UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
MINERAÇÃO DOS DADOS DA POLÍCIA MILITAR DE SANTA
CATARINA NO MUNICÍPIO DE BALNEÁRIO CAMBORIÚ PARA
GERAÇÃO DE INFORMAÇÃO E CONHECIMENTO NA ÁREA DE
SEGURANÇA PÚBLICA
Área de Mineração de Dados
por
Ricardo Sartori
Benjamin Grando Moreira
Orientador
Itajaí (SC), junho de 2012
UNIVERSIDADE DO VALE DO ITAJAÍ
CENTRO DE CIÊNCIAS TECNOLÓGICAS DA TERRA E DO MAR
CURSO DE CIÊNCIA DA COMPUTAÇÃO
MINERAÇÃO DOS DADOS DA POLÍCIA MILITAR DE SANTA
CATARINA NO MUNICÍPIO DE BALNEÁRIO CAMBORIÚ PARA
GERAÇÃO DE INFORMAÇÃO E CONHECIMENTO NA ÁREA DE
SEGURANÇA PÚBLICA
Área de Mineração de Dados
por
Ricardo Sartori
Relatório
apresentado
à
Banca
Examinadora do Trabalho Técnico
Científico de Conclusão do Curso de
Ciência da Computação para análise e
aprovação.
Orientador: Benjamin Grando Moreira, M.
Eng.
Itajaí (SC), junho de 2012
LISTA DE FIGURAS
Figura 1. Banco de dados de ocorrências, com as tabelas e suas relações. .............................. 48
Figura 2. Modelo dimensional com as tabelas de fatos e suas dimensões. .............................. 50
Figura 3. Distribuição das ocorrências nos anos de 2008 a 2011. ............................................ 53
Figura 4. Distribuição das ocorrências nos meses do ano. ....................................................... 54
Figura 5. Distribuição das ocorrências por dia da semana. ...................................................... 55
Figura 6. Distribuição das ocorrências por tipo de atendimento realizado. ............................. 56
Figura 7. Distribuição das ocorrências de acordo com o número de guarnições empenhadas
para atendimento....................................................................................................................... 57
Figura 8. Distribuição das ocorrências por hora do dia. ........................................................... 58
Figura 9. Distribuição das ocorrências de acordo com o número de pessoas envolvidas e sua
relação com o número de agentes. ............................................................................................ 58
Figura 10. Tempos de empenho e deslocamento médios para ocorrências tipo D, C e A. ...... 61
Figura 11. Distribuição de ocorrências por tipo de veículo utilizado no atendimento e tipos de
atendimentos para o qual foram empenhados. ......................................................................... 63
Figura 12. Resultado do algoritmo simplekmeans no WEKA, com 06 clusters. ..................... 66
Figura 13. Resultado do algoritmo FarthestFirst em pesquisa de segmentos de crimes e
contravenções. .......................................................................................................................... 69
Figura 14. Resultados apresentados pelo algoritmo LinearRegression sobre os parâmetros
passados. ................................................................................................................................... 75
Figura 15. Resultados do algoritmo LinearRegression com parâmetros reduzidos. ................ 75
Figura 16. Resultados de pesquisa de regressão linear: (a) sobre ocorrências de homicídio; (b)
sobre ocorrências de roubo a comércio. ................................................................................... 76
Figura 17. Resultado de experimento com regressão linear para as ocorrências de 'nada
constatado', código D308.......................................................................................................... 77
Figura 18. Resultado da função de regressão linear para previsão de ocorrências de um mês a
partir das ocorrências do mês anterior. ..................................................................................... 78
Figura 19. Matriz de confusão, onde se identifica a forma com que as pessoas foram
classificadas nas ocorrências. ................................................................................................... 79
Figura 20. Matriz de confusão retornada pelo JRIP em pesquisa por tipo de envolvimento. .. 80
Figura 21. Matriz de confusão do classificador J48graft para o alvo descrição da ocorrência
(atributo descricao_ocorrencia) ................................................................................................ 82
Figura 22. Matriz de confusão calculada pelo OneR, que classificou o grau de envolvimento
da pessoa baseado no tipo de ocorrência. ................................................................................. 85
Figura 23. Ocorrências da Central 190 exportadas em formato texto. ..................................... 86
Figura 24. Roteiros de viaturas exportados no formato texto pelo sistema EMAPE. .............. 87
LISTA DE QUADROS
Quadro 1. Comparativo entre os sistemas e projetos que utilizam IA e técnicas associadas para
auxiliar a tomada de decisão em segurança pública. ................................................................ 45
Quadro 2. Distribuição das ocorrências atendidas de acordo com as atividades realizadas. ... 55
Quadro 3. Parâmetros utilizados na pesquisa com algoritmo SimpleKMeans. ........................ 64
Quadro 4. Parâmetros usados para pesquisa com o algoritmo FarthestFirst em ocorrências de
crime e contravenções (C). ....................................................................................................... 67
Quadro 5. Parâmetros utilizados para realizar pesquisa de associação com algoritmo
PredictiveApriori em ocorrências de homicídio tentado e consumado. ................................... 70
Quadro 6. Parâmetros utilizados para realizar pesquisa de associação em ocorrências de
homicídio - consumado e tentado. ............................................................................................ 71
Quadro 7. Parâmetros usados para realizar pesquisa na base de pessoas envolvidas, sobre
ocorrências de homicídio - tentado e consumado. .................................................................... 72
Quadro 8. Parâmetros de experimento de associação com algoritmo Apriori, sobre a base de
dados de pessoas envolvidas em ocorrências de roubo. ........................................................... 73
Quadro 9. Variáveis utilizadas para experimento de predição com regressão linear. .............. 74
Quadro 10. Variáveis utilizadas no WEKA para pesquisa de classificação com algoritmo
RotationForest. ......................................................................................................................... 78
Quadro 11. Resultados apresentados pelo algoritmo RotationForest em pesquisa por pessoas
envolvidas em ocorrência. ........................................................................................................ 79
Quadro 12. Parâmetros repassados ao algoritmo JRIP para classificação por tipo de
envolvimento de pessoa. ........................................................................................................... 79
Quadro 13. Resultado emitido pelo algoritmo JRIP na classificação por nível de envolvimento
das pessoas ................................................................................................................................ 80
Quadro 14. Parâmetros utilizados na pesquisa de classificação sobre ocorrências de crimes
contra patrimônio. ..................................................................................................................... 81
Quadro 15. Resultados da classificação realizada com uso do algoritmo J48graft. ................. 81
Quadro 16. Valores utilizados na pesquisa de classificação com o algoritmo JRIP. ............... 82
Quadro 17. Resultado retornado pelo algoritmo JRIP. ............................................................. 83
Quadro 18. Argumentos utilizados no classificador OneR, para classificar as pessoas na
categoria de tipo de envolvimento. ........................................................................................... 83
Quadro 19. Algumas das regras criadas pelo algoritmo OneR, classificando as pessoas de
acordo com o tipo de ocorrência. ............................................................................................. 84
Quadro 20. Resultados retornados pelo algoritmo OneR. ........................................................ 85
Quadro 21: Forma de notação adotada na pesquisa. ................................................................ 90
Quadro 22. Tabela ocorrência. ............................................................................................... 101
Quadro 23. Tabela ocorrencia_codigo.................................................................................... 102
Quadro 24. Tabela ocorrencia_envolvido. ............................................................................. 102
Quadro 25. Tabela ocorrencia_guarnicao. .............................................................................. 103
Quadro 26. Tabela end_log. ................................................................................................... 103
Quadro 27. Tabela end_bairro. ............................................................................................... 103
Quadro 28. Tabela municipio. ................................................................................................ 104
Quadro 29. Tabela ocorrencia_viatura_evento. ...................................................................... 104
SUMÁRIO
1. INTRODUÇÃO .................................................................................................................. 10
1.1 PROBLEMATIZAÇÃO ..................................................................................................... 13
1.1.1 Formulação do Problema .............................................................................................. 13
1.1.2 Solução Proposta ........................................................................................................... 16
1.2 OBJETIVOS ....................................................................................................................... 16
1.2.1 Objetivo Geral ............................................................................................................... 16
1.2.2 Objetivos Específicos ..................................................................................................... 16
1.3 METODOLOGIA ............................................................................................................... 17
1.4 ESTRUTURA DO TRABALHO ....................................................................................... 18
2. FUNDAMENTAÇÃO TEÓRICA ..................................................................................... 19
2.1 DADOS ............................................................................................................................. 19
2.2 INFORMAÇÃO ................................................................................................................. 20
2.3 CONHECIMENTO ............................................................................................................ 21
2.4 DESCOBERTA DO CONHECIMENTO .......................................................................... 22
2.4.1 Seleção ............................................................................................................................ 23
2.4.2 Preparação dos dados.................................................................................................... 24
2.4.3 Transformação ............................................................................................................... 24
2.4.3.1 SGBD Operacional ....................................................................................................... 25
2.4.3.2 Data Warehouse ............................................................................................................ 26
2.4.3.3 Data Mart ...................................................................................................................... 26
2.4.4 Mineração de dados ....................................................................................................... 27
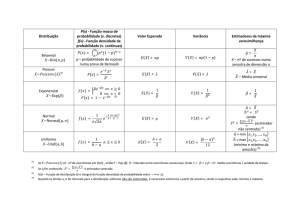
2.4.4.1 Classificação ................................................................................................................. 29
2.4.4.2 Estimativa ..................................................................................................................... 30
2.4.4.3 Predição ........................................................................................................................ 31
2.4.4.4 Agrupamento ................................................................................................................ 32
2.4.4.5 Segmentação ................................................................................................................. 33
2.4.4.6 Descrição ...................................................................................................................... 34
2.4.5 Interpretação e avaliação .............................................................................................. 34
2.5 UTILIZAÇÃO DE TÉCNICAS DE DESCOBERTA DE CONHECIMENTO NA
ATIVIDADE POLICIAL ......................................................................................................... 34
2.5.1 Ensino de investigação e elaboração de perfis de crimes utilizando raciocínio
baseado em casos e aprendizagem cognitiva ........................................................................ 35
2.5.2 Mineração de dados e utilização de sistemas especialistas em agências responsáveis
pela aplicação das leis ............................................................................................................. 36
2.5.2.1 Coplink ......................................................................................................................... 37
2.5.2.2 Sherpa ........................................................................................................................... 38
2.5.2.3 Matrix ........................................................................................................................... 38
2.5.2.4 Vicap............................................................................................................................. 39
2.5.2.5 Viclas ............................................................................................................................ 39
2.5.3 Mineração de dados na atividade forense ................................................................... 40
2.5.3.1 Redes neurais na identificação de amostras de cocaína ............................................... 41
2.5.3.2 FAIS ............................................................................................................................. 41
2.5.4 Mineração de regras de associação em bases policiais no Estado do Pará .............. 42
2.5.5 Mineração de dados na base de inquéritos policiais do Ministério Público do
Amapá
.............................................................................................................................. 43
3. DESENVOLVIMENTO..................................................................................................... 46
3.1 CENTRAL REGIONAL DE EMERGÊNCIAS 190 DE BALNEÁRIO CAMBORIÚ .... 46
3.2 BASE DE DADOS ............................................................................................................. 47
3.3 MINERAÇÃO DE DADOS ............................................................................................... 50
3.3.1 A ferramenta WEKA .................................................................................................... 51
3.3.2 Pré-processamento......................................................................................................... 53
3.3.3 Clusterização .................................................................................................................. 64
3.3.3 Associação ...................................................................................................................... 69
3.3.4 Predição .......................................................................................................................... 74
3.3.5 Classificação ................................................................................................................... 78
3.4 METODOLOGIA PARA MINERAÇÃO DE DADOS DAS OCORRÊNCIAS DA
PMSC
............................................................................................................................. 85
4. CONCLUSÃO..................................................................................................................... 91
REFERÊNCIAS BIBLIOGRÁFICAS ................................................................................. 96
APÊNDICE A – Dicionário de dados dos registros de ocorrências importados da Central
190 de Balneário Camboriú para banco de dados SQL – MySQL. ................................. 101
ANEXO A – Autorização do Comando Regional da 3ª Região de Polícia Militar para uso
da base de dados de ocorrências da Central Regional de Emergência 190 de Balneário
Camboriú ............................................................................................................................ 105
LISTA DE ABREVIATURAS
ARFF
AT
CRE
CRE190
DM
DW
EMAPE
FAIS
FinCEN
FBI
GM
GNU
GPL
IA
KDD
KDT
MATRIX
PM
PMSC
RBC
SGBD
TCC
UNIVALI
WEKA
VICAP
VICLAS
Atribute Relation File Format
Agentes de Trânsito
Central Regional de Emergência
Central Regional de Emergência 190
Data mart
Data warehouse
Estação Multitarefa para Atendimento Policial e Emergências
FinCEN Artificial Intelligence System
Financial Crime Enforcement Network
Federal Bureau of Investigation
Guarda Municipal
GNU's not UNIX
GNU General Public License
Inteligência Artificial
Knowledge Discovery in Database
Knowledge Discovery in Text
Multistate Anti-Terrorism Information Exchange Program
Polícia Militar
Polícia Militar de Santa Catarina
Raciocínio Baseado em Casos
Sistema Gerenciador de Banco de Dados
Trabalho de Conclusão de Curso
Universidade do Vale do Itajaí
Waikato Environment for Knowledge Analysis
Violent crime apprehension program
Violent crime linkage analysis system
RESUMO
SARTORI, Ricardo. Mineração dos dados da Polícia Militar de Santa Catarina no
Município de Balneário Camboriú para geração de informação e conhecimento na área
de segurança pública. Itajaí, 2012. 108 f. Trabalho de Conclusão de Curso (Graduação em
Ciência da Computação) – Centro de Ciências Tecnológicas da Terra e do Mar, Universidade
do Vale do Itajaí, Itajaí, 2012.
Temos, atualmente, vivenciado um momento de cobrança da população por políticas de
segurança pública eficientes e eficazes, que tenham o condão de diminuir os índices de
criminalidade do país. A Polícia Militar, como instituição permanente, é parte integrante do
sistema de segurança do país, pois tem a missão constitucional de preservação da ordem
pública. Tal missão é bastante ampla, e reflete-se diretamente nas atividades que a PM
desempenha diuturnamente. Associado a este grande rol de atividades, a capilaridade dos
atendimentos policiais gera uma grande quantidade de dados, que são armazenados em
sistemas informatizados próprios da instituição. Contudo, em que pese a quantidade de dados,
relativamente poucos são utilizados para gerar informação e, menos ainda, para gerar
conhecimento. As ferramentas de KDD (descoberta de conhecimento em bases de dados)
podem ser poderosas aliadas no estudo, avaliação e análise de tais dados, proporcionando aos
gestores de segurança pública conhecimento e informação útil, que pode se refletir em um
melhor desempenho nas atividades da Polícia Militar. Assim, o trabalho estudou e aplicou
técnicas de descoberta de conhecimento e mineração de dados nos dados da Polícia Militar,
quando de seus atendimentos na cidade de Balneário Camboriú. As técnicas de associação,
clusterização, predição e classificação foram utilizadas, e com sua aplicação foi possível o
bter conhecimentos e informações úteis a partir dos registros de ocorrências da PM.
Palavras-chave: Conhecimento, KDD, descoberta de conhecimento, mineração de dados,
segurança pública, Polícia Militar.
ABSTRACT
Currently, we live in times where the population questions the government about efficient
public safety politics, which can low the crime rates in the country. The Military Police is a
permanent institution and part of Brazil’s security system, as its constitutional mission is to
preserve the public order. This mission is very ample, and has straight reflects in the
activities that the PM does every day and night. Along with this big number of activities, the
capillarity of the police calls creates a dense quantity of data, which are stored in the
institution computer systems. However, despite this huge amount of data, just a few are used
to generate information, and fewer to discover knowledge. The KDD (knowledge discovery in
database) tools are powerful allies to study, evaluate and analyze this data, providing the
public safety managers with knowledge and information, that can reflect in a better
performance in the Military Police activities. So, this project seeks to study and apply
knowledge discovery and data mining techniques in the Military Police data, in the calls in
the Balneário Camboriú city, trying to reveal if it is possible to obtain useful knowledge and
information from these records.
Keywords: Knowledge, KDD, knowledge discovery, data mining, public safety, Military
Police.
10
1. INTRODUÇÃO
Vive-se, atualmente, um clamor da população para que os recursos em segurança
pública sejam incrementados, de forma a conter a sensação de insegurança que tem acometido
certas comunidades. Apesar dos esforços das autoridades, percebe-se que determinados
investimentos são feitos de maneira empírica, de acordo com uma agenda política, sem
obedecer a qualquer tipo de estudo ou técnica associada. Soares (2004, p.1), em seu artigo,
nos dá um diagnóstico bastante preciso quando o tema é a politização das atividades de
segurança pública:
Em outras palavras, são muitas as razões pelas quais as reformas policiais
não têm avançado, no Brasil, mesmo quando os diagnósticos que as
precedem e justificam são amplamente apoiados pela opinião
qualificada e ainda que os planos a que correspondem sejam publicamente
aprovados pelas lideranças políticas responsáveis.
Consideremos, neste artigo, apenas dois fatores: (1) a hiper-politização da
segurança pública, no Brasil, e a manipulação instrumental, oportunista,
demagógica e populista da segurança, enquanto tema da agenda pública. […]
(grifo do autor)
Além do abordado acima, nota-se também uma certa defasagem no que concerne ao
desenvolvimento de informações e conhecimentos com base nos dados colhidos pelos
policiais, que poderiam fornecer um diagnóstico mais técnico e apurado sobre a segurança
pública em uma determinada região. Vasco Furtado, ao destacar os cuidados que o gestor em
segurança pública deve ter ao realizar investimentos em tecnologia da informação, traz o
seguinte à tona:
“Continuamos sem informações confiáveis para tomada de decisão e assim fica
fácil perceber que continuamos aplicando mal os recursos ou tendo pouco retorno prático do
que tem sido investido.” (FURTADO, 2007, p. 1, grifo do autor).
Hawk e Chen (1999, p.1), ao estudarem os sistemas informatizados da Polícia da
cidade norte-americana de Tucson, Arizona, descreveram que:
Muitos dos sistemas gerenciadores de registros das agências responsáveis
pela aplicação da lei possuem uma grande quantidade de dados para cada
caso ou incidente, mas apesar destes dados estarem disponíveis, não se
apresentam numa forma que os permitam ser utilizados para processamento
de maior nível.1
1
Many record management systems for law enforcement agencies contain a large amount of data for
each case or incident, but although data may be available, they are not available in a form that makes them useful
for higher level processing.
11
Segundo Freitas (2000), convivemos permanentemente com um grande volume de
dados que estão disponibilizados através das tecnologias de informação. Tais dados vão, em
um momento posterior, ser utilizados para gerar informação.
“Entende-se como dados o conjunto de elementos que expressa um fato isolado gerado
por uma atividade que pode ser controlada, ou seja, tudo que é gerado no dia-a-dia da empresa
é um dado.” (BATISTA, 2006, p. 20).
Na Polícia Militar, cada ligação para as Centrais de Emergência 190 gera um evento
isolado que pode ser considerado dado. O atendimento da ocorrência pelos Policiais Militares,
a interação com o cidadão, com veículos, presos, outras Instituições, em suma, toda a rotina
Policial Militar gera uma quantidade extra de dados que fica armazenado na Central. Os
Boletins de Acidente de Trânsito e demais documentos também são inseridos em sistemas
informatizados, permanecendo armazenados em computadores. Verifica-se, entretanto, que
apesar da grande quantidade de dados que a Polícia Militar detém, há muito pouca informação
ou conhecimento produzido a partir de tais registros.
A partir do momento em que os dados sofrem algum tipo de processamento ou análise,
e trazem a este conjunto de símbolos isolados um significado que previamente não era visível,
eles passam a ser chamados de informação (SARTORI, 2007, p.20).
A informação, nos dias atuais, passou a ser considerada um capital precioso,
equiparando-se aos recursos de produção, materiais e financeiros (MORESI, 2000).
Bezerra (2006, p. 1), é enfático ao destacar a importância da informação:
No decorrer da história, diversos tipos de bens serviram de base para o
desenvolvimento da economia. Propriedade, mão-de-obra, máquinas e
capital são exemplos desses bens. Atualmente está surgindo um novo tipo de
bem econômico: a informação. Nos dias de hoje, a empresa que dispõe de
mais informações sobre seu processo de negócios está em vantagem em
relação a suas competidoras.
Apesar da importância atual, há falta de informação consistente e trabalhada sobre os
dados da Polícia Militar com relação aos seus atendimentos e a sua própria rotina operacional
e administrativa.
Grande parte das Unidades Operacionais da Polícia Militar (Batalhões, Companhias e
Pelotões), possuem setores ou policiais encarregados pela elaboração de estatísticas criminais.
Contudo, as informações geradas são pontuais, geralmente para atender o anseio da
comunidade ou da imprensa, que deseja conhecer os índices de criminalidade da região.
Assim, se a comunidade reclama em virtude dos furtos ou roubos noticiados na mídia, este
12
setor é responsável por compilar estatísticas que demonstrarão que os números divulgados são
reais ou não, e ainda fornecer informações complementares, como, por exemplo, se o número
de prisões por estes tipos de crimes também aumentaram.
Por vezes tais informações são utilizadas para direcionar o policiamento ou adequar as
escalas de serviço, mas raramente possuem um impacto mais profundo e estratégico na
tomada de decisões pelos Gestores da Polícia Militar.
Há de se ressaltar, também, que tais estatísticas estão baseadas quase que somente nos
registros das Centrais de Emergência (190), que gravam as ligações e possuem dados
referentes aos atendimentos da Polícia Militar. Desta forma, não levam em consideração
variáveis externas que podem ter influência nos índices, como: condições climáticas,
condições de iluminação e salubridade das vias públicas, se é ambiente residencial, comercial
ou industrial e até mesmo as condições sociais da localidade. Pouco se explora, também, as
variáveis relacionadas ao policial militar em si, seu equipamento, viatura, distância
percorrida, tempo de resposta para atendimento, tempo de atendimento e duração do turno de
serviço.
Miranda (1999) destaca que informação é um grupo de dados organizados de modo
significativo, sendo subsídio útil à tomada de decisão. Desta forma, para uma melhor gestão
dos recursos públicos, bem como uma resposta mais eficiente para a demanda por segurança
pública, é necessária a produção de informação consistente e útil a partir dos dados
disponíveis.
O conhecimento, que para Rodrigues (2006) é originado a partir de uma série de
informações bem estruturadas e organizadas a ponto de transmitir discernimento,
experiências, aprendizagem acumulada e habilidade para aplicação em um possível problema,
também é escasso na área de segurança pública. Com a geração de informações confiáveis e
úteis, fica mais fácil produzir conhecimento em segurança pública.
Para a obtenção de informações e conhecimentos, adotaram-se técnicas de mineração
de dados. Para a aplicação da mineração de dados foi necessário realizar a estruturação dos
dados em data mart para posterior análise e produção de dados. O processamento e produção
de informações e conhecimentos a partir de tais registros necessitou de técnicas automatizadas
e especializadas, que em seu conjunto podem ser denominadas mineração de dados.
O processo de mineração de dados, para Groth (1998, apud Fernandes, 2005) é aquele
responsável pela descoberta automática de informações. Em contrapartida, Ávila (1998)
descreve mineração de dados como parte integrante de um processo maior. Para o estudioso,
13
data mining diz respeito à aplicação de algoritmos para a extração de padrões de dados, sendo
parte integrante de uma atividade maior, denominada KDD (Descobrimento de Conhecimento
em Bases de Dados – Knowledge Discovery in Database).
Polito (1997, apud Fernandes, 2005) define data mining como:
“[...] técnica que permite buscar em uma grande base de dados, informações que,
aparentemente, estão camufladas ou escondidas, o que permite agilizar as tomadas de
decisões.”
Foi o que se pretendeu com a presente pesquisa: revelar informações que, mascaradas
pela grande quantidade de dados disponíveis, estão aparentemente ocultas. Este trabalho
acadêmico, portanto, buscou analisar as bases de dados disponíveis na Polícia Militar do
Município de Balneário Camboriú com o intuito de gerar informação e conhecimento na área
de segurança pública, por meio de técnicas de mineração de dados.
O sistema EMAPE (Estação Multitarefa Atendimento Policial e Emergências) é o que
está sendo usado atualmente na Polícia Militar para a gravação e gerenciamento das
ocorrências policiais no Município de Balneário Camboriú. Tal sistema oferece um módulo
que gera informações estatísticas básicas, como maior incidência de ocorrências em ruas,
bairros, dias e horários. Contudo, há carência de informações mais aprofundadas, que possam
revelar a dinâmica das ocorrências, criminais ou não, e dos próprios atendimentos da Polícia
Militar neste Município.
