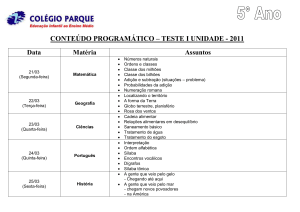
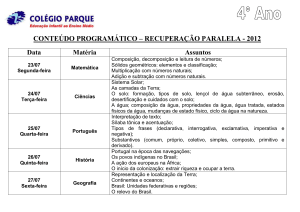
1. Introdução
Em vista de analisar ritmicamente o Português Brasileiro e o Português Europeu
através de textos escritos, foi analisado o banco de dados constituído de árvores
probabilísticas, estas que foram construídas através de textos jornalísticos dos anos de 1994
e 1995 do jornal brasileiro “Folha de São Paulo”, e do jornal português “Público”. Para
serem criados os modelos em forma de árvores, foi utilizado o pacote VLMC do software
estatístico R, que aborda a teoria de Cadeias de Markov de Alcance Variável existente na
sequência de códigos gerada através da codificação a qual os textos foram submetidos. Esta
codificação baseia-se basicamente em identificar sílabas tônicas/átonas e início/não início
de palavras prosódicas assim como a pontuação.
Este relatório apresentará algumas análises descritivas sobre o banco de dados
utilizado, bem como também explicará como ele foi obtido, a que processo foi submetido,
visto que os textos utilizados passaram por uma análise lingüística antes de serem definidos
como o banco de dados final.
Será apresentado também uma breve explicação sobre o teste estatístico que será
aplicado neste projeto que visa comparar as árvores do português europeu com as árvores
do português brasileiro.
2. Banco de Dados
Foram selecionados ao todo 80 textos jornalísticos, sendo que 40 reportagens são do
jornal “Folha de São Paulo” e outras 40 reportagens do jornal português “Público”. Cada
reportagem foi selecionada realizando-se amostragem Aleatória Simples entre os 365 dias
do ano, para ambos os jornais nos anos de 1994 e 1995. Estes textos escolhidos foram
utilizados para a construção das árvores probabilísticas, que é de fato o banco de dados
deste projeto. Cada texto gerou uma árvore, que foi modelada a partir do software
estatístico R.
Anterior ao processo de construção das árvores, houve um trabalho de limpeza dos
textos para serem submetidos à codificação. A codificação foi realizada utilizando o
algoritmo Sílaba, que foi processado através novamente do R, transformando as sílabas e
pontuação em códigos que permitissem a análise dos textos.
Seria interessante criar uma codificação que indicasse começo ou separação de
palavras prosódicas, além também de não se esquecer das implicações oriundas da
pontuação que traz muitas marcas para a oralidade, visto que uma frase interrogativa não é
expressa da mesma maneira que uma frase exclamativa, ou afirmativa. Esses três pontos
então foram considerados relevantes e em cima deles foi construída a proposta de
codificação. A codificação utilizada para este projeto, nos textos jornalísticos amostrados,
segue abaixo. Sejam Yt , Zt e Xt variáveis aleatórias assim definidas:
i. Yt = 0 se não corresponde a início de palavra prosódica e Yt = 1 se corresponde
a início de palavra prosódica;
ii. Zt = 0 se corresponde a sílaba átona e Zt = 1 se corresponde a sílaba tônica;
iii. Xt = 0 se (Yt,Zt)= (0,0) , ou seja, não início de palavra prosódica e sílaba átona;
Xt = 1 se (Yt,Zt) = (0,1), ou seja, não início de palavra prosódica e sílaba tônica;
Xt = 2 se (Yt,Zt) = (1,0), ou seja, início de palavra prosódica e sílaba átona;
Xt = 3 se (Yt,Zt) = (1,1) ou seja, início de palavra prosódica e sílaba tônica;
Xt = 4 corresponde a ponto final, de interrogação, de exclamação ou reticências.
Veja o exemplo de como seria codificado o texto abaixo, a partir das definições que
foram detalhadas acima:
“.
O
me
ni
no
já
co
meu
o
do
ce”
Yt
1
0
0
0
1
1
0
1
0
0
Zt
0
0
1
0
1
0
1
0
1
0
2
0
1
0
3
2
1
2
1
0
Xt
4
Como a codificação é baseada em sílabas tônicas de palavras prosódicas, nos
“inícios de palavras” que apresenta ao longo do discurso e sobre a pontuação, algumas
observações podem ser feitas. Dado que temos um código que expressa o fim de uma frase
(4), o próximo código não poderá ser o mesmo que expressa fim de frase (outro símbolo 4),
pois não faz sentido uma frase sem conteúdo algum, apenas com a pontuação. Da mesma
forma, quando aparece o código que expressa a sílaba tônica no meio de uma palavra, já se
pode concluir que a próxima sílaba não será tônica, pois só existe uma sílaba tônica por
palavra prosódica, e nem os códigos anteriores dentro da mesma palavra prosódica pode
indicar sílaba tônica.
