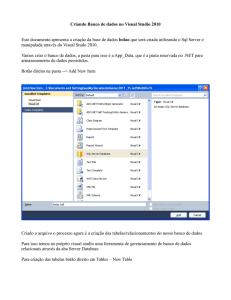
Modelo de dados do Data Warehouse
Ricardo Andreatto
O modelo de dados tem um papel fundamental para o desenvolvimento interativo do
data warehouse. Quando os esforços de desenvolvimentos são baseados em um único
modelo de dados sempre que for necessário unir estes esforços os níveis de
sobreposição de trabalho e desenvolvimento desconexo serão muito baixos, pois todos
os componentes do sistema estarão utilizando a mesma estrutura de dados.
Existe um grande número de enfoques sobre modelagem de dados já desenvolvidos por
vários autores, a maioria deles pode ser usada para construir um data warehouse. Dentre
estes modelos apenas o multidimensional será apresentado neste trabalho.
A Questão das Dimensões
Obter respostas a questões típicas de análise dos negócios de uma empresa geralmente
requer a visualização dos dados segundo diferentes perspectivas. Como exemplo,
imagine-se uma agência de automóveis que esteja querendo melhorar o desempenho de
seu negócio. Para isso, necessita examinar os dados sobre as vendas disponíveis na
empresa. Uma avaliação deste tipo requer uma visão histórica do volume de vendas sob
múltiplas perspectivas, como por exemplo: volume de vendas por modelo, volume de
vendas por cor, volume de vendas por fabricante, volume de vendas por período de
tempo. Uma análise do volume de vendas utilizando uma ou mais destas perspectivas,
permitiria responder questões do tipo:
Qual a tendência em termos de volume de vendas para o mês de dezembro para
modelos Volvo Sedan preto?
A capacidade de responder a este tipo de questão em tempo hábil é o que permite aos
gerentes e altos executivos das empresas formular estratégias efetivas, identificar
tendências e melhorar sua habilidade de tomar decisões de negócio. O ambiente
tradicional de bancos de dados relacional certamente pode atender a este tipo de
consulta. No entanto, usuários finais que necessitam de consultas deste tipo via acesso
interativo aos bancos de dados, mostram-se seguidamente frustrados por tempos de
resposta ruins e pela falta de flexibilidade oferecida por ferramentas de consulta
baseadas no SQL. Daí a necessidade de utilizar abordagens específicas para atender a
estas consultas.
Para compreender melhor os conceitos envolvidos, examinemos em maior detalhe o
exemplo acima. Chamaremos de dimensões as diferentes perspectivas envolvidas, no
caso, modelo, loja, fabricante, mês. Estas “dimensões” usualmente correspondem a
campos não numéricos em um banco de dados. Consideremos também um conjunto de
“medidas”, tal como vendas ou despesas com promoção. Estas medidas correspondem
geralmente a campos numéricos em um banco de dados. A seguir, avaliam-se
agregações destas medidas segundo as diversas dimensões e as armazenamos para
acesso futuro. Por exemplo, calcula-se a média de todas as vendas por todos os meses
por loja. A forma como estas agregações são armazenadas pode ser vista em termos de
dimensões e coordenadas, dando origem ao termo multidimensional.
1/10
Intuitivamente, cada eixo no espaço multidimensional é um campo/coluna de uma
tabela relacional e cada ponto um valor correspondente à interseção das colunas. Assim,
o valor para o campo vendas, correspondente a mês igual a maio e loja igual a Iguatemi
é um ponto com coordenada [maio, Iguatemi]. Neste caso, mês e loja são duas
dimensões e vendas é uma medida.
Teoricamente, quaisquer dados podem ser considerados multidimensionais. Entretanto,
o termo normalmente se refere a dados representando objetos ou eventos que podem ser
descritos, e, portanto, classificados por dois ou mais de seus atributos.
Estruturas relacionais podem ser usadas para a representação e o armazenamento de
dados multidimensionais. Neste caso, as abordagens encontradas incluem desde a
adoção de formas específicas de modelagem (os chamados esquemas estrela e floco de
neve) até mecanismos sofisticados de indexação.
