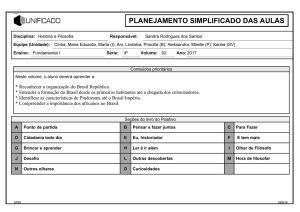
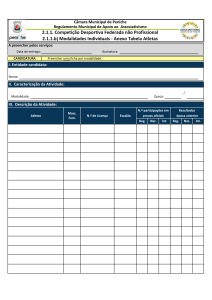
O Processador: Caminho
de Dados e Controle
Implemtação Monociclo
Implementação Multiciclo: Passos
1. Busca de instrução
2. Decodificação da instrução e busca do
registrador
3. Execução, cálculo do endereço de memória ou
efetivação do desvio condicional
4. Final da execução das instruções de acesso à
memória e do tipo R
5. Final do passo de leitura de memória
1° Passo: busca da instrução
IR=Memória[PC]
PC=PC+4
• Envio do PC para a memória como
endereço, realização da leitura e escrita
da instrução no registrador de instruções.
2° Passo: decodificação da
instrução e busca do registrador
a)
Executa algumas operações que podem depois ser
descartadas após a decodificação da instrução (ainda
não se sabe qual instrução está no IR)
São executadas para evitar a perda de tempo durante
a execução (ler rs e rt)
Carga de:
b)
c)
–
–
d)
e)
f)
Registradores de entrada da ULA
Endereço de desvio condicional (salvo em UALSaída)
A = Reg[IR[25-21]];
B = Reg[IR[20-16]];
UALSaída = PC + extensão de sinal (IR[15-0] << 2);
3° Passo: Execução, cálculo do
endereço de memória ou efetivação do
desvio condicional
a) Referência à memória
UALSaída = A + extensão de sinal IR[15-0]
b) Instrução aritmética ou lógica (tipo R)
UALSaída = A op B
c) Desvio condicional
Se (A == B) PC = UALSaída
d) Desvio incondicional
PC = PC [31-28] || (IR[25-0]<<2)
4° Passo: Final da execução das
instruções de acesso à memória e do
tipo R
a) Referência à memória
MDR = Memória [UALSaída];
ou
Memória = [UALSaída] = B;
b) Instruções aritméticas ou lógicas (tipo R)
Reg[IR[15-11]] = UALSaída;
5° Passo: Final de leitura da
memória
•
Load word:
– Reg[IR[20-16]] = MDR
Implementação Multiciclo
Como melhorar o desempenho ?
Pipelining
Técnica
de implementação em que várias instruções
são sobrepostas na execução
Pipelining não diminui o tempo para concluir uma
instrução, mas aumenta a vazão, reduzindo o tempo
para concluir a aplicação
Instruções MIPS normalmente exigem cinco
etapas: busca, decodificação/leitura de
registradores, cálculo de operação/endereço;
acesso a operando na memória, escrita de
resultado em registrador
Pipelining
de cinco estágios
Desempenho de ciclo único X
desempenho com pipelining
Classe
Busca de
Instruções
Leitura de
Registrador
Operação Acesso a
de ALU
Dados
Tipo R
200
100
200
lw
200
100
200
200
sw
200
100
200
200
Branch
200
100
200
Escrita em
Registrado
r100
Total
100
800
600
700
500
Desempenho de ciclo único X
desempenho com pipelining
Tempo
0
200
Busca
Reg
instrução
400
ALU
600
800
1000
1200
1400
1600
1800
Acesso
Reg
à dados
800ps
Busca
Reg
instrução
ALU
800ps
Ordem de execução do
programa (em instruções)
Acesso
Reg
à dados
Busca
instrução
Desempenho de ciclo único X
desempenho com pipelining
Tempo
Busca
instrução
200
600
400
200
0
Reg
Busca
instrução
200
ALU
Reg
Busca
instrução
200
Ordem de execução do
programa (em instruções)
800
1200
1000
1400
Acesso
Reg
à dados
ALU
Reg
200
Acesso
Reg
à dados
ALU
200
Acesso
Reg
à dados
200
200
1600
1800