O pesquisador atua como Oficial de Polícia na cidade de Balneário Camboriú e
reconhece a escassez de informações sobre a segurança pública na região. A aplicação de
informações e conhecimento de forma estratégica, obtidas por meio de processos de
mineração de dados, pode resultar na aplicação mais eficiente do policiamento, auxiliando a
prevenção de delitos e um incremento na sensação de segurança proporcionada à sociedade.
1.1 PROBLEMATIZAÇÃO
1.1.1 Formulação do Problema
A Polícia Militar é órgão que faz parte do sistema de segurança pública brasileiro, este
definido no art. 144 da Constituição Federal. Sua missão de preservar a ordem pública está
insculpida no §5° do mencionado artigo. Assim, lê-se que:
14
“§ 5º - às polícias militares cabem a polícia ostensiva e a preservação da ordem
pública; aos corpos de bombeiros militares, além das atribuições definidas em lei, incumbe a
execução de atividades de defesa civil.”
As missões de polícia ostensiva e preservação da ordem pública, contudo, revestem-se
de altíssima complexidade, como nos ensina Lazzarini (1999, p. 61):
[...] às Polícias Militares, instituídas para o exercício da polícia ostensiva e
preservação da ordem pública, compete todo o universo policial, que não
seja atribuição constitucional prevista para os demais seis órgãos elencados
no mesmo art. 144 da Constituição da República vigente.
Álvaro Lazzarini (1999, p. 61) segue com seu raciocínio:
“No tocante à preservação da ordem pública, com efeito, às Polícias Militares não
cabe só o exercício da polícia ostensiva, cabendo-lhe também a competência residual de
exercício de toda atividade policial de segurança pública não atribuída aos demais órgãos.”
Às Polícias Militares dos Estados cabe, então, executar uma série de atividades não
relacionadas diretamente à repressão criminal. Para que se possa prevenir atos criminosos,
evitando com que os mesmos aconteçam, é necessário desencadear operações, fiscalizações,
buscas pessoais e veiculares, blitzes, apoiar outras instituições e planejar a segurança em
eventos.
Na atividade repressiva, registram-se as atividades ilícitas flagradas pelos policiais
militares durante sua labuta, bem como as denunciadas pela população através do telefone
190. Entretanto, como já descrito, à PM cabe uma série de atividades de preservação da
ordem pública que não está diretamente relacionada à segurança pública e que não pode ser
desempenhada pelos demais órgãos. Neste sentido, pode ser verificado nos registros de
ocorrência policial a existência de atividades extras, tais como: primeiro atendimento nos
acidentes de trânsito, verificação de animais soltos em vias, auxílio a pessoas enfermas,
combate à incêndios, atividades de defesa civil, dentre outras.
Apesar do grande rol de atividades da PM, grande parte delas é registrada através da
Central 190. A Diretriz 006/CmdoG/2002, define o serviço emergência 190:
O serviço EMERGÊNCIA 190 destina-se exclusivamente ao recebimento e
atendimento de chamadas de emergência. Foi estruturado para receber,
através do sistema telefônico e despachar, através do sistema de rádio-
15
comunicação, as solicitações das comunidades, feitas pelos cidadãos que
desejam comunicar atos delituosos e/ou situações críticas que ofereçam risco
à vida, ao patrimônio, e à incolumidade pública.
E, ainda, segundo tal normativa da Polícia Militar, a geração de ocorrência é dever do
atendente, seja ele funcionário civil ou militar, cabendo ao mesmo:
d. Ao Atendente compete:
1) [...]
2) Ligar-se ao sistema telefônico;
3) Atender ao telefone 190;
4) Registrar todas as chamadas recebidas;
5) […] (Diretriz 006/CmdoG/2002).
Desta forma, foi desenvolvido um Sistema que pudesse gravar tais dados, de tal forma
que o registro das ocorrências pudesse se perenizar durante o tempo, e sempre que necessário,
pudesse ser consultado. O Sistema EMAPE, sigla para Estação Multitarefa para Atendimento
Policial e Emergências, é o responsável, na Polícia Militar de Santa Catarina, pelo
gerenciamento do atendimento e despacho das ocorrências e emergências (RODRIGUES,
2006, p. 89).
Em Balneário Camboriú, a Central de Emergências 190 integra a Guarda Municipal,
os Agentes de Trânsito e o SAMU (Serviço de Atendimento Médico de Urgência), além da
PM. Nesta Central, que atende os municípios de Balneário Camboriú, Camboriú, Itapema,
Porto Belo e Bombinhas, são recebidas cerca de 700 ligações por dia e são geradas, em média
300 ocorrências para atendimento policial.
De 1° de janeiro de 2008 a 31 de dezembro de 2011, foram registradas na Central de
Emergências 190 de Balneário Camboriú um total de 187.000 registros de ocorrência, as
quais possuem os seguintes campos: data, horário, logradouro, número do imóvel, bairro, tipo
de ocorrência, histórico inicial, histórico final, guarnições envolvidas, nome das partes, sua
idade, sexo e tipo de envolvimento.
Apesar da massiva quantidade de dados gerados, há pouca investigação detalhada
sobre suas variáveis. O Sistema EMAPE oferece um módulo estatístico que contém relatórios
operacionais, que fornecem estatísticas básicas relacionadas a logradouros, bairros, tipos de
ocorrência, relatórios de viaturas, dentre outros. Contudo, há carência de um processo mais
elaborado de geração de informação e conhecimento com base em tais registros.
16
1.1.2 Solução Proposta
A solução proposta tinha como meta aplicar técnicas de mineração nos dados
registrados na Central de Emergências 190 de Balneário Camboriú, referentes aos registros
desta cidade, de tal forma que fosse possível gerar informação e conhecimentos relevantes,
auxiliando no processo de tomada de decisão. Tais informações tiveram o condão de revelar
problemas desconhecidos, trazendo à luz relações, associações, características, perfis básicos
de tipos de atendimentos, pessoas, horários e localização das ocorrências. Desta forma, os
gestores da Polícia Militar podem fazer uso de tal informação para gerar conhecimento sobre
segurança pública e aplicá-los na área, direcionando recursos ou efetivo de acordo com as
necessidades evidenciadas.
1.2 OBJETIVOS
1.2.1 Objetivo Geral
Este trabalho teve como objetivo geral aplicar técnicas de mineração em dados da
Polícia Militar de Balneário Camboriú para auxiliar o processo de tomada de decisão e de
aplicação de recursos e efetivo na atividade de segurança pública.
1.2.2 Objetivos Específicos
Identificar, junto à Diretoria de Tecnologia de Informação da PMSC, os dados
armazenados naquele setor, bem como sobre a existência de ferramentas de mineração de
dados, existência de data warehouses ou data marts em uso na Polícia Militar;
Pesquisar soluções existentes e casos de uso de mineração de dados em bases
de dados policiais com o objetivo de formar informação e conhecimento sobre segurança
pública em um determinado local;
Pesquisar técnicas de mineração de dados para aplicação nas bases de dados
disponibilizadas pela DTI/PMSC (Diretoria de Tecnologia de Informação).
Trabalhar os dados disponibilizados pela DTI, de acordo com as metodologias
de mineração de dados estudadas, de tal forma a obter informação e conhecimento sobre
segurança pública no município de Balneário Camboriú.
17
Documentar as atividades realizadas, bem como as estratégias adotadas para
seleção e busca de informações, de maneira a se produzir uma metodologia a ser adotada
pelas Corporações Policiais ou por outros pesquisadores.
1.3 METODOLOGIA
A pesquisa em tela teve como prática inicial a realização de pesquisa bibliográfica, na
qual se levantou “[...] toda a bibliografia já publicada, em forma de livros, revistas,
publicações avulsas e imprensa escrita. Sua finalidade é colocar o pesquisador em contato
direto com tudo aquilo que foi escrito sobre determinado assunto [...]” (MARCONI;
LAKATOS, 2006, p. 44).
Nesta fase, foram ampliados os conhecimentos na área de inteligência artificial,
mineração de dados e descoberta de conhecimento em bases de dados. Tal pesquisa embasou
o restante do trabalho, que se desenvolveu de acordo com as metodologias de descoberta de
conhecimento levantadas.
No decorrer do trabalho foram realizadas as seguintes etapas: seleção dos dados,
preparação, transformação, mineração de dados e análise e avaliação dos resultados.
Os dados foram selecionados e migrados para uma base de dados SQL. Posteriormente
foram tratados e preparados, eliminando registros inúteis ou incompletos. Foram verificadas
incongruências e valores incorretos, tornando possível que as etapas seguintes fossem
desenvolvidas com dados completos e com um formato adequado.
Na transformação, foi elaborado um data mart, conforme modelo dimensional que
será apresentado. Os dados foram convertidos e adequados para que pudessem ser trabalhados
pelos algoritmos da ferramenta WEKA. Desta forma o data mart continha dados relevantes
que se encontravam dispersos na grande quantidade de dados de entrada. Os dados foram
normalizados, agrupados e convertidos em formatos que possam ser entendidos pelo WEKA e
melhor visualizados e compreendidos pelas pessoas.
A etapa de mineração de dados consistiu primeiramente na aplicação de técnicas de
associação, classificação, predição e estimativa na base de dados, que foram automaticamente
seguidas pelas fases de análise e interpretação dos resultados obtidos. Como se vislumbrará na
fundamentação teórica, todo este processo é incremental e iterativo, podendo-se iniciar o ciclo
18
de mineração desde o seu início. Assim, este ciclo de mineração acabou por ser repetido
diversas vezes, até que se pudesse chegar a conclusões coerentes e com conhecimento
relevante.
1.4 ESTRUTURA DO TRABALHO
O trabalho será apresentado em quatro capítulos distintos: introdução, fundamentação
teórica, desenvolvimento e conclusões.
No capítulo introdutório, abordaram-se conceitos superficiais acerca do trabalho em si,
apresentando o problema de pesquisa, explanando seus objetivos (geral e específicos), a
solução proposta, sempre tratando a realidade dos sistemas de mineração de dados na área de
segurança pública em Balneário Camboriú.
O segundo capítulo compreendeu a pesquisa bibliográfica, na qual o autor trabalhou os
conceitos de dados, informação, conhecimento e descoberta do conhecimento. Neste mesmo
caminho, introduziu e descreveu as etapas do processo de descoberta de conhecimento em
bases de dados, revelando a etapa de mineração de dados e apresentando ainda como este
processo é utilizado em situações reais.
Entendidos os principais conceitos, no terceiro capítulo foi abordada a realidade da
cidade de Balneário Camboriú, por meio de um estudo de caso da Central de Emergência 190
do município, que armazena as ocorrências geradas pelos cidadãos e que são atendidas pela
Polícia Militar. Foi demonstrado como se encontram organizados os dados importados da
Central 190, bem como a modelagem realizada em tais dados de tal forma que possam ser
trabalhados na forma de um data mart.
No capítulo final, serão apresentadas as conclusões, momento que em que será
verificado se os objetivos previstos foram atingidos, analisando os resultados obtidos, as
dificuldades enfrentadas no decorrer da pesquisa e a possibilidade de trabalhos futuros.
19
2. FUNDAMENTAÇÃO TEÓRICA
O conceito de mineração de dados é relativamente novo, tendo em vista que tal
atividade só passou a ser desenvolvida com a existência de grandes bancos de dados e a
necessidade de busca de informação útil em tais registros.
Contudo, faz-se necessário entender os conceitos de dados, informação e
conhecimento para uma melhor compreensão das tarefas associadas, e antes de ser
introduzido o conceito de mineração de dados e descoberta de conhecimento.
2.1 DADOS
O conceito de dados é bastante amplo e, apesar de estar bastante associado à área de
Tecnologia de Informação, não é restrito a ela. Neste sentido, Batista (2006, p. 20) assevera
que dados são conjuntos de “[...] elementos que expressa um fato isolado gerado por uma
atividade que pode ser controlada, ou seja, tudo que é gerado no dia-a-dia da empresa é um
dado.”
Laudon e Laudon (2001) seguem no mesmo rumo ao definir dados como fatos brutos
que estão acontecendo no momento ou aconteceram em um momento anterior.
O dado é um “elemento da informação, um conjunto de letras, números ou dígitos,
que, tomado isoladamente, não transmite nenhum conhecimento, ou seja, não contém um
significado claro.” (REZENDE; ABREU, 2000, p. 60).
Apesar de possuir um significado pouco claro, os dados, no seu conjunto, podem ser
trabalhados de tal forma que passem a representar fatos que, organizados e ordenados de
forma significativa, tornam-se informação (STAIR; REYNOLDS, 2006, p. 4).
Segundo tais definições, pode-se dizer que o dado é um fato bruto, um registro de
determinada situação ou evento, não necessariamente digitalizado, que possui pouco
significado por si só, mas que pode ser trabalhado em seu conjunto e transformado em
informação.
20
2.2 INFORMAÇÃO
Como visto, a partir do momento em que os dados sofrem algum tipo de
processamento ou análise, e trazem a este conjunto de símbolos isolados um significado que
previamente não era visível, eles passam a ser chamados de informação (SARTORI, 2007).
Assim como o conceito de dados, a definição de informação é bastante ampla e
complexa, tendo inúmeras definições na literatura.
“Informação não é, na verdade, um conceito único, singular, mas, sim, uma série de
conceitos conectados por relações complexas.” (ARAÚJO, 1995, p. 4).
Na área de Tecnologia de Informação e Ciências da Computação, contudo, é possível
estabelecer um conceito menos abrangente, restrito as peculiaridades da ciência em questão.
Neste norte, Rodrigues (2006, p. 26) e Miranda (1999, p. 2) asseveram que a informação
constitui-se de dados organizados, classificados e processados de forma a terem significado.
Daí surge a importância da informação: ao ter significado, passa a ter valor e ser útil a
tomada de decisão. Neste sentido, é farta a literatura ao destacar o peso dado às informações
atualmente.
A informação tornou-se uma necessidade crescente para qualquer setor da
atividade humana e é-lhe indispensável mesmo que a sua procura não seja
ordenada ou sistemática, mas resultante apenas de decisões casuísticas e/ou
intuitivas.
Uma empresa em atividade é, por natureza, um sistema aberto e interativo
suportado por uma rede de processos articulados, onde os canais de
comunicação existentes dentro da empresa e entre esta e o seu meio
envolvente são irrigados por informação (BRAGA, 2000, p. 1).
Tal importância é revelada por Moresi (2000 apud CARMO FILHO, 2009) ao levantar
os problemas relacionados ao não conhecimento das informações:
[...] desarticulação dos vários componentes do sistema em decorrência da
modificação em ritmo acelerado da informação; desconhecimento do
funcionamento da organização e do meio ambiente o qual ela pertence;
problemas organizacionais por conta das mudanças não elaboradas e
desconhecimento da estrutura e do fluxo de informações, bem como do
capital intelectual da organização.
O valor da informação está diretamente ligado ao modo com que auxilia os tomadores
de decisão a alcançar as metas da sua organização (STAIR; REYNOLDS, 2006, p. 4).
21
Pode-se inferir, portanto, que as informações revestem-se de grande importância
dentro de uma empresa ou instituição, pois possuem significado e com isto, podem ser
utilizadas pelos gestores para embasar ou direcionar suas decisões.
2.3 CONHECIMENTO
A definição de conhecimento, bem como a de dados e informação, encontra diversos
significados. Contudo, é possível estabelecer através de pesquisas já desenvolvidas, e para
consecução dos objetivos deste trabalho acadêmico, um rumo a ser seguido para a definição
de tal conceito.
É importante enfatizar, segundo Rodrigues (2006) que o conhecimento origina-se a
partir de uma série de informações que foram bem estruturadas e organizadas a tal ponto que
passam a transmitir discernimento, experiências, aprendizagem acumulada e habilidade para
aplicação em um possível problema.
Fernandes (2005, p. 5) estabelece uma série de características do conhecimento, e
enumera: é volumoso, de difícil caracterização, está em constante mudança, é diferente de
dados e é individual. Neste sentido, explica que o conhecimento possui diversos aspectos,
características e detalhes, está sempre em evolução, nem sempre podemos explicar como o
adquirimos, e muitas vezes nem consciência dele temos e cada indivíduo adquire
conhecimento de forma particular.
Contudo, nem todas as definições são tão amplas e complexas. Alguns autores tornam
o conceito de conhecimento mais simples, pois estabelecem quesitos e abordam o tema com
enfoque mais prático.
Laudon e Laudon (2001, p. 10) define conhecimento como “o conjunto de ferramentas
conceituais e categorias usadas pelos seres humanos para criar, colecionar, armazenar e
compartilhar a informação.”
Para Moresi (2000), conhecimento é o resultado do processo de análise e avaliação das
informações quanto aos quesitos confiabilidade, relevância e importância.
22
Apesar das inúmeras definições apresentadas, pode-se concluir, ao final deste capítulo,
a correlação existente entre dados, informação e conhecimento, imprescindível para que se
possa iniciar o estudo de inteligência artificial e mineração de dados.
2.4 DESCOBERTA DO CONHECIMENTO
Para que o dado tome a forma de informação e possa gerar conhecimento, faz-se
necessária a aplicação de determinadas técnicas e métodos, de tal forma que o conhecimento
gerado seja confiável, preciso e útil.
A busca por conhecimento em bases com grande quantidade de dados foi nomeada
com diversos termos até que em 1989 o termo “Descoberta de Conhecimento em Banco de
Dados” foi então utilizado para se referir ao processo total de extração de conhecimento
(FAYYAD, et al., 1996).
Neste sentido, a utilização das técnicas de descoberta de conhecimentos em bases de
dados, também conhecidas pela sigla KDD (Knowledge Discovery in Database) é considerada
“um processo que envolve a automação da identificação e do reconhecimento de padrões em
um banco de dados.” (KREMER, 1999, p. 18).
No processo de KDD, há uma sequência de estágios, cada um gerando uma saída que
alimenta a etapa seguinte, obtendo-se, ao final de todo o processo, o conhecimento. Destaca
Giroto (2009, p. 2):
“As etapas que compõem o processo de Descoberta do Conhecimento em Banco de
Dados compreendem uma série de estágios subsequentes e iterativos onde os resultados de
cada passo realimentam as próximas ações.”
De todo o processo acima citado, a mineração de dados, como será visto a seguir, é
uma das etapas. Hand, Mannila e Smyth (2001, p. 7), afirmam:
A mineração de dados geralmente está situada dentro do contexto maior que
é a descoberta de conhecimento em bases de dados, ou KDD. O termo se
originou do campo de pesquisa da inteligência artificial (IA). O processo de
KDD envolve diversos estágios: selecionar os dados, pré processá-los,
23
transformá-los (se necessário), realizar a mineração de dados para encontrar
padrões e relações, e depois interpretar e analisar as estruturas descobertas.2
Contudo, nem todos apontam o data mining como etapa do processo de KDD. Para
Myatt (2007, p.1), os processos acima citados estão encapsulados dentro do próprio contexto
de mineração de dados. Para os autores, a tarefa de mineração de dados consiste em: definir o
problema, preparar os dados, implementar a análise e verificar os resultados.
Fica claro, apesar da divergência relatada, que no processo de descoberta de
conhecimento em bases de dados faz-se necessário seguir um caminho determinado, que
requer a preparação os dados, a seleção de algoritmos e técnicas adequadas e sua aplicação
aos dados, a análise dos resultados e, por fim, a extração do conhecimento.
Silva Filho (2009, p. 6) define etapas distintas, a saber: seleção de dados,
processamento e limpeza, transformação, mineração de dados e interpretação e avaliação.
2.4.1 Seleção
Após a definição do domínio sobre o qual se quer gerar conhecimento através da
KDD, faz-se necessário selecionar e coletar o conjunto de dados ou variáveis necessárias para
tal atividade. Nesta etapa pode ser necessário integrar e compatibilizar as bases de dados
(SILVA FILHO, 2009, p.7).
Apesar de aparentemente simples, Berry e Linoff destacam que essa primeira etapa
pode se tornar complexa:
No melhor dos mundos, os dados requeridos já estarão residentes em um
data warehouse corporativo, limpos, disponíveis, com precisão histórica e
frequentemente atualizados. Mas de fato, costumam apresentar-se em
dispersos em uma variedade de sistemas operacionais, em formatos
incompatíveis, em computadores rodando em sistemas operacionais
distintos, acessados através de ferramentas de desktop incompatíveis.3
(BERRY; LINOFF, 2004, p. 60).
2
Data mining is often set in the broader context of knowledge discovery in databases, or KDD. This
term originated in the artificial intelligence (AI) research field. The KDD process involves several stages:
selecting the target data, preprocessing the data, transforming them if necessary, performing data mining to
extract patterns and relationships, and then interpreting and assessing the discovered structures.
3
In the best of all possible worlds, the required data would already be resident in a corporate data
warehouse, cleansed, available, historically accurate, and frequently updated. In fact, it is more often scattered in
a variety of operational systems in incompatible formats on computers running different operating systems,
accessed through incompatible desktop tools.
24
2.4.2 Preparação dos dados
Após o entendimento do domínio do problema e dos objetivos que se quer atingir com
o KDD, é importante realizar uma verificação dos dados que serão pesquisados. Esta etapa
pode ser considerada, inclusive, imprescindível, como lemos a seguir:
“Antes de iniciar qualquer análise de dados ou projeto de data mining, os dados
precisam ser coletados, caracterizados, limpos, transformados e particionados em uma forma
apropriada para posterior processamento.” (MYAT, 2007, p. 1).
O agrupamento organizado desta massa de dados, que será alvo da prospecção,
consiste em realizar uma limpeza e um pré-processamento, de tal forma que eles tornem-se
adequados para os algoritmos que serão utilizados. Esta tarefa envolve a integração de dados
heterogêneos, resolver problemas de incompletude dos dados, repetição de tuplas, problemas
de tipagem, entre outros (KREMER, 1999, p. 19).
Giroto ressalta que os dados “[...] são processados e trabalhados de forma diferenciada
da original, no entanto, suas propriedades são mantidas. O novo formato então é
disponibilizado e deve ser mais bem aproveitado nas etapas sucessoras”.
Nesta etapa, as informações que são consideradas desnecessárias são retiradas e devem
ser adotadas estratégias para manipular dados que estão ausentes ou são inconsistentes. É
ainda na preparação dos dados que devem ser detectadas e removidas anomalias dos dados,
aumentando sua qualidade (SILVA FILHO, 2009, p. 8).
2.4.3 Transformação
Na etapa de transformação tem-se a aplicação de fórmulas matemáticas nos valores de
determinadas variáveis, obtendo-se, então, dados em formatos mais apropriados para a
posterior modelagem.
Faz-se importante aplicar certas transformações matemáticas aos dados já que muitos
programas de análise/mineração de dados terão dificuldades para compreendê-los em sua
25
forma crua. Portanto, algumas transformações comuns que devem ser consideradas incluem a
normalização, mapeamento de valores, discretização e agregação4 (MYAT, 2007, p. 26).
As etapas acima descritas podem se tornar menos complexas e mais simples caso os
dados de um SGBD operacional já estejam organizados em um data warehouse ou um data
mart.
Neste fluxo do SGBD operacional para o data warehouse, Kremer (1999, p. 25) atesta
que “[...] um bom processo de 'limpeza de dados' (data cleaning), utilizado na passagem dos
dados para um Data Warehouse certamente beneficia o processo de Data Mining.”
2.4.3.1 SGBD Operacional
Os Sistemas Gerenciadores de Bancos de Dados (SGBD) operacionais são os
responsáveis por armazenar os registros das transações de uma instituição ou corporação.
Como seu foco é o chão de fábrica, ou seja, as atividades corriqueiras e que se desenvolvem
milhares de vezes a cada hora, minuto ou segundo na empresa, precisam ser rápidos e
precisos.
Inmon (2005, p. 16) destaca que os SGBD operacionais lidam com dados primitivos,
com foco nas aplicações e servem primariamente para a comunidade que necessita de alta
performance no processamento das transações.5
Como os dados armazenados possuem muito pouco ou nenhum processamento, ou
seja, são dados brutos, que se referem a atividades corriqueiras de uma empresa, torna-se
complexa a atividade de buscar informações ou conhecimento em tais bases. Assim, faz-se
necessária a modelagem e construção de Data Marts ou Data Warehouses, que recuperarão os
dados brutos, provenientes dos SGBDs operacionais, os transformarão e os armazenarão de
forma diferenciada, proporcionando informação e conhecimento mais precisos e úteis aos
gestores.
4
It is important to consider applying certain mathematical transformations to the data since many data
analysis/data mining programs will have difficulty making sense of the data in its raw form. Some common
transformations that should be considered include normalization, value mapping, discretization, and aggregation
.
5
The operational level of data holds application-oriented primitive data only and primarily serves the
high-performance transaction-processing community.
