Compiladores e Linguagens de Programação
Profº Carlos E. R. Alves ([email protected])
08/02/2010
Objetivos da Disciplina:
- Capacitar os alunos a construir componentes de compiladores;
- Melhorar o conhecimento dos alunos sobre linguagens de programaçãoe ferramentas de desenvolvimento,
permitindo um melhor uso destes e um aprendizados mais rápido de novas plataformas;
Bibliografia:
- SEBESTA, Robert. Conceitos de Linguagens de Programação. 5ª Edição. Bookman.
- Aho, SETHI, ULLMAN. Compiladores Princípios Técnicas Ferramentas. LTC.
Programa
- Conceitos Fundamentais.
- Definição formal de Linguagem de Programação;
- Caracteristicas de Linguagem de Programação;
- Componentes de Compiladores;
- Análise Léxica.
- Definições de tokens e expressões regulares;
- Autômatos Finitos;
- Conveções Léxicas;
- Implementação;
- Análise Sintática.
- Gramaticas Livres de Contexto (GLC);
- Análise Sintática Descendente;
- Análise Sintática Ascendente;
- Itens de um Programa, Atributos e Vinculações.
- Nomes e outros atributos (tipo, valor, escopo, etc.);
- Formas de vinculação;
- Tabela de Símbulos;
- Organização de dados durante a execução.
- Alocação de dados;
- Passagem de parâmetros para subprogramas;
- Mecanismo de chamada e retorno de subprogramas;
- Análise Semântica
- Análise Semântica orientada pela sintaxe;
- Análise de tipos;
- Outros exemplos;
- Geração de Código.
- formas de código intermediário;
- geração de código intermediário;
- Tópicos Adicionais.
- Linguagens Funcionais;
- Linguagens de Programação Lógicas;
22/02/2010
Introdução
Vamos avaliar várias caracteristicas de linguagens de programação e precisaremos adotar alguns crítérios
para isto.
Exemplos:
Disponibilidade para plataforma escolhida, adequação ao uso pretendido, outros critérios “externos”;
Custos: de aquisição, de treinamento, etc;
Desempenho: gasto de recursos (tempo, memória, etc.) durante a execução dos programas;
Confiabilidade: baixa probabilidade de erros;
Facilidade de escrita (menos “burocracia”, comandos e bibliotecas mais ricos, etc.);
Facilidade de leitura de programas prontos;
Etc.
Definição Formal de Linguagem de Programação
Em geral, as “boas” linguagens de programação têm a sintaxe baseada em uma gramática livre de contexto
(GLC). Em outras palavras, há regras de produção que indicam como construir um programa a partir de partes
menores.
No entretanto, não é prático usar a GLC até o nível dos caracteres. É conveniente dividir o programa nos seus
componentes básicos, “tokens”, e definir a GLC usando os tokens como símbolos terminais.
Exemplo:
𝒊𝒇(𝒙𝟏 >= 𝟑. 𝟓𝒆 − 𝟕) 𝒙𝟏 ∗= 𝟎. 𝟐;
Tokens:
if : palavra reservada if (IFT);
( : abertura de parênteses (ABREPART);
x1 : identificador (IDENT);
>= : operador relacional (OPRELT);
3.5e-7 : literal real (LITREALT);
) : fecha parênteses (FECHAPART);
x1 : identificador (IDENT);
*= : atribuição composta (ATRIBCOMT);
0.2 : literal real (LITREALT);
; : terminador de comando (TERMCOMT);
Obs.: os nomes dos tokens são meramente ilustrativos.
A sequência seria:
IFT ABREPART IDENT OPRELT LITREALT FECHAPART IDENT ATRIBCOMT LITREALT TERMCOMT
A definição dos tokens é feita à parte. O formato de cada token é, em geral, indicado por expressão regular.
Organização de um Copilador
A estrutura a seguir é clássica, mas não é única.
Outros componentes podem aparecer: pré-processador, “likers”, “loaders”, etc.
O analisador Léxico separa e classifica os tokens do programa.
O analisador sintático verifica se a sequencia de tokens está de acordo com a gramática.
Com base no resultado da Análise Sintática, o Analisador Semântico traduz o programa para um formato
intermediário.
A tabela de símbolos guarda informações sobre todos os itens declarados em um programa, como as variáveis.
Vamos nos concentrar no Front End, que é a parte do compilador que lida com a linguagem de alto nível.
A divisão do compilador em um Front End e um Back End (específico para a máquina alvo), ligados atraves de um
único código intermediário, modulariza o projeto do complador e facilita sua adaptação a novas linguagens e
máquinas.
01/03/2010
Análise Léxica
Como visto, na Análise Léxica os tokens são separados e classificados.
Para cada token, alguns atríbuitos são determinados.
- “tipo” do token: a informação que será usada na análise sintática, ou seja, o terminal da GLC.
- lexema: a string que define o token, como obtida do programa fonte.
- valor numérico, no caso de literal numérico.
