CENTRO UNIVERSITÁRIO DO TRIÂNGULO
INSTITUTO DE CIÊNCIAS EXATAS E TECNOLÓGICAS
CURSO DE CIÊNCIA DA COMPUTAÇÃO
Algoritmos de Casamento de String
Hernane Lemos Rodrigues de Sousa
Uberlândia, Dezembro/2003.
CENTRO UNIVERSITÁRIO DO TRIÂNGULO
INSTITUTO DE CIÊNCIAS EXATAS E TECNOLÓGICAS
CURSO DE CIÊNCIA DA COMPUTAÇÃO
Algoritmos de Casamento de String
Hernane Lemos Rodrigues de Sousa
Monografia apresentada ao Curso de
Ciência da Computação do Centro
Universitário do Triângulo - Unit, como
requisito básico à obtenção do grau de
Bacharel em Ciência da Computação, sob a
orientação do Prof. Jean Claude Richard.
Uberlândia, Dezembro/2003.
Algoritmos de Casamento de String
Hernane Lemos Rodrigues de Sousa
Monografia apresentada ao Curso de Ciência da Computação do Centro
Universitário do Triângulo - Unit, como requisito básico à obtenção do grau de
Bacharel em Ciência da Computação.
Jean Claude Richard, Msc.
(Orientador )
Clarimundo Machado Moraes Júnior , Msc.
(Avaliador)
Marcos Ferreira de Rezende, Msc.
(Avaliador)
Silvia Fernanda M. Brandão , Dsc.
(Coordenadora de Curso)
Uberlândia, Dezembro/2003.
ii
Agradecimentos a
A meus pais e a Deus.
iii
RESUMO
Esta
monografia
pretende
mostrar
a
importância
da
busca
computacional, implementações de novos sistemas e a conscientização dos
programadores, na avaliação dos processos de busca utilizados. Entre as formas e
procedimentos estudadas durante o curso, destacou-se primordialmente a função
de alguns algoritmos, entre os vários existentes. Os escolhidos são: o Força Bruta,
o Knuth-Morris-Prattis e o Boyer Moore. Para uma melhor compreensão destes
algoritmos, esta monografia mostrará o funcionamento com exemplos de cada um
e também como podem ser aplicados nos editores de textos, nos compiladores, na
internet e nos antivírus. O Estudo de Caso com testes práticos medindo os número
de comparações que cada algoritmo executa no seu processo de busca, assim
podendo avaliar com clareza qual destes algoritmos utiliza maior esforço
computacional, posteriormente determina qual deles é mais eficiente e ágil para o
processo de consulta.
iv
SUMÁRIO
1. INTRODUÇÃO ................................................................................................. 1
2. Histórico ............................................................................................................. 2
2.1. Soluções ........................................................................................................... 2
2.1.1. Método Força Bruta................................................................................... 3
2.1.2. Método Knuth, Morris e Pratt ................................................................... 4
2.1.3. Método Boyer e Moore ............................................................................. 7
2.2. Conclusão ...................................................................................................... 11
3. Aplicação dos Algoritmos ............................................................................... 12
3.1. Editor de Texto............................................................................................. 12
3.2. Compiladores................................................................................................ 14
3.3. Evolução da Internet.................................................................................... 16
3.4. Vírus e Antivírus .......................................................................................... 17
3.5. Conclusão ...................................................................................................... 18
4. Busca de Curinga ............................................................................................ 19
4.1. Funcionamento ............................................................................................. 19
4.1.1. ADJ.......................................................................................................... 19
4.1.2. OR ........................................................................................................... 19
4.1.3. AND ........................................................................................................ 20
4.1.4. NOT......................................................................................................... 20
4.1.5. Curinga .................................................................................................... 20
4.2. Algoritmo ...................................................................................................... 20
4.3. Aplicabilidade............................................................................................... 21
4.4. Conclusão ...................................................................................................... 22
5. Estudo de Caso ................................................................................................ 23
5.1. Algoritmo Força Bruta ................................................................................ 23
5.2. Algoritmo Knuth, Morris e Pratt ............................................................... 24
5.3. Algoritmo Boyer e Moore............................................................................ 25
5.4. Análise da Complexidade do Algoritmo Força Bruta .............................. 27