26
2.4.3.2 Data Warehouse
Um Data Warehouse (DW) é um grande repositório de dados históricos, com tamanho
significativo, integrados, que possuem uma coleção de ferramentas para apoio à tomada de
decisão, pois permite que o usuário final tome decisões com maior precisão, rapidez e
segurança. (TEOREY apud PERING, 2010, p. 24).
O DW é um banco de dados especializado, que obtém seus registros através do
processamento do fluxo de informações de bancos de dados operacionais corporativos.
Contém dados integrados, históricos e primitivos e que não podem ser atualizados.
Adicionalmente, alguns dados derivados também são encontrados (INMON, 2005, p. 16).
Contudo, dependendo do tamanho da organização e do número de departamentos,
pode ser necessário, ou mais viável, a criação de repositórios menores de dados, contendo
informações referentes apenas um departamento ou área de atuação da empresa pertinentes a
um período de tempo mais enxuto. Tais repositórios são chamados de Data Marts.
2.4.3.3 Data Mart
O Data Mart “é um pequeno data warehouse que fornece suporte à decisão de um
pequeno grupo de pessoas.” (SOUZA, 2003, p.1).
Oliveira (2002, p. 100) define Data Mart como subconjuntos de dados da empresa
armazenados fisicamente em locais distintos, geralmente separados em departamentos. Assim,
temos que no nível de dados departamental, ou de Data Mart, há quase que exclusivamente
dados derivados. Tais dados são modelados de acordo com os requerimentos do usuário em
uma forma especificamente modelada para satisfazer as necessidades do departamento 6
(INMON, 2005, p. 16).
Assim, percebe-se a relação dos Data Marts com os níveis de setorização de uma
empesa ou instituição. A quantidade de dados armazenada em tais subsistemas é menor que a
de dados que ficam registrados no Data Warehouse, tanto em virtude do período de tempo a
que se referem quanto ao tamanho do domínio do problema que registram. Os Data Marts são
6
The departmental or data mart level of data contains derived data almost exclusively. The departmental
or data mart level of data is shaped by end-user requirements into a form specifically suited to the needs of the
department.
27
conjuntos de dados, referentes às atividades de um certo departamento ou seção de uma
empresa e que passam por um processo de limpeza, transformação e, por fim, permanecem
armazenados para satisfazer a necessidade de um determinado grupo de usuários por certas
informações.
Desta forma, conclui Souza (2003, p. 1):
É preciso ter em mente que as diferenças entre Data Mart e Data
Warehouse são apenas com relação ao tamanho e ao escopo do problema a
ser resolvido. Portanto, as definições dos problemas e os requisitos de dados
são essencialmente os mesmos para ambos. Enquanto um Data Mart trata de
problema departamental ou local, um Data Warehouse envolve o esforço de
toda a companhia para que o suporte a decisões atue em todos os níveis da
organização.
2.4.4 Mineração de dados
Realizadas as etapas e processos acima descritos, inicia-se a fase de mineração de
dados propriamente dita.
Groth (1998, apud Fernandes, 2005) entende que a mineração de dados consiste em
um processo de descoberta de informações automático. Contudo, a relevância da
automaticidade do processo de mineração de dados é bastante discutida. Com relação a este
fato, Larose (2005, p. 4), tece considerações acerca da definição de Data Mining apresentada
por outros colegas em duas edições de uma mesma obra. Na primeira, mineração de dados é
descrita como uma tarefa automática ou semi-automática. Na edição seguinte, os autores da
mesma obra passam a informar que se arrependeram de ter utilizado as expressões automática
e semi-automática, pois isto levou muitas pessoas a entenderem que a mineração de dados é
um produto a ser comprado e não uma disciplina a ser compreendida.
Para os pesquisadores Hand, Mannila e Smyth (2001), o processo de mineração de
dados é a análise de (geralmente grandes) conjuntos de dados observacionais para encontrar
relações insuspeitas e sumarizar os dados de forma que sejam entendíveis e úteis ao dono dos
dados.7
7
Data mining is the analysis of (often large) observational data sets to find unsuspected relationships and
to summarize the data in novel ways that are both understandable and useful to the data owner.
28
Fernandes (2005, p. 132), após analisar inúmeros conceitos, resume o que é mineração
de dados: “Data mining é um processo analítico de informações que se baseia no Data
Warehouse e utiliza técnicas estatísticas e matemáticas para examinar as informações”
Não pode passar em branco a definição apresentada por Witten e Frank (2005),
pesquisadores da Universidade Waikato, para os quais a mineração de dados é a extração de
informações implícitas, desconhecidas previamente e potencialmente úteis a partir de dados.8
Contudo, não é trivial e simples a tarefa de realizar a mineração de dados. Existem
diversas técnicas e métodos envolvidos, de tal forma que se faz necessário entender qual o
momento é propício para aplicação de determinada algoritmo, fórmula ou conceito.
Os métodos e técnicas citados pelos autores na bibliografia disponível são vários,
contudo convergem para um grupo relativamente restrito, da qual cabe mencionar o memory
based reasoning, os algoritmos genéticos, detecção de agrupamentos, árvores de decisão,
redes neurais e análise de cluster.
O Memory based reasoning, ou seja, raciocínio baseado em memória, é uma técnica
que utiliza exemplos conhecidos para poder fazer previsões sobre exemplos desconhecidos
(FERNANDES, 2005, p. 133).
Já os algoritmos genéticos
[…] aplicam a mecânica da genética e seleção natural à pesquisa usada para
encontrar os melhores conjuntos de parâmetros que descrevem uma função
de previsão. Eles são utilizados no Data Mining dirigido e são semelhantes à
estatística, em que a forma do modelo precisa ser conhecida em
profundidade (KREMER, 1999, p. 28).
Na detecção de agrupamentos temos a construção de modelos para encontrar dados
semelhantes, e estas reuniões, por semelhança, são chamados de grupos (clusters). Tal tarefa
tem como meta encontrar similaridades não conhecidas anteriormente (HARRISON, 1998
apud KREMER, 1999).
Em tal tarefa busca-se segmentar todo o conjunto de dados em grupos relativamente
homogêneos, onde a similaridade entre os membros de um determinado grupo é maximizada,
8
data.
Data mining is the extraction of implicit, previously unknown, and potentially useful information from
29
ao mesmo tempo em que a similaridade entre componentes de grupos diferentes é
minimizada9 (LAROSE, 2005, p. 16).
Quando da utilização de árvores de decisão, ocorre a divisão dos registros do conjunto
de dados de treinamento em subconjuntos separados, cada qual descrito por uma regra
simples em um ou mais campos. A árvore de decisão cria um modelo bem explicável, pois
cria regras bem definidas. Geralmente é utilizado no processo de classificação dos dados
(KREMER, 1999, p. 29).
As redes neurais artificiais são definidas por Kohonen (1972 apud Fernandes, 2005)
como redes massivamente paralelas e interconectadas, de elementos simples, com
organização hierárquica e que interagem com objetivos do mundo real da mesma maneira que
o sistema nervoso biológico.
Assim como as técnicas utilizadas, as utilidades do processo de mineração de dados
devem ser destacadas. Desta forma, na literatura diz-se que podem ser utilizadas as técnicas
acima para classificar, estimar, agrupar por afinidade, prever e segmentar (KREMER, 1999,
p. 21).
Berry e Linoff (2004, p. 8) também nos trazem seis utilidades, a seguir: classificação,
estimativa, predição, agrupar por afinidade, segmentação e descrição (criação de perfis). É o
mesmo pensamento de Larose (2005, p. 11), que destaca como utilidades da mineração de
dados a descrição, estimativa, predição, classificação, segmentação e associação.
Assim sendo, tratar-se-á, a seguir, de forma mais aprofundada, as seis utilidades da
mineração de dados acima mencionadas.
2.4.4.1 Classificação
A classificação consiste em examinar as características de um novo objeto e
determiná-lo para uma classe de um determinado conjunto de classes (BERRY; LINOFF,
2004, p. 9).
9
[…] seek to segment the entire data set into relatively homogeneous subgroups or clusters, where the
similarity of the records within the cluster is maximized and the similarity to records outside the cluster is
minimized.
30
Giroto (2009, p. 4), segue na mesma linha, pois para a pesquisadora a classificação
“[...] procura classificar os dados de um conjunto baseando-se nos valores de alguns
atributos.”
Larose (2005, p. 14) não oferece um conceito definido de classificação, contudo,
exemplifica a questão de tal forma que possamos conhecer como aplicar, na prática, tal
utilidade da mineração de dados. O pesquisador nos traz os seguintes exemplos: determinar se
uma determinada transação no cartão de crédito é fraudulenta, colocar um determinado
estudante em uma determinada turma em decorrência de suas necessidades especiais; atribuir
se uma solicitação de financiamento possui baixo ou alto risco; diagnosticar se uma
determinada doença está presente; determinar se o testamento foi escrito pelo falecido ou
fraudulentamente feito por outra pessoa e, por fim, até identificar se o comportamento
financeiro de uma determinada pessoa indica uma possível ameaça terrorista.
2.4.4.2 Estimativa
Para Larose (2005, p. 12), a estimativa é muito parecida com a classificação, com a
diferença que a classificação trabalha com dados categóricos enquanto que a estimativa
processa dados numéricos.10
É basicamente o mesmo conceito apresentado por Berry e Linoff (2004, p. 9), para os
quais a classificação
[…] trata de valores discretos: sim ou não; sarampo, rubéola ou catapora. A
estimativa lida com valores contínuos. Com determinados dados de entrada,
a estimativa consegue definir um valor para uma variável contínua
11
desconhecida como renda, altura ou balanço do cartão de crédito.
Kremer (1999, p. 22), exemplifica atividades onde a estimativa pode ser utilizada:
“a) estimar o número de filhos numa família; b) estimar a renda total de uma família;
c) estimar o valor em tempo de vida de um cliente.”
10
Estimation is similar to classification except that the target variable is numerical rather than categorical.
Classification deals with discrete outcomes: yes or no; measles, rubella, or chicken pox. Estimation
deals with continuously valued outcomes. Given some input data, estimation comes up with a value for some
unknown continuous variable such as income, height, or credit card balance.
11
31
Nesta categoria de atividades encontramos a utilização de algoritmos de regressão
linear, que buscam estimar o valor de uma variável Y, partindo-se do pressuposto de que ela é
dependente de outras variáveis X1, X2, X3, etc presentes no problema. (BRAGA, 2005, p. 38)
Um dos exemplos que melhor explica a atividade de regressão linear é o trazido por
Abernethy (2010, p.1), que consegue elaborar uma função para o cálculo do preço de um
imóvel a partir de variáveis como tamanho da casa, tamanho do terreno, número de quartos,
presença de granito e existência de reforma recente no banheiro.
2.4.4.3 Predição
No concernente à predição, também conhecida por previsão, o conceito de Kremer
(1999, p. 23) é bastante esclarecedor. Para o mesmo a previsão “[...] é o mesmo que
classificação ou estimativa, exceto pelo fato de que os registros são classificados de acordo
com alguma atitude futura prevista.” E conclui: “Em um trabalho de previsão, o único modo
de confirmar a precisão da classificação é esperar para ver.”
Barry e Linoff (2004, p. 10) complementam o conceito ao afirmar que a primeira razão
para tratar a previsão como uma tarefa separada da classificação e estimativa é que na
modelagem de predição há questões adicionais referentes à relação temporal das variáveis ou
preditores da variável alvo.12
A tarefa de prever o comportamento de uma variável desconhecida depende, contudo,
de uma quantidade de dados para que o algoritmo consiga ser treinado. Baseado nestes
conjuntos completos de dados, o algoritmo de previsão consegue analisar novos dados e
prever o comportamento de determinadas variáveis.
O objetivo é, portanto, construir um modelo que vai permitir determinar o valor de
uma variável a partir dos valores conhecidos de outras variáveis13 (HAND; MANNILA;
SMYTH, 2001, p. 14).
Exemplos conhecidos da previsão são:
12
The primary reason for treating prediction as a separate task from classification and estimation is that in
predictive modeling there are additional issues regarding the temporal relationship of the input variables or
predictors to the target variable.
13
The aim here is to build a model that will permit the value of one variable to be predicted from the
known values of other variables.
32
Prever o preço de uma ação de mercado três meses no futuro;
Prever a porcentagem de aumento de morte no trânsito no ano que vem se
for aumentado o limite de velocidade;
Prever o campeão da Liga Mundial de Baseball, baseado numa comparação
estatística entre os times;
Prever se uma molécula particular descoberta vai gerar uma nova droga
lucrativa para uma determina empresa farmacêutica. (LAROSE, 2005, p. 13)
2.4.4.4 Agrupamento
O agrupamento por afinidade é descrito por Kremer (1999, p. 22) como “um algoritmo
tipicamente endereçado à análise de mercado, onde o objetivo é encontrar tendências dentro
de um grande número de registros de compras, por exemplo, expressas como transações.”
O referido pesquisador ressalta que tal algoritmo dá seus resultados na forma de regras
e dá os seguintes exemplos: “72% de todos os registros que contém os itens A, B, e C também
contém D e E” e “84% dos alunos inscritos em ‘Introdução ao Unix’ também estão inscritos
em ‘Programação em C’” (KREMER, 1999, p. 23).
Na literatura especializada, entretanto, é possível encontrar esta atividade da
mineração de dados com a nomenclatura de associação.
A tarefa de associação no data mining consiste no trabalho de encontrar
quais atributos “vão juntos”. Prevalente no mundo dos negócios, onde é
conhecida por análise de afinidades ou análise de cesta de compras, a tarefa
de associação busca revelar regras para quantificar o relacionamento entre
dois ou mais atributos. As regras de associação vem na forma “se
antecedente, então consequente,” juntamente com uma medida de suporte e
confiabilidade associada com tal regra 14 (LAROSE, 2005, p. 17).
O método de associação é um exemplo de atividade de agrupar sem
supervisionamento, ou seja, não há como direcionar como o agrupamento será gerado. Este
14
The association task for data mining is the job of finding which attributes “go together.” Most prevalent
in the business world, where it is known as affinity analysis or market basket analysis, the task of association
seeks to uncover rules for quantifying the relationship between two or more attributes. Association rules are of
the form “If antecedent, then consequent,” together with a measure of the support and confidence associated with
the rule.
33
método agrupa observações e procura entender os vínculos e associações entre diferentes
atributos do grupo15 (MYAT, 2007, p. 129).
2.4.4.5 Segmentação
A segmentação consiste em realizar o agrupamento de uma população heterogênea em
diversos subgrupos com características homogêneas. Difere da classificação, pois a
segmentação não depende de classes pré-determinadas (KREMER, 1999, p. 23).
No mesmo norte segue Giroto (2009, p. 4), para o qual a segmentação “[...] procura
fragmentar os elementos de dados em subconjuntos cujos elementos possuem uma certa
similaridade, de forma que os dados com propriedades semelhantes são considerados
homogêneos.”
Na análise de segmentação, por exemplo, o objetivo é agrupar junto os
registros similares, como na segmentação de marketing em bases de dados
comerciais. Aqui o objetivo é dividir os registros em grupos homogêneos
para que pessoas similares (se os registros se referem a pessoas) sejam
colocadas no mesmo grupo. Isto permite com que anunciantes e o pessoal do
marketing consiga direcionar, eficientemente, suas promoções para aqueles
que tem mais chance de responder a elas. 16 (HAND; MANNILA; SMYTH,
2001, p. 13)
A segmentação também é conhecida na bibliografia com a nomenclatura de clustering
ou clusterização, tendo em vista que sua tarefa é dividir um grupo maior em grupos menores,
chamados de clusters.
Portanto, temos que a tarefa de clusterização refere-se a agrupar registros, observações
ou casos em classes de objetos similares. Um cluster é uma coleção de registros que são
similares entre si, e não similares com registros em outros clusters. A clusterização é diferente
da classificação pois naquela não há variável alvo e não se tenta classificar, estimar ou prever
nenhuma incógnita. Ao invés disso, os algoritmos de segmentação buscam dividir todo o
conjunto de dados em subgrupos relativamente homogêneos, onde a similaridade entre os
15
The associative rules method is an example of an unsupervised grouping method, that is, the goal is not
used to direct how the grouping is generated. This method groups observations and attempts to understand links
or associations between different attributes of the group.
16
In segmentation analysis, for example, the aim is to group together similar records, as in market
segmentation of commercial databases. Here the goal is to split the records into homogeneous groups so that
similar people (if the records refer to people) are put into the same group. This enables advertisers and marketers
to efficiently direct their promotions to those most likely to respond.
34
registros de um cluster são maximizadas e a similaridade entre registros de grupos diferentes
é minimizada (LAROSE, 2005, p. 16).
“O exemplo clássico é o de segmentação demográfica, que serve de início para uma
determinação das características de um grupo social, visando desde hábitos de compras até
utilização de meios de transporte.” (KREMER, 1999, p. 24).
2.4.4.6 Descrição
Para Berry e Linoff (2004, p. 12), às vezes a mineração de dados pode ser utilizada
apenas para descrever o que está acontecendo dentro de um banco de dados complexo, de tal
forma que seja possível aumentar a capacidade de entendimento de pessoas, produtos ou
processos que produziram aqueles dados.
Larose (2005, p. 11) complementa: “A descrição de padrões e tendências geralmente
sugerem possíveis explicações para tais eventos.”
2.4.5 Interpretação e avaliação
Encerrada a mineração dos dados, momento em que foram aplicadas as diversas
técnicas e formas de utilização acima estudadas, cabe “avaliar o conhecimento extraído das
bases de dados, identificar padrões e interpretá-los, transformando-os em conhecimentos que
possam ser úteis para a tomada de decisão.” (SILVA FILHO, 2009, p. 9).
Como foi visto, o processo de descoberta de conhecimento é incremental e iterativo.
Assim, caso os resultados obtidos estejam aquém do esperado, faz-se necessário iniciar do
começo ou retomar as atividades a partir de outra parte do ciclo, avaliando novamente os
resultados e repetindo o processo sempre que necessário.
2.5 UTILIZAÇÃO DE TÉCNICAS DE DESCOBERTA DE CONHECIMENTO NA
ATIVIDADE POLICIAL
Após a melhor compreensão dos conceitos, atividades e técnicas envolvidas em um
processo de descoberta de conhecimento em bases de dados, desnecessário dizer que tal
atividade nada tem de trivial ou simples.
35
Conquanto tal atividade seja complexa, os resultados advindos podem ser bastante
promissores. Como foi visto, a extração de conhecimento útil, previamente desconhecido, a
partir de uma base de dados, pode ser de fundamental importância para uma instituição,
corporação ou departamento, seja trazendo vantagem competitiva sobre os concorrentes ou
melhorando os processos de relacionamento com demais stakeholders.
Com relação à aplicação de tais tecnologias pelas agências responsáveis pela aplicação
da lei, Hauck e Chen (1999, p. 6) afirmam que:
Um grande número de aplicações que se utilizam da tecnologia da
informação para fins de aplicação da lei atualmente existem. Enquanto o
número de agências que utilizam este tipo de tecnologias está crescendo, o
desenvolvimento de ferramentas de inteligência artificial úteis continua a
progredir. E por que há muitos usos para as bases de dados, análise de
inteligência e outras tecnologias, os usos potenciais de tais tipos de
tecnologias ainda precisam ser completamente explorados.17
Neste sentido, verifica-se que foram feitas algumas pesquisas relacionadas à
mineração de dados em bases policiais, que possuíam o objetivo de revelar informações
relevantes diante da grande massa de registros que são encontradas em tais bases.
Serão descritos, a partir de próxima seção, os casos mais pertinentes, de tal forma a
esclarecer como o processo de mineração de dados tem sido utilizado, mundo afora, para
auxiliar a tomada de decisão na área de segurança pública e combate ao crime.
2.5.1 Ensino de investigação e elaboração de perfis de crimes utilizando raciocínio
baseado em casos e aprendizagem cognitiva
Casey (2002) sugere que através da utilização de raciocínio baseado em casos e
aprendizagem cognitiva, é possível ensinar, de forma mais apurada, a investigar de crimes de
internet e a elaborar perfis criminais.
Segundo o supracitado autor, a mistura da teoria com a prática tem se revelado como a
melhor maneira de ensinar algum conteúdo aos alunos. Como atualmente é feito com os
pilotos de avião, que são submetidos sistematicamente a treinos em simuladores de vôo, o
17
A number of applications that take advantage of various information technologies for law enforcement
purposes currently exist. As the number of agencies that utilize these types of technologies is growing, the
development of useful artificial intelligence tools continues to progress. And because there are many uses of
databases, intelligence analysis and other technologies, the potential uses for these types of technologies have yet
to be fully explored.
36
mesmo poderia ser feito com investigadores e detetives, que aplicariam a teoria e suas
técnicas em um ambiente onde podem ser cometidos erros sem as consequências que uma
falha possui na vida real.
O raciocínio baseado em casos tem como pilar a idéia de que as pessoas entendem
experiências novas baseando-se em experiências passadas.
De acordo com Kolodner (1994):
Saber onde alguma coisa se encaixa naquilo que já sabemos é um prérequisito para racionalizar sobre isto. Nós achamos difícil sugerir uma
solução para um problema até que nós consigamos entender o problema em
si. Nós utilizamos o que conhecemos sobre uma situação para buscar algo
parecido na memória e a usamos como base para derivar expectativas e
inferências.
Wangenhein e Wangenhein (2003, p. 7) destacam que o raciocínio baseado em casos,
chamado também de RBC, tem se demonstrado, nos últimos anos, “como uma técnica
poderosa para a solução automática de problemas. RBC é aplicável de forma simples e direta
a um amplo espectro de tarefas, todas tipicamente relacionadas à Inteligência Artificial (IA).”
E concluem, de forma semelhante ao demonstrado por Kolodner:
Raciocínio baseado em casos é um enfoque para a solução de problemas e
para o aprendizado baseado em experiência passada. RBC resolve problemas
ao recuperar e adaptar experiências passadas – chamadas casos –
armazenadas em uma base de casos. Um novo problema é resolvido com
base na adaptação de soluções de problemas similares já conhecidos.
(WANGENHEIN; WANGENHEIN, 2003, p. 8)
Na abordagem de ensino, Casey (2002) ainda dá enfoque para a aprendizagem
cognitiva, destacando que se trata de outra ferramenta poderosa de aprendizagem para ensinar
aos alunos quando se utiliza o raciocínio baseado em casos.
2.5.2 Mineração de dados e utilização de sistemas especialistas em agências responsáveis
pela aplicação das leis
O trabalho apresentado por Monica Holmes, Diane Comstock-Davidson e Roger
Hayen, todos da Universidade Central de Michigan, destaca a importância que um sistema
integrado de mineração de dados com inteligência artificial possui para a resolução de crimes.
37
Revelam (HOLMES; COMSTOCK-DAVIDSON; HAYEN, 2007, p. 329) que a
utilização de bases de dados criminais e de inteligência artificial tem se provado eficiente no
combate e resolução de crimes em um determinado local. Contudo, há a necessidade de um
sistema especialista que conecte as agências de cumprimento da lei em âmbito nacional.
Os autores evidenciam a necessidade de um sistema integrado de combate ao crime,
através da utilização de programas de inteligência artificial, que poderiam ser aplicados aos
dados para detectar padrões e utilizados para conectar evidências aos suspeitos. Apesar desta
defasagem no âmbito das agências responsáveis pela aplicação da lei, existem alguns sistemas
gerenciadores de bancos de dados que se utilizam de sistemas especialistas e de inteligência
artificial para obtenção de informação e conhecimento. Neste sentido, mencionam cinco:
COPLINK, SHERPA, MATRIX, ViCAP e ViCLAS.
2.5.2.1 Coplink
O COPLINK é um sistema gerenciador de conhecimento e informação integrado que
foi desenvolvido pela Universidade do Arizona, em colaboração com os Departamentos de
Polícia de Tucson e Phoenix. Atualmente é utilizado para compartilhar informações sobre
vários crimes com o objetivo de vincular suspeitos entre si e, portanto, resolver mais crimes18
(HOLMES, COMSTOCK-DAVIDSON, HAYEN, 2007).
Este projeto foi iniciado em 1997 e tinha como objetivo principal criar um sistema
protótipo que integrasse os bancos de dados das agências aplicadoras da lei a fornecesse um
modelo para compartilhamento de informações. Ao invés de simplesmente converter as bases
e colocá-las em um banco só, foi utilizada uma abordagem com data warehouse, que
garantiria que os dados fossem depois utilizados em processos de mineração e produção de
conhecimento (SCHROEDER, 2001).
Ao ilustrar a forma com que o sistema Coplink pode ser utilizado, Chen et al (2004, p.
