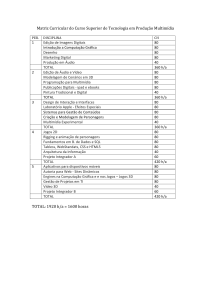
Universidade Federal do Rio de Janeiro
COPPE – Sistemas
Linha de Banco de Dados
Prof. Jano Moreira
Sistemas de Banco de Dados Multimídia
e
Mineração de Dados Multimídia
(Multimedia Mining)
Aluno: Pablo Vieira
Matrícula:101802600
Outubro de 2001
1.
INTRODUÇÃO..................................................................................................................................... 3
2.
MÍDIA E MULTIMÍDIA: CONCEITUAÇÃO ................................................................................. 4
2.1.
APLICAÇÕES MULTIMÍDIA ........................................................................................................... 4
3.
SGBDMM: ASPECTOS E REQUISITOS ........................................................................................ 5
3.1.
MODELAGEM, ESTRUTURAÇÃO E NAVEGAÇÃO EM SGBDMM ....................................... 6
3.2.
TRANSAÇÕES / CONTROLE DE CONCORRÊNCIA .............................................................. 6
4.
ARQUITETURA DE ARMAZENAMENTO ...................................................................................... 9
4.1.
ARQUITETURA EM 3 CAMADAS ............................................................................................... 9
4.2.
TIPOS DE ATRIBUTOS ................................................................................................................ 9
5.
CONSULTAS E RECUPERAÇÃO DE CONTEÚDO EM SGBDMM ......................................... 10
5.1.
INDEXAÇÃO, PREDICADOS E DOMÍNIOS .......................................................................... 11
5.2.
RECUPERAÇÃO POR CONTEÚDO........................................................................................... 11
5.3.
RECUPERAÇÃO DE OBJETOS LONGOS ................................................................................ 11
5.4.
COMPRESSÃO DE DADOS ........................................................................................................ 12
6.
MINERAÇÃO DE DADOS MULTIMÍDIA .................................................................................... 13
6.1.
PROCESSAMENTO DE IMAGENS ........................................................................................... 13
6.2.
REGRAS DE ASSOCIAÇÃO E PREDICADOS ........................................................................ 13
6.3.
DESAFIOS E DIFICULDADES PARA A MINERAÇÃO MULTIMÍDIA ............................. 14
7.
CONCLUSÃO ..................................................................................................................................... 16
REFERÊNCIAS.............................................................................................................................................. 17
1. Introdução
Com o advento das redes de alta velocidade e o aperfeiçoamento dos computadores
pessoais, o suporte a mídias não textuais passou a ser uma necessidade em áreas de
entretenimento, medicina, jornalismo e treinamento, entre outras. A necessidade de armazenar
dados como figuras, vídeos e sons para suportar toda esta demanda de informações nas mais
diversas áreas tornava-se inevitável. Para que isto fosse possível, algumas questões deveriam ser
tratadas como capacidade de armazenamento e tempo de acesso. Assim, como uma alternativa de
abordagem, SGBDs Multimídia (ou simplesmente SGBDMM) com suporte a armazenamento de
objetos do tipo figuras, vídeos e áudio foram desenvolvidos em detrimento da abordagem baseada
em arquivos. Nesta última, armazenamento, estruturação e suporte a acesso simultâneo não
existiam ou eram providos por simples estruturas de arquivos e diretórios de diferentes mídias.
Desta forma, os SGBDs relacionais que antes somente davam suporte a dados textuais, passaram a
oferecer novas opções de armazenamento para dados multimídia, aperfeiçoando de forma
significativa as aplicações existentes nesta área. Para que estas mudanças fossem possíveis, fatores
de impacto sobre a tecnologia de SGBD relacionais e sua arquitetura tiveram de ser incorporados.
Dentro do universo de SGBDMM, muitas áreas de estudo encontram-se ainda em
desenvolvimento como Consultas e Recuperação de Informações e Sincronização e Qualidade de
Serviços em tempo real[13]. Ao mesmo tempo, outros esforços vêm sendo realizados em áreas
mais específicas como Mineração de Dados Multimídia. No presente trabalho, algumas destas áreas
de estudos serão abordadas dentro do escopo de SGBDMM.
O presente trabalho encontra-se dividido da seguinte forma, sendo este texto introdutório
a Seção 1. A Seção 2 procura demonstrar de forma sucinta alguns conceitos relativos a área de
mídia e multimídia, bem como levantando alguns exemplos de aplicações. Na Seção 3 são
apresentados aspectos e requisitos necessários a um SGBDMM. Para a Seção 4, é sugerido um
modelo de arquitetura para SGBDMM. A Seção 5 e 6 desenvolvem breves explanações sobre
consultas e recuperação de informações multimídia e mineração de dados multimídia,
respectivamente. Finalmente, a Seção 7, demonstra a atual realidade dos sistemas multimídia e as
questões que ainda estão em aberto ou em desenvolvimento.
