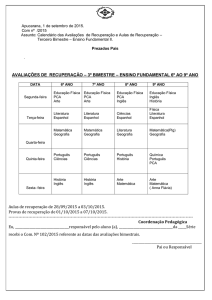
Reconhecimento de Padrões
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
Escola Superior de Tecnologia – Engenharia Informática
Reconhecimento de Padrões
Prof. João Ascenso
Sumário: Métodos não paramétricos
Introdução aos métodos não paramétricos
Janelas de Parzen
Método dos k vizinhos mais próximos
Classificação com o método dos k vizinhos mais
próximos
Distâncias (métricas)
Redução da dimensionalidade (PCA)
26-11-2003
2
Métodos não paramétricos
Na estimação de Bayes e de máxima verosimilhança a
forma das probabilidades é conhecida:
Na prática, as formas paramétricas mais conhecidas não são
adequadas a muitos problemas do mundo real.
Em particular, a maior parte das formas paramétricas são
unimodais enquanto muitos problemas práticos envolvem
densidades multimodais
Uma forma de ultrapassar este obstáculo é utilizar uma mistura de
densidades.
A outra forma é utilizar a estimação de parâmetros não
paramétrica
26-11-2003
3
Técnicas de estimação de parâmetros não paramétrica
Na estimação não paramétrica:
Existem dois tipos principais de estimação não paramétrica
de parâmetros no reconhecimento de padrões:
Não se assume que se conhece a forma de distribuição.
No entanto, calcula-se uma estimativa da função densidade de
probabilidade a partir dos dados de treino.
Estimação das funções de verosimilhança a partir das amostras de
treino.
Estimação directa das probabilidades à priori.
O método mais simples de estimação de parâmetros é o
método do histograma.
26-11-2003
4
Distribuição para características binárias
As características só podem assumir os valores 0,1.
Uma característica binária têm a probabilidade:
P(x = 1) = p
P(x = 0) = 1-p
E escreve-se da forma:
P( x) = p (1 − p )
x
(1− x )
Para um vector de d características i.i.d.
d
P( x) = ∏ p (1 − p)
xi
(1− xi )
i =1
26-11-2003
5
Método do histograma
Divide-se o espaço de amostras em intervalos ou células e
aproxima-se a densidade no centro de cada célula por uma
fracção de pontos dos dados de treino:
Intervalos de largura h e origem em x0,as células são definidas por:
⎡⎣ x0 + mh; x0 + ( m − 1) h⎤⎦
O histograma é definido como:
26-11-2003
6
Método do histograma
26-11-2003
7
Método do histograma
h controla a granularidade da estimativa:
26-11-2003
8
Método do histograma
Se h é largo:
Se h é estreito:
A probabilidade no intervalo é estimada com mais fiabilidade, uma
vez que é baseada num maior número de amostras.
Por outro lado, a densidade estimada é plana numa região muito
larga e a estrutura fina da distribuição é perdida.
Preserva-se a estrutura fina da densidade, mas o grau de
confiança diminui (no limite, pode haver intervalos sem amostras).
Regra empírica:
Sendo d o número de dimensões, o número de intervalos ou
1
células deve ser:
(n) d +1
26-11-2003
9
Método do histograma: problemas
Então, para ter nI intervalos por dimensão:
nI ≈ (n)
sao necessarias n ≈ (nI ) d +1 amostras de treino
Exemplo: d=5;10 intervalos ⇒ n ≈ 106
Problemas:
1
d +1
O histograma é descontínuo, é um artefacto da escolha dos
intervalos.
A escolha da origem pode ter um efeito significativo na estimativa
da densidade.
O número de intervalos cresce exponencialmente com o número
de dimensões.
Necessário um n.º elevado de amostras de treino.
Não é muito usado, apenas para visualização dos dados.
26-11-2003
10
Conceitos fundamentais
A maior parte das técnicas não paramétricas de estimação
de parâmetros assentam nos seguintes teoremas:
A probabilidade P que um vector x esteja contido na região R é
dado por:
P =
∫
p ( x)dx
R
Se tivermos n amostras, a probabilidade de k das n amostras
fazerem parte de R é:
Pk
⎛n⎞
= ⎜⎜ ⎟⎟ P
⎝k ⎠
26-11-2003
k
(1 − P ) n − k
E[k ] = nP
11
Conceitos fundamentais
A distribuição binomial possui um pico muito acentuado em
torno do valor esperado.
