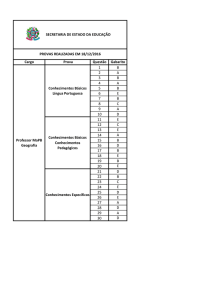
16°
TÍTULO: GESTÃO DE RECURSOS NA SAÚDE: MINERAÇÃO DE DADOS SOBRE DADOS ABERTOS
GOVERNAMENTAIS
CATEGORIA: EM ANDAMENTO
ÁREA: CIÊNCIAS EXATAS E DA TERRA
SUBÁREA: COMPUTAÇÃO E INFORMÁTICA
INSTITUIÇÃO: FACULDADE DE TECNOLOGIA TERMOMECÂNICA
AUTOR(ES): ANA RAQUEL BERTELLI DE OLIVEIRA, LEONARDO LAZARINI
ORIENTADOR(ES): CAMILA MARIANE COSTA SILVA
1. Introdução
Durante as últimas décadas, com a evolução dos recursos tecnológicos e com
o crescente uso de sistemas de informação, os frequentes censos e monitoramentos
passaram a acumular um número cada vez maior de dados de diferentes origens,
datas e temas. Para garantir que estes dados estarão disponíveis a todas as
pessoas, em 18 de novembro de 2011 foi declarada a Lei nº 12.527 (BRASIL, 2011),
cuja principal motivação é garantir o acesso à informação.
Viu-se a oportunidade de tratar e processar estes dados, advindos da INDE
(INDE, 2016), por meio de um processo de descobrimento de informações em bases
de dados - KDD (Knowledge-Discovery in Databases). Com este processo, é
possível encontrar padrões e montar um ou mais modelos de conhecimento, que
podem ser utilizados em um sistema de apoio a decisão (FAYAAD; PIATETSKYSHAPIRO; SMYTH, 1996). Note-se que um Sistema de Apoio a Decisão - SAD é
uma ferramenta cuja principal finalidade é, a partir do tratamento e disponibilização
de informações, auxiliar gestores e/ou pessoas envolvidas em decisões estratégicas
a efetivar suas escolhas no contexto de uma organização (pública ou privada)
(POLLONI, 2001).
2. Objetivo
Este estudo busca responder o problema de pesquisa: como os dados
abertos governamentais podem ser tratados para auxiliar a gestão de recursos na
área de saúde? Neste sentido, este projeto tem como objetivo desenvolver uma
ferramenta de apoio à decisão que auxilie a gestão de recursos na área de saúde.
3. Método de Pesquisa
Esta pesquisa tem uma abordagem exploratória em relação a seus objetivos
(GIL, 2010), pois será desenvolvida uma ferramenta que apresentará, de maneira
estruturada, informações que, inicialmente, não estavam relacionadas. Esta
exploração envolve:
Seleção de dados demográficos e da área de Saúde (doenças e
distribuição de unidades de saúde);
A coleta de dados quantitativos, contidas em planilhas (.csv), da INDE que
são carregados numa ferramenta, desenvolvida para este estudo;
Os dados coletados são submetidos a tratamentos de consolidação,
limpeza e integração na ferramenta desenvolvida;
Após consolidação do conjunto de dados, estes são inseridos na
ferramenta WEKA para pré-processamento e geração dos modelos de
conhecimento;
Desenvolvimento de uma ferramenta de apoio à tomada de decisão,
utilizando as linguagens PHP e Java, para visualização dos resultados dos
modelos gerados e para inserção de novos dados para análise.
4. Desenvolvimento
Até o momento foram coletados dados do Portal Brasileiro de Dados Abertos
(PBDA, 2016), onde diversos conjuntos de dados, agrupados por determinados
temas, são disponibilizados. Há conjuntos de dados referentes a saúde, geografia,
transporte, sociedade e outros. Além da coleta em si, os dados já foram préprocessados e agrupados por cidade, possuindo diversos atributos relacionados a
ela como grau de escolaridade dos moradores, clima da região, tipo de solo,
rendimentos médios familiares e etc. Para realizar esta etapa, foi desenvolvida uma
plataforma capaz de importar e realizar o pré-processamento de forma automática,
necessitando pouca interação humana.
O processo KDD foi iniciado pela primeira etapa, a de pré-processamento,
onde dados de diversas fontes foram coletados e tratados. Estes dados foram
submetidos a diversos algoritmos de teste, gerando modelos de conhecimento
preliminares tentando distinguir os fatores que mais influenciam na incidência de
AIDS, malária e microcefalia. Para gerar os modelos de conhecimento foi utilizado o
software Weka (UW, 2016), cujo código é aberto e foi desenvolvido pela
universidade de Waikato, especialista em mineração de dados.
Todo o conjunto faz parte de uma ferramenta governamental de apoio a
decisão que está sendo desenvolvida. Esta permitirá que os governantes visualizem
as áreas de risco onde determinada doença possa incidir, podendo prevenir ou
auxiliar de forma mais efetiva as áreas afetadas (cidades que possuem maior risco
disseminação de determinadas doenças).
5. Resultados Preliminares
Os dados coletados foram importados utilizando a ferramenta desenvolvida,
sendo que todos realizados com sucesso. Além disto, os algoritmos de integração
dos dados foram desenvolvidos e facilitaram no processo de importação e
padronização do banco de dados.
As doenças testadas até o momento foram AIDS, microcefalia e malária,
selecionando atributos diferentes dependendo no método de disseminação de cada
doença. A microcefalia, por exemplo, considerou como alto risco as cidades que
possuem temperatura quente a maior parte do ano, áreas urbanizadas com mais
chuvas durante o ano.
Os modelos de conhecimento gerados apresentaram uma taxa de acerto que
variam de 80% (malária) a 91% (AIDS e microcefalia), selecionando os atributos
mais importantes e que mais contribuem para distinguir as áreas de maior risco de
incidência de cada doença.
6. Fontes Consultadas
BRASIL. Constituição Federal (2011). Lei nº 12527, de 18 de novembro de 2011.
Lei Nº 12.527, de 18 de novembro de 2011. Brasília, 18 nov. 2011. Disponível em:
<http://www.planalto.gov.br/ccivil_03/_ato2011-2014/2011/lei/l12527.htm>.
Acesso
em: 10 ago. 2016.
FAYYAD, Usama; PIATETSKY-SHAPIRO, Gregory; SMYTH, Padhraic. From Data
Mining to Knowledge Discovery in Databases. American Association For Artificial
Intelligence, p.37-54, set. 1996. Disponível em: <http://www.csd.uwo.ca/faculty/ling/
cs435/fayyad.pdf>. Acesso em: 07 ago. 2016.
GIL, Antônio Carlos. Como elaborar Projetos de Pesquisa. 5 ed. São Paulo: Atlas,
2010.
INDE – Infraestrutura Nacional de Dados Espaciais (Org.). Infraestrutura Nacional
de Dados Espaciais. 2016. Disponível em: <http://www.inde.gov.br/>. Acesso em:
01 ago. 2016.
PBDA - Portal Brasileiro de Dados Abertos (Org.). Portal Brasileiro de Dados
Abertos. 2016. Disponível em: <http://dados.gov.br/>. Acesso em: 01 ago. 2016.
POLLONI, Enrico G. F. Administrando sistemas de informação: estudo de
viabilidade. 2.ed. São Paulo: Futura, 2001.
UW – University of Waikato (Org.). WEKA - Data Mining Software in Java. 2016.
Disponível em: <http://www.cs.waikato.ac.nz/>. Acesso em: 02 ago. 2016.