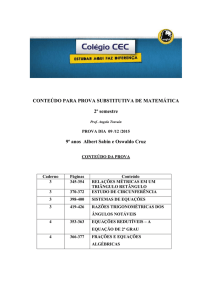
6.2.5 - Métodos específicos para matrizes de coeficientes do tipo banda:
Dado o seguinte sistema de equações:
r1
t
2
0
0
0
d1
0
0
r2
d2
0
t3
r3
d3
0
t n 1
rn 1
0
tn
0
0
0
0
rn 1
rn
x1
x
2
x3
x n 1
x
n
b1
b
2
b3
b n 1
b
n
(3)
Nota-se que a estrutura da matriz de coeficientes é do tipo Matriz Banda Tridiagonal,
onde existem apenas três diagonais não totalmente nulas, uma diagonal principal ri e duas
diagonais paralelas ti e di, os demais coeficientes são todos nulos.
Este sistema de equações pode ser resolvido por um método direto, como Gauss por
exemplo, o qual promove as devidas eliminações tornando a matriz de coeficientes uma
matriz do tipo triangular superior. Neste procedimento, o método de Gauss opera as devidas
eliminações inclusive nas posições dos elementos nulos, que não necessitam ser manipulados.
No caso de matrizes de grande porte teríamos um custo excessivo com operações
desnecessárias.
Então, para sistemas com matrizes de coeficientes do tipo banda é possível adaptar os
métodos diretos tradicionais, de modo que os valores nulos não sejam manipulados
desnecessariamente.
Assim, pode-se implementar um método de eliminação envolvendo apenas os
elementos não nulos, conforme a sequência a seguir, baseada no método de Gauss:
r1
t 2
0
d1
r2
0
d2
0
0
t i 1
ri 1
d i 1
ti
ri
di
0
0
tn
rn
r1
0
0
d1
r2*
0
d2
0
0
0
0
t i 1
ri 1
d i 1
ti
ri
di
0
0
t n rn
0
0
b1
t
b2 L2 L2 2 L1
r1
b i 1
bi
b n
b1
b *2
b i 1
bi
b n
73
onde
onde
t2
t2
d 1 e b *2 b 2 b 1
r1
r1
Generalizando para uma linha i qualquer, tem-se:
r2* r2
r1
0
0
d1
r2*
0
d2
0
0
0
0
0
r
d i 1
ti
ri
di
0
0
tn
rn
r1
0
0
d1
r2*
0
d2
0
0
0
0
0
ri*1
d i 1
*
i
di
*
i 1
0
r
0
0
0
rn*
ri* ri
ti *
d
e
ri*1 i 1
b*i b i
b1
b *2
b *i 1
t
b i L i L i *i L i 1
ri 1
b n
b1
b *2
b *i 1
b *i
b n
(4)
ti *
b
ri*1 i 1
Assim, chega-se a um algoritmo simples para efetuar a triangularização da matriz de
coeficientes:
Genericamente, para i = 2,3,...,n tem-se
ti *
d
ri*1 i 1
t
b*i b i *i b*i 1
ri 1
ri* ri
com r1* r1
e b 1* b 1 .
Como a solução de (3) é a mesma de (4), então por retrosubstituição sucessiva obtemse:
x n b *n / rn*
Para i = n-1,n-2,...,2,1 tem-se
x i ( b *i d i x i 1 ) / ri*
74
Assim, a solução do sistema de equações é obtida com o mínimo de operações
possíveis, manipulando apenas os elementos não nulos.
Nestes casos o pivotamento de linhas ou colunas não deve ser aplicado, pois isto
alteraria a estrutura em forma de banda da matriz.
Ex. 6: Resolva o seguinte sistema de equações de forma otimizada:
0
1 1 0
1 1 1 0
0 1 1 1
0 0 1 1
0 0
0 1
0
0
0
1
2
0
1
2
1
2
Solução:
(i). Triangularização baseada no pivô k = 1:
0
1 1 0
1 1 1 0
0 1 1 1
0 0 1 1
0 0
0 1
0
0
0
1
2
0
1
1 L 2 L 2 L1
1
2
1
2
0
1 1 0
0 2 1 0
0 1 1 1
0 0 1 1
0 0
0 1
0
0
0
1
2
0
1
2
1
2
(ii). Triangularização baseada no pivô k = 2:
0
1 1 0
0 2 1 0
0 1 1 1
0 0 1 1
0 0
0 1
0
0
1 1
0 2
1
0
0 0 0.5 1
1
1
0 0
0 0
0
1
0
0
0
1
2
0
1
1
2 L3 L3 L2
2
1
2
0
0
0
1
2
0
1
.