2. Mídia e Multimídia: Conceituação
Como já citado, este tópico tem o intuito de apresentar conceitos relativos à área objeto de
estudo deste documento. Serão apresentados conceitos relativos à mídia e multimídia, assim como
diferentes visões em relação a ambos os termos.
Tanto a mídia como a multimídia podem ser vistas por diferentes enfoques. No caso de
mídia, podemos ter as seguintes conceituações:
• Mídia de armazenamento (fita, disco magnético, disco ótico…)
• Mídia de transmissão (cabo coaxial, fibra ótica…)
• Mídia de intercâmbio ( mídia de armazenamento., mídia de transmissão ou ambos)
• Mídia de E/S (mouse, alto falantes, tela..)
• Mídia de representação (gráficos, ASCII...)
• Mídia de percepção (fala, música, filme)
Ao mesmo tempo, pode-se entender Multimídia por diferentes enfoques:
• Enfoque hardware: Multimídia é a integração entre a TV e Computadores
pessoais
• Enfoque indústria: Multimídia é a combinação de telecomunicações, publicidade,
TV, computação, ótica e tecnologia magnética
• Enfoque interação: Sistemas multimídia são as plataformas computacionais e
ferramentas de software que suportam o uso interativo dos seguintes tipos de
informação: áudio, imagem estática, animação, vídeo.
Um suporte tecnológico específico à área de multimídia faz-se necessário para gerar os
dados multimídia que por sua vez podem ser: Texto ( ASCII + fontes + efeitos especiais – SGML),
Áudio, Imagens estáticas, Vídeo, Objetos gráficos, Mídia Gerada (MIDI - Musical Instrument Digital
Interface). Diversos aparelhos de aplicação específica são utilizados neste momento para criar e
editar informações multimídia que podem ser classificadas em quatro tipos no que se refere à
metodologia de geração:
• Orquestrada: captura e/ou geração da informação a partir da recuperação de
objetos armazenados;
• Ao Vivo: informação gerada a partir de periféricos (câmera, microfone, teclado,…).
Ex: vídeo conferência;
• Discreta (independente de tempo): textos, gráficos, imagem (scanners);
• Contínua: informação disponível em intervalos de tempo (periódicos ou não)
Pode-se então definir um SGBDMM como sendo um Sistema de alta capacidade e
desempenho para suporte a tipos de dados multimídia, bem como a todos os demais tipos
alfanuméricos básicos, manipulando grandes volumes de informações multimídia [3]
2.1. Aplicações MultiMídia
Entre as aplicações voltadas à área de multimídia, e por sua vez, potenciais clientes de
SGBDMM, podemos citar: (a) Servidores VoD (Video on Demand), (b) Sistemas de Gerenciamento
de Documentos Multimídia, (c) Sistemas de Engenharia (provê suporte integrado para os processos
de sistemas de engenharia tais que as dependências entre diferentes documentos e a sua
consistência em ambientes multiusuário), (d) Sistemas de mensagens eletrônicas multimídia (com
suporte a edição e mensagens de voz), (e) Sistemas de Imagens Médicas, (f) Sistemas Militares
para a recuperação de imagens de radar, (g) Sensor remoto/GIS, (h) Sistemas Multimídia de
Instrução, entre outros.
3. SGBDMM: Aspectos e Requisitos
Uma aplicação multimídia envolve atividades como projeto, edição, autoria (na fase de
desenvolvimento da aplicação) e consulta, visões e atualização (na fase de utilização da aplicação).
Como qualquer SGBD, seja ele convencional ou não, é necessário definir aspectos e requisitos
inerentes à natureza do sistema em si e que atendam as atividades de uma aplicação Multimídia.
Para SGBDMM, deve-se evidenciar e comentar alguns requisitos básicos como: suporte a tipos de
dados multimídia, capacidade de manipular objetos multimídia de grandes volumes, alto
desempenho, gerenciamento de custo efetivo de armazenamento, expansibilidade e transparência
de armazenamento, funcionalidades p/ recuperação de informação. No entanto, os três requisitos
mais importantes para que um SGBDMM consiga atender aos seus objetivos são: volume de
armazenamento, continuidade e sincronização.
No primeiro caso, o volume requerido por informações de áudio e vídeo é
consideravelmente maior que as informações textuais encontradas em SGBDs relacionais. Neste
ponto, muitos fatores exercem influência como os dispositivos de armazenamento. Existem hoje,
além dos discos magnéticos, discos ópticos com relativo baixo custo, grande capacidade de
armazenamento e alta velocidade de acesso aleatório aos dados. Além disso, possuem
características de desempenho particulares, as quais devem ser entendidas detalhadamente para
que possibilitem a melhor utilização do seu sistema de recuperação de informações. Outras
intervenções podem ser feitas para otimização do desempenho no gerenciamento de bases de
dados muito extensas. Entre estas podemos citar, armazenamento ternário, implementação de
paralelismo (tanto em memória principal como secundária) e algoritmos de migração.
