenos aleatórios de observação
clínica, econômica, biológica, etc., através de modelo matemático probabilístico.
Muitos são os modelos que descrevem o comportamento das variáveis aleatórias discretas, entre
eles:
•
Binomial
•
Poisson
Também são muitos os modelos que descrevem o comportamento das variáveis aleatórias
contínuas, o principal é a distribuição Normal.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
66
Estatística Descritiva
Profª Maria Eliane
Distribuição binomial
É constituída pelo número de vezes que ocorre determinado evento, quando a probabilidade desse
evento for constante em cada prova.
É adequada aos experimentos que apresentam apenas dois resultados:Sucesso/Insucesso ou seja,
Ocorre/Não ocorre o evento em
estudo.
∗
Baseia-se nas seguintes hipóteses:
H1 n provas independentes e do mesmo tipo são realizadas
H2 cada prova admite dois resultados: ocorre ou não ocorre o evento
H3 a probabilidade de ocorrer o evento em cada prova é p e a de não ocorrer é 1-p=q.
∗
Fundamenta-se nas possibilidades dadas pela função de Bernoulli:
X=1 (ocorrência) = P(x1) = p
X=0 (não ocorrência) = P(x2)= 1 – p = q
∗
O somatório de todas as probabilidades da observação é igual a 1, ou seja, [p + (1-p)] = 1.
∗
O nome binomial é devido ao fato de o grau da variável está relacionado ao desenvolvimento do
binômio de Newton: (q+p)n.
∗
O número de possibilidades favoráveis ao evento é:
A fórmula para a distribuição binomial é:
P ( X = x) =
n
C x=
n!
x! (n − x )!
n!
⋅ p x ⋅ q n− x
x! (n − x )!
Onde, P(X=x)= probabilidade de ocorrer o evento desejado
x = número de provas
n = número de vezes que ocorre o evento
p = ocorrência do evento (em proporção ou freqüência relativa)
q = não ocorrência do evento (q = 1-p)
∗
Parâmetros da Distribuição Binomial:
Média
µ=n·p
Variância
σ2= n · p · q
Desvio padrão
σ = n× p×q
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
67
Estatística Descritiva
Profª Maria Eliane
Exemplo de distribuição binomial:
Os tipos de sangue M-N dos seres humanos estão sob o controle genético de um par de alelos
codominantes. Numa família com seis filhos, onde ambos os pais são do tipo MN, qual é a
probabilidade de encontrarmos três crianças do tipo M? considere que a ocorrência do tipo M é ¼.
Temos os seguintes fatos:
n = 6 filhos
x = 3 filhos
p = ¼ = 0,25 ou 25% , que é a ocorrência do tipo M
(1-p) = 1- 0,25 = 0,75 , que é a não ocorrência do tipo M.
Substituindo esses valores no modelo da distribuição binomial:
P ( X = x) =
P( X = 3) =
n!
⋅ p x ⋅ q n− x
x! (n − x )!
6!
⋅ (0,25) 3 ⋅ (0,75) 6−3 = 20 × 0,0156 × 0,4219 = 0,1318
3!(6 − 3)!
A probabilidade de em uma família com seis filhos, onde ambos os pais possuem sangue do tipo MN,
encontrarmos três crianças do tipo M é de 13,18%.
Distribuição de Poisson
∗
Idealizada pelo matemático francês Simeon Poisson.
∗
É um caso particular da distribuição de probabilidades, já que calcula apenas o número de
ocorrências do evento e não calcula as não ocorrências.
∗
Utilizada para descrever as possibilidades de determinado número de ocorrências em determinado
intervalo, espaço ou campo contínuo (tempo, comprimento, área, volume, peso, etc).
Ex.: Chegada de pacientes ao PS/minuto
Acidentes/dia
Microrganismos/cm3 de água
Ou seja, trabalha com a variável discreta inserida em um espaço contínuo (tempo, área, volume).
Baseia-se nas seguintes hipóteses:
H1 o experimento é constituído de eventos independentes
H2 só há um resultado possível: ocorrência do evento
H3 a probabilidade de ocorrer o evento é constante em todo o intervalo (espaço contínuo em estudo)
H4 a probabilidade de mais de uma ocorrência em um mesmo ponto é zero.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
68
Estatística Descritiva
∗
A fórmula da distribuição de Poisson é dada por:
Profª Maria Eliane
(λ t ) x − ( λt )
P ( X = x) =
⋅e
x!