53) enumera as seguintes utilizações: named-entity extraction, deceptive-identity detection,
and criminal-network analysis, que podem ser traduzidas para extração de entidades
nomeadas, detecção de identidades falsas e análise de redes criminosas.
18
COPLINK, an integrative information and knowledge management system developed at the University
of Arizona, in collaboration with the Tucson and Phoenix police departments, is being used to share information
about various crimes in order to link suspects and therefore solve more crimes
38
A extração de entidades nomeadas diz respeito a realizar uma análise textual dos
relatórios policiais, os quais, segundos os autores, são difíceis de serem analisados
automaticamente. A segunda tarefa, de detecção de identidades falsas, trata de utilizar a
mineração de dados para detectar dados falsos que foram inseridos na base de dados da
Polícia de Tucson. A última tarefa citada (análise de redes criminosas) consiste em identificar
subgrupos e membros chave em redes e grupos criminosos e depois estudar os padrões de
interação para desenvolver estratégias efetivas para interromper tais redes (CHEN et al, 2004,
p. 53-54).
2.5.2.2 Sherpa
O projeto SHERPA foi desenvolvido pela Divisão de Narcóticos da Polícia do Estado
norte-americano do Wisconsin. Trata-se de um sistema de informação multiagentes, criado
para ser utilizado como uma ferramenta de suporte à decisão com capacidade de combinar
dados de várias fontes para auxiliar na investigação de crimes relacionados a entorpecentes
(BHASKAR; PENDHARKAR, 1999).
O sistema acima consiste de três agentes, cada qual especializado em um tipo de
análise: classificação por métodos estatísticos, por aprendizagem indutiva e por engenharia do
conhecimento. Após estas análises, o sistema combina as soluções apresentadas para indicar
um suspeito. O objetivo principal por trás do desenvolvimento do sistema SHERPA é
aumentar a efetividade e eficiência no processamento e análise dos dados relacionados a
crimes envolvendo drogas, fornecendo mais evidências e identificando mais criminosos
(HOLMES, COMSTOCK-DAVIDSON, HAYEN, 2007).
2.5.2.3 Matrix
Cercado de muita controvérsia, principalmente no que tange uma possível ameaça às
liberdades individuais e ao direito à privacidade, o sistema norte-americano Matrix
(Multistate Anti-Terrorism Information Exchange Program) foi criado logo após os atentados
de 11 de setembro de 2001. O sistema permitia com que os estados daquela nação
compartilhassem entre si informações criminais, prisionais e veiculares (HOLMES,
COMSTOCK-DAVIDSON, HAYEN, 2007).
39
O software foi desenvolvido e mantido por uma empresa particular e, em virtude da
grande controvérsia gerada em torno de si, gradativamente os Estados e departamentos de
polícia norte-americanos deixaram de fazer parte do sistema até que, em 2005, foi anunciado
o encerramento do sistema.
2.5.2.4 Vicap
O Vicap, sigla para Violent crime apprehension program (programa de apreensão de
crimes violentos), foi implantado pelo FBI (Federal Bureu of Investigation) dos Estados
Unidos em 1985, com o objetivo primordial de “coletar, combinar e analisar todos os aspectos
de uma investigação de múltiplos homicídios com padrões similares, com abrangência
nacional, não importando a localização ou o número de agências policiais envolvidas.”
19
(STEVEN, 1990 apud WITZIG, 2003, p. 2).
Collins et al (1998, p. 277) nos proporciona uma definição mais simplificada, pois
considera que o objetivo principal do VICAP era criar ligações entre as informações coletadas
na investigação de crimes violentos.
A base de dados do VICAP inclui homicídios consumados e tentados (resolvidos ou
não), especialmente se envolvem o rapto, de natureza sexual ou aparentemente aleatória, ou
ainda, se fazem parte de uma série de homicídios; dados sobre pessoas desaparecidas, onde o
uso da violência pode ter acontecido e a vítima ainda encontra-se desaparecida; informações
sobre corpos não identificados, com suspeita de que foram vítimas de homicídio e, por fim,
informações sobre casos de violência sexual (HOLMES; COMSTOCK-DAVIDSON;
HAYEN, 2007).
Adderley (2007, p. 49) ressalta que quando um novo registro de caso é inserido, o
sistema simultaneamente compara e verifica 188 variáveis relacionadas às categorias de
modus operandi com os registros que já estão na base, retornando ao usuário uma lista com os
dez casos que mais se assemelham ao caso recém-cadastrado.
2.5.2.5 Viclas
19
[…] collect, collate, and analyze all aspects of the investigation of similar-pattern, multiple murders, on
a nationwide basis, regardless of the location or number of police agencies involved.
40
O sistema Viclas, sigla para violent crime linkage analysis system (sistema de
vinculação e análise de crimes violentos) surgiu de uma necessidade da Real Polícia Montada
Canadense, em meados de 1980, em virtude de uma série de crimes complexos, envolvendo
homicídios em série em múltiplas jurisdições (COLLINS et al, 1998, p. 278).
Segundo Adderley (2007, p. 50) o programa foi construído para capturar dados de
crimes resolvidos e não resolvidos, de forma semelhante ao VICAP, visto acima. Portanto,
registra dados relacionados a: homicídios, seqüestros e raptos, violência sexual, pessoas
desaparecidas e corpos com suspeita de terem sido vítimas de homicídio.
De forma sucinta, o VICLAS requer que o investigador preencha um questionário
relacionado ao crime e o remeta ao pessoal especializado no sistema, os quais submeterão as
informações no sistema. Após realizarem buscas e analisar as respostas dadas pelo VICLAS,
os especialistas remetem um relatório ao investigador, com os resultados de sua análise
(WILSON, 2011).
Wilson (2011) também ressalta que, apesar de ter sido criado pela Polícia Montada do
Canadá, o sistema atualmente encontra-se em uso em outros países, tais como: Bélgica,
República Tcheca, França, Alemanha, Irlanda, Holanda, Nova Zelândia, Suíça e Reino Unido.
2.5.3 Mineração de dados na atividade forense
As técnicas de mineração de dados podem ser utilizadas, também, na atividade
forense, quando há a necessidade de investigação pericial de um determinado material ou
evento relacionado a um crime.
Mena (2003, p. 377) destaca que:
Hoje temos que dizer aos computadores passo-a-passo o que fazer, o que
torna a codificação dos programas um processo muito lento. Contudo, com
técnicas de mineração de dados nós não damos o passo-a-passo ao
computador. Ao invés disto, nós o treinamos dando a ele uma pequena
iniciativa com foco bastante restrito, como aprender a assinatura de um
crime ou o perfil de um criminoso, que máquinas com funcionalidade
limitada mas extremamente rápidas são capazes de conseguir. 20
20
Today we have to tell computers blow-by-blow what to do, so coding or writing programs is a very
slow process. However, with datamining techniques we don't give the computer blow-by-blow instructions.
Instead we train it by giving it a narrowly focused initiative, such as learning the signature of a crime, or the task
41
Neste rumo, temos exemplos de sistemas, em uso pelos laboratórios criminais, que são
responsáveis pela vinculação de amostras pequenas a grandes lotes de drogas e da análise de
transações bancárias para identificar lavagem de dinheiro.
2.5.3.1 Redes neurais na identificação de amostras de cocaína
Casale e Watterson (1993) descrevem um procedimento prático para identificação de
uma amostra de cocaína, através de uma pesquisa em uma grande base de assinaturas da
droga, através de uma rede neural. Os autores destacam a existência de softwares
especializados em realizar a tarefa de classificação da assinatura de uma droga através das
funções distância, estatística e neurocomputacional. Contudo, destacam que:
“Continuando os esforços de pesquisa, nós desenvolvemos um programa de rede
neural que auxilia os especialistas forenses em identificar cromatografias de amostras de
cocaína que pertencem ao mesmo lote.” (CASALE, WATTERSON, 1993, p. 293)
Ao final da pesquisa, destacam que a rede neural criada comportou-se de forma
superior aos outros métodos de comparação de amostras de cocaína, não apresentando falsos
positivos ou negativos, sendo que foi possível emitir um número maior de alertas sobre
correlação de drogas às polícias locais, tendo em vista a adoção de tal sistema.
2.5.3.2 FAIS
Em 1995, Senator et al, apresentaram o FAIS, FinCEN Artificial Intelligence System.
Os pesquisadores, funcionários da FinCEN – Financial Crimes Enforcement Network –
desenvolveram tal sistema, cujo objetivo primordial é vincular e avaliar relatórios de
transações envolvendo grandes somas para identificar lavagem de dinheiro.
O FAIS integra software inteligente e agentes humanos em tarefas
cooperativas de descoberta em uma base de dados bastante grande. É um
sistema complexo, incorporando diversos aspectos da tecnologia de IA,
incluindo raciocínio baseado em regras e um blackboard. O FAIS consiste
de uma base de dados, uma interface gráfica e vários módulos de análise e
pré-processamento. 21 (SENATOR et al, 1995, p. 21)
of profiling a perpetrator, wich machines with very limited functionality but extreme speed are able to
accomplish.
21
FAIS integrates intelligent software and human agents in a cooperative discovery task on a very large
data space. It is a complex system incorporating several aspects of AI technology, including rule-based
42
Sua importância e efetividade é destacada por Berthold e Hand (2007, p. 430) para os
quais o FAIS foi capaz de reportar 400 casos de lavagem de dinheiro, com mais de 1 bilhão
de dólares em fundos envolvidos na atividade criminosa. O FAIS é ainda capaz de detectar
atividades criminosas que não são percebidas pelas agências policiais que atuam em campo,
como, por exemplo, crimes de lavagem de dinheiro com a participação de mais de 300
pessoas, com 80 operações de fachada e a realização de milhares de operações pecuniárias.
2.5.4 Mineração de regras de associação em bases policiais no Estado do Pará
Luiz Silva Filho (2009) conduziu pesquisa relacionada à mineração de dados de
ocorrências policiais de violência sexual, na base de dados da Polícia Civil do Estado do Pará.
Neste estudo, o pesquisador aplicou técnicas de associação para revelar informações e
conhecimento oculto nas bases de dados, tanto nos registros formatados pelo próprio banco de
dados, quanto nos textos escritos pelos escrivães policiais com base nos relatos das vítimas.
Silva Filho (2009, p. 48-50) conseguiu descobrir regras de associação na base de
dados, revelando informações acerca dos bairros, meios empregados pelos criminosos, faixa
horária e dia da semana. Contudo, revela o pesquisador:
[...] pode-se observar que as regras encontradas com a aplicação Mineração
de Dados se mostraram relativamente interessantes, porém o conhecimento
obtido ficou limitado a poucas características entre as instâncias da base de
dados, isso se deve ao fato de que a base de dados possui poucos atributos, o
que dificulta a descoberta de conhecimento útil ou não trivial. (SILVA
FILHO, 2009, p. 50)
No processo de mineração de textos o autor também conseguiu extrair regras
interessantes dos relatos, que, após análise, levaram-no a concluir, por exemplo:
Esta regra mostra, ainda, uma relação importante, uma vez que a utilização
de armas de fogo é utilizada por pessoas desconhecidas para forçar o
deslocamento das vítimas para o local onde cometerão o delito, diferentes
dos delitos praticados por pessoas conhecidas das vítimas que geralmente
utilizam a força física para forçá-las a praticarem a relação sexual; (SILVA
FILHO, 2009, p. 59)
reasoning and a blackboard. FAIS consists of an underlying database, a graphic user interface, and several
preprocessing and analysis modules.
43
O pesquisador (2009, p. 66) conclui, ao final de seu trabalho, que foi possível
visualizar um contexto em que as regras de KDD e KDT podem ser aplicadas em conjunto
para entender melhor um problema, no caso em tela o crime de estupro, de tal forma que
poder ser utilizadas pelos gerentes em segurança pública para tomar medidas preventivas, e,
ainda, ampliar o uso de tais técnicas para compreender melhor outros tipos de crimes.
2.5.5 Mineração de dados na base de inquéritos policiais do Ministério Público do
Amapá
Benicasa e Paixão (2006, p. 69) realizaram um trabalho científico que consistia em
realizar a mineração de dados na base de inquéritos policiais do Ministério Público do
Amapá.
Os pesquisadores realizaram tal trabalho através da ferramenta WEKA, utilizando-se,
mais especificamente, do algoritmo apriori para buscar a geração do conhecimento nos dados
disponibilizados.
O objetivo do trabalho era “verificar a existência ou não da relação entre os crimes
com alguns atributos dos criminosos, como sexo, naturalidade, bairro, estado civil e data de
ocorrência, dentre outras informações que podem estar guardadas nesta base de dados.”
(BENICASA; PAIXÃO, 2006, p. 69).
A tarefa de associação foi escolhida em virtude de que a base de dados estudada
contém informações sobre crimes ocorridos em diversos bairros da cidade de Macapá, delitos
estes cometidos por pessoas de origens diferentes, provenientes de diversos estados, de tal
forma tal tarefa da mineração de dados poderia revelar associações entre estas características,
auxiliando na descoberta de novos conhecimentos.
Ao final da pesquisa, foi possível chegar a diversas conclusões com relação aos
resultados obtidos:
Este processo gerou regras de associações consistentes, as quais foram
comprovadas através de informações coletadas da base do sistema. Houve
informações de caráter específico, como a associação do furto com
indiciados solteiros do sexo masculino, e do roubo com indiciados do sexo
masculino. Houve também descobertas de caráter geral, como a relação entre
os crimes de forma geral, com pessoas adultas, jovens, solteiras e do sexo
masculino. (BENICASA; PAIXÃO, 2006, p. 73-74)
44
E por fim, sobre associações obtidas, concluem: “Estas devem ser analisadas e
utilizadas como um processo de apoio à tomada de decisão.” (BENICASA; PAIXÃO, 2006,
p. 74).
Por fim, após análise dos diversos sistemas e casos que trataram de utilizar a
mineração de dados e outras ferramentas de inteligência artificial em processos de segurança
pública, foi possível elaborar o seguinte quadro comparativo:
Item – Nome do
projeto/software
Quando Área
iniciou
Onde iniciou
Objetivos e técnicas
associadas
2.5.1 - RBC e
Aprendizagem
Cognitiva
Proposto IA e ensino
em 2002
N/A
Ensinar investigadores
policiais com utilização de
técnicas de RBC e
aprendizagem cognitiva.
2.5.2.1 - Coplink
2001
Sistemas
especialistas,
IA e DM
Departamento de Análise de textos, detecção
Polícia de
de dados falsos e análise de
Tucson
redes criminosas, utilizando
técnicas de previsão,
associação e redes neurais.
2.5.2.2 - Sherpa
Final da Sistemas
década especialistas,
de 1990. IA e DM
Departamento de Apresentar suspeitos,
Polícia do
utilizando-se de
Wisconsin
classificação por métodos
estatísticos, por
aprendizagem indutiva e por
engenharia do
conhecimento.
2.5.2.3 - Matrix
2002
DM
16 Estados
NorteAmericanos
2.5.2.4 - VICAP
1985
Sistemas
FBI
especialistas e
IA
Compartilhamento de
informações e ligações entre
registros.
Analisar dados e criar
ligações entre os registros
referentes a crimes
violentos
2.5.2.5 - VICLAS 1992
DM
Polícia Montada Analisar dados e criar
do Canadá
ligações entre os registros
referentes a crimes
violentos
2.5.3.1 - Redes
neurais na
identificação de
amostras de
cocaína
IA
Estado Norte
Americano da
Carolina do
Norte
1993
Analisar amostras no
cromatógrafo de massa e
compará-las, através de uma
rede neural, com lotes de
drogas apreendidas
45
2.5.3.2 - FAIS
1995
IA e DM
Estados Unidos
Analisar relatórios de
transações em dinheiro e
apontar relações existentes,
identificando transações
fraudulentas e envolvidos
2.5.4 - Mineração 2009
de dados nos
registros policiais
do estado do Pará
DM
Polícia Civil do
Estado do Pará
Minerar dados da Polícia
Civil paraense referentes à
ocorrências de estupro
utilizando a associação
2.5.5 - Mineração 2006
de dados na base
de inquéritos do
Ministério
Público do
Amapá
DM
Ministério
Público do
Estado do
Amapá
Utilização do algoritmo
Apriori para minerar dados
(associação) dos inquéritos
policiais do Amapá
Quadro 1. Comparativo entre os sistemas e projetos que utilizam IA e técnicas associadas para auxiliar
a tomada de decisão em segurança pública.
.
46
3. DESENVOLVIMENTO
Esclarecidos os conceitos que envolvem a descoberta de conhecimento e mineração de
dados, bem como as tarefas associadas e, ainda, a utilização de tal tecnologia na área da
segurança pública, serão reveladas, neste capítulo, quais atividades foram desenvolvidas no
decorrer da pesquisa, incluindo: um breve estudo da Central Regional 190 de Balneário
Camboriú, a obtenção e adequação dos dados de ocorrências, a utilização da ferramenta
WEKA, as técnicas aplicadas e os consequentes resultados.
3.1 CENTRAL REGIONAL DE EMERGÊNCIAS 190 DE BALNEÁRIO CAMBORIÚ
Ativada em 21 de dezembro de 2006, a Central de Emergências de Balneário
Camboriú contava com dispositivos de atendimento e de telecomunicações modernos, com o
objetivo de bem atender a demanda de ligações ao serviço de emergência da comunidade
local.
Atualmente, situa-se na Rua Noruega, Bairro das Nações, em Balneário Camboriú. A
Central Regional de Emergência (CRE) 190 de Balneário, no entanto, atende as ligações dos
Municípios de Balneário Camboriú, Camboriú, Itapema, Bombinhas e Porto Belo. Além da
Polícia Militar, outros órgãos de segurança pública e atendimento ao cidadão estão integrados
no mesmo espaço físico. Atualmente o SAMU, os Agentes de Trânsito de Balneário
Camboriú e a Guarda Municipal, também deste Município, encontram-se gerenciando suas
atividades através da CRE em conjunto com a PM.
Das ligações recebidas pela Central, numa média diária de 700 chamadas, menos da
metade é convertida em ocorrência policial na base de dados. Apesar de não haver definição
específica na literatura, pode-se entender ocorrência policial como todo fato ou situação em
que haja perturbação da ordem pública em algum nível e que há a necessidade da presença
policial para sua completa ou parcial resolução.
Do total de chamadas telefônicas acima mencionadas, tem-se que grande parte trata-se
apenas de trotes, do cidadão ligando em busca de informações ou para realizar denúncias
sobre fatos não atinentes à PM. Muitas ligações ao serviço 190 são feitas pelo próprio público
interno, em busca de dados que concernem à rotina das corporações envolvidas: escalas de
47
serviço, trocas de escalas, repassar informações sobre faltas e estabelecer contatos com
supervisores ou chefes, etc.
Assim, após realizar esta primeira triagem acerca da ligação telefônica e da solicitação
do cidadão, é que o atendente decidirá se será gerada a ocorrência policial no sistema
informatizado. O programa responsável por gerenciar tais ocorrências é o EMAPE, sigla de
Estação Multitarefa para Atendimento Policial e Emergências. Tais dados, depois de gerados
pelo atendente, são mantidos e trabalhados pela própria aplicação.
Rodrigues (2006, p. 89) define com precisão o sistema EMAPE, e onde o mesmo
encontra-se em funcionamento:
É o sistema responsável pelo gerenciamento do atendimento e despacho das
ocorrências e emergências atendidas pela Polícia Militar, implementado nas
cidades de Araranguá, Camboriú, Blumenau, Brusque, Caçador, Canoinhas,
Chapecó, Concórdia, Criciúma, Dionísio Cerqueira, Florianópolis, Herval do
Oeste, Itajaí, Jaraguá do Sul, Joinville, Lages, Laguna, Mafra, Penha, Porto
União, Rio do Sul, Rio Negrinho, São Bento do Sul, São Miguel do Oeste e
Tubarão.
O Sistema EMAPE foi construído em linguagem Supermumps, e utiliza banco de
dados da mesma linguagem, sendo acessado via terminal remoto pelos atendentes.
(RODRIGUES, 2006, p. 157)
Tal ferramenta realiza a gravação de diversos dados relacionados às ocorrências e ao
próprio gerenciamento das viaturas e dos policiais de serviço, tais como: identificador da
ocorrência, instituição envolvida, data e horário da ocorrência, horário de empenho da
guarnição, horário de chegada da guarnição, horário de encerramento da ocorrência,
componentes da guarnição, roteiro da guarnição, status da viatura, prefixo da viatura,
histórico inicial, histórico final, nome do solicitante, telefone do solicitante, logradouro,
bairro, código inicial da ocorrência, código final da ocorrência, ambiente da ocorrência, nome,
idade, sexo, nível de envolvimento das pessoas atendidas.
3.2 BASE DE DADOS
48
Em virtude da pouca compatibilidade do sistema acima estudado com SGBDs atuais,
aliado à falta de uma equipe de desenvolvedores e ausência de documentação relacionada ao
projeto do sistema EMAPE, a obtenção de tais dados não se deu trivialmente.
Para a tanto, foi necessário implementar ferramentas que analisassem as ocorrências
uma a uma, o que possibilitou com que a modelagem de um banco relacional se tornasse
possível. Contudo, esta técnica impediu a importação de todas as variáveis presentes no
sistema, restando as seguintes: identificador da ocorrência, instituição envolvida, data e
horário da ocorrência, guarnições empenhadas, comandantes de guarnição, horário de
empenho da guarnição, de chegada e de encerramento da ocorrência, histórico inicial e final,
logradouro, bairro, código final da ocorrência, nome, idade, sexo e nível de envolvimento das
pessoas atendidas.
Dados que podem trazer informações adicionais úteis, como o código inicial e o
ambiente da ocorrência não puderam ser migrados, tendo em vista as dificuldades técnicas
para realizar tal tarefa.
Foram importadas para a base de dados um total de 187.863 ocorrências, referentes
aos anos de 2008, 2009, 2010 e 2011. Os dados foram migrados para o MySQL, que é um
SGBD relacional com suporte a linguagem SQL. Nesta nova estrutura, relacionam-se
conforme o esquema apresentado na Figura 1.
Figura 1. Banco de dados de ocorrências, com as tabelas e suas relações.
Para melhor identificar o que cada tabela busca identificar, foi elaborado um
dicionário de dados, disponível no Apêndice A deste trabalho.
49
A partir das tabelas e relações acima, buscou-se construir novas tabelas que
sumarizam os dados nela registrados. Em tal etapa, foi adotada a metodologia de modelagem
dimensional, chamada de star schema quando se trabalha em bases de dados relacionais,
como é o caso em questão.
O modelo dimensional divide a informação associada com o processo do
negócio em duas grandes categorias, chamadas fatos e dimensões. Fatos são
as medidas pelas quais um processo é avaliado. […] As dimensões dão aos
fatos o seu contexto. Elas especificam os parâmetros pela qual a medida é
tomada. 22 (ADAMSOM, 2006, p. 5)
Desta forma, elaborou-se um modelo dimensional conforme abaixo:
22
A dimensional model divides the information associated with a business process into two major
categories, called facts and dimensions. Facts are the measurements by which a process is evaluated. […]
Dimensions give facts their context. They specify the parameters by which a measurement is stated.
50
Figura 2. Modelo dimensional com as tabelas de fatos e suas dimensões.
3.3 MINERAÇÃO DE DADOS
Com base nos dados identificados, foi construído um data mart com informações
derivadas e sumarizadas, de tal maneira que o processo de mineração de dados pudesse ser
aplicado em informações consistentes, retornando conhecimento útil e preciso.
Por meio da pesquisa bibliográfica apresentada na fundamentação teórica, foi possível
compreender as diversas tarefas e utilidades da mineração de dados.
51
Como a base de dados é bastante ampla, com aproximadamente 187.000 registros, foi
possível aplicar diversas técnicas de mineração nos dados obtidos, a citar: associação,
segmentação, classificação e previsão.
A realização de tais atividades, tendo em vista a dificuldade matemática envolvida em
tais tarefas e a grande quantidade de dados envolvida requereu, contudo, a utilização de uma
ferramenta específica, o WEKA.