5.5. Análise da Complexidade do Algoritmo Knuth, Morris e Pratt.............. 27
v
5.6. Análise da Complexidade do Algoritmo Boyer e Moore .......................... 28
5.7. Código Fonte do Algoritmo FB linguagem C++........................................ 29
5.8. Código Fonte do Algoritmo KMP linguagem C++ ................................... 29
5.9. Código Fonte do Algoritmo BM linguagem C++ ...................................... 30
5.10. Testes Prático.............................................................................................. 31
5.10.1 Primeiro Teste ....................................................................................... 31
5.10.2 Segundo Teste ....................................................................................... 31
5.10.3 Terceiro Teste........................................................................................ 32
5.10.4 Quarto Teste .......................................................................................... 33
5.10.5 Quinto Teste .......................................................................................... 33
5.10.6 Sexto Teste ............................................................................................ 34
5.10.7 Sétimo Teste .......................................................................................... 34
5.11. Conclusão .................................................................................................... 35
6. Conclusão ......................................................................................................... 36
Referências Bibliográficas .................................................................................. 37
vi
LISTA DE FIGURAS
Figura 3.1 – Localizar Palavras ......................................................................... 13
Figura 3.2 – Localizar e Substituir Palavras .................................................... 13
Figura 3.3 – Verificar Ortografia e Gramática ................................................ 14
Figura 3.4 – Compilador .................................................................................... 14
Figura 3.5 – Funcionamento de Busca Internet ............................................... 16
Figura 3.6 – Antivírus ......................................................................................... 18
Figura 4.1 – Resultado do Teste 1...................................................................... 30
Figura 4.2 – Resultado do Teste 2...................................................................... 31
Figura 4.3 – Resultado do Teste 3...................................................................... 31
Figura 4.4 – Resultado do Teste 4...................................................................... 32
Figura 4.5 – Resultado do Teste 5...................................................................... 33
Figura 4.6 – Resultado do Teste 6...................................................................... 33
Figura 4.7 – Resultado do Teste 7...................................................................... 34
vii
1 - Introdução
Os algoritmos, para leigos, seriam sistemas altamente complexos “os
que realmente são” porém, para estudantes da ciência da computação, os
algoritmos são técnicas de resolução de problemas especiais de suma importância,
na operação de computadores. Eles são utilizados em pesquisas das mais variadas.
O objetivo desta monografia é mostrar de maneira clara e concisa o
funcionamento de três algoritmos que são Força Bruta, Knuht-Morris-Pratt e
Boyer e Moore entre os muitos existentes. Será mostrada a deficiência e a
eficiência entre um e outro.
A monografia é organizada da seguinte forma:
O capítulo 2 mostrará onde e qual foi a maior motivação em
desenvolver algoritmos de casamento de string e quais os tipos de soluções para a
implementação destes algoritmos. Descreve-se neste capítulo os métodos Força
Bruta, Knuht-Morris-Pratt e Boyer e Moore com exemplificações para o melhor
entendimento dos funcionamentos destes métodos.
O capítulo 3 mostrará onde e como podem ser aplicados os algoritmos
de casamento de strings nos editores de textos, compiladores, evolução da internet
e nos vírus e antivírus.
O capítulo 4 apresentará um estudo sobre algoritmo de busca de curinga
e também o seu funcionamento, o desenvolvimento do algoritmo e como são
aplicado este tipo de consulta.
No Estudo de Caso será mostrado o desenvolvimento o custo e a
complexidade dos algoritmos Força Bruta, Knuht-Morris-Pratt e Boyer e Moore
com exemplos práticos medindo a quantidade de comparações. O que se verificará
através de ilustrações gráficas.
1
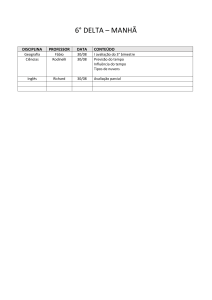
2 – Histórico
O surgimento do teorema de busca na computação ocorreu nas décadas 60
e 70 [3]. A motivação maior em desenvolver teorias pela busca foi forçada pelo
desenvolvimento da biologia computacional. Há algumas décadas cientistas de
vários países desenvolveram pesquisas sobre o DNA e sua influência na formação
de todos os seres vivos de todas as espécies. Fundando o projeto genoma, em
colaboração com laboratórios espalhados em quase todo mundo, inclusive no
Brasil, pretendem detalhar toda seqüência de DNA e registrar a interminável série
de ácidos cuja combinação vai constituir o gene.