O número de amostras observadas em R (kobs) deve ser
aproximadamente igual a kobs ≈ E[k] = nP
O que leva a P = kobs/n
26-11-2003
12
Conceitos fundamentais
26-11-2003
13
Conceitos fundamentais
Se assumirmos p(x) como uma função contínua e a região R
tão pequena que p(x) não varia, vamos ter:
P =
∫
p ( x ) d x ≈ p ( x ') V
R
em que x’ é um ponto na região R e
V é o volume no espaço R
Combinando as equações temos:
k obs / n
p ( x ') ≅
V
26-11-2003
14
Conceitos fundamentais
Existem duas aproximações nas relações anteriores:
Se k (ou n) tender para infinito
ou V convergir para zero.
Então estas aproximações vão convergir para valores exactos.
26-11-2003
15
Conceitos fundamentais
De forma a estimar a densidade em x defini-se as seguintes
regiões que contêm o ponto x:
R1, R2, ...., Rn com 1, 2, ..., n amostras
kn / n
pn (x) ≅
Vn
De forma a pn(x) convergir para p(x):
lim Vn = 0
n →∞
lim kn = ∞
n →∞
kn
lim = 0
n →∞ n
Exemplos que cumprem estas condições:
Parzen: O volume inicial Vo diminui: Vn = Vo
n
K-nn: Rn cresce até conter kn amostras: k = n
n
26-11-2003
16
Conceitos fundamentais
26-11-2003
17
Janelas de Parzen
Assume-se que região Rn é um cubo com d dimensões e com o
comprimento de cada contorno hn
O número de amostras que se encontram na região Rn pode ser
obtida analiticamente através da função de janela:
⎧⎪1
uj ≤ 1
2
ϕ (u ) = ⎨
⎪⎩0 caso contrario
O número de amostras e a estimativa para a densidade de
probabilidade é dada por:
⎛ x − xi ⎞
kn = ∑ ϕ ⎜
⎟
h
i =1
⎝ n ⎠
n
26-11-2003
1
p n ( x) =
n
1 ⎛ x − xi
ϕ ⎜⎜
V
hn
i =1 n ⎝
n
∑
⎞
⎟
⎟
⎠
18
Janelas de Parzen
A função da janela φ é utilizada para interpolação:
Cada amostra contribui para a estimativa de acordo com a sua
distância a x.
Se hn é muito grande então pn(x) é uma superposição de
funções que variam pouco, sendo uma estimativa pouco
fiável de p(x).
Se hn é muito pequena então pn(x) é uma função de dirac e a
sua estimativa é apenas a soma de pulsos pequenos.
Com um número ilimitado de amostras pn(x) converge para
p(x) para qualquer valor de hn.
Com um número limitado de amostras, o melhor a fazer é
procurar um compromisso.
26-11-2003
19
Janelas de Parzen
Escolha das janelas de parzen
26-11-2003
20
Janelas de Parzen
26-11-2003
21
Janelas de Parzen
26-11-2003
22
Condições de convergência
Se pn(x) é uma variável aleatória que depende dos valores
de {x1,x2, ... , xn} com média e variância dadas por:
A estimativa pn(x) converge para p(x) se:
e as seguintes condições garantem convergência:
26-11-2003
23
Janelas de Parzen
Convergência da média
26-11-2003
24
Janelas de Parzen
Convergência da variância
26-11-2003
25
Janelas de Parzen
p(x) é uma normal:
média zero
variância unitária
Univariada
A função de janela é:
1 −u2 2
ϕ (u ) =
e
2π
pn(x) é uma média das
densidades normais:
1 n 1 ⎛ x − xi ⎞
pn ( x) = ∑ ϕ ⎜
⎟
n i =1 hn ⎝ hn ⎠
26-11-2003
26
Janelas de Parzen
Com duas
densidades
normais.
26-11-2003
27
Janelas de Parzen
26-11-2003
28
Classificação utilizando Janelas de Parzen
26-11-2003
29
Redes PNN (probabilistic neural networks)
As janelas de Parzen podem ser implementadas como uma
rede neuronal estatística.
Considere n padrões com d dimensões, escolhidos
aleatoriamente de c classes.
