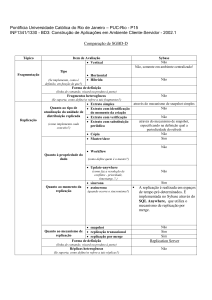
Replicação de Dados utilizando SQL Server 2008
Autor: Leo Lopes
Fonte: http://www.blogdati.com.br/index.php/2011/07/replicacao-de-dados-utilizando-sqlserver-2008/
Vamos abordar um assunto muito interessante e que a cada dia mais e mais empresas
necessitam dessa tecnologia, Replicação de dados utilizando SQL Server 2008.
O intuito não é só tratar a replicação em si, mas todo o projeto, desde a identificação da
necessidade de uma replicação, até sua implantação e manutenção.
Nós DBAs, diariamente nos deparamos com diversos tipos de necessidades para atender
as demandas de nossos clientes e negócios. Seja ela, por exemplo, a implantação de um
novo servidor de banco de dados, que irá ter uma réplica do banco de dados principal
que será utilizado para geração de relatórios, ou até mesmo um servidor de banco de
dados para atender uma nova filial da empresa. Nos dois casos podemos implementar
uma replicação. Aí você me pergunta: Mas no primeiro caso, por que eu implantaria
uma replicação, e não um log shipping? Basicamente, porque na replicação você tem o
poder de decidir quais os objetos que você quer replicar, e não necessariamente
precisará replicar o database por inteiro.
PROJETO
O primeiro passo, é conhecer e identificar o que precisa ser replicado. Nem todas as
tabelas ou todos os dados de uma tabela, precisam ser replicados. Nós precisamos
sempre ter em mente, que só devemos trafegar os dados que realmente são necessários.
Um erro muito comum nos projetos de replicação que identifico, é que nem tudo aquilo
que está sendo replicado, é necessário. Vou dar um exemplo bem prático: Uma fábrica
de calçados, resolveu abrir uma nova filial para atender somente a demanda de chinelos,
enquanto a matriz, realizava a fabricação de sapatos e botas. Quando foi montada a
replicação para o banco de dados que ficava na filial, não foi dada a devida a atenção
aos dados que seriam replicados, dessa forma, a replicação ficava enviando informações
de toda a produção de sapatos e botas do banco de dados da matriz para o banco de
dados da filial, e isso não era preciso. Ao identificar esse problema, reduzimos o tempo
de replicação, o custo de banda de link e espaço em disco no banco de dados da filial.
Obviamente, precisamos também que a modelagem do banco de dados a ser replicado,
esteja com as formas normais aplicadas. O que eu quero dizer com tudo isso? Não se
prendam somente a simplesmente montar a replicação, selecionar as tabelas e colocar
no ar. Existe todo um trabalho de levantamento das necessidades e conhecimento do que
realmente iremos replicar. Entendam o negócio, conheçam o modelo de dados e
conversem muito com os analistas/desenvolvedores da aplicação em questão. Um
escopo bem definido irá te ajudar e muito na hora da “mão na massa” no SQL Server.
Não se esqueçam também de avaliar todas as dependências das tabelas replicadas,
atentem-se a verificar as foreign keys existentes e replicar as tabelas correspondentes
também.
Outro fator importante e muito relevante no projeto, de quanto em quanto tempo eu terei
que replicar as informações? Esse é outro dado que impacta totalmente na decisão de
implantar uma replicação ou investir numa tecnologia para acesso remoto ao servidor de
banco de dados. Se você necessita que as informações sejam atualizadas numa
frequência alta, quase que “on-line”, não teria o porque implantar uma replicação.
Invista num link “forte” e coloque suas informações “publicadas” para as filiais, salvo
os casos em que o banco de dados seja criado para geração de relatórios, e assim
diminuir uma grande carga do servidor de banco de dados principal.