- “subtipo”, especificando melhor o token, além do necessário para a análise sintática.
Exemplos:
>= :
tipo = OPRELT
lexema = “ >=”
subtipo = MAIORIGUAL
xyz : tipo = IDENT
lexema = “xyz”
3.7e2 : tipo = LITREALT
lexema = “3.7e2”
valor = 370.0
Vamos nos preocupar mais com o “tipo”, que iremos considerar como sendo o próprio token.
A respeito da organização do copilador como um todo, o analisador léxico é frequêntimente implementado
como uma rotina que extrai um token na entrada a cada vez que é chamado.
O analisador sintático em geral é o “centro” do Front-End e chama a rotina de análise léxica cada vez que
requer um terminal da entrada.
Os formatos dos tokens devem ser expressos de maneiras precisa. Para isto usamos expressões regulares,
mas precisamos usar símbolos auxiliares para definir parte dos formatos e deixar os formatos mais simples.
Chamamos estas definições de “definições regulares”.
Ex.:
DIGITODEC
=(0|1|2|3|4|5|6|7|8|9)
Em alfabetos de uso prático, há uma ordem para os símbolos e podemos especificar faixas de
valores.
DIGITODEC
=[0-9]
O simbolo (“ - “) indica a faixa de valores colchetes indicam opção para escolha de um caracter.
LETRA
= [ a-z A-Z ]
DIGITOHEXA = [ 0-9 a-f A-F ]
DIGITOOCTAL = [ 0-7 ]
Com estes símbolos, podemos então definir formatos completos.
Vamos usar, para simplicar, os simbolos l, d, h e o para letras, dígitos decimais, dígitos hexadecimais e digitos
octais, respectivamente.
Vamos usar a notação tracional para expressões regulares.
LITERALINT
= ( 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 ) d* |
0o* |
0xh+ | 0Xh+
Exemplo:
“35”, “043”, “0x23” são lexemas válidos para o token LITERALINT de valor 35.s
IDENT
= ( l | _ )( l | d | _ )*
Para o literal real, vamos decompor o formato em “mantissa” e “expoente”.
MANTISSA
EXPOENTE
LITREALT
= ( d+ | d+ . d* | d* . d+ )
= e|E ( + | - |ε ) d+
= MANTISSA ( EXPOENTE | ε )
É preciso tomar cuidado, evitando o uso recursivo dos simbolos auxiliares. Com recursão, teríamos algo
proximo de uma GLC e a linguagem envolvida poderia não ser regular.
Podemos criar AFD’s para reconhecer estes formatos:
IDENT:
LITREALT:
Exercicio: crie uma e.r. e um AFD para reconhecer valores em reais, a partir da seguinte definição informal:
A string deve começar com R$, seguida de dígitos. O valor em si deve ser expresso como uma quantidade inteira
seguida de centavos (opcionais). A parte inteira deve ter ao menos um dígito. O uso de pontos é opcional, mas deve
ser consistente, separando os digitos em grupos de 3 a partir da direita.
Ex.: R$ d
R$ d,dd
R$ ddddd
R$ d.ddd
R$ d.ddd.ddd,dd
e.r. = R$ ( d+ | ( ( d | dd | ddd ) (. ddd)* ) ) (, dd | ε )
08/03/2010
Continuado: para implementar o analisador léxico podemos “fundir” os AFD’s dos vários tokens em um
único AFD que reconhece todos os tipos de tokens.
É interessante ter estados finais separados para cada tipo de token.
O A. Léxico faz uma simulação deste AFD, lendo símbolos da entrada a cada passo e verificando o estado
final atingido para identificar o token encontrado.
Algumas observações importantes:
- O Analisador Léxico processa a entrada procurando o próximo token, mas haverá mais caracteres após o
tekun encontrado. Ao contrário dos AFD’s clássicos, ele não para no final da entrada. Quando ele para?
Usualmente, ele para quando não é possível prolongar o token que ele está lendo. Esta é a convenção léxica
do lexema mais longo: o analisador léxico sempre etenta extrair o token mais longo possível.
já porcessado o A.L. parte daqui
Ex:
x = 3 +++ z;
este é o token extraído
- Em alguns casos, convm usar algumas “gambiarras”.
Por exemplo, frequêntimente não incluímos as palavras reservadas no AFD ( if, while, etc. )
Uma ideia mais simples é testar todos os identificadores (IDENT) encontrados para ver se são de fato,
palavras reservadas (fazendo comparações simples, por exemplo).
- Quando definimos formatos, podemos fazer simplificações que causam conflitos. Por exemplo, “546” pode
ser literal inteiro ou real. É preciso resolver estes conflitos, o que em geral é feito favorecendo o formato mais
restritivo.
- Parte da entrada não é formada por tokens, devendo ser descartada pelo analisador léxico. Por exemplo,
temos os “brancos” e “comentarios” que exercem influência na separação dos tokens, mas em geral não tokens
(possíveis exceções incluem “pulos de linha” em certas linguagens, por exemplo).
