Luana Vieira Morellato
SIDSN
Sistema Identificador de Sintagmas Nominais
Vitória - ES, Brasil
17 de Julho de 2007
Luana Vieira Morellato
SIDSN
Sistema Identificador de Sintagmas Nominais
Monografia apresentada para obtenção do Grau
de Bacharel em Ciência da Computação pela
Universidade Federal do Espírito Santo.
Orientador:
Sérgio Antônio Andrade de Freitas
D EPARTAMENTO DE I NFORMÁTICA
C ENTRO T ECNOLÓGICO
U NIVERSIDADE F EDERAL DO E SPÍRITO S ANTO
Vitória - ES, Brasil
17 de Julho de 2007
Monografia de Projeto Final de Graduação sob o título “SIDSN - Sistema Identificador
de Sintagmas Nominais” defendida por Luana Vieira Morellato e aprovada em 17 de Julho de
2007, em Vitória, Estado do Espírito Santo, pela banca examinadora constituída pelos membros:
Prof. Sérgio Antônio A. de Freitas, D. Sc.
Orientador
Prof. Ayrton Monteiro Cristo Filho, M. Sc.
Examinador
Carlos Roberto de Souza Rodrigues, B. Sc
Examinador
Resumo
Este trabalho trata de um sistema que identifica, automaticamente, sintagmas nominais em
sentenças escritas em português. Os sintagmas são formados por grupos de palavras que constituem uma unidade dentro da frase com comportamento de sujeito ou de objeto.
As literaturas apresentam a utilização de sintagmas nominais em sistemas de Recuperação
de Informações (RI), por exemplo, como termos de índices para sistemas de indexação de documentos, no lugar das palavras-chave, normalmente usadas. Na análise semântica, heurísticas
baseadas em resolução de anáforas consideram sintagmas nominais como possíveis antecedentes para expressões anafóricas
O Sistema de Identificação de Sintagmas Nominais (SIDSN) desenvolvido é composto de
dois módulos para obtenção de sintagmas a partir de textos digitalizados. O primeiro faz o préprocessamento no texto, estruturando-o em frases; a partir daí, o módulo Identificador realiza a
análise sintática da sentença e extraí os sintagmas nominais identificados.
Dedicatória
Dedico este trabalho à minha família, papai, mamãe, Lice e Dinho, razão da minha vida.
Agradecimentos
Agradeço a Deus, força maior que nos rege, por estar sempre presente em minha vida.
Aos professores que contribuíram em minha formação acadêmica, obrigado pela paciência
e a dedicação ao transformar o desconhecido em sabedoria. Em especial, aos docentes do
departamento de informática.
Ao Sérgio pela confiança e disponibilidade como professor e orientador. Mesmo com inúmeras atividades, trabalhos e reuniões, sempre respondeu a email’s, tirou dúvidas e, nos momentos de “aflição” da minha parte, a insistente pergunta surgia: Você tá bem?.
Agradeço aos meus pais por dedicarem, ao longo desses anos, o que fosse preciso para
que eu pudesse seguir os caminhos que escolhi. Ao papai por ser, para mim, exemplo de honestidade, responsabilidade e ética, e a mamãe, pelo amor dedicado e demostrado, seja em
sucos levados até o quarto, quando passava horas fazendo trabalho, ou em ligações preocupadas
quando eu esquecia de avisar que ia chegar tarde.
À vovó Teresinha por ser a minha maior “puxa-saco” e sempre ter meu biscoito favorito e
um café quentinho ao passar em sua casa. À madrinha e ao padrinho pelo carinho, e à Marlúcia
por ser a “primã”, a prima-irmã em quem posso confiar.
À Alice por acumular papéis de irmã, amiga, confidente, e por se propor a entender o que
era uma árvore vermelho-preto só para me ajudar a encontrar o motivo de um segmentation full
“inexplicável”. Amo-te de maneira imensurável. À Cris pela amizade incondicional dedicada
desde a época que Ciência da Computação era só uma opção no vestibular. Obrigado por
acreditar, sonhar e lutar junto, pelo sorriso, teimosia, pelas conversas no Transcol ou no sofá de
casa em tardes de domingo.
À Nick pela desenvoltura e flexibilidade demonstrada nos ótimos momentos vividos, por
me deixar fazer da sua república a minha segunda casa, por esperar (dormindo na janela) que
eu chegasse, por me deixar falar por horas. À Magdíssima pela sinceridade, alegria e companheirismo em todos os momentos, e por sempre me dizer o que eu precisava e não o que eu
queria ouvir. À Bruna pelas muitas, e foram muitas mesmo, histórias que, graças à ela, tenho
para contar. Obrigada pelos colchões divididos, roupas emprestadas, pelas fotos “oficiais” e por
me ajudar a acreditar que vale a pena. À querida amiga ártemis Sassá, pela simplicidade, força
e confiança.
Agradeço ao Tatá, o amigo japa mais legal do cantinho, por me ensinar que vírgula é um
sinal de pontuação e não deve ser usado de forma duvidosa. Graças a você, hoje bebo muito
cappucino e me jogo de cabeça, mas também sei a quem procurar quando surge a questão “E
agora, o que faço?”. Muito obrigado por fazer parte da minha vida.
Aos amigos de Santana (Wellington, Deivid, Lilian e Sheilla) e da PJ, Pastoral da Juventude
que, mesmo não havendo a alegria da convivência, continuam a ser muito importantes e queridos. À Lu por ser o recurso humano responsável pelos esclarecimentos e correções lingüísticas
deste trabalho e, também, por cuidar da Lice na minha ausência.
Aos grandes amigos que adquiri durante o curso, em especial, aos 66,666... % das meninas
da sala, Débora e Mary, pela cumplicidade feminina e por formarmos as “programadoras superpoderosas”.
Aos amados amigos e sócios da Top Three, Salomão e Kbelo, pelos trabalhos em duplas
(realizados em trio), os estudos em véspera de prova, pelas brincadeiras e os “papos-cabeça”,
os rocks na cachoeira do Brother e o “minha preta”. Sem a presença de vocês, chegar até aqui
seria muito mais difícil e menos divertido.
Ao Jão pelo companherismo, pelas vezes que o fiz de google, e por aprender antes para me
explicar depois. Agradeço ao Victão pela sinceridade e franqueza, ao Camilo pela amizade e
ternura, e ao Paulim pelo apoio, por compartilhar indecisões e por sempre lembrar que “Dormir
é para os fracos!”. Ao Guilherme, Ckin, Macarrão, Lufe, Diêgo, Gazzela e outros meninos da
turma pela companhia em aula, trabalhos e momentos de descontração.
E a todos que não foram citados, mas, de alguma maneira, fizeram e fazem parte da minha
história.
Sumário
Lista de Figuras
Lista de Tabelas
1 Introdução
p. 11
1.1
Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 11
1.2
Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 11
1.3
Revisão bibliográfica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 12
1.4
Metodologia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 13
1.5
Estrutura da monografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 13
2 Lingüística Computacional
p. 14
2.1
Introdução
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 14
2.2
Processamento da Linguagem Natural . . . . . . . . . . . . . . . . . . . . .
p. 15
2.3
Analisadores Sintáticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 16
2.3.1
Léxico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 16
2.3.2
Gramáticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 16
2.3.2.1
Formalismo . . . . . . . . . . . . . . . . . . . . . . . . .
p. 18
Métodos de Análise . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 18
Gramática Sintagmática do Português . . . . . . . . . . . . . . . . . . . . .
p. 19
2.4.1
Os Sintagmas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 20
2.4.1.1
Sintagma Nominal . . . . . . . . . . . . . . . . . . . . . .
p. 20
2.4.1.2
Sintagma Verbal . . . . . . . . . . . . . . . . . . . . . . .
p. 21
2.3.3
2.4
2.4.1.3
Sintagma Adjetival e Preposicional . . . . . . . . . . . . .
3 SIDSN, um identificador de sintagmas nominais
p. 21
p. 23
3.1
Definição . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 23
3.2
O Pré-processador de Textos . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 24
3.3
Identificador de Sintagmas Nominais . . . . . . . . . . . . . . . . . . . . . .
p. 25
3.3.1
Regras Gramaticais . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 26
3.3.1.1
DCG - Definite Clause Grammar . . . . . . . . . . . . . .
p. 27
3.3.1.2
Nomes e Verbos Composto . . . . . . . . . . . . . . . . .
p. 29
3.3.1.3
Sintagma Preposicional . . . . . . . . . . . . . . . . . . .
p. 30
3.3.1.4
Sintagma Verbal . . . . . . . . . . . . . . . . . . . . . . .
p. 30
3.3.1.5
Sintagma Nominal
. . . . . . . . . . . . . . . . . . . . .
p. 32
Dicionário de Dados . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 34
3.3.2.1
Classificação das palavras . . . . . . . . . . . . . . . . . .
p. 35
Interface de Comunicação . . . . . . . . . . . . . . . . . . . . . . .
p. 36
3.3.2
3.3.3
4 Testes e Avaliação dos Resultados
p. 39
4.1
Introdução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 39
4.2
Testes Iniciais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 39
4.3
Testes por Grupo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 43
4.4
Análise Qualitativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 50
4.5
Análise do Dicionário de Dados . . . . . . . . . . . . . . . . . . . . . . . .
p. 51
5 Conclusões e trabalhos futuros
p. 54
Referências
p. 57
Lista de Figuras
1
Modelo de implementação do SIDSN . . . . . . . . . . . . . . . . . . . . .
p. 23
2
Exemplo de entrada e saída dos módulos do SIDSN . . . . . . . . . . . . . .
p. 24
3
Descrição do Identificador de Sintagma Nominal . . . . . . . . . . . . . . .
p. 26
4
Árvore de derivação sintática de uma frase . . . . . . . . . . . . . . . . . . .
p. 26
5
Exemplos de frases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 29
6
Modelo do Dicionário de Dados . . . . . . . . . . . . . . . . . . . . . . . .
p. 34
7
Estrutura da Interface de Comunicação . . . . . . . . . . . . . . . . . . . . .
p. 36
8
Gráfico de Média e Desvio Padrão dos Grupo de Testes . . . . . . . . . . . .
p. 50
9
Gráficos de análise do dicionário de dados: Grupos Informal e Formal . . . .
p. 52
10
Gráficos de análise do dicionário de dados: Grupos Noticiário e Científico . .
p. 52
11
Gráficos de análise do dicionário de dados: Grupos Técnico e Narrativa . . .
p. 53
Lista de Tabelas
1
Resultados dos Testes Iniciais . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 40
2
Resultados de Testes Posteriores . . . . . . . . . . . . . . . . . . . . . . . .
p. 42
3
Resultado Geral
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 43
4
Textos Informais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 44
5
Textos Formais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 45
6
Textos Técnicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 46
7
Textos Noticiários . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 47
8
Textos Narrativos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 48
9
Textos Científicos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 49
10
Análise Qualitativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 50
11
Tempos de execução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
p. 55
11
1
Introdução
1.1 Motivação
O Processamento de Linguagem Natural (PLN) é voltado ao desenvolvimento de sistemas
que possam interpretar, planejar e produzir informação em linguagem natural. Com o grande
volume de informações armazenadas, atualmente, em formato digital, existe a preocupação em
se obter (e melhorar) ferramentas que possibilitem, dentre outras funcionalidades, organizar,
representar e facilitar a busca nestes dados.
Torna-se interessante, então, o desenvolvimento de sistemas de interpretação de linguagem
natural como aplicação específica ou, ainda, para auxiliar outros programas. O SIDSN, ao
identificar sintagmas nominais, pode ser utilizado por softwares de PLN, principalmente, da
área de Recuperação de Informação (RI), para obter informações de documentos.