3.3.1 A ferramenta WEKA
Para a aplicação dos algoritmos relacionados às técnicas de mineração de dados ora
tratadas, foi utilizada a ferramenta WEKA (Waikato Environment for Knowledge Analysis)
que é “[...] capaz de elaborar diversas tarefas e algoritmos do processo de descoberta de
conhecimento em base de dados”. (BENICASA; PAIXÃO, 2006, p. 70)
A ferramenta WEKA é livre, de domínio público, distribuída sob a licença GPL (GNU
General Public License). É desenvolvida na linguagem JAVA pela Universidade de Waikato,
na Nova Zelândia, e atualmente encontra-se na versão 3.6. O software é bastante completo,
podendo ser aplicado nas diversas fases da descoberta do conhecimento, não se restringindo à
etapa de mineração de dados. Neste sentido:
O workbench WEKA é uma coleção de algoritmos que podem ser
aprendidos pelo computador e de ferramentas de preparação de dados. Foi
desenvolvido para que você possa testar rapidamente os métodos existentes
em novos conjuntos de dados, de forma flexível. Fornece extensivo suporte
para todo o processo de mineração de dados experimental, incluindo a
preparação dos dados de entrada, avaliação estatística de esquemas de
aprendizado e visualização dos dados de entrada e o resultado do
aprendizado. (WITTEN; FRANK, 2005, p. 365) 23
O programa disponibiliza três módulos gráficos, a saber: o explorer, o knowledge flow
e o experimenter. Cada módulo possui uma forma de trabalho específica, que vão se adequar
ao conhecimento que o pesquisador possui da ferramenta, de seus dados e até mesmo ao
tamanho da amostra que está sendo trabalhada.
23
The Weka workbench is a collection of state-of-the-art machine learning algorithms and data
preprocessing tools. [...]. It is designed so that you can quickly try out existing methods on new datasets in
flexible ways. It provides extensive support for the whole process of experimental data mining, including
preparing the input data, evaluating learning schemes statistically, and visualizing the input data and the result of
learning.
52
Para Witten e Frank (2005, p. 367) a interface explorer é a mais fácil de ser utilizada,
pois ela dá acesso a todas as facilidades do programa através de um menu de seleção e de
formulários a serem preenchidos pelo usuário. Nesta interface o usuário pode escolher as
diversas tarefas da mineração de dados a serem realizadas, bem como os algoritmos e os
parâmetros que devem ser utilizados. Uma das desvantagens do explorer é que ele carrega
todos os dados de entrada na memória. Isso pode ser irrelevante quando os registros de
entrada são poucos, mas quando há quantidade massiva de dados a serem entrados, tal
situação pode se tornar um problema.
O knowledge flow, de outro lado, permite com que o usuário encadeie os dados de
entrada e saída, de tal forma que o processamento dos dados ocorre incrementalmente, o que
minimiza o consumo de memória do sistema. Esta interface permite a especificação de uma
sequência dos dados, conectando componentes que representam entradas de dados,
ferramentas de pré-processamento, algoritmos de aprendizado, métodos de avaliação e
módulos de visualização. 24 (WITTEN; FRANK, 2005, p. 367)
Por fim, ainda há a possibilidade de ser utilizado o experimenter, que tem como
função principal retornar ao usuário a resposta para os seguintes questionamentos quando se
aplicam técnicas de classificação e regressão: quais métodos e valores de parâmetros vão
funcionar melhor para o problema dado? Apesar de o explorer permitir com que o usuário
faça isto de maneira interativa e incremental, o experimenter automatiza tal processo
facilitando a execução de classificadores e filtros com parâmetros diferentes em várias
coleções de dados, coletando estatísticas de performance e fazendo testes de significação.
(WITTEN; FRANK, 2005, p. 367)
O WEKA utiliza o padrão de entrada de dados chamado ARFF, que significa Atribute
Relation File Format. Entretanto, é possível incorporar ao programa conectores, que
permitem com que os dados sejam obtidos diretamente de arquivos em outros formatos ou até
mesmo de bases de dados SQL.
24
It enables you to specify a data stream by connecting components representing data sources,
preprocessing tools, learning algorithms, evaluation methods, and visualization modules.
53
Na presente pesquisa foi utilizada a versão 3.6.6 do WEKA, rodando em ambiente
Linux, distribuição Ubuntu e com a importação de dados feita diretamente através de
comandos SQL.
3.3.2 Pré-processamento
A ferramenta WEKA proporciona uma tela de visualização de ocorrências que, em si,
permite aos pesquisadores esmiuçar as variáveis presentes na base e, a partir daí, estabelecer
visualmente relações entre tais incógnitas e direcionar seus esforços. Será apresentado,
portanto, um sumário com os resultados que a pesquisa revelou já na fase inicial, sem a
aplicação de qualquer algoritmo de mineração de dados.
As ocorrências estudadas foram registradas entre 01/01/2008 a 31/12/2011, que
resultou num total de 187.863 registros. A distribuição das ocorrências policiais é apresentada
conforme Figura 3, na qual se observa uma queda do número de registros a partir de 2009. Em
2008 foram registradas 49.461 ocorrências e em 2009 foi registrado o maior índice, com
50.614 ocorrências. 2010 registrou 44.846 ocorrências em 2011 vê-se o menor índice, com
42.942 ocorrências registradas.
Figura 3. Distribuição das ocorrências nos anos de 2008 a 2011.
Na Figura 4 vê-se a distribuição das ocorrências de janeiro a dezembro, com
subdivisões por ano. A tendência observada é de elevação do número de ocorrências policiais
54
nos meses de dezembro (19.383), janeiro (22.007) e Fevereiro (18.611), fato este que
comprova demanda por maior atendimento policial durante a temporada de verão. A
distribuição dos anos dentro de cada mês também é proporcional, o que evidencia que não
houve nenhum ano em que determinado mês teve um número demasiadamente acentuado de
ocorrências. Exceção se faz ao mês de dezembro, em que pode ser percebida uma menor
concentração de ocorrências no ano de 2010 (cor ciano).
Figura 4. Distribuição das ocorrências nos meses do ano.
A distribuição das ocorrências por dias de semana também revela uma tendência de
incremento durante os finais de semana. A Figura 5 demonstra, de terça a segunda-feira, a
distribuição dos registros durante a semana, evidenciando, em cada coluna, os registros de
cada ano (azul-2008 à cinza-2011). Desta forma, temos que terça-feira registra-se um total de
23.463 ocorrências, enquanto que na quarta-feira foram 23.975, na quinta-feira 24.739 e na
sexta sexta-feira um total de 27.727 registros. Nos sábados há um grande incremento, com
32.996 registros de ocorrência, e domingo apresenta 31.584. A segunda feira marca o início
da semana útil com redução dos índices, registrando 23.379 ocorrências.
55
Figura 5. Distribuição das ocorrências por dia da semana.
Apesar de representar 28% da semana, sábado e domingo representam 34% das
ocorrências. Ao incluirmos sexta-feira, constatamos que os três dias apresentam 49% das
ocorrências. A solicitação de reforço de policiamento nos finais de semana, por parte dos
Comandos de Batalhão ou da Companhia de Balneário Camboriú é pertinente tendo em vista
o constatado acima. Mais uma vez se observa que a distribuição das ocorrências no decorrer
dos anos é homogênea, não se podendo afirmar que em certo ano houve disparidade no
número ocorrências em determinado dia da semana.
A distribuição dos registros por tipo de ocorrência atendida revela diversas
informações. Através do pré-processamento foi possível construir o Quadro 2 e sua
representação gráfica, na Figura 6:
Tipo de ocorrência atendida
Registros
Ocorrências diversas (D):
87.476
Crimes e contravenções (C):
39.031
Auxílios à comunidade (A):
25.225
Emergências, traumas e acidentes (E):
12.987
Serviços/atividades de fiscalização de transito (Y):
5.211
Serviços/atividades afins (S):
4.825
Serviços/atividades operacionais (P):
12.864
Quadro 2. Distribuição das ocorrências atendidas de acordo com as atividades realizadas.
56
Figura 6. Distribuição das ocorrências por tipo de atendimento realizado.
O gráfico revela que grande parte das ocorrências geradas pela Central 190 não são
relacionadas a crimes ou contravenções. A primeira coluna representa 46% do total de
ocorrências, que são as que possuem código D, de “ocorrências diversas”. Somente 20,77%
dos registros policiais tratam-se de ocorrências de crimes ou contravenções (código C –
segunda coluna) e 13,42% referem-se a auxílios à comunidade (código A – terceira coluna).
Com relação à distribuição dos tipos de ocorrências no decorrer dos anos (cores dentro
das colunas), vê-se certa homogeneidade. Uma ressalva, contudo, deve ser feita na 6ª coluna,
que trata das ocorrências de serviços/atividades afins (código S). Percebe-se uma maior
quantidade desse tipo de ocorrência no ano de 2011 em comparação aos anos anteriores. Tal
grupo de atividades inclui ocorrências de apreensão de arma, prestação de informação pela
Central e recuperação de veículo furtado.
Após análise, entretanto, verificou-se que este incremento foi em virtude das
ocorrências com código S105 – PRESTAÇÃO DE INFORMAÇÃO PELO COPOM, que teve
registrado, em 2011, um total de 2.616 ocorrências, enquanto que em 2008, 2009 e 2012
registraram-se, respectivamente, 94, 549 e 811 ocorrências com este código.
A distribuição das ocorrências de acordo com o número de guarnições empenhadas
para seu atendimento também é interessante. Neste sentido, o WEKA gerou o gráfico
representado na Figura 7. Nele, temos que a primeira coluna representa ocorrências em que
não foram empenhadas guarnições. A segunda refere-se às ocorrências em que foi empenhada
57
somente uma viatura para atendimento, num total de 150.368 registros, aproximadamente
80% do total. Na terceira coluna, com duas viaturas empenhadas para atendimento, tem-se
23.156 ocorrências. Vê-se, portanto, que a imensa maioria das ocorrências é atendida por
apenas uma viatura da PM, fato que pode ser utilizado pelo Comandante da OPM ou pelo
Comandante Geral para refutar teses de que há má aplicação do policiamento.
Figura 7. Distribuição das ocorrências de acordo com o número de
guarnições empenhadas para atendimento.
A seguir, foi verificado como acontece a distribuição das ocorrências de acordo com o
horário do dia. Pode ser verificado na Figura 8 que a distribuição não é homogênea, tendo
momentos do dia em que há grande número de ocorrências para atendimento, enquanto que
em outros horários a demanda é bem menor.
58
Figura 8. Distribuição das ocorrências por hora do dia.
Para melhor análise destes dados, dividiu-se o dia em quatro períodos: madrugada (das
00:00h às 05:59h), manhã (das 06:00h às 11:59h), tarde (das 12:00h às 17:59h) e noite (das
18:00h às 23:59h). Assim verifica-se que o período noturno é o que mais concentra
ocorrências, com um total de 62.676 registros (33,36%), seguido pelo período vespertino,
com 49.017 (26,09%) ocorrências. Os registros dos períodos da madrugada e manhã somam,
respectivamente, 30.549 e 45.621. Verifica-se, portanto, que apenas 16,26% das ocorrências
são registradas no período matutino, fato que implica diretamente na decisão dos
Comandantes ao elaborar as escalas e turnos de serviço de seus policiais.
Ainda na fase de pré-processamento, foi possível estabelecer a distribuição de
ocorrências com base no número de pessoas atendidas e o número de agentes identificados em
cada atendimento. Assim, foi gerado o gráfico da Figura 9:
Figura 9. Distribuição das ocorrências de acordo com o número de pessoas
envolvidas e sua relação com o número de agentes.
59
Pela análise constatamos que grande parte das ocorrências acontece sem o registro de
pessoas envolvidas (112.006 – 59%). Das ocorrências com 1 pessoa envolvida (42.979)
pequena parte é de agentes (9.086), representado no gráfico pela área em vermelho. Nas
ocorrências com 2 pessoas envolvidas, uma pequena parte envolve 1 agente (5.904, em
vermelho) e um índice menor representa a identificação de 2 agentes (2.718 ocorrências, em
ciano).
O total de ocorrências em que o policial militar entrou em contato e pegou os dados de
ao menos uma pessoa no local é 75.847. Em 28% destas ocorrências, num total de 21.318, o
policial militar, durante o atendimento, identificou alguém como sendo o agente dos fatos.
Isto implica que o contato do policial durante a ocorrência nem sempre é com o agente
de algum tipo de crime, o que poderia ser utilizado para garantir mais treinamento à tropa no
que tange à sua postura como representante estatal e na sua verbalização com o público
externo, em complemento aos treinamentos de abordagem e tiro.
Outro aspecto que é tratado com relevância quando o assunto é o atendimento de
ocorrências policiais é o tempo de resposta da Polícia. A prestação de um serviço policial que
possa ser considerado eficiente passa também pela análise do tempo que uma corporação
policial, no caso a PM, leva para atender uma solicitação do cidadão.
Neste sentido, a dimensão data também foi estudada, sendo que o dado extraído
preliminarmente, através de pesquisa na base de dados foi a média dos tempos, quais sejam:
Tempo de empenho: tempo do momento em que o telefonista recebe a ligação
na Central 190 ao momento em que o despachante, via rádio, repassa a informação da
ocorrência para a viatura;
Tempo de deslocamento: calculado do instante em que a guarnição toma
ciência da ocorrência ao momento em que ela informa estar no local dos fatos;
Tempo de atendimento: o período de tempo em que a guarnição PM leva para
dar atendimento à ocorrência.
60
Tempo de espera do solicitante: o período de tempo que a pessoa que ligou
para a central fica aguardando, contado a partir do instante em que ela faz a ligação telefônica
para o número 190 até o horário em que a viatura policial chega ao local.
Tempo total da ocorrência: do momento em que o solicitante liga para 190 ao
momento em que a guarnição repassa que a ocorrência já foi encerrada.
De um total de 187.863 ocorrências, foram realizados os empenhos de 210.273
guarnições no sistema EMAPE. Deste total de guarnições empenhados, em apenas 158.492 o
momento de chegada e de encerramento foi registrado corretamente, resultando em
aproximadamente 24,62% dos empenhos sem este tipo de dado cadastrado. Com
aproximadamente ¼ dos despachos de viatura sem os dados de data e hora em que chegaram
na ocorrência e quando ela foi encerrada por aquela viatura, surge uma primeira constatação:
que há algum tipo deficiência no procedimento de troca de informações entre a Central e as
viaturas que estão realizando o atendimento.
Com relação ao tempo, a média para empenho nas ocorrências foi de 10 minutos e 50
segundos. O tempo gasto no deslocamento foi, na média, de 10 minutos e 21 segundos. Já o
tempo médio gasto no atendimento foi de 28 minutos e 58 segundos. Temos, então, que o
solicitante fica aguardando a chegada de uma viatura PM no local da ocorrência por, em
média, 22 minutos e 39 segundos. Para o cálculo destes tempos foram consideradas somente
as ocorrências em que o momento de chegada e de encerramento da ocorrência foi cadastrado
na Central.
Com relação aos três principais tipos de ocorrências atendidas pela PM em Balneário
Camboriú (Ocorrências diversas, crimes e contravenções e auxílios à comunidade) foi
possível criar o gráfico comparativo exposto na Figura 10, que traz as médias de tempo de
empenho e de deslocamento destes três grupos de ocorrências.
61
Figura 10. Tempos de empenho e deslocamento médios para ocorrências tipo D, C e A.
O que se pode perceber é que grande parte das ocorrências é despachada (tempo de
empenho) em um período de tempo de 5 a 10 minutos (área ciano). No gráfico de tempo de
deslocamento temos um incremento no número de empenhos em que as guarnições chegaram
em pelo menos 5 minutos (área vermelha), sendo tal incremento mais acentuado nas
ocorrências do tipo C (crimes e contravenções) e A (auxílios à comunidade).
Foram feitos, a partir daí, cálculos de média de tempo para alguns tipos de ocorrências
criminosas, de tal forma que se pudesse verificar o desempenho da central 190 em virtude da
gravidade das ocorrências. Chegou-se aos números demonstrados na Tabela 1.
Tabela 1. Comparativo entre os tempos relacionados ao atendimento da ocorrência de acordo com o
tipo de crime.
Tempo/Tipo
ocorrência
Todos os tipos
Tipo C2 –
Crimes contra
patrimônio
Tipo C21 e C22 Tipo C104 e 114
– furtos e roubos – Homicídios e
sua tentativa
Tempo para
empenho
12m18s
10m34s
10m11s
20m55s
Tempo para
deslocamento
10m21s
09m57s
09m12s
05m08s
Tempo para
atendimento
28m58s
33m33s
30m36s
1h05m19s
Tempo de espera 22m39s
do solicitante
20m30s
19m22s
25m59s
O que se percebe com o comparativo acima é que a tendência é de os tempos de
empenho e de deslocamento se reduzirem à medida que se aumenta a gravidade da ocorrência.
62
Exceção se faz a ultima coluna, de ocorrências tipo C104 e C114, que registra alto tempo de
empenho e baixo tempo de deslocamento.
Tal situação pode estar sendo evidenciada em virtude de mau uso do sistema. Em
ocorrências desta gravidade é comum o telefonista repassar o caso diretamente ao
despachante antes mesmo da ocorrência ter sido gerada no sistema. Da mesma forma, o
despachante informa todas as guarnições acerca da ocorrência, não se preocupando, em um
primeiro momento, em fazer o controle de quais viaturas estão se deslocando ao local.
Ainda com relação aos tempos, foi buscado identificar, na base de dados dos tempos
das guarnições, em que categorias de ocorrências consumia-se mais tempo para realizar o
atendimento. A partir destes dados foi criada a Tabela 2.
Tabela 2. Comparativo de tempo gasto no atendimento (atributo tempo_atendimento) das diversas
categorias de ocorrências.
Área da ocorrência
Tempo de atendimento
(em segundos)
Tempo de atendimento % do tempo de
(em horas)
atendimento total
Crimes e
contravenções (C)
78853920
21903,87
28,63%
Serviços/atividades
operacionais (P)
67231320
18675,37
24,41%
Emergências/traumas 42804120
e acidentes (E)
11890,03
15,54%
Auxílios à
comunidade (A)
34941600
9706
12,69%
Ocorrências diversas
(D)
33119880
9199,97
12,02%
Serviços/Atividades
de fiscalização de
trânsito (Y)
12689520
3524,87
4,61%
Serviços/Atividades
Afins (S)
5447700
1513,25
1,98%
Incêndios (I)
199860
55,52
0,07%
Serviços de proteção
à natureza (N)
162540
45,15
0,05%
Total
275450460
76514,02
100,00%
63
Apesar de não ser o tipo de ocorrência mais frequente, é nas situações de crimes e
contravenções que os policiais militares permanecem mais tempo em atendimento. As
atividades operacionais, que englobam operações preventivas, escoltas, policiamentos em
futebol, em eventos públicos e privados, etc, vem em segundo lugar, ocupando 24,41% do
tempo de atendimento das guarnições policiais. Tal dado é importante já que evidencia que a
Polícia Militar não possui foco eminentemente repressivo, e busca desempenhar atividades
preventivas de preservação de ordem pública em quase ¼ (24,41%) do tempo.
Com relação ao tipo de viatura utilizado e o tipo de ocorrência atendida, foi elaborado
o gráfico da Figura 11, onde deve está evidenciada a distribuição das ocorrências por tipo de
veículo utilizado e por serviço prestado durante o atendimento.
Figura 11. Distribuição de ocorrências por tipo de veículo utilizado no atendimento e tipos de
atendimentos para o qual foram empenhados.
Primeiramente há de ser destacado que grande parte das ocorrências acaba sendo
atendida pelas viaturas do tipo automóvel, seguidas pelas motocicletas. Na Figura 11
podemos observar que há a presença da Central 190, pois muitas vezes o efetivo que trabalha
neste setor é o responsável pela resolução de determinados tipos de ocorrências e podem ser
empenhados no sistema para realizar o monitoramento das câmeras em certos tipos de
situação.
O que também pode ser destacado nesta estrutura é a distribuição das ocorrências do
tipo “E” (Emergências, traumas e acidentes – cor cinza), que aparece quase com a mesma
incidência entre as viaturas do tipo automóvel e motos. Isto revela a tendência que as
64
Unidades de Polícia Militar possuem de utilizar os Policiais Militares embarcados em
motocicleta para realizar o atendimento de acidentes de trânsito.
Apesar de não ter sido empregada nenhuma técnica ou algoritmo específico na fase de
pré-processamento do WEKA, foi possível perceber que se trata de uma ferramenta poderosa
de cruzamento de dados, que, em um primeiro momento, oportunizou o desenvolvimento de
hipóteses e conclusões acerca das diversas atividades realizadas pela PM em Balneário
Camboriú.
3.3.3 Clusterização
Após as diversas conclusões obtidas na etapa de pré-processamento, foi realizada a
segmentação dos dados de atendimentos, de tal forma que se pudesse obter segmentos de
ocorrências que possuam características semelhantes entre si e diferentes entre os outros
segmentos. Foram utilizados nesta pesquisa os argumentos do Quadro 3:
Base:
data_mart_ocorrencia
Query:
select
if(guarnicoes_empenhadas
>
0,
1,
0)
foi_empenhada,
if(pessoas_envolvidas > 0, 1, 0) ha_envolvidos, if(vitima > 0, 1, 0) ha_vitima,
if(agente > 0, 1, 0) ha_agente, if(testemunha > 0, 1, 0) ha_testemunha,
if(condutor > 0, 1, 0) ha_condutor, if(crianca > 0, 1, 0) ha_crianca,
if(adolescente > 0, 1, 0) ha_adolescente, if(idoso > 0, 1, 0) ha_idoso,
if(dia_pagamento like "sim",1,0) dia_pagamento, if(final_de_semana like
"sim",1,0) final_de_semana, if(area like "C",1,0) crime, area, if(chuva like
"true",1,0) chuva, if(nevoeiro like "true",1,0) nevoeiro, if(trovoada like
"true",1,0) trovoada from dmocorrencia.data_mart_ocorrencia where
data_mart_ocorrencia.pessoas_envolvidas > 0;
Justificativa Realizar a clusterizaçao das ocorrências e obter 06 segmentos de ocorrências
que possuem entre si características mais semelhantes e entre os segmentos
características distintas.
Algoritmo
weka.clusterers.SimpleKMeans -N 6 -A "weka.core.EuclideanDistance -R firstlast" -I 500 -S 10
Atributos
foi_empenhada, ha_vitima, ha_agente, ha_testemunha, ha_condutor
inicialmente ha_crianca, ha_adolescente, ha_idoso, dia_pagamento, final_de_semana, crime,
presentes
area, chuva, nevoeiro e trovoada.
Quadro 3. Parâmetros utilizados na pesquisa com algoritmo SimpleKMeans.
O algoritmo dividiu o grupo de ocorrências em 06 clusters distintos, abaixo descritos
como Cluster 0 a 5, que, após análise, evidenciaram o seguinte:
65
Cluster 0, com 25% das ocorrências: não eram crimes, não ocorriam em final
de semana e em sua grande maioria eram Auxílios.
Cluster 1, com 15% das ocorrências: crimes que não acontecem em dia de
pagamento e em que ninguém é preso.
Cluster 2, com 6% das ocorrências: ocorrências em que sempre são
empenhadas guarnições para atendimento, que ocorrem durante o final de semana, não são
crimes e em sua maioria são emergências.
Cluster 3, com 14% das ocorrências: ocorrências que não são crimes, em sua
maioria emergências e que não ocorrem nos finais de semana.
Cluster 4, com 14% das ocorrências: ocorrências que não ocorrem em dia de
pagamento (começo e final do mês), que não são crimes e em sua maioria são auxílios.
Cluster 5, com 25% das ocorrências: crimes em geral, sem características que o
destacassem dos demais.
O resultado obtido pelo WEKA pode ser visualizado na Figura 12.
66
Figura 12. Resultado do algoritmo simplekmeans no WEKA, com 06 clusters.
Em outra atividade experimental desenvolvida na tarefa de segmentação foram
encontrados resultados interessantes com relação às ocorrências de crime e contravenção
(código C), desta vez com o algoritmo FarthestFirst. Foram utilizados parâmetros descritos
no Quadro 4.
Base:
data_mart_ocorrencia
Query:
select if(pessoas_envolvidas > 0, 1, 0) ha_envolvidos, if(vitima > 0, 1, 0)
ha_vitima, if(agente > 0, 1, 0) ha_agente, if(testemunha > 0, 1, 0)
ha_testemunha, if(condutor > 0, 1, 0) ha_condutor, if(dia_pagamento like
"sim",1,0)
dia_pagamento,
if(final_de_semana
like
"sim",1,0)
final_de_semana, if(media_empenho <= 300, 1, 0) empenho_em_5min,
if(media_deslocamento
<=
300,
1,
0)
deslocamento_em_5min,
if(media_empenho > 300, 1, 0) empenho_maior5min, if(media_deslocamento >
300, 1 , 0) deslocamento_maior5min, violencia_potencial, periodo,
dimensao_codigo.grupo,
chuva
from
data_mart_ocorrencia
JOIN
data_mart_ocorrencia_tempo
Ond
ata_mart_ocorrencia.id=data_mart_ocorrencia_tempo.ocorrencia_id
JOIN
dimensao_codigo
ON
67
dimensao_codigo.id=data_mart_ocorrencia.codigo_id
data_mart_ocorrencia.codigo_id LIKE "C%";
and
Justificativa Realizar a clusterizaçao das ocorrências de crime e contravenção e obter
segmentos de ocorrências que possuem entre si características mais
semelhantes e entre os segmentos características distintas.