É comum o AFD processar estas partes descartáveis, sem gerar tokens, no entanto.
Exemplo: cometários em Java.
- Outras tarefas podem ser realizadas pelo analisador léxico ou módulos anterioes, incluindo vários tipos de
pré-processamento:
- inclusão de arquivos;
- macro-expansão;
- compilação condicional;
- processamento de gabaritos (templates);
- etc.
15/03/2010
Geradores de Analisadores Léxicos
São programas que geram código fonte para analisadores léxicos a partir de um arquivo de definição,
contendo:
- definições regulares de tokens e simbolos auxiliares;
- codigo especifico a ser aplicado quando certos tokens são encontrados;
- rotinas auxiliares a serem integradas ao Analisador Léxico.
O Analisador Léxico gerado contém uma rotina de extração de tokens e variáveis que caracterizam o último
token encontrado.
Ele pode ser facilmente integrado a outros componentes de um compilador.
Ex. clássico = Lex.
Exercício: decomponha a seguinte string em tokens, como faria o Analisador Léxico de Java:
for 23e-7 a++ = 3ee7.e1
for23e
7
a
++
=
3
ee7
token mais longo da sequencia, token de variavel.
token de sinal.
token de literal.
token de variavel.
token de sinal.
token de sinal.
token de literal.
token de de variavel.
.
e1
token de sinal.
token de variavel.
Exercício 2:
Ifelse+”for 3.2”+/* ? * */ 4.e4
Ifelse
+
“for 3.2”
+
/* ? * */
4.e4
token de variável.
token de sinal.
token de literal string
token de sinal.
comentário.
token de literal real.
Análise Sintática
Nesta fase da compilação, os tokens obtidos pelo Analisador Léxico são tratados como GLC (Gramatica Livre
de Contexto). O Analisador Sintético verifica se a sequência de tokens pode ser gerada pela GLC, obtendo a árvore
de derivação se for o caso.
Muitas linguagens de programação são definidas com uso de GLCs, em geral com variações.
Formas de definição de gramáticas:
Observações: os terminais não são mais simples letras. É preciso usar uma maneira de identificá-los.
No caso de tokens simples, (como operadores e palavras reservadas) é comum os manuais usarem
diretamente o lexema destes tokens. Ex:
if
else
+
++
>>=
Tokens mais complexos recebem nomes especiais, como “ident”. Às vezes são tratados como não-terminal,
para fins de documentação.
Os não-terminais normalmente tem nomes longo e representativos e devem ser destacados nas produções.
Há muitas variações...
Exemplos de notação:
Backus-Naur Form (BNF)
- não-terminais envolvidos em <>.
- produções alternativas separadas por barras verticais (“|”).
Exemplo:
<Expressao> := <Termo> | <Expressao> + <Termo>
<Termo> := <Fator> | <Termo> * <Fator>
<Fator> := literalNumerico | - <Fator> | (<Expressao>)
Seria o equivalente a:
ET
EE+T
TF
TT*F
Fn
F -F
F (E)
Na documentação de Java:
- não terminais em itálico;
- produções alternativas em linhas separadas;
- Indicação de partes opcionais e outras variações.
Exemplo:
Expressao:
Termo
Expressao + Termo
...
Outras variações incluem “loops” e extensões inspiradas em expressões regulares.
Exemplo:
<Expressao> := <Termo> { + <Termo> }
as “{ }” representa 0 ou mais repetições
Também há representações gráficas (diagramas sintáticos).
Uma usada em alguns manuais de Pascal:
Uma variação, usando diagramas semelhantes ao de AFD’s:
(Outro diagrama, INSERIR)
22/03/2010
Analise Sintática Descendente Recursiva
29/03/2010
Análise Sintática Descendente
Vamos ver agora o procedimento “canônico” de ASD.
Este tipo de análise se caracteriza por montar a árvore de derivação de cima (raiz) para baixo (folhas),
simulando o proprio processo de derivação da string.
A string é lida um símbulo por vez, da esqueda para a direita, por questões de eficiência.
Vamos ver um exemplo:
Análise de
01
02
03
04
05
06
07
08
09
10
uxyyu
ABu
ACA
Bx
BEy
Ct
CuD
DCD
DB
Ey
EzA
Derivação
Simulada
A
CA
uDA
uBA
uxA
uxBu
uxEyu
uxyyu
Entrada
(símbolo lido = sublinhado)
Uxyyu
Uxyyu
Uxyyu
Uxyyu
Uxyyu
Uxyyu
Uxyyu
Uxyyu
02
06
08
03
01
04
09
//
1. Que tipo de estrutura de dados é preciso utilizar?
Para manter a string que está sendo gerada na derivação simulada usamos uma pilha. Os terminais mais à
esquerda são logo descartados e as produções são aplicadas no topo da pilha.