Devido à quantidade e tamanho dos dados armazenados, dificilmente somente um
dispositivo de um tipo específico é o bastante para atender a demanda. Assim, faz-se necessária a
utilização simultânea de diversos dispositivos de armazenamento em conjunto, também conhecido
como JukeBox. Assim, novos dispositivos de armazenamento podem ser adicionados de acordo com
a demanda. Neste quesito (dispositivos de armazenamento), um SGBDMM deve prover a
interoperabilidade com diferentes dispositivos e mídias de armazenamento, como gravação em
diferentes tipos de discos e CDs, sejam eles regraváveis ou não. Para que isto seja possível, é
necessário estabelecer um conjunto básico de operações mapeando as mesmas para as instruções
particulares a cada dispositivo[5].
As dificuldades continuam presentes no tratamento de objetos multimídia que reúnem
grande volume de informações. Para otimizar o processo de recuperação destes dados e posterior
exibição dos mesmos, alguns investimentos devem ser feitos no sentido de armazenar o objeto em
partes. Este processo deve ser o mais simples possível atentando para o fato de alcançar bons
tempos de resposta no processo de gravação e, ao mesmo tempo, realizá-lo de forma agrupada.
Esta última preocupação servirá para agilizar o processo de leitura dos dados referentes a um
objeto que foi dividido em partes. Esta abordagem, no entanto, não se aplica a todas as classes de
objetos multimídia. Imagens, por exemplo, devem ser exibidas como um todo e não em partes.
Mas no caso de objetos de áudio e vídeo, a informação pode ser armazenada em blocos e ser
recuperada a medida que é requisitada.
No caso da continuidade, é necessário atentar para o fato dos dados, no caso de áudio e
vídeo, estarem armazenados em diversas unidades de informação, denominadas de quadros, que
juntas e encadeadas dão forma à informação final. Isto leva a necessidade de disponibilização
contínua das unidades de informação formando um fluxo seqüencial, não permitindo a perda de
dados. Outro fato é a sincronização necessária no caso de diferentes fluxos de dados que precisam
estar juntos e síncronos para resultar em informação palpável [13]. Como exemplo, num vídeo,
podemos ter um fluxo de dados com a voz, outro com as imagens e outro com a legenda de
tradução. Todos estes fluxos devem estar sincronizados para manter a integridade da informação.
Tanto a sincronização, como a transmissão continuada (transferência em tempo real),
depende de fatores como taxa de compressão dos dados, tamanho de buffer alocado, algoritmos
de escalonamento, distribuição de dados e capacidade de banda alocada para o canal de
comunicação[5]. Algumas otimizações propostas para garantir a entrega dos dados de forma
sincronizada são: utilização de armazenamento secundário e mecanismos de caching no caminho
entre a aplicação e o usuário final.
Entre algumas das premissas das funcionalidades de um SGBDMM está o suporte a
recuperação e consultas específicas. Esta funcionalidade será desenvolvida num tópico em
particular deste documento.
As tarefas gerenciais de um sistema de dados englobam não só armazenamento e exibição,
mas a atualização dos dados em si. Logo, no caso de dados multimídia, deverá também ser
possível que os dados sofram atualizações como redimensionamento de imagens por exemplo.
Outros pontos importantes a serem tratados são indexação e caching de dados desta natureza.
3.1. Modelagem, Estruturação e Navegação em SGBDMM
Um dos prováveis problemas em SGBDMM que gerenciam grande quantidade de dados
será prover mecanismos eficientes de localização de informações. Ao deparar-se de com imensas
bases de dados armazenadas em diversos tipos de dispositivos, são necessárias ferramentas
eficazes para encontrar e recuperar informações relevantes. Boa parte das informações deve ser
registrada no momento de inserção das mesmas com o intuito de permitir que um posterior retorno
de informações seja rápida e eficaz. Alguns métodos para a captura de informações que podem ser
utilizados são: reconhecimento, digitação, agrupamento e definição de relações explícitas.
SGBDs relacionais permitem que usuários encontrem as informações desejadas através de
tipos, atributos e relacionamentos entre os seus elementos. Por outro lado, as técnicas de
recuperação de informação concentram-se principalmente em conteúdos alfanuméricos. No
entanto, técnicas baseadas em similaridade permitem consultas que avaliam se a palavra chave de
um determinado documento é de alguma forma próxima àquelas definidas na consulta do usuário.
É importante notar aqui a principal diferença entre os enfoques da recuperação de dados e da
recuperação de informações. A primeira se baseia em fatos onde um valor deve ter um
relacionamento explicitado pela consulta. No entanto, a segunda abordagem sugere que uma
entidade ou objeto somente seja retornado se o mesmo for relevante, sem necessariamente existir
uma relação explícita entre a entidade e a especificação da consulta.