Onde,
P(X=x)= probabilidade de ocorrer o evento desejado
λ = taxa média de ocorrências dos eventos por unidade de medida
(letra grega “lambda”)
t = espaço de medidas ou número de intervalos
x = número de ocorrências
e = base dos logaritmos neperianos (é um número infinito, e=2,71828...)
∗
Parâmetros da Distribuição de Poisson:
Média
µ=λ
Variância
σ² = λ
Desvio padrão σ = λ
Exemplo de distribuição de Poisson:
Suponha que apenas um em cada mil indivíduos, em uma população, seja albino. Se uma amostra de
100 indivíduos é retirada ao acaso desta população, qual é a probabilidade de se encontrar dois
indivíduos albinos?
Temos os seguintes fatos:
t = 100 indivíduos
x = 2 albinos
λ = um em cada mil indivíduos = 1/1000 = 0,001
Substituindo esses valores no modelo da distribuição de Poisson:
P ( X = x) =
(λ t ) x − ( λt )
(0,001 × 100) 2 −( 0,001×100 ) (0,9048)(0,01)
⋅e
= P ( X = 2) =
⋅e
=
= 0,0045
2!
2
x!
A probabilidade de se encontrar dois indivíduos albinos nessa população, é 0,45% isto é, é menor do
que 1% de chance.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
69
Estatística Descritiva
Profª Maria Eliane
Distribuições contínuas:
contínuas.
São as distribuições utilizadas para as variáveis aleatórias
Uma observação importante é que não se pode associar uma probabilidade pontual a cada valor da
variável contínua, pois ao se aplicar a fórmula matemática de probabilidade:
P ( A) =
n( A)
n( A)
como n(U) = ∞ ⇒ P ( A) =
=0
n(U )
∞
Assim a distribuição de probabilidade das variáveis contínuas são dadas para intervalos de valores da
variável: P(a≤ X≤b).
A principal dentre os vários tipos de distribuição contínua e a mais utilizada é a Distribuição Normal.
Distribuição Normal: O estudo da variável contínua na distribuição normal é feita com o auxílio da
curva normal padrão (denominada de curva de Gauss ou do Sino), através da Variável Aleatória
Padronizada (VAP), denominada de Z cujos valores são lidos em uma tabela.
A variável aleatória X tem distribuição normal com média µ e variância σ2 , representada por:
X~N(µ ; σ2). Para a variável transformada Z representamos Z~N(0;1) sendo,
Z=
∗
x−µ
σ
O modelo matemático da Distribuição Normal é:
P ( x1 ≤ X ≤ x 2 ) = P ( z1 ≤ Z ≤ z 2 ) =
x1 − µ
σ
≤Z≤
x2 − µ
σ
Onde,
x=
µ=
σ=
valor da média da variável observada
valor da média populacional
valor do desvio padrão populacional
Os resultados obtidos (área de z1 e de z2)são lidos na tabela normal padrão (em anexo).
Como a área associada a um ponto é igual a zero, para o cálculo de probabilidades sob uma curva
normal torna-se indiferente o uso dos sinais < ou ≤ bem como > ou ≥.
A distribuição normal é a mais importante para os estudos da estatística, pois é através dela que se
baseia toda a conclusão estatística por meio da Inferência, fazendo a ligação entre a Estatística
Descritiva e a Probabilidade, dando sustentação ao caráter afirmativo de confiança nos estudos e testes
realizados.
Para o estudo da variável aleatória X com distribuição normal valem as seguintes propriedades:
a) A curva é simétrica, centrada na média;
b) A distância de µ aos pontos onde a curvatura da distribuição muda de sentido é igual a σ ;
c) A moda e a mediana de X são iguais à média;
d) A área sob a curva Normal e acima do eixo horizontal é igual a 1;
e) É assintótica em relação ao eixo das abscissas.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
70
Estatística Descritiva
Profª Maria Eliane
Exemplo de distribuição Normal: em um estudo com a mosca das frutas, observou-se que o tempo
decorrido entre a ovoposição e a emergência do adulto, na sequência ovo-larva-pulpa-adulto, é de
273horas em média, com desvio padrão de 20horas (Nascimento, 1992). Qual é a probabilidade de
ocorrer um tempo entre a ovoposição e a emergência, entre 260 e 280horas?