2. Como pode melhorar a escolha para ser utilizada?
As produções a serem usadas são escolhidas unicamente com base apenas no não-terminal mais à esquerda
(topo da pilha) e no próximo símbolo da entrada. Para tornar a analise mais rápida, usamos uma tabela para
determinar a regra a ser usada.
Tabela de Análise
t
A
B
C
D
E
u
X
Y
z
02 02 01 01 01
X X 03 04 04
05 06 X X X
07 07 08 08 08
X X X
10
$
X
X
X
X
X
(N, s) = regra a ser usada quando o não-terminal N estivr no topo da pilha e s for o próximo símbolo da entrada.
Exemplo de análise: string t z x u y u.
Pilha (topo
Entrada
à esquerda)
(símbolo lido = sublinhado)
A$
t z x u y u $ 02
CA$
t z x u y u $ 05
tA$
t z x u y u $ tira t
A$
z x u y u $ 01
Bu$
z x u y u $ 04
Eyu$
z x u y u $ 10
zAyu$
z x u y u $ tira z
Ayu$
x u y u $ 01
Buyu$
x u y u $ 03
xuyu$
x u y u $ tira x
uyu$
u y u $ tira u
yu$
y u $ tira y
u$
u $ tira u
$
$ // FIM
A sequência de produções usadas nos dá a derivação mais à esquerda da string.
Árvore de derivação:
Algoritmo de A.S.D.
Entradas: gramática, tabela de análise e string a ser analisada;
Saida: sequência de produções.
No início, a pilha contém apenas o símbulo inicial da gramatica no topo e $ no fundo. A string a ser lida
recebe $ no final.
Chamamos de T o símbolo no topo da pilha e de x o próximo símbulo da entrada.
Enquanto T ≠ $ ou x ≠ $ Faça:
Se T é terminal ou $ Então
Se T = x Então
Desempilha T
Tira x da entrada
Senão
ERRO
Senão
Se há produção T α indicada na linha de T, coluna de x na tabela de análise
Desempilha T
Empilha α
Mostra T α na saída
Senão
Erro
STRING ACEITA
Exercicio de Analise Léxica
Crie uma e.r. e um AFD para reconhecer endereços de e-mail válidos, inclindo os símbulos:
x = letra ou coisa assim;
p = ponto;
@;
e.r. 1 = ( x+ ( p x+ )* ) @ ( x+ ( p x+ )+ x )
e.r. 2 = ( x+ ( p x+ )* ) @ ( x+ ( p x+ )* ) ( x+ p xxx | x+ p xxx p xx )
12/04/2010
Criação da Tabela de Análise
Vamos ver um caso simplificado: gramáticas sem produções do tipo N ε.
01
02
03
04
05
06
07
08
09
10
ABu
ACA
Bx
BEy
Ct
CuD
DCD
DB
Ey
EzA
Neste caso, é preciso analisar cada produção e determinar quais são os terminais que podem iniciar algo
gerado por ela. Mais exatamente, se N α é a produção, queremos saber o que pode iniciar algo gerado por α.
No nosso caso simplificando, isto será simples.
Sendo α uma string de terminais e não terminais, definimos
FIRST( α ) = conjunto dos terminais que podem iniciar algo gerado a partir de α.
Exemplos, com a gramática anterior:
𝐹𝐼𝑅𝑆𝑇 ( 𝐵𝑢 ) = { 𝑥, 𝑦, 𝑧 }𝐹𝐼𝑅𝑆𝑇 ( 𝐴 ) = { 𝑡, 𝑢, 𝑥, 𝑦, 𝑧 }𝐹𝐼𝑅𝑆𝑇 ( 𝑧𝐴 ) = { 𝑧 }
Nosso caso admite as simplificações:
𝐹𝐼𝑅𝑆𝑇 ( 𝑁𝛽 ) = 𝐹𝐼𝑅𝑆𝑇( 𝑁 ); para todo não terminal N e string β.
𝐹𝐼𝑅𝑆𝑇 ( 𝑡𝛽 ) = { 𝑡 };
para todo terminal t e string β.
Para determinar o conjunto FIRST de cada não terminal, fazemos:
Para todo não-terminal N faça:
𝐹𝐼𝑅𝑆𝑇 ( 𝑁 ) = 0
Para toda produção N tβ, sendo t um terminal, faça:
𝐹𝐼𝑅𝑆𝑇 ( 𝑁 ) 𝐹𝐼𝑅𝑆𝑇 ( 𝑁 ) ∪ { 𝑡 }
1
2
1
Repita
Para toda produção N Mβ, sendo M um não terminal, faça:
𝐹𝐼𝑅𝑆𝑇 ( 𝑁 ) 𝐹𝐼𝑅𝑆𝑇 ( 𝑁 ) ∪ 𝐹𝐼𝑅𝑆𝑇 ( 𝑀 )
3
Enquanto houver alteração em algum FIRST.