TIPOS DE REPLICAÇÕES NO SQL SERVER 2008
Quando hailitamos um servidor de banco de dados para replicação, ele solicitará a
criação de um novo database de sistema, que funcionará como um repositório de
informações sobre as publicações criadas. Esse database é chamado de distributor.
No SQL Server 2008, temos alguns tipos de replicações, as quais brevemente irei
explicar:
Replicação Snapshot: Essa replicação, é o modelo inicial de replicação. Por padrão,
todos os modelos de replicação existentes, utilizam inicialmente um Snapshot para
iniciar a replicação. Ela funciona basicamente como uma foto do seu banco de dados
atual. De maneira prática, geralmente utilizamos essa replicação, para bancos de dados
distribuídos que não necessitam de uma atualização tão frequente na massa de dados,
que são atualizados sempre em uma única via, ou seja, do publicador (principal) para os
assinantes. Um exemplo de aplicação para esses databases, são aplicações para
dispositivos móveis, aplicações desenvolvidas para tótens entre outras.
Replicacao Transacional: Nesse modelo, como o próprio nome sugere, iremos
trabalhar por transações. Essa replicação parte inicialmente de uma replicação snapshot,
porém todas as atualizações necessárias a serem replicadas, serão processadas a partir
do log de transações do SQL Server. Quando construímos uma replicação utilizando
esse modelo, o SQL Server habilita um agente, o Log Reader Agent, que fica
constantemente lendo o log de transações, verificando o que já foi replicado e o que
ainda precisa ser. Esse ponto é muito importante, pois precisamos levar em
consideração o tempo que replicamos as informações, pois enquanto as informações do
log de transações não foram replicadas, o log não liberará o espaço ocupado por aquela
informação no logfile, sendo assim, se você tiver um tempo de replicação longo, precisa
prever que seu arquivo de log irá ocupar um espaço considerável, pelo tempo que
aquela informação ainda não foi replicada, mesmo você realizando o backup do log.
Existem 2 tipos de replicação transacional. A Transactional Publication (padrão), que
somente envia dados para os assinantes e a Transactional Publication with updatable
subscriptions, essa permite que você possa realizar alterações nas tabelas replicadas
também nos assinantes, e enviar esses dados para o database publicador. Quando
utilizamos a Transactional Publication with updatable subscriptions, todas as tabelas
nela relacionadas a serem replicadas, terão uma nova coluna do tipo uniqueidentifier. O
SQL Server utiliza esse artifício, para poder ter um identificador único de cada linha da
tabela, independente da quantidade de assinantes dessa replicação. Na prática, podemos
utilizar a replicação transacional padrão, quando se tem diversos bancos de dados
replicados, mas as tabelas principais de cadastro são centralizadas na matriz, dessa
forma, tudo é cadastrado e mantido na matriz e então replicados para todas filiais. E a
Transactional Publication with updatable subscriptions, também podemos utilizar no
mesmo cenário para a tabelas de usuários, pois os usuários poderão alterar suas senhas
também nos sistemas das filiais e assim replicar essa informação também para o
database da matriz.
Replicação Merge: Esse tipo de replicação, é indicado para replicações complexas, que
exigem que os dados sejam manipulados em qualquer um dos databases de todo o
ambiente replicado. Ele tem mecanismos configuráveis e detalhados para resolução de
conflitos. Além do que, você poderá configurar os ranges de campos identities de suas
tabelas. Mas é preciso tomar muito cuidado com esse tipo de replicação. Ela trabalha na
sua essência, com a aplicação de triggers em todas as tabelas relacionadas na replicação.
Apesar do SQL Server ter melhorado muito seus mecanismos para trabalhar com
triggers nas tabelas, temos que ser cautelosos e talvez reavaliar alguns ítens no servidor
de banco de dados atual, tais como modelagem, um bom e preciso trabalho de tuning e
até o hardware.
Necessariamente não precisamos replicar somente tabelas e seus dados. Também
podemos utilizar a replicação para distribuir Store Procedures, Views e Funções. De
certa forma, é uma maneira muito prática e segura de distribuir suas atualizações em
todos os dabatases.
