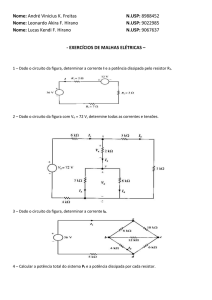
1.6. Tipos de")
Curso de Ciências da Computação
1. NÍVEL CONVENCIONAL DE MÁQUINA (Cont.)
1.6. Tipos de Instruções
As instruções podem ser classificadas de acordo com o número de endereços que elas
utilizam.
Não se deve esquecer que um conjunto de registradores numerados da CPU constitui, de
fato, uma memória de alta velocidade e define um espaço de endereçamento. Uma instrução que
soma o registrador 1 ao registrador 2 deve ser classificada como tendo dois endereços porque a
instrução deve especificar quais os registradores que serão adicionados, do mesmo modo que
uma instrução que soma duas palavras de memória deve especificar as palavras.
Instruções que especificam um, dois e três endereços são comuns. Em muitas máquinas
que fazem aritmética com um endereço apenas, um registrador especial denominado
acumulador prove um dos operandos. Nestas máquinas, o endereço é geralmente o endereço
m de uma palavra de memória, no qual se localiza o operando. A instrução para adição com o
conteúdo instruções de dois endereços de soma utiliza um dos endereços como fonte e o outro
como destino. A fonte é então somada ao destino:
destino := destino + fonte
As instruções de três endereços especificam duas fontes e um destino. As duas fontes são
adicionadas e armazenadas no destino.
As instruções de nível convencional de máquina podem ser divididas aproximadamente em
dois grupos:
instruções de propósito geral, e;
instruções de propósito especial.
As instruções de propósito geral tem vasta aplicação. Por exemplo, a capacidade de mover
dados pela máquina é algo necessário em quase toda aplicação.
As instruções de propósito especiais têm aplicações bem restritas. Por exemplo, a
instrução MOVEP do 68000 pega o conteúdo de um registrador D e o armazena na memória
em bytes alternados, com um byte não usado entre os bytes de dados. Poucas aplicações
podem fazer uso efetivo desta instrução, e nenhum compilador irá gerá-la. (Ela foi incluída para
simplificar a comunicação com as antigas pastilhas periféricas de 8 bits.)
Nosso foco, portanto, será os principais grupos de instruções de propósito geral.
1.6.1. Instruções de Transferência de Dados
A cópia de dados de um lugar para outro é a mais fundamental de todas as operações. Por
cópia entendemos a criação de um novo objeto, com o padrão de bits idêntico ao do original. O
uso da palavra "transferência" é algo diferente de seu uso normal em português. Quando dizemos
que um paciente foi transferido da UTI para o quarto, não significa que uma cópia idêntica do
paciente foi criada no quarto e o original permaneceu na UTI.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 1 de 7
Curso de Ciências da Computação
Quando dizemos que o conteúdo da posição de memória 2000 foi transferido para algum
registrador, isto quase significa que uma cópia idêntica foi criada lá e que o original
permanece intacto na posição 2000. Instruções de transferência de dados seriam melhor
chamadas de instruções de "duplicação de dados", mas o termo "transferência de dados" já
está oficializado.
Dados podem estar armazenados em vários lugares, diferindo no modo como as
palavras são acessadas. Três lugares comuns são:
Uma palavra de memória específica;
Um registrador, ou;
A pilha.
A pilha é mantida tanto em registradores especiais como na memória, mas a maneira de
acessa-la é diferente dos acessos-padrão a memória. Um acesso à memória requer um
endereço, enquanto o empilhar de um item não explicita endereço na pilha.
Sabemos que é altamente desejável ter instruções de máquina tão curtas quanta
possível para economizar memória e tempo de CPU. O máximo em redução de comprimentos
de endereço seria ter instruções com absolutamente nenhum endereço, apenas códigos de
operação. Esta situação, bastante surpreendente, é possível. É conseguida organizando a
máquina em torno de uma estrutura de dados denominada pilha.
Uma pilha consiste em itens de dados (palavras, caracteres, bits) armazenados em
ordem consecutiva na memória. O primeiro item colocado na pilha é denominado fundo da
pilha. Associado a cada pilha há um registrador ou palavra de memória que contém o endereço
do topo da pilha. É denominado apontador da pilha.
Utilizar pilhas em aritmética é muito diferente de utilizar pilhas para armazenar variáveis
locais (ambos os casos podem, naturalmente, ser combinados). A Fig. 1.8 ilustra a operação de
uma pilha. Na Fig. 1.8(a) dois itens já se encontram na pilha. O fundo da pilha localiza-se na
posição 1000 da memória e o topo da pilha localiza-se na posição 1001 da memória. O apontador
da pilha contém o endereço do item no topo da pilha, ou seja, 1001; isto significa que ele "aponta"
para o topo da pilha. Na Fig. 1.8(b), 6 foi colocado na pilha e o apontador da pilha indica 1002
como o novo topo da pilha. Na Fig. 1.8(c), 75 foi colocado na pilha e o apontador da pilha
aumentado para 1003. Na Fig. 1.8(d), 75 foi retirado da pilha.