O trabalho de Júnior [Júnior 2007] propõe uma metodologia para recuperar informações
relevantes a partir da resolução das anáforas de um documento. A recuperação de informações
é dada pela estrutura proposta por Freitas, [Freitas 2005]. Essa estrutura permite acompanhar
as entidades que se mantêm em evidência ao longo do discurso. No processo de resolução de
anáforas e na obtenção desta estrutura, faz-se necessária a identificação dos sintagmas nominais
contidos no documento.
1.2 Objetivos
O objetivo deste trabalho é construir um sistema para identificar e recuperar, automaticamente, sintagmas nominais contidos em textos escritos. Os textos são irrestritos em relação aos
assuntos tratados, à origem e à estruturação de escrita. A língua adotada nos textos, disponíveis
por meio de documentos digitais, é o Português.
O sistema desenvolvido deve ser capaz de processar documentos para obtenção de textos
em estrutura de frases, além de analisar sintaticamente cada uma para obter a sua composição,
1.3 Revisão bibliográfica
12
de acordo com a gramática sintagmática da língua portuguesa. Deve ser capaz, também, de
identificar todos os sintagmas nominais da frase, recuperar os elementos e informações morfológicas que os compõem, as características sintáticas e a função exercida pelos mesmos na
frase.
1.3 Revisão bibliográfica
A área de Processamento de Linguagem Natural contém trabalhos que implementam a recuperação de sintagmas nominais e trabalhos que utilizam os SN’s como parte da solução. Esta
seção apresenta brevemente alguns exemplos encontrados nas literaturas.
Miorelli [Miorelli 2001] desenvolveu um método denominado ED-CER, de extração de
sintagmas nominais, constituído de dois módulos. O módulo Seletor elimina palavras que não
fazem parte de um sintagma nominal (como verbos, locuções e pontuação), encontrando candidatos a SN. O módulo Analisador recebe esses candidatos, realiza análise sintática, verificando
a sua conformidade com as regras da gramática e, então, o sintagma nominal é reconhecido.
Vieira, em [Vieira et al. 2001], apresenta um trabalho de extração semi-automática de sintagmas nominais para resolver co-referência textual para a Língua Portuguesa. A extração dos
sintagmas nominais foi feita por meio de árvores sintáticas geradas pelo software interativo do
projeto Visual Interactive Syntax Learning (VISL) em forma de listas PROLOG. As correções
nos sintagmas obtidos foi feita manualmente. O trabalho utilizou um corpus constituído por um
conjunto de textos do jornal Correio do Povo.
Kuramoto [Kuramoto 1996] aborda o uso de sintagmas nominais como uma alternativa
na recuperação da informação. Propõe, por meio da construção de um protótipo, um sistema
de recuperação de informação capaz de navegar em uma estrutura em árvore de SN’s. Em
[Kuramoto 2002], procurou explicitar e analisar as freqüências de ocorrências de cada estrutura
possível para os sintagmas nominais.
Souza [Souza 2005], em sua tese de doutorado, investiga o potencial de uso dos sintagmas
nominais em processos de indexação automática, partindo do pressuposto que estes têm maior
grau de informação semântica embutida e, assim, podem vir a se tornar mais eficazes do que
as palavras-chave normalmente utilizadas como descritores em processos automatizados de representação de documentos ou em sistemas de leitura das palavras oferecidas pelo autor dos
documentos.
Em [Freitas 2005] é proposto, por Freitas, um método de resolução de anáforas nominais
1.4 Metodologia
13
definida. Tal tarefa, dependendo do seu tipo, é feita mediante a procura de um antecedente,
tendo como estrutura uma lista de entidades explícitas, composta por sintagmas nominais indefinidos, pronomes e elipses e uma implícita com sintagmas nominais definidos. O conceito de
definido e indefinido está associado ao tipo do artigo que acompanha o sintagma.
1.4 Metodologia
A metodologia adotada para o desenvolvimento deste trabalho iniciou-se com uma revisão
bibliográfica, incluindo estudos relacionados ao conhecimento sobre processamento de linguagem natural, linguagem de programação lógica e armazenamento de dados por meio de banco
relacional; além da realização de estudos da gramática da língua portuguesa.
Logo após a revisão bibliográfica, definiram-se as ferramentas para implementar o identificador de sintagmas nominais e iniciou-se o processo de desenvolvimento. A seguir, foram
realizados testes no sistema e, paralelamente, foi produzido um cronograma para a elaboração
da monografia, seguido até sua conclusão.
1.5 Estrutura da monografia
O presente trabalho está estruturado da seguinte forma:
O capítulo 2 apresenta pontos teóricos relacionados ao sistema. Os conhecimentos computacionais abrangem na área Processamento de Linguagem Natural o estudo de Analisadores
Sintáticos. A descrição de conceitos da Gramática da Língua Portuguesa relativos aos sintagmas
são encontrados na seção 2.4
No capítulo 3, é apresentado o SIDSN, o modelo de implementação, as etapas envolvidas
e ferramentas utilizadas. O capítulo 4 trata dos testes efetuados e da análise dos resultados
obtidos. As considerações finais, conclusões e trabalhos futuros são descritas no capítulo 5.
14
2
Lingüística Computacional
Neste capítulo apresentam-se os principais conceitos relacionados ao desenvolvimento de
um identificador de sintagmas nominais.
2.1 Introdução
“A Lingüística Computacional é a área de conhecimento que explora as relações entre
lingüística e informática, tornando possível a construção de sistemas com capacidade de reconhecer e produzir informação apresentada em linguagem natural” [Vieira e Lima 2001]. Envolve conhecimentos de lingüística teórica e aplicada como, por exemplo, a sintaxe, a semântica, a pragmática e análise de discurso, normalmente provenientes de estudiosos linguistas, e de
linguagens de programação e software para processar as línguas naturais. A Lingüística Computacional pode ser dividida em duas áreas: Lingüística baseada em Corpus e Processamento
de Linguagem Natural (PLN).
A Lingüística baseada em Corpus utiliza um conjunto de textos, corpus, com a finalidade
de obter informações como freqüência de palavras, de formas, fazer comparações entre a língua
falada e escrita, analisar usos da língua em diferentes épocas, encontrar diferenças entre o português do Brasil e de Portugal, dentre outras. Existem corpus de diferentes fontes e tipos como
os de linguagem falada, linguagem escrita literária, textos de jornal, dentre outros.
Nessa área da lingüística, a utilização da computação limita-se a auxiliar na obtenção das
informações e no armazenamento dos dados, não se destinando diretamente à construção ou
aperfeiçoamento de algum software ou aplicativo.
O Processamento de Linguagem Natural (PLN) é voltado à construção de softwares, aplicativos e sistemas computacionais específicos que possam interpretar, planejar e produzir informação em linguagem natural. Sendo necessário “diversos subsistemas para dar conta dos
diferentes aspectos da língua: sons, palavras, sentenças e discurso nos níveis estruturais, de
significado e de uso”, [Vieira e Lima 2001].
2.2 Processamento da Linguagem Natural
15
Analisadores sintáticos, também chamados de parsers, chatterbots (programas que simulam a conversação humana), tradutores automáticos, reconhecedores de voz e geradores de
resumo são alguns exemplos de sistemas desenvolvidos pelo PLN.
Este trabalho compreende o Processamento de Linguagem Natural para o desenvolvimento
de um software específico que identifique sintagmas nominais.
2.2 Processamento da Linguagem Natural
“O Processamento de Linguagem Natural é um subcampo da Inteligência Artificial (IA)
e da lingüística que estuda os problemas de geração automática e entendimento da linguagem
natural”, [Wikipédia]. O PLN envolve sistemas para tratar a linguagem escrita e falada.
Na linguagem falada tem-se o desenvolvimento de sistemas de reconhecimento e de síntese
da fala. O reconhecimento da fala compreende a interpretação dos sons e a ligação destes com
os símbolos existentes na linguagem. A síntese da fala contém programas capazes de gerar uma
saída sonora a partir de um texto. Os conhecimentos em lingüística considerados englobam
estudo de fonética, que consiste na análise da fala humana num nível fisiológico de produção, e
fonologia, que estuda as regras e princípios da distribuição dos sons da língua.
As áreas da Lingüística de grande importância para o desenvolvimento de programas que
manipulam linguagem escrita são a morfologia, a sintaxe, a semântica e, em alguns casos, a
pragmática e o discurso. Aplicativos nessa área podem fazer traduções automáticas de textos,
geração de resumos, correção ortográfica e gramatical, análise sintática, dentre outras funcionalidades.
Segundo [Xavier 1992], a sintaxe é “a área da lingúistica que estuda as regras, as condições
e os princípios subjacentes à organização estrutural dos constituintes das frase, ou seja, o estudo
da ordem dos constituintes das frases”. Os analisadores sintáticos, parsers, são os programas
responsáveis pela interpretação automática (ou semi-automática) de sentenças de linguagem
natural.
“A semântica é a área que estuda o significado tal como ele é estruturado nas línguas”,
[Xavier 1992]. É a parte do estudo da linguagem que se ocupa do significado das expressões da
língua, enquanto a pragmática relaciona o significado com o contexto no qual está inserido.
A pragmática é, então, definida como “a área que estuda os princípios da linguagem em
situação de uso, na qual os comunicadores e o contexto são as categorias principais que determinam a interpretação lingüística”, [Xavier 1992].
2.3 Analisadores Sintáticos
16
O sistema identificador de sintagmas nominais lida com o tratamento em nível sintático de
linguagem natural, fundamentado na obtenção de um analisador sintático que classifica palavras
e expressões sintagmáticas em sentenças e define uma estrutura de relação entre estas, de acordo
com uma gramática definida.
2.3 Analisadores Sintáticos
O analisador sintático tem a função de reconhecer uma seqüência de palavras e afirmar
se esta compõe uma frase da língua. As relações entre as palavras que constituem uma frase
podem ser mostradas por meio de uma representação gráfica dada por uma árvore de derivação.
A análise sintática determina a sintaxe de uma linguagem, dada pelas regras de uma gramática. Estas são definidas pela combinação de um conjunto de palavras, denominado léxico. É
necessário, também, especificar um método de análise para o processo de analisador sintático,
[Louden 2004].
2.3.1 Léxico
O léxico, também conhecido como dicionário, é a estrutura que contém os itens lexicais
e suas informações morfológicas. Os itens podem ser palavras isoladas ou composições vocabulares e, dentre as informações associadas a eles, tem-se a classe gramatical, além de valores
como gênero, número, grau, pessoa, tempo, modo, regência e, em alguns casos, representações
ou descrições semânticas.
A morfologia estuda a constituição das palavras e sua classificação em categorias, sendo
necessária na composição do léxico de um analisador. Trata do conhecimento da estrutura das
palavras, que podem ser constítuídas por unidades básicas, chamadas de morfemas, e elementos
adicionais, como sufixos e prefixos.
Também é a morfologia que classifica as palavras em diferentes categorias gramaticais
como substantivos, verbos, adjetivos, preposições etc. Uma palavra pode ser classificada em
mais de uma categoria, dependendo do contexto no qual está inserida e de sua função na frase.
2.3.2 Gramáticas
A gramática utilizada num analisador sintático deve ser capaz de reconhecer as sentenças
válidas da língua, além de mostrar sua expressividade. É composta por regras por meio das
2.3 Analisadores Sintáticos
17
quais é possível obter os elementos da linguagem. A classificação de gramáticas, segundo
[Chomsky 1956], possui 4 níveis:
• Tipo 0: Gramáticas sem restrição
As gramáticas pertencentes a essa classificação são aquelas às quais nenhuma limitação
é imposta.
• Tipo 1: Gramáticas livres de contexto
São gramáticas que não levam em consideração o contexto em que estão sendo analisadas,
permitindo a representação de linguagens com um certo grau de complexidade. Para a
linguagem natural, o maior problema está relacionado às dependências e concordâncias,
pois abordagens puramente livres de contexto não são suficientemente poderosas para
captar a descrição adequada deste gênero de linguagem.