Exemplo com a gramática dada:
Após o passo 1 :
𝐹𝐼𝑅𝑆𝑇(𝐴) = { }𝐹𝐼𝑅𝑆𝑇(𝐵) = { }𝐹𝐼𝑅𝑆𝑇(𝐶) = { }
𝐹𝐼𝑅𝑆𝑇(𝐷) = { }
𝐹𝐼𝑅𝑆𝑇(𝐸) = { }
Após o passo 2 :
FIRST ( A ) = { }
FIRST ( B ) = { x }
FIRST ( C ) = { t, u }
FIRST ( D ) = { }
FIRST ( E ) = { y, z }
Após 1ª iteração do passo 3 :
FIRST ( A ) = { x, t, u }
FIRST ( B ) = { x, y, z }
FIRST ( C ) = { t, u }
FIRST ( D ) = { t, u, x, y, z }
FIRST ( E ) = { y, z }
Após 2ª iteração do passo 3 :
FIRST ( A ) = { x, t, u, y, z }
FIRST ( B ) = { x, y, z }
FIRST ( C ) = { t, u }
FIRST ( D ) = { t, u, x, y, z }
FIRST ( E ) = { y, z }
Após 3ª iteração do passo 3 :
FIRST ( A ) = { x, t, u, y, z }
FIRST ( B ) = { x, y, z }
FIRST ( C ) = { t, u }
FIRST ( D ) = { t, u, x, y, z }
FIRST ( E ) = { y, z }
Não houve alteração, processo encerrado.
Agora que terminamos o conjunto FIRST ( α ) para toda produção N α.
No exemplo:
01
02
03
04
05
06
07
08
09
10
ABu
ACA
Bx
BEy
Ct
CuD
DCD
DB
Ey
EzA
{ x, y, z }
{ t, u }
{x}
{ y, z }
{t}
{u}
{ t, u }
{ x, y, z }
{y}
{z}
Finalmente, montamos a tabela
𝑇(𝑁, 𝑡) = produção a ser usada quando o não terminal N está no topo da pilha e o terminal t está na
entrada.
Para cada produção N α faça:
Para cada terminal 𝑡 ∈ 𝐹𝐼𝑅𝑆𝑇 ( 𝛼 ) faça:
𝑇(𝑁, 𝑡) í𝑛𝑑𝑖𝑐𝑒 𝑑𝑎 𝑝𝑟𝑜𝑑𝑢𝑡çã𝑜 𝑁 𝛼
t
A
B
C
D
E
u
x
Y
z
02 02 01 01 01
X X 03 04 04
05 06 X X X
07 07 08 08 08
X X X
10
$
X
X
X
X
X
A tabela gerada por este procedimento (ou pelo procedimento completo, incluindo produções com ε) não
deve apresentar conflitos (mais de uma produção em uma mesma casa).
Se não há conflitos, a ASD pode ser usada e dizemos que a gramática é LL(1)*.
Obs.: 𝐿𝐿(1): “Left Left”; L: admite análise com leitura da string a paritr da esquerda.; L: admite análise com a
derivação mais à esquerda da string; (1): indica que a analise envolve a leitura adiantada de um símbolo por vez.
19/04/2010
Algumas considerações adicionais sobre A.S.D.
- Algumas características podem impedir que uma gramatica se LL(1).
- Pode-se tentar modificar a gramatica para obter outra que seja LL(1) e que a mesma linguagem.
𝐴 → 𝐴𝑏
𝐴 → 𝑐𝐵
𝐴 → 𝑏𝐵
𝐴→𝜀
- Se a gramatica é ambigua, em principio não se deve faze ASD, mas há casos particulares em que isto é
possível.
Exemplo:
𝐶 → 𝑖𝐶
𝐶 → 𝑖𝐶 𝑒𝐶
𝐶→𝑥
(FAZER O RESTO!!!!!!!!!!!!)
𝑥=0
26/04/2010
Para fazer a análise de forma sequêncial, usamos uma pilha para fazer as reduções.
As operações do analisador são duas:
Deslocamento (shift): levar o próximo elemento da entra para a pilha;
Redução: reduzir alguns elementos no topo da pilha (combinando com o lado direito de alguma
produção), substituindo-os por um não terminal (o lado esquerdo da produção).
A decisão de descolar ou reduzir é feita com base na comparação do terminal mais próximo do tpo da pilha
com o próximo símbulo da entrada.
