ESTATÍSTICA
June 4, 2013
UFOP
June 4, 2013
1 / 87
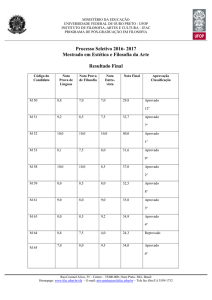
NOME
1
2
Medidas de Tendência Central
Média aritmética
Mediana
Moda
Separatrizes
Medidas de Dispersão
Amplitude Total
Variância e Desvio-padrão
Coeficiente de Variação de Pearson
Erro padrão da média
3
Momentos, assimetria e curtose
Momentos
Assimetria
Curtose
4
Representação Gráfica
UFOP
June 4, 2013
2 / 87
Medidas de Tendência Central
Uma medida de tendência central procura sintetizar as informações da
amostra em um único e informativo valor.
As principais medidas de posição estão apresentadas a seguir.
UFOP
June 4, 2013
3 / 87
Média aritmética
A média é a principal medida de posição, sendo utilizada
principalmente quando os dados apresentam distribuição simétrica ou
aproximadamente simétrica, como acontece com a maioria das
situações práticas.
Simbologia:
µ para a média populacional.
X para a média amostral.
UFOP
June 4, 2013
4 / 87
A média populacional é calculada pela expressão a seguir:
Para dados brutos
X1 + X2 + · · · + Xn
µ=
⇒µ=
N
em que, N é o tamanho da amostra.
UFOP
PN
i
Xi
N
June 4, 2013
5 / 87
O estimador da média populacional é:
Para dados brutos
X1 + X2 + · · · + Xn
X=
⇒X=
n
em que, n é o tamanho da amostra.
Pn
i
Xi
n
Para dados agrupados em Tabela de Frequências
Pk
i
X=
Xi fi
n
em que, k é o número de classes.
UFOP
June 4, 2013
6 / 87
Exemplo
Dados Brutos
Vamos voltar ao exemplo das alturas,expressas em centímetros, de 30
atletas do sexo masculino de uma universidade:
168
176
175
172
173
164
170
170
181
181
186
179
169
183
172
173
170
169
164
168
174
175
166
171
182
169
178
177
180
166
A média aritmética será dada por:
X=
X1 + X2 + · · · + Xn
168 + 172 + · · · + 166
⇒X=
n
30
X = 173, 37
UFOP
June 4, 2013
7 / 87
Exemplo
Para dados agrupados em Tabela de Frequências
A tabela de distribuição de frequências foi apresentada na aula
anterior:
UFOP
June 4, 2013
8 / 87
Assim, a média aritmética será dada por:
P5
Xi fi
X = i=1
n
X=
166, 2 · 6 + 170, 6 · 9 + · · · + 183, 8 · 3
= 173, 53
30
UFOP
June 4, 2013
9 / 87
Hipótese Tabular Básica
Alguém pode questionar a razão da diferença observada no uso dos
dois estimadores.
A resposta é dada pela hipótese tabular básica, a qual considera que
todos os elementos de uma classe são representados pelo seu ponto
médio, fato este, que não é verdadeiro em praticamente todas as
situações.
Desta forma, este último resultado é apenas aproximado. No entanto,
o erro cometido é mínimo e, portanto, pode ser desprezado.
UFOP
June 4, 2013
10 / 87
Propriedades da média
A soma algébrica dos desvios em relação à média aritmética é
nula.
n
X
(Xi − X) = 0
i
A soma dos quadrados dos desvios de um conjunto de dados em
relação a sua média e um valor mínimo.
D=
n
X
(Xi − X)2
i
UFOP
June 4, 2013
11 / 87
Propriedades da média
A média de um conjunto de dados acrescido em cada elemento
por uma constante e igual à média original mais essa constante.
∗
X =X +k
∗
em que X é a média do novo conjunto de dados e k é a
constante.
Multiplicando todos os dados por uma constante a nova média
será igual ao produto da média anterior pela constante.
∗
X =X ·k
A média é influenciada por valores extremos.
UFOP
June 4, 2013
12 / 87
Mediana
A mediana divide as observações ordenadas em partes iguais.
Para sua determinação é necessário o conhecimento da posição
central.