A rede PNN consiste em:
d unidades de entrada (input layer)
n unidades intermédias (pattern layer) ligadas a
apenas uma e só uma unidade de classe (output layer)
Os pesos entre as unidades entrada e as unidades
intermédias vão ser calculados através de uma fase de
treino.
26-11-2003
30
Redes PNN (probabilistic neural networks)
26-11-2003
31
Redes PNN - Treino
26-11-2003
32
Redes PNN - Classificação
26-11-2003
33
Redes PNN - vantagens
Velocidade da aprendizagem.
Memória reduzida.
A classificação é realizada em paralelo.
Novos padrões de treino podem ser incorporados facilmente.
26-11-2003
34
Estimação dos Kn vizinhos mais próximos
Um dos problemas com as janelas de Parzen é como
determinar uma função de janela óptima.
Outro problema é que as janelas de parzen dependem da
selecção inicial do volume da célula V
Uma solução é escolher o volume da célula de acordo com a
distribuição dos dados.
A estimação dos k vizinhos mais próximos permite resolver
este problema:
A região é agora em função dos dados de treino
Para estimar p(x) em x, a região deve crescer até capturar kn
amostras, onde kn é uma função especificada por n p ( x ) ≅
n
26-11-2003
kn / n
Vn
35
Exemplos
26-11-2003
36
Exemplos
26-11-2003
37
Exemplos
26-11-2003
38
Estimação das probabilidades a Posteriori
Todos os métodos estudados podem ser utilizados para
obter as probabilidades a posteriori dos dados P(ωi|x).
Para uma célula de volume V em redor de x captura-se k
amostras, das quais ki amostras pertencem a ωi
ki / n
pn ( x, ωi ) =
V
Pn (ωi | x) =
pn ( x, ωi )
c
∑ p ( x, ω
j =1
n
j
)
ki
=
k
Para obter o mínimo erro, escolhe-se a classe mais
frequentemente representada na célula.
Para um número suficientemente grande de células, as
probabilidades a posteriori estimadas são fiáveis.
26-11-2003
39
Regra do vizinho mais próximo (NN)
Ambos os métodos, janelas de parzen e Kn vizinhos mais
próximos, podem ser utilizados para calcular as
probabilidades a posteriori utilizando n-amostras de dados
de treino.
Esta probabilidade pode ser utilizada pela regra de Bayes.
Uma abordagem radical é utilizar o método dos vizinhos
mais próximos para classificar directamente os dados de
treino desconhecidos ⇒ regra do vizinho mais próximo.
Enquanto a regra de Bayes (classificação MAP) é óptima
para escolher entre as diferentes classes, a regra do vizinho
mais próximo é sub-óptima.
26-11-2003
40
Regra do vizinho mais próximo
Suponha que temos Dn={x1, ......, xn} amostras de treino
classificadas (rotuladas).
Seja x’ em Dn o ponto mais próximo de x, que necessita de
ser classificado.
A regra do vizinho mais próximo consiste em atribuir ao
elemento x a mesma classificação que o x’.
A regra do vizinho mais próximo cria partições no espaço de
características em células de Voronoi.
26-11-2003
41
Regra do vizinho mais próximo
26-11-2003
42
Limite para o erro
Seja P* o mínimo erro possível (classificador MAP)
Seja P o erro dado pela regra do vizinho mais próximo.
Dado um número ilimitado de dados de treino podemos
mostrar que:
c
P* )
P ≤ P ≤ P (2 −
c −1
*
26-11-2003
*
43
Regra dos k-vizinhos mais próximo (KNN)
As técnicas NN ou k-NN constróem directamente a regra de
decisão sem estimar as densidades condicionadas às
classes.
Motivação: Padrões próximos no espaço de características
possivelmente pertencem à mesma classe.
Extensão do NN: a regra dos k-vizinhos mais próximos
classifica x atribuindo-lhe a classe mais representada nos k
vizinhos mais próximos do conjunto de treino.
Por outras palavras, dado x procuramos as k amostras mais
próximas.
A classe mais frequente é atribuída a x.
k é usualmente ímpar para evitar empates.
26-11-2003
44
Exemplo
26-11-2003
45
Regra dos k-vizinhos mais próximos
A selecção de k é um compromisso:
Se k é muito alto ⇒ alguns destes vizinhos k podem ter
probabilidades diferentes.
Se k é muito baixo ⇒ A estimação pode não ser fiável.
