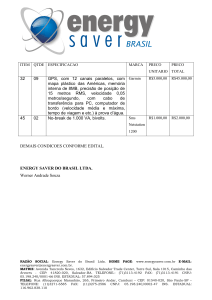
Fundamentação Teórica
AGs: Algoritmos de busca baseados nos mecanismos de seleçãoo natural
e na genética. Implementam estratégias de buscas paralelas e aleatórias
para solucionar problemas de otimização [Goldberg 1989].
Para implementação é necessário:
Representação do problema no formato de um código genético
População inicial que contenha diversidade suficiente
Método para medir a qualidade de uma solução (fitness)
Procedimento de combinação para gerar novos indivíduos
Critério de escolha das soluções que permanecerão na população ou
serão retirados
Procedimento para introduzir novas alterações em algumas soluções
da população.
Problemas Complexos
Meta-heurística Tabu (Kurahashi S.; Terano T.,
2000.)
Evolução Cooperativa (Potter, M.A.; De Jong K.,
2000)
Criação de Nichos (Hiroyasu T.; Miki M.;Watanabe S.,
1999)
Técnicas para Melhorar AGs
AGS são apropriados para problemas complexos, mas
algumas melhorias devem ser feitas, permitindo
trabalhar com problemas multimodal e multiobjetivo.
Sharing ou Compartilhamento de Recursos reduz o valor de aptidão de indivíduos que tem
membros altamente similares dentro da populaçao;
Evolução Cooperativa força a competição entre
espécies
Integração de Algoritmos Genéticos com
Algoritmos de Busca Simulated annealing, Hill
climbing, Busca tabu, entre outros.
Sharing
Limita o crescimento descontrolado de espécies
particulares dentro de uma população;
Força uma maior diversidade populacional
Similaridade pode ser medida tanto no espaço
genotípico como no espaço fenotípico;
Genotípico: atributos iguais entre dois indivíduos
Fenotipico: exemplos de treinamento cobertos pela
regra.
(GOLDBERG; RICHARDSON, 1987)
Meta-heurística Tabu - [Kurahashi e Terano,
2000].
tabu
População (t)
Candidatos (t+1)
muta₤₧o
similar
AG
Renovado
Renovado
passou
tabu
Esp₫cie - 1
indivíduo
EA
Popula₤
₧o
fitness
Modelo do
Domínio
Esp₫cie - 1
EA
Esp₫cie - 2
EA
Esp₫cie - 3
EA
representante
Esp₫cie 1 - Avalia₤₧o
Popula₤₧o
representante
Esp₫cie 2 - Avalia₤₧o
Popula₤
₧o
Esp₫cie - 3
EA
Popula₤₧o
Esp₫cie - 2
EA
Esp₫cie - 1
EA
Popula₤₧o
representante
fitness
Modelo do
Domínio
representante
Esp₫cie - 2
EA
Popula₤₧o
Popula₤₧o
representante
indivíduo
Popula₤₧o
Modelo do
Domínio
representante
Esp₫cie - 3
EA
fitness
indivíduo Popula₤
₧o
Esp₫cie 3 - Avalia₤₧o
Evolução Cooperativa - [Potter e De Jong 2000]
Criação de Nichos [Hiroyasu T.; Miki M.;Watanabe S., 1999]
GADBMS
GADBMS: sistema classificador baseado na indução de
regras.
Utiliza um algoritmo genético restrito por x listas Tabu
para efetuar a busca das regras (x = quantidade classes)
Implementado em C++ com interface DOS
Conjuntos de dados devem estar armazenados em banco
de dados
Arquitetura do GADBMS
Módulo Configura₤₧o
Recebe os parâmetros de entrada:probabilidade de
cruzamento, mutação, probabilidade de criação de
restrições vazias, medida de similaridade (genótipo /
fenótipo), tamanho da lista longa e da lista curta, etc.
Arquivo contendo a seguinte informação:
CLASSES 0,1,2.
v1
continuous.
v2
1,2,3.
v3
0,1.
v4
1,2,3,4,5.
v5
continuous.
v6
0,1.
v7
continuous.
v8
continuous.
Módulo GATABU
População
classes v1 (min) v1(máx)
v2
v3
v4 ...