Algoritmo
weka.clusterers.FarthestFirst -N 6 -S 1
Atributos
ha_vitima,
ha_agente,
final_de_semana,
empenho_em_5min,
inicialmente deslocamento_em_5min, violencia_potencial, periodo e grupo.
presentes
Quadro 4. Parâmetros usados para pesquisa com o algoritmo FarthestFirst em ocorrências de crime e
contravenções (C).
Para este algoritmo foi utilizado o atributo violencia_potencial, atributo booleano
marcado como verdadeiro quando na presença das seguintes palavras chave no atributo de
descrição dos códigos de ocorrência: roubo, assalto, sequestro, disparo de arma, homicídio,
estupro, motim e atentado violento, que buscou identificar as violências com o mais alto nível
de violência por parte do agressor.
O algoritmo apresentou 06 clusters com as seguintes informações:
Cluster 0, representando 27% das ocorrências: comumente não há vitima
identificada, há agente, acontece em finais de semana, o tempo de empenho é superior a cinco
minutos, o tempo de deslocamento é igual ou inferior a 5 minutos, geralmente acontecem a
noite e são ocorrências do tipo C7 – contra a paz pública. Este cluster identifica, de forma
geral, as ocorrências de perturbação do trabalho e sossego alheio.
Cluster 1, identificado em 15% das ocorrências – geralmente há vítima, não há
agente, ocorre durante a madrugada, não em finais de semana, e são ocorrências de crime
contra o patrimônio em que há violência potencial. Nestas ocorrências geralmente o tempo de
empenho é menor ou igual a 5 minutos, apesar do tempo de deslocamento ser acima. Tais
ocorrências identificam a tendência de acontecer roubos durante a madrugada, sem que seja
possível prender o agente.
Cluster 2, 24% dos casos de crimes e contravenções – crimes contra a pessoa,
geralmente não violentos, ocorridos durante as tardes de dias de semana em que tanto o tempo
68
de empenho e de deslocamento passa dos 5 minutos. São ocorrências, em geral, com potencial
de violência menor e em que não são identificadas as vítimas, tampouco os agentes.
Cluster 3, representando 8% das situações - ocorrências em que são
identificados os agentes e as vítimas, nas manhãs dos finais de semana. O tempo de empenho
é inferior ou igual a 5 minutos e são geralmente ocorrências de crimes contra a pessoa com
potencial de violência mais baixo.
Cluster 4, com pouca representatividade, apenas 3% dos casos – ocorrências de
crimes contra os costumes, em que não são identificados agentes e vítimas, ocorridas
geralmente nos finais de semana, tanto com tempo de deslocamento quanto de empenho
inferior ou igual a 5 minutos. Este cluster, apesar de representar 3% das ocorrências revela um
dado interessante: dos crimes contra os costumes, os únicos classificados com potencial de
violência elevado são os sexuais, ou seja, o estupro - tentado e consumado - e o atentado
violento ao pudor.
Como a segmentação busca maximizar a semelhança entre os elementos do mesmo
segmento e maximizá-las entre segmentos distintos, a conclusão que se pode tirar do cluster 4
é que, do universo de ocorrências que acontecem nos finais de semana à tarde, este tipo de
violência acaba por se destacar. Portanto, os policiais que trabalham nos finais de semana a
tarde tem maior chance de atender este tipo de situação.
Cluster 5, com 16% de representatividade – ocorrências de crimes contra a
incolumidade pública, ocorridos sem identificação de vítimas e agentes, durante as
madrugadas de dias da semana. Este cluster identifica, de forma geral, as denúncias de
comércio de entorpecentes, em que a denúncia acaba sendo anônima e, em virtude da
característica ostensiva da PM, o trabalho de realizar a prisão em flagrante de tais criminosos
acaba sendo bastante dificultado.
Cluster 6, com 5% das ocorrências – ocorrências com baixo potencial de
violência, que acontecem nas manhãs de dias de semana, com tempo de empenho abaixo dos
5 minutos e de deslocamento superior, com identificação de agentes e vítimas.
69
Na Figura 13 temos o resultado da pesquisa, com a identificação dos 07 segmentos e
sua distribuição na amostra.
Figura 13. Resultado do algoritmo FarthestFirst em pesquisa de segmentos de crimes
e contravenções.
3.3.3 Associação
Na busca por conhecimento relevantes acerca das ocorrências na cidade de Balneário
Camboriú, foram realizadas diversas pesquisas de associação, sendo utilizado, em sua grande
maioria, o algoritmo Apriori e o PredictiveApriori, que, a partir dos parâmetros a seguir, nos
forneceram alguns resultados interessantes. No Quadro 5 temos os parâmetros utilizados para
realizar a pesquisa com o algoritmo PredictiveApriori em ocorrências de homicídio tentado e
consumado.
70
Base:
data_mart_ocorrencia
Query:
Select * from data_mart_ocorrencia where codigo_id like “C1%4”
Justificativa Realizar pesquisa sobre ocorrencias de homicídio (C104) e tentativa de
homicídio (C114)
Algoritmo
weka.associations.PredictiveApriori -N 100 -c 3
Atributos
guarnicoes_empenhadas, pessoas_envolvidas, dia_do_mes, mês, ano,
inicialmente final_de_semana,
periodo,
logradouro_bairro,
descricao_ocorrencia,
presentes
temp_media, chuva, codigo_id, crianca, adolescente, adulto_jovem, adulto e
idoso.
Quadro 5. Parâmetros utilizados para realizar pesquisa de associação com algoritmo PredictiveApriori
em ocorrências de homicídio tentado e consumado.
Com esta configuração foram obtidos alguns resultados, que seguem:
1. codigo_id=C114 82 ==> crianca=0 82
acc:(0.98745): A regra nos revela que
ocorrências de homicídios tentados (codigo_id=C114) não possuem crianças envolvidas com
98,74% de certeza.
2. pessoas_envolvidas=1 adulto_jovem=1 24 ==> masculino=1 24
acc:(0.9614): Da
mesma forma, o algoritmo PredictiveApriori mostra nesta regra, com aproximadamente 96%
de certeza, que nas ocorrências de homicídio tentado e consumado, quando há apenas uma
pessoa envolvida e ela é um adulto jovem, trata-se de pessoa do sexo masculino.
Cabe destacar que, numa ocorrência de tentativa de homicídio ou homicídio, a PM é
obrigada a pegar os dados básicos da vítima para cadastro. Desta forma, infere-se que,
havendo somente uma pessoa envolvida na ocorrência, ela é a vítima.
Novas pesquisas de associação foram realizadas alterando-se apenas os atributos,
conforme pode ser verificado no Quadro 6, direcionando o algoritmo para obtenção de regras
entre menos variáveis, com os seguintes resultados:
Base:
data_mart_ocorrencia
Query:
Select * from data_mart_ocorrencia where codigo_id like “C1%4”
Justificativa
Realizar pesquisa sobre ocorrencias de homicídio (C104) e tentativa de
homicídio (C114)
Algoritmo
weka.associations.PredictiveApriori -N 100 -c 3
Atributos
guarnicoes_empenhadas,
dia_do_mes,
mês,
ano,
final_de_semana,
71
inicialmente
presentes
periodo, logradouro_bairro, descricao_ocorrencia, temp_media e chuva.
Quadro 6. Parâmetros utilizados para realizar pesquisa de associação em ocorrências de homicídio consumado e tentado.
1.
periodo=tarde
logradouro_bairro=Dos
Municipios
8
==>
chuva=true
8
acc:(0.97249): A regra revela que ocorrências de tentativa de homicídio ou homicídios
existentes no período da tarde, no bairro dos municípios, aconteceram em dias chuvosos com
97% de certeza.
2. mes=4 descricao_ocorrencia=HOMICIDIO 7 ==> final_de_semana=nao 7
acc:(0.96734): Homicídios no mês de abril não aconteceram nos finais de semana com 96,7%
de certeza.
3. mes=4 11 ==> final_de_semana=nao 9 acc:(0.76227): De forma geral, homicídios
tentados e consumados no mês de abril não aconteceram no final de semana com 76,22% de
certeza.
No total há 11 ocorrências de homicídio tentado ou consumado para o mês de abril, e
apenas 2 delas foram registradas em finais de semana. Do total geral de ocorrências de
homicídio tentado e consumado, há 69 (47,9%) ocorrências nos finais de semana e 75 (52,1%)
em dias de semana. Para o mês de abril, temos a seguinte divisão: 9 (81%) não ocorreram em
finais de semana e 2 (19 %) sim, revelando uma incidência anômala deste tipo de ocorrência
quando no mês de abril.
4. mes=8 5 ==> final_de_semana=sim 5
acc:(0.94963): A informação trazida com
esta regra é que no mês de agosto, ocorrências de homicídio e tentativa de homicídio
aconteceram nos finais de semana com 94,9% de certeza.
5. logradouro_bairro=Nova Esperanca 7 ==> chuva=false 6
acc:(0.78666): Nesta
associação revela-se que as ocorrências de homicídio tentado e consumado no bairro nova
esperança acontecem, com 78,6% de certeza, em dias sem chuva.
Com a obtenção destas regras, vislumbrou-se que novas informações poderiam ser
obtidas através da base de dados de pessoas envolvidas, e, desta forma, foram utilizadas as
variáveis descritas no Quadro 7, com os seguintes resultados:
72
Base:
data_mart_envolvido
Query:
Select * from data_mart_envolvido where codigo_id like “C1%4”
Justificativa
Realizar pesquisa sobre ocorrências, vítimas e agentes de homicídio
(C104) e tentativa de homicídio (C114)
Algoritmo
weka.associations.PredictiveApriori -N 100 -c -1
Atributos
inicialmente
presentes
Idade, sexo, faixa_etaria, menor, adolescente, crianca, idoso,
adulto_jovem, adulto, descricao_envolvimento, dia_do_mes, mês, ano,
dia_da_semana, hora, minuto, logradouro_bairro, codigo_id, temp_media,
chuva e trovoada.
Quadro 7. Parâmetros usados para realizar pesquisa na base de pessoas envolvidas, sobre ocorrências
de homicídio - tentado e consumado.
1. faixa_etaria=adulto_jovem descricao_envolvimento=Vitima codigo_id=C104 20
==> sexo=Masculino 20
acc:(0.97013): Vítimas de homicídio consumado com idade entre
18 e 25 anos (adulto jovem) são do sexo masculino com 97% de certeza. Esta regra confirma
a associação obtida na base de dados de ocorrências.
2.
faixa_etaria=adulto_jovem
sexo=Masculino 49
descricao_envolvimento=Vitima
50
==>
acc:(0.97011): Vítimas de homicídios (consumado ou tentado) com
idade entre 18 e 25 anos (adulto jovem) são do sexo masculino com 97% de certeza.
3.
descricao_envolvimento=Agente
HOMICIDIO 33 ==> sexo=Masculino 32
descricao_ocorrencia=TENTATIVA
DE
acc:(0.94681): Esta associação informa que
agentes de tentativa de homicídios são do sexo masculino com 94,6% de certeza
4. descricao_envolvimento=Agente 52 ==> sexo=Masculino 50
acc:(0.94555): Já
nesta regra tempos a informação de que agentes de homicídios ou tentativas de homicídios
são do sexo masculino com 94,5% de certeza.
5.
logradouro_bairro=Centro
descricao_ocorrencia=HOMICIDIO
rendicao_noturna=NAO rendicao_matutina=NAO 59
59
==>
acc:(0.99355): Outra descoberta foi a
apontada com esta regra, que demonstra que ocorrências de homicídio no bairro centro não
aconteceram nos períodos de rendição (troca de guarnição), com 99% de certeza.
73
Após a obtenção das regras relacionadas às ocorrências de homicídio, tanto na sua
forma consumada quanto na tentada, buscou-se estabelecer relações para as ocorrências de
roubo, conforme parâmetros estipulados no Quadro 8.
Base:
data_mart_envolvido
Query:
select * from data_mart_envolvido where codigo_id like "C215" or
codigo_id like "C218" or codigo_id like "C221" or codigo_id like "C222"
or codigo_id like "C223"
Justificativa
Realizar pesquisa sobre ocorrências, vítimas e agentes de roubos
Algoritmo
weka.associations.Apriori -N 10 -T 0 -C 0.8 -D 0.05 -U 1.0 -M 0.1 -S -1.0
-c -1
Atributos
inicialmente
presentes
Sexo, faixa_etaria, descricao_envolvimento, mês,
periodo, logradouro_bairro e descricao_ocorrencia.
dia_da_semana,
Quadro 8. Parâmetros de experimento de associação com algoritmo Apriori, sobre a base de dados de
pessoas envolvidas em ocorrências de roubo.
As regras obtidas também revelaram novos conhecimentos sobre tais situações:
1. descricao_envolvimento=Agente 441 ==> sexo=Masculino 411
conf:(0.93):
Quando o envolvido neste tipo de ocorrência é o agente, há 93% de certeza que ele é do sexo
masculino.
2. sexo=Feminino descricao_ocorrencia=ROUBO OU ASSALTO CONTRA PESSOA
389 ==> descricao_envolvimento=Vitima 335
conf:(0.86): Se a pessoa envolvida na
ocorrência específica de ROUBO OU ASSALTO CONTRA PESSOA é do sexo feminino, há
86% de certeza de que ela seja vítima.
3. sexo=Feminino periodo=noite 455 ==> descricao_envolvimento=Vitima 390
conf:(0.86): A regra diz que se a pessoa envolvida na ocorrência de roubo de forma geral é do
sexo feminino e a ocorrência aconteceu no período noturno, há 86% de certeza que é vítima.
4.
sexo=Feminino
descricao_ocorrencia=ROUBO
OU
ESTABELECIMENTO 428 ==> descricao_envolvimento=Vitima 366
ASSALTO
A
conf:(0.86): De
forma geral, se a pessoa envolvida em ocorrência de ROUBO OU ASSALTO A
ESTABELECIMENTO é do sexo feminino, há 86% de certeza de que seja vítima.
74
sexo=Feminino 1064 ==> descricao_envolvimento=Vitima 897
conf:(0.84): E,
genericamente falando, com relação às ocorrências de roubo, se o sexo da pessoa envolvida
neste tipo de ocorrência é o feminino, então há 84% de certeza de que se trata de uma vítima.
O que se pode inferir, a partir das associações acima, no que tange às ocorrências de
roubo, é que de forma geral os agentes deste tipo de crime são do sexo masculino, enquanto
que grande parte das femininas, quando envolvidas, figuram como vítimas neste tipo de
situação.
3.3.4 Predição
Através de algoritmos de predição, buscou-se verificar se havia a possibilidade de
prever o número de uma determinada categoria de ocorrências com base nas ocorrências de
outras categorias. Para tal, foi utilizada a função de regressão linear, com os parâmetros
disponibilizados no Quadro 9.
Base:
data_mart_dia
Query:
Select * from data_mart_dia
Justificativa
Estimar o número de determinado tipo de ocorrências em um espaço
temporal baseado nas demais variáveis
Algoritmo
weka.classifiers.functions.LinearRegression -S 0 -R 1.0E-8
Atributos
inicialmente
presentes
Crimes, auxilios, emergencias, ocor_diversas,
numero_ocorrencias,
guarnicoes_empenhadas, dia_pagamento, dia_do_mes, mês, temp_media,
atividades_operacionais, homicidio, tentativa_homicidio, disparo_arma,
roubo_consumado, roubo_banco, roubo_residencia, roubo_pessoa
e roubo_comercio.
Quadro 9. Variáveis utilizadas para experimento de predição com regressão linear.
Inicialmente o algoritmo obteve os resultados mostrados na Figura 14, onde se percebe
que pode ser usada a fórmula encontrada para prever, com base nas variáveis apresentadas, o
número total de ocorrências de uma determinada data com aproximadamente 12% de erro.
numero_ocorrencias =
0.7311 * crimes +
0.7105 * auxilios +
0.5992 * emergencias +
0.7313 * ocor_diversas +
0.2852 * guarnicoes_empenhadas +
-0.0332 * pessoas_envolvidas +
75
-0.1052 * vitimas +
-0.0258 * agentes +
0.0499 * condutores +
1.7226 * mes=6,8,5,4,9,10,11,3,12,2,1 +
-1.3595 * mes=8,5,4,9,10,11,3,12,2,1 +
-1.8616 * mes=4,9,10,11,3,12,2,1 +
2.4923 * mes=9,10,11,3,12,2,1 +
-1.3176 * mes=10,11,3,12,2,1 +
-1.3798 * mes=11,3,12,2,1 +
1.6713 * mes=12,2,1 +
5.0087 * mes=2,1 +
0.0965 * temp_media +
-0.0268 * humidade_media +
6.6998
Correlation coefficient
0.9921
Mean absolute error
3.8338
Root mean squared error
4.9878
Relative absolute error
12.6038 %
Root relative squared error
12.5609 %
Total Number of Instances
1449
Figura 14. Resultados apresentados pelo algoritmo LinearRegression sobre os parâmetros passados.
Reduzindo-se o número de variáveis, o algoritmo de regressão linear obteve nova
fórmula, desta vez com erro de 15%, conforme pode ser visualizado na Figura 15.
numero_ocorrencias =
1.0614 * crimes +
1.1137 * auxilios +
0.9584 * emergencias +
1.0361 * ocor_diversas +
2.3366 * mes=6,8,5,4,9,10,11,3,12,2,1 +
-1.9188 * mes=8,5,4,9,10,11,3,12,2,1 +
-2.274 * mes=4,9,10,11,3,12,2,1 +
3.6156 * mes=9,10,11,3,12,2,1 +
-2.1329 * mes=10,11,3,12,2,1 +
3.009 * mes=12,2,1 +
7.638 * mes=2,1 +
0.9416 * chuva=false +
7.9495
Correlation coefficient
0.9879
Mean absolute error
4.7191
Root mean squared error
6.1496
Relative absolute error
15.5142 %
Root relative squared error
15.4866 %
Total Number of Instances
1449
Figura 15. Resultados do algoritmo LinearRegression com parâmetros reduzidos.
76
Verifica-se que o algoritmo pode alcançar uma eficiência interessante no que tange a
previsão do número de ocorrências de uma determinada data, baseado nas demais ocorrências.
Contudo, tal dado pode se tornar irrelevante tendo em vista que, geralmente, obtendose acesso aos demais atributos, o usuário pode facilmente obter acesso ao número total de
ocorrências, sem ter que recorrer a qualquer tipo de fórmula preditiva para obter tal dado.
Apesar disto, é interessante observar os pesos que o algoritmo estabelece para cada
atributo. Merece destaque, portanto, o peso maior dado aos meses de dezembro, janeiro e
fevereiro (grifados no quadro), revelando matematicamente o aumento do número de
ocorrências neste período do ano.
Partindo-se destas conclusões, tentou-se obter o número de ocorrências de certo tipo a
partir da incidência de outras categorias de ocorrências. Neste sentido, contudo, os resultados
não foram satisfatórios. Fez-se tal experimento com as ocorrências de homicídio e de roubo,
obtendo-se os resultados mostrados na Figura 16.
homicidio =
roubo_comercio =
0.0012 * crimes +
0.0009 * ocor_diversas +
-0.0012 * numero_ocorrencias +
0.0006 * guarnicoes_empenhadas +
-0.0184 * dia_pagamento +
-0.003 * mes +
0.036 * tentativa_homicidio +
-0.0138 * roubo_pessoa +
0.0561
Correlation coefficient
Mean absolute error
Root mean squared error
Relative absolute error
Root relative squared error
Total Number of Instances
0.0083
0.0836
0.2172
101.796 %
100.6354 %
1449
0.0222 * crimes +
-0.0093 * auxilios +
0.0166 * emergencias +
0.0074 * ocor_diversas +
-0.0199 * numero_ocorrencias +
0.0088 * guarnicoes_empenhadas +
0.1024 * dia_pagamento +
-0.0106 * temp_media +
0.0153 * atividades_operacionais +
0.7407
Correlation coefficient
0.2129
Mean absolute error
0.6224
Root mean squared error
0.7828
Relative absolute error
95.4058 %
Root relative squared error
97.6976 %
Total Number of Instances
1449
(a)
(b)
Figura 16. Resultados de pesquisa de regressão linear: (a) sobre ocorrências de homicídio; (b) sobre
ocorrências de roubo a comércio.
77
Ou seja, partindo-se de outras variáveis, o algoritmo não conseguiu predizer o número
de ocorrências de homicídio ou roubo para um determinado período, apresentando erros da
ordem de 101% e 95%, respectivamente.
Outro experimento realizado e que não resultou em uma fórmula adequada foi o de
buscar prever o número de ocorrências do mês de janeiro de 2011 a partir dos dados históricos
do ano de 2008, 2009 e 2010. O único resultado satisfatório está demonstrado na Figura 17,
que evidencia que a fórmula para calcular o número ocorrências do tipo D308 (Nada
constatado) possui erro de 27%:
nada_constatado =
-0.6402 * auxilios +
1.3096 * emergencias +
45.0093 * roubos +
5.7563 * AVG(humidade_media) +
-1606.9599
Time taken to build model: 0.01 seconds
=== Evaluation on test set ===
=== Summary ===
Correlation coefficient
0
Mean absolute error
213.1422
Root mean squared error
213.1422
Relative absolute error
27.7891 %
Root relative squared error
27.7891 %
Total Number of Instances
1
Figura 17. Resultado de experimento com regressão linear para as ocorrências de 'nada constatado',
código D308.
Tentou-se verificar se o algoritmo seria capaz de chegar a uma fórmula que
apresentasse o número de ocorrências de um determinado mês baseado nas ocorrências do
mês anterior. A Figura 18 mostra o resultado deste experimento, onde se verifica que a
fórmula possui aproximadamente 70% de erro:
numero_ocorrencias =
0.8019 * ocor_diversas +
-0.6799 * pessoas_envolvidas +
2.3094 * agentes +
440.3071 * mes=8,4,9,10,2,1,11,12 +
1038.4256 * mes=11,12 +
394.9625 * ano=2008,2009 +
78
2097.1771
=== Summary ===
Correlation coefficient
Mean absolute error
Root mean squared error
Relative absolute error
Root relative squared error
Total Number of Instances
0.7489
432.1468
558.614
69.9663 %
68.2696 %
48
Figura 18. Resultado da função de regressão linear para previsão de ocorrências de um mês a partir das
ocorrências do mês anterior.
Como verificado, apesar dos inúmeros experimentos realizados, somente alguns
retornaram resultados que podem ser considerados relevantes. Em que pese à ausência de
resultados concretos, é possível utilizar o algoritmo de regressão linear nas bases de dados,
pois, de forma geral, revelará o peso que cada variável possui na tarefa de previsão.
3.3.5 Classificação
As técnicas de classificação foram utilizadas, primeiramente, para verificar se os
algoritmos conseguiam estabelecer uma regra para classificar as pessoas envolvidas nas
ocorrências pelo seu grau de envolvimento, de acordo com as demais variáveis pessoais e da
ocorrência. Os parâmetros do Quadro 10 foram os inicialmente adotados nesta tarefa.
Base:
data_mart_envolvido
Query:
select * from data_mart_envolvido where codigo_id LIKE “C2%”
Justificativa
Classificar as pessoas envolvidas em ocorrências de crime contra o
patrimônio no tipo de crime envolvido (atributo descricao_ocorrencia)
com base nas demais variáveis
Algoritmo
weka.classifiers.meta.RotationForest -G 3 -H 3 -P 50 -F
"weka.filters.unsupervised.attribute.PrincipalComponents -R 1.0 -A 5 -M
-1"
Atributos
inicialmente
presentes
Sexo, faixa_etaria, dia_da_semana,
descricao_ocorrencia.
periodo,
logradouro_bairro
e
Quadro 10. Variáveis utilizadas no WEKA para pesquisa de classificação com algoritmo
RotationForest.
Foi obtida uma árvore com 1.135 nós e 568 folhas que apresentou os resultados do
Quadro 11 e uma matriz de confusão conforme a demonstrada na Figura 19:
79
Correctly Classified Instances
3543
Incorrectly Classified Instances 12482
Kappa statistic
0.0914
Mean absolute error
0.0743
Root mean squared error
0.1954
Relative absolute error
95.4503 %
Root relative squared error
99.0619 %
Total Number of Instances
16025
22.1092 %
77.8908 %
Quadro 11. Resultados apresentados pelo algoritmo RotationForest em pesquisa por pessoas
envolvidas em ocorrência.
Figura 19. Matriz de confusão, onde se identifica a forma com que as pessoas foram classificadas nas
ocorrências.