• Tipo 2: Gramáticas sensíveis ao contexto
Ao utilizar gramática sensível ao contexto, o problema de dependência é resolvido. Porém, seu uso em PLN é restrito devido à complexidade algorítmica envolvida. Além
disso, tais gramáticas não tratam de maneira satisfatória algumas restrições gramaticais.
• Tipo 3: Gramáticas regulares
São gramáticas simples e facilmente reconhecidas. Porém, apresentam um poder de expressão limitado.
Em Exemplo 1 tem-se exemplo de uma gramática com duas regras de formação definidas
por meio de fatos e regras em lógica de 1a ordem.
Exemplo 1 : A menina sorriu. Ela sorriu.
frase ⇒ artigo , nome, verbo.
frase ⇒ pronome, verbo.
verbo(sorriu).
artigo(a).
nome(menina).
pronome(ela).
2.3 Analisadores Sintáticos
18
2.3.2.1 Formalismo
Pode-se definir um formalismo como uma maneira de escrever uma gramática. Porém, não
há como demarcar um formalismo que contemple todas as necessidades da linguagem natural.
Os modelos utilizados e propostos seguem em um nível intermediário às gramáticas de livre
contexto e às gramáticas sensíveis ao contexto.
Segundo [Vieira e Lima 2001], dentre os formalismos gramaticais destacam-se as redes de
transição, gramáticas de constituintes imediatos (phrase structure grammar PSG), gramáticas
de constituintes imediatos generalizadas (GPSG), gramáticas de unificação funcional, PATR-II,
e, ainda, HPSG (head-driven phrase strutcture grammar).
Dos formalismos gramaticais citados anteriormente, mostrar-se-á dois deles. Primeiramente, as PSG’s (phrase structure grammar), gramáticas livres de contexto que estruturam
a sintaxe frasal em função de seus constituintes. Por exemplo, define-se uma Frase como sendo
composta pelos constituintes Sintagma Nominal e Sintagma Verbal.
O formalismo PSG tem poder gerativo e capacidade computacional e é utilizado, por exemplo, em algoritmos que reconhecem linguagens de programação. No entanto, não consegue
resolver questões de concordância de gênero, número e pessoa, que são de grande importância
em linguagem natural.
O problema de concordância é resolvido no formalismo PATR-II, onde é possível fornecer
informações de gênero, número e pessoa nas regras gramaticais.
2.3.3 Métodos de Análise
Apresentada as noções de gramática e os formalismos de representação, a seguir tem-se
diferentes métodos de análise sintática, por meio de analisadores top-down, bottom-up, leftcorner e chart parser.
A análise top-down caracteriza-se por construir uma árvore de derivação da raiz para as
folhas, ou seja, começando pelas regras iniciais e descendo para os símbolos da sentença, as
palavras. Um analisador top-down utilizado no Exemplo 1, encontraria o conceito frase e,
então, verificaria as regras das quais é composto. Uma análise de regras da esquerda para a
direita irá descer pelo ramo mais à esquerda da árvore até encontrar um elemento terminal que
a satisfaça.
O método top-down permite uma redundância na análise de dados, ao precisar verificar as
regras mais de uma vez. Dependendo da estruturação das regras, pode acontecer uma recursão
2.4 Gramática Sintagmática do Português
19
em loop mais a esquerda, não sendo possível terminar a análise da frase.
Um analisador bottom-up faz o contrário, começa pelas folhas da árvore de derivação, e
tenta montá-la combinando as regras. Não há problemas com loop para regras recursivas à
esquerda, porém, não tem como tratar fenômenos linguísticos como constituintes vazios, componentes facultativos na frase, entre outros.
O left-corner é uma combinação das análises bottom-up e top-down pois, ao encontrar uma
palavra, ele verifica que tipo de regra inicia com tal palavra e, então, faz o restante da análise de
forma top-down partindo desta regra. Assim, não há problemas com loop.
O chart parser, também chamado de tabular, evita a redundância de buscas ao guardar as
estruturas já analisadas e reutilizá-las, se for preciso. Assim, elimina-se o backtraking e previne
a explosão combinatorial de possibilidades que poderia vir a ocorrer durante o processamento.
Verificados os assuntos computacionais relacionados à estruturação de um programa para
processamento de linguagem natural, no caso específico dos analisadores sintáticos, tem-se a
necessidade de ligação com um domínio.
Na análise sintática, a gramática abrange um conjunto de regras que definem as formas
permitidas de uma linguagem. A Gramática Sintagmática do Português explicita as regras de
formação de sentenças válidas da língua por meio de seus constituintes, os sintagmas.
2.4 Gramática Sintagmática do Português
Segundo [Silva 1993] “uma frase é a expressão verbal de um pensamento, ou seja, todo
enunciado suficiente por si mesmo para estabelecer comunicação”. A frase consiste, então, em
uma combinação de elementos lingüísticos agrupados segundo regras e princípios que a tornam
uma sentença válida da língua.
Oração é todo enunciado lingüístico que se estrutura ao redor de um verbo. O conceito de
frase, por vezes, é empregado como sinônimo de oração. Mas a frase não precisa obrigatoriamente ter um verbo. Em Exemplo 2 tem-se casos de orações e frases.
Exemplo 2 :
1. Cuidado!
2. A aula irá começar mais cedo.
3. Viajaremos nas férias de julho.
2.4 Gramática Sintagmática do Português
20
As regras gramaticais têm como função especificar e formalizar as relações existentes entre
os elementos que compõem as frases. As regras devem ser capazes de descrever a estrutura
sintática da língua a qual se referem. Os elementos que, quando combinados, formam orações
são chamados de sintagmas.
2.4.1 Os Sintagmas
“O sintagma consiste num conjunto de elementos que constituem uma unidade significativa
dentro da oração e que mantêm entre si relações de dependência e de ordem”, [Silva 1993]. Um
sintagma é formado por uma ou várias palavras que, juntas, desempenham uma função na frase.
A natureza do sintagma depende da classe gramatical a qual seu núcleo pertence, existindo
assim sintagmas nominais (SN), sintagmas verbais (SV), sintagmas adjetivais (SA) e sintagmas
preposicionais (SP).
Uma oração deve conter, obrigatoriamente, o SN e o SV, e, de forma facultativa, o SA e o
SP. O sintagma nominal apresenta-se oculto em algumas frases, como no Exemplo 2.3, em que
o vocábulo Nós não aparece. No Exemplo 3, vê-se um frase e sua decomposição em sintagmas.
Exemplo 3 : O bebê acordou cedinho.
• Sintagma Nominal ⇒ O bebê
• Sintagma Verbal ⇒ acordou cedinho
• Sintagma Preposicional ⇒ cedinho
2.4.1.1 Sintagma Nominal
O Sintagma Nominal é a unidade sintática-semântica em que o núcleo é constituído por um
nome ou pronome. O núcleo pode ser acompanhado pelos elementos caracterizadores denominados determinante e modificador.
Um sintagma nominal pode ter função de sujeito ou objeto na frase, dependendo da sua
relação com os outros constituintes. A seguir, tem-se a regra de formação geral de um sintagma
nominal, onde os parênteses indicam que o elemento é facultativo, no caso o determinante, Det,
e o modificador, Mod.
SN −→ (Det) + (Mod) + Núcleo + (Mod)
2.4 Gramática Sintagmática do Português
21
O nome pode ser representado por elementos da classe dos substantivos (sobretudo simples,
composto e próprio), e dos pronomes (pessoal). O determinante é composto por artigos definidos e indefinidos, numeral, pronomes possessivos, indefinidos, e pode também ser formado de
maneira composta. O modificador é constituído de sintagmas adjetivais e preposicionais.
O Exemplo 4 exibe frases que destacam os sintagmas nominais, além de ressaltar sua função.
Exemplo 4 :
• Duas caixas caíram no chão. (sujeito - objeto)
• Os meus dois cachorros fugiram. (sujeito)
• Ela chama-se Maria José. (sujeito - objeto)
• Todos choraram. (sujeito)
2.4.1.2 Sintagma Verbal
O sintagma verbal é constituído do seu núcleo, o verbo, e de modificadores facultativos
SN, SP e/ou SA. O verbo pode ser composto por um ou mais vocábulos. Alguns exemplos de
sintagmas verbais com os seus respectivos tipos de verbos são mostrados no Exemplo 5.
Exemplo 5 :
• A menina adormeceu. (adormecer - verbo intransitivo)
• Alice vendeu a casa. (vender - verbo transitivo direto)
• Os alunos faltaram à aula. (faltar - verbo transitivo indireto)
• O professor falou de você ao diretor. (falar - verbo transitivo direto e indireto)
2.4.1.3 Sintagma Adjetival e Preposicional
O sintagma adjetival (SA) e o sintagma preposicional (SP) podem ser encontrados como
parte de outros sintagmas, exercendo a função de modificadores destes. O SA tem como núcleo
um adjetivo e pode possuir modificadores e intensificadores, conforme exibido no Exemplo 6.
Exemplo 6 :
2.4 Gramática Sintagmática do Português
22
• A escola é velha. (adjetivo)
• A escola é muito velha. (advérbio + adjetivo)
O sintagma preposicional é composto por uma preposição e um SN, ou de um advérbio,
mostrados no Exemplo 7.
Exemplo 7 :
• A caminhada começa cedinho. (advérbio)
• A caminhada começa de madrugada. (preposição + SN)
Fundamentado nos conhecimentos obtidos no que diz respeito às áreas computacionais de
Análise Sintática em Processamento de Linguagem Natural, e lingüísticas de Gramática da
Língua Portuguesa, é possível construir um sistema capaz de identificar expressões da língua,
no caso específico, de sintagmas nominais em frases.
23
3
SIDSN, um identificador de sintagmas
nominais
Este capítulo apresenta o SIDSN - Sistema Identificador de Sintagmas Nominais.
3.1 Definição
O Sistema Identificador de Sintagmas Nominais - SIDSN - é um conjunto de programas
que tem por objetivo reconhecer e retornar os sintagmas nominais contidos em frases. Estas,
por sua vez, pertencem a textos que estão disponíveis em formato digital.
Na Figura 1, tem-se um modelo geral da estrutura de implementação do sistema, que foi
dividido em dois módulos: o Pré-processador de Textos e o Identificador de Sintagmas Nominais.
Figura 1: Modelo de implementação do SIDSN
O Pré-processador de Textos tem a função de estruturar em frases um texto digital submetido ao sistema. O programa recebe um arquivo em formato texto (.txt) como entrada, e fornece
um arquivo contendo as frases pertencentes a esse texto na saída. As frases estão descritas em
forma de lista de palavras.
O Identificador de Sintagmas Nominais utiliza como entrada o conjunto de frases segmentadas fornecido pelo Pré-processador de Textos. Cada frase é processada e verificada se, de
acordo com as regras definidas da língua portuguesa, é uma sentença válida. Nesse caso, retorna uma lista contendo os sintagmas nominais encontrados com suas respectivas funções de-
3.2 O Pré-processador de Textos
24
sempenhadas dentro da frase. Caso essa frase não obedeça às regras gramaticais estabelecidas
no identificador, uma mensagem é retornada informando que não foi possível reconhecê-la.
A Figura 2 mostra um exemplo de entrada e saída de cada etapa do sistema. A mensagem
No indica que a frase não foi reconhecida.
Figura 2: Exemplo de entrada e saída dos módulos do SIDSN
A seguir, descreve-se de maneira mais detalhada a implementação dos dois módulos que
compõem o SIDSN.
3.2 O Pré-processador de Textos
O Pré-processador de Textos é o módulo do SIDSN responsável pela organização do texto
em frases e pela retirada de símbolos, tais como pontuação e caracteres de delimitação.
