UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
BIP IV: ESPECIFICAÇÃO E SUPORTE NA IDE BIPIDE
Área de Compiladores
por
Paulo Roberto Machado Rech
André Luis Alice Raabe, Dr.
Orientador
Cesar Albenes Zeferino, Dr.
Co-orientador
Itajaí (SC), junho de 2011
UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
BIP IV: ESPECIFICAÇÃO E SUPORTE NA IDE BIPIDE
Área de Compiladores
por
Paulo Roberto Machado Rech
Relatório apresentado à Banca Examinadora do
Trabalho de Conclusão do Curso de Ciência da
Computação para análise e aprovação.
Orientador: André Luís Alice Raabe, Dr.
Itajaí (SC), junho de 2011
SUMÁRIO
LISTA DE ABREVIATURAS.................................................................. iv
LISTA DE FIGURAS ................................................................................. v
LISTA DE TABELAS ............................................................................... vi
RESUMO ................................................................................................... vii
ABSTRACT ..............................................................................................viii
1 INTRODUÇÃO ...................................................................................... 1
1.1 PROBLEMATIZAÇÃO ..................................................................................... 2
1.1.1 Formulação do Problema ................................................................................. 2
1.1.2 Solução Proposta ............................................................................................... 2
1.2 OBJETIVOS ........................................................................................................ 3
1.2.1 Objetivo Geral ................................................................................................... 3
1.2.2 Objetivos Específicos ........................................................................................ 3
1.3 METODOLOGIA................................................................................................ 3
1.4 ESTRUTURA DO TRABALHO ....................................................................... 4
2 FUNDAMENTAÇÃO TEÓRICA ........................................................ 5
2.1 PROCESSADORES BIP .................................................................................... 5
2.1.1 BIP I.................................................................................................................... 5
2.1.2 BIP II .................................................................................................................. 8
2.1.3 BIP III .............................................................................................................. 10
2.1.4 µBIP .................................................................................................................. 11
2.2 SIMULADORES DE ARQUITETURA .......................................................... 14
2.2.1 NeanderWin..................................................................................................... 14
2.2.2 MipsIt ............................................................................................................... 15
2.2.3 ABACUS .......................................................................................................... 16
2.2.4 WinMIPS64 ..................................................................................................... 17
2.2.5 GNUSim8085 ................................................................................................... 18
2.2.6 Comparação entre Simuladores Analisados ................................................ 19
2.3 BIPIDE................................................................................................................ 20
2.3.1 Compilador ...................................................................................................... 20
2.3.2 Simulador ......................................................................................................... 23
3 DESENVOLVIMENTO ...................................................................... 26
3.1 ESPECIFICAÇÃO DO BIP IV ........................................................................ 26
3.1.1 Arquitetura ...................................................................................................... 26
3.1.2 Organização ..................................................................................................... 31
3.2 ALTERAÇÕES NA IDE BIPIDE .................................................................... 33
3.2.1 Operações de E/S............................................................................................. 34
3.2.2 Utilização de Vetores ...................................................................................... 36
ii
3.2.3
3.2.4
3.2.5
3.2.6
3.2.7
Chamada de sub-rotinas................................................................................. 39
Operações de Lógica ....................................................................................... 42
Componentes da Organização dos Processadores na Simulação ............... 45
Módulo de Ajuda............................................................................................. 46
Testes ................................................................................................................ 46
4 CONCLUSÕES .................................................................................... 49
4.1 TRABALHOS FUTUROS ................................................................................ 50
REFERÊNCIAS BIBLIOGRÁFICAS ................................................... 51
A GRAMÀTICA PORTUGOL .............................................................. 54
B CONJUNTO DE INSTRUÇÕES do BIP IV ..................................... 58
B.1
B.2
B.3
B.4
B.5
B.6
B.7
B.8
B.9
CLASSE: CONTROLE .................................................................................... 58
CLASSE: ARMAZENAMENTO .................................................................... 58
CLASSE: CARGA ............................................................................................. 59
CLASSE: ARITMÉTICA ................................................................................. 60
CLASSE: LÓGICA BOOLEANA ................................................................... 62
CLASSE: DESVIO ............................................................................................ 65
CLASSE: DESLOCAMENTO LÓGICO ....................................................... 69
CLASSE: MANIPULAÇÃO DE VETOR ...................................................... 70
CLASSE: SUPORTE A PROCEDIMENTOS ............................................... 71
C CONJUNTO DE INSTRUÇÕES PARA TESTE UNITÁRIO ........ 72
D PROGRAMAS PORTUGOL UTILIZADOS PARA VALIDAÇÃO
DO COMPILADOR ................................................................................. 78
iii
LISTA DE ABREVIATURAS
ACC
ANTLR
AST
BIP
CPU
E/S
IDE
INDR
IR
LIFO
PIC
PC
SFR
SP
TCC
TOS
UFSC
ULA
UNIVALI
WPF
XAML
XML
µBIP
Accumulator
ANother Tool for Language Recognition
Abstract Syntax Tree
Basic Instruction-set Processor
Central Processing Unit
Entrada/Saída
Integrated Development Environment
Index Register
Instruction Register
Last In First Out
Programmable Intelligent Computer
Program Counter
Special Function Register
Stack Pointer
Trabalho de Conclusão de Curso
Top of Stack
Universidade Federal de Santa Catarina
Unidade Lógica Aritmética
Universidade do Vale do Itajaí
Windows Presentation Foundation
eXtensible Application Markup Language
eXtensible Markup Language
microBIP
iv
LISTA DE FIGURAS
Figura 1. Organização do BIP I ............................................................................................................8
Figura 2. Organização do BIP II ........................................................................................................10
Figura 3. Organização do µBIP ..........................................................................................................13
Figura 4. Tela principal do sistema NeanderWin ...............................................................................15
Figura 5. Janelas do MipsIt ................................................................................................................16
Figura 6. Tela principal do ABACUS ................................................................................................ 17
Figura 7. Tela principal do WinMIPS64 ............................................................................................ 18
Figura 8. Tela Principal do GNUSim8085 .........................................................................................19
Figura 9. Exemplo da gramática do Portugol no ANTLR .................................................................22
Figura 10. Exemplos de ações semânticas do Bipide.........................................................................22
Figura 11. Simulador do Bipide .........................................................................................................23
Figura 12. Exemplo de código fonte da linguagem XAML ............................................................... 24
Figura 13. Visão geral da ferramenta Expression Blend 2 .................................................................25
Figura 14. Organização da Memória de E/S ......................................................................................27
Figura 15. Formato de Instruções do BIP IV .....................................................................................27
Figura 16. Classes de Instruções dos processadores BIP ...................................................................30
Figura 17. Organização do módulo de manipulação de vetores ........................................................32
Figura 18. Organização do BIP IV .....................................................................................................33
Figura 19. Fluxo de Implementação do Bipide ..................................................................................34
Figura 20. Alterações na gramática de E/S ........................................................................................35
Figura 21. Geração de código para E/S .............................................................................................. 35
Figura 22. Interface de E/S .................................................................................................................36
Figura 23. Alterações na gramática para suporte a vetores ................................................................ 37
Figura 24. Geração de Código para suporte a vetores ........................................................................38
Figura 25. Ações semânticas para geração de código para atribuições .............................................38
Figura 26. Alterações na Gramática para suporte a sub-rotinas .........................................................40
Figura 27. Geração de código para sub-rotinas ..................................................................................41
Figura 28. Alterações na gramática para suporte a operações lógicas ...............................................43
Figura 29. Geração de código para operações de lógica ....................................................................44
Figura 30. Tratamento de precedência de operadores ........................................................................45
Figura 31. Componentes da Organização do processador no Simulador ...........................................46
Figura 32. Programa utilizado para validar uma instrução de chamada de sub-rotina ......................48
v
LISTA DE TABELAS
Tabela 1. Arquitetura do BIP I .............................................................................................................6
Tabela 2. Conjunto de Instruções do BIP I ..........................................................................................7
Tabela 3. Arquitetura do BIP II ............................................................................................................9
Tabela 4. Instruções de desvio do BIP II ............................................................................................. 9
Tabela 5. Instruções do Lógica do BIP III .........................................................................................11
Tabela 6. Instruções agregadas ao µBIP ............................................................................................ 12
Tabela 7. Características dos sistemas analisados ..............................................................................20
Tabela 8. Lista de Símbolos da Gramática Portugol ..........................................................................21
Tabela 9. Conjunto de Instruções do BIP IV .....................................................................................28
Tabela 10. Resumo da arquitetura do BIP IV ....................................................................................31
Tabela 11. Conjunto de Instruções para teste Unitário ......................................................................72
vi
RESUMO
RECH, Paulo R. M. BIP IV: Especificação e Suporte na IDE Bipide. Itajaí, 2011. 92 f. Trabalho
de Conclusão de Curso (Graduação em Ciência da Computação)–Centro de Ciências Tecnológicas
da Terra e do Mar, Universidade do Vale do Itajaí, Itajaí, 2011.
Para permitir a redução da abstração de conceitos de lógica de programação nos primeiros
semestres de cursos da área de computação, uma família de processadores, denominada BIP - Basic
Instruction-set Processor, e um ambiente de desenvolvimento integrado, chamado Bipide, foram
desenvolvidos. Os processadores da família BIP, suportados pela ferramenta Bipide, têm algumas
limitações, não suportando interações, como entrada e saída, ou subrotinas, não permitindo a sua
utilização em problemas mais complexos ou que necessitem de alguma interação. Neste contexto,
este trabalho apresenta o desenvolvimento de um novo processador, integrante da família BIP,
denominado BIP IV, que estende as características dos processadores BIP, agregando novas
funcionalidades, aumentando a abrangência de sua utilização. Também foram implementadas
modificações na IDE Bipide a fim de suportar o uso do processador BIP IV. O resultado alcançado
permite maior interação ao aluno com a ferramenta, além do aprendizado de novas funcionalidades
e seu uso na resolução de problemas mais complexos. A ferramenta ainda permite ao aluno
compreender a representação das novas funcionalidades em linguagem de baixo nível e sua
representação no hardware, através do simulador presente na IDE. Este trabalho apresenta uma
revisão de conceitos associados à Arquitetura e Organização dos processadores BIP e conceitos
aplicados no desenvolvimento da IDE Bipide, assim como descreve o projeto do processador BIP
IV e seu suporte na ferramenta Bipide.
Palavras-chave: Simuladores de Arquitetura de Computadores. Compiladores. Arquitetura e
Organização de Computadores.
vii
ABSTRACT
To allow a reduction in the abstraction of concepts of programming logic in the first semester of
courses in computing, a family of processors, called BIP - Basic Instruction-set Processor, and an
integrated development environment, called Bipide were developed. The BIP processor family,
supported by the tool Bipide, has some limitations, not supporting interactions, such as input and
output, or subroutines, not allowing their use in complex problems or those with user interaction. In
this context, this research presents the development of a new BIP processor family member called
BIP IV, which extends its features increasing the scope of use. Modifications were also
implemented in the IDE Bipide to support use of BIP IV processor. The result obtained allows the
students more interaction with the tool, as well as new features learning and its use in solving
complex problems. The tool also allows the student to understand the representation of the new
features in low-level assembly language and its representation in the hardware through Bipide
architecture simulator. This research also presents a review of concepts related to Architecture and
Organization of processors BIP and concepts applied in the development of Bipide IDE, and
describes the design of the processor BIP IV, his support in Bipide tool.
Keywords: Simulation of Computer Architecture. Compilers. Computer Organization and
Architecture.
viii
1 INTRODUÇÃO
Com o objetivo de auxiliar o aprendizado do aluno nos semestres iniciais dos cursos de
Ciência da Computação, em Zeferino et al (2010) foi proposta uma abordagem interdisciplinar
envolvendo conceitos de arquitetura de computadores e de seus desdobramentos nas disciplinas
ligadas a aprendizagem de programação. Este enfoque parte do pressuposto que, ao reduzir a
abstração envolvida na aprendizagem dos conceitos iniciais, auxilia a reduzir os problemas de
aprendizagem, que segundo diversos autores como McCracken et al (2001) e Lister et al (2004), são
freqüentes nos semestres iniciais.
Para isso foi proposta uma família de processadores denominada BIP (Basic Instruction-set
Processor), e em conjunto com ela uma ferramenta chamada Bipide (VIEIRA, 2009).
A Família BIP foi concebida em níveis de complexidade de arquitetura e organização
crescentes, sendo que o processador BIP I (MORANDI et al., 2006) possui oito instruções que
possibilitam o controle, armazenamento em memória, carga no acumulador e instruções aritméticas.
No BIP II (MORANDI; RAABE; ZEFERINO, 2006), foram acrescidas instruções para suporte a
laços de repetição e desvios. No BIP III foi acrescido suporte para instruções lógicas e de operação
binária. Já o µBIP (PEREIRA; ZEFERINO, 2008) foi desenvolvido com o intuito de ensino de
Sistemas Embarcados agregando periféricos e funcionalidades típicas de microcontroladores.
A ferramenta Bipide, por sua vez, consiste em um ambiente de desenvolvimento integrado
(IDE - Integrated Development Environment) que implementa instruções dos processadores BIP I e
BIP II. Nela é possível a criação de pequenos algoritmos em portugol (pseudolinguagem utilizada
para facilitar o ensino de algoritmos) e sua execução passo a passo. Também é ilustrado o código
correspondente em linguagem assembly e o estado dos componentes da organização do
processador. A interface do Bipide ainda contempla animações que ilustram o funcionamento dos
componentes da organização do processador destacando o código em portugol sendo executado e
também o código assembly correspondente (VIEIRA; RAABE; ZEFERINO, 2010).
Esta abordagem didática tem sido utilizada ao longo de três semestres letivos e tem trazido
resultados positivos conforme mencionado em Vieira, Raabe e Zeferino (2010).
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
Tanto no BIP I quanto no BIP II e III não são possíveis interações como entrada e saída e
chamadas de procedimentos permitindo somente algoritmos mais simples.
Este aspecto tem gerado limitações quanto ao uso da abordagem para o ensino de conceitos
mais abrangentes da aprendizagem de programação, e em especial, desfavorecem a criação de
programas em que o aluno pode interagir com seu algoritmo. Analisando a bibliografia de apoio a
disciplina de algoritmos, percebe-se que bons livros (MANZANO et al, 2005 e ZIVIANI, 2007)
adotam problemas que necessitam interações como entrada e saída de dados. Baseado nisso,
conclui-se que a interação, via entrada e saída de dados, é um componente importante para auxiliar
a despertar mais interesse por parte do aluno.
Além disso, a implementação de entrada e saída, chamadas de procedimentos permitem que
sejam trabalhados problemas que demandem soluções com algoritmos mais complexos e
modulares.
1.1.2 Solução Proposta
Neste contexto, a solução proposta neste trabalho consiste na criação de um novo integrante
da família BIP, o BIP IV, que incorpora instruções de entrada e saída e chamadas de procedimentos.
Por fim, o projeto e desenvolvimento do suporte deste novo processador na ferramenta Bipide.
Para atender as novas funcionalidades do BIP IV, várias alterações no ambiente Bipide
foram necessárias, inclusive na estrutura da pseudolinguagem portugol.
Entre os benefícios da implementação em questão estão: (i) maior interação do aluno com a
ferramenta; (ii) aprendizagem de novas funcionalidades e seu funcionamento no processador; (iii)
extensão do uso da ferramenta para disciplinas de semestres posteriores aos já aplicados, uma vez
que permitirá algoritmos mais complexos; (iv) continuidade da pesquisa relacionada à abordagem
didática interdisciplinar.
2
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Conceber e especificar a arquitetura e organização do processador BIP IV, visando dar
suporte a instruções de entrada e saída e chamadas de sub-rotinas
1.2.2 Objetivos Específicos
Caracterizar a arquitetura e o conjunto de instruções dos processadores da família BIP;
Analisar simuladores de outros processadores com enfoque na interface de entrada e
saída;
Implementar as alterações necessárias na ferramenta Bipide para permitir suporte ao Bip
III e BIP IV; e
Avaliar as alterações realizadas na ferramenta Bipide.