Para dados ordenados, temos basicamente têm-se duas situações
distintas:
Se n for par:
md =
Xn/2 + X(n+2)/2
2
Se n for ímpar:
md =
UFOP
X(n+1)
2
June 4, 2013
13 / 87
Exemplo
Dados ordenados
No caso dos atletas a posição central está entre o 15o e o 16o
elemento.
Portanto, a mediana é a média aritmética destas duas observações.
Logo,
md =
X(15) + X(16)
X(30/2) + X(30+2)/2
⇒ md =
2
2
md = 172, 5cm
UFOP
June 4, 2013
14 / 87
Dados agrupados em Tabela de Frequências
No caso de dados agrupados a mediana pode ser calculada de
acordo com a seguinte expressão:
n/2 − Fant
md = LImd +
· cmd
fmd
em que
fmd é a freqüência da classe mediana;
cmd é a amplitude da classe mediana;
Fant é a frequência acumulada das classes anteriores à classe
mediana;
LImd é o limite inferior da classe mediana.
A classe mediana é a classe que contém a posição n/2 (posição
mediana) da distribuição de freqüência.
UFOP
June 4, 2013
15 / 87
Exemplo
No caso dos atletas temos:
Posição mediana = 30/2 = 15 (contida na 2a classe), Fant = 6;
LImd = 168, 4, fmd = 9 e cmd = 4, 40.
Logo,
15 − 6
· 4, 40
md = 168, 4 +
9
md = 172, 8cm
UFOP
June 4, 2013
16 / 87
Propriedades da mediana
A mediana de um conjunto de dados acrescido em cada elemento
por uma constante e igual à mediana original mais essa
constante.
md∗ = md + k
em que md∗ é a mediana do novo conjunto de dados e k é a
constante.
Multiplicando todos os dados por uma constante a nova mediana
será igual ao produto da mediana anterior pela constante.
md∗ = md · k
UFOP
June 4, 2013
17 / 87
Observação
Muitas vezes existem dúvidas de qual medida utilizar para sintetizar os
dados amostrais.
Como uma regra geral, pode-se definir qual medida é mais
conveniente para uma dada situação com base na análise do
histograma ou do polígono de freqüências.
Se a distribuição dos dados for assimétrica, isto é quando valores
extremos predominam em uma das caudas da distribuição, deve se
preferir a mediana como medida sintetizadora.
Isto se deve ao fato da mediana ser pouco sensível a presença de
valores extremos, sendo considerada mais robusta que a média.
O termo robusto é o termo técnico usado para indicar esta
propriedade da mediana em relação à média aritmética, que quando a
situação de simetria é violada a mediana é uma medida que sofre
menos “interferências” nas suas estimativas.
UFOP
June 4, 2013
18 / 87
Moda
A moda é definida para dados qualitativos ou para quantitativos
discretos como sendo o valor de maior freqüência na amostra.
Para dados quantitativos contínuos a moda é o valor de maior
densidade. Portanto para dados quantitativos contínuos o estimador
da moda é baseado na distribuição de freqüências.
Esse estimador busca encontrar o ponto de máximo do polígono de
freqüências.
Um conjunto pode ter mais de uma moda ou até mesmo não ter moda.
UFOP
June 4, 2013
19 / 87
O estimador da moda para dados quantitativos contínuos é definido a
partir da distribuição de freqüência por meio de um método
geométrico, o qual conduz a seguinte expressão:
mo = LImo +
∆1
· cmo
∆1 + ∆ 2
em que:
LImo : limite inferior da classe modal;
∆1 : diferença entre as freqüências da classe modal e a classe
anterior;
∆2 : diferença entre as freqüências da classe modal e a classe
posterior;
cmo : amplitude da classe modal.
A classe modal é a classe com maior freqüência.
UFOP
June 4, 2013
20 / 87
Propriedades da moda
A moda de um conjunto de dados acrescido em cada elemento
por uma constante e igual à moda original mais essa constante.
mo∗ = mo + k
em que mo∗ é a mediana do novo conjunto de dados e k é a
constante.