Esquemas do tipo Estrela e Floco de Neve
Em um esquema do tipo estrela ou "star" as instâncias são armazenadas em uma tabela
contendo o identificador de instância, valores das dimensões descritivas para cada
instância, e valores dos fatos, ou medidas, para aquela instância (tabela de fatos). Além
disso, pelo menos uma tabela é usada, para cada dimensão, para armazenar dados sobre
a dimensão (tabela de dimensão). No caso mais simples, a tabela de dimensão tem uma
linha para cada valor válido da dimensão. Esses valores correspondem a valores
encontrados na coluna referente àquela dimensão na tabela de fatos.
Este esquema é chamado de estrela, por apresentar a tabela de fatos "dominante" no
centro do esquema e as tabelas de dimensões nas extremidades. A tabela de fatos é
ligada às demais tabelas por múltiplas junções, enquanto as tabelas de dimensões se
ligam apenas à tabela central por uma única junção. A figura abaixo mostra um exemplo
de um modelo tipo estrela.
2/10
Modelo Estrela
A tabela de fatos é onde as medidas numéricas do fato representado estão armazenadas.
Cada uma destas medidas é tomada segundo a interseção de todas as dimensões. No
caso do exemplo, uma consulta típica selecionaria fatos da tabela FATOSVENDAS a
partir de valores fornecidos relativos a cada dimensão.
Outro tipo de estrutura bastante comum é o esquema do tipo floco de neve ou
"snowflake", que consiste em uma extensão do esquema estrela onde cada uma das
"pontas" da estrela passa a ser o centro de outras estrelas. Isto porque cada tabela de
dimensão seria normalizada, "quebrando-se" a tabela original ao longo de hierarquias
existentes em seus atributos. No caso do exemplo, a dimensão produto possui uma
hierarquia definida onde categoria se divide em marca e marca se divide em produtos
(veja figura). Da mesma forma, a dimensão tempo inclui ano que contem mês e mês que
contem dia-do-mes. Cada um destes relacionamentos muitos-para-1 geraria uma nova
tabela em um esquema floco de neve.
Vantagens do modelo estrela
•
O modelo Estrela tem uma arquitetura padrão e previsível. As ferramentas
de consulta e interfaces do usuário podem se valer disso para fazer suas
interfaces mais amigáveis e um processamento mais eficiente;
•
Todas as dimensões do modelo são equivalentes, ou seja, podem ser vistas
como pontos de entrada simétricos para a tabela de fatos. As interfaces do
usuário são simétricas, as estratégias de consulta são simétricas, e o SQL
gerado, baseado no modelo, é simétrico;
•
O modelo dimensional é totalmente flexível para suportar a inclusão de
novos elementos de dados, bem como mudanças que ocorram no projeto.
Essa flexibilidade se expressa de várias formas, dentre as quais temos:
o
Todas as tabelas de fato e dimensões podem ser alteradas
simplesmente acrescentando novas colunas a tabelas;
o
Nenhuma ferramenta de consulta ou relatório precisa ser alterada
de forma a acomodar as mudanças;
o
Todas as aplicações que existiam antes das mudanças continuam
rodando sem problemas;
3/10
•
•
Existe um conjunto de abordagens padrões para tratamento de situações
comuns no mundo dos negócios. Cada uma destas tem um conjunto bem
definido de alternativas que podem então ser especificamente programadas
em geradores de relatórios, ferramentas de consulta e outras interfaces do
usuário. Dentre estas situações temos:
o
Mudanças lentas das dimensões: ocorre quando uma determinada
dimensão evolui de forma lenta e assíncrona;
o
Produtos heterogêneos: quando um negócio, tal como um banco,
precisa controlar diferentes linhas de negócio juntas, dentro de um
conjunto comum de atributos e fatos, mas ao mesmo tempo esta
precisa descrever e medir as linhas individuais de negócio usando
medidas incompatíveis;
Outra vantagem é o fato de um número cada vez maior de utilitários
administrativos e processo de software serem capazes de gerenciar e usar
agregados, que são de suma importância para a boa performance de
respostas em um data warehouse.