1.3 Metodologia
A metodologia adotada no desenvolvimento deste trabalho foi dividida em quatro partes:
Estudo: Nesta etapa foram realizados estudos a fim de adquirir conhecimento
sobre os processadores BIP, simuladores de arquiteturas que permitam
entrada e saída e dados sobre a implementação da ferramenta Bipide. Os
recursos utilizados nesta etapa foram livros, artigos e documentações;
Projeto: Nesta etapa foi realizada a especificação e o projeto da arquitetura e
organização do processador BIP IV bem como a análise e projeto das
alterações necessárias na ferramenta Bipide;
Revisão: Foi realizada uma revisão do projeto inicial, levando em
consideração as questões levantadas durante a apresentação do TCC I;
Desenvolvimento: Nesta etapa foram implementadas as alterações na IDE
Bipide baseada no projeto realizado;
Avaliação: Nestas etapas foram realizados testes a fim de validar a
ferramenta; e
3
Documentação: Consiste na redação deste trabalho e de um artigo científico.
1.4 Estrutura do trabalho
Este documento está dividido em quatro capítulos. O Capítulo 1, Introdução, apresentou
uma visão geral sobre o tema abordado no trabalho e seus objetivos. O Capítulo 2, Fundamentação
Teórica, apresenta a revisão bibliográfica dos temas envolvidos no trabalho. O Capítulo 3,
Desenvolvimento, apresenta o projeto e a implementação em questão. O último Capítulo apresenta
as conclusões sobre o Trabalho. O documento também apresenta quatro apêndices que contemplam
o conteúdo deste trabalho.
4
2 FUNDAMENTAÇÃO TEÓRICA
Neste capítulo é apresentada a revisão bibliográfica sobre os temas envolvidos no projeto. A
seção 2.1 apresenta um levantamento das características dos processadores BIP. A seção 2.2
apresenta uma breve descrição sobre os simuladores de arquitetura estudados. Na seção 2.3 são
apresentadas as características atuais do compilador e do simulador da ferramenta Bipide.
2.1 Processadores BIP
Os processadores BIP foram desenvolvidos por pesquisadores do Laboratório de Sistemas
Embarcados e Distribuídos da UNIVALI – Universidade do Vale do Itajaí – com o intuito de
estabelecer uma relação entre a programação de alto nível e sua representação em hardware bem
como auxiliar o aprendizado de Arquitetura e Organização de Computadores nas fases iniciais dos
cursos de Graduação em Computação (VIEIRA; RAABE; ZEFERINO, 2010).
2.1.1 BIP I
O BIP I tem como foco dar suporte ao entendimento a conceitos básicos de programação,
níveis de linguagem em representação de dados e instruções em linguagem de máquina
(MORANDI; RAABE; ZEFERINO, 2006; PEREIRA, 2008).
2.1.1.1 Arquitetura
A arquitetura do processador BIP I é baseada na arquitetura do processador PIC
(Programmable Intelligent Computer). Este processador é orientado a acumulador e não possui
banco de registradores.
Conforme a Tabela 1, o formato de instruções do processador BIP I é composto por dois
campos: 5 bits para o código de operação; e 11 bits para o operando. (MORANDI, RAABE,
ZEFERINO, 2006).
Tabela 1. Arquitetura do BIP I
Tamanho da palavra de
dados
Tipo de dados
Tamanho da palavra de
instruções
Formato de instrução
16 bits
Registradores
ACC: acumulador
IR: registrador de Instrução
PC: contador de programa
Transferência (acesso a memória): STO, LD e LDI
Aritmética: ADD, ADDI, SUB e SUBI
Controle HLT.
Classes de instrução
Inteiro de 16 bits com sinal: -32768 a +32767
16 bits
Fonte: Adaptado de Morandi et al. (2006).
A arquitetura do BIP I possui três registradores: PC (Program counter – Contador de
Programa), IR (Instruction Register – Registrador de Instrução), e ACC (Accumulator Acumulador). O registrador PC aponta para o endereço da próxima instrução. O registrador IR
aponta para o endereço da instrução em execução. O registrador ACC é utilizado para
armazenamento de dados durante uma operação.
O conjunto de instruções do BIP I, apresentado na Tabela 2, é composto por uma instrução
de controle, três instruções de transferência e quatro instruções de aritmética. Exceto na instrução
halt (HLT), o PC é incrementado em uma unidade no final do ciclo de execução da instrução.
Abaixo uma breve descrição de cada uma das instruções:
HLT: Desabilita a atualização do PC. Nenhum registrador é afetado e nenhuma operação
é realizada.
STO: Armazena o conteúdo do registrador ACC na posição de memória indicada por
operand.
LD: Carrega para o registrador ACC o conteúdo da posição de memória indicada por
operand.
LDI: Carrega uma constante indicada por operand para o registrador ACC.
6
ADD: Soma o conteúdo do registrador ACC com o conteúdo da posição de memória
indicado por operand. O resultado da adição é armazenado no registrador ACC.
ADDI: Soma o conteúdo do registrador ACC a uma constante indicada por operand e
o armazena no ACC.
SUB: Subtrai o conteúdo do registrador ACC pelo conteúdo da posição de memória
indicado por operand. O resultado da subtração é armazenado no registrador ACC.
SUBI: Subtrai o conteúdo do registrador ACC pela constante indicada por operand. O
resultado é armazenado no ACC.
Tabela 2. Conjunto de Instruções do BIP I
Código da
Operação
00000
00001
00010
00011
00100
00101
00110
00111
01000-11111
Instrução
Operação
HLT
Paralisa a execução
STO operand
Memory[operand]ACC
LD operand
ACCMemory[operand]
LDI operand
ACCoperand
ADD operand
ACCACC+Memory[operand]
ADDI operand
ACCACC+operand
SUB operand
ACCACC-Memory[operand]
SUBI operand
ACCACC-operand
Reservado para futuras gerações.
Classe
Controle
Transferência
Transferência
Transferência
Aritmética
Aritmética
Aritmética
Aritmética
Fonte: Adaptado de Morandi et al. (2006).
2.1.1.2 Organização
A organização do processador utiliza a estrutura Harvard, com memórias separadas para
dados e instruções (MORANDI, RAABE, ZEFERINO, 2006). O processador é dividido em dois
blocos, conforme a Figura 1, sendo o Controle, responsável por gerar sinais para o caminho de
dados e atualização do PC, e Caminho de dados, responsável por executar a instrução.
7
Figura 1. Organização do BIP I
Fonte: Adaptado de Zeferino (2007).
2.1.2 BIP II
2.1.2.1 Arquitetura
O BIP II é extensão do BIP I e uma das mudanças realizadas foi a inclusão de instruções de
desvio, tornando possível a implementação de desvios condicionais, incondicionais e laços
repetição (MORANDI; RAABE; ZEFERINO, 2006).
Para possibilitar o suporte a desvios um novo registrador chamado de STATUS foi agregado
à arquitetura original do BIP I, conforme a Tabela 3. As operações aritméticas são responsáveis por
atualizar o estado do registrador STATUS que por sua vez possui dois flags: (i) Z, que indica se o
estado da última operação na ULA (Unidade Lógica Aritmética) foi igual a zero ou não; e (ii) N,
que indica se o resultado da ULA foi um número negativo ou não.
8
Tabela 3. Arquitetura do BIP II
Tamanho da palavra de
dados
Tipo de dados
Tamanho da palavra de
instruções
Formato de instrução
16 bits
Registradores
ACC: acumulador
IR: registrador de Instrução
PC: contador de programa
STATUS: registrador de estado com dois flags (Z e N)
Transferência (acesso a memória): STO, LD e LDI
Aritmética: ADD, ADDI, SUB e SUBI
Controle HLT.
Desvio: BEQ, BNE, BGT, BGE, BLT, BLE e JMP
Inteiro de 16 bits com sinal: -32768 a +32767
16 bits
Classes de instrução
Fonte: Adaptado de Morandi, Raabe e Zeferino (2006).
As instruções HLT, STO, LD, LDI, ADD, ADDI, SUB e SUBI, presentes no BIP II,
possuem as mesmas características do BIP I. As instruções de desvio agregadas ao BIP II, conforme
a Erro! Fonte de referência não encontrada., são BEQ, BNE, BGT, BGE, BLT, BLE e JMP,
onde JMP é uma instrução de desvio incondicional e as outras são de desvio condicional.
Tabela 4. Instruções de desvio do BIP II
Opcode
Instrução
01000
BEQ
operand
01001
BNE
operand
01010
BGT
operand
01011
BGE
operand
01100
BLT
operand
01101
BLE
operand
01110
01111-11111
JMP
operand
Operação e atualização do PC
Se (STATUS.Z=1) então PC endereço
Senão
PC PC + 1
Se (STATUS.Z=0) então PC endereço
Senão PC PC + 1
Se (STATUS.Z=0) e (STATUS.N=0) então
PC endereço
Senão PC PC + 1
Se (STATUS.N=0) então
PC endereço
Senão PC PC + 1
Se (STATUS.N=1) então
PC endereço
Senão PC PC + 1
Se (STATUS.Z=1) ou (STATUS.N=1) então
PC endereço
Senão
PC PC + 1
PC endereço
Reservado para as futuras gerações
Fonte: Adaptado de Zeferino (2007).
9
2.1.2.2 Organização
A organização do BIP II, ilustrada pela Figura 2, compreende uma extensão BIP I incluindo
o registrador STATUS e modificações necessárias para a implementação de desvios no circuito de
atualização do PC. A fonte da atualização do PC, neste caso, é definida em função do tipo de desvio
e do estado do registrador STATUS.
Figura 2. Organização do BIP II
Fonte: Adaptado de Pereira (2008).
2.1.3 BIP III
O BIP III estende o BIP II acrescentando instruções de lógica com foco no suporte à
operação de lógica bit a bit. Sua arquitetura e organização não foram formalizadas em trabalhos
anteriores relacionados à família BIP, pois não acrescentou grandes mudanças em relação ao BIP II.
Dentre as mudanças na organização destaca-se a inclusão de uma unidade lógica e mudanças
no decodificador para suportar as novas instruções. Conforme Pereira (2008), a junção da unidade
aritmética com a unidade lógica passa a se chamar Unidade Funcional assim como no µBIP que
será detalhado posteriormente.
10
Quanto à arquitetura somente houve a adição da classe de instruções de lógica booleana e
deslocamento lógico conforme a Tabela 5.
Tabela 5. Instruções do Lógica do BIP III
Opcode
01111
10000
10001
10010
10011
10100
10101
10110
10111
Instrução
NOT
AND operand
ANDI operand
OR
operand
ORI operand
XOR operand
XORI operand
SLL operand
SRL operand
Flags
Z,N
Z,N
Z,N
Z,N
Z,N
Z,N
Z,N
Z,N
Z,N
Operação e atualização do PC
PC PC + 1
ACC NOT(ACC)
ACC ACC AND Memory[operand] PC PC + 1
ACC ACC AND operand
PC PC + 1
ACC ACC OR
Memory[operand] PC PC + 1
ACC ACC OR
operand
PC PC + 1
ACC ACC XOR Memory[operand] PC PC + 1
ACC ACC XOR operand
PC PC + 1
ACC ACC <<
operand
PC PC + 1
ACC ACC >>
operand
PC PC + 1
Fonte: Adaptado de Pereira (2008).
2.1.4 µBIP
O µBIP é um microcontrolador da família BIP com foco no ensino de sistemas embarcados
em cursos de graduação e pós-graduação (PEREIRA, 2008).
2.1.4.1 Arquitetura
O µBIP estende a arquitetura do BIP agregando um conjunto de instruções típicas de
microcontroladores (PEREIRA, 2008). Além das instruções herdadas da família BIP, o µBIP
contempla instruções de manipulação de vetores, interrupções e chamadas de subrotinas. O µBIP
possui ainda o modo de endereçamento indireto, utilizado para manipulação de vetores.
O µBIP, assim como os demais processadores da família BIP, possui os seguintes
registradores: (i) PC, que contém o endereço da instrução corrente (a partir do BIP II passou a
exercer a função do registrador IR); (ii) ACC, que contém o resultado das operações realizadas; e
(iii) STATUS, que contem informações sobre o resultado da operação na ULA;
Para dar suporte à chamada de procedimentos e manipulação de vetores, os seguintes
registradores foram incluídos: (i) INDR (Index Register), que contém o índice do vetor; e (ii) SP
(Stack Pointer), que aponta para o topo da pilha (Top of Stack, ou ToS) de suporte a chamada de
procedimentos.
11
Quanto ocorre uma chamada de procedimento ou interrupção, o endereço da próxima
instrução é armazenado no topo de uma estrutura de pilha.
Além dos flags Z e N, já presentes no registrador STATUS no BIP II, o flag C está presente
no µBIP com a finalidade de indicar se ocorreu um carry-out ou borrow (excede os 16 bits, no caso
dos processadores BIP) em instruções aritméticas (PEREIRA, 2008).
A Tabela 6 ilustra as instruções acrescidas ao µBIP onde STOV e LDV dão suporte à
manipulação de vetores, CALL e RETURN à chamada de subrotinas e RETINT a suporte a
interrupções.
Tabela 6. Instruções agregadas ao µBIP
Opcode
11000
11001
11010
11011
Instrução
STOV operand
LDV operand
RETURN
RETINT
11100
CALL operand
Operação e atualização do PC
Memory[operand + INDR] ACC
PC PC + 1
ACC Memory[operand + INDR]
PC PC + 1
PC ToS
PC ToS
PC operand
ToS PC+1
Fonte: Adaptado de Pereira (2008).
Nas instruções de manipulação de vetores (STOV e LDV) deve-se armazenar o
deslocamento no registrador INDR utilizando o comando “STO $indr”. O cálculo do endereço
efetivo será a soma do conteúdo do registrador INDR com operand.
A instrução CALL realiza uma chamada de procedimento para o endereço indicado por
operand. O endereço seguinte a instrução CALL é armazenado no topo da pilha de suporte a
procedimentos. O retorno do procedimento é feito através da instrução RETURN.
A instrução RETINT é utilizada para retornar de uma interrupção. Ao utilizar esta instrução
a execução é desviada para o endereço anterior à interrupção.
2.1.4.2 Organização
A organização do µBIP, conforme a Figura 3, além dos atributos já citados nos outros
processadores BIP, acrescenta: (i) uma pilha para controle do suporte a procedimentos; (ii) uma
unidade de manipulação de vetores; (iii) uma interface de acesso aos registradores de propósito
12
especiais (SFR – Special Function Register) utilizados nos periféricos integrados; e (iv) um
controlador de interrupções.
CPU
Unidade de Controle
Caminho de Dados
Extensão de
Sinal
Pilha
Stack in
Stack out
Op
WrEn
SFRs
0
1
2
3
4
SelA
0x001
Decodificador
0x001
Intr
1
3
2
1
WrACC
Stack_wr
Stack_op
WrPC
WrACC
SelA
SelB
SelC
is_vector
WrData
FU_Op
SourcePC
+
0
0
SelB
data_in
wren
data_out
operando1
operando2
SelC
Unidade Funcional
0
N
1
WrData
Z N C
Z
C
FU_Op
ena
addr_in
ACC
0
Opcode
ena
1
Controle de
Interrupções
Operação
ena
PC
is_vector
is_vector
Manipulação
de Vetores
STATUS
N
Z
C
data_in
addr_in
Indr
addr_out
WrData
Addr
Out_Data
Wr
Memória de Instruções
Addr
In_Data
Out_Data
Memória de Dados
Figura 3. Organização do µBIP
Fonte: Pereira (2008).
A pilha tem a finalidade de guardar o endereço seguinte à instrução call. Seu hardware é
simples, composto de uma estrutura tipo LIFO (Last In First Out), um somador/subtrator e um
registrador (SP - Stack Pointer) que indica o topo da pilha (PEREIRA, 2008).
Para a manipulação de vetores o µBIP utiliza um hardware composto de um registrador
(INDR) e um somador. O acesso e a gravação ocorrem utilizando o valor do operando somado do
valor do registrador SP para definir a posição de memória (PEREIRA, 2008).