Fig. 1.8
Funcionamento de uma pilha.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 2 de 7
Curso de Ciências da Computação
Os computadores orientados para pilha possuem uma instrução para inserir o
conteúdo de uma posição de memória ou de um registrador na pilha. Tal instrução deve tanto
incrementar o apontador de pilha quanta copiar o item. Similarmente, uma instrução que copia o
conteúdo do topo da pilha para um registrador ou posição de memória deve fazer a nova cópia
para o lugar escolhido e decrementar o apontador da pilha. Alguns computadores tem suas pilhas
de cima para baixo, com os novos itens sendo inseridos consecutivamente em posições de
memória de endereços de menor valor em vez de consecutivamente em posições de endereços
superiores, este segundo como na Fig. 1.8.
As instruções sem endereço são utilizadas conjuntamente com uma pilha. Esta forma
de endereçamento específica que os dois operandos devem ser retirados da pilha, um após o
outro, a operação executada (ex., multiplicação ou AND) e o resultado recolocado na pilha.
A Fig. 1.9(a) mostra uma pilha que contém quatro itens. Uma instrução de multiplicação
retira o 5 e o 6 da pilha, faz o apontador de pilha apontar temporariamente para 1001 e então
recoloca o resultado, 30, de volta na pilha, como mostra a Fig. 1.9(b). Se uma adição for depois
executada, o resultado será como mostra a Fig. 1.9(c).
Fig. 1.9 Utilização de uma pilha em aritmética. (a) Configuração inicial. (b) Após uma multiplicação, (c) Após uma adição.
Instruções de transferência de dados requerem que ambos, fonte (i.e., o original) e
destino da informação (i.e., onde a cópia será colocada), sejam especificados quer explícita ou
implicitamente.
Instruções da transferência de dados precisam indicar, de algum modo, a quantidade
de dados a ser transferida. Existem instruções para mover quantidades de dados desde 1 bit até
a memória inteira. Em máquinas com palavras de tamanho fixo, o número de palavras a serem
transferidas é usualmente especificado pela instrução - por exemplo, instruções separadas para
mover uma palavra e mover meia palavra. Máquinas com palavra de tamanho variável
frequentemente tem instruções que apenas especificam os endereços de fonte e destino
mas não à quantidade. A transferência continua até que a marca do fim de dados é encontrada
nos próprios dados.
As CPUs Intel tem instruções MOVE muito limitadas, mas existem muitas delas, de tal
maneira que são também possíveis transferências entre dois lugares quaisquer.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 3 de 7
Curso de Ciências da Computação
1.6.2. Operações Diádicas
Operações diádicas são aquelas que combinam dois operandos para produzir um
resultado. Existe basicamente dois grupos destas instruções:
Para fazer adição e subtração de inteiros, e;
O grupo dos operadores booleanos.
Três instruções presentes em muitas máquinas são AND, OR e XOR. Seus usos em
operações diádicas são:
Em máquinas com palavra de tamanho fixo, AND calcula o produto booleano bit a
bit de dois argumentos de uma palavra, tendo como resultado também uma
palavra.
Outro uso do AND é a extração de bits de palavras. Para extrair o caractere, é feito
um AND da palavra contendo o caractere e uma constante, chamada máscara. O
resultado dessa operação é que os bits indesejáveis são todos mudados para zeros,
isto é, mascarados.
Um uso importante para OR é empacotar bits em uma palavra, sendo empacotar o
inverso de extrair.
A operação AND tende a remover os números 1, porque nunca há mais números
1 no resultado que em qualquer dos operandos.
A operação OR tende a inserir números 1, porque há sempre no mínimo tantos
números 1 no resultado quanto no operando com mais números 1.
A operação XOR, por outro lado, é simétrica, tendendo, em média, a nem inserir
nem remover números 1.
Quase todas as máquinas de Nível 2 (Nível de Máquina Convencional) tem instruções
para fazer adição e subtração de inteiros. Exceto para os microcomputadores de 8 bits, as
instruções de multiplicação e divisão de inteiros são também comuns. Praticamente, todos os
computadores, portanto, são equipados com instruções aritméticas.
1.6.3. Operações Monádicas
As operações monádicas tem “1” operando e produzem “1” resultado. Como são
especificados menos endereços que as diádicas, as instruções são bem mais curtas.
Instruções para deslocar e rodar o conteúdo de uma palavra ou byte são realmente.