15
1
2
75
(iii). Triangularização baseada no pivô k = 3:
0
0
1 1
0 2
1
0
0 0 0.5 1
1
1
0 0
0 0
0
1
0
0
0
1
2
0
1
.
15
( 1)
1 L 4 L 4
L
( 0.5) 3
2
0
0
1 1
0 2
1
0
0 0 0.5 1
0
1
0 0
0 0
0
1
0
0
0
1
2
0
1
.
15
4
2
(iv). Triangularização baseada no pivô k = 4:
0
0
1 1
0 2
1
0
0 0 0.5 1
0
1
0 0
0 0
0
1
0
1
0 15
.
1 4
( 1)
L
2 2 L 5 L 5
( 1) 4
0
0
1 1
0 2
1
0
0 0 0.5 1
0
1
0 0
0 0
0
0
0
0
0
1
1
0
0
0
1
.
15
4
2
(v). Retrosubstituição:
1 . x5 2
1 . x 4 + 1 . x 5 4
0.5 . x 3 + 1 . x 4 15
.
2 . x2 - 1 . x3 1
1 . x1 - 1 . x 2 0
x5 2
x4 6
x3 9
x2 5
x1 5
Solução = {5,5,9,6,2}
Considerações finais:
(i). Em sistemas de equações lineares que relacionam variáveis com grandezas de magnitudes
diferentes, como por ex.: metros e milímetros, podem existir coeficientes também com
magnitudes bastante diferentes. Nestes casos recomenda-se normalizar os coeficientes das
76
equações do sistema, dividindo cada equação pelo coeficiente de maior módulo. Este
procedimento reduz os erros por perda de significação;
(ii). A avaliação do determinante da matriz de coeficientes é uma questão estrategicamente
importante para que se possa classificar as possibilidades de soluções do sistema de equações
lineares. Se o cálculo do determinante for efetuado via a sua definição clássica, dada pela
"Soma do termo principal, dada pelo produto da diagonal principal da matriz, com os
produtos dos elementos do termo principal permutando-se os seus segundos índices", tem-se
um número de operações aritméticas envolvidas muito elevado.
Por isso, adota-se uma forma de cálculo alternativa, baseada nas operações elementares
utilizadas nos métodos de resolução do sistema de equações lineares.
Por exemplo, no método de Gauss aplica-se um conjunto de operações elementares
para triangularizar a matriz expandida, mas nenhuma destas operações aplicadas altera a
magnitude do determinante, podem alterar apenas o sinal do determinante quando acontecem
as trocas de linhas ou colunas.
Então, após o procedimento de eliminações sucessivas gera-se a matriz
triangularizada, cujo determinante pode ser obtido pelo simples produto dos elementos da
diagonal principal.
Uma desvantagem deste cálculo do determinante sobre a matriz triangular processada,
através das operações elementares, é o fato de que esta forma final sofreu o acumulo de erros
de arredondamentos sucessivos. Então, esta forma de cálculo do determinante não é exata, e
pode gerar inconsistências. Por exemplo, em matrizes singulares é possível avaliar um
determinante residual diferente de zero decorrente de erros de arredondamento acumulados,
gerando uma solução inconsistente para o sistema original.
(iii). As soluções dos sistemas de equações lineares podem ser classificadas segundo três
casos distintos:
(a). Sistema Determinado: quando o sistema de equações tem solução única, nestes
casos a matriz de coeficientes é não singular e o determinante é não nulo. Ocorrem quando
todas as equações do sistemas são linearmente independentes (LI), nenhuma é combinação
linear de outras.
(b). Sistema Indeterminado: quando o sistema de equações tem infinitas soluções,
neste caso a matriz de coeficientes é singular, ou seja, o seu determinante é nulo. Ocorrem
quando se tem um sistema de equações lineares, cujos coeficientes possuem alguma relação
de dependência, por exemplo, uma equação é gerada a partir da combinação linear de outras.