Para E/S (Entrada/Saída) o µBIP possui 16 pinos que podem ser configurados
individualmente como entrada ou saída onde o registrador portX_dir determina a direção e o
registrador portX_data é o registrado utilizado para armazenar o dado lido ou a escrever. A direção
é definida pelo registrador portX_dir atribuindo 1 para entrada e 0 para saída para cada um dos 16
pinos. Lembrando que „X‟ representa o identificador da porta (PEREIRA, 2008).
13
O µBIP possui um temporizador configurável onde cada estouro do temporizador gera uma
interrupção. As interrupções, além de serem ativadas pelo temporizador, podem ser por detecção de
borda do pino 0 da porta port0. Ao ocorrer uma interrupção a execução do programa desvia para o
endereço 0x001 onde as rotinas de interrupção serão tratadas (PEREIRA, 2008).
2.2 Simuladores de Arquitetura
Esta etapa visa analisar características de simuladores de arquitetura de processadores que
permitam E/S. Utilizaram-se como referência inicial os simuladores de arquitetura analisados em
Vieira (2009), porém alguns destes foram retirados da análise por não possuírem versões funcionais
acessíveis como o Simularq ou por não contemplarem entrada e saída como o 4AC, VLIW-DLX e
R10k e outros três simuladores foram incluídos: ABACUS, WinMIPS64 e GNUSim8085.
2.2.1 NeanderWin
O NeanderWin é um simulador de caráter educacional desenvolvido para a máquina
Neander-X onde é possível editar, compilar e executar códigos de programas em linguagem de
montagem do processador Neander-X (BORGES; SILVA, 2006).
Conforme Borges e Silva (2006), o Neander-X é uma extensão da máquina Neander original
e sua arquitetura inclui entre outros detalhes:
1. Carga de dados imediatos no acumulador;
2. Modo indireto de endereçamento; e
3. Operações de E/S para dois dispositivos mapeados no simulador NeanderWin: um painel
de chaves e um visor.
A Figura 4 mostra a tela principal do sistema NeanderWin. Na parte superior estão os botões
usados em conjunto com o editor de texto. Logo abaixo, à esquerda, estão os dispositivos mapeados
para entrada e saída, ilustrados por chaves e um visor seguido do editor de textos e a direita se
situam os verificadores dos registradores principais da CPU (Central Processing Unit) e o
visualizador da memória.
14
Figura 4. Tela principal do sistema NeanderWin
Fonte: Borges e Silva (2006).
As instruções de E/S do Neander-X são representadas por IN e OUT seguido do operando
ender. A instrução IN trás para o acumulador o valor lido em um dispositivo externo indicando pelo
operando ender que no NeanderWin são chaves (endereço 0) e o status de “dado disponível” das
chaves (endereço 1). Já a instrução OUT descarrega o conteúdo do acumulador em um dispositivo
externo, representado no NeanderWin por um visor no endereço 0 (BORGES; SILVA, 2006).
2.2.2 MipsIt
O MipsIt é um conjunto de ferramentas formado por um ambiente de desenvolvimento, uma
plataforma de hardware e uma série de simuladores desenvolvidos com o propósito de auxiliar o
ensino de arquitetura e organização de computadores (BRORSSON, 2002).
15
No MipsIt é possível ter uma visão geral do funcionamento do processador, como
registradores, sinais de interrupção, portas de E/S e memória. A Figura 5 mostra o MipsIt com
algumas de suas janelas abertas. A entrada e saída no MipsIt é feita através de oito chaves binárias e
oito leds que, conforme Brorsson (2002), são as mesmas implementadas em hardware.
Figura 5. Janelas do MipsIt
Fonte: Brorsson (2002).
2.2.3 ABACUS
O ABACUS (ZILLER, 1999) é um simulador do Microprocessador 8085 desenvolvido por
pesquisadores da Universidade Federal de Santa Catarina (UFSC), sob a coordenação do Prof.
Roberto M. Ziller.
A Figura 6 ilustra a interface do simulador ABACUS. A interface dispõe de várias janelas
onde são exibidas as instruções, conteúdo dos registradores, conteúdo da memória e portas de E/S.
As portas de E/S são representadas por um conjunto de chaves e um conjunto de leds
respectivamente.
16
Figura 6. Tela principal do ABACUS
Fonte: Ziller (1999).
2.2.4 WinMIPS64
O WinMIPS64 é um simulador de instrução do MIPS 64 bits e foi projetado como um
substituto para o utilitário WinDLX (SCOTT, 2010).
A interface do WinMIPS64 é composta de sete janelas: Pipeline, Code, Data, Registers,
Statistics, Cycles e Terminal.
O simulador suporta entrada e saída através dos registradores de controle, utilizado para
configurar a porta, e de dados. A comunicação é realizada através de um terminal conforme ilustra a
Figura 7.
17
Figura 7. Tela principal do WinMIPS64
Fonte: Scott (2010).
2.2.5 GNUSim8085
O GNUSim8085 (GNUSim8085, 2003) é um simulador do processador Intel 8085
desenvolvido por Sridhar Ratnakumar em 2003 para os ambientes Linux e Windows.
Na interface do GNUSim8085 é possível visualizar o conteúdo dos registradores, flags e
memória. A ferramenta apresenta também campos para interação com portas de entrada e saída e
memória conforme ilustra a Figura 8.
18
Figura 8. Tela Principal do GNUSim8085
Fonte: GNUSim8085 (2003).
2.2.6 Comparação entre Simuladores Analisados
A partir dos simuladores descritos foi possível identificar características referentes à
interface de E/S. Outras funcionalidades analisadas em Vieira (2009), como simulação da
organização e desenvolvimento de programas em linguagem de alto nível representam um grande
diferencial para o ensino (BORGES; SILVA, 2006) e foram incluídas na comparação que é
ilustrada na Tabela 7.
Os simuladores estudados, em sua maioria, apresentam interfaces baseadas em controles
simples, como representações de chaves e leds, e também visores ilustrando valores em decimal ou
em hexadecimal. Estas interfaces permitem resolver problemas onde entrada e saída são números,
como um algoritmo simples que soma dois números, e problemas que simulem o controle de algum
dispositivo acoplado ao processador que tenham a necessidade de ler ou escrever em determinados
bits da porta. Baseado nisto, optamos por adotar como proposta para o Bipide uma interface
baseada em chaves e leds e que tenha também a opção de edição e leitura em decimal.
19
Tabela 7. Características dos sistemas analisados
Simulador
Simulação da Desenvolvimento de programas
Interface
Organização
em linguagem de alto nível
Não
Não
Chaves e visor
NeanderWin
Sim
Sim
Chaves e Leds
MipsIt
Não
Não
Chaves e Leds
ABACUS
Não
Não
Terminal
WinMIPS64
Não
Não
Campo Editável
GNUSim8085
Proposta para
Sim
Sim
Chaves e Leds
o Bipide
Observa-se que na comparação acima os sistemas Bipide e MipsIt apresentam as mesmas
características. Porém, a simulação da organização do Bipide, permite ao usuário visualizar, através
de animações, o funcionamento dos componentes do processador. Esta característica é um grande
diferencial auxiliando o aprendizado.
2.3 Bipide
A ferramenta Bipide é uma IDE que implementa instruções dos processadores BIP I e BIP II
onde é possível a criação de algoritmos em portugol e sua execução passo a passo. A ferramenta
permite visualizar o código correspondente em linguagem assembly e o estado dos componentes da
organização do processador contando com animações que ilustram seu funcionamento (VIEIRA,
2009).
Na implementação da interface gráfica e classes do Bipide foi utilizada a ferramenta de
desenvolvimento Visual Studio 2008 (MICROSOFT CORPORATION, 2009) na linguagem C#.
Para implementar as animações e elementos gráficos do simulador utilizou-se a ferramenta
Expression Blend 2 (MICROSOFT CORPORATION, 2008a). A gramática e os analisadores do
compilador foram definidos utilizando a linguagem ANTL3 e a IDE ANTLRWorks (PARR, 2009).
2.3.1 Compilador
Conforme Vieira (2009), o subconjunto da linguagem Portugol, suportado pelo Bipide, foi
definido segundo as características arquiteturais dos processadores BIP I e BIP II, onde foram
disponibilizadas estruturas básicas de desvio e repetição além dos elementos básicos da estrutura de
um programa.
20
A Tabela 8 ilustra a lista de símbolos da gramática Portugol onde é possível observar que
somente o tipo de dado inteiro é suportado assim como os operadores aritméticos de adição e
subtração.
Tabela 8. Lista de Símbolos da Gramática Portugol
Portugol
Programa
Declarações
Defina
Inicio
Fim
Inteiro
se ___ então
Senão
Fimse
enquanto ___ faca
Fimenquanto
repita ___ quando
para ___ ate ___ passo
Fimpara
<(,)
+,>, <, >=, <=, !=, =
Descrição
Símbolo inicial da gramática
Definição de bloco de declaração de
variáveis
Definição de constantes
Identifica o início do algorítmo
Identifica o fim do algorítimo
Tipo de dado numério inteiro
Desvio condicional
Negação do ‘SE’
Fim do bloco de desvio condicional
Laço de repetição com condição no início
Fim de bloco de laço condicional
Laço de repetição com condição no fim
Laço condicional com repetição incremental
Fim de bloco de laço condicional com
repetição incremental
Operador de atribuição
Parênteses
Operadores aritméticos
Operadores relacionais
Fonte: Adaptado de Vieira (2009).
O compilador do Bipide gera, a partir do código em portugol, o código em linguagem de
montagem para os processadores BIP dividido em duas seções: (i) cabeçalho (.data), contendo a
declaração de variáveis; e (ii) código (.text), contendo as instruções do programa.
Para construção do compilador do Bipide, foi utilizada a ferramenta ANTLR3 (ANother
Tool for Language Recognition V.3 ), (ANTLR, 2007) onde foram gerados os analisadores léxico e
sintático e definidas as ações semânticas para geração do código em linguagem de montagem e
tratamento de erros. Utilizou-se também a IDE ANTLRWorks que é um ambiente de
desenvolvimento de gramáticas para o ANTLR3.
Segundo Vieira (2009), a utilização da IDE ANTLRWorks facilitou a integração do
compilador no ambiente Bipide, já que permite a geração de código para C#, linguagem na qual o
Bipide foi desenvolvido.
21
A Figura 9 ilustra o trecho de gramática correspondente aos comandos aceitos pelo portugol
onde cmdo é composto por desvios, laços e atribuições e estes compostos por suas devidas
estruturas. Note que nas linhas 8 e 9 os comandos para leia e escreva estão comentados, já que o
Bipide em seu estado atual não os suporta. O Apêndice A contém a gramática completa da
linguagem portugol incluindo as novas especificações que serão vistas posteriormente.
Figura 9. Exemplo da gramática do Portugol no ANTLR
Fonte: Adaptado de Vieira (2009)
As ações semânticas na ANTLR são definidas na gramática adicionando o código fonte que
será responsável pela ação. A Figura 10 mostra um trecho da gramática do portugol onde as partes
da gramática aparecem em negrito seguido da ação semântica delimitada por chaves. Os símbolos
terminais são representados por letras maiúsculas e os símbolos não terminais são representados por
letras minúsculas. As ações ilustradas na Figura 10 são responsáveis por armazenar o código em
portugol para posteriormente relacionar com a instrução ou instruções correspondentes em
assembly.
Figura 10. Exemplos de ações semânticas do Bipide
22
Fonte: Adaptado de Vieira (2009).
2.3.2 Simulador
Conforme Vieira (2009), o módulo de simulação do Bipide, ilustrado na Figura 11, permite
a visualização simultânea da linguagem de alto nível, linguagem assembly e a organização do
processador permitindo a redução da abstração apresentadas nos conceitos de programação.
Figura 11. Simulador do Bipide
Fonte: Vieira (2009)
O WPF trata-se de uma tecnologia para desenvolvimento de aplicativos e interfaces,
desenvolvida pela Microsoft. O WPF permite que a interface seja independente do código, podendo
ser desenvolvida por um designer enquanto que o código por um programador especializado. A
flexibilidade do WPF permite interfaces com recursos 3D, animações, gráficos vetoriais entre
outros recursos (SONNINO; SONNINO, 2006).
Um programa em WPF é geralmente composto por um arquivo XML (eXtensible Markup
Language) com características especiais chamado XAML (eXtended Aplication Markup Language)
23
e um código para .NET. No XAML os elementos assim como seus atributos são definidos usando
tags. A Figura 12 ilustra um exemplo de código fonte na linguagem XAML onde é possível
observar a definição de um componente Label e seus atributos. Este mesmo componente poderá ser
utilizado da mesma maneira que um componente de uma aplicação Windows Forms utilizando um
código para .NET.
Figura 12. Exemplo de código fonte da linguagem XAML
Fonte: Sonnino, Sonnino (2006).
O Expression Blend 2, por sua vez, é uma ferramenta de design para criação de aplicações
em WPF que podem ser desenvolvidos para plataforma Windows ou Web (MICROSOFT
CORPORATION, 2008b). A linguagem XAML permite que aplicações criadas com o Expression
Blend 2 sejam compatíveis com o Visual Studio 2008 (MICROSOFT CORPORATION, 2008a).
A Figura 13 apresenta uma visão geral da ferramenta Expression Blend 2 onde é possível
observar parte da definição das animações do simulador do Bipide, o código em linguagem XAML
e logo abaixo as linhas de tempo que representam animação ao longo do tempo o que facilita a
criação de animações.
As animações do simulador foram definidas em função das instruções dos processadores
BIP. A execução de uma instrução resulta na execução de uma animação na organização do
processador.
24
Figura 13. Visão geral da ferramenta Expression Blend 2
Fonte: Adaptado de Vieira (2009)
25
3 DESENVOLVIMENTO
Esta seção tem por objetivo apresentar os requisitos e especificações do BIP IV e seu
suporte na IDE Bipide. Também detalha a implementação das alterações na IDE Bipide.
3.1 Especificação do BIP IV
Para contemplar os objetivos deste trabalho o BIP IV deve suportar E/S e chamada de
subrotinas. Por isso, a especificação do BIP IV foi baseada em antecipar algumas instruções
presentes no µBIP e estender o BIP III. Além de E/S e chamada de procedimentos foi adotado
suporte a operações lógicas, deslocamento bit a bit e manipulação de vetores.
3.1.1 Arquitetura
Esta seção tem como objetivo descrever os atributos arquiteturais presentes no processador
BIP IV.
3.1.1.1 Tamanho da Palavra e tipo de Dados
O tamanho da palavra de dados e de instruções do BIP IV, assim como nos outros
processadores BIP, é de 16 bits. Somente o tipo Inteiro de 16 bits é suportado, comportando valores
entre -32768 e +32767.
3.1.1.2 Espaços de Endereçamento
O espaço de endereçamento de memória de dados e instruções do BIP IV foi mantido em 11
bits sendo possível endereçar até 2K de instruções ou dados. Para suportar entrada e saída foi
adotado o método de E/S mapeada em memória, assim como em Pereira (2008), não necessitando
grandes modificações na arquitetura e na organização. Neste caso, 1K da memória de dados é
reservado para os registradores de E/S, dividindo a memória ao meio e permitindo identificar pelo
bit mais significativo se o acesso será à memória (0) ou à E/S (1). Dos endereços reservados para
E/S, apenas dois são utilizados conforme mostra a Figura 14.
26
Figura 14. Organização da Memória de E/S
3.1.1.3 Registradores
O BIP IV possui os seguintes registradores: PC, que contém o endereço da instrução
corrente; ACC que contém o resultado da UF; STATUS, que contém informações sobre o resultado
da operação na ULA; INDR, que contém o índice a ser utilizado no suporte a vetores; SP, que
aponta para o topo da pilha da chamada de procedimento; IN_PORT, mapeado em endereço de E/S,
utilizado para entrada de dados; e OUT_PORT, também mapeados em endereço de E/S, utilizado
para saída de dados. Os registradores INDR e SP são os mesmos adotados em Pereira (2008).