Ex: análise do 𝑛 + − 𝑛 ∗ (𝑛 + 𝑛)
Pilha (topo à direita)
$
$n
$E
$E+
$E+$E+-n
$E+-E
$E+E
$E+E*
$E+E*(
$E+E*(n
$E+E*(E
$E+E*(E+
$E+E*(E+n
$E+E*(E+E
$E+E*(E
$E+E*(E)
$E+E*E
$E+E
$E
Entrada
n+-n*(n+n)$
+-n*(n+n)$
+-n*(n+n)$
-n*(n+n)$
n*(n+n)$
*(n+n)$
*(n+n)$
*(n+n)$
(n+n)$
n+n)$
+n)$
+n)$
n)$
)$
)$
)$
$
$
$
$
$ < n, desloca
n > +, reduz (5)
$ , +, desloca
+ < -, desloca
- < n, desloca
n > *, reduz (5)
- > *, reduz (3)
+ < *, desloca
* < ( , desloca
( < n, desloca
n > +, reduz (5)
( < +, desloca
+ < n, desloca
n > ), reduz (5)
+ > ), reduz (1)
( = ), desloca
) > $, reduz (4)
* > $, reduz (2)
+ > $, reduz (1)
// FIM
Algoritmo
Entrada:
- gramática;
- tabela de precedências;
- string de entrada;
Saída:
- sequência de reduções;
Na descrição a seguir, t indica o terminal mais próximo do topo da pilha e x indica próximo simbolo da
entrada.
No início, a pilha contém apenas $ e a entrada tem $ no final.
Enquanto 𝑡 ≠ $ ou 𝑥 ≠ $
Se 𝑡 > 𝑥 (t precede x)
Seja 𝑁 → 𝛼 a produção tal que α combina com o topo da pilha.
Desempilha α
Empilha N
Mostra “𝑁 → 𝛼” na saída.
Senão, se 𝑡 ≤ 𝑥 ( x precede t ou há empate )
Remove x da entrada
Empilha x
Senão
ERRO
Se a pilha contem apenas $𝐸
SUCESSO
Senão
ERRO
Uma vez obtida a sequencia de reduções, pode-se reconstruir a árvore de derivação. Lida de trás para frente,
a sequencia de redução nos dá a derivação mais à direita.
No ultimo exemplo, a sequência de reduções foi:
5, 5, 3, 5, 5, 1, 4, 2, 1
Às vezes é possível evitar o uso da tabela de precedências I que ocupa muito espaço), associando valores
numéricos aos operadores. Cada operador recebe um valor para quando estiver à esquerda de outro operador e
outro valor para quando estiver à direita.
Chamemos estes valores de funções de precedência.
Exemplo:
…+ 𝐸 ∗ …
não temos tabela.
Tomamos os valores esq (+) e dir (*) e os comparamos para obter a precedência.
No caso, 𝑒𝑠𝑞(+) < 𝑑𝑖𝑟(∗).
Se há n operadores, guardamos 2n valores ao invés de n² itens da tabela.
No nosso exemplo:
+
*
(
)
n
$
esq
2
4
4
0
5
5
0
dir
1
3
5
5
0
5
0
As informações de erro são perdidas, mas os erros podem ser detectados mais tarde.
03/05/2010
Atributos e Vinculação
Vamos estudar propriedades de itens de um programa, como variáveis, parâmetros, subprogramas,
etc.
Há muita variação entre linguagens e pretendemos ter uma visão geral das diversas possibilidades.
Para facilitar a discussão, vamos usar variáveis como exemplo, mas muito do que discutimos se
estender a outros itens.
Exemplos de atributos de uma variável:
Nome
Tipo
Valor
Espaço em memória
Escopo
Forma de alocação
Permissões de acesso
A vinculação de um valor ao atributo de uma variável pode ser feita em dois períodos básicos:
- antes da execução (Vinculação Estática);
- durante a execução (Vinculação Dinâmica);
Alguns atributos podem ser vinculados de uma forma ou outra dependendo da linguagem. Vamos
ver alguns casos.
Rapida discussão sobre tipos
Um tipo define:
- conjunto de valores representáveis.
- operações admitidas.
Se não entrarmos em detalhes de implementação, temos um Tipo Abstrato de Dados.
A implementação diz respeito a:
- forma de representação, incluindo espaço alocado;
- forma de execução das operações;
Os tipos podem ser pré-definidos (primitivos) ou definidos pelo usuário (derivados). Em geral, as
linguagens de programação fornecem meios de criação de novos tipos a partir de tipos mais simples.
A vinculação de um tipo a uma variável pode ser estática ou dinâmica.
Na vinculação estática a variável é explicitamente declarada no programa e vinculada a um tipo.
Todos os usos desta variável devem ser adequados ao tipo. O compilador pode fazer esta verificação (em geral).
Na vinculação dinâmica, a variável pode ou não ser declarada e o seu tipo é redefinido a cada vez
que uma atribuição é realizada.
Ex:
x = 12
tipo inteiro
x = 1.2
tipo real
x = “hello”
tipo string
Tudo isto exige controle adiciona, talvez na forma de uma tebela com as informações sobre as
variáveis ativas no momento, seus tipos e valores. A verificação dos tipos devem ser feitas durantes a execução.
Vantagens da vinculação dinâmica de tipos:
- Flexibilidade no uso das variáveis;
- Facilidade de escrita.
Desvantagens:
- Não há verificação de tipos pelo compilador;
- Dificuldade de leitura;
- Baixo desempenho (gasto de memória e tempo).
Em geral, a vinculação dinâmica de tipos é mais usada em linguagens (semi) interpretadas.