1
0.85
1.26
1
*
3
0
0.15
*
1
0
1
1
0.85
1.26
1
1
3
1
*
1.02
*
0
5
2
*
*
3
0
4
IF v1 >= 0.85 AND v1 <= 1.26
v2 =
1
v3 =
*
v4 =
3
Then classes = 1
FITNESS = 0.81818182
Módulo GATABU
Função de Aptidão
(VP + 1)/(VP+FP+K)
VP, exemplos positivos corretamente classificados pela
regra
FP, exemplos negativos incorretamente classificados
como positivos
K, ₫ o número de classes no domínio
Módulo GATABU (AG Restrito)
Mutação
x ListasTabu
População
(t)
Seleção
Cruzamento
Mutação
População
(t+1)
Módulo GATABU
Similaridade:
Genótipo - quantidade de atributos similares ou
id₨nticos na regra;
Fenótipo - quantidade de registros corretamente
classificados pela regra.
Cruzamento em dois pontos;
Mutação:
Escolhe aleatoriamente um dos atributos e altera o
valor de acordo com os valores pré-definidos no
módulo de configuração.
Módulo Regras Extraídas
Reúne em um só conjunto as regras armazenadas nas
Listas Longas para verificação da precisão do
classificador;
Ordena de uma maneira apropriada;
Elimina regras que não cobrem nenhum exemplo no
conjunto de treinamento;
Classe padrão será aquela que possuir mais registros não
cobertos pelas regras;
Avalia as regras verdadeiras na base de teste;
Experimentos Realizados
Conjuntos de dados analisados (UCI)
(LIM;LOH;SHIH,1999;LOPES;POZO,2001)
Nome
Tam.
Classes Atributos Atributos
(D)
(C)
BLD
345
2
6
BLD+
345
2
15
PID
532
2
7
PID+
532
2
15
SMO
1855
3
3
5
SMO+
1855
3
10
5
VOT
435
2
16
VOT+
435
2
30
D - atributo discreto, C - atributo continuo, + dados com ruídos
Resultados Obtidos
Similaridade aplicada no conjunto de dados Smoke
Genótipo
Fenótipo
3
10
Taxa de erro
0,3050
0,3050
Popula₤₧o
200
200
4
4
00:01:56
00:16:58
Regras encontradas
Distância
Tempo (hh:mm:ss)
Distância 4
Genótipo: corresponde a quantidade de atributos iguais
Fenótipo: percentual de indivíduos cobertos (4 = 40%)
Resultados Obtidos Precisão
LIM;
Nome
Min
LOH;
SHIH
LOPES;POZO GADBMS
Max.
Mediana
Mediana
Mediana
BLD
0,2790 0,4320
0,3220
0,3775
0,3862
BLD+
0,3130 0,4410
0,3490
0,3475
0,4219
PID
0,2210 0,3100
0,2380
0,2593
0,2576
PID+
0,2210 0,3180
0,2500
0,2778
0,2705
SMO
0,3040 0,4240
0,3050
0,3008
0,3050
SMO+
0,3050 0,4110
0,3050
0,3068
0,3050
VOT
0,0364 0,0580
0,0457
0,0582
0,0503
VOT+
0,0412 0,0662
0,0469
0,0611
0,0455
MEDIA
0,2151 0,3075
0,2327
0,2486
0,2553
Resultados Obtidos
GADBMS obteve taxa de erro de 0,2553.
Comparado à taxa de erro dos 23 algoritmos
apresentados por (LIM; LOH; SHIH, 1999; LOPES;
POZO, 2001),que obtiveram taxa de erro de 0.2151 e
0.2486, GADBMS não é estatisticamente diferente
desses algoritmos ao nível de 10%, pois a diferença
entre eles não é maior que 0,058 (M₫todo Tukey).
De acordo com a análise de rank, GADBMS obteve a
posição 15,2. Segundo HOLLANDER (1999), a
diferença na m₫dia dos ranks maior que 8.7 ₫
estatisticamente significante ao nivel de 10%. Dos 22
algoritmos (LIM;LOH,SHIH,1999) a melhor posição
ficou com o algoritmo QL1 (7,6) e a pior posição ficou
com o algoritmo IB (19,1).
Conclusões
Com o GADBMS as regras podem ser encontradas em
apenas uma execução;
Uso de comandos SQL possibilita a execução do classificador
em bases de dados relacionais;
Mostrou efici₨ncia trabalhando com populações pequenas;
Se encontrada uma função de aptidão adequada ao
problema tratado, a precisão pode ser melhorada;
A medida de similaridade também mostra ser um parâmetro
importante na busca das regras;
A classificação utilizando regras tem a vantagem de ser
facilmente compreendida por humanos.
Trabalhos Futuros
Executar a ferramenta em conjuntos maiores de dados,
analisando tamb₫m o tempo de execução e as regras
encontradas;
Utilizar novos conjuntos de parâmetros e funções de aptidão
que possam vir a aumentar a precissão do classificador;
Encontrar uma medida de distância adequada que possa ser
aplicada indiferente aos tipos de atributos que estão sendo
avaliados;
Utilizar novas heurísticas na busca das regras, como a
utilização da Evolução Cooperativa.