MÃO NA MASSA
Agora que já temos informações sobre o projeto, o negócio, a necessidade e os tipos de
replicações que podemos utilizar, devemos juntar todos esses dados e decidir qual
caminho iremos adotar. Não se prendam a somente um tipo de replicação no seu
projeto, pois é possível mesclar todos os tipos de replicação em um único database ou
conjunto de databases.
Nomenclaturas
Irei detalhar algumas nomenclaturas que utilizaremos em nosso passo a passo exemplo:
Publisher: É o pacote que irá conter os os objetos que farão parte da replicação. Dentro
desse pacote, as tabelas, store procedures, views e user defined functions são
referenciados como Articles.
Subscriber: São os assinantes do publisher, ou seja, os clientes do pacote de replicação.
Distributor: Database onde é armazenado todos os dados dos publicadores e assinantes.
Também é o responsável pela “entrega” dos objetos e dados para todos os assinantes.
Antes de mais nada, vamos criar um database e algumas tabelas para utilizarmos em
nosso exemplo, conforme Listagem 1:
Listagem 1: Criação do database e tabelas utilizadas no exemplo
1
2
3
4
USE [master]
GO
CREATE DATABASE [DBMatriz]
GO
5
6 USE DBMatriz
7 GO
8
CREATE TABLE [dbo].[tbAcao](
9 [idAcao] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
10[idAcaoTipo] [int] NOT NULL,
11[idAcaoStatus] [int] NOT NULL,
12[dtSolicitacao] [smalldatetime] NOT NULL,
[int] NOT NULL,
13[idUsuarioSolicitacao]
[dtExecucao] [smalldatetime] NULL,
14[idUsuarioExecucao] [int] NULL,
15[obsExecucao] [varchar](255) NULL,
16[dsAcao] [varchar](255) NULL,
17[obsSolicitacao] [varchar](255) NULL,
CONSTRAINT [PK_tbAcao] PRIMARY KEY CLUSTERED
18(
19[idAcao] ASC
20)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
21IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
[PRIMARY]
22ON
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
23GO
24
25CREATE TABLE [dbo].[tbAcaoPedido](
26[idAcaoPedido] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
27[idAcao] [int] NOT NULL,
[idPedido] [bigint] NOT NULL,
28CONSTRAINT [PK_tbAcaoPedido] PRIMARY KEY CLUSTERED
29(
30[idAcaoPedido] ASC
31)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
32IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
ON [PRIMARY]
33) ON [PRIMARY]
34GO
35
36CREATE TABLE [dbo].[tbAcaoTipo](
37[idAcaoTipo] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[varchar](120) NOT NULL,
38[nmAcaoTipo]
[idUsuarioGrupo] [int] NOT NULL,
39CONSTRAINT [PK_tbAcaoTipo] PRIMARY KEY CLUSTERED
40(
41[idAcaoTipo] ASC
42)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
43ON [PRIMARY]
44) ON [PRIMARY]
45
46
47
O primeiro passo que devemos realizar, é habilitar a replicação no servidor de banco de
dados que será replicado. Durante a instalação, selecione a opção SQL Server
Replication, conforme Figura 1.
Figura1. Habilitar SQL Server Replication
Após instalada a feature de replicação no servidor de banco de dados, devemos
configurar o Distributor. No cenário ideal, nós devemos separar o distributor em um
servidor dedicado, porém também podemos configurá-lo no servidor que será replicado,
lembrando que essa decisão deve ser estudada, levando em consideração os databases
existentes no servidor e o tamanho da replicação que estará sendo implementada.
Para configurar o distributor, clique com o botão direito em Replication e em seguida
Configure Distribution, conforme Figura 2.
Figura 2. Configurando o Distributor
Em Configure Distribution Wizard – Distributor (Figura3), você irá configurar o
servidor atual como Distributor ou poderá indicar um outro servidor para ser o
Distributor. No nosso exemplo, o próprio servidor será o Distributor.