Multiplicando todos os dados por uma constante a nova moda
será igual ao produto da moda anterior pela constante.
mo∗ = mo · k
UFOP
June 4, 2013
21 / 87
Relações empíricas entre média, mediana e moda
X = md = mo (distribuição simétrica)
X > md > mo (distribuição assimétrica à direita)
X < md < mo (distribuição assimétrica à esquerda)
UFOP
June 4, 2013
22 / 87
Separatrizes
São as medidas que separam a distribuição de freqüências em partes
iguais.
Vimos que a mediana divide a distribuição em duas partes iguais
quanto ao número de elementos de cada parte.
Agora vamos estudar outras medidas que dividem a distribuição em
partes iguais, que serão as chamadas separatrizes.
Lembrem-se: os dados deves etar ordenados em ordem crescente!!!
UFOP
June 4, 2013
23 / 87
Quartis
Os quartis dividem um conjunto de dados em quatro partes iguais.
Assim:
Q1 : 1o quartil. Deixa 25% dos elementos antes do seu valor
Q2 : 2o quartil. Deixa 50% dos elementos antes do seu valor.
Coincide com a mediana.
Q3 : 3o quartil. Deixa 75% dos elementos antes do seu valor.
UFOP
June 4, 2013
24 / 87
Genericamente, para determinar a ordem ou posição do quartil a ser
calculado, usaremos a seguinte expressão:
EQi = in/4
em que:
i é o número do quartil a ser calculado.
n é o número de observações.
UFOP
June 4, 2013
25 / 87
Para dados não agrupados, vejamos um exemplo simples:
Considere os dados ordenados:
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
Neste caso temos n = 10
Se eu estiver interessado em encontrar o terceiro quartil, temos:
EQ3 = 3 · 10/4 = 7, 5
Se o número resultante for decimal, a regra é arredondar sempre para
cima. Logo, Q3 = 8.
Assim, 75% dos valores estão abaixo de 8 e 25% dos valores estão
acima de 8 na distribuição de dados apresentada no exemplo.
UFOP
June 4, 2013
26 / 87
Para dados agrupados em classes temos:
EQi − Fant
Qi = LI + c
fQi
em que
LI = limite inferior da classe que contém o quartil desejado
c = amplitude do intervalo de classe
EQi = elemento quartílico
Fant = frequência acumulada até a classe anterior à classe que
contém EQi
fQi = frequência absoluta simples da classe quartílica.
UFOP
June 4, 2013
27 / 87
Decis
Os decis dividem um conjunto de dados em dez partes iguais.
De maneira geral, para calcular os decis, recorreremos à expressão
que define a ordem em que o decil se encontra:
EDi = in/10
em que:
i é o número do decil a ser calculado.
n é o número de observações.
UFOP
June 4, 2013
28 / 87
Para dados não agrupados, vejamos o exemplo anterior:
Considere os dados ordenados:
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} em que n = 10
Se eu estiver interessado em encontrar o D6 , temos:
ED6 = 6 · 10/10 = 6
Se o número resultante for inteiro, a regra é fazer a média dele com o
númeor imediatamente posterior a ele na ordem dos dados. Logo,
D6 = 6+7
2 = 6, 5.
Assim, 60% dos valores estão abaixo de 6, 5 e 40% dos valores estão
acima de 6, 5 na distribuição de dados apresentada no exemplo.
UFOP
June 4, 2013
29 / 87
Para dados agrupados em classes temos:
EDi − Fant
Di = LI + c
fDi
em que
LI = limite inferior da classe que contém o decil desejado
c = amplitude do intervalo de classe
Fant = frequência acumulada até a classe anterior à classe que
contém EDi
fDi = frequência absoluta simples da classe que contém EDi .
UFOP
June 4, 2013
30 / 87
Percentis ou Centis
Os percentis dividem um conjunto de dados em cem partes iguais.
O elemento que definirá a ordem do centil será encontrado pelo
emprego da expressão:
ECi = in/100
em que:
i é o número do percentil a ser calculado.
n é o número de observações.
UFOP
June 4, 2013
31 / 87
Para dados não agrupados, consideremos novamente:
Considere os dados ordenados:
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
Se estivermos interessados em encontrar o P75 , temos:
EP75 = 75 · 10/100 = 7, 5
Como o número resultante é decimal, temos, P75 = 8.