Programação Genética
$
$
$
Programação Genética (PG): método de
indução de programas baseado na
seleção natural das espécies.
Objetivo: evoluir uma população de
programas candidatos à solução de um
dado problema.
Função de aptidão ao ambiente (fitness):
mede a habilidade de um programa para
resolver um problema
Funcionamento da PG
$
É feito iterativamente em quatro etapas:
$ 1. Gera-se população inicial de programas
de forma aleatória
$ 2. Avaliação dos programas (função de
aptidão)
$ 3. Com base nos valores de aptidão,
programas sofrem ação de operadores
genéticos: reprodução, cruzamento,
mutação
$ 4. Aplicação dos operadores genéticos
segue até que uma nova população tenha
sido gerada
F={+, -, *, /}
T = { x, 2 }
Árvore de Sintaxe Abstrata de x*x+2
+
*
X
2
X
Exemplo de criação de programa
Terminais: T={A,B,C}
Fun₤ões:
F={+,*,%,If,Lte}
Come₤e com + e 2arg
Continue com * e 2arg
Complete com terminais
A,B,C
O resultado é um prog.
Executavel, Closed
+
+
*
+
C
*
A
B
Mutuação
2 tipos de mutuções são possiveis
Uma função pode substituir uma função
ou um terminal pode substituir outro;
Um subtree pode ser substituido o novo
subtree é gerado aleatoriamente ao
igual que a população inicial.
Implementação
Lil-gp: ferramenta de PG
Problema da Formiga de Santa Fé
Melhorando a Taxa de Erro na
Tarefa de Classificação
Celso Yoshikazu Ishida, Dra. Aurora T. R. Pozo
[email protected], [email protected]
Departamento de Informática,
Universidade Federal do Paraná,
Centro Politécnico, Jardim das Americas
81531-970 Curitiba - PR, Brazil
Resumo
Introdução
Objetivos do Trabalho
DM, Classificação
GGP
GPSQL Miner
Experimentos
Conclusão
Mineração
A atual “era da informação” é
caracterizada por uma expansão
extraordinária do volume de dados.
Esta situação tem gerado demandas por
novas técnicas e ferramentas que, com
eficiência, transformem os dados
armazenados e processados em
conhecimento útil.
Classificação
Dado um conjunto de instâncias.
A tarefa de classificação encontra uma
descrição lógica (modelo) para um
atributo objetivo a partir de um
conjunto de atributos descritores.
Tabela: Cliente
Alias: C
Cli
1
2
3
4
Estuda
Trabalha
Sim
Não
Sim
Sim
Sim
Sim
Não
Não
Tabela: Venda
Alias: V
Cli
1
1
2
2
2
3
Comp
Preço
Venda R$
C20
C30
C10
C20
C21
C30
1100
400
2000
1100
3100
400
Tabela: TipoComputador
Alias: T
Comp
C10
C20
C21
C30
Tipo
(goal)
Laptop
Desktop
Desktop
HandHeld
Preço
(R$)
2000
1000
3000
500
IF C.Estuda = ‘Não’ and C.Trabalha = ‘Sim’ and V.PrecoVenda = T.Preco THEN T.Tipo = ‘Laptop’
ELSE IF C.Trabalha = ‘Sim’ and T.Preco < V.PrecoVenda THEN T.Tipo = ‘Desktop’
ELSE IF C.Estuda = ‘Sim’ and T.Preco > V.PrecoVenda THEN T.Tipo = ‘Handheld’
GPSQL Miner ?
Classificação em SGBD com GGP
GP - Genetic Programming
SQL - formato do classificador é SQL
Miner - ferramenta para mineração de
dados
GPSQL Miner – GP ?
Porque utilizar GP ?
Manipula dados inválidos e imprecisos. São
dados que podem impossibilitar a um
algoritmo encontrar uma solução adequada
para o problema.
Fácil adaptação a diferentes aplicações
Procura paralela implícita pelo espaço de
busca
GPSQL Miner – GGP ?
Porque GGP ?
Automatizar o processo
Uma vez que o sistema gera automaticamente
a gramática de acordo com a base de dados
Para gerar apenas soluções válidas
(indivíduos)
Orientar operações genéticas
GPSQL Miner
Porque utilizar SGBD ?
R: Para aproveitar as vantagens: [Freitas]
Informações em SGBD (DataWarehouse)
Re-utilização e redundância
Recursos SGBD:
Escalabilidade
Controle de segurança e privacidade
Paralelismo (Parallel SQL Servers)
GPSQL Miner
Porque utilizar SGBD ?
