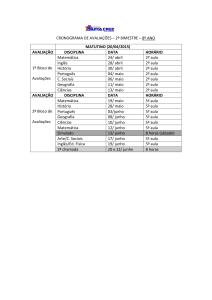
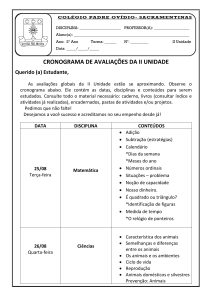
Criação de um Framework Generalista
para Filtragem Colaborativa Baseado em
Computação Paralela e Apache Hadoop
Antenor do Váu Cabrerisso
Objetivos
A Filtragem Colaborativa (Collaborative Filtering) é uma técnica muito
utilizada com a finalidade de gerar recomendações.
O principal objetivo deste trabalho é tentar resolver o problema encontrado
por instituições onde existem vários sistemas de domínios diferentes que
precisam gerar recomendações aos seus usuários.
A solução proposta deve ser flexível o bastante para não necessitar de
modificações para tratar as várias bases de dados disponíveis.
Problema
Geralmente as bases de dados processadas por essa técnica são muito grandes
Grande quantidade de dados esparsos
Cada usuário avalia apenas uma quantidade muito pequena dos itens
disponíveis
Vários sistemas de domínios diferentes que precisam gerar recomendações
aos seus usuários
Solução
Criação de framework (RecomFrame)
Gera recomendações através do cálculo da matriz de co-ocorrência
Flexível para tratar dados de domínios diferentes
Definição de um formato de entrada de dados genérico
Utilização de MapReduces para tratar grandes volumes de dados
Avaliação de Filmes
Usuário
Filme
Nota
1
101
5
1
102
3
1
103
2
2
101
2
Id
Usuário
Id
Filme
2
102
2
1
Antonio
101
Fargo
2
103
5
2
Paulo
102
Heavy Metal
2
104
2
3
Maria
103
Aristocats, The
3
101
2
4
Sandra
104
All Dogs Go to Heaven 2
3
104
4
5
Wagner
105
Theodore Rex
3
105
4
106
Sgt. Bilko
3
107
5
107
Diabolique
4
101
5
4
103
3
4
104
4
4
106
4
5
101
4
5
102
3
5
103
2
5
104
4
5
105
3
5
106
4
Geração de Recomendações
101
102
103
104
105
106
107
Antonio
101
5
3
4
4
2
2
1
5
102
3
3
3
2
1
1
0
3
103
4
3
4
3
1
2
0
2
104
4
2
3
4
2
2
1
0
105
2
1
1
2
2
1
1
0
106
2
1
2
2
1
2
0
0
107
1
0
0
1
1
0
1
0
Antonio
42
30
37
32
14
17
5
Itens em vermelho serão descartados pois o usuário já os assistiu
Itens em azul serão recomendados
Fluxo de Execução
Desafios
Necessidade de executar os Jobs de forma orquestrada
Uso do Hamake resolveu
Um dos grandes desafios desse trabalho foi a criação do ambiente para testes
Não existiam recursos financeiros e nem computacionais que viabilizassem a
criação de um cluster Hadoop
Máquina virtual preparada para trabalhar no modo “pseudo-distributed“
Ambiente de Testes
Notebook DELL
Intel Core i7-3612qm de 2.10 GHz
8 Gb RAM
Windows 8
Máquina Virtual (VirtualBox)
Ubuntu 12.04 LTS 64 bits
Apache Hadoop 1.03
com 4 núcleos
4 Gb RAM
Experimentação
Comparação com o método de recomendação baseado em co-ocorrência
disponível no Apache Mahout, versão 0.9
Bancos de dados do projeto MovieLens com várias quantidades de avaliações:
100.000
200.000
500.000
1.000.000
Resultados
O Apache Mahout se comportou bem com bases de tamanhos variáveis e
demonstrou estabilidade e escalabilidade
Testado com 100.000, 500.000 e 1.000.000 de avaliações
O RecomFrame para bases de 100.000 conjuntos de avaliações mostrou um
tempo de execução bem próximo ao do Mahout
Não foi capaz de escalar para bases maiores
Testado com 200.000 e 500.000
Resultados - Gráfico
Conclusão
O RecomFrame se mostrou efetivo para processar uma quantidade
considerável de conjuntos de avaliações e capaz de realizar boas
recomendações
Seu formato de entrada de dados permite que ele possa ser utilizados para
tratar dados de qualquer domínio que possa representar avaliações de itens
Pode ser uma alternativa viável ao Mahout em algumas situações
Próximos Passos
Realizar otimização no passo de recomendações para tornar mais escalável
Troca de algumas estruturas de dados que consomem muita memória por
versões mais leves
Otimização do algoritmo em si, eliminando alguns laços condicionais e
paralelizando a execução em determinados pontos
A realização de experimentos em um cluster Hadoop real seria muito
importante
Obrigado!