Pode-se concluir que a(s) equação(es) gerada(s) a partir da combinação linear de outras
existentes, não acrescenta(m) informações novas ao conjunto de equações do sistema. Desta
forma, o sistema se comporta como se tivesse menos equações que incógnitas, deixando
alguma(s) incógnita(s) livre(s) de equações próprias que restrinjam o seu(s) valor(es). No
Método de eliminação de Gauss com pivotamento total, pode-se constatar este fato
observando que no final do processo de eliminação, uma, ou mais, linhas inteiras da matriz
expandida se anulam e seu termo independente também se anula.
(b). Sistema Impossível: quando o sistema de equações não tem solução alguma,
neste caso a matriz de coeficientes também é singular, e seu determinante é nulo. Ocorrem
quando alguma equação do sistema é impossível de ser satisfeita. Por exemplo, se alguma
equação do sistema é gerada a partir da combinação linear de apenas um dos membros de
duas outras equações, gerando uma equação inconsistente. No Método de Gauss com
pivotamento total, pode-se constatar este fato observando que no final do processo de
eliminação, uma, ou mais, linhas da matriz de coeficientes se anulam, mas o termo
77
independente não se anula. Na prática, significa ter uma equação com todos os coeficientes
nulos e que deve satisfazer a um termo independente não nulo, o que é impossível de ser
satisfeito.
Exercícios:
7). Classifique as possíveis soluções dos seguintes sistemas de equações lineares, através do
método de Gauss com pivotamento total:
3x 1 15
. x 2 4.75x 3 8
a). 4 x 1 2 x 2 3x 3 7
2 x 5x 3x 12
2
3
1
x 1 0.5x 2 175
. x 3 1
b). 3x 1 15
. x 2 4.75x 3 8
4 x 2 x 3x 7
2
3
1
x 1 0.5x 2 175
. x3 0
c). 3x 1 15
. x 2 4.75x 3 8
4 x 2 x 3x 7
2
3
1
6.3 - Solução de Sistemas Lineares por Métodos Iterativos
6.3.1- Introdução
Quando o sistema de equações lineares A x = b possuir algumas características
especiais, tais como:
a). Ordem n elevada (n é o número de equações);
b). A matriz dos coeficientes possuir grande quantidade de elementos nulos (matriz esparsa);
c). Os coeficientes puderem ser gerados através de alguma lei de formação;
em geral, será mais eficiente resolvê-lo através de um método iterativo, desde que a
convergência seja possível.
Obs.: Note que se um algoritmo de um método direto, como o do Método de Gauss, for
aplicado ao um sistema com matriz de coeficientes esparsa, muitas operações aritméticas
desnecessárias serão empregadas, por exemplo na manipulação de zeros com outros zeros.
A solução iterativa de A x = b consiste em se tomar uma solução inicial xo para a
solução = [1,2,...,n]T procurada e construir uma sequência S x k k 0 de soluções
aproximadas tal que
limx k , se esta sequência for convergente.
k
A questão fundamental é como gerar esta sequência convergente.
78
Em A x = b, tomando a matriz A e particionando-a na forma canônica,
A = B + C, com B não singular, resulta que:
(B + C) x = b
Bx=b-Cx
x = B-1 b - B-1 C x
(1)
Então, aplicando a solução inicial xo na eq. (1), resulta
x1 = B-1 b - B-1 C xo
reaplicando x1 em (1), obtém-se x2 e assim sucessivamente, resultando numa
sequência
S x k k 0 , onde
xk+1 = B-1 b - B-1 C xk
(2)
Se a sequencia (2) for convergente, então existe
lim x k 1 lim x k
k
(3)
k
Aplicando o limite a ambos os termos da eq. (2), tem-se
lim x k 1 B1 b B1C lim x k
k
(4)
k
Aplicando a eq. (3) na eq. (4), tem-se
lim x k 1 B1 b B1C lim x k 1
k
k
(1 B1C) lim x k 1 B1 b
k
(5)
Multiplicando a eq. (5) a esquerda pela matriz B, tem-se
( B C) lim x k 1 b
k
(6)
Mas A = B + C, então
A lim x k 1 b
k
Logo,
lim x k 1
k
O problema agora é que para se gerar a sequência (2) necessita-se da matriz inversa Be portanto esta inversa, por questão de eficiência, tem que ser obtida facilmente. A seguir
serão abordadas duas maneiras, não exclusivas, de se particionar a matriz A de modo que a
matriz B seja trivialmente invertida.
