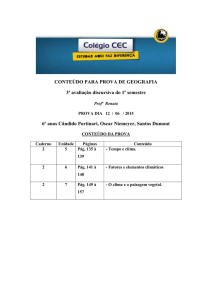
PR3 [[adaptado
p
de AQA3e
Q
– 3.15,, pág.
p g 294]]
z
Enunciado
•
Considere um BTB (Branch Target Buffer) com penalizações de 0, 2
e 2 ciclos de relógio respectivamente para uma predição correcta
de um branch, para uma predição errada e para uma falta (“miss”)
no buffer. Considere um projecto para o BTB que distingue entre
dois tipos de saltos
saltos, saltos condicionados (branches) e
incondicionais, que guardam o endereço alvo no caso dos primeiros e
a instrução alvo no caso do segundo
•
Carlos Sê
C
êrro
•
A) Qual é penalização, em número de ciclos de relógio, quando um salto
incondicional é encontrado no BTB?
B) Determine a melhoria que resulta de guardar a instrução alvo em vez
do endereço alvo (esta operação designa-se por branch folding). Admita
uma taxa de acerto ((“hit rate”)) de 90%,, uma frequência
q
de saltos de
5%, e uma penalização de 2 ciclos de relógio no caso de uma falta
(“miss”) no acesso ao BTB. Qual deve ser o valor da taxa de acerto (o
“hit rate”) para que esta alternativa dê origem a uma melhoria de
desempenho?
p
PR2
1
7-Mai-07
Arquitectura de Computadores 2004/05
PR3 [[adaptado
p
de AQA3e
Q
– 3.15,, pág.
p g 294]]
Carlos Sê
C
êrro
z
Resolução
•
•
•
Relembremos a arquitectura de um Branch Target Buffer
Dos n bits do PC, p deles (os de menor peso) vão endereçar uma
entrada do BTB
Os restantes n-p bits são comparados com outros tantos bits
existentes numa etiqueta (“tag”) da entrada do BTB
PR2
2
7-Mai-07
Arquitectura de Computadores 2004/05
PR3 [[adaptado
p
de AQA3e
Q
– 3.15,, pág.
p g 294]]
Carlos Sê
C
êrro
z
Resolução
•
•
•
PR2
3
7-Mai-07
S hou
Se
houverr igualdade
gua a
na comparação, a entrada
ntra a foi
fo previamente
pr am nt
preenchida com o endereço alvo de um branch (ou com a instrução
alvo de um salto incondicional) e com bits de predição (como
existem numa arquitectura BPB pura)
Isso quer dizer (quando há igualdade) que já tínhamos passado
anteriormente pelo salto incondicional (localidade espacial)
Tudo isto ocorre no andar IF do pipeline, antes de a CPU sequer
saber que vai descodificar uma instrução de salto
Arquitectura de Computadores 2004/05
PR3 [[adaptado
p
de AQA3e
Q
– 3.15,, pág.
p g 294]]
Resolução
•
A) Guardar a instrução de salto de um JMP em vez do endereço de
salto de um Branch permite ganhar uma instrução no pipeline. Com
efeito, se houver acerto (“hit”) no BTB durante o andar IF e a
instrução alvo estiver disponível, podemos inserir essa instrução no
andara ID,
ID no lugar da instrução de branch
branch. A penalização é,
é nesse
caso, igual a -1, ou seja, ganhamos 1 ciclo de relógio
Carlos Sê
C
êrro
z
PR2
4
7-Mai-07
Arquitectura de Computadores 2004/05
PR3 [[adaptado
p
de AQA3e
Q
– 3.15,, pág.
p g 294]]
z
Resolução
•
B) Se o BTB guardar o endereço alvo, o fetch tem de ir buscar a
instrução nesse endereço. Isso dá-nos um CPI de
5% x (90% x 0 + 10% x 2) = 0,01
•
Este valor é o CPI para branches, ponderado pelas suas frequências
(5%)
Se o BTB guardar a instrução alvo, o CPI é de
5% x (90% x (-1) + 10% x 2) = -0,035
Carlos Sê
C
êrro
O valor negativo deste CPI significa que esta opção diminui o CPI
global do processador
A percentagem de acertos que começam a dar origem a uma
melhoria de desempenho é de 60%
5% x (X% x (-1) + (1-X)% x 2) = 0,01 Æ X = 0,6
Ou seja, com hit rates acima de 60% começamos a ganhar ao
implementar
p
esta solução
ç
PR2
5
7-Mai-07
Arquitectura de Computadores 2004/05