Assim sendo, como existe esta dependência entre os códigos, existe um
encadeamento entre eles, e pode-se assim utilizar a modelagem de estruturas markovianas
nesta sequência de códigos. A teoria de cadeias de Markov torna-se útil calculando-se as
probabilidades de transição para os códigos, por exemplo, qual é a probabilidade de que um
código “1” apareça depois de outro código “1”? Neste projeto, poderá observar-se que a
probabilidade de ocorrência de um determinado código não depende apenas do código
anterior, depende até de k-passos anteriores. Desta forma existem k-passos anteriores que
são relevantes para predizer o próximo símbolo, e este número de passos varia para cada
símbolo. Estes k-passos que são relevantes para predizer o próximo símbolo são chamados
de “contextos”, e são os contextos que moldam as formas das árvores obtidas a partir dos
textos. São realizados testes de razão de verossimilhança sobre cada probabilidade de
transição possível e as árvores obtidas são compostas de ramificações (probabilidades de
transições) que são estatisticamente significantes e relevantes para predizer próximos
valores. A seguir então serão apresentadas análises iniciais sobre as árvores obtidas das
reportagens amostradas, bem como exemplo gráfico de contextos para facilitar a
compreensão.
3. Análises Descritivas
Devido a grande complexidade do processo de limpeza deste banco de dados, foram
analisados até este momento todos os textos amostrados do jornal “Folha de São Paulo” e
“Público” do ano de 1994 apenas. Este projeto está sendo desenvolvido junto com
profissionais do departamento da área de Linguística, que analisaram cuidadosamente
todos os textos. Como existe uma dependência e conectividade neste grupo de trabalho, não
se pode fazer as análises sem ter a validação Lingüística de peritos, assim como não se
pode fazer análises estatísticas sobre os dados sem ter o conhecimento e as suposições
necessárias (aleatorização, amostra razoavelmente grande para utilizar o teorema central
doo limite, etc.) .
Desta forma, foram analisadas as árvores até então obtidas e observou-se:
Nas árvores do português brasileiro e do português europeu, os contextos “100”, “10”,
“20”, “30”, “1”, “2”, “3” e “4” aparecem em 100% dos textos;
O contexto “200” aparece em 30% das árvores do português brasileiro e em 45% do
português europeu;
O contexto “300” foi observado em 85% dos textos da “Folha de São Paulo e em 65%
do Público”;
Apenas nos textos do português europeu apareceu o contexto “000”, em 5% dos dados.
Foram observados em ambos os idiomas basicamente 3 tipos de árvores, como
pode-se observar abaixo:
Tipo 1:
Tipo 2:
Tipo 3
Observou-se que para as árvores do português do português brasileiro árvores do
tipo 2 apresentaram maior freqüência (55%) enquanto que para os textos do português
europeu árvores do tipo 3 apresentaram maior freqüência (40%), seguidas do tipo 2 ( 35%),
veja a tabela abaixo:
Tabela 3.1 ) Tabela de Contigência (Tipo de Árvores x Jornal)
Tipo 1
Tipo 2
Tipo 3
Folha de São Paulo
3
11
6
20
Público
5
7
8
20
Total
8
18
14
40
A partir desta tabela, podemos fazer algumas análises interessantes. Assumindo-se
que o jornal Folha de São Paulo tem distribuição Multinomial com parâmetros (p1, p2, p3,
20) e o jornal Público também tem distribuição com parâmetros Multinomial (q1, q2, q3, 20)
para o tipo de árvores que eles geram a partir dos textos amostrados, onde pi e qi indicam a
proporção de árvores do tipo i, para i = 1,2 e 3. Pode-se testar se existe igualdade ou
diferença da procedência do texto testando os parâmetros a partir do Teste de Razão de
Verossimilhança.
Os estimadores obtidos pelo método da Verossimilhança são:
p 1=
3
11
6
5
7
8
; p 2=
; p 3=
;q 1=
;q 2=
;q 3=
20
20
20
20
20
20
O interesse é testar se os parâmetros são iguais ou não, ou seja:
H 0 : p1= q1 , p2 = q 2 , p 3= q 3
H 1 : algum i tal que p i≠ qi
Sob Ho, temos uma distribuição para os dados como Multinomial, com parâmetros
(p1=8/40, p2=18/40, p3 =14/40=40).