Os textos submetidos a processamento devem estar em formato texto (.txt), mas, caso estejam em outro formato, pode-se utilizar programas disponíveis no sistema operacional Linux,
por exemplo, para fazer a transformação. Existem disponíveis os comandos de conversão pdfto-
3.3 Identificador de Sintagmas Nominais
25
text para formato pdf, html2text para html e wvText para documentos Microsoft Word e BrOffice
Writer. Ao utilizar esses programas, símbolos não identificáveis pelo pré-processador podem
surgir devido a diferenças de codificação dos arquivos.
O pré-processador foi implementado usando AWK, uma linguagem de programação script
para processamento de dados baseados em texto. Uma linguagem de programação script tem
como característica ser formada de um conjunto de componentes já desenvolvidos em outras
linguagens, além de ser interpretada. No caso específico do AWK, possui uma sintaxe parecida
com a liguagem C, utiliza vetores indexados por palavras chave e expressões regulares.
O Algoritmo 1 descreve os procedimentos do script. Ao encontrar um sinal de pontuação,
tal como ponto final, exclamação, interrogação, reticências etc, é formada uma nova frase. O
critério utilizado para separar uma frase de outra quando estas são compostas por mais de uma
oração separadas por vírgula é a quantidade de palavras existentes.
Algoritmo 1: Script pré-processador de texto
Entrada: Arquivo texto
1
Construir Lista com as frases (Lista de palavras);
2
para cada um dos tokens de texto faça
3
Retira símbolos encontrados;
4
Insere token numa Lista de palavras;
5
se símbolo estiver em (! . ? ; : ... )
6
OR símbolo for (,) e a tamanho da lista for maior que 3 então
7
Termina Lista de palavras, formando assim uma frase;
8
Insere na Lista de frases;
9
Inicia uma nova Lista de palavras;
10
11
enquanto não for fim da Lista de frases faça
Imprime no arquivo cada Lista de palavras;
Saída: Arquivo com lista de frases
3.3 Identificador de Sintagmas Nominais
O Identificador de Sintagmas Nominais é responsável pelo reconhecimento dos sintagmas
nominais nas frases. Seu diagrama de blocos é apresentado na Figura 3.
O Identificador de Sintagmas Nominais analisa a estrutura sintática das frases e retorna seus
sintagmas nominais, desconsiderando os demais elementos. A gramática necessária na análise
3.3 Identificador de Sintagmas Nominais
26
Figura 3: Descrição do Identificador de Sintagma Nominal
sintática é definida pelas Regras Gramaticais e o léxico utilizado pelas regras encontra-se no
Dicionário de Dados. A comunicação entre a gramática e o léxico é dada pela Interface de
Comunicação.
3.3.1 Regras Gramaticais
As Regras Gramaticais implementam um subconjunto das regras definidas da língua portuguesa para determinar sentenças válidas da linguagem. A explicação de composição das regras
será feita em modo top-down e, em alguns casos, usando árvore de derivação, como observado
na Figura 4.
Figura 4: Árvore de derivação sintática de uma frase
3.3 Identificador de Sintagmas Nominais
27
A linguagem de programação utilizada foi o PROLOG que, originalmente projetado para
o processamento de linguagem natural, possui algumas características vantajosas. Dentre elas,
um formalismo para representação de gramáticas livres de contexto denominado DCG (Definite
Clause Grammar), associado a um analisador top-down recursivo, da esquerda para a direita.
Para melhor entendimento das regras, apresenta-se o formalismo DCG e, logo após, como
é empregado nas regras.
3.3.1.1 DCG - Definite Clause Grammar
A DCG, Definite Clause Grammar, é um formalismo representativo de gramáticas livres de
contexto, onde as regras gramaticais podem ser definidas como no Exemplo 8.
Exemplo 8 :A menina sorriu. O menino sorriu.
frase --> sn, sv.
sn --> artigo, subst.
sv --> verbo.
artigo --> [a]; [o].
subst --> [menina]; [menino].
verbo --> [sorriu].
As regras descritas em DCG são diretamente transformadas em cláusulas PROLOG, [SWI-Prolog],
como pode ser observado no Exemplo 9.
Exemplo 9 :
DCG:
frase --> sn, sv.
Prolog: frase(R1,R2) :- sn(R1,R2), sv(R1,R2).
DCG:
artigo --> [a]; [o].
Prolog:
artigo(A, B) :-
( A=[a|B] ;
A=[o|B]).
O formalismo DCG possibilita a extensão da gramática livre de contexto por meio da inclusão de argumentos para, por exemplo, tratar concordância entre os componentes de uma regra
3.3 Identificador de Sintagmas Nominais
28
gramatical. O Exemplo 10 exibe uma regra de formação de um sintagma nominal com a adição de informações. Dessa forma, o analisador só identifica como corretos os sintagmas que
concordem em número e gênero.
Exemplo 10 :
sn(Numero,Genero) --> artigo (Numero,Genero), subst(Numero,Genero).
artigo(singular,masculino) --> [o].
artigo(singular,feminino) --> [a].
artigo(plural,masculino) --> [os].
artigo(plural,feminino) --> [as].
subst(singular, masculino) --> [menino].
subst(singular, feminino) --> [menina].
subst(plural, masculino) --> [meninos].
subst(plural, feminino) --> [meninas].
As regras utilizadas no módulo Identificador de Sintagmas Nominais foram implementadas
em DCG’s e serão mostradas de maneira similar, porém, em um nível mais alto de abstração. A
composição das frases faz uso das regras contidas nas seções 3.3.1.3, Sintagma Preposicional,
3.3.1.4, Sintagma Verbal, e 3.3.1.5, Sintagma Nominal.
O conceito mais alto na hierarquia da análise sintática é o de FRASE, que é definido em
quatro regras. Na Regra 1, vê-se FRASE definida como uma ORACAO, e em Regra 2. como
sendo composta de duas orações unidas por uma conjunção. O conceito ORACAO não é a
implementação da definição do português para oração.
Regra 1 FRASE =⇒ ORACAO
Ex: A menina chegou em casa feliz.
Regra 2 FRASE =⇒ ORACAO + conjunção + ORACAO
Ex: A casa era grande e o jardim era pequeno.
Regra 3 FRASE =⇒ pronome interrogativo + ORACAO
Ex: Quem é você ?
3.3 Identificador de Sintagmas Nominais
29
Regra 4 FRASE =⇒ SP + ORACAO
Ex: Certamente ele virá.
A Regra 3 abrange as frases que utilizam os pronomes interrogativos no ínicío da oração, e
na Regra 4, as frases que têm um modificador, advérbio ou locução adverbial, antes de ORACAO.
As regras de formação do termo ORACAO são mostradas na Figura 5, abrangendo os tipos
de frase existentes na língua. Na Figura 5(a) tem-se a formação da maioria das frases, contendo
um sintagma nomimal e um verbal. Na Figura 5(b) observa-se um exemplo de frase que não
contém o sintagma nominal, as chamadas frases verbais. Nas frases nominais não existe a
presença de um verbo, como visto na Figura 5(c).
(a) Oração
(b) Frase Verbal
(c) Frase nominal
Figura 5: Exemplos de frases
Os termos, como conjunção, pronome interrogativo, nome presentes nas regras, são classificações dadas pelo Dicionário de Dados. Este faz a verificação de qual categoria pertence as
palavras analisadas da frase.
As palavras que não estão presentes em nenhuma categoria do Dicionário de Dados são
classificadas como sem_categoria. As regras seguintes utilizam NOMECOMPOSTO e VERBOCOMPOSTO para tratar os casos de nomes e verbos formados de maneira composta.
3.3.1.2 Nomes e Verbos Composto
Um nome composto é um composição de substantivos podendo estar ligados por conectivos, como por exemplo, Secretaria Municipal de Saúde, Donald Knuth. Na Regra 5 tem-se a
descrição de formação da regra NOMECOMPOSTO, compostos recursivamente por palavras
encontradas na categoria nome ou classificadas em sem_categoria.
3.3 Identificador de Sintagmas Nominais
30
Os verbos compostos são definidos na Regra 6, englobando uso de verbos consecutivos
como em Vai ser feito o acordo.
Regra 5 NOMECOMPOSTO =⇒ [nome OU sem_categoria] + NOMECOMPOSTO
NOMECOMPOSTO =⇒ []
Regra 6 VERBOCOMPOSTO =⇒ [verbo OU sem_categoria] + VERBOCOMPOSTO
VERBOCOMPOSTO =⇒ []
3.3.1.3 Sintagma Preposicional
Os sintagmas preposicionais são tratados em regras explícitas ou como parte de outras regras. A formação prep + SN de um sintagma preposicional está imbutida nas regras de sintagmas nominais. As regras a seguir têm o sintagma preposicional definido como advérbio, Regra
7, e locuções adverbiais, Regra 8 e Regra 9.
Regra 7 SP =⇒ adverbio
• Ex: Provalvelmente virá amanhã.
Regra 8 SP =⇒ preposicao + adverbio
• Ex: Executou com rapidez a ação.
Regra 9 SP =⇒ preposicao + adverbio + adverbio
• Ex: Executou com muita rapidez a ação.
3.3.1.4 Sintagma Verbal
O Sintagma Verbal é um dos elementos básicos de uma oração, sendo composto de um ou
mais vocábulos e podendo vir acompanhado de complemento e modificadores. As regras de
formação são definidas pelo EXPVERBAL com a presença, de forma facultativa, de sintagmas
nominais (SN).
A Regra 10 trata o caso dos verbos intransitivos ou impessoais. Os verbos transitivos diretos
ou indiretos, ou seja, aqueles que precisam de somente um complemento, objeto direto (não
exige preposição) ou indireto (exige preposição), são tratados na Regra 11. E os verbos que são
transitivos diretos e indiretos (exigem os dois objetos) são tratados na Regra 12.
3.3 Identificador de Sintagmas Nominais
31
Regra 10 SV =⇒ EXPVERBAL
• Ex: A menina chorona adormeceu.
• Ex: Ontem, não choveu.
Regra 11 SV =⇒ EXPVERBAL + SN
• Ex: Ele mora em Vitória.
• Ex: O céu é azul.
Regra 12 SV =⇒ EXPVERBAL + SN + SN
• Ex: Eu falei de você ao meu pai.
• Ex: Os alunos desse ano ofereceram um convite de formatura ao coordenador do
curso.
A regra EXPVERBAL, contida na formação dos sintagmas verbais, é constituída de VERBO,
Regra 15 e 16, e mostrada a seguir. Os componentes que estão entre parênteses são termos facultativos, e entre aspas duplas, palavras específicas.
Regra 13 EXPVERBAL =⇒ VERBO
• Ex: João correu muito.
Regra 14 EXPVERBAL =⇒ (“não”) + “se”+ VERBO
• Ex: Ele não se conteve.
Regra 15 VERBO =⇒ (SP) + VERBOCOMPOSTO + (SP)
• Ex: Alice muito falou que se cansou.
• Ex: Ele irá trabalhar arduamente.
Regra 16 :
VERBO =⇒ (SP) + VERBOCOMPOSTO + conjuncao + VERBOCOMPOSTO + (SP)
• Ex: As vendas cresceram e caíram de forma acentuada naquele ano
3.3 Identificador de Sintagmas Nominais
32
3.3.1.5 Sintagma Nominal
O elemento de maior interesse do SIDSN são os sintagmas nominais. A Regra 17 e a
Regra 18 tratam o caso de sintagmas compostos por SINTAGMANOMINAL podendo estar
precedidos por preposição e unidos por conjunção.
Regra 17 SN =⇒ (preposicao) + SINTAGMANOMINAL
Regra 18 SN =⇒ (preposicao) + SINTAGMANOMINAL + conjuncao + SINTAGMANOMINAL
A regra EN encontrada nos sintagmas é a composição que abrange os nomes compostos,
podendo conter adjetivos.