Pelo desenho da curva, a ocorrência deseja representa a seguinte área hachurada:
no modelo de cálculo temos:
P( x1 ≤ X ≤ x2 ) = P( z1 ≤ Z ≤ z 2 ) =
x1 − µ
σ
≤Z≤
x2 − µ
σ
260 − 273
280 − 273
≤Z≤
20
20
P(260 ≤ X ≤ 280) = −0,65 ≤ Z ≤ +0,35
P(260 ≤ X ≤ 280) =
P(260 ≤ X ≤ 280) = 0,2422 + 0,1368
P(260 ≤ X ≤ 280) = 0,3790
260h
273h
280h
Pelo enunciado do exemplo, sabemos
que:
a média é µ=273
o desvio padrão é σ=20
limite inferior do intervalo é z1=260
limite superior do intervalo é z2=280
Logo, a probabilidade de ocorrer ovoposição emergência adulto em
período de tempo entre 260-280horas é de 37,90%.
Esses valores (-0,65 e +0,35) serão lidos na tabela da distribuição
normal da p.71. Como a curva é simétrica (lado esquerdo e direito
ao eixo da média são iguais) os valores são lidos como módulo,
não se considera o sinal. Observe pela tabela que o valor para 0,65 é 0,2422 e para +0,35 é 0,1368. Deixei marcado com um
retângulo para facilitar sua compreensão. Como a área desejada
está em torno da média, a operação feita é de soma desses dois
valores encontrados para z1 e z2.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
71
Estatística Descritiva
Profª Maria Eliane
Tabela para leitura dos valores da distribuição Normal (x=z)
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
72
Estatística Descritiva
Profª Maria Eliane
TESTES DE HIPÓTESES
CONCEITO
É uma regra de decisão para aceitar ou rejeitar uma hipótese com base nas
diferenças observadas entre os valores alegados e aqueles fornecidos pelas
estatísticas amostrais.
Hipótese estatística é uma suposição quanto ao valor de um parâmetro
populacional, ou quanto à natureza da distribuição de probabilidade de
uma variável populacional.
UTILIDADE
Fazer Inferência Estatística com o maior nível possível de confiança e
representação, partindo de algum referencial (amostras).
APLICAÇÃO
Investigação, pesquisa e observação de problemas, especialmente para
avaliação de situações múltiplas. Exemplos:
a) testar as afirmativas feitas por fabricantes sobre % de defeitos de um
lote de medicamentos;
b) verificar se o teor de oxigênio DBO em amostras de um rio está dentro
do limite tolerável estabelecido por órgão de controle ambiental.
PRESSUPOSTO
ADOTADOS
Variáveis normalmente distribuídas.
CONCEITUAÇÕES:
IMPORTANTES
Nível de significância: define a probabilidade de o teste aceitar
uma hipótese falsa. É representado por α=0,05 α=0,01 α=0,1 que são os
valores mais usados. Equivale à região crítica onde rejeita-se a hipótese
principal.
Nível de confiança: define o intervalo em que deve cair o parâmetro
amostral para que se possa considerar verdadeira a hipótese formulada. É
representado por 1-α=0,9 (90%) 1-α=0,95 (95%) 1-α=0,99 (99%),
sendo estes os valores mais usados, limitados pelos respectivos valores de
z. Equivale à região de aceitação onde aceita-se a hipótese principal.
Hipótese nula ou principal (Ho): é a que afirma uma dada propriedade
ou característica sobre a população. Vem sempre acompanhada do sinal =.
Hipótese alternativa (H¹): é a que se opõe ou nega a hipótese principal.
Vem acompanhada de um dos sinais: ≠ > ou <.
Teste Bilateral: utiliza toda a área da curva normal (as duas caudas para
os valores críticos), considerando os níveis: 90% 95% e 99%.
Teste Unilateral: utiliza uma parte da curva (à esquerda ou à direita para
os valores críticos ), considerando os níveis de 40% 45% e 49%.
Erro Tipo I ou alfa: é o erro de se aceitar H0, quando a H1 é verdadeira.
Erro tipo II ou beta: é o erro de se rejeitar H0, sendo ela a hipótese
verdadeira verdadeira.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
73
Estatística Descritiva
Profª Maria Eliane
• As hipóteses definidas da forma: H0: θ = x1 versus Ha: θ = x2
sem conter desigualdades, são denominadas hipóteses simples .