1
79
6.3.2. Método iterativo de Jacobi
No sistema A x = b tomando a matriz A e particionando-a na forma
A = D + L + U,
onde
D = Diagonal principal de A;
L = Matriz triangular inferior estrita obtida dos elementos infradiagonais de A;
U = Matriz triangular superior estrita obtida dos elementos supradiagonais de A.
Então, considerando na forma canônica que B = D C = L + U
e aplicando-as na eq. (2) vem:
x k 1 D1 b D1 (L U)x k
(7)
onde os elementos de D-1 são trivialmente obtidos tomando-se os recíprocos dos elementos
diagonais de A. Expressando a eq. (7) na forma desenvolvida resulta
x
k 1
i
n
( b i a ij x kj ) / a ii
i = 1,2,...,n
(8)
j 1
j i
Logo, para se resolver A x = b por Jacobi, toma-se uma solução inicial
x x 1o , x o2 ,..., x on T, isola-se a i-ésima incógnita xi na i-ésima equação e aplica-se (2) para
se tentar obter a sequência convergente.
o
Ex. 7): Resolver o seguinte sistema pelo método de Jacobi.
3x1 x 2 x 3 1
x1 3x 2 x 3 5
2x 2x 4x 4
2
3
1
Montando as equações evolutivas para as variáveis do sistema tem-se:
x1k+1 (1 x 2k x 3k ) / 3
k+1
k
k
x 2 = (5 x1 x 3 ) / 3
k+1
k
k
x 3 = (4 2x1 2x 2 ) / 4
Valor inicial: ( x10 , x 02 , x 03 ) (0,0,0)
80
k
0
1
2
3
4
5
6
x1k
x 2k
x 3k
0
0,333
1,222
1,296
0,901
0,868
1,044
0
1.667
1,222
0,704
0,901
1,132
1.044
0
1
0,667
1
0,704
1
1,132
Pode-se notar que a sequência evolutiva obtida para as variáveis x ik está convergindo
para a solução S, que no caso é dada por S = {1,1,1}.
Neste ponto é necessário estabelecer um critério de parada que determine o quão
próxima da solução exata está a sequência convergente x ik , dentre os critérios mais comuns
estão:
(i). Max xik 1 xik
i = 1,2,3,...,n
Corresponde à máxima diferença absoluta entre valores novos e antigos de todas as
variáveis.
x ik 1 x ik
k 1
xi
(ii). Max
i = 1,2,3,...,n
Corresponde à máxima diferença relativa entre valores novos e antigos de todas as
variáveis.
(iii). Max Rik 1
i = 1,2,3,...,n
n
Corresponde ao maior resíduo dentre todas as equações, onde R ik 1 b i a ij x kj 1
j1
No caso do exemplo 7 anterior, aplicando-se o critério (i), tem-se:
k
0
1
2
3
4
5
6
x1k
x 2k
x 3k
| x1k 1 x1k |
| x 2k 1 x 2k |
| x 3k 1 x 3k |
0
0,333
1,222
1,296
0,901
0,868
1,044
0
1.667
1,222
0,704
0,901
1,132
1.044
0
1
0,667
1
0,704
1
1,132
0,333
0,889
0,074
0,395
0,033
0,176
1,667
0,555
0,518
0,197
0,197
0,088
1
0,333
0,333
0,296
0,296
0,132
Portanto, neste exemplo, o critério alcançado é Max | x ik 1 x ik | 0,176 .
81
Obs.: Note que, neste exemplo, o processo iterativo é do tipo oscilatório, onde as variáveis
aumentam e diminuem alternativamente. Este efeito prejudica a convergência, tornando o
processo lento.
6.3.3 - Método Iterativo de Gauss Seidel
Em A x = b com a partição de A na forma A = D + L + U como no Jacobi, porém
tomando B = D + L para a canônica, tem-se de (2) que:
x k 1 ( D L) 1 b [( D L) 1 U]x k
(9)
Multiplicando a eq. (9) pela matriz (D+L), tem-se
( D L) x k 1 b Ux k
Dx k 1 b Lx k 1 Ux k
x k 1 D 1 (b Lx k 1 Ux k )
(10)
que expressa na forma desenvolvida, torna-se
i 1
x k 1 ( b i a ij x kj 1
j 1
ji
n
a
j i 1
ji
ij
x kj ) / a ii
i = 1,2,...,n
(11)
cuja operacionalização é semelhante à do método de Jacobi, exceto que em (11) utiliza-se
sempre o último valor obtido e em (8) utiliza-se o último vetor obtido.