10/05/2010
Atributos de Memória
Vamos ver como as variáveis são alocadas na memória. Há duas formas básicas e variantes:
- Alocação Estática;
- Alocação Dinâmica
- Na Pilha;
- No Heap
- Explícita;
- Implícita;
Alocação estática: a variavel é associada uma única vez a uma posição de memória, em geral no
única vez a uma posição de memória, em geral no início da execução, e permance alocada até o fim da execução.
Exemplos:
- variáveis globais (C, C++, Pascal, ... )
- variáveis explicitamente indicadas como static;
- variáveis locais em linguagens mais antigas;
Alguns casos interessantes:
→ variaveis static em classes Java são de alocação estática. Não são de alocação atributos dos
objetos, mas da própria classe;
→ variáveis static em funções em C são de alocação estática, apesar de terem escopo local. Elas
mantém o valor entre as execuções.
Exemplo:
int serial ( ) {
static int s = 0;
return s++;
}
Vantagens:
- A alocação estática é simples e não consome tempo;
- É intuitiva para programadores iniciantes;
Desvantagens:
- Quando usada para variáveis locais a subrotinas , dificulta o uso de recursividade;
- Consome memória, mesmo quando a variável não está em uso;
Em geral, este tipo de alocações convive com outros tipos na mesma linguagem.
Alocação Dinâmica na Pilha: é usanda para variáveis locais a rotinas em liguagens modernas.
As variáveis locais são alocadas no momento em que a rotina é invocada e desalocadas quando ela
termina.
Usa-se uma pilha porque as rotinas que foram chamadas por último são as primeiras a terminar. A
estrutura de dados para armazenar as variaveis das rotinas devem ser do tipo “Last-in-First-Out”.
Exemplo: Três rotinas A, B e C, A chama B e B chama C.
C
A
Aé
chamada
B
B
B
A
A
A
A
A
chama
B
B
chama
C
C retorna
B retorna
Cada rotina possio uma estrutura de dados chamada Registro de Ativação. Veremos mais tarde como
esta estrutura é alocada e desalocada na pilha.
Importate: este tipo de alocação torna a recursão mais natural. As variáveis locais podem ter várias
versões simultáneas na memória, uma para cada chamada à rotina.
Exemplo:
int mdc ( int a, int b ) {
int res;
if ( b == 0 )
return a;
else {
res = a % b;
return mdc ( b, res );
}
}
Este tipo de alocação permite o uso racional do espaço para variáveis locais: apenas o que é
necessário é alocado.
Além disso, a alocação pode ser feita segundo blocos de programas. Por exemplo:
int s = 0;
for ( int i = 0; i < 30; i++ ) {
int j = i * i;
s+= j;
}
Observação: em programas recursivos, é comum o estouro da pilha (“Stack Overflow”) em casos de
erro ou em casos de uso mais complex. Alguma adaptação (por exemplo, uso de alocação estática explícita quando
posspivel) pode ser usado.
24.05.2010
Vantagens da alocação dinâmica na pilha:
- Melhor aproveitamento da memória (dados locais são alocados apenas quando necessário);
- A recursividade torna-se mais natual;
Desvantagens com relação à alocação estática:
- Tempo gasto em alicação e desalocação;
Alocação Dinâmica no Heap
“𝐻𝑒𝑎𝑝” ≅ 𝑀𝑜𝑛𝑡𝑒.
O Heap é uma estrutura de dados capaz de controalr vários espaços de memória que podem ser alocados e
desalocados de maneira “caótica”.
Uma aplicação pode fazer uso do Heap “pedindo” uma área de memória livre para ele, usando esta área
para qualquer fim e depois “devolvendo” está área ao Heap.
Tipicamente, é preciso usar algum tipo de variável capaz de guardar um endereço de memória (ponteiros em
C, referências em Java).
Uma operação explícita pode ser usada para pedir meória ao Heap, devolvendo o endereço da área alocada.
Exemplos:
em C: malloc, calloc, ...
em C++: idem, mais new;
em Java: new;
Obs.: às vezes não é possível fazer a alocação (não há espaço contínuo com tamanho suficiente para
satisfazer a requisição).
Esta variante da alocação dinâmica no Heap é dito explícita, uma vez que o processo de alocação é feito com
operadores explícitas no código.
Nesta variante, a desalocação pode ser explícita ou não. Exemplos de comandos explícitos para desalocação:
em C: free()
em C++: delete
Algumas linguagens não requerem desalocação explícita, como Java. Áreas de memória alocadas mas não
mais usadas são automaticamente desalocadas por um “Garbage Collector” (Coletor de Lixo).
Vantagens do uso do Garbage Collector:
- Programas mais simples de escrever;
- Maior confiabilidade: evita-se o uso de espaços de memória erroneamente desalocados (“dangling
pointers”) e a perda de espaço devida a áreas sem uso que não foram desalocadas (“vazamento de memória”);
Desvantagens :
- Perda de desempenho devivo à complexidade da coleta de lixo;
Uma outra variante de alocação dinâmica no Heap é a implícita.