Neste processo, muita ênfase tem sido dada a abordagens de estruturação baseadas em
hipertextos. Este enfoque de organização do conteúdo da informação permite que a mesma seja
visitada navegando através de ligações em diferentes direções. Esta abordagem, aproxima-se do
modelo Orientado a Objeto, suportando métodos para exibição de informações de sua base [6].
3.2. Transações / Controle de Concorrência
Assim como num SGBD relacional, um SGBDMM deve oferecer suporte a transações
garantindo a estas as propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade).
No que se refere especificamente a transações em SGBDMM, o mesmo deve basicamente oferecer
suporte a transações que possam ser longas, aninhadas e cooperativas, não necessariamente nesta
ordem e ao mesmo tempo.
Em aplicações comerciais, as transações são geralmente curtas, dando maior ênfase a
robustez e desempenho. Ao tratar de objetos longos e complexos, como CAD/CAM entre outros, as
transações em SGBDMM passam a dar maior ênfase a outros aspectos como o número de passos
necessários para execução de toda operação. No entanto, as propriedades ACID têm que ser
contempladas. Todos estes requisitos geram transações longas, durando às vezes semanas para a
sua execução total.
SD1
Esboço
documento
SD2
10
Rascunho
SD3
SD4
20
Rascunho
Revisões
Doc
Final
(integração:
figuras,gráficos,etc)
Fig. 1 Fluxo de uma transação em SGBDMM
Ainda sim, as transações longas possuem alguns problemas e desafios em aberto como:
ocorrência de falha em fases e/ou subfases da transação sendo necessário a
reexecução da transação (roll-back)
Quanto mais complexa a transação, maior o número de conflitos a serem tratados
Trabalho cooperativo, requisito em Sistemas Multimídia, não suportados pelo modelo
de transação tradicional
No caso de transações aninhadas, existe uma hierarquia composta de uma transação
principal sobre diversas transações filhas (ou subtransações). As transações do topo satisfazem às
propriedades ACID com respeito às demais transações superiores. Subtransações sob uma
transação de mais alto nível permanecem isoladas. Outro requisito é de que todas as transações
filhas estejam terminadas, para que uma transação superior possa prosseguir na sua execução.
T
ST2
ST1
Fig. 2 Transações Aninhadas
ST11
ST12
ST21
ST22
No caso mais específico de transações cooperativas para SGBDMM, a idéia é prover
funcionalidades de SGBD junto a um sistema de recuperação por conteúdo e um sistema
hierárquico. Este modelo é dirigido ao usuário que tem o poder de decidir a sincronização. É
importante também salientar como transações contribuem no processo de controle de concorrência
em um SGBDMM, principalmente quando conceitos de granularidade são utilizados. Assim, ao se
bloquear algum objeto multimídia, quão maior seja a sua granularidade, menor será tanto a
concorrência como a sobrecarga do sistema. No entanto, a melhor abordagem seria adotar
bloqueios multigranulares com o intuito de permitir que diferentes transações possam estabelecer
diferentes níveis de bloqueio. Desta forma, é possível minimizar o número de bloqueios em um
SGBDMM. Se na definição de um SGBDMM, for adotada uma abordagem Orientada a Objeto, então
pode-se trabalhar com várias categorias de granularidade, dando maior liberdade a política de
concorrência. As categorias poderiam ser as seguintes:
Organização de Armazenamento Físico: tabelas, páginas, registros
Classes e Instâncias: lock classe1, lock classe n
Objetos Complexos
Hierarquia de Classes: : lock classe1 lock classe 2
4. Arquitetura de Armazenamento
Neste tópico é sugerida uma arquitetura de armazenamento para SGBDMM, abordando
aspectos como memória principal, memória secundária e classes de dispositivos de
armazenamento, como visto em [6] et al.
4.1. Arquitetura em 3 camadas
A arquitetura de armazenamento de um SGBDMM deve ser baseada em um modelo
hierárquico de três camadas [6], provendo eficiência e transparência. Na primeira camada,
localizada na memória principal, ficarão residentes partes ativas do SGBD. Isto devido ao fato de
memórias principais estarem hoje ainda maiores e mais rápidas. No segundo nível, utilizando discos
óticos e magnéticos, ficariam os dados com maiores probabilidades relativas de acesso.
Por fim, na terceira camada, composta por agrupamentos de dispositivos de
armazenamento (também chamados Jukebox), seriam armazenados os dados com menor
probabilidade de acesso. Este nível possui maior capacidade de armazenamento, estando assim
preparado para acomodar longos objetos multimídia. No entanto, deverá provavelmente apresentar
pior desempenho que as outras duas camadas.
Para que esta abordagem seja utilizada, é necessário oferecer suporte ao processo de troca
de informações entre os 3 níveis garantindo um mínimo de eficiência. Por conseguinte, alguns
pontos deste processo deverão ser tratados tais como limitações de espaço, mudança de padrões
de acesso, procedimentos internos de organização, conversão de dados (ponteiros, índices,
agrupamentos). Para controlar os acessos simultâneos aos dados, algoritmos de escalonamento
devem ser empregados durante este processo.