Assim, 75% dos valores estão abaixo de 8 e 25% dos valores estão
acima de 8 na distribuição de dados apresentada no exemplo.
Note que P75 coincide com Q3
UFOP
June 4, 2013
32 / 87
Para dados agrupados em classes temos:
ECi − Fant
Ci = LI + c
fCi
em que
LI = limite inferior da classe que contém o percentil desejado
c = amplitude do intervalo de classe
Fant = frequência acumulada até a classe anterior à classe que
contém ECi
fCi = frequência absoluta simples da classe que contém ECi .
UFOP
June 4, 2013
33 / 87
Exemplo
Com base na tabela de distribuição de frequências abaixo encontre:
Primeiro quartil
Septuagésimo quinto centil
Nono decil
UFOP
June 4, 2013
34 / 87
Exemplo
Tabela 1 - consumo médio de eletricidade (kWh) entre 80
consumidores - RJ - 1980
Consumo (Kwh)
5 ` 25
25 ` 45
45 ` 65
65 ` 85
85 ` 105
105 ` 125
125 ` 145
145 ` 165
UFOP
fi
4
6
14
26
14
8
6
2
FA
4
10
24
50
64
72
78
80
June 4, 2013
35 / 87
Resolução:
Encontrar a posição do primeiro quartil:
EQi = in/4 =
1 · 80
= 20
4
O Q1 está localizado na 20a posição, logo encontra-se na 3a classe.
Então,
EQi − Fant
20 − 10
Qi = LI + c
= 45 + 20
= 59, 29
fQi
14
Interpretação: 25% dos usuários consomem até 59,59 kwh.
De maneira análoga, 75% dos usuários consomem mais de 59,59
kwh.
UFOP
June 4, 2013
36 / 87
Resolução:
Encontrar a posição do septuagésimo quinto percentil:
ECi = in/100 =
75 · 80
= 60
100
O C75 está localizado na 60a posição, logo encontra-se na 5a classe.
Então,
ECi − Fant
60 − 50
Ci = LI + c
= 85 + 20
= 99, 29
fCi
14
Interpretação: 75% dos usuários consomem até 99,29 kwh.
De maneira análoga, 25% dos usuários consomem mais de 99,29
kwh.
UFOP
June 4, 2013
37 / 87
Resolução:
Encontrar a posição do nono decil:
EDi = in/10 =
9 · 80
= 72
10
O d9 está localizado na 72a posição, logo encontra-se na 6a classe.
Então,
72 − 64
EDi − Fant
= 105 + 20
Di = LI + c
= 125
fDi
8
Interpretação: : 90% dos usuários consomem até 125 kwh.
De maneira análoga, 10% dos usuários consomem mais de 125 kwh.
UFOP
June 4, 2013
38 / 87
Medidas de dispersão ou de variabilidade
As medidas de posição não informam sobre a variabilidade dos dados
e são insuficientes para sintetizar as informações amostrais.
Para exemplificar este fato, tem-se a seguir três amostras com a
mesma média:
A = {8, 8, 9, 10, 11, 12, 12}
X A = 10
B = {5, 6, 8, 10, 12, 14, 15}
X B = 10
C = {1, 2, 5, 10, 15, 18, 19}
X C = 10
UFOP
June 4, 2013
39 / 87
Pode-se observar que as amostras diferem grandemente em
variabilidade.
Por esta razão torna-se necessário estabelecer medidas que indiquem
o grau de dispersão, ou variabilidade em relação ao valor central.
Desta forma pode-se afirmar que uma amostra deve ser representada
por uma medida de posição e dispersão.
As principais medidas de dispersão que são:
Amplitude total
Variância e Desvio-padrão
Coeficiente de Variação de Pearson
Erro padrão da média
UFOP
June 4, 2013
40 / 87
Amplitude total
A amplitude total é definida como a diferença entre o maior e o menor
valor de uma amostra.
A = X(n) − X(1)
Note que para os conjuntos de dados A, B, C, temos:
AA = 12 − 8 = 4
AB = 15 − 5 = 10
AC = 19 − 1 = 18
UFOP
June 4, 2013
41 / 87
Desvantagens
A amplitude tem as seguintes desvantagens:
só considerar os valores extremos para o seu cálculo, e
principalmente se houver outlier ela será grandemente afetada;
ser influenciada pelo tamanho da amostra, pois à medida que a
amostra aumenta a amplitude tende a ser maior.