Regra 19 EN =⇒ (adjetivo) + (sem_categoria) + NOMECOMPOSTO + (adjetivo)
As regras a seguir são relativas aos sintagmas nominais, implementadas pela gramática. Os
SN’s podem exercer função de sujeito ou objeto na frase, mas as Regras 30 a 32 só podem ser
encontradas com a função de objeto.
Regra 20 SINTAGMANOMINAL =⇒ pronome pessoal
• Ex: Ela está aqui.
• Vou com vocês.
Regra 21 SINTAGMANOMINAL =⇒ (artigo) + EN + (SP)
• Ex: O restaurante provalvelmente está funcionando.
• O professor encontra-se no departamento de informática.
Regra 22 SINTAGMANOMINAL =⇒ (artigo) + pronome possessivo + EN
• Ex: Meu cachorro fugiu.
Regra 23 SINTAGMANOMINAL =⇒ (artigo) + “mesmo” + EN
3.3 Identificador de Sintagmas Nominais
• Ex: É o mesmo carro.
Regra 24 SINTAGMANOMINAL =⇒ (artigo) + “próprio” + EN
• Ex: O próprio filho comprou a casa.
• Ex: Maria sabia da história da própria família.
Regra 25 SINTAGMANOMINAL =⇒ (artigo) + “outro” + EN
• O outro caso discutido será mostrado na próxima reunião.
Regra 26 SINTAGMANOMINAL =⇒ pronome indefinido + EN
• Ex: Nenhum aluno foi embora.
• Todos os países assinaram o acordo.
Regra 27 SINTAGMANOMINAL =⇒ (“qualquer”/“cada”) + (“um”/“uma”)
• Qualquer um pode participar.
• É dever de cada um.
Regra 28 SINTAGMANOMINAL =⇒ “qualquer” + (“outro”/“outra”) + EN
• Escolha qualquer outro.
• Qualquer outro medicamento lhe fará mal.
Regra 29 SINTAGMANOMINAL =⇒ pronome demonstrativo
• Aquele é o advogado da família.
Regra 30 SINTAGMANOMINAL =⇒ pronome obliquo + “mesmo”
• Ex: Entregue a mim mesmo.
Regra 31 SINTAGMANOMINAL =⇒ pronome obliquo + “próprio”
33
3.3 Identificador de Sintagmas Nominais
34
• O réu condenou a si próprio
Regra 32 SINTAGMANOMINAL =⇒ pronome obliquo
• Ex: Entregou a mim.
O conjunto das 32 regras descritas compõe a gramática que o SIDSN utilizará para definir
sentenças válidas da língua portuguesa.
Considerando a árvore de derivação formada pelas regras gramaticais, os elementos encontrados nas folhas são as classes das palavras e, em algumas regras específicas, é utilizada a
própria palavra. Durante o processo de análise sintática é preciso verificar se os elementos da
frase pertencem a uma categoria de palavras. As informações das palavras pertencentes à língua
e sua classificação estão contidas no Dicionário de Dados.
3.3.2 Dicionário de Dados
O Dicionário de Dados é a implementação do léxico do analisador sintático. Contém o
conjunto de vocábulos da língua e as informações correspondentes a estes. Foi implementado
utilizando o banco de dados relacional PostgreSQL, segundo o modelo conceitual visto na Figura 6.
Figura 6: Modelo do Dicionário de Dados
As palavras contidas no dicionário de dados possuem informações como número, grau,
gênero, pessoa, além da classe gramatical a qual pertence.
3.3 Identificador de Sintagmas Nominais
35
3.3.2.1 Classificação das palavras
Os substantivos e verbos são as principais classes gramaticais do português, pois formam
o núcleo das orações. Algumas classes servem para exprimir atributos das classes principais,
como os artigos, adjetivos, pronomes e advérbios, mas pode ocorrer, no caso dos adjetivos
e pronomes, do núcleo do sintagma ser composto por uma dessas classes. As preposições e
conjunções têm função conectiva e são necessárias para estruturar a sintaxe de uma oração.
O Dicionário de Dados define a seguinte classificação incluindo as respectivas classes de
palavras do português:
• Pronome: contém os pronomes pessoais, possessivos, demonstrativos, indefinidos, relativos, interrogativos;
• Determinante: engloba os artigos definidos (o, a, os, as) e os indefinidos (um, uma, uns,
umas);
• Adjetivo: todos os adjetivos;
• Verbo: contém verbos regulares e irregulares, no infinitivo e conjugados;
• Nome: os substantivos masculinos, femininos e de dois gêneros;
• Conjunção: as conjunções definidas por integrante (que, se), causal (pois, porque), concessiva (embora, conquanto), condicional (quando, caso), conformativa (conforme, segundo), comparativa (quanto, como), proporcionais (enquanto, quanto mais), temporal
(quando, antes que), final (para que, a fim de) e consecutiva (que tal, que tanto). No caso
das locuções conjuntivas, a identificação é feita por meio das regras gramaticais.
• Preposição: ante, após, até, com, contra, de, entre outras.
• Advérbios: afirmação (sim, realmente), negação (não, nunca), dúvida (talvez, provavelmente), tempo (ontem, atualmente), lugar (aqui, perto), modo (rapidamente, tristemente),
intensidade (pouco, bastante).
• sem_categoria: classificação dada a palavras que não se encontram no dicionário de
dados.
Uma palavra é classificada como sem_categoria quando não está no dicionário de dados.
As regras permitem essa classe em sua formação como uma alternativa no papel de substantivos,
verbos ou adjetivos. A adição de elementos no Dicionário de Dados priorizou as classes com
3.3 Identificador de Sintagmas Nominais
36
número menor de elementos, possibilitando o uso da classificação sem_categoria somente nas
classes mais numerosas.
Definidas as regras gramaticais e o dicionário de dados, deve-se criar um meio para a troca
de informação entre as partes. A função de permitir essa comunicação é exercida pela Interface
de Comunicação.
3.3.3
Interface de Comunicação
A Interface de Comunicação faz a ligação entre a implementação das Regras Gramaticais,
em linguagem PROLOG, e o Dicionário de Dados, em banco de dados PostgreSQL, como
mostrado na Figura 7. Foi implementada em linguagem C, utilizando funções definidas pela
biblioteca libpq para a comunicação com o banco de dados e a biblioteca SWI-Prolog para
ligar-se ao PROLOG.
Figura 7: Estrutura da Interface de Comunicação
A libpq é uma biblioteca do PostgreSQL que permite, dentre outras funcionalidades, abrir
uma conexão com o banco, executar consultas SQL’s, verificar status da conexão. Algumas das
funções de controle de conexão disponibilizada na biblioteca:
• PQsetdbLogin: estabelece uma nova conexão com o servidor de banco de dados, passando informações como host, nome do banco de dados, login e senha.
PGconn *PQsetdbLogin(const char *pghost,
const char *pgport,
const char *pgoptions,
const char *pgtty,
const char *dbName,
3.3 Identificador de Sintagmas Nominais
37
const char *login,
const char *pwd);
• PQfinish: fecha a conexão com o servidor e libera a memória utilizada para conectar.
void PQfinish(PGconn *conn);
• PQstatus: retorna o valor CONNECTION_OK quando uma conexão é bem sucedida
com o banco de dados, do contrário, CONNECTION_BAD.
ConnStatusType PQstatus(const PGconn *conn);
• PQexec: submete um comando ao servidor e aguarda pelo resultado. São processados
em uma única transação, a menos que existam comandos BEGIN e COMMIT explícitos,
para dividi-la em várias transações.
PGresult *PQexec(PGconn *conn, const char *command);
• PQresultStatus: retorna o status do resultado do comando, dentre eles, PGRES_EMPTY_QUERY,
envio de comando vazio, PGRES_COMMAND_OK, término bem-sucedido, PGRES_FATAL_ERRO
ocorreu um erro fatal.
ExecStatusType PQresultStatus(const PGresult *res);
• PQresStatus: cadeia de caracteres que descreve o código do status do PQresultStatus.
char *PQresStatus(ExecStatusType status);
• PQclear: libera o armazenamento associado a PGresult.
void PQclear(PGresult *res);
O objetivo da relação C - Prolog é ter flexibilidade e desempenho. As funções que serão
utilizadas pela outra linguagem devem ter o mesmo número dos argumentos e ocorrer a conversão de tipos C a argumentos de instanciação e unificação Prolog. A comunicação foi realizada
do Prolog, chamando funções estrangeiras definidas em C, mas o contrário também é possível utilizando outras funções da biblioteca SWI-Prolog. A seguir algumas funções de retorno,
unificação e conversão de tipos que foram utilizadas.
• PL_succeed: sucesso alcançado, definida como return True;
3.3 Identificador de Sintagmas Nominais
38
foreign_t PL_succeed()
• PL_fail: Falha e inicia o backtracking do Prolog.
foreign_t PL_fail()
• PL_unify_integer: unifica um inteiro no termo Prolog.
int PL_unify_integer(term_t ?t, long n)
• PL_get_wchars: Funcão para usar o caracter extendido wchar, que foi utilizado devido o
uso de palavras acentuadas.
int PL_get_wchars(term_t t, size_t *len, pl_wchar_t **s,
unsigned flags)
Após implementado o Sistema Identificador de Sintagmas Nominais, faz-se necessário executar testes no programa, a fim de verificar se este atinge o objetivo pretendido.
39
4
Testes e Avaliação dos Resultados
Este capítulo apresenta os testes realizados no SIDSN e a avaliação dos resultados obtidos.
4.1 Introdução
Para a realização dos testes, utilizou-se um conjunto de textos de diversas fontes, com
diferentes características, obtidos, principalmente, por meio de pesquisas em sites de busca na
Internet. Dentre os tipos, pode-se citar, notícias jornalísticas, artigos científicos, blogs, teses de
doutorado e livros literários.
As informações apresentadas nos resultados se referem às características dos textos, como
quantidade de palavras e frases, e dos testes, como número de acertos, erros, valores de médias
e desvio padrão.
Durante o processo de implementação foram realizados os primeiros testes, quando o identificador não compreendia todas as regras definidas, e, então, observado o comportamento dos
resultados. Posteriormente, com o sistema contendo as regras gramaticais explicitadas no capítulo 3, novos testes foram realizados, além de uma análise de resultados por agrupamento de
instâncias semelhantes. Por fim, fez-se uma análise qualitativa nos sintagmas identificados pelo
SIDSN, e uma avaliação do dicionário de dados.
4.2 Testes Iniciais
Inicialmente definiu-se um conjunto de regras gramaticais que contemplam alguns casos
de definições de frase do português, como os descritos nas Regras 1 e 3 do Capítulo 3. Estas
regras e exemplos de casos abrangidos por elas podem ser vistos no Exemplo 11. Os primeiros
testes foram executados sobre o Identificador de Sintagmas Nominais implementado com esse
conjunto limitado de Regras Gramaticais e um Dicionário de Dados incompleto.
4.2 Testes Iniciais
40
Exemplo 11 :
1. Frase =⇒ Oração
Oração =⇒ Sintagma Nominal + Sintagma Verbal + Sintagma Nominal
• O menino alegre chegou da cidade.
• Papai está triste.
2. Frase =⇒ pronome interrogativo + Oração
Oração =⇒ Sintagma Verbal
• Quem ganhou ?
• Por que choveu ?
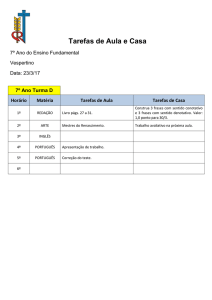
A Tabela 1 mostra, para cada instância testada, a quantidade de palavras e de frases do
texto, o número e as percentagens de acertos e erros, as médias e o Desvio Padrão. Considera-se
acerto quando o sistema encontra uma regra que se ajustou à frase e, então, retorna os sintagmas
nominais contidos nela. A Média Geral é dada pela razão da quantidade total de acertos dos
textos pela a quantidade total de frases e a Média Percentual é média dos percentuais de acerto.