Ex. 8): Resolver o seguinte sistema pelo método de Gauss-Seidel:
3x1 x 2 x 3 1
x1 3x 2 x 3 5
2x 2x 4x 4
2
3
1
Montando as equações evolutivas para as variáveis do sistema temos:
x1k+1 (1 x 2k x 3k ) / 3
k+1
k 1
k
x 2 = (5 x1 x 3 ) / 3
k+1
k+1
k+1
x 3 = (4 2x1 2x 2 ) / 4
Note que as equações evolutivas se utilizam dos valores disponíveis mais atualizados.
Valor inicial: ( x10 , x 02 , x 03 ) (0,0,0)
k
x1k
x 2k
x 3k
| x1k 1 x1k |
| x 2k 1 x 2k |
| x 3k 1 x 3k |
82
0
1
2
3
4
5
6
0
0,333
1.388
0.768
1.137
0.918
1.048
0
1,555
0.666
1.197
0.882
1.069
0.958
0
1.611
0.638
1.214
0.872
1.075
0.955
0.333
1.055
0.620
0.368
0.218
0.129
1.555
0.888
0.531
0.314
0.186
0.110
1.611
0.972
0.575
0.341
0.202
0.120
Aplicando o critério (i), tem-se: Max | x ik 1 x ik | 0,129 .
Obs.: Note que, no mesmo exemplo, o processo iterativo correspondente a aplicação do
Método de Gauss-Seidel também é um processo oscilatório, porém neste caso tem-se um
processo de convergência um pouco mais rápido, por que no método de Gauss-Seidel são
tomados os valores disponíveis mais atualizados.
6.3.4 - Convergência dos Métodos Iterativos
Nos tópicos anteriores foram desenvolvidas duas formas (expressões (8) e (11)) de se
construir uma seqüência S =
x
k
k 0
de possíveis aproximações para a solução de Ax = b.
Aqui, será abordada a questão de quando esta seqüência será convergente. Para tanto,
necessita-se de mais dois conceitos.
Definição 1: No sistema Ax = b, sejam S i | a ij |, i 1,..., n . Daí, diz-se que ele é diagonal
j i
dominante se ocorrer:
1o ) | a ii | S i , i 1,..., n e
2o ) | a ii | S i , para pelo menos uma linha i de A.
Definição 2: No sistema Ax = b se ocorrer | a ii | S i , i 1,..., n diz-se que o mesmo é diagonal
estritamente dominante.
Definição 3: Um sistema Ax=b é irredutível se for impossível obter algum(ns) valor(es)
isolado(s) de sua solução sem resolver o sistema todo.
Por exemplo:
x1 2 x2 x3 4
O sistema x1 x3 2
2 x x 1
3
1
é redutível, uma vez que pode-se obter os valores de x1 e x3
resolvendo-se um sistema de ordem n = 2 correspondente as
duas últimas linhas.
Teorema (Convergência):
Se o sistema A x = b for irredutível e diagonal dominante, ou diagonal estritamente
dominante, então tanto a seqüência construída pelo método de Jacobi, quanto a de GaussSeidel convergem para a solução.
83
Vide exemplos 7 e 8.
Com relação à convergência dos métodos iterativos, algumas características
importantes devem ser salientadas, dentre as quais destacam-se:
1o) A convergência de S = x k
k 0
não depende do valor inicial x0. Portanto, a escolha do x0
adequado afeta apenas na quantidade de iterações a serem efetuadas. Verificar isto, a título de
x x 1
exemplo, em 1 2
x1 2. x2 5
com vários x0 diferentes;
2o) O teorema da convergência contém uma condição suficiente, porém não necessária.
Portanto, se for verdadeiro, a seqüência S convergirá e se não for verdadeiro nada pode-se
x 1 2. x 2 3
x1 3. x 2 2
afirmar. Verificar que em
Gauss-Seidel fornece a seqüência convergente,
mesmo não satisfazendo o teorema;
3o) Um sistema que não seja diagonal dominante, ou diagonal estritamente dominante, pode
em alguns casos ser transformado, através de troca de linhas e/ou colunas (pivotamento
parcial e total), para satisfazer esta condição;
4o) Existem sistemas, muitos até triviais, que não são solúveis por estes métodos iterativos, a
x x 0
menos que x0 = . Testar isto em 1 2
;
x1 x 2 3
5o) A validade da condição suficiente de convergência do teorema citado estende-se também
aos sistemas lineares que são diagonal estritamente dominante sobre as colunas da matriz de
coeficientes.