Definição da gramática de acordo com o
problema através da pesquisa de
informações na base de dados
Possibilitando a geração automática de
classificadores
GPSQL-Miner
IF C.Estuda = ‘Não’ and C.Trabalha = ‘Sim’ and V.PrecoVenda = T.Preco THEN T.Tipo =
‘Laptop’
ELSE IF C.Trabalha = ‘Sim’ and T.Preco < V.PrecoVenda THEN T.Tipo = ‘Desktop’
ELSE IF C.Estuda = ‘Sim’ and T.Preco > V.PrecoVenda THEN T.Tipo = ‘Handheld’
S ‘Laptop’ W C.Estuda = ‘Não’ and C.Trabalha = ‘Sim’ and V.PrecoVenda = T.Preco
S ‘Desktop’ W C.Trabalha = ‘Sim’ and T.Preco < V.PrecoVenda
S ‘Handheld’ W C.Estuda = ‘Sim’ and T.Preco > V.PrecoVenda
Programação Genética
Usa um processo de evolução baseado
em Darwin para inducir programas
Inspirados na Teoria da Evolução: os
indivíduos mais adaptados
sobrevivem
Algoritmos Evolucionarios
Uma população de individuos
A noção de fitness
Um ciclo de nascimento e morte
baseados na fitness
A noção de herança
Grammar Based Genetic Programming
Arquivo BNF para base de dados de vendas de computadores.
1 Start ::= <classifier>
2 <classifier> ::= <r> <r> <r>
3 <r> ::= S <goal> W <cond> | S <goal> W <cond> and <cond> | S <goal> W <cond> and
<cond> and <cond>
4 <goal> ::= ‘Laptop’ | ‘Desktop’ | ‘Handheld’
5 <cond> ::= C.Estuda = <boolean> | C.Trabalha = <boolean> | T.Preco <Noperator>
<value_T.P> | V.PrecoVenda <Noperator> <value_V.PV>
6 <value_T.P> ::= V.PrecoVenda | 500 | 1000 | 2000 | 3000 | random( 400, 3100)
7 <value_V.PV> ::= T.Preco | 500 | 1000 | 2000 | 3000 | random( 400, 3100)
8 <boolean> ::= ‘Sim’ | ‘Não’
9 <Noperator> ::= = | != | < | > | <= | >=
Qualidade Classificador
Capacidade de compreensão do
conhecimento descoberto
Tamanho Classificador
Número de Regras
Simplificação do Classificador
Critérios subjetivos
Taxa de Erro
GPSQL Miner
SQL
Parameters
Oracle
BNF File
SQL-BNF
Oracle
Evaluate
Crossover
Statistics File
GP
Config
File
Mutation
Statistics File
SQL Parameter File
//Tables
P -> Pessoa
Com -> Endereco
//Goal
Column -> Compra
Table -> L
//Columns
Column -> L.GENERO
Column -> L.PAIS
Column -> L.IDADE
Experimentos
Comparação com 33 algoritmos
22 algoritmos de árvore de decisão
9 clássicos e modernos algoritmos
estatísticos
2 algoritmos de redes neurais
Databases: 16 databases
8 com ruído ‘+’
Execução
Cada Database foi executado 10 vezes
10 sub-conjuntos distintos (ten-fold crossvalidation)
Train 90% e Test 10%
Calculado o Accuracy do melhor indivíduo de
cada Run
Calculado a média de Accuracy
Comparação
Foi feita a transformação de variáveis
sugerida por [Box & Cox 1964] devido
ao fato que as variâncias não se
mostraram homogêneas.
Detectou-se uma relação positiva entre
as médias da variável resposta e a
variabilidade dadas mesmas.
Box, G.E.P. and Cox, D.R.(1964) An analysis of transformations. JRSS B 26:211-246.
Comparação
A transformação Box-Cox tornou as
variâncias homogêneas de acordo com
os pressupostos das análises.
Para comparação das médias foi
utilizada a análise de variância para o
modelo em blocos ao acaso e o teste de
Tukey para comparação das médias.
Programa R - http://www.r-project.org/
Conclusão
Utilização SGBD ajuda na criação do
arquivo BNF de acordo com cada base
GPSQL Miner:
Boa representação de conhecimento para
problemas de Classificação
É melhor do que XX algoritmos com 95%
de segurança
Arquivos de estatísticas podem ser usados
para melhorar a própria ferramenta
Trabalhos Futuros
Aplicação em outros domínios
Melhorar performance (tempo)
Adaptação automática de parâmetros
Melhorar a Accuracy
Criar outros operadores genéticos (dropping
conditional)
Melhorar os pontos de crossover e mutação
Descoberta automática do número de regras