Figura 3. Selecionando o servidor para Distributor
Na Figura 4, caso o seu servidor não esteja com o SQL Server Agent configurado para
iniciar automaticamente, o wizard da replicação irá questionar se você não quer mudar a
inicialização para automática. É altamente recomendável que o SQL Server Agent seja
configurado para iniciar automaticamente, pois ele tem papel fundamental no
funcionamento da replicação.
Figura 4. Alterar inicialização do SQL Server Agent para iniciar automaticamente
Como dito anteriormente, para todo tipo de replicação, será necessário criar um pacote
Snapshot, com a estrutura e dados para carga inicial. Para que todos os assinantes
consigam acessar esse pacote, criaremos um compartilhamento com acesso somente aos
usuários que iniciam o SQL Server Agent dos servidores replicados (Figura 5).
Figura 5. Configurando a Snapshot Folder
DICA: Para um bom funcionamento de toda a estrutura de replicação, sugiro que utilize
sempre um mesmo usuário e senha locais, criados em todos os servidores que fazem
parte da replicação, e que esse usuário seja configurado para iniciar o SQL Server e o
SQL Server Agent. Mas fica a seu critério, lembrando que se forem usuários diferentes
em cada servidor replicado, você precisará configurar o acesso desses usuários no
compartilhamento do snapshot.
O passo seguinte conforme Figura 6, é configurar o nome do database e o local onde
ficarão fisicamente os arquivos de dados e log. Nesse exemplo, iremos seguir o
sugerido, mas lembre-se, é sempre recomendável separar os arquivos de dados e log em
discos físicos diferentes.
Figura 6. Nome e local do database distributor
A próxima tela do wizard será para habilitar os servidores e databases publicadores
(Publishers). Conforme Figura 7, nesse exemplo somente teremos o servidor local.
Figura 7. Habilitando os publicadores
Em seguida, será perguntado qual a ação que você quer tomar para finalizar o wizard.
Temos 2 opções, configurar o Distributor nesse momento ou gerar um script para
configurá-lo depois. Nesse exemplo, já iremos configurá-lo. Seguindo, será mostrado
um resumo de todas as opções selecionadas durante esse wizard. Figura 8.
Figura 8. Ação para finalização e resumo das opções selecionadas
Agora já podemos criar nossos pacotes de replicação, chamados de Publications. Iremos
criar uma publicação, utilizando a Transaction Replication, para ilustrar o que podemos
fazer com a replicação do SQL Server.
Para criar uma publicação, clique com o botão direito em Local Publication e depois em
New Publication, conforme Figura 9.
Figura 9. Criando nova publicação
Na tela seguinte, clique me Next. Como mostrado na Figura 10, em Publication
Database, vamos selecionar o database que iremos replicar as informações, no nosso
exemplo DBMatriz. Em seguida, na tela Publication Type, iremos selecionar a opção
Transactional Replication. Nessa replicação, como dito anteriormente, os dados
somente são enviados aos assinantes, não haverá retorno de nenhuma alteração ou
novos dados. Clique em Next.
Figura 10. Selecionando o database e o tipo de replicação
Serão exibidos todos os objetos do dabatase escolhido. Agora iremos selecionar as
tabelas que desejamos replicar. Note na Figura 11, onde estão listadas as tabelas de
nosso exemplo, que há uma tabela com um um símbolo indicando que ela não pode ser
selecionada/replicada. A tabela tbAMB2 não tem primary key definida, por esse motivo
não pode ser replicada. Um requisito básico para replicar tabelas, é que elas precisam ter
a chave primária criada.
Figura 11. Selecionando as tabelas a serem replicadas
Após selecionar todas as tabelas, iremos verificar as propriedades dos objetos
selecionados, clicando em Article Properties e depois em Set Properties of All Table
Articles, conforme indica a Figura 12.