Tendo em vista as características das pessoas, foi verificado se o algoritmo conseguia
distinguir as pessoas na categoria tipo de envolvimento (ou seja, se era vítima, agente,
testemunha etc), com base nas demais características de uma ocorrência de homicídio (tentado
ou consumado). Foi então utilizado o algoritmo JRIP com os parâmetros do Quadro 12.
Base:
data_mart_envolvido
Query:
select * from data_mart_envolvido where codigo_id LIKE “C1%4”
Justificativa
Classificar as pessoas envolvidas em ocorrências de crime de homicídio
(tentado e consumado) em seu tipo de envolvimento (atributo
tipo_envolvimento)
Algoritmo
weka.classifiers.rules.JRip -F 3 -N 2.0 -O 2 -S 1
Atributos
inicialmente
presentes
idade, sexo, faixa_etaria, descricao_envolvimento, mes_do_ano, periodo,
logradouro_bairro e descricao_ocorrencia.
Quadro 12. Parâmetros repassados ao algoritmo JRIP para classificação por tipo de envolvimento de
pessoa.
80
Após o processamento, foram obtidas as seguintes regras de classificação e resultados
apresentados no Quadro 13 e a matriz de confusão da Figura 20.
JRIP rules:
===========
(logradouro_bairro
=
Vila
Real)
and
(sexo
=
Feminino)
descricao_envolvimento=Outros (4.0/1.0)
(logradouro_bairro
=
Barra)
and
(mes_do_ano
=
August)
descricao_envolvimento=Testemunha (4.0/0.0)
=> descricao_envolvimento=Vitima (289.0/152.0)
Correctly Classified Instances
Incorrectly Classified Instances
[...]
Total Number of Instances
[…]
135
162
=>
=>
45.4545 %
54.5455 %
297
Quadro 13. Resultado emitido pelo algoritmo JRIP na classificação por nível de envolvimento das
pessoas
Figura 20. Matriz de confusão retornada pelo JRIP em pesquisa por tipo de
envolvimento.
Em análise aos resultados, incluindo-se as regras criadas, percebe-se que o algoritmo
cria uma regra que implica que em grande parte o resultado da pesquisa apontará a pessoa
como sendo vítima. Tal regra se reflete na matriz de confusão, onde as demais categorias de
envolvimento (testemunha, agente, etc), acabam sendo classificadas como vítimas,
registrando um erro de 45.45% na classificação.
Trabalhou-se também com o algoritmo J48graft, que, de forma semelhante ao JRIP,
produz regras semelhantes aos algoritmos de associação. Foram feitos diversos experimentos,
principalmente com a base de dados de ocorrências (buscando verificar se o algoritmo
classificava corretamente o tipo de ocorrência com base nos demais fatores) e de pessoas (se
81
era possível estabelecer qual a participação da pessoa na ocorrência com base nas demais
características dela e da ocorrência), sem, entretanto, obter-se resultados satisfatórios.
Neste sentido, foi realizado o experimento com o algoritmo J48graft, de acordo com as
variáveis presentes no Quadro 14.
Base:
data_mart_ocorrencia
Query:
select * from data_mart_ocorrencia codigo_id like "C2%"
Justificativa
Classificar as ocorrências da categoria C2* (crimes contra o patrimônio)
no seu tipo de acordo com as demais características.
Algoritmo
weka.classifiers.trees.J48graft -C 0.25 -M 2
Atributos
inicialmente
presentes
feriado,
dia_pagamento,
final_de_semana,
rendicao_noturna,
rendicao_matutina, periodo, logradouro_bairro e descricao_ocorrencia.
Quadro 14. Parâmetros utilizados na pesquisa de classificação sobre ocorrências de crimes contra
patrimônio.
Tendo como alvo a descrição da ocorrência (atributo descricao_ocorrencia), o
algoritmo produziu uma árvore com alguns resultados que pareciam promissores e estão
evidenciados no Quadro 15.
[...]
logradouro_bairro = Centro
| feriado = ano: FURTO DE VEICULO (43.0/31.0)
| feriado = nao
| | periodo = madrugada
| | | final_de_semana = nao
| | | | rendicao_matutina != SIM: FURTO TENTADO (1116.0/908.0)
| | | final_de_semana = sim
| | | | dia_pagamento != sim: FURTO DE VEICULO (618.0/529.0)
[...]
| | periodo = manha
| | | rendicao_matutina = NAO: FURTO CONSUMADO (1150.0/907.0)
[...]
=== Summary ===
Number of Leaves : 295
Size of the tree :
440
Correctly Classified Instances
Incorrectly Classified Instances
2936
11468
20.3832 %
79.6168 %
Quadro 15. Resultados da classificação realizada com uso do algoritmo J48graft.
82
Para a árvore e as regras de classificação geradas, o algoritmo retornou a matriz de
confusão da Figura 21.
Figura 21. Matriz de confusão do classificador J48graft para o alvo descrição da ocorrência
(atributo descricao_ocorrencia)
Apesar de produzir regras de classificação relativamente interessante, vê-se a baixa
quantidade de acertos do algoritmo, que ficou em 20,3%. Muitas regras apresentadas
pareciam reveladoras, mas foram rapidamente descartadas como válidas quando foi feita a
pesquisa na base para verificar os acertos e erros do algoritmo.
Em outra tentativa, com os parâmetros do Quadro 16, tentou-se verificar se o
algoritmo JRIP conseguia criar regras que classificavam as ocorrências de tentativa de
homicídio e homicídio de acordo com as demais variáveis.
Base:
data_mart_ocorrencia
Query:
Select * from data_mart_ocorrencia where codigo_id LIKE “C1%4”
Justificativa
Classificar as ocorrências de homicídios e sua forma tentada de acordo
com dados da ocorrência e de atuação de guarnições
Algoritmo
weka.classifiers.rules.JRip -F 3 -N 2.0 -O 2 -S 1
Atributos
inicialmente
presentes
Vitima, agente, dia_pagamento, final_de_semana, rendicao_noturna,
rendicao_matutina, periodo, logradouro_bairro e descricao_ocorrencia.
Quadro 16. Valores utilizados na pesquisa de classificação com o algoritmo JRIP.
Conforme vê-se no Quadro 17, o algoritmo JRIP apenas supôs que destes dois tipos de
ocorrência (homicídio tentado e consumado), era mais eficiente classificar todas como
83
TENTATIVA DE HOMICÍDIO, resultando numa classificação com 55,5% de erro e numa
matriz de confusão pouco confiável.
JRIP rules:
===========
=> descricao_ocorrencia=TENTATIVA DE HOMICIDIO (144.0/62.0)
Correctly Classified Instances
Incorrectly Classified Instances
[...]
Total Number of Instances
80
64
55.5556 %
44.4444 %
144
=== Confusion Matrix ===
a b <-- classified as
16 46 | a = HOMICIDIO
18 64 | b = TENTATIVA DE HOMICIDIO
Quadro 17. Resultado retornado pelo algoritmo JRIP.
Um algoritmo que produziu um resultado ao menos interessante, sob o ponto de vista
da conclusão apresentada, é o classificador OneR, utilizado com os argumentos presentes no
Quadro 18.
Base:
data_mart_envolvido
Query:
Select * from data_mart_envolvido where codigo_id NOT LIKE “D%”
Justificativa
Classificar as pessoas na categoria de tipo de envolvimento (atributo
descricao_envolvimento) com base nos demais dados da ocorrência.
Algoritmo
weka.classifiers.rules.OneR -B 6
Atributos
inicialmente
presentes
Sexo, faixa_etaria, descricao_envolvimento, dia_da_semana, periodo,
logradouro_bairro e descricao_ocorrencia.
Quadro 18. Argumentos utilizados no classificador OneR, para classificar as pessoas na categoria de
tipo de envolvimento.
As regras apresentadas pelo algoritmo, observadas no Quadro 19, é que possuem
característica interessante. O algoritmo OneR utiliza somente um atributo para realizar a
classificação. Desta forma, dos 06 atributos repassados, classificou as pessoas baseando-se
exclusivamente pelo tipo de ocorrência (atributo descricao_ocorrencia).
84
descricao_ocorrencia:
FURTO A RESIDENCIA -> Vitima
TRANS CONTRAMAO EM VIAS SENTIDO UNICO -> Condutor
ACIDENTE DE VEICULOS COM DANOS MATERIAIS
-> Condutor
AVERIGUACAO DE ELEMENTO EM ATITUDE SUSPEITA -> Outros
HOMICIDIO -> Vitima
LESOES CORPORAIS
-> Vitima
FURTO TENTADO -> Agente
PORTE DE ARMA -> Agente
ARROMBAMENTO OU FURTO EM VEICULO -> Vitima
[...]
FURTO CONSUMADO
-> Vitima
[...]
ROUBO OU ASSALTO CONTRA PESSOA
-> Vitima
[...]
USO DE TOXICO OU ENTORPECENTES
-> Agente
[...]
JOGO DE AZAR
-> Agente
NEGAR SALDAR DESPESAS
-> Agente
ESTELIONATO
-> Agente
RECEPTACAO
-> Agente
[…]
COMERCIO DE TOXICO OU ENTORPECENTES
-> Agente
RIXA BRIGA ENTRE TRES OU MAIS PESSOAS
-> Agente
FERIMENTO POR ARMA DE FOGO
-> Vitima
[...]
ROUBO TENTADO -> Vitima
ROUBO OU ASSALTO A ESTABELECIMENTO
-> Vitima
[...]
ESTUPRO -> Vitima
[...]
JOGO DO BICHO -> Agente
[...]
ESTAC NA CONTRA MAO DE DIRECAO
-> Condutor
[...]
Quadro 19. Algumas das regras criadas pelo algoritmo OneR, classificando as pessoas de acordo com
o tipo de ocorrência.
Apesar de simplista, por apenas apresentar os resultados baseados em uma variável,
percebe-se que a classificação baseada no tipo de ocorrência que a pessoa está envolvida
apresentou resultados melhores do que os avaliados anteriormente, podendo-se constatar os
erros e acertos no Quadro 20.
85
=== Summary ===
Correctly Classified Instances
61508
Incorrectly Classified Instances 43703
Kappa statistic
0.4578
Mean absolute error
0.0831
Root mean squared error
0.2882
Relative absolute error
52.9139 %
Root relative squared error
102.8734 %
Total Number of Instances
105211
Ignored Class Unknown Instances
12
58.4616 %
41.5384 %
Quadro 20. Resultados retornados pelo algoritmo OneR.
Para melhor ilustrar a classificação realizada pelo OneR, a Figura 22 revela a matriz de
confusão onde se observa que com esta regra simples, o algoritmo conseguiu classificar com
boa precisão as pessoas como condutores (acertou 22145 – 89,32% e errou 2649 – 10,68%
dos casos) e como desaparecidos (acertou em 90 – 81,82% e errou em 20 – 18,18%). Para as
demais categorias de envolvimento o resultado não foi tão bom, apresentando, conforme
quadro acima, incorreção na classificação em 41,53% dos casos.
Figura 22. Matriz de confusão calculada pelo OneR, que classificou o grau de envolvimento da
pessoa baseado no tipo de ocorrência.
3.4 METODOLOGIA PARA MINERAÇÃO DE DADOS DAS OCORRÊNCIAS DA PMSC
No decorrer de toda a atividade de mineração de dados foi possível, através do uso
prático da ferramenta WEKA e da manipulação da base de dados, estipular uma série de
práticas para os pesquisadores que desejam se utilizar de tal ferramenta para minerar dados.
Desta forma, propõem-se as seguintes práticas para que tal tarefa possa ser realizada
com maior eficiência, superando automaticamente desafios que a pesquisa teve que transpor
por desconhecimento da ferramenta e de metodologia de mineração de dados.
86
De forma geral, deve-se seguir os passos adotados pela metodologia de mineração de
dados, contudo, serão trazidos à baila as nuances envolvidas na mineração de dados da base
de ocorrências da Central 190.
O primeiro passo é conseguir o registro das informações que se deseja minerar. Elas
devem estar no estado mais bruto possível para que no passo seguinte possam ser trabalhadas,
sempre mantendo o registro original. Assim, as ocorrências da Central 190 foram exportadas
do Sistema EMAPE em formato texto, através de arquivos gravados pelo sistema. Eles
contêm as informações de ocorrências de um determinado período de tempo, no formato que
pode ser visto na Figura 23.
Figura 23. Ocorrências da Central 190 exportadas em formato texto.
Em complemento, foram exportados os roteiros das viaturas, também em formato
texto, conforme evidenciado na Figura 24.
87
Figura 24. Roteiros de viaturas exportados no formato texto pelo sistema EMAPE.
A partir destes dois arquivos, foram elaborados programas em linguagem PERL para
sua interpretação, limpeza e posterior inserção na base de dados SQL, conforme modelagem
prévia.
Com relação aos dados da Polícia Militar, verificou-se que alguns dos códigos
presentes na base estavam em desacordo com a Diretriz do Comando Geral que prevê tal
codificação. Neste sentido, as infrações do código N foram tratadas em geral como
ocorrências de crimes contra a natureza, apesar de não terem sido especificados grupos e
áreas, como acontecem com as codificadas no grupo crimes e contravenções. As do código T
não se encontram mais em uso e não apareceram na base de ocorrências. Havia ainda
ocorrências que estavam na base de ocorrências e não estavam categorizadas na Diretriz, e
foram sendo adicionadas à medida que tais incongruências eram reveladas.
Depois de realizadas tais etapas, faz-se necessária a criação de data marts derivados,
que sumarizem e descrevam os dados de forma diferente da original e que possam ser
utilizados pelos diversos algoritmos do WEKA. Deve-se criar, desta forma, diversas tabelas
que conterão muitas variáveis e uma quantidade massiva de dados, mas serão utilizadas com
frequência e evitarão que, a cada nova consulta, o SGBD tenha que executar diversos joins e
filtros para mostrar o resultado. Este processo poderá ser realizado durante toda a pesquisa,
mas sugere-se que o modelo dimensional seja seguido e que o pesquisador já tenha uma ideia
do que se quer minerar com o WEKA.
Após a criação da base, parte-se para o uso do WEKA, disponível para download na
internet, mas que necessita ser adaptado adequadamente para que seja capaz de ler
diretamente de uma base de dados. No caso em tela foi utilizado o MySQL, que é suportado
pelo WEKA. Apesar de não ser mandatório, realizar tal adaptação torna, sem dúvida, a
88
pesquisa mais ágil e prática. A forma nativa de importação dos dados no WEKA é através de
arquivos texto no formato ARFF, que não é nada prático quando há a necessidade de mudar,
restringir ou ampliar sua amostra de pesquisa de forma mais dinâmica.
Em relação ao WEKA, cabe destacar que grande parte das ferramentas disponíveis
possui um requisito imprescindível: uma amostra de dados com variáveis que sejam
relativamente independentes entre si. Portanto, apesar da modelagem dimensional sugerir que
as diversas variáveis sejam derivadas e transformadas em outras, que facilitarão o
entendimento e tornarão a leitura dos dados mais amigável, a maioria das ferramentas de
mineração dispensa tal cuidado, devendo apenas se ter a preocupação em conseguir grande
quantidade de incógnitas que não tenham vínculos diretos entre si.
Antes de partir para as atividades de mineração propriamente ditas, deve-se realizar
uma boa avaliação dos dados na fase de pré-processamento. Esta tela do WEKA Explorer
pode dar ao pesquisador uma variedade grande de informações, que podem direcionar a
pesquisa e até mesmo revelar incongruência nos dados.
A ferramenta de pré-processamento desenha gráficos, que podem ser utilizados para
visualizador a relação entre as diversas variáveis do problema. Esta etapa serve também para
ajustar as incógnitas, eliminando da amostra variáveis indesejadas ou inúteis. Da base de
ocorrências da Polícia Militar, devem ser eliminadas as chaves primárias (id) e o campo
ocorrencia_id (chave estrangeira), pois são identificadores únicos de dados que não agregam
nada à etapa de mineração. As modas devem ser evitadas sempre que possível, pois grande
parte dos algoritmos acabará vinculando as variáveis modais entre si, gerando relações que
agregam pouco conhecimento.
Para cada atividade de mineração devem ser observados os requisitos dos algoritmos.
Neste sentido, deve-se acessar a atividade selecionada e escolher a ferramenta computacional.
Se o algoritmo estiver indisponível, é por que alguma variável está em um formato não
suportado. As capacidades de cada algoritmo podem ser descobertas na sua caixa de
propriedades, nos botões More e Capabilities.
De forma geral, os algoritmos de classificação que produzem regras podem ser
utilizados com dados nominais, numéricos, dentre outros. Tais algoritmos produzirão regras
89
que buscarão classificar os dados para que se encaixe em uma categoria que deve ser definida
pelo pesquisador. Esta categoria em especial deve ser do tipo nominal.
Dentro da classificação há ainda os que retornam funções. Neste trabalho foi utilizada
a função de Regressão Linear. Como os demais algoritmos de classificação, a regressão aceita
dados numéricos e nominais, mas a variável que se pretende prever deverá ser numérica, caso
contrário o algoritmo não aparecerá como disponível.
Os algoritmos de associação também foram utilizados no trabalho. Uma das
preocupações que se deve ter em mente neste tipo de atividade é o tamanho da amostra e o
algoritmo a ser selecionado. Isto em virtude da memória computacional e do tempo de
processamento que os algoritmos associativos requerem para produzir resultados. É muito
custoso para o pesquisador aguardar várias horas para um resultado que não apresente
nenhuma regra interessante ou que possa ser refinada.
Os algoritmos Apriori e PredictiveApriori, utilizados nesta pesquisa, trabalham com
dados nominais. Caso existam dados numéricos na amostra, devem ser categorizados em
classes nominais na base de dados ou convertidos diretamente na etapa de pré-processamento.
A utilização de variáveis que não tenham relação conhecida entre si se faz necessária, pois os
algoritmos tem como objetivo chegar a tais relações. Caso usem-se variáveis vinculadas em
algum nível, os algoritmos retornarão diversas regras contendo tais associações, fazendo com
que o analista gaste precioso tempo verificando informações já conhecidas.
A base de dados de ocorrências de Balneário Camboriú pode ser aplicada em todos os
algoritmos acima mencionados, bastando realizar a conversão das variáveis, quando
necessário, e restringir a amostra para que os resultados não custassem muito a serem exibidos
pelo WEKA.
Independente do algoritmo selecionado e da base de dados estudada, torna-se
imprescindível realizar anotações sobre os experimentos executados. Estas notas devem
conter dados básicos das atividades realizadas, sem, contudo, consumir tempo excessivo do
pesquisador. Desta forma, sugere-se a adoção da tabela padrão apresentada neste trabalho, que
contem dados suficientes para que seja possível reproduzir os experimentos. A tabela faz
referência à base utilizada, a query que resultou nos dados importados para o WEKA, o que se
90
buscava descobrir com o experimento, o algoritmo e seus argumentos e os atributos
repassados ao algoritmo.
Para melhor exemplificar e explicar o que foi anteriormente sugerido, pode-se
observar o Quadro 21:
Base:
Deve ser constado em qual base ou data mart o pesquisador realizou a
pesquisa, tendo em vista as diversas interpretações que podem ser dadas
em virtude das fontes de dados que estão sendo pesquisadas.
Exemplo: data_mart_envolvido
Query:
Aqui deve ser anotada a pesquisa que foi feita na base de dados e que
resultou na amostra que foi estudada.
Exemplo: Select * from data_mart_envolvido where codigo_id NOT
LIKE “D%”
Justificativa:
Neste campo o pesquisador deve anotar o porquê de estar realizando
aquele experimento ou o que busca encontrar com tal atividade.
Exemplo: Classificar as pessoas na categoria de tipo de envolvimento
(atributo descricao_envolvimento) com base nos demais dados da
ocorrência.
Algoritmo:
Faz-se imprescindível registrar, também, o algoritmo e os parâmetros
utilizados para realizar a pesquisa de mineração. No WEKA, o comando
de mineração executado pelo software já mostra também os argumentos
selecionados.
Exemplo: weka.classifiers.rules.OneR -B 6
Atributos
inicialmente
presentes:
O pesquisador deve deixar anotado também os argumentos que foram
utilizados, tendo em vista que os resultados podem variar de acordo com o
número de argumentos utilizados.
Exemplo: Sexo, faixa_etaria, descricao_envolvimento, dia_da_semana,
periodo, logradouro_bairro e descricao_ocorrencia.
Quadro 21: Forma de notação adotada na pesquisa.
91
4. CONCLUSÃO
No decorrer do desenvolvimento deste trabalho, foi possível estabelecer uma série de
conclusões pertinentes, principalmente no que tange aos objetivos da pesquisa, sua
metodologia, dificuldades enfrentadas no transcurso do desenvolvimento e a possibilidade de
trabalhos futuros.
A aplicação de técnicas de mineração de dados nos registros de ocorrências do
Município de Balneário Camboriú foi realizada, gerando novos conhecimentos, úteis e
relevantes. Entretanto, apesar dos intensos esforços e dos diversos experimentos realizados,
não foi possível chegar a nenhum conhecimento que pudesse ser classificado como revelador
e que tivesse o condão de mudar radicalmente a forma de pensar o planejamento das ações de
polícia ostensiva. Foi possível, contudo, confirmar cientificamente e matematicamente
diversas informações que por vezes, são obtidas de forma empírica e baseadas na experiência
policial militar.
No início da pesquisa verificou-se que a Polícia Militar não dispunha de um sistema de
data marts completo, que pudesse ser utilizado neste trabalho acadêmico. Desta forma, foi
necessário buscar os dados diretamente da fonte, qual seja, a Central Regional de
Emergências 190 de Balneário Camboriú.
O Sistema EMAPE, utilizado na Central 190 e responsável por gerenciar e armazenar
as ocorrências policiais, apresenta pouca compatibilidade com demais sistemas de bancos de
dados. Aliada a esta incapacidade, está a falta de módulos estatísticos avançados, que possam
gerar, de maneira prática e rápida, informação e conhecimento aos gestores de segurança
pública. A modelagem relacional proposta neste trabalho facilitou o entendimento dos dados
de ocorrências armazenados no Sistema EMAPE e possibilitou a elaboração de um modelo
dimensional, que podem ser utilizados futuramente em pesquisas que obtenham dados
semelhantes.
Os dados armazenados na Central de Emergência 190, migrados para uma SGBD SQL
durante o desenvolvimento da pesquisa, estavam mal estruturados e careciam de maior refino
e validação. A importação de tais bases para a realização da pesquisa se deu através da
92
construção de programas capazes de ler a precária estrutura dos arquivos de ocorrências,
convertendo-os para uma estrutura mais adequada para a mineração de dados. Muitas
inconsistências foram detectadas e grande parte delas foi resolvida durante o processo de
migração. Entretanto, determinadas características do sistema de ocorrências da PMSC,
construído há mais de 20 anos, dificultaram tal tarefa e impossibilitaram a importação de uma
maior quantidade de atributos, fato este que teve certo impacto na pesquisa.
Foi possível constatar, através da análise dos dados, que o uso do Sistema EMAPE não
é devidamente regulado: não há normativa que auxilie os profissionais das Centrais 190 a
preencher os campos com uma metodologia adequada e padronizada e não há muitos filtros e
controles nas entradas de dados do próprio software. Tais circunstâncias, que acabam gerando
dados incorretos, incompletos ou que não refletem a realidade dos fatos, podem ser
contornadas com a edição de diretrizes e normas internas e com adaptações ao programa
EMAPE, ações que padronizariam os dados produzidos, tornando-os mais confiáveis.
Importados os dados, foi realizada uma revisão bibliográfica que englobou programas
desenvolvidos por corporações policiais nos diversos países do mundo e pesquisas utilizando
mineração de dados em bases policiais, estas no Brasil. Foi possível verificar que este tipo de
trabalho ainda é pouco comum, mas, inobstante sua escassez, revela dados interessantes sobre
a segurança pública no nosso país.
Ainda durante a revisão bibliográfica, foram estudadas as diversas técnicas de
mineração de dados, com o intuito de verificar quais delas poderiam ser aplicadas durante a
pesquisa. Neste sentido, foram abordados conceitos e exemplos das mais comuns aplicações
da mineração de dados: classificação, estimativa, previsão, agregação, segmentação e
descrição.
Com este conhecimento em mãos, e já com a base de dados migrada, foi possível
estabelecer quais atividades poderiam trazer resultados interessantes e que seriam
desenvolvidas no trabalho. Assim, foram realizados diversos experimentos com classificação,
previsão e associação. Como o processo de mineração de dados é incremental e iterativo, por
vezes foi necessário retornar à fonte de dados, buscar novas variáveis, transformá-las e
processá-las para poder formular novas hipóteses e aplicar os algoritmos.