3.1.1.4 Formato de Instruções
O formato de instrução, ilustrado pela Figura 15, permaneceu composto por 5 bits para o
código da instrução e 11 bits para o operando sendo o único formato suportado pelos processadores
BIP.
15 14 13 12 11 10
Cód. Operação
9
8
7
6 5 4
Operando
3
2
1
0
Figura 15. Formato de Instruções do BIP IV
3.1.1.5 Modos de Endereçamento
Os modos de endereçamento no BIP IV são os mesmos presentes no µBIP, que além dos
modos de endereçamento direto e imediato, possui o modo indireto. No modo direto o operando
refere-se a um endereço efetivo da memória de dados. No modo imediato o operando é uma
constante. Já no indireto, utilizado nas instruções STOV e LDV, o operando é um endereço base de
um vetor o qual será somado ao registrador INDR determinando o endereço efetivo da memória de
dados.
27
3.1.1.6 Conjunto de Instruções
O conjunto de instruções do BIP IV, ilustrado pela Tabela 9, é uma extensão do conjunto de
instruções presentes no BIP III, acrescidos de instruções presentes no µBIP responsáveis pelo
suporte a sub-rotinas e manipulação de vetores.
Tabela 9. Conjunto de Instruções do BIP IV
Opcode
00000
00001
00010
00011
00100
00101
00110
00111
Instrução
HLT
STO
LD
LDI
ADD
ADDI
SUB
SUBI
operand
operand
operand
operand
operand
operand
operand
01000
BEQ
operand
01001
BNE
operand
01010
BGT
operand
01011
BGE
operand
01100
BLT
operand
01101
BLE
operand
01110
01111
10000
JMP
NOT
AND
operand
10001
10010
ANDI operand
OR
operand
10011
10100
ORI
XOR
10101
XORI operand
operand
operand
operand
Operação e atualização do PC
Desabilita atualização do PC
PC PC
Memory[operand] ACC
ACC Memory[operand]
ACC operand
ACC ACC + Memory[operand]
ACC ACC + operand
ACC ACC – Memory[operand]
ACC ACC – operand
PC
PC
PC
PC
PC
PC
PC
PC
PC
PC
PC
PC
PC
PC
+
+
+
+
+
+
+
1
1
1
1
1
1
1
Se (STATUS.Z=1) então
PC endereço
Se não
PC PC + 1
Se (STATUS.Z=0) então
PC endereço
Se não
PC PC + 1
Se (STATUS.Z=0) e
(STATUS.N=0) então
PC endereço
Se não
PC PC + 1
Se (STATUS.N=0) então
PC endereço
Se não
PC PC + 1
Se (STATUS.N=1) então
PC endereço
Se não
PC PC + 1
Se (STATUS.Z=1) ou
(STATUS.N=1) então
PC endereço
Se não
PC PC + 1
PC endereço
ACC NOT(ACC)
ACC ACC AND
Memory[operand]
ACC ACC AND operand
ACC ACC OR
Memory[operand]
ACC ACC OR operand
ACC ACC XOR
Memory[operand]
ACC ACC XOR operand
28
PC PC + 1
PC PC + 1
PC PC + 1
PC PC + 1
PC PC + 1
PC PC + 1
PC PC + 1
10110
10111
11000
SLL operand
SRL operand
STOV operand
11001
LDV
11010
11011
11100
RETURN
operand
ACC ACC << operand
ACC ACC >> operand
Memory[operand + INDR]
ACC
ACC Memory[operand +
INDR]
PC PC + 1
PC PC + 1
PC PC + 1
PC PC + 1
PC ToS
Não utilizada
CALL operand
PC operand
ToS PC+1
A Tabela 9 contém o conjunto de instruções e suas respectivas ações e atualização PC. A
instrução 11011 está implementada no µBIP e é responsável pelo retorno de interrupções, porém
não foi utilizada. Para manter a compatibilidade entre os processadores BIP IV e µBIP, este mesmo
código não foi utilizado para uma instrução com outra finalidade.
O conjunto de instruções é formado por 28 instruções. Como o opcode composto por 5 bits
permite até 32 instruções, restam 4 instruções, sendo 3 para novas instruções e 1 delas está
implementada como retorno de interrupção em Pereira (2008). A Figura 16 mostra as classes de
instruções dos processadores BIP sendo possível observar também, em qual processador cada classe
de instrução está presente. Lembrando que as instruções agregadas ao BIP IV foram herdadas do
processador µBIP. Uma descrição mais completa do conjunto de instruções do BIP IV é
apresentada no Apêndice B .
29
Figura 16. Classes de Instruções dos processadores BIP
Ressalta-se que o suporte a procedimento foi baseado na solução utilizada em Pereira
(2008), onde há uma pilha implementada em hardware dedicada para armazenar o endereço da
instrução seguinte a chamada de procedimento.
30
3.1.1.7 Resumo da arquitetura do BIP IV
A Tabela 10 ilustra o resumo da arquitetura do BIP IV.
Tabela 10. Resumo da arquitetura do BIP IV
Tamanho da palavra de dados
Tipos de dados
Tamanho da palavra de instrução
Formato de instrução
16 bits
Inteiro de 16 bits com sinal –32768 a +32767
16 bits
Modos de endereçamento
Direto: o operando é um endereço da memória
Imediato: o operando é uma constante
Indireto: o campo Operando é um endereço base de um
vetor que é somado ao INDR para o cálculo de um
endereço efetivo da memória de dados
ACC: acumulador
PC: contador de programa
STATUS: registrador de Status
INDR: registrador de índice
SP: apontador do topo da pilha
Armazenamento: STO
Carga: LD e LDI
Aritmética: ADD, ADDI, SUB e SUBI
Lógica booleana: AND, OR, XOR, ANDI, ORI, XORI e NOT
Controle: HLT
Desvio: BEQ, BNE, BGT, BGE, BLT, BLE e JMP
Deslocamento Lógico : SLL e SRL
Manipulação de vetor: LDV e STOV
Suporte a procedimentos : RETURN e CALL
Registradores
Classes de instrução
15 14 13 12 11 10
Cód. Operação
9
8
7
6 5 4
Operando
3
2
1
0
3.1.2 Organização
A organização do BIP IV foi baseada na organização do processador BIP III com a adição
de alguns componentes presentes no µBIP para suportar manipulação de vetores e chamada de subrotinas além dos pinos de E/S (registradores IN_PORT e OUT_PORT). Estes componentes
compreendem uma pilha de suporte a procedimentos, onde será salvo o endereço de memória da
instrução seguinte à chamada da sub-rotina e uma unidade de manipulação de vetores.
O módulo de manipulação de vetores é composto por um registrador (INDR) e um somador.
Este módulo é responsável por calcular o endereço efetivo de memória através da soma do
operando nas instruções LDV e STOV com o conteúdo do registrador INDR. A Figura 17 mostra a
organização do módulo de manipulação de vetores, onde os pinos wr_indr e data_in são
responsáveis pela gravação do registrador INDR, e o pino select, é responsável por definir se a saída
será a soma da entrada operand com o conteúdo do registrador INDR ou apenas operand
(PEREIRA,2008).
31
select
operand
wr_indr data_in
ena
INDR
+
0
1
sel
addr
Figura 17. Organização do módulo de manipulação de vetores
A Figura 18 ilustra a organização do BIP IV onde é possível observar os componentes
agregados ao processador, como a pilha (representada como Stack) e a unidade de manipulação de
vetores (representada por Vector Access), além dos controles adicionados ao decodificador de
instruções.
32
Extensão de
Sinal
STACK
Stack in
Stack out
WrEn
2
0
1
SelA
0x001
Decoder
Stack_wr
Stack_op
WrPC
WrACC
SelA
SelB
SelC
is_vector
WrData
FU_Op
SourcePC
+
3
2
1
0
Opcode
WrACC ena
ACC
N
operand1
SelB
operand2
addr_in
Function Unit
data_in
WrData
C
FU_Op
ena
0
E/S
Z N C
Z
1
wren
data_out
Operation
ena
PC
STATUS
N
Z
SelC
0
Vector Access
data_in
addr_in
is_vector
is_vector_in
1
addr_out
WrData
Addr
Out_Data
Wr
Program Memory
Addr
In_Data
Out_Data
Data Memory
Figura 18. Organização do BIP IV
3.2 Alterações na IDE Bipide
Para contemplar o objetivo deste trabalho, a IDE Bipide foi alterada de modo a suportar os
seguintes requisitos: (i) fornecer suporte a operações de E/S; (ii) fornecer suporte a utilização de
vetores; (iii) fornecer suporte a chamada de sub-rotinas com passagem de parâmetros; e (iv)
fornecer suporte a operações de lógica.
As principais alterações no Bipide foram relacionadas basicamente a mudanças na gramática
do portugol, geração do código em assembly e mudanças no simulador. Em decorrência das
alterações na gramática, novas verificações nas ações semânticas foram implementadas e serão
descritas ao longo desta Seção. A Figura 19 ilustra a estrutura básica na qual o Bipide foi
desenvolvido.
33
Gramática +
ações
semânticas
Classes e
Interface
ANTLR
Analisadores do
compilador
Código Fonte em
C#
Visual Studio
Bipide
XAML
(Animações do
Simulador)
Expression Blend
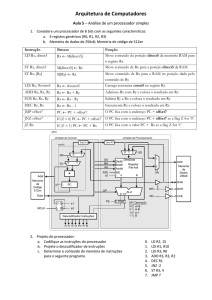
Figura 19. Fluxo de Implementação do Bipide
O simulador do Bipide, em sua versão anterior, permitia escolher entre os processadores BIP
I e BIP II, refletindo em mudanças nas instruções disponíveis, ilustrações e animações do
processador. A fim de manter esta idéia, o simulador foi alterado de modo a permitir escolher, além
do BIP I e BIP II, os processadores BIP III e BIP IV.
3.2.1 Operações de E/S
O ambiente Bipide foi modificado a fim de suportar comandos de E/S ao simular o
processador BIP IV. Estas modificações incluem a gramática do portugol, geração de código
assembly e mudanças no simulador.
3.2.1.1 Mudanças na Gramática de Portugol
A gramática portugol definida neste projeto suporta comandos do tipo leia e escreva. Estes
comandos permitem um ou mais argumentos como parâmetro conforme a Figura 20. Para isso,
foram incluídos dois símbolos terminais (tokens), chamados “ leia e escreva” , e mais duas
derivações para o não-terminal cmdo conforme mostra a Figura 20.
LEIA
:
ESCREVA:
cmdo
'leia' | 'LEIA';
'escreva' | 'ESCREVA';
:
|
|
|
|
|
|
cmd_se
cmd_se_senao
cmd_enq_faca
cmd_faca
cmd_para
cmd_leia
cmd_escreva
34
| atribuicao
| cmd_return
| cmd_call
;
cmd_leia
cmd_escreva
lista_id
: LEIA '(' lista_id ')' ;
: ESCREVA '(' lista_saida ')';
: id (',' id)*;
lista_saida : exp (',' exp)*;
Figura 20. Alterações na gramática de E/S
3.2.1.2 Geração de Código Assembly
Como as operações de E/S são mapeadas em endereço de memória, foram utilizadas
instruções de transferência (armazenamento e carga) onde os operandos são os registradores
$in_port (para entrada) e $out_port (para saída). A Figura 21 apresenta um código exemplo em
portugol e seu respectivo código em assembly. A geração de código ficou semelhante a uma
atribuição, não gerando grande complexidade de implementação.
Portugol
procedimento principal()
declarações
inteiro a,b
inicio
leia (a,b)
a <- a + b
escreva (a)
fim
Descrição
.DATA
A : 0
B : 0
.TEXT
_principal:
LD $in_port
STO A
LD $in_port
STO B
LD A
ADD B
STO A
LD A
STO $out_port
HLT
;lê o endereço de entrada
;grava em a
;lê o endereço de entrada
;grava em b
;carrega a
;grava no edereço de saída
Figura 21. Geração de código para E/S
3.2.1.3 Mudanças no Simulador
No caso do BIP IV, o simulador apresenta uma interface de leds como periférico de saída e
chaves binárias como periférico de entrada. Estes periféricos representam os valores das posições
mapeadas em memória para esta finalidade. Esta solução, utilizando leds e chaves, foi adotada em
alguns simuladores estudados como NeanderWin, MipsIt e ABACUS e a utilizamos por refletir em
um nível de abstração médio na qual fica transparente ao utilizador o real funcionamento do
35
hardware. Além das chaves e leds, é possível a edição e leitura em decimal assim com citado na
comparação entres os simuladores estudados. A Figura 22 apresenta a interface de E/S do simulador
do Bipide.
Figura 22. Interface de E/S
No caso da leitura, como não há como saber quando os dados estão prontos para leitura, uma
opção de breakpoint (ponto de parada) automática foi disponibilizada no simulador para estas
operações. Com um programa em execução e com a opção de breakpoint habilitada, o simulador
para a execução antes da instrução de entrada, permitindo que o utilizador informe um valor através
das chaves da interface de E/S ou digitando.
Para a execução da simulação foram necessários ajustes no tratamento de instruções de
transferência (LD e STO) a fim de suportar acesso aos registradores $in_port e $out_port, que estão
localizados nos endereços 1024 e 1025 respectivamente. Também foram implementadas duas novas
animações que ilustram o acesso aos registradores.
3.2.2 Utilização de Vetores
Para suportar a utilização de vetores, foram necessárias alterações na gramática do Portugol,
no analisador semântico, na geração de código assembly e no simulador, conforme detalhado a
seguir. Cabe lembrar que o suporte a vetores estará disponível somente ao simular o BIP IV.
3.2.2.1 Mudanças na Gramática do Portugol
As mudanças na gramática compreendem declarações de vetores e seu uso em expressões e
comandos. A Figura 23 ilustra as alterações efetuadas na declaração de variáveis, atribuição e uso
de vetores em expressões. Estas alterações permitem códigos em portugol semelhantes ao ilustrado
pela Figura 24.
.
.
.
ID : (('a'..'z' | 'A'..'Z')
.
.
.
('a'..'z'|'A'..'Z'| '0'..'9' | '_' )*
36
);
dec_var
lista_var
: INTEIRO
lista_var ;
: ID ('['VINT']')?
(','ID ('['VINT']')?)* ;
.
.
.
atribuicao : id ('['exp']')? '<-' exp ;
.
.
.
atom :
VINT
| ID
| ID ('['exp04']')
| '('! exp04 ')'!
| ID '('explist')'
| ID '('')'
;
.
.
.
Figura 23. Alterações na gramática para suporte a vetores
3.2.2.2 Geração de Código Assembly
Para a manipulação de vetores no BIP IV, são utilizadas as instruções STOV, para
armazenamento, e LDV para carga. Estas instruções dependem do valor contido no registrador
INDR para obter o valor efetivo da memória de dados a ser acessado. Para armazenar um valor no
registrador INDR é utilizada a instrução STO seguido do endereço de acesso ao registrador
representado por INDR. A Figura 24 mostra um pequeno algoritmo em portugol compilado pela
ferramenta, com seu respectivo código assembly. Ao final da execução, o conteúdo de cada posição
do vetor b será igual ao seu índice.