UFOP
June 4, 2013
42 / 87
Variância e Desvio-padrão
A variância é uma medida da variabilidade que considera todas as
observações e, devido às propriedades que possui, é a mais utilizada
na maioria das situações na estatística.
A variância relaciona os desvios em torno da média e sua raiz
quadrada é conhecida como desvio-padrão.
Simbologia
σ 2 para a variância populacional e σ para o desvio-padrão
populacional
s2 para a variância amostral e s para o desvio-padrão amostral
UFOP
June 4, 2013
43 / 87
A variância populacional é dada por:
2
σ =
PN
i=1 (Xi
− µ)2
N
em que N é o tamanho da População.
UFOP
June 4, 2013
44 / 87
A variância amostral é dada por:
Pn
(Xi − X)2
2
s = i=1
n−1
em que n é o tamanho da amostra e (n − 1) é denominado graus de
liberdade..
UFOP
June 4, 2013
45 / 87
Numa amostra de tamanho n deveria ser utilizado este valor (n) como
divisor desta soma de quadrados de desvios.
No entanto, devido a motivos associados a propriedades dos
estimadores, o divisor da variância amostral é dado por n-1 em lugar
de n na expressão do estimador da variância.
A unidade da variância é igual ao quadrado da unidade dos dados
originais. O desvio padrão, por sua vez, é expresso na mesma
unidade do conjunto de dados, sendo obtido pela extração da raiz
quadrada da variância.
UFOP
June 4, 2013
46 / 87
Para o cálculo da variância ou desvio padrão amostral a partir dos
dados elaborados é preferível utilizar as seguintes expressões:
" n
#
P
X
( ni=1 Xi )2
1
2
2
Xi −
s =
n−1
n
i=1
e
√
s=
UFOP
s2
June 4, 2013
47 / 87
Para dados agrupados temos:
" k
#
P
X
( ki=1 fi X i )2
1
2
2
fi X i −
s =
n−1
n
i=1
em que k é o número de classes.
Exemplo
Assim, para os conjuntos de dados A, B, C, temos:
s2A = 3
s2B = 15
sA ∼
= 1, 77
s2C = 56, 57
sB ∼
= 3, 87
sC ∼
= 7, 53
UFOP
June 4, 2013
48 / 87
O Desvio-padrão
A variância é expressa pelo quadrado da unidade de medidad da
variável que está sendo estudada.
Assim, e a variável sob análise for medida em metro, então a variância
será expressa em m2 .
Para melhr interpretar a dispersão de uma variável, usaremos o desvio
padrão, que será expresso na unidade de medida original dos dados.
Trata-se da mais importante das medidas de dispersão, pois indica a
dispersão média absoluta dos dados em torno da própria média
aritmética.
UFOP
June 4, 2013
49 / 87
Interpretação do Desvio-padrão
Numa linguagem mais simplista, devemos ter em mente que o
desvio-padrão mede a variação entre valores. Assim:
Se os valores estiverem próximos uns dos outros, então o
desvio-padrão será pequeno, e conseqüentemente os dados
serão homogêneos. Ou seja, haverá uma grande concentração
de dados em torno da média.
Se os valores estiverem distantes uns dos outros, então o
desvio-padrão será grande, e conseqüentemente os dados serão
heterogêneos. Ou seja, os valores não se concentrarão com tanta
intensidade em torno da média.
UFOP
June 4, 2013
50 / 87
Terorema de Tchebycheff
Essa idéia de concentração em torno da média pode ser expressa
mais formalmente pelo seguinte Teorema:
Teorema: Para qualquer conjunto de dados (população ou amostra)e
qualquer constante k > 1, a proporção dos dados que podem estar a
menos de k desvios-padrões da média (para qualquer dos dois lados)
é pelo menos 1 − k12 , isto é:
P (µ − kσ < Xi < µ − kσ) ≥ 1 −
1
k2
P (µ − ks < Xi < µ − ks) ≥ 1 −
1
k2
ou
UFOP
June 4, 2013
51 / 87
Para ilustrar o Teorema de Tchebychev, por exemplo, é possível
afirmar que ao menos 1 − 212 = 34 = 75% dos valores de qualquer
conjunto de dados, devem estar a menos de dois desvios-padrões da
média, de qualquer lado dela.