Texto Palavras Frases
Texto1
102
13
Texto2
143
15
Texto3
176
19
Texto4
240
20
Texto5
465
75
Texto6
496
63
Texto7
825
80
Texto8
1044
149
Texto9
1706
235
Texto10
4862
419
Total de Frases
Média
Média %
Desvio Padrão
Acertos
9
4
7
5
40
19
26
77
95
180
Erros
4
11
12
15
35
44
54
72
140
239
%Acertos %Erros
69,23
30,77
26,67
73,33
36,84
63,16
25,00
75,00
53,33
46,67
30,16
69,84
32,50
67,50
51,68
48,32
40,43
59,57
42,96
57,04
1088
42,46 %
40,88 %
41,60 %
Tabela 1: Resultados dos Testes Iniciais
Os dez textos submetidos a teste contabilizam um total de 1088 frases, são distintos em
número de palavras, tipo, fonte, englobando notícias jornalística, estórias infantis, blogs e artigos científicos. A Média Geral obtida foi de 42,46 % e a Média Percentual de 40,88%. O pior
resultado de acertos, 25,00%, foi apresentado pelo Texto4, e o melhor, 69,23%, pelo Texto1,
obtendo assim um Desvio Padrão de 41,60%.
4.2 Testes Iniciais
41
Observa-se uma grande variação entre os resultados obtidos e um baixo valor médio de
acertos. Esse resultado decorre do ambiente de testes compreender um dicionário de dados e um
conjunto de regras gramaticais incompleto. Classes de palavras como Artigos e Preposições,
por exemplo, não continham seus elementos no dicionário de dados, o sistema também não
compreendia as regras gramaticais, Regra 2, 4 e 5, definidas no Capítulo 3. A descrição e os
exemplos de frases que seguem essas regras são exibidos em Exemplo 12.
Exemplo 12 :
1. Frase =⇒ advérbio + Sintagma Nominal + Sintagma Verbal + Sintagma Nominal
• Indubitavelmente, ele é inteligente.
2. Frase =⇒ Oracao + conjunção + Oracao
• Ele é feliz e ela vive sozinha.
3. Nome Composto
• Ciência da Computação
• Exame Nacional de Desempenho de Estudantes
Buscando melhorar os resultados obtidos, estas regras foram incorporadas ao escopo do
identificador e novas palavras ao Dicionário de Dados. Um novo conjunto de testes foi realizado, utilizando as mesmas instâncias do teste anterior e os resultados são exibidos na Tabela
2.
Houve uma melhora nos resultados, e os novos valores encontrados foram 49,72% e 48,98%
para Média Geral e Percentual, respectivamente. O Desvio Padrão aumentou para 50,05%
devido, principalmente, ao Texto3 que, diferente dos demais, diminuiu o número de acertos.
Nesse caso, a frase foi identificada erroneamente, caracterizando os chamados falsos positivos. O Exemplo 13 mostra tal frase, os sintagmas identificados ao efetuar o primeiro teste e a
categoria de cada palavra no dicionário de dados.
Exemplo 13 :
>>> À medida em que se aproxima o prazo final.
Sintagma nomimal, sujeito => [a, medida, em]
4.2 Testes Iniciais
42
Texto Palavras Frases
Texto1
102
13
Texto2
143
15
Texto3
176
19
Texto4
240
20
Texto5
465
75
Texto6
496
63
Texto7
825
80
Texto8
1044
149
Texto9
1706
235
Texto10
4862
419
Total de Frases
Média
Média %
Desvio Padrão
Acertos
11
5
6
9
50
28
27
80
103
222
Erros
2
10
13
11
25
35
53
69
132
197
%Acertos %Erros
84,62
15,38
33,33
66,67
31,58
68,42
45,00
55,00
66,67
33,33
44,44
55,56
33,75
66,25
53,69
46,31
43,83
56,17
52,98
47,02
1088
49,72%
48,98%
50,05%
Tabela 2: Resultados de Testes Posteriores
artigo -
a
substantivo - medida
não encontrada no banco - em
pronome relativo - que
=> se
Sintagma verbal => aproxima
verbo - aproxima
Sintagma nominal, objeto => [o, prazo, final]
artigo - o
substantivo - prazo
adjetivo - final
A palavra em não estava presente no Dicionário de Dados e foi empregada com o papel de
substantivo, formando o sintagma nominal [a, medida, em] de forma errada. Após as modificações no Dicionário de Dados, a palavra em foi incorporada à classe das preposições. Ao testar
novamente o texto, o programa não mais identificou essa frase, porque a sua regra formação
não estava presente em Regras Gramaticais. Percebe-se, então, que, apesar da diminuição da
quantidade de frases identificadas, ocorre uma melhora na qualidade da solução obtida e torna
menor o número de falsos positivos.
Ao analisar os conjuntos de testes e perceber uma melhora geral nos resultados obtidos
advindos das mudanças efetuadas, o desenvolvimento do identificador focou a adição de regras
gramaticais e aumento do número de elementos do dicionário de dados.
4.3 Testes por Grupo
43
Após o processo de implementação das 32 regras definidas no Capítulo 3, novos testes
foram realizados em um conjunto de 40 textos, diferentes dos utilizados anteriormente e o
Resultado Geral pode ser verificado na Tabela 3.
Resultado Geral
40
71.362
37.742
57,57%
54,72%
51,74%
38,46%
71,60%
Total de Textos
Total de Palavras
Total de Frases
Média
Média %
Desvio Padrão
Menor %Acerto
Maior %Acerto
Tabela 3: Resultado Geral
A Média de acertos obtida foi de 57,57% e a Média Percentual de 54,72%, valores maiores
que os encontrados anteriormente. Porém, o valor de Desvio Padrão para o novo conjunto de
instâncias, 51,74% foi consideravelmente maior que o valor obtido no primeiro grupo, 41,60%.
Tal valor contrasta com as melhoras obtidas nas médias de acertos, indicando a influência de um
fator, ou presença de uma característica, ainda não identificada. Sugere-se, então, uma divisão
de instâncias em grupos semelhantes de textos.
4.3 Testes por Grupo
A separação de textos em grupos deu-se a partir de semelhança de gênero (formais, funcionais, formal-funcional) e tipos textuais (noticiário, científico, editorial, carta, entrevista etc).
Entretanto, não foi realizado agrupamento por assunto dos textos (computação, biologia, arte
etc).
O primeiro grupo engloba textos que têm como características em comum a pequena quantidade de frases e linguagem informal, onde podem ocorrer erros léxicos, desrespeito às regras
gramaticais, uso de gírias e neologismos. Como, por exemplo, encontrados em blogs, emails,
wikis. Os resultados para divisão dos Textos Informais são mostrados na Tabela 4.
Os valores obtidos de Média, 46,17%, e de Média Percentual, 44,73%, foram menores
que os alcançados em Resultado Geral, mas percebe-se que o Desvio Padrão foi muito menor,
8,52%. Algumas frases extraídas dos textos utilizados neste grupo podem ser vistas no Exemplo
14.
A informalidade dos textos é percebida no item 1 do Exemplo 14, onde ocorre uma ono-
4.3 Testes por Grupo
44
Texto
Palavras Frases Acertos
Informal1
743
78
30
Informal2
521
52
23
Informal3
366
30
14
Informal4
1218
134
60
Informal5
4677
426
188
Informal6
4395
441
221
Total Frases
Média
Média %
Desvio Padrão
Erros
48
29
16
74
238
220
%Acertos
38,46
44,23
46,67
44,78
44,13
50,11
1161
46,17 %
44,73 %
8,52 %
%Erros
61,54
55,77
53,33
55,22
55,87
49,89
Tabela 4: Textos Informais
matopéia, palavra que imita sons e ruídos e que não se encontra na escrita formal. Porém,
isso não ocasionou um erro na identificação da frase, porque a palavra foi classificada como
sem_categoria e enquadrada em uma regra que permite palavras que não estejam no dicionário
de dados.
Em Exemplo 14.3 e 14.4 a existência de palavras que não estão no dicionário de dados,
fazem, dá e pudessem, e de palavras com mais de uma classificação, voto e muito, leva à não
identificação da frase nas regras estabelecidas.
Exemplo 14 :
1. Ela tem seguidores, hahahahaha. (Inform2) Acerto
2. A divisão continental separa a floresta da sua vizinha. (Inform5) Acerto
3. Uma máquina de calcular onde a forma de calcular pudesse ser controlada por cartões.
(Inform6) Erro
4. Aqui no Brasil, os políticos fazem coisas muito piores com quem lhes dá voto. (Inform1)
Erro
Relatórios administrativos, editais, normas e diário oficial são alguns dos textos utilizados
no próximo teste. Têm como características em comum a grande quantidade de palavras não
encontradas no dicionário de dados e de estruturas como enumeração de itens, tabelas etc. Os
resultados deste grupo formado pode ser observado na Tabela 5.
O desvio padrão foi de 10,90% e a média de 68,96%, bem maior que a Média Geral. Os
melhores resultados percentuais de acerto atingidos pertencem a este grupo, devido, principalmente, à estrutura dos textos. O Exemplo 15 mostra um trecho retirado do texto Formal5
4.3 Testes por Grupo
45
Texto
Palavras Frases Acertos
Formal1
27157
4147
2849
Formal2
18456
2595
1858
Formal3
12791
1695
1192
Formal4
629
95
59
Formal5
5041
737
487
Formal6
4502
541
320
Total Frases
Média
Média %
Desvio Padrão
Erros
1298
737
503
36
250
221
%Acertos
68,7
71,6
70,32
62,11
66,08
59,15
9810
68,96%
66,33%
10,90%
%Erros
31,3
28,4
29,68
29,68
37,89
40,85
Tabela 5: Textos Formais
que, ao ser submetido ao Pré-processador de Textos, teve como saída a geração de uma frase
para cada item. Todas essas frases, segundo as regras definidas em Regras Gramaticais, estão
corretas.
Exemplo 15 :
a)
Comprovação dos pré-requisitos/escolaridade;
b)
Comprovação dos requisitos enumerados no item 1 do Capítulo III;
c)
Certidão de nascimento ou casamento;
d)
Título de eleitor;
e)
Certificado de Reservista ou de Dispensa de Incorporação;
f)
Cédula de Identidade;
g)
CPF;
h)
Documento de inscrição no PIS ou PASEP, se houver;
i)
Quatro fotos 3x4 recentes;
j)
Curriculum Vitae (2 cópias);
k)
Comprovante do tipo sangüineo e Fator RH;
O próximo agrupamento utiliza textos técnicos como apostilas, capítulos de livros, artigos,
abrangendo assuntos diversos tais como geografia, química, direito, psicologia e matemática.
Os textos presentes nesse grupo têm característica dissertativa e descritiva, são normalmente
objetivos e coerentes, têm maior quantidade de frases que os textos do grupo anterior, escrita
formal, e palavras específicas da área a qual se referem.
A Tabela 6 mostra um Desvio Padrão de 11,45%, Média Geral de 51,27% e Percentual de
51,80%. Percebe-se pelas frases do Exemplo 16 que os textos tratam de assuntos diferentes e
4.3 Testes por Grupo
46
Texto
Palavras Frases
Tecnic1
2474
310
Tecnic2
7854
942
Tecnic3
872
92
Tecnic4
2155
134
Tecnic5
487
51
Tecnic6
1357
161
Tecnic7
3376
372
Tecnic8
564
59
Tecnic9
2832
250
Tecnic10
11712
1141
Tecnic11
648
65
Total frases
Média
Média %
Desvio Padrão
Acertos
172
490
49
63
26
96
195
31
125
556
31
Erros
138
452
43
71
25
65
177
28
125
585
34
%Acertos
55,48
52,2
53,26
47,01
50,98
59,63
52,42
52,54
50
48,73
47,69
3577
51,27%
51,80%
11,45%
%Erros
44,52
47,98
46,74
52,99
49,02
40,37
47,58
47,46
50
51,27
52,31
Tabela 6: Textos Técnicos
que é possível identificar uma frase, como o Exemplo 16.2, mesmo esta possuindo estruturas
como uma expressão matemática.