•
As hipóteses definidas da forma: H0: θ = θ0
H1: θ ≠ θ0
H1: θ > θ0
ou
H1: θ < θ0
são denominadas de hipóteses compostas, sendo as mais comumente utilizadas, definindo-se se o teste é
uni ou bilateral, de acordo com o interesse do estudo. Por conveniência técnica, a hipótese nula sempre
fica com o sinal de igualdade.
•
Uma parte importante do teste de hipóteses é controlar a probabilidade de cometer os erros
associados:
α = P(erro tipo I)= P(rejeitar H0|H0 verdadeira)
β = P(erro tipo II) = P(não rejeitar H0| H0 falsa)
A situação ideal é aquela em que ambas as probabilidades estão próximas de zero. Entretanto, à medida
que diminui o erro alfa, a probabilidade de beta aumenta. Portanto, deve-se construir as hipóteses de
maneira que o erro mais importante seja evitado, que é o erro tipo alfa.
•
De modo geral, como o erro beta depende do valor de µ, é conveniente obter uma função que ajude a
caracterizar o desempenho do teste: Função de Poder do Teste, dada por:
g (µ ) = 1 − β (µ )
Para um mesmo nível de significância α, quanto maior o poder melhor o teste.
Como não se pode diminuir os dois erros simultaneamente, uma alternativa é aumentar o tamanho da
amostra, pois quanto maior for n, melhor é a precisão do estimador utilizado e maior é o poder do teste.
A função β é também chamada Curva Característica de Operação CCO, que são gráficos que indicam
as probabilidades de erros do tipo II, sob várias hipóteses. Elas proporcionam indicações de como testes
bem aplicados podem possibilitar a redução ao mínimo de erros do tipo I e II, i.é., indicam o poder do
teste, para evitar que sejam tomadas decisões erradas. São úteis no planejamento de experiências, por
mostrarem, por exemplo, que tamanhos de amostras devem ser usados.
•
Os testes de hipóteses para a média apresentados pressupõem variância conhecida. Se a variância for
desconhecida, deve-se utilizar a estatística t-Student, valendo-se do estimador da variância
populacional, que é a variância amostral s2.
•
Se a variável de interesse, além de ter variância desconhecida, não tiver densidade Normal, é
necessário utilizar técnicas não-paramétricas para a realização do teste da média.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
74
Estatística Descritiva
Profª Maria Eliane
Testes de Hipóteses Utilizando o Nível Descritivo:
Ao realizarmos um teste de hipóteses, partimos de um dado valor de alfa pré-fixado, para
construir a regra de decisão. Uma alternativa é deixar a cargo de quem vai utilizar as conclusões do teste
a escolha do valor para a probabilidade alfa, que não precisará ser fixada a priori.
A idéia consiste em calcular, supondo que a hipótese nula seja verdadeira, a probabilidade de se
obter estimativas mais desfavoráveis ou extremas (à luz da H1) do que a que está sendo fornecida pela
amostra.
Esta probabilidade será o nível descritivo, denotado por α∗ (ou p-valor). Valores pequenos de
α indicam que a hipótese nula é falsa pois, sendo a amostra a ferramenta de inferência sobre a
população, ela fornece uma estimativa que teria probabilidade muito pequena de acontecer, se H0 fosse
verdadeira. O conceito do que é pequeno fica a cargo do usuário, que assim decide qual alfa utilizar para
comparar com o valor α∗ obtido.
∗
Observações importantes:
•
Para comparação de médias de mais do que duas populações, o método utilizado é o teste ANOVA
(Análise de Variância).
•
Para a comparação de várias variâncias deve-se utilizar o teste de Cochran (para amostras de mesmo
tamanho), e o teste de Bartlett ( para amostras de tamanhos diferentes).
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
75
Estatística Descritiva
Profª Maria Eliane
TESTES DE HIPÓTESES (Clássico)
Teste Bilateral:
Região de
Rejeição
Região de
Rejeição
α/2
α/2
Região de
Aceitação
para Ho
1-α
-z
H0 : θ = x
H1 : θ≠
x
(Hipótese Nula)
(Hipótese Alternativa)
+z
Região de
Rejeição
α
Região de
Aceitação
para Ho
1-α
Teste Unilateral à Esquerda:
H0 : θ = x
H1 : θ < x
-z
Região de
Aceitação
para Ho
1-α
(Hipótese Nula)
(Hipótese Alternativa)
Região de
Rejeição
α
Teste Unilateral à Direita:
H0 : θ = x
H1 : θ > x
(Hipótese Nula)
(Hipótese Alternativa)
z
Valores Críticos de ±z:
Para
Teste
Bilateral
Teste
Unilateral
α = 10%
α = 5%
α = 1%
1,64
1,96
2,58
1,28
1,64
2,33
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
76
Estatística Descritiva
Profª Maria Eliane
Distribuição t-Student: é utilizada para amostras com número de elementos menor do que 30, que têm
a variável aleatória contínua X com uma distribuição normal. O estudo de X é feito através da variável
t, chamada de variável estudentizada representada como t≈N(0;1) com valores também lidos em tabela.