Portugol
procedimento principal()
declaracoes
inteiro a,b[5]
inicio
a <- 0
enquanto (a < 5) faca
b[a] <- a
escreva(b[a])
a<-a+1
fimenquanto
fim
Assembly
.data
a : 0
b : 0
.text
_PRINCIPAL:
LDI
0
STO
a
INI_ENQ1:
LD
a
STO
1000
LDI
5
STO
1001
LD
1000
SUB
1001
BGE
FIMFACA1
LD
a
37
STO
LD
STO
LD
STO
LD
STOV
LD
STO
LDV
STO
LD
ADDI
STO
JMP
FIMFACA1:
HLT
1000
a
1001
1000
$indr
1001
b
a
$indr
b
$out_port
a
1
a
INI_ENQ1
0
Figura 24. Geração de Código para suporte a vetores
Note que o índice de um vetor do lado esquerdo da atribuição é armazenado em uma
variável temporária para posteriormente ser gravado no registrador $indr a fim de permitir sua
utilização na expressão do lado direito da atribuição. A Figura 25 ilustra o código responsável pela
geração de código para atribuições, onde é possível observar o tratamento no caso de vetores.
atribuicao
@init
{
paraphrases.Push("Erro no comando Atribuição");
}
@after
{
string strInst = "STO";
this.desempilhaContexto(); //desempilha as variáveis de controle
if (atribuicaoVetor){
strInst = "STOV";
string nomeVar = GetVarTemp();
string indice = temporarios.Pop();
this.AddInstrucao("STO", nomeVar);
this.AddInstrucao("LD", indice);
this.AddInstrucao("STO", "\$indr");
this.AddInstrucao("LD", nomeVar);
atribuicaoVetor = false;
}
paraphrases.Pop();
this.AddInstrucao(strInst, pilha.Pop());
this.SetInstrucaoPortugol($atribuicao.text);
}
: id ({this.atribuicaoVetor = true;
this.AddInstrucaoPortugol();
}'['exp']'{
string nomeVar = GetVarTemp();
temporarios.Push(nomeVar);
this.AddInstrucao("STO", nomeVar);
})?
{
if (!this.atribuicaoVetor)
this.AddInstrucaoPortugol();
this.empilhaContexto(); //armazena as variáveis de controle em uma pilha
pilha.Push($id.text);
} '<-' exp ;
Figura 25. Ações semânticas para geração de código para atribuições
38
3.2.2.3 Mudanças no Simulador
Além dos componentes organizacionais do BIP III e BIP IV, o simulador foi alterado a fim
de permitir a visualização do registrador INDR (no caso do BIP IV) e permitir a visualização da
memória seqüencial alocada para o vetor no depurador. Também foram feitas animações quanto ao
caminho de dados e controle do decodificador de instruções, como já implementados para os
processadores BIP I e BIP II.
Em caso de a posição a ser acessada em um vetor, durante uma simulação, violar o espaço
definido em sua declaração, uma mensagem é exibida e a simulação é interrompida. Esta
verificação é feita nas instruções LDV e STOV.
3.2.3 Chamada de sub-rotinas
Para implementação de chamada de sub-rotinas, de suporte ao BIP IV, houve mudanças na
gramática portugol, na geração do código assembly e no simulador.
3.2.3.1 Mudanças na Gramática do Portugol
Anteriormente, a gramática portugol era composta por um único escopo identificado com o
símbolo inicial programa. Para possibilitar o suporte a sub-rotinas, a gramática foi modificada para
permitir mais de um escopo no programa sendo um principal. As sub-rotinas podem ser
procedimentos ou funções e deverão suportar passagem de parâmetro.
Na fase de projeto foi cogitado suporte a passagem de parâmetros por referência. Porém,
após análise, foi constatado que sua utilização seria inviável, pelo fato de os processadores BIP não
possuem instruções que permitam utilização de ponteiros. A solução adotada na fase de projeto, na
qual as variáveis passadas por referências seriam recuperadas após a chamada da sub-rotina,
causaria o mesmo efeito, porém didaticamente, causaria uma falsa impressão de como seria a
passagem de parâmetros por referência.
A declaração de procedimentos tem como símbolo inicial o token procedimento. As funções
iniciam com o símbolo inteiro (único tipo suportado pelos processadores BIP) já existente na
gramática. A chamada das sub-rotinas é feita pelo seu identificador seguido pelos parâmetros entre
parênteses e, no caso das funções, podem ser utilizadas em expressões, atribuições e comandos de
Saída.
39
Para retornar da sub-rotina, foi adicionado o comando RETORNAR, que, no caso de uma
função, poderá ser seguido de uma expressão, variável, constante ou até mesmo uma função. Na
Figura 26 é possível observar as alterações que foram necessárias para o suporte a sub-rotinas.
PROCEDIMENTO:
programa
'procedimento' | 'PROCEDIMENTO';
: escopo+;
escopo
: (PROCEDIMENTO | INTEIRO) ID (('(' lista_param ')')|('(' ')'))
dec
INICIO
lista_cmdo
FIM
;
cmdo
: cmd_se
| cmd_se_senao
| cmd_enq_faca
| cmd_faca
| cmd_para
| cmd_leia
| escreva
| atribuicao
| cmd_return
| cmd_call
;
parametro
: INTEIRO id;
lista_param
: parametro (',' parametro)*;
cmd_return : RETORNAR exp;
parametro_chamada :
exp;
parametros_chamada :
'(' parametro_chamada (',' parametro_chamada )* ')';
lista_param_chamada
:
'('')' | parametros_chamada;
cmd_call: ID '(' lista_param_chamada ')';
atom
:
VINT
| ID
| ID
| '('! exp04 ')'!
| ID '('explist')'
| ID '('')'
;
Figura 26. Alterações na Gramática para suporte a sub-rotinas
3.2.3.2 Geração de Código Assembly
O suporte a sub-rotinas no BIP IV é feito através das instruções CALL, utilizada para
chamar uma sub-rotina, e RETURN, utilizada para retornar à instrução posterior a chamada, cujo
endereço estará armazenado na pilha de suporte a procedimentos.
40
Como as variáveis podem ter o mesmo nome em escopos diferentes, a geração do código
das variáveis, com exceção do escopo principal, é composta do nome do procedimento e da
variável, como é possível observar na Figura 27 onde é ilustrado um programa compilado pela
ferramenta.
Os procedimentos e funções são separados em blocos identificados por rótulos, onde a
primeira instrução da seção .text é um desvio incondicional para o rótulo correspondente ao
procedimento ou função principal conforme mostra a Figura 27.
O retorno da função é feito através do registrador ACC sendo apenas necessário carregar o
valor a ser retornado utilizando as instruções LD ou LDI. Após a execução do comando RETURN a
execução do programa desviará para a instrução imediatamente posterior à chamada da sub-rotina.
Portugol
Assembly
.data
soma_r : 0
soma_a : 0
soma_b : 0
a : 0
b : 0
x : 0
.text
JMP
_PRINCIPAL
_SOMA:
LD
SOMA_a
ADD
SOMA_b
STO
SOMA_r
LD
SOMA_r
RETURN 0
_PRINCIPAL:
LD
$in_port
STO
a
LD
$in_port
STO
b
LD
a
STO
SOMA_a
LD
b
STO
SOMA_b
CALL
_SOMA
STO
x
HLT
0
inteiro soma(inteiro a,inteiro b)
declaracoes
inteiro r
inicio
r <- a+b
retornar r
fim
//principal
procedimento principal()
declaracoes
inteiro a, b, x
inicio
leia (a,b)
x <- soma(a,b)
fim
Figura 27. Geração de código para sub-rotinas
Procedimentos e funções são inseridos em uma tabela de símbolos para que seja possível
verificar erros em declarações. No caso do uso de funções ou procedimentos, as mesmas devem
estar declaradas, ou seja, seu código de declaração deverá estar anterior a sua utilização. O
41
compilador, também impede que procedimentos, por não retornarem valor sejam utilizados em
expressões ou comandos derivados de expressões.
O código fonte em portugol deve, obrigatoriamente, conter um procedimento ou função
principal de nome “principal” e este não deve conter parâmetros. Como a gramática dá suporte a
parâmetros, estes também são incluídos na tabela de símbolos.
O compilador obriga também que uma função tenha um comando de retorno. Procedimentos
podem conter o comando de retorno, porém este somente irá interromper sua execução não
retornando nenhum valor.
Devido às limitações da estrutura de suporte a procedimentos no BIP IV, herdada do µBIP,
não é permitido recursividade. A pilha grava somente o endereço de instruções o que obriga o uso
de variáveis globais não permitindo recursividade. Também pelo motivo do uso de variáveis
globais, não é permitido que a chamada de uma função seja utilizada como parâmetro para a mesma
função (Ex: asoma(soma(2,3),4).
Durante a implementação das alterações foram detectados problemas relacionados ao uso de
variáveis temporárias (posições de memória temporárias utilizadas em instruções onde é necessário
guardar o valor contido no acumulador). Estas posições de memória são definidas na geração de
código assembly, e em testes realizados, ocorreram casos em que endereços temporários de
memória eram compartilhados entre escopos diferentes comprometendo os dados. Para contornar a
situação, a alocação desta memória temporária foi modificada a fim de impedir que endereços
sejam compartilhados entre escopos diferentes.
3.2.3.3 Mudanças no Simulador
As alterações no simulador, quanto à chamada de sub-rotinas, foram alteradas a fim permitir
a visualização do conteúdo do registrador SP (topo da pilha) e também apresentar animações
referentes ao caminho de dados e sinais de controle do decodificador de instruções.
3.2.4 Operações de Lógica
Para a implementação de operações de lógicas, de suporte ao BIP III e conseqüentemente ao
BIP IV, foram necessárias pequenas mudanças na gramática portugol, geração de código assembly
e simulador.
42
3.2.4.1 Mudanças na Gramática do Portugol
As operações de lógica foram incluídas nas produções referentes as expressões conforme
suas prioridades em relação às operações já existentes. Os operadores definidos para operações com
lógica são: (i) „!‟ como operador NOT; (ii) „^‟ como operador XOR; (iii) „|‟ como operador OR; (iv)
„&‟ como operador AND; (v) „<<‟ como operador de deslocamento à esquerda; e (vi) „>>‟ como
operador de deslocamento à direita.
Para o suporte às operações lógicas no portugol, apenas a produção exp foi modificada
incluindo um nível de hierarquia de operadores conforme ilustra a Figura 28. A prioridade segue a
seqüência da menor para a maior a partir do não terminal exp04 até o exp01.
exp04 :
exp03 (( '&'^ | '|'^ | '\^'^) exp03)*;
exp03 :
exp02 (( '<<'^ | '>>'^) VINT)*;
exp02 :
exp01 (( '+'^ | '-'^) exp01)*;
exp01 :
('-' atom) -> ^('-' VOID atom)
|('!' atom) -> ^('!' VOID atom)
|atom;
explist:
atom
exp04 (','exp04)*
-> ^(PARAM exp04)+;
: VINT
| ID
| ID ('['exp04']') -> ^(VETOR ID exp04)
| '('! exp04 ')'!
| ID '('explist')'
-> ^(CALL ID explist)
| ID '('')'
-> ^(CALL ID VOID)
;
Figura 28. Alterações na gramática para suporte a operações lógicas
43
3.2.4.2 Geração de código assembly
Para a geração de código assembly foram utilizadas as instruções de lógica, presentes no
BIP III e BIP IV, apresentadas na Tabela 9 neste Capítulo. A Figura 29 mostra um código em
portugol com várias instruções de lógica e seus respectivos códigos em assembly gerados pela
ferramenta.
Portugol
Assembly
procedimento principal()
declaracoes
inteiro a, b, x
inicio
x <- a | 1;
x <- a & b;
x <- a ^ b;
x <- a << 2;
x <- a >> 3;
x <- ~a;
fim
.data
a : 0
b : 0
x : 0
.text
_PRINCIPAL:
LD
a
ORI
1
STO
x
LD
a
AND
b
STO
x
LD
a
XOR
b
STO
x
LD
a
SLL
2
STO
x
LD
a
SRL
3
STO
x
LD
a
NOT
0
STO
x
HLT
0
Figura 29. Geração de código para operações de lógica
Durante o desenvolvimento, observou-se que a abordagem utilizada até então para a geração
de código,
não permitiria o tratamento de precedência de operadores, uma vez que não era
necessária. Neste caso, a geração de código para expressões, foi feita através de uma AST (Abstract
Syntax Tree), gerada pelo ANTLR. Esta árvore então é processada e seu respectivo código assembly
é gerado. Na Figura 28 é possível observar o símbolo „^‟ que é responsável por criar um novo nó na
árvore, e o símbolo „->‟ responsável por permitir a modificação da geração da árvore.
Na Figura 30 é possível observar os processos realizados para geração de código assembly
de expressões. A primeira coluna representa a instrução em portugol. A segunda coluna representa a
árvore, em formato texto, onde o primeiro símbolo dentro de um parêntese representa um nó e os
restantes representam folhas ou outros nós. A terceira coluna, por sua vez, representa um código
44
intermediário gerada para facilitar a geração do código assembly apresentado na quarta coluna. O
símbolo „#‟ foi utilizado, em conjunto com um controle interno do uso do acumulador, para
identificar operandos que estão em posições temporárias de memória ou no acumulador.
Observe que no código assembly na Figura 30 é utilizado endereço de memória 1000 para
que a operação de subtração seja executada na seqüência correta uma vez que a operação de
negação foi executada anteriormente.
Portugol
a<-2-!3
Árvore (em formato
texto)
(- 2 (! VOID 3))
Instruções intermediárias
para geração de código
Assembly
LDI
NOT
STO
LDI
SUB
STO
HLT
! VOID 3
- 2
#
3
0
1000
2
1000
a
0
Figura 30. Tratamento de precedência de operadores
3.2.4.3 Mudanças no Simulador
As mudanças no simulador foram baseadas na interpretação das instruções e apenas uma
animação nova para a instrução NOT que não possui operando agindo no valor contido no
acumulador. Para o restante das instruções, foram reaproveitadas as animações utilizadas nas
instruções de aritmética. O componente que ilustra a unidade de aritmética, utilizada nos
processadores BIP I e BIP II, foi mantido inalterado, uma vez que também pode ser utilizada para
representar uma unidade de aritmética e lógica.
3.2.5 Componentes da Organização dos Processadores na Simulação
Assim como no BIP I e BIP II, a comutação da organização dos processadores é baseada em
ocultar ou exibir componentes presentes em cada processador. Na Figura 30 é possível observar a
interface onde é exibida a organização do processador exibindo os componentes do BIP IV onde os
itens numerados representam respectivamente: (i) pilha de suporte a procedimentos; (ii) unidade de
manipulação de vetores; (iii) bloco de registradores de E/S; e (iv) componente responsável por
definir se o acesso será a memória ou aos registradores de E/S.
45
Figura 31. Componentes da Organização do processador no Simulador
Lembrando que no simulador, como já explicado na seção anterior, não há alteração da
ilustração do componente „ULA‟. Por isso, na ilustração da organização, não há diferenças entre o
BIP II e BIP III.
3.2.6 Módulo de Ajuda
O módulo de ajuda presente na ferramenta foi atualizado a fim de comportar as novas
definições referentes à linguagem portugol, arquitetura e organização dos novos processadores
suportados.
3.2.7 Testes
Na fase de projeto, foi cogitado o uso de instruções (testbench) disponibilizadas na página
do Dalton Project (THE DALTON PROJECT TEAM, 2001). Porém observou-se que muitas destas
instruções eram baseadas em cálculos com ponto flutuante, não sendo possível representá-las em
portugol, e fazem mais sentido para testes diretamente em código assembly. Por isso optou-se pela
criação de programas testes escritos em portugol disponíveis no Apêndice D . Também foram feitos
testes unitários baseados em conjuntos de instruções assembly adaptados de Pereira (2008) que
46
estão disponíveis no Apêndice C . Em ambos os testes, os resultados foram analisados e
comparados com os esperados.
A Figura 32 apresenta um programa escrito em portugol utilizado no teste com seu
respectivo código assembly. Este programa foi utilizado para validar uma instrução de chamada de
sub-rotina.
Portugol
Assembly
inteiro multiplica(inteiro a, inteiro c)
declaracoes
inteiro i, result
inicio
result <- 0
para i <- 1 ate c passo 1
result<-result+a
fimpara
retornar result
fim
procedimento principal()
declaracoes
inteiro j,k
inicio
k<-3
j<-2
k<-multiplica(k,j)
escreva(k)
fim
47
.data
multiplica_i : 0
multiplica_result : 0
multiplica_a : 0
multiplica_c : 0
j : 0
k : 0
.text
JMP
_PRINCIPAL
_MULTIPLICA:
LDI
0
STO
MULTIPLICA_result
LDI
1
STO
MULTIPLICA_i
LD
MULTIPLICA_c
STO
1000
LDI
1
STO
1001
LD
MULTIPLICA_i
PARA1:
SUB
1000
BGT
FIMPARA1
LD
MULTIPLICA_result
ADD
MULTIPLICA_a
STO
MULTIPLICA_result
LD
MULTIPLICA_i
ADD
1001
STO
MULTIPLICA_i
JMP
PARA1
FIMPARA1:
LD
MULTIPLICA_result
RETURN 0
_PRINCIPAL:
LDI
3
STO
k
LDI
2
STO
j
LD
k
STO
MULTIPLICA_a
LD
j
STO
MULTIPLICA_c
CALL
_MULTIPLICA
STO
k
LD
k
STO
$out_port
HLT
0
Figura 32. Programa utilizado para validar uma instrução de chamada de sub-rotina
Os resultados obtidos durante os testes foram consistentes e corresponderam aos resultados
esperados. Os testes também serviram como processo de refinamento onde pequenos erros foram
detectados e corrigidos. Vale salientar que, assim como em Vieira (2009), os códigos assembly
resultantes do processo de compilação não passam por nenhum processo de otimização.