Exemplo 16 :
1. A transformação desta energia se inicia nas plantas verdes através da fotossíntese. (Tecnic8) Acerto
2. Um aluno pode escrever 7 + 5 = 2 x 6 ou 7 + 5 = 10 + 5 - 3. (Tecnic9) Acerto
3. Esta campanha, entretanto, marcou o início da derrocada de Napoleão. (Tecnic1) Acerto
4. Entretanto, ângulos ahb de até 30o já foram medidos. (Tecnic4) Erro
5. Por exemplo, a molécula de água pode formar ligações do tipo ponte de hidrogênio cuja
representação é: (Tecnic5) Erro
Um exemplo de erro decorrido do dicionário de dados incompleto pôde ser observado na
frase 16.4, na qual o verbo foram foi classificado como sem_categoria e adequado como correto em parte de uma regra. Mas na análise total da frase não é encontrada regra que a satisfaça.
Frases com estrutura como a do Exemplo 16.5 não têm regra definida na gramática implementada.
Os próximos testes foram realizados utilizando textos jornalísticos que caracterizam-se por
serem descritivos e informativos, de linguagem objetiva, compreendendo uma quantidade média
4.3 Testes por Grupo
47
de frases. Os resultados do grupo Textos Noticiários são exibidos na Tabela 7, onde se pode ver
a Média de 58,72%, a Média Percentual de 57,03%, e Desvio Padrão de 12,31%. Os valores
obtidos estão acima da Média Geral encontrada na análise dos 40 textos.
Texto
Palavras Frases Acertos
Noticia1
15357
1354
826
Noticia2
590
63
40
Noticia3
2074
209
105
Noticia5
824
110
65
Noticia6
1053
128
66
Noticia7
2252
221
120
Noticia8
2325
267
159
Total Frases
Média
Média %
Desvio Padrão
Erros
528
23
104
45
62
101
108
%Acertos %Erros
61
39
63,49
36,51
50,24
49,76
59,09
40,91
51,56
48,44
54,3
45,7
59,55
40,45
2352
58,72%
57,03%
12,31%
Tabela 7: Textos Noticiários
A análise do Exemplo 17.1 mostrou que, mesmo com a ausência, no dicionário de dados,
do verbo da frase, reúne, ela foi identificada corretamente. No item 2 tem-se um exemplo de
frase nominal, onde se encontra apenas um sintagma nominal.
Durante a análise da frase, pode ocorrer o exame de verbos que não estão definidos no
dicionário de dados, como substantivos, ocasionando falha na identificação. Tal como pode ser
visto no Exemplo 17.4, em que o erro não se deu pela presença do nome próprio Vera Simão,
mas pelo verbo garante, que não se encontra no dicionário.
Exemplo 17 :
1. Na Áustria encontro anual que reúne aficionados pelo carro da montadora alemã. (Noticia2) Acerto
2. Queda nas taxas de juros e aumento do crédito bancário. (Noticia1) Acerto
3. O medicamento age sobre o neurotransmissor gaba. (Noticia3) Erro
4. Garante a empresária Vera Simão. (Noticia6) Erro
O grupo a seguir é composto por textos narrativos, relatam fatos, ações, acontecimentos,
incluindo, por exemplo, histórias infantis e obras literárias. Caracterizam-se por ter subjetividade, predominância de verbos, escrita com certo grau de informalidade. Porém, espera-se que
4.3 Testes por Grupo
48
Texto
Palavras Frases Acertos
Narrativa1
651
77
39
Narrativa2
465
76
51
Narrativa3
10809
1480
961
Narrativa4
17298
2291
1145
Narrativa5
52088
7146
4197
Narrativa6
11543
1613
934
Total Frases
Média
Média %
Desvio Padrão
Erros
38
25
519
1146
2949
679
%Acertos %Erros
50,65
49,35
67,11
32,89
64,93
35,07
49,98
50,02
58,73
41,27
57,90
42,10
12683
57,77%
58,22%
15,80%
Tabela 8: Textos Narrativos
obedeçam às regras gramaticais do português. O resultado dos testes pode ser verificado na
Tabela 8.
A quantidade de frases analisadas é superior aos grupos analisados anteriormente, pois,
dentre os textos utilizados, encontram-se livros da literatura nacional como A viuvinha, de José
de Alencar, Escrava Isaura, de Bernardo Guimarães e Adão e Eva, de Eça de Queirós. A média
de acertos obtida foi de 57,77% e a média percentual, de 58,22%.
O desvio padrão de 15,80% destaca a diferença entre o resultado do texto Narrativa4 (A
viuvinha), 49,98%, e o texto Narrativa2 (Chapeuzinho Vermelho - Estória Infantil), 67,11%. O
primeiro texto tem linguagem poética com regras gramaticais antigas, enquanto o segundo é
composto de linguagem simples e tal diferença pode ser vista nas frases do Exemplo 18.
Exemplo 18 :
1. O lobo resolveu dar uma cochilada e começou a roncar. (Narrativa2) Acerto
2. Por que não vai pela floresta?. (Narrativa2) Acerto
3. Minha prima, antes que as novas ruas que se abriram tivessem dado um ar de cidade
às lindas encostas do morro de Santa Teresa, veria de longe sorrir-lhe entre o arvoredo.
(Narrativa4) Erro
4. Não conheceis esse sublime requinte da alma que sente um alívio em deixar-se vencer
pela dor. (Narrativa4) Erro
Os textos classificados no grupo Textos Científicos têm como característica em comum a
organização em partes, como por exemplo, introdução, objetivos, resultados e referências bibliográficas. Estes podem incluir termos funcionais para descrever operações ou processos, além
4.3 Testes por Grupo
49
de possuir muitas figuras e tabelas. Foram utilizadas nos testes teses, dissertações, monografias que compreendiam diferentes assuntos como educação, engenharia etc. Os resultados estão
presentes na Tabela 9.
Texto Palavras Frases Acertos
Cientif1
25954
2910
1684
Cientif2
31205
3076
1471
Cientif3
41706
4367
2173
Cientif4
47186
5511
3081
Total Frases
Média
Média %
Desvio Padrão
Erros
1226
1605
2194
2430
%Acertos
57,87
47,82
49,76
55,91
15864
53,01%
52,81%
8,33%
%Erros
42,13
52,18
50,24
44,09
Tabela 9: Textos Científicos
Os resultados mostram Média de 53,01%, Média Percentual 52,81% e Desvio Padrão de
8,33%. Alguns exemplos de frases deste grupo são encontrados no Exemplo 19.
Exemplo 19 :
1. Uma estratégia metodológica que privilegie a relação teoria-prática. (Cientific2) Acerto
2. Nesta última etapa apresentamos o levantamento quantitativo. (Cientific4) Acerto
3. Os autores citam que em 1830 instala-se o primeiro serviço de medicina do trabalho.
(Cientific4) Erro
4. Em todos os grupos observa-se um aumento significativo no tempo de uso passando de
acessos esporádicos a acessos semanais ou diários. (Cientific2) Acerto
A Figura 8 apresenta um gráfico que confronta os valores obtidos de Média Percentual de
acerto e Desvio Padrão de cada grupo e a Média Geral e Desvio Padrão do teste realizado com
todos os textos.
O grupo Formal, que compreendia editais, relatórios e outros arquivos onde existe um
grande número de estruturas como tabelas, gráficos e citações, teve o melhor resultado em
quantidade de acertos. O valor de média mais baixo foi encontrado no grupo Informal.
Percebe-se a grande diferença entre o Desvio Padrão do teste geral e o obtido nos grupos,
mostrando que o agrupamento por estrutura, tipo e gênero semelhantes, mesmo tratando de
assuntos distintos, é válido, porque obtém-se uma menor variação dos resultados.
4.4 Análise Qualitativa
50
80
Media %
Desvio Padrao
70
60
Porcentagem
50
40
30
20
10
0
Total Geral
Informal
Formal
Tecnico
Noticia
Narrativa Cientifico
Figura 8: Gráfico de Média e Desvio Padrão dos Grupo de Testes
Para averiguar a autenticidade dos sintagmas nominais identificados pelo SIDSN, faz-se
necessária uma análise qualitativa dos resultados.
4.4 Análise Qualitativa
A análise qualitativa do resultado foi realizada nas frases que o programa reconheceu como
acerto, verificando se os sintagmas nominais foram identificados corretamente. É um trabalho
realizado manualmente, necessitando, por vezes, conhecimentos específicos da língua portuguesa. Por isso, a quantidade de textos utilizados é menor. A Tabela 10 mostra o resultado da
análise feita em alguns dos textos utilizados anteriormente.
Texto
% Acertos
Inform1
38,46
Tecn5
50,98
Formal4
62,11
Noticia5
59,09
Narrativa2
67,11
Acertos
30
26
59
65
51
%SN incorreto
46,65
34,61
0,05
29,23
43,13
SN incorreto
14
9
3
19
22
Motivo1* Motivo2*
10
4
7
2
2
1
17
2
20
2
Tabela 10: Análise Qualitativa
*Motivo1: Palavras não encontradas no Dicionário de Dados
*Motivo2: Palavras com várias classificações gramaticais
Dois foram os motivos que ocasionaram a identificação dos SN de forma incorreta: palavras
4.5 Análise do Dicionário de Dados
51
presentes na frase que não se encontravam no Dicionário de Dados, e palavras que tinham mais
de um registro, ou seja, pertencentes a mais de uma classe gramatical.
Percebe-se um grande número de frases nas quais o SIDSN identifica de forma errada os
sintagmas nominais. Em alguns casos, esse valor chegou a 46,65% dos acertos obtidos, sendo
a maioria dos erros advinda do dicionário de dados incompleto.
O baixo valor de frases com sintagma identificado erroneamente em Formal4, 0,05%, foi
devido à grande quantidade de frases nominais encontradas neste texto. Em Exemplo 20, vê-se
frases que abordam os motivos da falha na identificação dos sintagmas.
Exemplo 20 :
1. A menina vai dormir cedo.
2. Casa, mas logo separa.
A identificação incorreta no caso mostrado no item 1 é ocasionada pelo Motivo1. A palavra
vai não está presente no dicionário de dados, e, durante a análise da frase pelo Identificador de
Sintagmas Nominais, foi classificada e considerada como um substantivo retornando o sintagma
nominal com função de sujeito da frase, [A menina vai]. O segundo caso, item 2, ocorre quando
a palavra tem mais de uma classificação gramatical. Nesse exemplo a palavra casa é a 3a pessoa
do verbo casar, mas o programa identifica como substantivo casa.
Com intuito de obter uma maior quantidade de frases reconhecidas pelo sistema e que os
sintagmas identificados estejam corretos, é preciso melhorar o dicionário de dados. Uma análise
comparativa entre a freqüência de palavras encontradas no dicionário e a quantidade de acertos
pode ajudar neste processo.
4.5 Análise do Dicionário de Dados
Para obter os bons resultados pretendidos na interpretação de textos, é necessário um dicionário de dados com grande número de elementos que estejam definidos de forma correta. O
banco de dados utilizado contém aproximadamente:
• 716 mil palavras, sendo que 64 mil estão inseridas em mais de uma classe de palavras;
• 700 palavras básicas, como pronomes, conjunções, artigos, preposições, advérbios etc;
4.5 Análise do Dicionário de Dados
52
• 144 mil adjetivos;
• 231 mil substantivos, sendo que 80 mil são primitivos, sem derivação de gênero, grau
e/ou número. Como a base de dados está incompleta, os substantivos derivados não têm
informação sobre grau, somente concernente a gênero e número.
