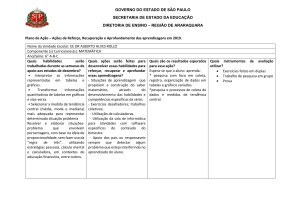
As tabelas podem ser baixadas para o computador do usuário e editadas. Os hyperlinks
encontrados nas células das tabelas referem-se a arquivos armazenados em computadores da
UFRJ ou a sítios da internet.
Os arquivos
Rp-454_asb-fasta-more_than_249.fsa e
Rp-454_asb-fasta-less_than_249.fsa
contêm o resultado da clusterização de 1.951.750 reads que ainda tinham mais de 40
nucleotídeos após a remoção das seqüências de primers e vetores, são provenientes das
seguintes bibliotecas de c-DNA e correspondem a 317.168 contigs e singletons.
Corpo Gorduroso – Biblioteca não normalizada
Túbulos de Malphigi – Biblioteca não normalizada
Ovários – Biblioteca não normalizada
Intestino médio anterior – Biblioteca normalizada
Intestino médio posterior – Biblioteca normalizada
Reto – Biblioteca normalizada
Testículos – Biblioteca normalizada
Corpo inteiro de vários estágios – Biblioteca normalizada
A tabela Rp-454-250.xls contém informações das análises dos contigs e singletons com
mais de 250 nucleotídios (66.010 contigs totalizando 1.666.858 reads).
As tabelas S1 e S2 são derivadas da tabela completa (Rp-454-250.xls) e contêm
informações sobre 2570 seqüências.Estas seqüências são aquelas diferencialmente super ou
sub expressas no aparelho digestivo em relação ao corpo inteiro. Quando proteínas com
expressão neutra faziam parte de famílias protéicas importantes para este tecido (últimas
colunas da tabela S2) elas foram incluídas na tabela.
Nas tabelas S1 e S2 estão informações sobre 2570 contigs (S1) e as proteínas
correspondentes (S2). No caso da tabela S2 foram criadas planilhas contendo subgrupos do
total levando em conta suas funções.