2. x 3. x 2 5
Verificar que 1
é diagonal estritamente dominante sobre as colunas e portanto
x1 5. x 2 4
tem convergência assegurada.
6o) O teorema da convergência enunciado anteriormente não é o único e nem o mais
abrangente. Verificar na literatura outros critérios de convergência.
6.3.5 - Aplicação de coeficientes de Relaxação
Caso o sistema de equações lineares não satisfaça os critérios de convergência o
processo iterativo poderá oscilar ou até mesmo divergir. Nestes casos pode-se tentar
desacelerar o processo de atualização iterativa usando fatores de sub-relaxação em cada
equação.
Por exemplo, para obter o valor mais atualizado de uma variável x ik1 qualquer, temse
x ik 1 x ik x ik 1
84
onde x ik é o valor antigo, x ik1 é o valor da atualização imposta ao valor antigo x ik para
atingir o valor novo x ik1 .
Caso se queira aplicar um fator de desaceleração, ou amortecimento na atualização do
valor novo, impõe-se um fator de subrelaxação , com 0 1 , da seguinte forma,
x ik 1 x ik x ik 1
Alternativamente, pode-se substituir o valor da atualização total x ik 1 x ik 1 x ik na
equação anterior, o que gera a seguinte forma,
x ik 1 x ik ( x ik 1 x ik )
x ik 1 (1 ) x ik x ik 1
Por exemplo, a aplicação de subrelaxação para o método de Gauss-Seidel gera a seguinte
equação geral,
i 1
x ik 1 (1 ) x ik ( b i a ij x kj 1
j 1
ji
n
a
j i 1
ji
ij
x kj ) / a ii
i = 1,2,...,n
(11)
Ex. 9): Resolver o seguinte sistema pelo método de Gauss-Seidel adotando uma subrelaxação
= 0.5 (lembrando que no exemplo 8 este mesmo sistema foi resolvido e sofreu oscilações).
3x1 x 2 x 3 1
x1 3x 2 x 3 5
2x 2x 4x 4
2
3
1
Montando as equações evolutivas para as variáveis do sistema temos:
x1k+1 (1 ) x1k + (1 x 2k x 3k ) / 3
k+1
k
k 1
k
x 2 = (1 ) x 2 + (5 x1 x 3 ) / 3
k+1
k
k+1
k+1
x 3 = (1 ) x 3 + (4 2x1 2x 2 ) / 4
Note que as equações evolutivas se utilizam dos valores disponíveis mais atualizados.
Valor inicial: ( x10 , x 02 , x 03 ) (0,0,0) e = 0.5
k
0
1
2
3
4
5
6
x1k
x 2k
x 3k
| x1k 1 x1k |
| x 2k 1 x 2k |
| x 3k 1 x 3k |
0
0.166
0.494
0.748
0.896
0.966
0.993
0
0.805
1.043
1.069
1.041
1.014
1.000
0
0.659
0.967
1.063
1.067
1.046
1.024
0.166
0.327
0.254
0.147
0.069
0.026
0.805
0.238
0.025
0.027
0.026
0.014
0.659
0.307
0.096
0.004
0.021
0.021
85
Aplicando o critério (i), tem-se: Max | x ik 1 x ik | 0,026 .
Obs.: Note que o processo iterativo com o fator de subrelaxação é mais estável, gerando um
processo de convergência monotônico (com erro sempre decrescente), e consequentemente
tem-se um processo iterativo mais rápido. Note que com as mesmas 6 iterações do método de
Gauss-Seidel atinge-se um erro máximo de 0,026 com sub-relaxação contra um erro de 0,129
sem sub-relaxação.
Considerações:
(i). A utilização de fatores de sub-relaxação não garante a convergência do processo, mas
pode agilizar esta convergência (vide exemplo 9).