Para qualquer distribuição com média e desvio-padrão:
O intervalo (X ± 2s) ou (X ± 2σ) contém, no mínimo, 75% de
todas as observações.
O intervalo (X ± 3s) ou (X ± 3σ) contém, no mínimo, 89% de
todas as observações.
UFOP
June 4, 2013
52 / 87
Propriedades
Variância
Somando ou subtraindo uma constante aos dados a variância
não se altera;
Multiplicando todos os dados por uma constante K a nova
variância ficara multiplicada por K 2 .
Desvio-padrão
Somando ou subtraindo uma constante K aos dados o desvio
padrão não se altera;
Multiplicando todos os dados por uma constante K o novo desvio
padrão fica multiplicado por K.
UFOP
June 4, 2013
53 / 87
Coeficiente de Variação de Pearson
A variância e o desvio padrão medem a variabilidade absoluta de uma
amostra.
Portanto, a variabilidade de amostras de grandezas diferentes ou de
médias diferentes não pode ser comparada diretamente pelas
estimativas da variância ou do desvio padrão obtidas.
O desvio padrão ou variância permitem a comparação da variabilidade
entre conjuntos numéricos que possuem a mesma média e a mesma
unidade de medida ou grandeza.
Nos casos em que os conjuntos possuem diferentes unidades ou
possuem médias diferentes, uma medida de dispersão relativa, como
o coeficiente de variação (CV), é indispensável para se comparar à
variabilidade.
UFOP
June 4, 2013
54 / 87
O coeficiente de variação refere-se à variabilidade dos dados
mensurada em relação a sua média, sendo obtido pela expressão
seguinte:
σ
CVp = x100
µ
O estimador do Coediciente de Variação populacional CVp é dado por
CV =
s
x100
X
O coeficiente de variação é a expressão do desvio-padrão como
porcentagem da média do conjunto de dados.
É uma medida adimensional de variabilidade, ou seja, não possui
unidade de medida.
UFOP
June 4, 2013
55 / 87
Algumas regras empíricas para a interpretação do coeficiente
de variação
Se CV < 15% há baixa dispersão → boa representatividade da
média aritmética como medida de posição.
Se 15% ≤ CV < 30% há média dispersão → a representatividade
da média aritmética como medida de posição é apenas regular.
Se CV ≥ 30% há elevada dispersão → a representatividade da
média aritmética como medida de posição é ruim.
UFOP
June 4, 2013
56 / 87
Exemplo
A média e o desvio-padrão da produtividade de duas cultivares de
milho são: X = 4, 0t/ha e sA = 0, 8t/ha para a variedade de
polinização aberta A e X = 8, 0t/ha e sA = 1, 2t/ha para o híbrido
simples B. Qual das cultivares possui maior uniformidade de
produção?
UFOP
June 4, 2013
57 / 87
Se ao inspecionar as estatísticas apresentadas, você respondesse
que variedade de polinização aberta A seia a demaior uniformidade e
que a razão seria o menordesvio padrao apresentado, você teria
cometido um engano.
Embora as unidades não sejam diferentes, as médias das amostras o
são.
Assim, não é correto utilizar uma medida de varabilidade absoluta,
como o desvio-padrão, para compará-las.
O procedimento adequado é calcular o CV para as cultivares e aí sim,
proceder a comparação.
UFOP
June 4, 2013
58 / 87
CVA =
0, 8
x100 = 20%
4, 0
1, 2
x100 = 15%
8
Assim, é fácil observar que o milho híbrido simples (B) é o mais
uniforme, pois possui menor CV do que a variedade de polinização
aberta A.
CVp =
UFOP
June 4, 2013
59 / 87
Erro padrão da média
Para definir o erro padrão da média suponha que amostras aleatórias
de tamanho n são retiradas de uma população e que em cada
amostra seja calculada a média.
Se for computado o desvio padrão da população formada por todas as
estimativas de médias obtidas, o valor encontrado é cohecido como
erro padrão da média.