1. Memória Principal
2. Discos óticos e magnéticos
3. Agrupamento de dispositivos de armazenamento
mais lentos (JukeBox)
Fig. 3 Arquitetura em 3 camadas
4.2. Tipos de Atributos
Por outro lado, aspectos não triviais aos SGBDs tradicionais devem ser incorporados,
causando impacto em suas arquiteturas. Um destes aspectos é a implementação de tipos de dados
longos com suporte a informações multimídia e, além disso, que requeiram grande quantidade de
memória para armazenamento. Estes tipos de dados são geralmente implementados em atributos
denominados BLOB. Além destes tipos de atributos com suporte a múltiplas mídias, existem outros
como VARGRAPHIC ou IMAGE.
5. Consultas e Recuperação de Conteúdo em SGBDMM
Neste quesito, não basta simplesmente realizar a consulta. É necessário fazer uso de
interfaces robustas para que não somente consultas e recuperação de dados multimídia sejam
possíveis mas também a navegação entre os resultados seja permitida. Uma relação dos possíveis
tipos de consultas a serem suportados seriam:
• Consultas ao conteúdo dos objetos - ex: “Recupere as imagens contento crianças
loiras” ou “Recupere as músicas com maior concentração de graves”,
• QBE - ex: “Recupere um filme contendo uma determinada cena”,
• Consultas indexadas por tempo - ex: “Mostrar um filme 30min após o seu início” ou
“Reproduza o a faixa musical 25 segundos antes do seu termino”,
• Consultas espaciais - ex: “Mostrar uma imagem onde o presidente Yelstin esteja à
esquerda do pres. Clinton”,
• Consultas de aplicação específica - ex: “Mostrar um vídeo onde aparece a evolução de
uma célula p/ tumor canceroso”. Além destas, é necessário prover suporte a outros
tipos de consultas baseados em cor da imagem, objetos contidos em imagens, objetos
espaciais e em imagens de vídeo (cenas, cortes ou objetos).
Cada um dos tipos de consultas citados necessita de uma metodologia de processamento e
recuperação associada para que a consulta gere os resultados esperados. É válido lembrar que
neste processo serão utilizadas informações como metadados e indexações.
GUI
Consulta
Visual
Especificação,
consulta e refinamento
f
e
e
d
b
a
c
k
Diferentes
domínios
Processamento
Consulta
Geração de
Resultados
Fig. 4 Processo de execução de consulta em SGBDMM
Pesos
Incerteza
5.1. Indexação, Predicados e Domínios
A indexação pode ser implementada de três formas de Extração: (a) Manual - usuário
fornece e indexa as várias características do componente multimídia, (b) automática: listas de
termos indexados são geradas através de algoritmos, (c) híbridas: o sistema determina alguns
valores, usuário os corrige. Além disso, no caso particular de imagens, a indexação pode acontecer
sobre as seguintes características: cor, textura, formas e relacionamentos espaciais.
Para o processamento de consultas, é necessário especificá-las em função de predicados
para pesquisa. Estes por sua vez podem fazer uso de busca por similaridade ou predicados
especiais em domínios característicos dos tipos multimídia como cor, textura ou forma, por
exemplo. Além dos domínios, existem também outros aspectos relacionados a predicados para
informações multimídia como pesos (níveis de relevância de um predicado) e incerteza (termos
imprecisos: similar a, parecido com).
A recuperação de informações multimídia também pode fazer uso da combinação de
diferentes propriedades de um objeto multimídia simultaneamente, passando a ter a função de
chaves neste caso. Como exemplo destas combinações, temos:
combinações exatas: cor=azul, brilho=55, contraste=25, textura=10
combinações parciais: somente 1 subconjunto de valores é especificado (cor, brilho)
por faixa: ex:[1,100]
faixa parcial (especifica apenas faixas p/ um subconjunto de atributos)
5.2. Recuperação por Conteúdo
Como já mencionado, a Incerteza ou Imprecisão no processo de recuperação de dados
multimídia é uma característica importante. Nos SGBDs relacionais, a recuperação de informações é
realizada mediante comparações exatas entre os dados requisitados e aqueles existentes na base
de dados. No entanto, uma das características desejadas em um SGBDMM é a realização de
consultas por conteúdo. Nesta modalidade, o objetivo é retornar imagens que combinem com uma
dada Imagem. Neste caso, as técnicas de comparação de imagens baseiam-se em algoritmos de
melhor combinação[4], contemplando aquelas que tiveram o melhor “casamento”. As comparações
não exigem resultados exatos no processo de combinação entre duas imagens. O uso de
formalismos de Incerteza, neste caso, são essenciais.
Sistemas como o QBIC (Query By Image and video Content )[7], desenvolvido pela IBM,
são exemplos de aplicações que realizam consultas por conteúdo de imagens ou vídeos. O QBIC
serviu de base para criar extensões multimídia em um já conceituado SGBD relacional, DB2 [12].