48
4 CONCLUSÕES
Neste trabalho foi apresentado o projeto do processador BIP IV, bem como a implementação
de seu suporte na IDE Bipide. Com isso, amplia-se as possibilidades de utilização dos
processadores BIP, promovendo maior interação do aluno com a ferramenta e permitindo sua
aplicação em problemas mais complexos.
Ressalta-se que todos os objetivos definidos para este trabalho foram alcançados, conforme
pôde ser observado no decorrer deste documento e são resgatados e discutidos a seguir.
A pesquisa bibliográfica realizada, permitiu compreender conceitos de Arquitetura e
Organização de Computadores aplicados nos processadores da família BIP, além de tecnologias
utilizadas no desenvolvimento da ferramenta Bipide. Também foram estudadas características de
simuladores similares à ferramenta Bipide, que serviram para definir aspectos relacionados à
interface de entrada e saída.
A especificação da arquitetura e organização do processador BIP IV, um novo integrante da
família de processadores BIP, foi produzida neste trabalho. Este processador possui funcionalidades
intermediárias aos processadores BIP III e µBIP, suportando entrada e saída, manipulação de
vetores, operações de lógica bit a bit e sub-rotinas.
A ferramenta Bipide foi alterada de modo a permitir entrada e saída de dados, suportada
pelo processador BIP IV. Estas alterações resultaram em mudanças na gramática do portugol e no
compilador e também no simulador, onde uma interface foi desenvolvida para este fim.
Mudanças na especificação da linguagem portugol foram necessárias para atender o suporte
a sub-rotinas, assim como alterações no compilador e simulador da ferramenta Bipide. Estas
mudanças suportam o uso de funções e procedimentos permitindo a confecção de códigos mais
modulares. A avaliação foi conduzida por meio de testes com problemas pré-definidos. Estes
também serviram como processo de refinamento onde pequenos erros foram detectados e
corrigidos.
Vale salientar que, além de entrada e saída e suporte de sub-rotinas, principais motivações
deste projeto, foram implementados na ferramenta Bipide, suporte a vetores e operações de lógica
49
bit a bit que não estavam originalmente previstos. Estas funcionalidades permitem maior
abrangência da utilização da ferramenta, aumentando seu potencial didático.
Destaca-se que foram encontradas dificuldades relacionadas à ferramenta ANTLR que não
eram previstas, no tratamento de precedência de operadores, mas estas foram contornadas e
explicadas neste documento.
Entende-se que a relevância deste projeto está nos resultados obtidos, disponibilizando
recursos na ferramenta Bipide, permitindo maior interação dos alunos com a ferramenta, redução
da abstração de novas funcionalidades, além de seu uso em problemas mais complexos. Além
disso, permitiu continuidade à pesquisa relacionada à abordagem didática interdisciplinar.
4.1 TRABALHOS FUTUROS
Durante o desenvolvimento deste trabalho foram identificadas oportunidades de trabalhos
co-relacionados e que podem dar continuidade a este projeto. Sendo:
Avaliar a utilização da ferramenta junto aos alunos em sala de aula;
Implementar suporte a diferentes linguagens de alto nível;
Possibilitar o uso de ponteiros e passagem de parâmetro por referência em sub-rotinas; e
Otimizar o código Assembly gerado.
50
REFERÊNCIAS BIBLIOGRÁFICAS
ANTLR. ANTLR v3. [S.l.], 2007. Disponível em: < http://www.antlr.org/>. Acesso em: 28 set.
2010.
BORGES, José Antonio. S.; SILVA, Gabriel P. NeanderWin – um simulador didático para uma
arquitetura do tipo Acumulador. In: WORKSHOP SOBRE EDUCAÇÃO EM ARQUITETURA DE
COMPUTADORES, 1., 2006, Ouro Preto. Proceedings… Porto Alegre: SBC, 2006. Disponível
em <http://www.ppgee.pucminas.br/weac/2006/PDF/WEAC-2006-Artigo-05.pdf>. Acesso em: 10
set. 2010.
BRORSSON, Mats. MipsIt: A Simulation and Development Environment Using Animation for
Computer Architecture Education. In: WORKSHOP ON COMPUTER ARCHITECTURE
EDUCATION, 2002, Anchorage, Alaska. Proceedings… New York, NY: Acm, 2002. Disponível
em: <http://portal.acm.org/citation.cfm?id=1275462.1275479>. Acesso em: 15 set. 2010.
GNUSim8085. GNUSim8085. [S.l.], 2003. Disponível em: http://gnusim8085.org/downloads.php>.
Acesso em: 28 set. 2010.
LISTER, Raymond et al. A multi-national study of reading and tracing skills in novice
programmers. ACM SIGCSE Bulletin, USA, v. 36, n. 4, p. 119-150, dez. 2004.
LISTER, Raymond et al. Research perspectives on the objects-early debate. ACM SIGCSE
Bulletin, USA, v. 38, n. 4, p. 146-165, dez. 2006.
MANZANO, Jose Augusto N. G; OLIVEIRA, Jayr Figueiredo de. Algoritmos: lógica para
desenvolvimento de programação de computadores. 17. ed. São Paulo, SP: Érica, 2005. 236 p. :
ISBN 857194718X
McCRACKEN, Michael et al. A Multi-National, Multi- Institutional Study of Assessment of
Programming Skills of First-year CS Students. SIGCSE Bulletin, USA, n. 33, v. 4, p. 125-140,
2001.
MICROSOFT CORPORATION. Microsoft Expression Blend 2: perguntas freqüentes. [S.l.],
2008a. Disponível em:
<http://www.microsoft.com/brasil/msdn/expression/products/FAQ.aspx?key=blend>. Acesso em:
28 set 2010.
______. Microsoft Visual Studio. [S.l.], 2009b. Disponível em:
<http://www.microsoft.com/visualstudio/en-us/default.mspx>. Acesso em: 28 set. 2010.
______. Recursos do Microsoft Expression Blend 2. [S.l.], 2008b.
Disponível em:
<http://www.microsoft.com/brasil/msdn/expression/features/Default.aspx?key=blend>. Acesso em:
28 set 2010.
MORANDI, Diana et al. Um processador básico para o ensino de conceitos de arquitetura e
organização de computadores. Hífen, Uruguaiana, v. 30, p. 73-80, 2006.
MORANDI, Diana; RAABE, André Luis Alice; ZEFERINO, Cesar Albenes. Processadores para
Ensino de Conceitos Básicos de Arquitetura de Computadores. In: WORKSHOP DE EDUCAÇÃO
EM ARQUITETURA DE COMPUTADORES, 1., 2006, Ouro Preto. Proceedings of the 18th
International Symposium on Computer Architecture and High Performance Computing Workshops. Porto Alegre: SBC, 2006. p. 17-24.
PARR, Terence. ANTLRWorks: The ANTLR GUI Development Environment. 2009 Disponível
em:<http://www.antlr.org/works/index.html>. Acesso em: 28 set. 2010.
PEREIRA, Maicon Carlos ; ZEFERINO, Cesar Albenes . uBIP: a simplified microcontroller
architecture for education in embedded systems design. In: IP BASED ELECTRONIC SYSTEM
CONFERENCE & EXHIBITION - IP 08, 2008, Grenoble. Proceedings.... Grenoble : Design and
Reuse, 2008. p. 193-197.
PEREIRA, Maicon Carlos. uBIP: microcontrolador básico para o ensino de sistemas embarcados.
2008. Trabalho de Conclusão de Curso. (Graduação em Ciência da Computação) - Universidade do
Vale do Itajaí.
SCOTT, Mike. WinMIPS64. [S.l.], 2010. Disponível em:
<http://www.computing.dcu.ie/~mike/winmips64.html>. Acesso em: 28 set. 2010.
SONNINO, Bruno; SONNINO, Roberto. Introdução ao WPF. 2006 Disponível em:
<http://msdn.microsoft.com/pt-br/library/cc564903.aspx>. Acesso em: 28 set 2010.
THE DALTON PROJECT TEAM. The UCR Dalton Project. University of California – Riverside,
2001. Disponível em: < http://www.cs.ucr.edu/~dalton/ >. Acesso em: 20 set 2010.
VIEIRA, Paulo Viniccius; RAABE, André Luís Alice; ZEFERINO, Cesar Albenes. Bipide –
ambiente de desenvolvimento integrado para a arquitetura dos processadores BIP.Revista Brasileira
de Informática na Educação, Vol. 18, No 1 (2010)
VIEIRA, Paulo Viníccius ; RAABE, André Luis Alice ; ZEFERINO, Cesar Albenes. Bipide –
ambiente de desenvolvimento integrado para a arquitetura dos processadores BIP. Trabalho de
Conclusão de Curso – Faculdade de Ciência da Computação, Universidade do Vale do Itajaí, Itajaí,
2009.
ZEFERINO, Cesar A. Especificação da Arquitetura e da Organização do Processador BIP.
Itajaí, 2007. (Relatório Técnico).
ZEFERINO, Cesar Albenes et al. Um Enfoque Interdisciplinar no Ensino de Arquitetura de
Computadores. In: Arquitetura de Computadores: educação, ensino e aprendizado. Martins, C;
Navaux P.; Azevedo, R.; Kofuji, S. (Org.). No Prelo, 2010.
ZIILER, Roberto M. ABACUS. [S.l.], 1999. Disponível em:
<http://www2.ufersa.edu.br/portal/view/uploads/setores/147/arquivos/MM/AbacusSetup.zip>.
Acesso em: 28 set. 2010.
ZIVIANI, Nivio. Projeto de algoritmos: com implementações em Java e C++. São Paulo, SP:
Thomson, 2007. 621 p. ISBN 8522105251
52
APÊNDICES
A GRAMÀTICA PORTUGOL
grammar portugol;
options {
language= 'CSharp2';
backtrack = true;
memoize=true;
output = AST;
}
tokens
{
CALL = 'CALL';
VETOR = 'VETOR';
VOID
= 'VOID';
PARAM
=' PARAM';
}
@namespace {Bipide}
@header {
using Bipide;
/*using Classes;*/
}
@members{
int x;
int nomevar;
}
@rulecatch {
catch (RecognitionException e) {
throw e;
}
}
PROGRAMA:
'programa' | 'PROGRAMA';
DECLARACOES:
'declaracoes' | 'DECLARACOES';
DEFINA:
'defina' | 'DEFINA';
INICIO:
'inicio' | 'INICIO';
FIM:
'fim' | 'FIM';
INTEIRO:
'inteiro'| 'INTEIRO';
SE:
'se'| 'SE';
ENTAO:
'entao'| 'ENTAO';
SENAO:
'senao'| 'SENAO';
FIMSE:
'fimse'| 'FIMSE';
ENQUANTO:
'enquanto'| 'ENQUANTO';
FACA:
'faca'| 'FACA';
FIMENQUANTO:
'fimenquanto' | 'FIMENQUANTO';
REPITA:
'repita' | 'REPITA';
QUANDO
:
'quando' |'QUANDO';
PARA:
'para' | 'PARA';
ATE:
'ate' | 'ATE';
PASSO:
'passo' | 'PASSO';
FIMPARA:
'fimpara' | 'FIMPARA';
LEIA:
'leia' | 'LEIA';
ESCREVA:
'escreva' | 'ESCREVA';
PROCEDIMENTO:
'procedimento' | 'PROCEDIMENTO';
RETORNAR:
'retornar' | 'RETORNAR';
/*ID : ('a'..'z' ('a'..'z'|'A'..'Z'|'_' )* );*/
ID : (('a'..'z' | 'A'..'Z')
('a'..'z'|'A'..'Z'| '0'..'9' | '_' )*
VINT : '0'..'9' + ;
//NEWLINE:'\r' ? '\n' ;
WS : (' ' |'\t' |'\n' |'\r' )+ {$channel=HIDDEN;} ;
COMENTARIO:
'/*' .* '*/' {$channel=HIDDEN;};
COMENTARIOLINHA:'//' ~('\n'|'\r')* '\r'? '\n' {$channel=HIDDEN;};
programa
:
escopo+;
escopo
: (PROCEDIMENTO | INTEIRO) ID
dec
INICIO
lista_cmdo
FIM
;
dec
: DECLARACOES lista_decl
| /* vazio */
;
lista_decl
: decl+;
decl
: dec_const
| dec_var
;
dec_const
: DEFINA ID VINT ;
dec_var
: INTEIRO
lista_dec_var
lista_var
lista_var ;
: dec_var+;
: ID
(','ID)* ;
lista_cmdo
: cmdo+
;
cmdo
:
|
|
|
|
|
|
|
|
|
;
cmd_se
cmd_se_senao
cmd_enq_faca
cmd_faca
cmd_para
cmd_leia
cmd_escreva
atribuicao
cmd_call
cmd_return
55
lista_param
);
//parametros da declaracao
parametro : INTEIRO ID;
parametros
: '(' parametro (',' parametro )* ')';
lista_param : '('')' | parametros;
//parâmetros da chamada
parametro_chamada :
exp ;
parametros_chamada :
lista_param_chamada:
'(' parametro_chamada (',' parametro_chamada )* ')';
'('')' |
parametros_chamada;
cmd_call: ID lista_param_chamada ;
cmd_return :
cmd_se
RETORNAR
(exp)?;
: SE
expRelacional
ENTAO
lista_cmdo
FIMSE ;
cmd_se_senao
: SE
ENTAO
lista_cmdo
SENAO
lista_cmdo
FIMSE
;
cmd_enq_faca
:ENQUANTO
expRelacional
FACA
lista_cmdo
FIMENQUANTO
;
cmd_faca
:REPITA
cmdo+
QUANDO
expRelacional
;
cmd_para
:PARA
id '<-' exp1=exp
ATE exp2=exp
PASSO valneg
lista_cmdo
FIMPARA
;
valneg
:
'-'? VINT;
56
cmd_leia
: LEIA '(' lista_id ')';
cmd_escreva : ESCREVA '(' lista_saida ')';
atribuicao
lista_id
: id ('['exp']')?
' <-' exp ;
: id ('['exp']')?
(',' id ('['exp']')?)*;
lista_saida : exp (',' exp )*;
expRelacional
:
'(' exp (('>'
;
exp
:
;
| '<' | '>=' | '<=' | '=' | '!=' ) exp) ')'
exp04 {this.expressao((CommonTree)$exp04.tree);}
exp04 :
exp03 (( '&'^ | '|'^ | '\^'^) exp03)*
;
exp03 :
exp02 (( '<<'^ | '>>'^) VINT)*
;
exp02 :
exp01 (( '+'^ | '-'^) exp01)*
;
exp01
:
('-' atom) -> ^('-' VOID atom)
|('!' atom) -> ^('!' VOID atom)
|atom
;
explist:
exp04 (','exp04)*
;
atom :
-> ^(PARAM exp04)+
VINT
| ID
| ID ('['exp04']') -> ^(VETOR ID exp04)
| '('! exp04 ')'!
| ID '('explist')' -> ^(CALL ID explist)
| ID '('')'
-> ^(CALL ID VOID)
;
id
: ID ;
57
B CONJUNTO DE INSTRUÇÕES DO BIP IV
Este apêndice apresenta uma descrição mais detalhada do conjunto de instrução do BIP IV.