(ii). Se o sistema satisfizer os critérios de convergência, provavelmente não haverá
necessidade de aplicação de fatores de sub-relaxação, pois nestes casos o processo iterativo
normalmente já é monotônico. Em algumas destas situações práticas é possível acelerar o
processo iterativo com o uso de fatores de sobre-relaxação, com 1 2 . Este método de
Gauss-Seidel modificado é conhecido na literatura pertinente como SOR ("Sucessive Over
Relaxation").
(iii). A escolha adequada do fator ( 1 2 ) pode conduzir o processo iterativo a uma
performance ótima, com o menor número possível de iterações. Acima deste fator ótimo o
processo iterativo começa a oscilar, tornando a convergência dificil.
5.4 - Sistemas Lineares Mal Condicionados:
Considere o seguinte sistema linear:
x1 3x 2 4
a).
x1 3.00001x 2 4.00001
cuja solução exata é S = {1,1}
Toma-se agora um sistema de equações derivado do sistema (a), e que sofreu uma
pequena perturbação em dois de seus coeficiente, impondo-se uma variação ao coeficiente a22,
de 3.00001 para 2.99999 e em b2, de 4.00001 para 4.00002, conforme segue:
x1 3x 2 4
b).
x1 2.99999 x 2 4.00002
cuja solução exata é S = {10,-2}
Note que uma pequena variação em dois coeficientes, da ordem de 0.025% acarreta
uma variação enorme de 900% na solução do sistema. Classificam-se estes sistemas altamente
sensíveis a variações nos seus coeficientes como sistemas mal condicionados.
Imagine agora que esta pequena variação é devida a uma perturbação decorrente de
erros de arredondamento, que estão presentes em todo método direto, na manipulação dos
coeficientes das equações. Então, nestes casos pode-se obter soluções irreais, decorrentes de
pequenas alterações nos coeficientes.
86
Por isso, é necessário tomar cuidados especiais na resolução destes sistemas mal
condicionados, devido a grande sensibilidade da solução em relação aos seus coeficientes,
deve-se então conhecer uma maneira de identificar o sistema de equações mal condicionado,
de preferência antes de resolver o sistema. Para isto pode-se recorrer a alguns critérios:
a). Se o determinante da matriz A for considerado relativamente pequeno, ou melhor, se o
determinante normalizado de A ( ||det(A)|| ) for muito pequeno:
||det( A )||
|det( A )|
n
i 1
n
i
a
i 1
2
ij
<< 1 , onde
i
i {1,2,...,n}
Então, se || det(A) || << 1 o sistema é considerado mal condicionado.
Na prática pode-se adotar um limite, onde || det(A) || < 0,1
condicionamento do sistema A x = b.
representa mal
b). Se o número de condicionamento, Cond(A), for considerado muito grande, ou seja:
Cond (A) = || A || . || A-1 || >> 1
Então, se Cond (A) >> 1 o sistema é considerado mal condicionado.
Também para efeitos práticos, pode-se estabelecer que se Cond(A) > 10, então, o
sistema A x = b é mal condicionado.
A norma de A (||A||) estabelecida é definida da seguinte forma:
n
A Max a ij
1 i n
j 1
que corresponde a maior soma dos módulos dos elementos de uma linha da matriz A.
Ex. 10: Avaliar o condicionamento do sistema
x1 3x 2 4
x1 3.00001x 2 4.00001
a). Verificar se ||det(A)|| <<1
det(A) = 0,00001
1 10
2 10
0.00001
=10-6
10 10
||det(A)|| 106 1
||det(A)||
b). Verificar se Cond (A) >> 1
87
|| A|| 4.00001 4
||A 1|| 600001
300001 300000
onde A 1
100000 100000
Cond (A) = 4.00001 . 600001 2,4 . 1011
Cond (A) 2,4 . 1011 >> 10
Exercícios:
8). Avalie o condicionamento do sistema abaixo pelos dois critérios estabelecidos:
x 1 0.5x 2 0,05x 3 1
. x 2 4.75x 3 8
3x 1 15
4 ,01x 2 x 3x 7
1
2
3
Considerações:
(i). Neste caso é interessante usar um método de solução que não altere a forma original das
equações, como é o caso dos métodos iterativos (vide capítulo ). Porém, os métodos
iterativos nem sempre convergem, como visto;
(ii). No caso da necessidade de aplicação de métodos diretos, deveríamos adotar
procedimentos com menor número de operações aritméticas possível, e consequentemente
arredondamentos menores. Neste caso sugere-se a aplicação de métodos diretos de
decomposição LU, que apesar de terem um número total de operações da mesma ordem que o
método de Gauss (O(n3/3) - para o método de Crout), mas acumulam menos erros de
arredondamento, devido a menor influência das operações de divisão.