Algoritmos voltados para o processamento de imagens e identificação das informações
contidas nestas conseguem capturar e mapear suas propriedades. Um exemplo de algoritmo com
este propósito é o FASTMAP [11]. Este algoritmo trabalha com o mapeamento de atributos que
representam um objeto multimídia. Objetos deste tipo possuem um grande número de atributos
complexos. A idéia do algoritmo é mapear estes atributos em pontos num espaço dimensional
gerenciável. Assim, o mesmo consegue indexar, minerar e visualizar conjuntos de dados multimídia
de forma eficiente. O grande objetivo do FASTMAP é prover recuperação e visualização em cima de
grandes coleções de dados multimídia.
5.3. Recuperação de Objetos Longos
Como já citado, a recuperação de objetos muitos longos pode se beneficiar do
armazenamento particionado do objeto. Por diversas vezes, consultas são feitas sem, no entanto,
requisitar a exibição do objeto multimídia. Assim, os objetos somente seriam realmente carregados
quando uma requisição explícita fosse feita. Para prover esta característica, os SGBDMM devem
implementar formas apropriadas de indexação e agrupamento de longos dados multimídia.
A recuperação de longos objetos de dados pode, obviamente, apresentar elevado tempo de
resposta usando técnicas de reconhecimentos de padrões. Otimizações neste processo podem ser
feitas em três frentes:
- explorar o paralelismo em armazenamento secundário
- diferenciar os tipos de objetos multimídia requisitados de forma a utilizar algoritmos
específicos otimizados para cada
- prover aos objetos multimídia métodos descritores dos seus conteúdos.
5.4. Compressão de Dados
Embora a compressão de dados seja uma característica bastante desejada para bases de
dados muito largas, como as bases multimídia, esta propriedade torna mais complexo o processo
de consulta e recuperação de informações. Ao alterar e tentar otimizar o processo de
armazenamento e a estrutura interna dos dados multimídia, uma parte considerável das
propriedades das informações multimídia termina perdida. Este fato causa maior complexidade no
processo de processamento e identificação das características inerentes aos dados multimídia.
6. Mineração de Dados Multimídia
Mineração de Dados Multimídia é uma subárea de estudo da Mineração de Dados que trata
da extração de conhecimento implícito, relacionamentos multimídia, ou outros padrões ainda não
explicitados e armazenados mas presentes em dados multimídia. A mineração de dados multimídia
não se limita somente a imagens e vídeos mas engloba também a mineração de textos. Estes
documentos textuais concentram-se em formatos semi-estruturados localizados na Internet [1].
Com o aumento da utilização de objetos multimídia em SGBDs relacionais estendidos ou
objeto-relacionais, está se tornando cada vez mais importante descobrir relacionamentos entre
dados textuais-relacionais e dados multimídia em grandes bases de dados, procurando dar o
mesmo tratamento a ambas as classes de dados. Percebe-se como muitos dos SGBDs relacionais
estão incorporando informações multimídia, como por exemplo fotos de clientes e usuários. O
aumento da quantidade de dados multimídia é cada vez maior e mais rápido em redes globais
como a Internet, evidenciando a urgência de meios de classificar e entender estes dados [1].
Com a grande explosão do volume de dados multimídia gerados por câmeras de vídeo,
câmeras digitais, câmeras para vigilância, gravadores de áudio (note-se aí a ascensão do formato
Moving Picture Expert Group Layer 3 - MP3 ) [10], satélites, sistemas de sensores remotos, entre
outros, torna-se de fundamental o desenvolvimento de ferramentas com a capacidade da
descoberta de relacionamentos não explícitos em bases de dados multimídia.
Os avanços alcançados na área de SGBDMM, como em [8] e [7] , permitem que grandes
bases de dados multimídia sejam criadas e consultadas de uma maneira eficiente. Estes avanços,
em combinação com a pesquisa desenvolvida em mineração de dados sobre SGBDs relacionais,
criam um ambiente propício para o desenvolvimento de sistemas de mineração de dados
multimídia. Protótipos deste tipo de sistema já podem ser encontrados em [9] et al.
Para que seja possível realizar mineração de dados sobre informações multimídia é
necessário integrar estas tecnologia as de tratamento de dados não convencionais como os dados
multimídia. Assim, é possível que algoritmos de associação e classificação possam ser empregados
para a mineração deste tipo de dado.
6.1. Processamento de Imagens
Para que seja possível implementar mineração de dados multimídia, faz-se necessário
extrair destes dados suas características e propriedades. Ao segmentar e mapear imagens, a
captura das suas propriedades irá facilitar e otimizar o processo de detecção de relacionamentos
não explícitos entre os dados.
No caso do processamento de imagens, é necessário realizar a segmentação da figura em
regiões disjuntas. Uma região consiste de um conjunto de pixels que compartilham uma
determinada propriedade como coloração ou textura [5]. A localização de características através de
áreas (e não de pixels) é um tipo de segmentação um tanto quanto rudimentar que não necessita
ser uma operação completa. Esta pode apresentar melhores resultados pelo fato de não ser tão
refinada quanto a segmentação. Assim, é possível realizar combinações parciais para a descoberta
de associações que por sua vez irão identificar se um objeto está contido, sobreposto ou próximo a
um outro.