Este conjunto de instruções é baseado no conjunto de instruções do µBIP, tendo como diferença a
ausência da instrução RETINT, utilizada para suporte a interrupções. As subseções, o conjunto de
instruções de cada classe de instrução.
B.1 CLASSE: CONTROLE
Halts
HLT
Sintaxe:
HLT
Descrição:
Desabilita a atualização do PC
Opcode:
00000
Status:
Nenhum bit afetado
PC:
Não é atualizado
Operação:
Nenhuma operação é realizada
Exemplo:
HLT
Antes da instrução:
PC = 0x0100
Após a instrução:
PC = 0x0100
B.2 CLASSE: ARMAZENAMENTO
Store
STO
Sintaxe:
STO
operand
Descrição:
Armazena o conteúdo do ACC em uma posição da memória
indicada pelo operand.
Opcode:
00001
Status:
Nenhum bit afetado
PC:
PC PC + 1
Operação:
Memory[operand] ACC
Exemplo:
STO 0x0002
Antes da instrução:
ACC = 0x0005
MEM[2] = 0x0000
Após a instrução:
ACC = 0x0005
MEM[2] = 0x0005
58
B.3 CLASSE: CARGA
Load
LD
Sintaxe:
LD
operand
Descrição:
Carrega um valor armazenado em uma posição de memória
indicado pelo operand para o registrador ACC .
Opcode:
00010
Status:
Nenhum bit afetado
PC:
PC PC + 1
Operação:
ACC Memory[operand]
Exemplo:
LD 0x0002
Antes da instrução:
ACC = 0x0000
MEM[2] = 0x0005
Após a instrução:
ACC = 0x0005
MEM[2] = 0x0005
LDI
Load Immediate
Sintaxe:
LDI
Descrição:
Carrega o valor de um operando imediato para o registrador ACC
Opcode:
00011
Status:
Nenhum bit afetado
PC:
PC PC + 1
Operação:
ACC operand
Exemplo:
LDI 0x0005
operand
Antes da instrução:
ACC = 0x0000
Após a instrução:
ACC = 0x0005
59
B.4 CLASSE: ARITMÉTICA
ADD
Sintaxe:
ADD
operand
Descrição:
O valor do registrador ACC é somado com o valor armazenado na
posição de memória indicado pelo campo operand e o resultado
armazenado no ACC .
Opcode:
00100
Status:
Z, N e C são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC + Memory[operand]
Exemplo:
ADD 0x0002
Antes da instrução:
ACC = 0x0004
MEM[2] = 0x0003
Após a instrução:
ACC = 0x0007
MEM[2] = 0x0003
ADDI
Add Immediate
Sintaxe:
ADDI
Descrição:
O valor do registrador ACC é somado com o valor operando
operand
imediato e o resultado armazenado no ACC .
Opcode:
00101
Status:
Z, N e C são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC + operand
Exemplo:
ADDI 0x0002
Antes da instrução:
ACC = 0x0004
Após a instrução:
ACC = 0x0006
60
SUB
Subtract
Sintaxe:
SUB
Descrição:
O valor do registrador ACC é subtraído pelo valor armazenado na
operand
posição de memória indicado pelo campo operand e o resultado
armazenado no ACC .
Opcode:
00110
Status:
Z, N e C são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC - Memory[operand]
Exemplo:
SUB 0x0002
Antes da instrução:
ACC = 0x0004
MEM[2] = 0x0003
Após a instrução:
ACC = 0x0001
MEM[2] = 0x0003
SUBI
Subtract Immediate
Sintaxe:
SUBI
Descrição:
O valor do registrador ACC é subtraído pelo valor do operando
operand
imediato e o resultado armazenado no ACC .
Opcode:
00110
Status:
Z, N e C são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC - operand
Exemplo:
SUBI 0x0002
Antes da instrução:
ACC = 0x0004
Após a instrução:
ACC = 0x0002
61
B.5 CLASSE: LÓGICA BOOLEANA
NOT
Sintaxe:
NOT
Descrição:
Aplica o operador de “negação” lógico ao valor armazenado no
ACC e armazena o resultado no ACC.
Opcode:
01111
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC NOT (ACC)
Exemplo:
NOT
Antes da instrução:
ACC = 0x000F
Após a instrução:
ACC = 0xFFF0
AND
Sintaxe:
AND
operand
Descrição:
Aplica o operador “E” lógico entre o valor do registrador ACC e o
valor armazenado na posição de memória indicado pelo
operand. O resultado é armazenado no ACC .
Opcode:
10000
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC AND Memory[operand]
Exemplo:
AND 0x0002
Antes da instrução:
ACC = 0x00C4
MEM[2] = 0x0007
Após a instrução:
ACC = 0x0004
MEM[2] = 0x0007
62
ANDI
And Immediate
Sintaxe:
ANDI
Descrição:
Aplica o operador “E” lógico entre o valor do registrador ACC e o
operand
valor do operando imediato. O resultado é armazenado no ACC .
Opcode:
10001
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC AND operand
Exemplo:
ANDI 0x0003
Antes da instrução:
ACC = 0x00C5
Após a instrução:
ACC = 0x0001
OR
Sintaxe:
OR
operand
Descrição:
Aplica o operador “OU” lógico entre o valor do registrador ACC
e o valor armazenado na posição de memória indicado pelo
operand. O resultado é armazenado no ACC .
Opcode:
10010
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC OR Memory[operand]
Exemplo:
OR 0x0002
Antes da instrução:
ACC = 0x0004
MEM[2] = 0x00C0
Após a instrução:
ACC = 0x00C4
MEM[2] = 0x00C0
63
ORI
Or Immediate
Sintaxe:
ORI
Descrição:
Aplica o operador “OU” lógico entre o valor do registrador ACC
operand
e o valor do operando imediato. O resultado é armazenado no
ACC .
Opcode:
10011
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC OR operand
Exemplo:
ORI 0x0002
Antes da instrução:
ACC = 0x0004
Após a instrução:
ACC = 0x0006
XOR
Sintaxe:
XOR
operand
Descrição:
Aplica o operador “OU” lógico exclusivo entre o valor do
registrador ACC e o valor armazenado na posição de memória
indicado pelo operand. O resultado é armazenado no ACC .
Opcode:
10100
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC XOR Memory[operand]
Exemplo:
XOR 0x0002
Antes da instrução:
ACC = 0x0006
MEM[2] = 0x0004
Após a instrução:
ACC = 0x0002
MEM[2] = 0x0004
64
XORI
Xor Immediate
Sintaxe:
XORI
Descrição:
Aplica o operador “OU” lógico exclusivo entre o valor do
operand
registrador ACC e o valor do operando imediato. O resultado é
armazenado no ACC .
Opcode:
10101
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC XOR operand
Exemplo:
XORI 0x0002
Antes da instrução:
ACC = 0x0006
Após a instrução:
ACC = 0x0004
B.6 CLASSE: DESVIO
Branch Equal
BEQ
Sintaxe:
BEQ
operand
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
resultado da operação anterior na ULA foi zero.
Opcode:
01000
Status:
Nenhum bit é afetado
PC:
Se (STATUS.Z=1) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BEQ
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0005
STATUS.Z = 1
STATUS.N = 0
PC = 0x0002
65
BNE
Branch Non-Equal
Sintaxe:
BNE
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
operand
resultado da operação anterior na ULA tenha sido diferente zero.
Opcode:
01001
Status:
Nenhum bit é afetado
PC:
Se (STATUS.Z=0) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BNE
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0006
STATUS.Z = 0
STATUS.N = 1
PC = 0x0002
BGT
Branch Greater Than
Sintaxe:
BGT
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
operand
resultado da operação anterior na ULA tenha sido maior que zero.
Opcode:
01010
Status:
Nenhum bit é afetado
PC:
Se (STATUS.Z=0) e (STATUS.N=0) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BGT
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0004
STATUS.Z = 0
STATUS.N = 0
PC = 0x0002
66
BGE
Branch Greater Equal
Sintaxe:
BGE
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
operand
resultado da operação anterior na ULA tenha sido maior ou igual
zero.
Opcode:
01011
Status:
Nenhum bit é afetado
PC:
Se (STATUS.N=0) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BGE
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0005
STATUS.Z = 1
STATUS.N = 0
PC = 0x0002
BLT
Branch Less Than
Sintaxe:
BLT
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
operand
resultado da operação anterior na ULA tenha sido menor que zero.
Opcode:
01100
Status:
Nenhum bit é afetado
PC:
Se (STATUS.N=1) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BLT
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0006
STATUS.Z = 0
STATUS.N = 1
PC = 0x0002
67
BLE
Branch Greater Equal
Sintaxe:
BLE
Descrição:
Atualiza o valor do PC com o valor do campo operand caso o
operand
resultado da operação anterior na ULA tenha sido menor ou igual
a zero.
Opcode:
01101
Status:
Nenhum bit é afetado
PC:
Se (STATUS.N=1) ou (STATUS.Z=1) então
PC endereço
Se não
PC PC + 1
Operação:
Nenhuma Operação Realizada
Exemplo:
LDI
0x0005
SUB
0x0008
BLE
0x0002
Antes da instrução:
Após a instrução:
PC = 0x000A
MEM[8] = 0x0006
STATUS.Z = 0
STATUS.N = 1
PC = 0x0002
JMP
Jump
Sintaxe:
JMP
Descrição:
Atualiza o valor do PC com o valor do campo operand, ou
operand
seja, realiza um desvio incondicional.
Opcode:
01110
Status:
Nenhum bit é afetado
PC:
PC endereço
Operação:
Nenhuma Operação Realizada
Exemplo:
JMP 0x0002
Antes da instrução:
PC = 0x000A
Após a instrução:
PC = 0x0002
68
B.7 CLASSE: DESLOCAMENTO LÓGICO
Shift Left Logical
SLL
Sintaxe:
SLL
operand
Descrição:
Realiza o deslocamento lógico à esquerda no número de bits
informado pelo operand sobre o registrador ACC.
Opcode:
10110
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC << operand
Exemplo:
SLL
0x0002
Antes da instrução:
ACC = 0x0001
Após a instrução:
ACC = 0x0004
SRL
Shift Right Logical
Sintaxe:
SRL
Descrição:
Realiza o deslocamento lógico à direita no número de bits
operand
informado pelo operand sobre o registrador ACC.
Opcode:
10111
Status:
Z e N são afetados por esta operação
PC:
PC PC + 1
Operação:
ACC ACC >> operand
Exemplo:
SRL
0x0002
Antes da instrução:
ACC = 0x0004
Após a instrução:
ACC = 0x0001
69
B.8 CLASSE: MANIPULAÇÃO DE VETOR
Load Vector
LDV
Sintaxe:
LDV
operand
Descrição:
Carrega o valor armazenado no endereço dado por (operand +
INDR) para o registrador ACC.
Opcode:
11000
Status:
Não afetados por esta operação
PC:
PC PC + 1
Operação:
ACC Memory[Operand + INDR]
Exemplo:
LDI
0x0001
STO
$indr
LDV
$0
Antes da instrução:
ACC = 0x0000
MEM[0]=0x0004
MEM[1]=0x0007
Após a instrução:
ACC = 0x0007
MEM[0]=0x0004
MEM[1]=0x0007
STOV
Store Vector
Sintaxe:
STOV operand
Descrição:
Armazena o valor do registrador ACC, no endereço dado por
(operand + INDR).
Opcode:
11001
Status:
Não afetados por esta operação
PC:
PC PC + 1
Operação:
Memory[operand + INDR] = ACC
Exemplo:
LDI
0x0001
STO
$indr
LDI
0x0003
LDV
$0
Antes da instrução:
ACC = 0x0000
MEM[0]=0x0004
MEM[1]=0x0007
Após a instrução:
ACC = 0x0007
MEM[1]=0x0003
70
MEM[0]=0x0004
B.9 CLASSE: SUPORTE A PROCEDIMENTOS
CALL
Sintaxe:
CALL
operand
Descrição:
Realiza uma chamada de procedimento para o endereço de
memória de instrução indicado pelo campo operand. Antes da
chamada, o endereço de retorno (PC + 1) é armazenado na pilha
(ToS).
Opcode:
11100
Status:
Não afetados por esta operação
PC:
ToS PC+1
PC operand
Operação:
Nenhuma operação realizada
Exemplo:
CALL 0x00F0
Antes da instrução:
PC = 0x00D3
ToS = 0xXXXX
Após a instrução:
PC = 0x00F0
ToS = 0x00D4
RETURN
Return
Sintaxe:
RETURN
Descrição:
Retorna da sub-rotina, recuperando o valor do PC armazenado na
pilha (ToS). O procedimento chamado deve usar o ACC para
retornar um valor ao procedimento chamador.
Opcode:
11010
Status:
Não afetados por esta operação
PC:
PC ToS
Operação:
Nenhuma operação realizada
Exemplo:
RETURN
Antes da instrução:PC=0x00F0 ToS=0x00D3
ACC=Valor de Retorno
Após a instrução:
PC=0x00D3 ToS=0xXXXX
ACC=Valor de Retorno
C CONJUNTO DE INSTRUÇÕES PARA TESTE UNITÁRIO
Neste apêndice são apresentados os programas utilizados para a realização de testes da
simulação das instruções dos processadores BIP. A Tabela 11 contém os programas utilizados
nestes testes bem como os resultados apresentados após suas execuções.