Os valores de t dependem do número de elementos da amostra em estudo, por isso a dependência dos
graus de liberdade.
O modelo de cálculo da Distribuição t é:
t=
x −μ
s
n
Onde,
x
µ
s
n
=
=
=
=
valor da média da variável observada
valor da média populacional
valor do desvio padrão amostral
tamanho da amostra
A leituras dos valores da área de t levam em consideração o nível de confiança (probabilidade) e o grau
de liberdade (n-1). Também tem seus valores lidos em tabela (ver p.78).
A distribuição T-Student tem a curva semelhante à curva Normal, todavia é mais achatada e com
probabilidades mais densas nas caudas, conforme mostra a figura 5.3 a seguir:
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
77
Estatística Descritiva
Profª Maria Eliane
Exemplo de teste de hipóteses: estudos anteriores mostravam que a alcalinidade média do rio Caí era
de 19,6mg de CaCo3/L (Vargas, 1992). Entretanto, estudo recente com 16 observações, a média de
CaCo3/L encontrada foi de 16,2mg e desvio padrão de 7,7mg. Esse novo valor estará indicando que a
alcalinidade no rio se modificou? ou será que a diferença de 3,4mg é devida a um erro aleatório?
Como o que se deseja é apenas verificar se a alcalinidade se modificou, e não se é menor que 19,6mg, o
teste é bilateral.
Adotaremos nível de significância (ou seja, admitiremos erro máximo nesse teste de hipótese em relação
ao verdadeiro valor da concentração de CaCo3/L no rio Caí) de α/2=5%/2=2,5%. Isso quer dizer que
vamos comparar o valor de t-calculado com o valor de t-tabelado sob os seguintes critérios:
α/2=5%/2=2,5%=0,025
para n-1graus de libredade = 16-1 = 15
(observe o valor marcado com um retângulo na tabela da p.78).
na tabela t será o valor = 2,131
O desenho da curva e escrita das hipóteses do teste bilateral é:
Região de
Rejeição
Região de
Rejeição
α/2=0,025
α/2=0,025
α/2=0,025
Teste Bilateral:
H0 : µx=19,90mg/L
(Hipótese Nula)
H1 : µx≠19,90mg/L
(Hipótese Alternativa)
Região de
Aceitação
para Ho
1-α
-t=-2,131
+t=+2,131
Se o valor de t-calculado estiver dentro de uma das áreas de α/2=0,025, rejeitamos a hipótese de que o
valor da alcalinidade é de 19,9mg/L. Então vamos ao cálculo:
pelo enunciado do exemplo sabemos que:
a média da hipótese principal ou nula é µx=19,60
a média da amostra em teste é µx=16,2
o desvio padrão é conhecido por meio da amostra, portanto é s e não σ, s=7,7
e o tamanho da amostra é n=16. Substituindo esses valores no modelo de cálculo:
t=
x − μ 16,2 − 19,6 − 3,4 − 3,4
=
=
=
= −1,766
s
7,7
7,7 1,925
4
n
16
Então, como (t-calculado = -1,766) é maior que (t-tabelado = -2,131), isto é, pertence à área de aceitação
da hipótese nula, podemos dizer que estatisticamente ao nível de confiança de 95% a alcalinidade do rio
Caí não se modificou.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
78
Estatística Descritiva
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
Profª Maria Eliane
79
Estatística Descritiva
Profª Maria Eliane
Teste qui-quadrado (χ2): a distribuição qui-quadrado é contínua e assimétrica, assumindo apenas
valores positivos. Assim como a distribuição normal e a distribuição t, a qui-quadrado também é
tabelada (ver tabela na p.81).O valor depende do tamanho da amostra, portanto dos graus de liberdade.