(iii). O processo de pivotamento é indispensável sempre que surgem zeros nas posições dos
pivôs durante a aplicação das operações elementares, no caso de matrizes de coeficientes não
singulares (det(A) 0). No entanto, nos casos específicos de sistemas mal condicionados, o
processo de pivotação é considerado imprescíndivel e a pivotação normalmente é insuficiente
para estabilizar os efeitos dos arredondamentos, nestas situações recomenda-se o uso da
pivotação total, ou completa, que torna a solução do sistema menos sensível aos efeitos dos
erros de arredondamento.
(iv). Uma forma de minimizar os erros de arredondamento, principalmente em sistemas mal
condicionados, é utilizar a precisão dupla na implementação dos cálculos envolvidos na
resolução do sistema. É interessante resolver o sistema de equações usando precisão simples e
precisão dupla, para depois fazer uma comparação e verificar se os erros decorrentes de
arredondamentos sucessivos é significativo ou não, dependendo da tolerância requerida.
(v). Em sistemas de equações mal condicionados tem-se uma característica peculiar na
avaliação dos resíduos das equações, onde se pode notar que nem sempre a solução mais
exata gera os menores resíduos.
Vamos analisar a seguinte situação prática:
Suponha que temos duas soluções aproximadas S1 e S2 para o sistema apresentado
anteriormente,
88
x 1 3x 2 4
x 1 3.00001x 2 4.00001
onde S1 = {4,0} e S2 = {1.5,1}.
Calculando os resíduos das equações do sistema para cada solução proposta tem-se:
r1 4 ( x 1 3x 2 )
R = {r1,r2}
r2 4.00001 ( x 1 3.00001x 2 )
Para S1 R1 = {0,0.00001} e
para S2 R2 = {0.5,0.5}
Aparentemente, pela avaliação dos resíduos das equações, a solução mais exata é S 1,
pois gera menores resíduos, porém, sabendo que a solução exata é S = {1,1}, conclui-se que a
solução S2 está mais próxima da solução exata do que S1.
Então, conclui-se que a avaliação dos resíduos das equações de um sistema não pode
ser usada como critério para análise da proximidade de uma solução em relação ao seu valor
exato (não pode ser usado como critério de convergência).
(vii). Sabe-se que todos os métodos diretos, de eliminação e de decomposição, geram
soluções com erros de arredondamento, então, quando são avaliados os resíduos das equações
a partir das soluções obtidas, geram-se valores não nulos decorrentes do acúmulo de
arredondamentos ao longo das operações.
Uma forma alternativa para minimização dos efeitos dos arredondamentos sucessivos,
é o chamado processo de refinamentos sucessivos, em que cada solução obtida sofre uma
correção E na direção da solução exata.
Suponhamos que se queira refinar a solução S1 obtida para o sistema Ax = b. Então,
vamos impor uma correção E sobre S1, e supor que esta correção seja suficiente para conduzir
a solução exata s:
S = S1 + E E = S - S1
Multiplicando a matriz A na equação acima temos,
A E = A (S - S1)
A E = A S - A S1
Como S é a solução exata do sistema A x = b, então A S = b e logo,
A E = b - A S1
Sabe-se que b - A S1 corresponde ao resíduo das equações do sistema em relação a
solução proposta S1, tem-se que
r = b - A S1
AE=r
Então, resolvendo o sistema A E = r , obtém-se o valor da correção E, que só não é a
correção exata para a solução, porque os erros de arredondamento ainda estão presentes.
89
Então, na verdade, se obtém uma solução nova (S2) para A x = b, que deve ser mais exata que
S1, conforme segue:
S2 = S1 + E
Caso a solução S2 ainda esta esteja significativamente afetada por erros de
arredondamento, pode-se aplicar novamente o mesmo procedimento de correção, até que a
solução obtida se torne suficientemente próxima da solução exata, para ser adotada como
solução do sistema.
(viii). Uma limitação deste processo de refinamentos sucessivos, além do alto custo, é o fato
dele se utilizar do mesmo procedimento de resolução que gerou os arredondamentos iniciais,
então, estes arredondamentos vão continuar também presentes ao longo do processo de
refinamento.
90