O erro padrão da média σX é dado pela razão entre o desvio-padrão
populacional e a raiz quadrada de n (número de elementos na
amostra):
σ
σX = √
n
UFOP
June 4, 2013
60 / 87
O estimador amostral desse parâmetro é dado por
s
sX = √
n
Tal estimador é necessário pois:
em geral, nao se conhece o desvio-padrão populacional
na maioria das situações reais não é possível retirar todas as
amostras de uma população
em geral, apenas uma amostra é extraída da população
UFOP
June 4, 2013
61 / 87
O erro padrão da média é uma medida de dispersão das médias
amostrais em torno da média da população.
Quanto menor for seu valor, mais porvável será a chance de obter a
média da amostra nas proximidades da média da população, e quanto
maior for esse valor, menos provável se torna esse evento.
Assim, o erro-padrão da média é estimador da precisão da estimativa
de uma média popualcional.
UFOP
June 4, 2013
62 / 87
Os momentos populacionais centrados na média populacional (µr )
são definidos pela equação
PN
µr =
i=1 (Xi
− µ)r
N
O coeficiente r na expressão é a ordem do momento.
para r = 1 tem-se o momento de primeira ordem, o qual é sempre
igual a zero
para r = 2 tem-se o momento de ordem 2, que é a variância da
população
para r = 3 tem-se o momento de asimetria ordem 3
para r = 4 tem-se o momento de curtose de ordem 4
UFOP
June 4, 2013
63 / 87
Os estimadores amostrais para o momento centrado de ordem r, (mr )
são dados por:
Pn
(Xi − X)r
mr = i=1
n
em que n é o número de elementos na amostra.
UFOP
June 4, 2013
64 / 87
Assimetria
Assimetria é o grau de desvio ou afastamento da simetria de uma
distribuição.
Se a curva de frequência (polígono de frequencia suavizado) de uma
distribuição tem uma "cauda" mais longa à direita da ordenada
máxima do que à esquerda, diz-se que a distribuição é assimétrica à
direita ou que ela tem assimetria positiva.
Se o inverso ocorre, diz-se que a distribuição é assimétrica à
esquerda ou que ela tem assimetria negativa.
UFOP
June 4, 2013
65 / 87
Distribuição simétrica
UFOP
June 4, 2013
66 / 87
Distribuição assimétrica à direita
UFOP
June 4, 2013
67 / 87
Distribuição assimétrica à esquerda
UFOP
June 4, 2013
68 / 87
√
O coeficiente de assimetria populacional β1 é uam forma
padronizada do estimador do momento de assimetria (r = 3).
√
Seu estimador b1 é dado pela razão do momento amostral de ordem
3 pelo de ordem 2, na potência de 32
p
b1 =
m3
3
(m2 ) 2
As
√ populações cuja distribuição é simétrica apresentam valor de
β1 = 0
√
As distribuições assimétricas à direita apresentam β1 > 0
√
As distribuições assimétricas à esquerda apresentam β1 < 0
UFOP
June 4, 2013
69 / 87
Curtose
Curtose é o grau de achatamento de uma distribuição considerado,
usualmente, em relação à distribuição normal.
Para medir a curtose, define-se o estimador (b2 ) do coeficiente de
curtose β2
m4
b2 =
(m2 )2
As distribuições que possuem valores
mesocúrticas
As distribuições que possuem valores
leptocúrticas
As distribuições que possuem valores
platicúrticas
UFOP
√
√
√
β2 = 3 são denominadas
β2 > 3 são denominadas
β2 < 3 são denominadas
June 4, 2013
70 / 87
As distribuiões leptocúrticas são aquelas que possuem uma
concentração de valores próxima ao valor central maior que a da
distribuição normal (mesocúrticas).
Nas distribuições platicúrticas ocorre o contrário, ou seja, uma menor
concentração de valores em torno do valor central da distribuição.
UFOP
June 4, 2013
71 / 87
UFOP
June 4, 2013
72 / 87
Box-plot
Em 1977, John Tukey publicou uma proposta que posteriormente foi
reconhecida como sendo um eficiente método para mostrar cinco
número que sumarizam qualquer conjunto de dados.