Deslocamentos são operações nas quais os bits são movidos para a esquerda ou direita,
perdendo os bits deslocados para fora da palavra. Rotações são deslocamentos nos quais
os bits jogados fora da palavra reaparecem do outro lado. A diferença entre um deslocamento
e uma rotação é ilustrada abaixo.
00000000 00000000 00000000 01110011 A
0000000000000000 00000000 00011100 A deslocado 2 bits para a direita
1100000000000000 00000000 00011100 A rodado 2 bits para a direita
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 4 de 7
Curso de Ciências da Computação
1.6.4. FLUXO DE CONTROLE
O fluxo de controle se refere à sequência na qual as instruções são executadas.
Geralmente, as instruções executadas sucessivamente são buscadas de posições de memória
consecutivas. Chamadas de procedimento causam alterações no fluxo de controle, parando o
procedimento atual e iniciando o procedimento chamado. Co-rotinas são parecidas com
procedimentos e causam alterações similares no fluxo de controle. Armadilhas (traps) e
Interrupções também alteram o fluxo de controle quando ocorrem condições especiais. Vejamos:
1.6.4.2. Fluxo de Controle Sequencial e Desvios
A maioria das instruções não altera o fluxo de controle. Após uma instrução ser
executada, a seguinte na memória é buscada e executada. Após cada instrução, o contador de
programa é incrementado do número de posições de memória da instrução.
Se observado durante um intervalo de tempo longo comparado com o tempo de instrução
médio, o contador de programa é aproximadamente uma função linear do tempo, aumentando do
comprimento médio de instruções por tempo médio de instrução. Expresso de outra forma, a
ordem dinâmica na qual o processador realmente executa as instruções é a mesma ordem
na qual elas aparecem na Iistagem do programa.
Se um programa contém desvios, esta relação simples entre a ordem em que as instruções
aparecem na memória e a ordem em que elas são executadas não é mais verdadeira. Quando
desvios estão presentes, o contador de programa não é mais uma função monotonamente
crescente no tempo. Como consequência, torna-se difícil visualizar a sequência de execução de
instruções da Iistagem do programa. Quando os programadores tem problemas em manter-se a
par da sequência na qual o processador irá executar as instruções, eles estão propensos a
cometer erros. Esta observação levou Dijkstra (1968) a escrever um artigo nessa época polêmico
intitulado "GO TO Statement Considered Harmful", no qual, sugere evitar comandos GO TO. Este
artigo deu origem à revolução da programação estruturada, sendo um de seus lemas a
substituição de comandos GO TO por formas mais estruturadas de controle de fluxo, tais como
loops WHILE. Naturalmente, esses programas são compilados para programas de nível 2 que
podem conter muitos desvios, pois a implementação de IF, WHILE e outras estruturas de
controle de alto nível requerem desvios por toda parte.
1.6.4.3. Procedimentos
A técnica mais importante para estruturar programas é o procedimento. De certo ponto
de vista, uma chamada de procedimento altera o fluxo de controle tal como um desvio faz,
mas, ao contrário do desvio, quando terminar sua tarefa ela retorna o controle para o
comando ou instrução seguinte a chamada.
Entretanto, de outro ponto de vista, o corpo de um procedimento pode ser visto como a
definição de uma nova instrução em um nível superior. Deste ponto de vista, uma chamada de
procedimento pode ser considerada uma única instrução, mesmo que o procedimento seja
muito complicado. Para entender um trecho do programa que contenha uma chamada de
procedimento, basta saber o que ele faz, não como ele faz.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 5 de 7
Curso de Ciências da Computação
1.6.4.4. Co-rotinas
Na sequência comum de chamada, há uma clara distinção entre o procedimento que chama
e o procedimento chamado. Considere um procedimento A que chama um procedimento B. O
procedimento B é executado por um tempo e então retorna para A. A primeira vista você poderia
considerar essa situação simétrica, porque nem A nem B são programas principais, ambos são
procedimentos (o procedimento A pode ter sido chamado pelo programa principal, mas isto é
irrelevante). Além disto, inicialmente o controle é transferido de A para B – a chamada - e mais
tarde o controle é transferido de B para A - o retorno.
A assimetría vem do fato de que quando o controle passa de A para B, o
procedimento B começa do início; quando B retorna para A, a execução não começa no
início de A, mas no comando seguinte a chamada. Se A é executado por um tempo e chama B
de novo, a execução começa no início de B, e não no comando seguinte ao retorno anterior. Se
durante a execução A chama B várias vezes, B começa do início todas às vezes, enquanto A
nunca começa do início de novo.