O comportamento óptimo é obtido à medida que k e n se
aproxima de infinito.
26-11-2003
46
Regra do k-vizinhos mais próximo: métricas
26-11-2003
47
Métricas
O classificador dos vizinhos mais próximos baseia-se numa métrica ou
função de distância entre dois padrões.
26-11-2003
48
Propriedades das métricas
Não negativa: d(a,b) ≥ 0
Reflexiva: d(a,b) = 0 se e só se a = b
Simétrica: d(a,b) = d(b,a)
Inequação do triângulo: d(a,b) + d(b,c) ≥ d(a,c)
26-11-2003
49
Métricas
Distância de Minskowski, classe genérica de métricas para padrões
com d dimensões:
1/ k
⎛
k ⎞
Lk (a, b) = ⎜ ∑ ai − bi ⎟
⎝ i =1
⎠
d
Esta distância é parametrizável através do parâmetro k
A distância euclidiana ou a norma L2 é dada por:
L2 = d euclidiana (a, b) =
d
∑(a − b )
i =1
i
2
i
Dá mais ênfase às características com elevada dissimilaridade.
26-11-2003
50
Métricas
A distância de manhattam, city-block ou diferença absoluta é
calculada a partir da norma L1 :
d
L1 = d manhattam (a, b) = ∑ ai − bi
i =1
Reduz tempo de cálculo em relação à distância euclidiana.
Não é possível encurtar esquinas.
26-11-2003
51
Mais métricas
Distância de máxima distância:
d
d max dist (a, b) = max bi − ai
i =1
Apenas considera o par de características mais distantes.
Distância de Mahalanobis:
d mahalanobis (a, b) = ( x − y ) Σ
T
26-11-2003
−1
( x − y)
52
Variantes na decisão K-NN
Escolha da medida de distância no cálculo dos vizinhos
No caso do conjunto de treino ser infinito, o desempenho é
independente da métrica !
Regra de k-NN com distâncias pesadas:
Sejam x1,x2, ... , xk os k vizinhos mais próximos da amostra a
classificar x’
Seja dj = d(x’,xj)
Atribui-se um peso a cada vizinho xj de acordo com:
ωj =
dk − d j
d k − d1
0 ≤ωj ≤1
Somam-se os pesos para os vizinhos pertencentes à mesma
classe, atribuindo x’ à classe com maior peso.
26-11-2003
53
Exemplos de kNN
26-11-2003
54
Exemplos de kNN (k=5)
26-11-2003
55
Desvantagens e vantagens
Propriedades ideais:
Vantagens:
Menos que 20 atributos por instância
Muitos dados de treino
O treino é rápido.
Aprende funções complexas
Desvantagens:
As estimativas são sensíveis ao ruído.
O método KNN produz estimativas com declives acentuados (heavy tails).
A estimativa pode ter descontinuidades e o integral sobre todo o espaço de
amostras diverge.
A classificação é lenta.
As estimativas podem se afastar muito se houver atributos irrelevantes.
26-11-2003
56
A maldição da dimensionalidade
Uma história de horror:
Suponha que os dados são descritos por n atributos, e.g. n=20
Apenas n’ são relevantes e.g. n’ = 2
Mau desempenho ! Os problemas são usualmente tão maus como
este ou mesmo piores (e.g. atributos correlacionados) !
Maldição da dimensionalidade: O algoritmo dos k vizinhos mais
próximos é usualmente enganado quando n é grande, i.e.
dimensão de x é alta.
Como solucionar este problema:
Seleccionar características mais relevantes !
Atribuir pesos às características
Transformações que reduzem a dimensionalidade: PCA, SOM,
etc...
26-11-2003
57
Redução da dimensionalidade
Redução da
dimensionalidade
Triangulos
Delaunay
Voronoi (vizinhos
mais próximos)
26-11-2003
58
Redução da dimensionalidade (PCA)
Noção Intuitiva: Porque motivo devemos usar transformadas que
reduzem a dimensionalidade na aprendizagem supervisionada ?
Principal Components Analysis (PCA)
Pode haver muitos atributos (ou características) com propriedades indesejadas.
Irrelevância: xi têm pouco utilidade se as regiões de decisão g(x) = yi
Dispersão da informação: a “característica de interesse” está espalhado por
muitos xi’s.