Figura 12. Verificando as propriedades das tabelas selecionadas
A Figura 13, mostra a tela de propriedades que podemos alterar para replicar, tanto a
estrutura da tabela, quando seus dados. Obviamente para cada tipo de necessidade,
temos que alterar propriedades diferentes, porém sugiro uma atenção para as seguintes
propriedades: Copy foreign keys constraints, Copy check constraints, Copy Clustered
index, Copy nonclustered indexes, Copy collation, Copy permissions. Uma atenção
especial em Action if name is in use, pois é nesse item que definiremos qual o
comportamento da replicação, caso a tabela já exista no destino. Normalmente utilizo a
opção, Truncate all data in the existing object. Essa opção irá realizar um truncate na
tabela antes de enviar os dados a serem replicados.
Figura 13. Propriedades das tabelas selecionadas
Após configuradas as propriedades, clique em OK e depois em Next. Então chegamos
aos filtros que podemos criar para as tabelas que serão replicadas, Figura 14. Para cada
tabela que selecionamos anteriormente, podemos criar filtros para os dados que serão
replicados. Não criem filtros complexos ou selects muito extensos, pois isso pode
impactar drasticamente na performance da replicação, e consequentemente no seu
database principal. Justamente por esse motivo, você poderá notar que JOINs não são
permitidos no select principal desses filtros. Outro fator importante ao criar um filtro,
tenha em mente que se nas propriedades das tabelas, você habilitou enviar para os
assinantes todas as regras de constraints, certifique-se que não haverá violação dos
dados nesses filtros.
Figura 14. Adicionando filtros as tabelas de sua replicação
Seguindo adiante, iremos configurar o Snapshot Agent. Como mencionado no início,
toda replicação é sempre iniciada através de um snapshot do database. Nesse momento,
iremos indicar se queremos criar o snapshot imediatamente ao término do wizard, e
deixá-lo disponível para os novos assinantes, e as opções de agendamento da execução
do agente que controla o snapshot. Conforme mostrado na Figura 15, recomendo deixar
marcada a opção Create snapshot immediately and keep ths snapshot available to
initialize subscriptions e deixar desmarcada a opção que configura o agente do
snapshot. O Snapshot Agent somente deve ser executado na criação de um novo
assinante, ou na necessidade de reinicializar algum assinante, portando sua executação
poderá ser manual, somente quando necessária.
Figura 15. Configuração do Snapshopt Agent
Na Figura 16, vamos configurar as contas de usuários que irão executar o Snapshot
Agent e Log Reader Agent. O ideal, é que você tenha em todos os servidores que fazem
parte da replicação, uma mesma conta local, com usuários e senhas iguais, para
evitarmos problemas de acessos e permissões pelos agentes.
Figura 16. Configurando a segurança dos agentes do snapshot e log reader
Por fim, será questionado se queremos criar a publicação nesse momento ou gerar um
script que fará todo esse trabalho. No nosso caso, só iremos deixar marcada a opção
Create the publication. Após será solicitado um nome para nossa publicação.
Figura 17. Finalizando o processo de criação de uma publicação e nomeando o
publication
Finalizamos o primeiro passo. Agora iremos criar os assinantes que receberão os dados
da publicação que acabamos de criar. No Microsoft SQL Server Management, em
Replication e depois em Local Publications, note que apareceu um ítem com o nome do
database replicado, mais o nome que você preencheu ao criar a publicação. Clique com
o botão direito em cima desse novo item, e depois em New Subscriptions, conforme
indica a Figura 18.
Figura 18. Criando um novo Subscription (assinante)
Conforme ilustrado na Figura 19, devemos selecionar um Publisher e depois qual será a
ação do distributor. Temos duas opções, a Push subscriptions e Pull subscriptions. Na
Push o distributor irá enviar as informações ao subscriber (assinante), já na Pull, o
assinante é responsável por ir até o distributor e pegar as informações. No nosso
exemplo, iremos utilizar a push subscription.