Bancos de Dados Multidimensionais
Embora seja viável utilizar estruturas relacionais na representação de dados
multidimensionais, a solução não é ideal. Na figura a seguir, é fácil verificar como uma
matriz bidimensional representa mais claramente os dados armazenados na forma
relacional tradicional. Na matriz, os valores de vendas estão localizados nas interseções
dos eixos X e Y da matriz 3x3. Cada eixo corresponde a uma dimensão, e cada
elemento dentro de uma dimensão corresponde a uma posição. Um array agrupa
informações semelhantes em colunas e linhas.
Além disso, na representação multidimensional, totais consolidados são facilmente
obtidos e armazenados, bastando simplesmente adicionar totais de colunas e fileiras
[CAM99].
4/10
Conversão do modelo E-R para o modelo do data
warehouse
Para tal, W. H. Inmon fornece então alguns passos que podem ser seguidos, não se
esquecendo de que o fundamental é que as decisões de transformação devem ser
tomadas levando-se em consideração os requisitos específicos da empresa. Os passos
básicos são:
Remoção dos dados puramente operacionais
A primeira ação consiste em remover os dados que são usados apenas no ambiente
operacional, como vemos no exemplo da figura abaixo. Neste, atributos tais como
mensagem, descrição e status são retirados, pois é muito pouco provável que estes
sejam utilizados no processo de tomada de decisão.
Neste momento, pode ser que se pense em manter todos os atributos, pois talvez algum
destes seja necessário para alguma decisão específica. Entretanto, deve-se levar em
conta o custo para gerenciar grandes volumes de dados.
Adição de um elemento de tempo na estrutura da chave
A segunda modificação a ser feita no modelo corporativo é adicionar um elemento de
tempo a chave das tabelas, se estas já não o tiverem.
No exemplo da figura a seguir, o campo Data_Snapshot foi adicionado como parte da
chave. Enquanto no modelo corporativo a chave é apenas a identificação do
consumidor, no modelo do data warehouse a data do instantâneo deve fazer parte da
chave, já que com o passar do tempo os dados do consumidor podem se alterar. Esta
técnica é apenas uma forma de tirar instantâneos dos dados.
Outra forma de fazê-lo é adicionar dois campos do tipo data, um marcando o início e
outro o fim de um determinado intervalo de tempo. Esta técnica é melhor por
representar faixas contínuas de tempo ao invés de pontos ou datas específicas.
5/10
Introdução de dados derivados
O próximo passo é adicionar dados derivados ao modelo, como mostrado na figura a
seguir, já que por regra geral estes não existem no modelo corporativo. Devem ser
adicionados os dados derivados que serão usados habitualmente de forma que estes
sejam calculados apenas uma vez. Dessa forma, haverá uma redução no processamento
que deve ser feito para acessar os dados derivados ou sumarizados.
Outra razão para o armazenamento de dados derivados é que uma vez calculados e
armazenados, a integridade destes aumenta, uma vez que se torna impossível a
utilização de diferentes algoritmos para o cálculo destes derivados.
Transformação de Relacionamentos entre dados em artefatos dos dados
Os relacionamentos encontrados nas modelagens de dados clássicas assumem que há
um e somente um valor de negócio no relacionamento. Levando-se em consideração
que nos sistemas operacionais o dado estar integro no momento da transação, esta
abordagem é correta. Entretanto, o data warehouse por sua característica de armazenar
dados históricos, tem muitos valores para um dado relacionamento entre duas tabelas.
Dessa forma a melhor maneira de representar o relacionamento entre duas tabelas no
data warehouse é através da criação de artefatos.
Um artefato de um relacionamento é somente a parte do relacionamento que é óbvia e
tangível no momento do instantâneo. Em outras palavras, quando o instantâneo é feito
os dados associados com o relacionamento que são úteis e óbvios serão colocados no
data warehouse.