6.2. Regras de Associação e Predicados
Regras de associação para a mineração de dados têm sido exaustivamente desenvolvidas e
estudadas. Muitos algoritmos e abordagens foram propostos com o intuito de minerar diversos
tipos de regras de associação em grandes bases de dados [5]. No entanto, boa parte dos esforços
concentra-se em identificar associações em dados alfanuméricos. No caso específico de dados
multimídia, regras de associação específicas são aplicadas fazendo uso de características
topológicas que estabelecem relacionamentos de localização (proximidade vertical ou horizontal,
sobreposição e inclusão). Dados multimídia possuem propriedades peculiares: a ocorrência repetida
de uma determinada característica como cor pode significar que existem outras informações
implícitas que a simples existência daquela característica por si só revelará.
Para que sejam aplicadas as técnicas de Mineração de dados multimídia para estabelecer
associações e/ou agrupamentos, os predicados não são necessariamente baseados em
características visuais ou topológicas da imagem mas também em descrições como tamanho,
duração de vídeo ou palavras relacionadas. Além disso, regras de associação podem ser
identificadas em níveis de baixa resolução, sendo confirmadas progressivamente em níveis de alta
resolução.
Segundo [5], pode-se trabalhar com dois tipos de regras de associação multimídia:
Baseadas em características visuais atômicas, também denominadas regras de
associação multimídia baseadas em conteúdo com descritores recorrentes
Com relacionamentos espaciais, também chamados de regras de associação multimídia
com relacionamentos espaciais recorrentes
No primeiro caso, as características atômicas representam descritores de aspectos como
cor e textura. Regras de associação baseadas nestes aspectos são similares a regras de associação
de multi-níveis, enfatizando a presença de valores em níveis de conceitos pré-informados.
O segundo tipo de regra de associação utiliza relacionamentos topológicos entre posições
de objetos (proximidade horizontal e vertical, sobreposição e inclusão).
6.3. Desafios e dificuldades para a Mineração Multimídia
O primeiro problema com a mineração de dados em SGBDMM é obter acesso a conjuntos
de dados multimídia significativamente grandes. Embora pareça trivial, não é fácil fazer acesso a
dados de diferentes mídias oriundas de aparelhos de uso específico, como scanners médicos
utilizados em hospitais. Estes tipos de dados seriam, com certeza, uma boa oportunidade para
aplicações que investigassem a existência de regras de associação baseadas em cor. Embora sem
um campo específico de estudo, pode-se encontrar na Internet um número extremamente grande
de imagens, vídeos e dados multimídia em geral cujo acesso é, em tese, livre[1].
Outro problema encontrado refere-se a Hierarquia de palavras chaves. Palavras chaves que
descrevem imagens são dados muito importantes e de grande utilidade no caso de coleções de
imagens muito grandes. No entanto, a associação automática de descrição com uma imagem não é
trivial, ao passo que a adição manual desta informação descritiva não possui boa escalabilidade.
Uma abordagem alternativa para a extração destas descrições, é procurar examinar
documentos textuais semi-estruturados como os disponíveis na Internet. Estes documentos são
normalizados e filtrados pelas tags e descrições que os formam, para então serem associados a
imagens. O processo de normalização utiliza análise morfológica enquanto a filtragem usa lista de
palavras de parada e uma base de dados léxica para eliminação de termos não desejados ou
ilícitos. Refinamentos podem ser feitos utilizando-se de heurísticas de linguagens natural.
Entre as várias questões complicadoras do processo de mineração de dados multimídia,
existe também a compressão de dados. Como já citado no tópico 5.3, a análise refinada das
propriedades de dados desta natureza torna-se fica bastante prejudicada. Muitas das características
que antes poderiam implicar da identificação de uma relação podem ter sido suprimidas no
processo de compressão dos dados. No caso de análises em diferentes níveis, o processo contínuo
de análise e refinamento à procura de relações termina se prolongando. Resultados que antes
poderiam ser identificados logo nos primeiros níveis, são postergados para níveis mais avançados.
Outro problema evidenciado está na definição de uma estrutura particular de dados,
denominada cubo, que armazena dados multidimensionais e trata consultas que agregam algumas
destas dimensões em diferentes níveis de abstração. No caso de cubos para dados multimídia, o
número de dimensões é maior que o normal. O grande problema está no comportamento do cubo
de dados, cujo tamanho cresce exponencialmente em relação ao número de dimensões[1].
7. Conclusão
A demanda por uma estrutura com suporte a aplicações multimídia em tempo real, como a
exibição de vídeos sob demanda ou rádios virtuais, já se mostra relativamente grande com
perspectivas de maior crescimento. Com o advento da Internet e sua popularização e uma
arquitetura cliente ainda mais robusta, tal estrutura precisava agora melhorar o seu processo de
armazenamento de informações multimídia. No entanto, pode-se perceber claramente como é
grande o desenvolvimento e amadurecimento na área de sistemas de banco de dados multimídia.