Como o teste qui quadrado é feito com dados representados por uma, tabela o graus de liberdade (g.l.)
vai considerar o número de de linhas (r) e o número de colunas (c), do seguinte modo:
g.l. = (r-1) x (c-1)
k
O modelo de cálculo do teste é: Q = ∑
2
i =1
(oi − ei ) 2
ei
Onde,
Σ
oi
ei
i
= somatório
= freqüência observada na i-ésima casela da tabela
= freqüência esperada na i-ésima casela da tabela
= i-ésima casela, ou seja, casela 1, 2, 3,... de uma tabela.
A distribuição χ2 tem curva assimétrica, conforme gravura a seguir:
Observe que os valores de χ2 serão todos positivos.
O χ21-γ;ν é chamado de qui quadrado inferior;
O χ2γ;ν é chamado de qui quadrado superior.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
80
Estatística Descritiva
Profª Maria Eliane
Exemplo do teste qui quadrado: em uma universidade foi apurada o número de estudantes dos cursos
da área de ciências humanas e de ciências exatas. Uma amostra de 170 estudantes apontou os seguintes
resultados, segundo o sexo:
Ciências
humanas
Ciências
exatas
Total
Masculino
48
52
100
Feminino
45
25
70
Total
93
77
170
Será que o sexo influência a escolha da área de estudo?
Para responder esta pergunta, primeiro precisamos transformas as freqüências absolutas (observadas) da
tabela em freqüências percentuais (esperadas).
Ciências
humanas
Ciências
exatas
Masculino
55
45
Feminino
38
32
A pergunta agora é a proporção do sexo masculino (πM) é igual à de mulheres (πF) nas áreas de estudo?
Vamos adotar um nível de significância de 5%. Os grau de liberdade para 2linhas e 2colunas será:
(2-1)x(2-1)=1. Então 1 g.l. e α=0,05, o valor de χ2-tabelado = 3,841.
O desenho da curva e a construção das hipóteses é:
Área de
rejeição
α=0,05
Área de
aceitação
para H0
H0 : πM = πF (as proporções são iguais nas áreas de estudo)
H1 : πM ≠ πF (as proporções são diferentes nas áreas de estudo)
3,841
O qui quadrado calculado é:
k
Q =∑
2
i =1
(oi − ei ) 2 (48 − 55) 2 (52 − 45) 2 (45 − 38) 2 (25 − 32) 2
=
+
+
+
= 4,79 .
ei
55
45
38
32
Como (χ2-calculado = 4,79) é maior que ( χ2-tabelado = 3,841), ou seja, está na área de rejeição da
hipótese nula, pode-se dizer que estatisticamente ao nível de confiança de 95% do teste há influência do
sexo na escolha da área de estudo.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
81
Estatística Descritiva
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
Profª Maria Eliane
82
Estatística Descritiva
Profª Maria Eliane
BIBLIOGRAFIA CONSULTADA
BOTTER, Denise Aparecida. Noções de estatística. São Paulo, EDUSP, 1996, pg. 45-76.
CALLEGARI-JACQUES, S. M. Bioestatística. Porto Alegre: Artmed, 2003.
FRANCISCO, Walter de. Estatística. São Paulo, Atlas, 1982, pg.71-121.
GRIFFITHS, A. J. F. et al. Introdução à genética. Rio de Janeiro: Guanabara Koogan, 2006.
HOEL, P. G.; PORT, S. C.; STONE, C.J. Introdução à teoria da probabilidade. Rio de Janeiro:
Interciência, 1978.
LINDGREN, B. W. Introdução à estatística. São Paulo: Ao livro Técnico, 1972.
MENDENHALL, W. Probabilidade e estatística. Rio de Janeiro: Campus, 1985.
MEYER, P. Probabilidade – aplicações à estatística. Rio de Janeiro: 2.ª ed. Livros Técnicos e
Científicos Editora, 1984.
MILONE, G.; ANGELINI, F. Estatística Geral. São Paulo: Ed. Atlas, 1993.
MIRSHAWKA, V. Estatística. São Paulo: Nobel, 1972.
SPIEGEL, M.R. Probabilidade e Estatística. São Paulo: McGraw-Hill do Brasil, 1978.
STANSFIELD, W.D. Genética. São Paulo: McGraw Hill do Brasil, 1985.
TOLEDO, G. L.; OVALLE, I. I. Estatística Básica. São Paulo: Atlas, 1994.
Licenciatura em Biologia, Educação à Distância, UESC 2011.2
83