O artefato pode incluir chaves estrangeiras e outros dados relevantes, tais como colunas
de tabelas associadas, ou este pode incluir somente os dados relevantes, sem incluir as
6/10
chaves estrangeiras. Como exemplo, consideremos as tabelas e o relacionamento entre
estas na figura a seguir.
Nesta existe um relacionamento entre produto e fornecedor, onde cada produto tem um
fornecedor principal. Se fossemos fazer então um instantâneo deste relacionamento,
teríamos que considerar a informação do fornecedor principal que está relacionado ao
produto. Além disso, outras informações de artefato relacionadas com o fornecedor
deveriam então ser capturadas. A tabela de produtos no modelo do data warehouse
ficaria então como a mostrada na figura abaixo.
Acomodação dos diferentes níveis de granularidade
Dependendo do caso, o nível de granularidade do sistema transacional pode ser o
mesmo do data warehouse ou não. Quando o nível de granularidade se altera, o modelo
do data warehouse deve representar esta mudança, como no exemplo da figura a seguir.
No exemplo, o modelo de dados corporativo mostra dados da atividade de envio de um
determinado produto que são armazenadas toda vez que uma entrega é feita. Quando
este é passado para o data warehouse, duas agregações são feitas, alterando então a
granularidade. Na primeira, o total de entregas é agregado mensalmente, fazendo com
que a granularidade seja o mês, já na segunda, existe uma agregação das entregas feitas
por mês e local de origem, fazendo então com que a granularidade seja o mês associado
ao fornecedor.
7/10
União dos dados comuns de diferentes tabelas
Nesta fase, deve-se considerar a possibilidade de combinar duas ou mais tabelas do
modelo corporativo em uma única tabela do modelo do data warehouse. Para que esta
junção possa ser feita, as seguintes condições devem ser verdadeiras:
•
As tabelas compartilham uma chave comum (ou chave parcial);
•
Os dados das diferentes tabelas geralmente são usados juntos;
•
Padrão de inserção nas tabelas é o mesmo.
Como exemplo, consideremos a figura a seguir, onde temos as tabelas NOTAS e ITENS
DAS NOTAS. Quando estas são colocadas no modelo do data warehouse, estas vão para
uma mesma tabela. Dessa forma, a junção entre estas tabelas passa a não ser mais
necessária quando uma consulta for feita. Neste caso, podemos ver que as três
condições são atendidas: as tabelas compartilham parte da chave, ID da Nota; estas duas
tabelas geralmente são usadas juntas; e o padrão de inserção é o mesmo, ou seja, sempre
que uma nota é inserida seus itens também o são.
8/10
Criação de arrays de dados
Os dados no modelo corporativo geralmente estão normalizados, onde a existência de
grupos repetitivos não é permitida. Entretanto, em algumas situações no ambiente de
data warehouse pode haver grupos repetitivos de dados. As condições para existência
destes são:
•
Quando o número de ocorrências do dado é previsível;
•
Quando a ocorrência do dado é relativamente pequena (em termos de
tamanho físico);
•
Quando as ocorrências do dado geralmente são usadas juntas;
•
Quando o padrão de inserção e remoção dos dados é estável;
A figura abaixo mostra uma tabela no modelo corporativo com as previsões de gasto
mensais. Quando esta é colocada no modelo do data warehouse, os dados são
armazenados de forma que cada mês do ano é uma ocorrência no array.
9/10
Separação dos atributos de dados de acordo com sua estabilidade
A próxima atividade de projeto, referente à passagem do modelo de dados da empresa
para o modelo de dados do data warehouse, consiste em realizar a análise de
"estabilidade". A análise de estabilidade é uma tarefa que consiste em agrupar atributos
de dados segundo sua propensão a alterações. A figura abaixo ilustra a análise de
estabilidade de uma tabela de produtos. Neste exemplo é possível perceber que os dados
que raramente sofrem alterações são agrupados com outros dados que apresentam essa
mesma característica, dados que às vezes são alterados são agrupados com outros dados
que às vezes são alterados e dados que freqüentemente são alterados são agrupados com
outros dados freqüentemente alterados. O resultado final da análise de estabilidade é a
criação de grupos de dados que apresentem características semelhantes.
10/10