Queremos aumentar a “densidade de informação” através da “compressão” de X
Combina-se variáveis redundantes numa única variável, referida como
componente, ou factor
Factor Analysis (FA)
Termo genérico para uma classe de algoritmos que incluem o PCA
Tutorial: http://www.statsoft.com/textbook/stfacan.html
26-11-2003
59
Redução da dimensionalidade (PCA)
Formulação do problema:
Para o conjunto de dados {x1,x2,...,xn} temos:
xi= {x1i,x2i,...,xdi}
Assume-se que a dimensão d dos dados é alta.
Pretende-se classificar x
Problemas com dimensões elevadas:
Se os conjunto de dados for pequeno:
Confiança reduzida na estimativa de parâmetros.
Overfit
Atributos irrelevantes
Muitas dimensões,
poucos pontos
26-11-2003
60
Principal Component Analysis (PCA)
Objectivo: Pretende-se substituir os dados de entrada com
uma dimensão elevada por um conjunto mais reduzido de
características
PCA:
Transformação linear da entrada x de d dimensões para m
dimensões de forma a que m < d e preservar o máximo de
variância para os dados.
Equivalentemente, é uma projecção linear para a qual o erro
quadrático médio é minimizado.
26-11-2003
61
PCA
26-11-2003
62
PCA
26-11-2003
63
PCA
26-11-2003
64
PCA
26-11-2003
65
Método PCA
O PCA é uma técnica de projecção linear:
u =W (x − µ)
onde u são os dados com m dimensões, x são os dados
originais com d dimensões e W é uma transformação linear.
O W guarda os vectores de projecção que devem:
Maximizar a variância dos dados transformados.
ou fornecer distribuições não correlacionadas.
ou minimizar os erro de reconstrução quadrático
O W é constituído por funções (ou vectores)
de base.
26-11-2003
66
Obter as funções de base
Pretende-se encontrar as funções de base que permitem a
melhor aproximação dos dados, preservando o máximo de
informação possível !
Formalização: substituir d dimensões por M de zi
coordenadas que representam x. Pretende-se obter o
subconjunto M das funções de base.
O erro para cada xn é:
26-11-2003
67
Obter as funções de base
Diferencia-se a função de erro em relação a todo o bi e
iguala-se a zero:
Rescrevendo:
O erro é mínimo quando os vectores de base satisfazem:
26-11-2003
68
Funções de base
As melhores funções de base : eliminar d-M vectores com
os valores próprios mais pequenos (ou manter os M
vectores com os maiores vectores próprios)
Os vectores próprios ui são referidos como componentes
principais.
Depois dos vectores próprios ui serem calculados, podemos
transformar os dados de d dimensões em m dimensões.
Para encontrar a verdadeira dimensionalidade dos dados
basta encontrar os valores próprios que contribuem mais (os
pequenos valores próprios são eliminados).
26-11-2003
69
Algoritmo PCA completo
Suponha que têm x1, x2, ... , xM vectores de n × 1
Passo 1: Cálculo da média µi
Passo 2: Subtrair a média aos dados vi = xi – µi
Passo 3: Formar a matriz A = [v1 v2 ... vm] (NxM) e calcular a
matriz de covariância C = AAT
Passo 4: Calcular os valores próprios e vectores próprios de
C.
Passo 5 (Redução da dimensionalidade): manter apenas
os termos correspondentes aos K valores próprios maiores
26-11-2003
70
Exemplo com duas dimensões
GO
26-11-2003
71
Exemplos do PCA
x2
y2
z1
4
2
3
1
z2
2
2
1
1
2
y1
-2
-1
1
-
1
-2
-1
1
2
26-11-2003
x1
2
-1
-2
-1
-2
-2
72
Como escolher a dimensionalidade (m)
Como definir a dimensionalidade dos dados transformados ?
Proporção da variância retida:
m é tipicamente 90% ou 95%. O resto é ruído !
26-11-2003
73
Exemplos de PCA: Faces
26-11-2003
74
Exemplos de PCA: Faces
26-11-2003
75
Problemas do PCA
Problemas:
O PCA é um método linear.
A verdadeira dimensionalidade pode ser sobre estimada.
Os dados podem ser correlacionados de uma forma não linear.
Existem muitas técnicas nesta área:
NPCA (Nonlinear PCA): As projecções são não lineares.
ICA (Independent Component Analysis): descorrelaciona
totalmente as componentes.
26-11-2003
76