1.6.4.5. Traps (Armadilhas)
Uma armadilha (trap) é um tipo de chamada automática de procedimento iniciada por
alguma condição causada pelo programa, usualmente uma condição importante mas rara. Um
bom exemplo é o transbordo (overflow). Em muitos computadores, se o resultado de uma
operação aritmética excede o maior número que pode ser representado, ocorre um “trap”,
significando que o fluxo de controle é transferido para alguma posição fixa na memória em
vez de continuar sequencialmente.
Nesta posição fixa há um salto para um procedimento chamado rotina de tratamento de trap,
que executa alguma ação apropriada, tal como a impressão de uma mensagem de erro. Se o
resultado de uma operação está dentro do intervalo permitido, não ocorre nenhum trap.
1.6.4.6. Interrupções
Interrupções são modificações no fluxo de controle causadas não por uma execução
de programa mas por outra coisa, usualmente relacionada a E/S. Por exemplo, um programa
pode instruir ao disco para prover uma interrupção tão logo à transferência tenha terminado.
Como uma armadilha (trap), a interrupção para o programa em execução e transfere o controle
para o tratamento de interrupção, que executa alguma ação apropriada. Ao terminar, a rotina de
tratamento de interrupção retorna o controle para o programa interrompido. É preciso reativar o
processo interrompido exatamente no mesmo estado em que ele estava quando ocorreu a
interrupção, o que significa restaurar todos os registradores internos aos seus estados
anteriores a interrupção.
A diferença essencial entre armadilhas e interrupções é que as armadilhas (traps) são
síncronas com o programa e as interrupções são assíncronas. Se o programa é reexecutado
um milhão de vezes com a mesma entrada, as armadilhas irão ocorrer no mesmo lugar a cada
vez, mas as interrupções podem variar, dependendo, por exemplo, de quando precisamente
uma pessoa no terminal pressiona a tecla de retorno do carro.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 6 de 7
Curso de Ciências da Computação
1.7. RESUMO
O nível de máquina convencional é o que muitas pessoas tem como "linguagem de
máquina". Neste nível a máquina tem uma memória orientada por byte ou por palavra desde
dezenas de quilo bytes a dezenas de megabytes, e instruções como MOVE, ADD e JUMP.
A maioria dos computadores modernos possui memória que é organizada como uma
sequência de bytes, com 2 ou 4 bytes agrupados em palavras. Estão também presentes
normalmente entre 8 e 32 registradores, cada um deles contendo uma palavra. Muitos
computadores vem em famílias, tais como as famílias Intel.
As instruções tem geralmente um ou dois operandos que são endereçados usando os
modos imediato, direto, indireto, indexado ou outros modos de endereçamento. Algumas
máquinas tem muitos modos de endereçamento. Geralmente, são disponíveis instruções para
transferência de dados, operações diádicas e monádicas, incluindo operações aritméticas e
booleanas, desvios, chamadas de procedimento, loops e algumas vezes para E/S. As instruções
tipicamente copiam uma palavra de memória para um registrador (ou vice-versa), somam,
subtraem, multiplicam ou dividem os conteúdos de dois registradores ou os conteúdos de
um registrador e de uma posição de memória, ou comparam dois itens localizados em
registradores ou na memória.
Não é comum um computador ter mais de 100 instruções em seu repertório. O fluxo de
controle no nível 2 é conseguido utilizando diversas primitivas, incluindo desvios, chamadas de
procedimento, chamadas de co-rotinas, traps e interrupções. Os desvios são usados para terminar
uma sequência de instruções e iniciar uma nova. Os procedimentos são utilizados como um
mecanismo de abstração para permitir que uma parte do programa seja isolada como uma
unidade e chamada de diversos lugares. Co-rotinas permitem que duas threads de controle
executem simultaneamente. Traps são utilizadas para sinalizar situações excepcionais, tais como
transbordo (overflow) aritmético. Finalmente, as interrupções permitem E/S acontecer em
paralelo com a computação principal, com a CPU recebendo um sinal tão logo a E/S tenha
sido completada.
Disciplina: Projeto Lógico de Computadores (5º/6º Sem - 2014).
Livro: Andrew S. Tanenbaum
Página 7 de 7
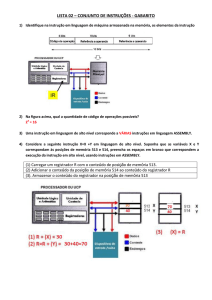
 1.6. Tipos de")
![aula10-EXTRA-Arqs43210Ends [Modo de Compatibilidade]](http://s1.studylibpt.com/store/data/001011244_1-a6aa2e8b625601e12d5149ac51d4d875-300x300.png)






![a) MnBr2 b) Na2S2O3 c) O3 d) [NO3]-](http://s1.studylibpt.com/store/data/004824294_1-e6644befe23aef65a5e854b9876a94db-300x300.png)