• 18 mil verbos no infinitivo, sendo que somente 7,6 mil estão conjugados, referentes às
conjugações básicas(-AR, -ER, -IR), totalizando 404 mil verbos conjugados;;
De todas as palavras contidas nos textos utilizados para teste, verificou-se, na média, que
18,94% não estavam presentes no dicionário de dados. A seguir, tem-se gráficos para uma
análise comparativa dos grupo de teste, mostrando a porcentagem de frases de acertadas e de
palavras não encontradas, para cada texto.
Teste na base de dados
Teste na base de dados
80
80
%Nao encontradas
%Acertos
70
60
Porcentagem
Porcentagem
60
50
40
30
50
40
30
20
20
10
10
0
%Nao encontradas
%Acertos
70
Inf6
Inf1
Inf2
Inf5
Inf3
0
Inf4
Formal5 Formal1 Formal6 Formal3 Formal4 Formal2
(a) Informal
(b) Formal
Figura 9: Gráficos de análise do dicionário de dados: Grupos Informal e Formal
Teste na base de dados
Teste na base de dados
80
70
80
%Nao encontradas
%Acertos
60
Porcentagem
Porcentagem
60
50
40
30
50
40
30
20
20
10
10
0
%Nao encontradas
%Acertos
70
Notic8 Notic3 Notic5 Notic4 Notic6 Notic7 Notic1 Notic2
(a) Noticiario
0
Cientif1
Cientif2
Cientif3
(b) Científico
Figura 10: Gráficos de análise do dicionário de dados: Grupos Noticiário e Científico
Cientif4
4.5 Análise do Dicionário de Dados
53
Teste na base de dados
Teste na base de dados
80
80
%Nao encontradas
%Acertos
70
60
Porcentagem
Porcentagem
60
50
40
30
50
40
30
20
20
10
10
0
%Nao encontradas
%Acertos
70
T10 T2
T7
T5
T3 T11 T8
T6
T1
T9
T6
0
Narrat5 Narrat2 Narrat1 Narrat4 Narrat3 Narrat6
(a) Técnico
(b) Narrativa
Figura 11: Gráficos de análise do dicionário de dados: Grupos Técnico e Narrativa
Como o número de dados presente em cada caso é pequeno, pode-se fazer uma estimativa
do comportamento da quantidade de acertos que cada categoria terá em relação à qualidade da
base de dados utilizada.
Na Figura 9(a), vê-se que os bons resultados do grupo de teste Informal são obtidos quando
os textos contêm pequeno número de palavras não encontradas no dicionário. Quando esse
valor aumenta, os resultados tendem a ser piores.
No grupo de teste Formal, visto pela Figura 9(b), os melhores resultados são obtidos com o
aumento do número de palavras desconhecidas presentes nos textos.
Os grupos de textos Noticiário, Figura 10(a), e Científico, Figura 10(b), mostram bons
resultados obtidos quando os textos têm menores e maiores taxas de palavras desconhecidas do
dicionário.
Os gráficos das figuras 11(a) e 11(b), relativos aos grupos Técnico e Narrativa, respectivamente, apresentam melhores resultados quando o dicionário de dados está mais completo.
Pode-se perceber, a partir desses resultados, que a quantidade de palavras do texto que
encontram-se no banco influencia na porcentagem de acertos e também na veracidade destes,
pois palavras não conhecidas podem identificar sintagmas de forma incorreta. Mas não é o
único fator determinante. O processamento do texto para transformá-lo em frase e as regras
gramaticais que o identificador abrange também são de grande importância para obtenção de
bons resultados.
54
5
Conclusões e trabalhos futuros
Este trabalho abordou o problema de interpretar, computacionalmente, informações fornecidas em linguagem natural. O PLN, Processamento de Linguagem Natural, é voltado ao
desenvolvimento de programas para este fim, exigindo, além de estudos em computação, conhecimentos específicos em lingüística. Apresentou-se um sistema que realiza a análise sintática e
a identificação de sintagmas nominais em frases da língua portuguesa, o SIDSN.
Na construção do identificador, foi considerada a Gramática Sintagmática do Português
para a composição de regras gramaticais, e palavras categorizadas segundo classificação morfológica da língua portuguesa para compor o dicionário de dados. Todavia, a implementação do
SIDSN se deu com um subconjunto de regras gramaticais e um dicionário de dados incompleto.
Foram realizados testes no sistema, utilizando um conjunto de textos com características
distintas, como a quantidade de palavras, assunto, gênero e fonte. A identificação de todas as
frases que foram submetidas à análise configura o quadro ideal. Entretanto, considerando a
limitação do sistema referente ao conjunto de regras gramaticais, ao dicionário de dados e à
dificuldade em resolver determinadas questões sintáticas da língua, os resultados obtidos são
considerados satisfatórios.
Dentre as maiores dificuldades encontradas, durante a implementação do Pré-processador
de Textos, destaca-se o tratamento da diferença do uso de vírgulas para a separação de sintagmas
e separação de orações. Além disso, há problemas para identificar fórmulas, uso de cifras
e expressões numéricas de forma correta dentro da oração. Nas regras gramaticais, a questão
dava-se na distinção de casos em que uma conjunção liga termos simples dos casos de separação
de orações.
Relacionado à comunidade científica e acadêmica, há muita pesquisa e trabalhos realizados, principalmente, para o processamento do Inglês. Porém, tem-se carência de pesquisas,
ferramentas e recursos lingüísticos para tratar computacionalmente a Língua Portuguesa.
Melhores resultados em relação aos alcançados neste trabalho podem ser obtidos aperfeiçoando o dicionário de dados e incorporando novos elementos, principalmente, a forma conjugada
5 Conclusões e trabalhos futuros
55
de verbos. Pode-se, também, aumentar o conjunto de regras gramaticais implementadas para
tratar casos como, por exemplo, locuções adjetivas e preposicionais, orações coordenadas e
subordinadas.
O processo de implementação do SIDSN seguiu o critério definido no objetivo: identificar
sintagmas nominais em frases. Portanto, não foi prioridade encontrar uma solução otimizada de
tempo do algoritmo. Porém, de qualquer maneira, foram adotadas medidas para diminuir este
tempo de execução. Como exemplo, tem-se, no gerenciamento do banco de dados, a criação
de índices para os campos mais acessados das tabelas e o uso de comandos para recolher e
armazenar estatísticas sobre o conteúdo das tabelas. Assim, posteriormente, o planejador de
comandos poderá utilizá-las para determinar o plano de execução de consultas de maneira mais
eficiente.
A tabela Tabela 11 exibe um exemplo de tempos de execução do algoritmo para algumas
das instâncias testadas.
Texto
Frases
Inform2
52
Tecnic8
59
Narrat1
77
Tecnic1
310
Inform1
78
Noticia2
63
Cientif1 2910
Narrat4
2291
Formal1 4147
%Acertos Tempo(s)
44,23
12
52,54
13
50,65
28
55,48
32
38,46
48
63,49
166
57,87
222
49,98
501
68,7
682
Tabela 11: Tempos de execução
Os altos valores nos tempos de execução decorrem do alto grau de complexidade dos algoritmos envolvidos. Segundo [Cole et al. 1997], todos os algoritmos, para gramáticas livres
de contexto, (CFG), são relativos, de uma maneira ou de outra, aos conhecidos algoritmos de
Cock, Kasami e Younger, (CKY) e de Earley. A complexidade desses algoritmos, em um pior
caso, é O(n3 ) onde n é o tamanho da sentença. Existe um fator multiplicativo que depende do
tamanho da gramática e é da ordem de O(G2 ), onde G é o tamanho da gramática expresso pela
número de regras.
Como trabalho futuro ao que foi apresentado nesta monografia, pode-se citar o desenvolvimento de um identificador que possibilite a estruturação dinâmica das regras gramaticais, e
considere a classe gramatical dos elementos anteriores e posteriores ao efetuar classificação de
palavras que não estejam presentes no dicionário de dados.
5 Conclusões e trabalhos futuros
56
Pode-se, ainda, trabalhar na busca de soluções mais eficientes com relação ao tempo de
processamento. Além de analisar as vantagens de tratamento de acordo com agrupamento de
textos, tanto nas regras como no pré-processamento, considerando que o desvio padrão dos
resultados obtidos foi menor do que o encontrado com os testes sem agrupamento.
57
Referências
[Chomsky 1956]CHOMSKY, N. Three models for the description of language.
Information Theory, IEEE Transactions on, v. 2, n. 3, 1956. Disponível em:
<http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1056813>. 17
[Cole et al. 1997]COLE, R. A. et al. Survey of the State of the Art in Human Language
Technology. Cambridge: Cambridge University Press / Giardini, 1997. Disponível em:
<citeseer.ist.psu.edu/cole95survey.html>. 55
[Freitas 2005]FREITAS, S. A. A. de. Interpretação automatizada de textos: Processamento de
Anáforas. Tese (Doutorado) — Univerdade Federal do Espírito Santo, 2005. 11, 12
[Júnior 2007]JúNIOR, H. S. Recuperação de informações relevantes em documentos digitais
baseada na resolução de anáforas. Dissertação (Mestrado) — Universidade Federal do Espírito Santo, 2007. 11
[Kuramoto 1996]KURAMOTO, H. Uma abordagem alternativa para o tratamento e a recuperação de informação textual : os sintagmas nominais. Ciência da Informação (Brasília), 1996.
12
[Kuramoto 2002]KURAMOTO, H. Sintagmas nominais: uma nova proposta para a recuperação
de informação. DataGramaZero Revista de Ciência da Informação, v. 3, n. 1, Fevereiro 2002.
Disponível em: <http://www.dgzero.org/fev02/Art_03.htm>. 12
[Louden 2004]LOUDEN, K. C. Compiladores Princípios e Práticas. 1a . ed. [S.l.]: Editora:
Thomson Pioneira, 2004. 16
[Miorelli 2001]MIORELLI, S. T. ED-CER: Extração de Sintagma Nominal em Sentenças em
Português. Dissertação (Mestrado) — Porto Alegre: Faculdade de Informática da PUC-RS,
2001. 12
[Silva 1993]SILVA, I. G. V. K. Maria Cecília Pérez de Souza e. Lingüística aplicada ao português: sintaxe. [S.l.]: Cortez, 1993. 19, 20
[Souza 2005]SOUZA, R. R. Uma proposta de metodologia para escolha automática de descritores utilizando sintagmas nominais. Tese (Doutorado) — Escola de Ciência da Informação
Universidade Federal de Minas Gerais, 2005. 12
[SWI-Prolog]SWI-PROLOG. Documentação do interpretador SWI-Prolog. Disponível em:
<http://www.swi-prolog.org>. 27
[Vieira et al. 2001]VIEIRA, R. et al. Extração de sintagmas nominais para o processamento
de co-referência. Anais do V Encontro para o Processamento Computacional do Português
Escrito e Falado PROPOR Atibaia-SP, Novembro 2001. 12
Referências
58
[Vieira e Lima 2001]VIEIRA, R.; LIMA, V. de. Lingüística computacional: princípios e aplicações. IX Escola de Informática da SBC-Sul, 2001. 14, 18
[Wikipédia]WIKIPéDIA. Definição Processamento de Linguagem Natural. Disponível em:
<http://pt.wikipedia.org/wiki/Processamento_de_linguagem_natural>. 15
[Xavier 1992]XAVIER, M. H. M. M. e M. F. Dicionário de termos lingüísticos. Lisboa: Edições
Cosmos, 1992. Disponível em: <www.ait.pt/recursos/dic_term_ling/index2.htm>. 15