Figura 19. Selecionando o publisher e a opção do distributor
Na próxima tela, iremos selecionar os subscribers que receberão a replicação. Note que
aparecerão os servidores que você tem registrado no seu Management Studio. Caso
queira incluir mais servidores, basta clicar no botão Add Subscriber e cadastrá-los.
Após selecionar cada servidor subscriber, será necessário escolher o database no
servidor assinante que receberá os dados ou até poderá criar novos databases nos
mesmos.
Figura 20. Selecionando os assinantes e os respectivos databases
Após, iremos configurar as contas que serão utilizadas pelos agentes do subscriber.
Clicando em (…), irá abrir uma tela para configurar as contas que serão utilizadas pelos
agentes. Recomendo que utilize a mesma conta local criada anteriormente, lembrando
novamente que a utilização de uma mesma conta, irá reduzir a possibilidade de
problemas referentes a permissões entre os servidores.
Figura 21. Configurando as contas utilizadas pelos agentes no subscriber
Em seguida iremos definir como o agente do distributor irá enviar as informações ao
assinante. Essa é uma informação que você deverá ter definido no projeto de sua
replicação. A pergunta que se aplica a isso é: Por quanto tempo posso manter as
informações das tabelas sem atualizar? . Respondida essa pergunta, poderemos
configurar a latência dessa replicação. Mas não podemos deixar a replicação por um
longo período de tempo sem replicar os dados, pois isso pode expirar os dados, e se isso
acontecer, será necessário reiniciar o assinante e novamente gerar um snapshot do
database principal. A tela seguinte, conforme Figura 22, nos dá a opção de inicializar
imediatamente a Subscription no término do wizard.
Figura 22. Agendamento e inicialização do assinante
Finalizando, a Figura 23 mostra as duas últimas telas no processo de criação do
subscriber. A primeira mostra as opções de criação do subscriber. Deixaremos marcada
a primeira opção, que irá criar o subscriber imediatamente e a segunda é para gerar o
script desse wizard. Após será exibido um resumo do wizard.
Figura 23. Finalizando a criação do subscriber
Pronto! Criamos nossa replicação com Publicadores e Assinantes.
Agora iremos abrir o Replication Monitor e verificar se todas as ações de inicialização,
criação do snapshot e envio das informações ao subscriber foram realizadas com
sucesso. No Management Studio do servidor matriz, vá em Replication e clique com o
botão direito. Após selecione a opção Launch Replication Monitor. Será apresentada
uma tela como a Figura 24.
Figura 24. Replication Monitor
Essa é a tela que utilizamos para administrar a replicação no SQL Server. Nela podemos
definir as propriedades de tempo de sincronização, iniciar e parar replicações para um
ou todos os assinantes, ver detalhes da replicação, entre outras coisas. Como podemos
visualizar na Figura 24, na guia All Subscriptions, estão listados todos os assinantes da
publicação selecionada. Como a latência está em 00:00:00, podemos perceber que os
dados foram enviados e o pelo tempo da latência, essa indica que o dados está
praticamente on-line.
Outra guia importante e que temos que monitorar constantemente, é a guia Agents
(Figura 25). Nela podemos verificar os status dos agentes de Snapshot e Log Reader.
Figura 25. Guia Agents do Replication Monitor
Para testar na prática, crie uma nova Database Engine Query no seu Management
Studio, e no database DBMatriz, execute os inserts da Listagem 2:
Listagem 2: Inserindo dados na tabela da matriz
INSERT INTO tbAcaoTipo (nmAcaoTipo, idUsuarioGrupo) VALUES
1('Preparando', 1)
2INSERT INTO tbAcaoTipo (nmAcaoTipo, idUsuarioGrupo) VALUES
('Replicando', 1)
Para finalizar e complementar a atividade, rodar algumas sentenças SQL (se for preciso,
pesquisar o que pode ser utilizado). Por exemplo, executar um select na tabela
tbAcaoTipo no database DBFilial (nosso exemplo), e veja que os dados encontram-se
lá.