Tabela 11. Conjunto de Instruções para teste Unitário
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
add_1.s
ADD
addi_1.s
ADDI
and_1.s
AND
andi_1.s
ANDI
beq_1.s
BEQ
beq_2.s
ldi
sto
ldi
add
0x0002 0x0007 0x0 0x0
ldi 0x00C
sto $15
ldi 0x007
and $15
0x0004 0x0004 0x0 0x0
ldi 0x00C
andi 0x007
ldi 0x004
subi 0x004
beq __end
ldi 0x055
__end:
0x0002 0x0004 0x0 0x0
0x0004 0x0000 0x1 0x0
BEQ
0x0004 0x0055 0x0 0x0
BGE
0x0004 0x0000 0x1 0x0
BGE
ldi 0x005
subi 0x004
bge __end
ldi 0x055
__end:
bge_3.s
N
ldi 0x003
addi 0x004
ldi 0x004
subi 0x004
bge __end
ldi 0x055
__end:
bge_2.s
Z
0x0004 0x0004 0x0 0x0
ldi 0x005
subi 0x004
beq __end
ldi 0x055
__end:
bge_1.s
ACC
0x001
$14
0x003
$14
BGE
0x0004 0x0001 0x0 0x0
ldi 0x004
subi 0x005
bge __end
ldi 0x055
__end:
0x0004 0x0055 0x0 0x1
72
Memória
M[0x000E]=0x0001
M[0x000F]=0x000C
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
bgt_1.s
BGT
0x0004 0x0055 0x0 0x1
BLE
ldi 0x004
subi 0x004
ble __end
ldi 0x055
__end:
ble_2.s
0x0004 0x0000 0x1 0x0
BLE
ldi 0x003
subi 0x004
ble __end
ldi 0x055
__end:
ble_3.s
0x0004 0xFFFF 0x1 0x0
BLE
ldi 0x005
subi 0x004
ble __end
ldi 0x055
__end:
btl_1.s
0x0004 0xFFFF 0x0 0x1
BLT
ldi 0x003
subi 0x004
blt __end
ldi 0x055
__end:
btl_2.s
0x0004 0x0055 0x0 0x0
BGT
ldi 0x004
subi 0x005
bgt __end
ldi 0x055
__end:
ble_1.s
N
0x0004 0x0001 0x0 0x0
ldi 0x003 subi 0x003
bgt __end ldi
0x055__end:
bgt_3.s
Z
BGT
ldi 0x004
subi 0x003
bgt __end
ldi 0x055
__end:
bgt_2.s
ACC
0x0004 0xFFFF 0x0 0x1
BLT
ldi 0x003
subi 0x003
blt __end
ldi 0x055
__end:
0x0004 0x0055 0x0 0x0
73
Memória
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
btl_3.s
0x0004 0x0001 0x0 0x0
BNE
0x0004 0x0055 0x0 0x0
CALL
ldi 0x003
sto $14
ldi 0x002
sto $15
call __sum
addi 0x001
jmp __end
__sum:
ld $14
add $15
return
__end:
htl_1.s
jmp_1.s
ld_1.s
ldi_1.s
not_1.s
Memória
BNE
ldi 0x003
subi 0x003
bne __end
ldi 0x055
__end:
call_1.s
N
0x0004 0x0055 0x0 0x0
ldi 0x004
subi 0x003
bne __end
ldi 0x055
__end:
bne_2.s
Z
BLT
ldi 0x005
subi 0x004
blt __end
ldi 0x055
__end:
bne_1.s
ACC
HTL
JMP
LD
LDI
NOT
0x000A 0x0006 0x0 0x0
ldi 0x004
hlt
ldi 0x055
0x0002 0x0004 0x0 0x0
ldi 0x004
jmp __end
ldi 0x055
__end:
0x0003 0x0004 0x0 0x0
ldi 0x044
sto $15
ldi 0x055
sto $16
ld
$15
ldi 0x055
0x0005 0x0044 0x0 0x0
0x0001 0x0055 0x0 0x0
ldi 0x00F
not
0x0002 0xFFF0 0x0 0x1
74
M[0x000E]=0x0003
M[0x000F]=0x0002
M[0x000F]=0x0044
M[0x0010]=0x0055
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
ldv_1.s
or_1.s
ori_1.s
LDV
OR
ORI
.text
main:
ldi 1
sto $2
sto $0
for:
subi 2
bgt endfor
ld
$0
subi 1
sto $indr
ldv $2
addi 1
sto $1
ld
$0
sto $indr
ld
$1
stov $2
ld
$0
addi 1
sto $0
jmp for
endfor:
ldi 0
sto $0
print:
subi 2
bgt endprint
ld
$0
sto $indr
ldv $2
sto $port0_data
ld
$0
addi 1
sto $0
jmp print
endprint:
hlt
endmain:
ldi 0x008
sto $15
ldi 0x007
or
$15
ldi 0x008
ori 0x007
ACC
Z
N
0x001F 0x0001 0x0 0x0
M[0x0000]=0x0003
M[0x0001]=0x0003
M[0x0002]=0x0001
M[0x0003]=0x0002
M[0x0004]=0x0003
0x0004 0x000F 0x0 0x0
M[0x000F]=0x0000
0x0002 0x000F 0x0 0x0
75
Memória
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
ACC
Z
N
Memória
return_1.s RETURN
ldi 0x003
sto $14
ldi 0x002
sto $15
call __sum
addi 0x001
jmp __end
__sum:
ld $14
add $15
return
addi 0x055
__end:
sll_1.s
0x000B 0x0006 0x0 0x0
M[0x000E]=0x0003
M[0x000F]=0x0002
SLL
0x0003 0x0004 0x0 0x0
ldi 0x004
sll 0x001
srl_1.s
SRL
ldi 0x004
srl 0x001
0x0002 0x0002 0x0 0x0
xori_1.s
XOR
ldi 0x005
xori 0x00A
0x0002 0x000F 0x0 0x0
sto_1.s
STO
ldi 0x055
sto $15
0x0002 0x0055 0x0 0x0
76
M[0x000F]=0x0055
Arquivo Instrução Seqüência de instruções
para o teste
Resultado esperado após a seqüência de
instruções
PC
stov_1.s
sub_1.s
sub_2.s
sub_3.s
STO
SUB
SUB
SUB
.text
main:
ldi 1
sto $2
sto $0
for:
#ld
$0
subi 2
bgt endfor
ld
$0
subi 1
sto $indr
ldv $2
addi 1
sto $1
ld
$0
sto $indr
ld
$1
stov $2
ld
$0
addi 1
sto $0
jmp for
endfor:
hlt
endmain:
ldi 0x00A
sto $15
ldi 0x00A
sub $15
ldi 0x004
sto $15
ldi 0x005
sub $15
ldi 0x004
sto $15
ldi 0x003
sub $15
ACC
Z
N
Memória
0x0013 0x0001 0x0 0x0
M[0000]=0x0003
M[0001]=0x0003
M[0002]=0x0001
M[0003]=0x0002
M[0004]=0x0003
0x0004 0x0000 0x1 0x0
M[0x000F]=0x000A
0x0004 0x0001 0x0 0x0
M[0x000F]=0x0004
0x0004 0xFFFF 0x0 0x1
M[0x000F]=0x000A
subi_1.s
SUBI
ldi 0x002
subi 0x005
0x0002 0xFFFD 0x0 0x1
subi_2.s
SUBI
ldi 0x005
subi 0x002
0x0002 0x0003 0x0 0x0
subi_3.s
SUBI
0x0002 0x0000 0x1 0x0
xor_1.s
XOR
ldi 0x005
subi 0x005
ldi 0x005
sto $15
ldi 0x00A
xor $15
0x0004 0x000F 0x0 0x0
M[0x000F]=0x0005
D PROGRAMAS PORTUGOL UTILIZADOS PARA VALIDAÇÃO
DO COMPILADOR
Para validação do compilador, um conjunto de programas Portugol foram compilados e seus
códigos assembly simulados na ferramenta.
Portugol
procedimento principal()
declaracoes
inteiro x
inicio
x<-1
se (2 = 2) entao
x <- 30
fimse
fim
procedimento principal()
declaracoes
inteiro x
inicio
x<-1
se (2 = 2) entao
x<-30
senao
x<-60
fimse
fim
procedimento principal()
declaracoes
inteiro fat,temp, i, j, num
inicio
num <- 5
fat <- 1
temp<- 0
i <- 0
j <- 0
para i<- 2 ate num passo 1
temp <- fat
para j <- 1 ate i-1 passo 1
fat <- fat + temp
fimpara
fimpara
fim
Código resultante da
Compilação
.data
x : 0
.text
_PRINCIPAL:
LDI
1
STO
x
LDI
2
STO
1000
LDI
2
STO
1001
LD
1000
SUB
1001
BNE
FIMSE1
LDI
30
STO
x
FIMSE1:
HLT
0
.data
x : 0
.text
_PRINCIPAL:
LDI
1
STO
x
LDI
2
STO
1000
LDI
2
STO
1001
LD
1000
SUB
1001
BNE
ELSE1
LDI
30
STO
x
JMP
FIMSE1
ELSE1:
LDI
60
STO
x
FIMSE1:
HLT
0
.data
fat : 0
temp : 0
i : 0
j : 0
num : 0
.text
_PRINCIPAL:
LDI
5
STO
num
LDI
1
STO
fat
LDI
0
STO
temp
LDI
0
STO
i
LDI
0
STO
j
78
Resultado esperado após a
seqüência de instruções
PC ACC Z N
Memória
11
30
1
0
14
30
1
0
42
1
0
0
X->Mem[0] = 30
X->Mem[0] = 30
Fat->Mem[0] = 120
Temp->Mem[1] = 24
i->Mem[2] =
6
j->Mem[3] =
5
num->Mem[4] =
5
procedimento principal()
declaracoes
inteiro x
inteiro y
inicio
y<-0
para x <- 1 ate 5 passo 1
y<- 1 + x
fimpara
fim
procedimento principal()
declaracoes
inteiro a, b, c
inicio
a<-2
b<-3
c <- a+b<<1&4|!1
escreva(c)
fim
LDI
2
STO
i
LD
num
STO
1000
LDI
1
STO
1001
LD
i
PARA1:
SUB
1000
BGT
FIMPARA1
LD
fat
STO
temp
LDI
1
STO
j
LD
i
SUBI
1
STO
1002
LDI
1
STO
1003
LD
j
PARA2:
SUB
1002
BGT
FIMPARA2
LD
fat
ADD
temp
STO
fat
LD
j
ADD
1003
STO
j
JMP
PARA2
FIMPARA2:
LD
i
ADD
1001
STO
i
JMP
PARA1
FIMPARA1:
HLT
0
.data
x : 0
y : 0
.text
_PRINCIPAL:
LDI
0
STO
y
LDI
1
STO
x
LDI
5
STO
1000
LDI
1
STO
1001
LD
x
PARA1:
SUB
1000
BGT
FIMPARA1
LDI
1
ADD
x
STO
y
LD
x
ADD
1001
STO
x
JMP
PARA1
FIMPARA1:
HLT
0
.data
a : 0
b : 0
c : 0
.text
_PRINCIPAL:
LDI
2
STO
a
LDI
3
STO
b
LD
a
ADD
b
79
18
17
1
-2
0
0
0
x->Mem[0] = 6
y->Mem[1] = 6
1
a->Mem[0]
b->Mem[2]
c->Mem[3]
$out_port
= 2
= 3
= -2
= -2
procedimento principal()
declaracoes
inteiro a, b, c
inicio
a<-2
b<-3
c <- (a+b)<<1
escreva(c)
fim
inteiro multiplica(inteiro a,
inteiro c)
declaracoes
inteiro i, result
inicio
result <- 0
para i <- 1 ate c passo 1
result<-result+a
fimpara
retornar result
fim
procedimento principal()
declaracoes
inteiro j,k
inicio
k<-3
j<-2
k<-multiplica(k,j)
escreva(k)
fim
SLL
1
ANDI
4
STO
1000
LDI
1
NOT
0
STO
1001
LD
1000
OR
1001
STO
c
LD
c
STO
$out_port
HLT
0
.data
a : 0
b : 0
c : 0
.text
_PRINCIPAL:
LDI
2
STO
a
LDI
3
10
STO
b
LD
a
ADD
b
SLL
1
STO
c
LD
c
STO
$out_port
HLT
0
.data
multiplica_i : 0
multiplica_result : 0
multiplica_a : 0
multiplica_c : 0
j : 0
k : 0
.text
JMP
_PRINCIPAL
_MULTIPLICA:
LDI
0
STO
MULTIPLICA_result
LDI
1
STO
MULTIPLICA_i
LD
MULTIPLICA_c
STO
1000
LDI
1
STO
1001
LD
MULTIPLICA_i
PARA1:
SUB
1000
BGT
FIMPARA1
LD
MULTIPLICA_result
33
ADD
MULTIPLICA_a
STO
MULTIPLICA_result
LD
MULTIPLICA_i
ADD
1001
STO
MULTIPLICA_i
JMP
PARA1
FIMPARA1:
LD
MULTIPLICA_result
RETURN 0
_PRINCIPAL:
LDI
3
STO
k
LDI
2
STO
j
LD
k
STO
MULTIPLICA_a
LD
j
STO
MULTIPLICA_c
CALL
_MULTIPLICA
STO
k
LD
k
STO
$out_port
HLT
0
80
10
0
0
a->Mem[0]
b->Mem[2]
c->Mem[3]
$out_port
= 2
= 3
= 10
= 10
6
0
0
k->Mem[5] = 6
inteiro multiplica(inteiro a,
inteiro c)
declaracoes
inteiro i, result
inicio
result <- 0
para i <- 1 ate c passo 1
result<-result+a
fimpara
retornar result
fim
inteiro quadrado(inteiro n)
declaracoes
inicio
retornar multiplica(n,n)
fim
procedimento principal()
declaracoes
inteiro j,k
inicio
j<-3
k<-quadrado(j+1)
escreva(k)
fim
procedimento principal()
declaracoes
inteiro atual, anterior,
proximo, saida[10], i
inicio
atual <-1
anterior <- 0
i<-1
saida[0]<-0
enquanto (i < 10) faca
saida[i]<-atual
i<-i+1
proximo <-anterior + atual
anterior <- atual
atual<-proximo
fimenquanto
fim
.data
multiplica_i : 0
multiplica_result : 0
multiplica_a : 0
multiplica_c : 0
quadrado_n : 0
j : 0
k : 0
.text
JMP
_PRINCIPAL
_MULTIPLICA:
LDI
0
STO
MULTIPLICA_result
LDI
1
STO
MULTIPLICA_i
LD
MULTIPLICA_c
STO
1000
LDI
1
STO
1001
LD
MULTIPLICA_i
PARA1:
SUB
1000
BGT
FIMPARA1
LD
MULTIPLICA_result
ADD
MULTIPLICA_a
STO
MULTIPLICA_result 33
LD
MULTIPLICA_i
ADD
1001
STO
MULTIPLICA_i
JMP
PARA1
FIMPARA1:
LD
MULTIPLICA_result
RETURN 0
_QUADRADO:
LD
QUADRADO_n
STO
MULTIPLICA_a
LD
QUADRADO_n
STO
MULTIPLICA_c
CALL
_MULTIPLICA
RETURN 0
_PRINCIPAL:
LDI
3
STO
j
LD
j
ADDI
1
STO
QUADRADO_n
CALL
_QUADRADO
STO
k
LD
k
STO
$out_port
HLT
0
.data
atual : 0
anterior : 0
proximo : 0
saida : 0
i : 0
.text
_PRINCIPAL:
LDI
1
STO
atual
LDI
0
STO
anterior
40
LDI
1
STO
i
LDI
0
STO
1000
LDI
0
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
saida
INI_ENQ1:
LD
i
81
16
0
0
1
0
k->Mem[6] = 16
0
saida[0]->Mem[ 3]= 0
saida[1]->Mem[ 4]= 1
saida[2]->Mem[ 5]= 1
saida[3]->Mem[ 6]= 2
saida[4]->Mem[ 7]= 3
saida[5]->Mem[ 8]= 5
saida[6]->Mem[ 9]= 8
saida[7]->Mem[10]=13
saida[8]->Mem[11]=21
saida[9]->Mem[12]=34
procedimento principal()
declaracoes
inteiro vetor[5], i, j, aux
inicio
vetor[0]<-5
vetor[1]<-3
vetor[2]<-4
vetor[3]<-2
vetor[4]<-1
para i <- 0 ate 4 passo 1
para j <- i+1 ate 4 passo 1
se (vetor[i] > vetor[j])
entao
aux <- vetor[i]
vetor[i] <- vetor[j]
vetor[j] <- aux
fimse
fimpara
fimpara
fim
STO
1000
LDI
10
STO
1001
LD
1000
SUB
1001
BGE
FIMFACA1
LD
i
STO
1000
LD
atual
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
saida
LD
i
ADDI
1
STO
i
LD
anterior
ADD
atual
STO
proximo
LD
atual
STO
anterior
LD
proximo
STO
atual
JMP
INI_ENQ1
FIMFACA1:
HLT
0
.data
vetor : 0
i : 0
j : 0
aux : 0
.text
_PRINCIPAL:
LDI
0
STO
1000
LDI
5
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
vetor
LDI
1
STO
1000
LDI
3
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
vetor
LDI
2
STO
1000
LDI
4
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
vetor
LDI
3
STO
1000
LDI
2
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
vetor
LDI
4
STO
1000
LDI
1
STO
1001
LD
1000
STO
$indr
LD
1001
STOV
vetor
LDI
0
82
100 1
0
0
Vetor[0]->Mem[0]
Vetor[1]->Mem[1]
Vetor[2]->Mem[2]
Vetor[3]->Mem[3]
Vetor[4]->Mem[4]
=
=
=
=
=
1
2
3
4
5
STO
LDI
STO
LDI
STO
LD
PARA1:
SUB
BGT
LD
ADDI
STO
LDI
STO
LDI
STO
LD
PARA2:
SUB
BGT
LD
STO
LDV
STO
LD
STO
LDV
STO
LD
SUB
BLE
LD
STO
LDV
STO
LD
STO
LD
STO
LDV
STO
LD
STO
LD
STOV
LD
STO
LD
STO
LD
STO
LD
STOV
FIMSE1:
LD
ADD
STO
JMP
FIMPARA2:
LD
ADD
STO
JMP
FIMPARA1:
i
4
1000
1
1001
i
1000
FIMPARA1
i
1
j
4
1002
1
1003
j
1002
FIMPARA2
i
$indr
vetor
1004
j
$indr
vetor
1005
1004
1005
FIMSE1
i
$indr
vetor
aux
i
1004
j
$indr
vetor
1005
1004
$indr
1005
vetor
j
1004
aux
1005
1004
$indr
1005
vetor
j
1003
j
PARA2
i
1001
i
PARA1
HLT
83
0