Calculando a razão de verossimilhança,observou-se que Λ = 0, 090301, onde Λ é a
razão de verossimilhança.
2
2
Como − 2 ln Λ ~ χ 4− 2= χ 2 , então foi calculado o valor e observamos que o valor
2
da estatística do teste é χ 2= 4,809014 .
Para este valor, temos que o o p-valor está entre 0,05 e 0,1, o que não fornece tantas
evidências para se rejeitar a hipótese nula.
Entretanto esse resultado foi obtido a partir de um teste onde as árvores foram
dividas em grupos e os grupos foram testados, de certa forma este teste não é de fato o
ideal. O próximo passo é justamente realizar um teste mais poderoso, sobre todas as
árvores, e apresenta-se como uma alternativa razoável para o problema em questão.
4. Metodologia
Será realizado neste próximo instante o teste estatístico sobre as árvores
probabilísticas do português brasileiro e português europeu.
O teste que será utilizado aqui é baseado em um teste do tipo Kolmogorov, onde a
estrutura média que caracteriza duas amostras de populações distintas são comparadas e
busca-se testar se a diferença (distância) entre essas estruturas são estatisticamente
significantes para rejeitar uma igualdade de comportamento.
A metodologia detalhada deste teste será apresentado no próximo relatório, bem
como o resultado obtido.
5. Considerações Finais
A próxima etapa deste projeto, como foi dito anteriormente, será aplicar o teste
sobre as árvores e observar se há ou não diferença entre os textos do português europeu e
do português brasileiro.
Esta análise será realizada sobre os 80 textos que foram coletados, que estão em
processo de finalização de limpeza.
6. Referências Bibliográficas
- Carvalho, J.B., “Phonological conditions on Portuguese clitic placement: on syntactic
evidence for stress and rhythmic pattern”, Linguistics, Vol. 27, pp. 405–435, 1989;
- Frota, S. and Vigário, M., “Aspectos de prosódia comparada: ritmo e entoação no PE e no
PB”, Actas do XV Encontro da Associação Portuguesa de Lingıística, Coimbra, Vol. 1, pp.
533-55, 2000;
- Frota, S. and Vigário, M., “On the correlates of rhythm distinctions: the European/
Brazilian Portuguese case”, Probus, Vol. 13, pp. 247–275, 2001;
- Sândalo, F., Abaurre, M. B., Mandel, A. and Galves, C., “Secondary stress in two
varieties of Portuguese and the Sotaq optimality based computer program”, Probus, Vol.
18, to appear, 2006;
- Ramus, F., Nespor, M. and Mehler, J., “Correlates of linguistic rhythm in the speech
signal”, Cognition, Vol. 73, pp. 265–292, 1999.
- Duarte, D, Galves, A., Lopes, N. and Maronna, R., “The statistical analysis of acoustic
correlates of speech rhythm”, Workshop on Rhythmic patterns, parameter setting and
language change, ZiF, University of Bielefeld, 2001. Can be downloaded from
http://www.physik.unibielefeld.de/complexity/duarte.pdf;
- Rissanen, J., “A universal data compression system”, IEEE Trans. Inform. Theory, Vol.
29, pp. 656–664, 1983;
- Bühlmann, P. and Wyner, A. J., “Variable length Markov chains”, Ann. Statist., Vol. 27,
pp. 480–513, 1999;
- ”The R Project for Statistical Computing”, http://www.rproject.org;
- Mächler, M., “The VLMC package”, 2005. Can be downloaded from http: // cran.r project. org / doc / packages/VLMC . Pdf.;
- Mächler, M. and B¨uhlmann, P., “Variable length Markov chains: methodology,
computing, and software”, J. Comput. Graph. Statist., Vol. 13, pp. 435–455, 2004;
- Bühlmann, P., “Model selection for variable length Markov chains and tuning the context
algorithm”, Ann. Inst. Statist. Math., Vol. 52, pp. 287–315, 2000;
- Vigário, M. The prosodic word in European Portuguese, Mouton de Gruyter, 2003;
- Kleinhenz, U. ”Domain typology at the phonology-syntax interface” in G. Matos et al.
(eds) . Interfaces in Linguistic Theory, Lisboa: APL/Colibri, pp.201-220, 1997.