O gráfico proposto é chamado de boxplot (também conhecido como
gráfico de caixa) e resume as seguintes medidas estatísticas:
mediana
quantis superior e inferior
os valores mínimos e máximos
UFOP
June 4, 2013
73 / 87
Interpretando o Boxplot
A caixa (box) propriamente contém a metade 50% dos data. O
limite superior da caixa indica o percentil de 75% dos dados e o
limite inferior da caixa indica o percentil de 25%. A distancia entre
esses dois quantis é conhecida como interquartil.
UFOP
June 4, 2013
74 / 87
Interpretando o Boxplot
A linha na caixa indica o valor de mediana dos dados.
Se a linha mediana dentro da caixa não é eqüidistante dos
extremos, diz-se então que os dados são assimétricos.
UFOP
June 4, 2013
75 / 87
Interpretando o Boxplot
Os extremos do gráfico indicam os valores mínimo e máximo, a
menos que valores outliers estejam presentes.
Os pontos fora do gráfico são então outliers ou suspeitos de
serem outliers.
UFOP
June 4, 2013
76 / 87
Vantagens do Boxplot
Mostra graficamente a posição central dos dados (mediana) e a
tendência.
Fornece algum indicativo de simetria ou assimetria dos dados.
Ao contrário de muitas outras formas de representar os dados, o
boxplots mostra os outliers.
Utilizando o boxplot para cada variável categórica lado-a-lado no
mesmo gráfico, pode-se facilmente comparar os dados.
UFOP
June 4, 2013
77 / 87
Observações sobre o Boxplot
Um detalhe do box-plot é que ele tende a enfatizar as caudas da
distribuição, que são os pontos ao extremo nos dados.
Também fornece detalhes da distribuição dos dados.
Mostrar o histograma em conjunto com o box-plot ajuda a entender a
distribuição dos dados, constituindo estes dos gráficos ferramentas
importantes na análise exploratória.
UFOP
June 4, 2013
78 / 87
O Boxplot
UFOP
June 4, 2013
79 / 87
Exemplo
Os dados a seguir referem-se aos dados de amostras de terra de um
Latossolo em determinações analíticas realizadas pelo Laboratório de
Análise de Solos da UFLA.
4.4
4.9
5.5
4.4
5.1
5.5
4.5
5.1
5.7
4.5
5.3
6.2
4.6
5.3
6.4
4.6
5.3
6.4
4.6
5.3
4.7
5.4
4.7
5.5
4.8
5.5
4.8
5.5
4.8
5.5
Construir um boxplot e interpretar os resultados.
UFOP
June 4, 2013
80 / 87
UFOP
June 4, 2013
81 / 87
Interpretação
Avaliando o box plot para os dados de solo, visualizamos que os 25%
menores valores referentes aos solos oscilam menos do que os 25%
maiores valores referentes aos solos.
Além disso percebemos uma assimetria na distribuição desta amostra.
Avaliando os 50% dos dados centrais. Os 25% iniciais oscilam mais
do que os 25% finais.
O que pode ser confirmado com a constução do histograma.
UFOP
June 4, 2013
82 / 87
UFOP
June 4, 2013
83 / 87
Aqui, podemos ver alguns resultados de medidas descritivas (feitas no
Excell)e confirmar as suspeitas de assimetria da distruibuição dos
dados
UFOP
June 4, 2013
84 / 87
No Excel, para calcular os coeficientes de Assimetria e Curtose são
utilizadas espressões diferentes daquelas apresentadas neste
material.
Assim, quando as medidas forem obtidas por meio do excell, há que
se interpretar da seguinte maneira:
UFOP
June 4, 2013
85 / 87
Assimetria
As populações cuja distribuição é simétrica apresentam valor de
coeficiente de assimetria = 0
As distribuições assimétricas à direita apresentam coeficiente de
assimetria > 0
As distribuições assimétricas à esquerda apresentam coeficiente de
assimetria < 0
UFOP
June 4, 2013
86 / 87
Curtose
As distribuições que possuem coeficiente de curtose = 0 são
denominadas mesocúrticas
As distribuições que possuem coeficiente de assimetria < 0
denominadas leptocúrticas
As distribuições que possuem coeficiente de assimetria > 0 são
denominadas platicúrticas
UFOP
June 4, 2013
87 / 87