93
As atividades e estratégias adotadas, bem como a conclusão sobre cada experimento
realizado foi sendo documentada e registrada. Ao final foi possível elaborar uma série de
recomendações e boas práticas que foram anotadas no decorrer da pesquisa, de tal forma que
futuros pesquisadores possam utilizar tais recomendações em complemento à metodologia de
mineração de dados estudada.
Apesar de ter atingido os objetivos da pesquisa, foi necessária a transposição de alguns
obstáculos e dificuldades para que o trabalho tivesse sucesso. Um dos pontos a ser levantado
como dificuldade foi a incongruência na base de dados de ocorrências. A base foi importada
com um total de 187.863 registros de ocorrências, 119.326 registros de pessoas envolvidas e
210.273 registros de guarnições empenhadas. Em muitas delas o tratamento dos dados se dava
de forma trivial, com a segmentação, sumarização e contagem dos dados. Contudo, em
virtude do grande número de registros, era inviável verificar se, dado um histórico inicial de
tentativa de homicídio, o código gerado pelo operador foi o compatível com a ocorrência.
A dinâmica da atividade policial e a própria dinâmica da Central 190 também gera
diversas distorções na base de dados. Apesar dos dados importados da CRE190 terem sido
tomados como sendo o reflexo da realidade, por muitas vezes a rapidez com que as coisas
acontecem durante a atividade policial inibem seu registro correto no sistema. Da mesma
forma, a dinâmica do serviço na Central 190, com políticas sobre o uso do sistema,
interpretação das ocorrências e até a forma como determinada ocorrência é registrada
resultam num incremento de ocorrências ou em sua total supressão das bases de dados.
Ainda no que concerne aos dados, ficou claro, durante o transcorrer das atividades de
mineração, que apesar de conter muitos registros, a base apresentava poucas variáveis.
Citando o exemplo das pessoas envolvidas na ocorrência, os dados revelavam apenas de sexo,
idade e a participação da pessoa na ocorrência. Tal restrição teve impacto na pesquisa pois os
algoritmos utilizados demandavam, grande parte das vezes, por variáveis que não tivessem
qualquer relação entre si, de tal forma a poder revelar uma relação desconhecida entre tais
incógnitas.
94
Outra dificuldade encontrada é relacionada à própria atividade policial militar. Em
virtude da gama de serviços realizados pela corporação, que vão de apoio a mulheres grávidas
passando por escoltas e diligências com oficiais de justiça, chegando às ocorrências de prisão
em flagrante e óbitos, os algoritmos não conseguiram produzir nenhuma informação
reveladora acerca de todo o espectro de ocorrências atendidas em Balneário Camboriú. Para
que se pudesse produzir algum conhecimento, foi sempre necessário restringir a amostra a ser
passada aos algoritmos de mineração, dividindo-a em subgrupos específicos. Nesta pesquisa,
acabaram-se privilegiando as ocorrências mais violentas e com maior impacto social, como
furtos, roubos e homicídios, bem como as características das pessoas envolvidas em tais
situações.
Por fim, um dos grandes entraves encontrados no decorrer da pesquisa foi estabelecer
o melhor algoritmo a ser utilizado em cada caso. Apesar de a pesquisa bibliográfica ter sido
esclarecedora, o falta de domínio do software WEKA, aliado a massiva quantidade de dados
que se pretendia analisar, resultou em algoritmos que custavam a fornecer respostas e
demoravam horas e até mesmo dias para apresentar resultados que, em diversas ocasiões, não
tiveram qualquer relevância ou pudessem ser considerados estatisticamente satisfatórios.
Em que pesem as dificuldades enfrentadas e o os resultados nem sempre reveladores,
ficou claro que a mineração de dados é uma ferramenta poderosa a ser utilizada em qualquer
instituição ou corporação que queira aprimorar suas atividades ou negócios.
No âmbito da Polícia Militar de Santa Catarina, que durante o decorrer desta pesquisa
iniciou um processo de análise de informações com Business Intelligence, é possível verificar
que as informações obtidas com a mineração de dados superam as estatísticas básicas
fornecidas pelo Sistema EMAPE. Enquanto o EMAPE consegue apenas produzir tabelas
simples, contendo informações básicas dos números de ocorrências por período, guarnição,
logradouro, etc, as atividades de mineração de dados podem cruzar dados, gerar regras e
identificar novos padrões sobre as ocorrências, com maior potencial de agregar conhecimento
à área de segurança pública.
Neste rumo, um dos conhecimentos que pretendia ser adquirido era o de poder
classificar as ocorrências em uma escala de risco para o policial, baseado nos históricos inicial
95
e final e nos demais atributos. Contudo, tal atividade exigiria um treinamento supervisionado
do algoritmo e percebeu-se que demandaria grande quantidade de tempo para sua execução.
Fica, portanto, a ideia para um trabalho futuro, que pode agregar mais informações
sobre as ocorrências e sobre as pessoas envolvidas a partir da busca textual dos boletins de
ocorrência registrados nas Delegacias de Polícia ou até mesmo do histórico inicial e final dos
registros da Central, e, a partir daí, elaborar uma escala de gravidade ou risco para os policiais
no atendimento de ocorrências.
96
REFERÊNCIAS BIBLIOGRÁFICAS
ABERNETHY, Michael. Mineração de dados com o WEKA, Parte 2: Classificação e
armazenamento em cluster. DeveloperWorks Brasil. 2010. Disponível em
http://www.ibm.com/developerworks/br/opensource/library/os-weka2/. Acesso em: 16 Jan
2012.
ADAMSON, Christopher. Mastering Data Warehouse Aggregates: Solutions for Star
Schema Perfomance. Wiley Publishing: 2006. 344 p.
ADDERLEY, Richard. The Use of Data Mining Techniques in Crime Trend Analysis and
Offender Profiling. 2007. 255 f. Tese (Doutorado) - Curso de Filosofia, University Of
Wolverhampton, Wolverhampton, 2007. Disponível em: <http://hdl.handle.net/2436/15413>.
Acesso em: 14 set. 2011.
ARAÚJO, Vania Maria Rodrigues Hermes de. Sistemas de informação: nova abordagem
teórico-conceitual. Ciência da Informação, Brasília, v. 24, n. 1, jan. 1995.
ÁVILA, B. C. Data Mining. Dissertação (Mestrado em Informática Aplicada) – Pontifícia
Univerisade Católica do Paraná PUC-PR. Curitiba, 1998.
BATISTA, Emerson de Oliveira. Sistemas de Informação: O Uso Consciente da Tecnologia
para o Gerenciamento. Saraiva: 2006. 282 p.
BENICASA, Alcides Xavier; PAIXÃO, Rodinei Silva. MINERAÇÃO DE DADOS COMO
FERRAMENTA PARA DESCOBERTA DE CONHECIMENTO. In: SEMINÁRIO DE
INFORMÁTICA DO RIO GRANDE DO SUL, 2006, Torres. Seminário. Torres, RS:
Seminfo-RS, 2006. p. 68 - 74.
BERRY, Michael J. A.; LINOFF, Gordon S.. Data Mining Techniques For Marketing,
Sales, and Customer Relationship Management. 2. ed. Indianapolis: Wiley Publishing,
2004. 643 p.
BERTHOLD, Michael; HAND, David J.. Inteligent Data Analysis: An Introduction. 2. ed.
[s.l.]: Springer, 2007. 514 p.
BEZERRA, Eduardo. Princípios de Análise e Projeto de Sistemas com UML. 3. ed. Rio de
Janeiro: Campus, 2006.
BHASKAR, Rahul; PENDHARKAR, Parag C.. The Wisconsin Division of Narcotics
Enforcement Uses Multi-Agent Information Systems to Investigate Drug Crimes. Interfaces,
[s.l.], v. 29, n. 3, p.77-87, 1999.
BRAGA, Ascenção. A gestão da informação. Millenium, Portugal, n. 19, 2000. Disponível
em: http://www.ipv.pt/millenium/Millenium_19.htm. Acesso em: 16 set 2011.
97
BRAGA, Luis Paulo Vieira. Introdução à Mineração de Dados. 2. ed. Rio de Janeiro: Epapers. 2005.
BRASIL. Presidência da República. Casa Civil. Subchefia Para Assuntos Jurídicos.
Constituição da República Federativa do Brasil de 1988. Disponível em:
<http://www.planalto.gov.br>. Acesso em: 15 set. 2011.
CARMO FILHO, Manoel Martins do. Procedimento metodológico de avaliação da
acessibilidade e mobilidade nos pólos produtivos do interior do Amazonas. 2009. 232 f.
Tese (Doutorado) - Ufrj, Rio de Janeiro, 2009.
CASALE, J. F.; WATTERSON, J. W.. A Computerized Neural Network Method for Pattern
Recognition of Cocaine Signatures. Journal Of Forensic Sciences, [s.l.], v. 38, n. 2, p.292301, mar. 1993.
CASEY, Eoghan. Using Case-Based Reasoning and Cognitive Apprenticeship to Teach
Criminal Profiling and Internet Crime Investigation. 2002. Disponível em:
<http://www.corpus-delicti.com/case_based.html>. Acesso em: 16 set. 2011.
CHEN, Hsinchun et al. Crime data mining: a general framework and some examples.
Computer, [s.l.], v. 37, n. 4, p.50-56, abr. 2004.
COLLINS, Peter I. et al. Advances in violent crime analysis and law enforcement: the
canadian violent crime linkage analysis system. Journal Of Government Information, [s.l.],
v. 25, n. 3, p.277-284, 1998.
FAYYAD, Usama M. et al. (Ed.). Advances in Knowledge Discovery and Data Mining.
Menlo Park: Mit Press, 1996.
FERNANDES, Anita Maria da Rocha. Inteligência Artificial: Noções Gerais. Florianópolis:
Visual Books, 2005.
FREITAS, Henrique. As tendências em sistemas de informação com base em recentes
congressos. Revista Eletrônica de Administração, Porto Alegre, v. 6, n. 13, fev. 2000.
Disponível em: http://read.adm.ufrgs.br/. Acesso em: 16 jul 2007.
FURTADO, Vasco. Tecnologia da informação e segurança pública. 2007. Disponível em:
<http://www2.forumseguranca.org.br/content/tecnologia-da-informa%C3%A7%C3%A3o-eseguran%C3%A7-p%C3%BAblica>. Acesso em: 14 set. 2011.
GIROTO, Rafaela. Estudo e Análise da Base de Dados do Portal Corporativo da Sexta Região
da Polícia Militar com vista à aplicação de Técnicas de Mineração de Dados. In:
CONGRESSO DE EXTENSÃO DA UFLA – CONEX, 4., 2009, Lavras. Anais... . Lavras:
Ufla,
2009.
p.
1
7.
Disponível
em:
<http://www.proec.ufla.br/conex/ivconex/arquivos/trabalhos/a132.pdf>. Acesso em: 14 set.
2011.
98
HAND, David; MANNILA, Heikki; SMYTH, Padhraic. Principles of Data Mining.
Cambridge: Mit Press, 2001.
HAUCK, Roslin V.; CHEN, Hsinchun. Coplink: A Case of Intelligent Analysis and
Knowledge Management. In: PROCEEDINGS OF THE INTERNATIONAL CONFERENCE
ON INFORMATION SYSTEMS, 20., 1999, Charlotte. Proceedings of the International
Conference on Information Systems. Charlotte: ICIS, 1999. p. 15 - 28.
HOLMES, Monica C.; COMSTOCK-DAVIDSON, Diane D.; HAYEN, Roger L.. Data
mining and expert systems in law enforcement agencies. Issues In Information Systems,
Oklahoma,
v.
8,
n.
2,
p.329-335,
2007.
Disponível
em:
<http://iacis.org/iis/2007_iis/PDFs/Holmes_Davidson_Hayen.pdf>. Acesso em: 14 set. 2011.
INMON, William. H.. Building the Data Warehouse. 4. ed. Indianapolis: Wiley Publishing,
2005. 543 p.
KOLODNER, Janet L., From Natural Language Understanding to Case-Based Reasoning and
Beyond: A Perspective on the Cognitive Model That Ties It All Together. In: SHANCK,
Roger C.; LANGER, Ellen (Eds.). Beliefs reasoning and decision making Psycho logic in
honor of Bob Abelson. Hillsdale: Lawrence Erlbaum Associates, 1994. Cap. 3, p. 55-110.
KREMER, Ricardo. Sistema de apoio à decisão para previsões genéricas utilizando
técnicas de data mining. 1999. 68 f. Monografia (Graduação) - Curso de Ciências da
Computação, Furb, Blumenau, 1999.
LAROSE, Daniel T.. Discovering Knowledge in Data: An Introduction to Data Mining.
Indianapolis: Wiley Publishing, 2005. 222 p.
LAUDON, Kenneth C; LAUDON, Jane Price. Sistemas de Informação. 4. ed. Rio de
Janeiro: Livros Técnicos e Científicos, 2001.
LAZZARINI, Alvaro. Estudos de Direito Administrativo. 2. ed. São Paulo: Revista Dos
Tribunais, 1999. 447 p.
MARCONI, Marina de Andrade; LAKATOS, Eva Maria. Fundamentos de Metodologia
Científica. 6. ed. São Paulo: Atlas, 2006.
MENA, Jesús. Investigative Data Mining for Security and Criminal Detection.
Burlington: Elsevier Science, 2003.
MIRANDA, Roberto Campos da Rocha. O uso da informação na formulação de ações
estratégicas pelas empresas. Ciência da Informação, Brasília, v. 28, n. 3, p. 286-292,
set./dez. 1999.
MORESI, Eduardo Amadeu Dutra. Delineando o valor do sistema de informação de uma
organização. Ciência da Informação, Brasília, v. 29, n. 1, p. 14-24, jan./abr. 2000.
99
MYATT, Glenn J.. Making Sense of Data: A Practical Guide to Exploratory Data Analysis
and Data Mining. Hoboken: John Wiley & Sons, 2007.
OLIVEIRA, Wilson José de. Data warehouse. Florianópolis, SC: Visual Books, 2002 188 p.
PERING, Elton Adriano. Um Data Mart para Previsão de Vendas Anual da Empresa
Quimisa/SA. 2010. 89 f. Monografia (Graduacão) - Curso de Ciências da Computação,
UNIVALI, Itajaí, 2010.
POLÍCIA MILITAR DE SANTA CATARINA. Diretriz Permanente 006/CmdoG/2002.
Diretriz de ação operacional na área do serviço 190. Disponível em:
http://intranet.pm.sc.gov.br. Acesso em: 14 set. 2011.
REZENDE, Denis Alcides; ABREU, Aline França de. Tecnologia da Informação: Aplicada
a Sistemas de Informação Empresariais. São Paulo: Atlas, 2000. 306 p.
RODRIGUES, Daniel Henrique. Uma análise da segurança dos sistemas de informação da
Polícia Militar de Santa Catarina. 2006. 169 f. Monografia (Graduação) - Curso de
Bacharelado em Segurança Pública, Univali/PMSC, Florianópolis, 2006.
SARTORI, Ricardo. Gestão do Ensino na PMSC: Proposta de implantação de um sistema
informatizado de controle acadêmico. 2007. 102 f. Monografia (Graduação) - Curso de
Bacharelado em Segurança Pública, Univali/PMSC, Florianópolis, 2007.
SCHROEDER, Jennifer. Coplink: Database Integration and Access for a Law Enforcement
Intranet.
Tucson:
Ncjrs,
2001.
Disponível
em:
<https://www.ncjrs.gov/App/publications/Abstract.aspx?id=190988>. Acesso em: 16 set.
2011.
SENATOR, Ted E. et al. The Financial Crimes Enforcement Network AI System (FAIS):
Identifying Potential Money Laundering from Reports of Large Cash Transactions. AI
Magazine, S/I, p. 21-39. 1995.
SILVA FILHO, Luiz Alberto da. Mineracão de regras de associação utilizando KDD e
KDT: Uma aplicação em segurança pública.. 2009. 85 f. Dissertacão (Mestrado) Universidade Federal do Pará, Belém, 2009.
SOARES, Luis Eduardo. O Dilema e Sísifo e a Segurança Pública: Hiper-politização eo
Conflito entre as Reformas e o Ciclo Eleitoral. 2004. Disponível em:
<http://www.ie.ufrj.br/aparte/pdfs/luizeduardo_hiperpolitizacao_e_o_conflito.pdf>. Acesso
em: 14 set. 2011.
SOUZA,
Michel
de.
BI:
Data
Marts.
2003.
Disponível
em:
<http://imasters.com.br/artigo/1612/gerencia-de-ti/bi-data-marts>. Acesso em: 14 set. 2011.
STAIR, Ralph M; REYNOLDS, George W. Princípios de sistemas de informação: uma
abordagem gerencial. 6. ed. São Paulo: Thompson Learning, 2006.
100
WANGENHEIN, Aldo von; WANGENHEIN, Christiane Gresse von. Raciocínio baseado
em casos. 2003. Editora Manole: Rio de Janeiro. 1a edição. 290 p.
WILSON, Larry. Violent Crime Linkage System (VICLAS). 2011. Disponível em:
<http://www.rcmp-grc.gc.ca/tops-opst/bs-sc/viclas-salvac-eng.htm>. Acesso em: 14 set. 2011.
WITTEN, Ian H.; FRANK, Eibe. Data Mining: Practical Machine Learning Tools and
Techniques. 2. ed. San Francisco: Elsevier, 2005. 525 p.
WITZIG, Eric W.. The New VICAP: More User-Friendly and Used by More Agencies. Fbi
Law Enforcement Bulletin, Quantico, v. 72, n. 6, p.1-12, jun. 2003.
101
APÊNDICE A – Dicionário de dados dos registros de ocorrências importados da Central
190 de Balneário Camboriú para banco de dados SQL – MySQL.
Descrição da tabela: preserva os dados básicos das ocorrências geradas no sistema.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto incremental contendo o
identificador único da ocorrência.
ocorrência
INT
O número da ocorrência gerado automaticamente pelo
sistema EMAPE da PMSC. O campo ocorrência não
pode ser utilizado como chave primária pois o Sistema
EMAPE suporta somente 999.999 ocorrências, sendo
reiniciado sempre que este número é atingido.
data
DATE
O dia em que a ocorrência foi gerada.
horario
TIME
O horário de geração da ocorrência.
log_id
INT
É chave estrangeira para a tabela de logradouros, que irá
identificar em qual logradouro foi gerada a ocorrência.
log_num
INT
Refere-se ao número da casa em uma determinada rua.
endereco
VARCHAR(90) O endereço completo, para busca textual.
codigo
VARCHAR(5)
É a chave estrangeira para tabela ocorrencia_codigo, e
refere-se à codificação da ocorrência, de acordo com as
diretrizes da PMSC, composto por um caractere
alfabético que refere-se ao grupo de ocorrência seguido
por 3 números, que especificam o subgrupo e tipo de
ocorrência. Tal código identifica que tipo de ocorrência
foi gerada. Apresentada no formato: [A-Z]+[0-9]+[09]+[0-9]
historico_inicial MEDIUMTEXT Informações da ocorrência repassadas no momento em
que ela foi gerada no sistema.
historico_final
MEDIUMTEXT Informações repassadas pelos policiais militares que
atenderam a ocorrência no momento em que ela é
encerrada.
Quadro 22. Tabela ocorrência.
102
Descrição da tabela: mantém armazenados os códigos de ocorrência e seus significados, de
acordo com as diretrizes da PMSC. Assim, temos, por exemplo, que o código de ocorrência
C204 identifica uma ocorrência de estelionato.
Campo
Formato
Descrição do campo
id
VARCHAR(5)
Chave primária, única, contendo o identificador do tipo
de ocorrência.
descrição
TEXT
A descrição da ocorrência, ou seja, que tipo de ilícito
penal ou perturbação à ordem pública foi identificado
pelo operador do sistema ao gerar a ocorrência.
Quadro 23. Tabela ocorrencia_codigo.
Descrição da tabela: mantém armazenados os dados referentes as pessoas que participaram
ou tiveram algum tipo de envolvimento durante o atendimento da ocorrência policial. Nesta
tabela ficam registrados dados básicos, que identificam de forma superficial o cidadão, tais
como nome, idade, sexo e tipo de envolvimento.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto-incremental, contendo o
identificador da pessoa envolvida na ocorrência.
ocorrencia_id
INT
Chave estrangeira, que vinculará aquela
envolvida à ocorrência na tabela ocorrencia.
nome
VARCHAR(50) O nome da pessoa envolvida.
idade
INT
sexo
VARCHAR(50) Feminino ou masculino, identificando o gênero da
pessoa envolvida.
envolvimento
INT
pessoa
A idade da pessoa envolvida.
Chave estrangeira, que aponta para a tabela
ocorrencia_envolvimento, e que identifica o nível de
envolvimento da pessoa na ocorrência em questão. São
10 tipos: 1 – Policial Militar, 2 - Bombeiro Militar, 3 –
Policial Civil, 4 – Outros, 5 – Vitima, 6 – Agente, 7 –
Testemunha, 8 – Desaparecido, 9 – Solicitante, 10 –
Condutor.
Quadro 24. Tabela ocorrencia_envolvido.
Descrição da tabela: nesta tabela encontram-se os dados relativos à guarnição que atendeu à
determinada ocorrência. Identifica, de forma básica, a viatura envolvida – através do seu
prefixo PM e o comandante da guarnição durante aquele atendimento.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto-incremental, contendo o
identificador da guarnição envolvida na ocorrência.
ocorrencia_id
INT
Chave estrangeira, que vinculará aquela guarnição
envolvida à ocorrência na tabela ocorrencia.
103
gu
VARCHAR(20) O prefixo PM ou a nomenclatura determinada pela
Central para a viatura ou policial que atendeu a
ocorrência. Exemplo: VBC0928 – viatura de Balneário
Camboriu numeração PM 0928. Apresentada no
formato: [A-Z]+[A-Z]+[A-Z]+[0-9]+[0-9]+[0-9]+[0-9].
nome
VARCHAR(30) O nome do Cmt da Guarnição PM, geralmente o policial
mais antigo da dupla.
Quadro 25. Tabela ocorrencia_guarnicao.
Descrição da tabela: a tabela em questão armazena dados referentes aos nomes de
logradouros cadastrados na cidade.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto-incremental, contendo o
identificador do logradouro.
nome
VARCHAR(50)
O nome do logradouro.
bairro_id
INT
Chave estrangeira para a tabela end_bairro, que
identifica em qual bairro está situada a rua em questão.
nome_google
VARCHAR(100) O nome deste logradouro no sistema de
geomapeamento do google (http://maps.google.com),
para futura aplicação de geoprocessamento das
ocorrências.
Quadro 26. Tabela end_log.
Descrição da tabela: a tabela em questão armazena dados referentes aos nomes de bairros
cadastrados na cidade.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto-incremental, contendo o
identificador do bairro.
nome
VARCHAR(50)
O nome do bairro.
municipio_id
INT
Chave estrangeira para a tabela municipio, que
identifica em qual município está situada a rua em
questão.
Quadro 27. Tabela end_bairro.
104
Descrição da tabela: a tabela em questão armazena dados referentes aos nomes de bairros
cadastrados na cidade.
Campo
Formato
Descrição do campo
id
INT
Chave primária, única, auto-incremental, contendo o
identificador do município.
nome
VARCHAR(50)
O nome do município.
Quadro 28. Tabela municipio.
Descrição da tabela: a tabela em questão armazena dados referentes aos horários em que as
viaturas executaram determinadas atividades.
Campo
Formato
Descrição do campo
ocorrencia_id
INT
Chave estrangeira, que vinculará aquela guarnição
envolvida à ocorrência na tabela ocorrencia.
ocorrência
INT
O número da ocorrência gerado automaticamente pelo
sistema EMAPE da PMSC. O campo ocorrência não
pode ser utilizado como chave primária pois o Sistema
EMAPE suporta somente 999.999 ocorrências, sendo
reiniciado sempre que este número é atingido.
evento
VARCHAR(5)
O tipo de evento que foi cadastrado para a viatura,
sendo somente 4 tipos: J9 – viatura se deslocamento
para o local da ocorrência; J10 – viatura chegou ao
local da ocorrência; J11 – viatura encerrou a ocorrência
e P115 – viatura está parada em algum ponto de
policiamento.
data_hora
DATETIME
A data e a hora em que cada evento foi cadastrado.
viatura
VARCHAR(10)
O prefixo PM ou a nomenclatura determinada pela
Central para a viatura ou policial que atendeu a
ocorrência. Exemplo: VBC0928 – viatura de Balneário
Camboriu numeração PM 0928. Apresentada no
formato: [A-Z]+[A-Z]+[A-Z]+[0-9]+[0-9]+[0-9]+[0-9].
Quadro 29. Tabela ocorrencia_viatura_evento.
105
ANEXO A – Autorização do Comando Regional da 3ª Região de Polícia Militar para
uso da base de dados de ocorrências da Central Regional de Emergência 190 de
Balneário Camboriú