Uma variável é associada a um espaço em memória no momento em que é usada (tipicamente em uma
atribuição). Esta forma de alocação é comumente associada à vinculação dinâmica de tipos de dados.
Vantagens:
- facilidade de escrita;
- flexibilidade;
Desvantagens:
- baixo desempenho;
31.05.2010
Subprogramas
Vamos ver alguns detalhes de subprogramas (rotinas, funções, métodos, etc.). Em particular, vamos ver algo
sobre passagem de parâmetros.
Passagens de Parâmetros
4 Tipos Clássicos:
- Por valor ( ou por cópia );
- Por referência;
- Por valor-resultado;
- Por nome;
* Passagem por valor-resultado e nome são menos comuns;
Na passagem de parâmetros ocorre a troca de informações entre o chamador e o subprograma, que pode
ser bidirecional. Note que um subprograma pode apresentar um valor de retorno também.
Vamos ver as formas básicas.
- Passagem por valor ( ou cópia ).
O subprograma apresenta itens capazes de receber informações do chamador: são os chamados parâmetros
formais. Estes parâmetros formais atuam como variáveis locais do subprograma.
Eles são, porém, iniciados com valores indicados pelo chaador. Estes valores são chamados parâmetros reais
(“actual parameters”)
Exemplo:
int fat ( int n ) {
int res = 1;
while ( n >1)
res *= n--;
return res;
}
Exemplo de usos:
c = fat(m) / ( fat(5) * fat(m-5) );
Os parârametros reais neste exemplo são os valores calculados das expressões indicadas na chamada. Uma
cópia destes valores é passada para a rotina. Alterações no valor do parâmentro formal dentro da rotina não
provocam alterações sentidas pelo chamador.
Exemplos de linguagens que usam apenas este tipo de passagem de parâmetro: C e Java.
Em C, às vezes é útil criar funções que alteram o valor de variaveis do chamador. Para isso, é preciso usar
explicitamente o endereço da variável.
(ponteiro):
void incrementa ( int *p ) {
*p ++;
}
int x = 3;
incrementa (&x );
O que pode ser passado como parâmetro real?
O parâmetro real deve ser atribuível ao parâmetro formal, o que implica compatibilidade de tipos.
Exemplo:
int f ( int x ) {
return x + 1;
}
Chamadas válidas
int n, m;
n = f (1);
n = f ( m + 1 );
n = f ( f ( f ( 1 ) ) );
//etc.
Se o subprograma tiver mais de um parâmetro formal, é preciso considerar a ordem em que eles são
avaliados.
Exemplo:
int f ( int x, int y ) {
return x + y;
}
Chamadas válidas
int n = 3;
n = f ( n ++ , n -- );
Em Java os parâmetros reais seriam 4 e 3. Em C, seriam 2 e 3 (a avaliação é feita da direita para a esquerda).
Passagem Por Referência
Temos também parâmetros formais (declarados como variáveis) e parâmetros reais. Os parâmetros reais
devem ser do mesmo tipo dos parâmetros reais e devem ser “valores-l” ou “l-values”, ou seja, devem poder
aparecer do lado esquerdo de uma atribuição. São itens capazes de receber valores (variáveis, itens de vetores, etc.).
Tudo se passa como se o próprio parâmetro real ocupasse o lugar do parâmetro formal no processamento
de uma chamada.
Alterações feitas no parâmetro formal afetam o parâmetro real.
Exemplo em C++ :
void incrementa ( int &x ) {
x ++;
}
Chamando:
int n = 3;
incrementa (n); n passa a valer 4.
* & referência;
Outras linguagens: Pascal, Visual Basic, etc.
Outras chamadas permitidas:
int v[100];
incrementa( v[i+1] );
incrementa( v[v[v[3]]] );
Comparando com que é feito em C, usando apenas passagem por valor, com passagem de parâmetros não é
preciso usar endereços explícitos. De fato, no código de máquina ocorre de memória, mas para o programador tudo
se passa como se a “variável” tivesse sido entregue para rotina.
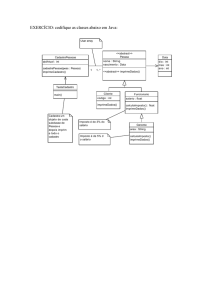
Em Java, qualquer variável ou parâmetro formal declarado com tipo não primitivo é uma referência, ou seja,
é capaz de armazenar um endereço de memória.
O uso de correto de referências exige a noção de que estas são endereços de memória.
Desta maneira, não há passagem de parâmetros por referência em Java.
Pode-se passar refeências (endereços) para os subprogramas, mas de fato ocorre uma passagem por valor (
o valor de uma variável do tipo referência é copiado em um parâmetro formal de tipo compatível).
void muda ( Minhaclass x ) {
x.modifica( );
x = new MinhaClasse( );
}
MinhaClass y = new MinhaClasse();
muda(y);