Estes sistemas não irão simplesmente armazenar mas também gerenciar este tipo peculiar de
informação. Muitas das funcionalidades e requisitos necessários ao funcionamento de um sistema
para gerência de dados foram desenvolvidas para este caso em especial, tornando esta tecnologia
utilizável por diversas aplicações na área de multimídia.
No entanto, muitas questões referentes ainda encontram-se em aberto. Uma das principais
é o modelo a ser adotado para desenvolvimento de uma arquitetura para SGBDMM. Dentre os
modelos estudados para o presente trabalho, o modelo Orientado a Objetos mostrou-se o mais
indicado. O modelo OO além de aproximar-se mais facilmente do mundo real, traz consigo
características como classes e encapsulamento, muito importante nos diferentes tipos de objeto
multimídia. No entanto, o que se percebe em muitas das implementações hoje existentes é a
utilização do modelo relacional, estendendo-o com funcionalidades que oferecem suportes a dados
multimídia.
Aspectos como consultas e recuperação de informações multimídia, ainda sim, precisam ser
aprofundadas, principalmente em tipos de dados multimídia como o áudio. Mesmo na consulta e
recuperação sobre conjuntos de imagens, há ainda muitas otimizações a serem implantadas como
consultas por comparação a outras imagens ou a navegação num conjunto resultante de uma
consulta.
Outro ponto a ganhar maturidade é a mineração de dados multimídia. Embora alguns
protótipos acadêmicos de pequeno porte já realizem esta tarefa, suas definições e regras de
associação ainda são pouco exploradas e em reduzido número. Além disso, os atuais estudos desta
área restrita da mineração de dados têm englobado quase que exclusivamente imagens. Uma boa
proposta seria identificar e mapear características de informações de áudio, para a definição de
relacionamentos. Estes relacionamentos baseados em sons iriam contemplar não somente as
combinações entre si mas também a relação com imagens de um vídeo ou descritores
alfanuméricos.
Referências
[1]
ZAIANE, O.; HAN, J.; LI, Z.; HOU, J.; Mining MultiMedia Data, Intelligent DataBase
Systems Research Laboratory, School of Computing Science, Universidade Simon
Fraser University, Canadá, 1998
[2]
RIBEIRO,D., Bases de Dados em Multimídia, UFRGs, Instituto de Informática,
Programa de Pós-Graduação em Computação, Mestrado em Informática, Junho,
2001
[3]
MOURA, A.M.C., Banco de Dados Multimídia ; IME, RJ, 1999
[4]
MOTRO, A., KIM, W., Management of Uncertainty in Database Systems; Modern
Database Systems, ACM Press, 1995
[5]
ZAIANE, O.; HAN, J.; ZHU, H.;
Mining Recurrent Itens in Multimedia with
Progressive Resolution Refinement, Department of Computing Science, University
of Alberta, School of Computing Science, Simon Fraser University, Canadá, 1998
[6]
CHRISTODOULAKIS, S., KOVEOS, L., KIM, W., Multimedia Information Systems:
Issues And Approaches; Modern Database Systems, ACM Press, 1995
[7]
FLICKNER, M.; SAWHNEY, H.; NIBLACK, W., Query By Image and Video Content:
The QBIC System. IEEE Computer, Setembro, 1995
[8]
LI, Z.; ZAÏANE, O.; YAN, B.; C-BIRD: Content-Based Image Retrieval from Image
Repositories Using Chromaticity and Recognition Kernel, Proc. International
Workshop on Storage and retrieval Issues in Image and Multimedia Databases, in
conjunction with the 9th International Conference on Database and Expert Systems
(DEXA'98), Viena, Áustria, Agosto, 1998
[9]
ZAIANE, O.; HAN, J.; LI, Z.; HOU, J.; CHEE, S. H.; CHIANG, J.; Mining MultiMedia
Data, Intelligent DataBase Systems Research Laboratory, School of Computing
Science, Universidade Simon Fraser University, Canadá, 1998
[10]
VALLE, A.; GUIMARAES, C.; CHALUB, F.; MP3 – A Rev. do Som via Internet,
Reichmann & Affonso Editores, Rio de Janeiro, 1999
[11]
CHAN, C.; LEUNG, W.; CHOI, K.; CHU, M.; Image-Video Standards and Database
Techniques, Department of Computer Science, Hong Kong University of Science
and Technology, 1999
[12]
IBM Inc.; http://www-4.ibm.com/software/data/db2, 10/2001
[13]
SEN, S.; GONZALEZ, O.; STANKOVIC, J.; TAKEGAKI, M.; SHEN, C.; Multimedia
Capabilities in Distributed Real-Time Applications, Department of Computer Science,
University of Massachusetts Amherst, 1998