Para se ter idéia da enormidade destas pesquisas só o genoma humano
pode ter de 800 a 140 mil genes com 3 bilhões de bases químicas [6].
Coube à ciência da computação oferecer meios para se operar
computadores de alta tecnologia criando programas para consultar, processar e
armazenar esta imensa gama de informações.
2.1 – Soluções
Foram desenvolvidos diversos métodos de algoritmos de casamento de
string para melhorar e agilizar o processo de busca computacional. Estes métodos
buscam encontrar as ocorrências de uma palavra em um texto em todas as
posições do texto em que a palavra ocorre como fator. O texto no caso, é dito ser
dinâmico o que significa que não se conhece nenhuma informação prévia “além
do seu comprimento” que possa ser utilizada na busca. Este é o caso na editoração
em que se deseja fazer busca de palavras em um texto que é constantemente
alterado.
2
2.1.1 - Método Força Bruta
O método mais simples que foi desenvolvido é o algoritmo força
bruta[3][10][11].
O funcionamento do método força bruta é da seguinte forma: possui
duas variáveis auxiliares para a varredura: i para a varredura do texto e o j para a
varredura da palavra.
O sentido da varredura do texto é da esquerda para direita. A variável i
posiciona o primeiro caracter do texto e faz a comparação com o primeiro caracter
da palavra. Se a comparação for igual incrementa se a variável j e calcula-se i+j e
faz-se novamente a comparação. Se o valor da variável j for igual ao tamanho da
palavra isto significa que encontrou a palavra dentro do texto. Se a comparação
dos carateres do texto e o da palavra for diferente incrementa-se a variável i e
posiciona a variável j para o primeiro caracter da palavra. Esta varredura do texto
é feita até o valor da variável i estar menor que valor do tamanho do texto.
Utiliza-se o seguinte exemplo para mostrar o funcionamento do
algoritmo força bruta: no caso o texto = hernane, e a palavra = nan.
Este método é da seguinte forma: Primeiro posiciona o ponteiro i na
primeira posição do texto e o ponteiro j para a primeira posição da palavra e fará a
comparação texto[i] = palavra [j], ou seja, H = N.
Comparação 1:
I = 0
H
E
N
A
J = 0
R
N
N
A
N
E
É falso então incrementa o ponteiro i <- i + 1 e atribui o ponteiro j <- 0
e faz novamente a comparação texto[i] = palavra[j], ou seja, E = N.
Comparação 2 :
I = 1
E
H
N
J = 0
R
A
N
N
A
N
E
Se é falso então incrementa o ponteiro i <- i + 1 e atribui o ponteiro j
<- 0 e faz novamente a comparação texto[i] = palavra[j], ou seja, R = N.
Comparação 3:
3
H
E
I = 2
R
N
J = 0
N
A
A
N
N
E
Se é falso então incrementa o ponteiro i <- i + 1 e atribui o ponteiro j
<- 0 e faz novamente a comparação texto[i] = palavra[j], ou seja, N = N.
Comparação 4:
H
E
R
I=3
N
N
J=0
A
A
N
N
E
Se é verdadeiro então o ponteiro i fica na mesmo posição até que houver
outra falha e atribui o ponteiro j <- j + 1 e faz novamente a comparação texto[i +
j] = palavra[j], ou seja, A = A. Assim por diante até o valor j for igual ao tamanho
da palavra.
Comparação 5:
H
E
R
I = 3
N
N
I+J = 4
A
A
J = 1
I+J = 5
N
N
J = 2
E
Quando houver uma falha ou encontrou a palavra dentro do texto
incrementa o ponteiro i <- i +1 e posiciona o ponteiro j <- 0. Fazendo a varredura
até o ponteiro i for menor ao tamanho do texto.
Comparação 6:
H
E
R
I = 4
A
N
J = 0
N
N
A
E
N
Como pode-se constatar o funcionamento do algoritmo força bruta é simples a
sua aplicação é imediata, por isso, ele se chama força bruta.
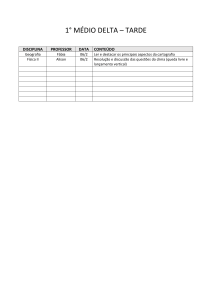
2.1.2 - Método Knuth, Morris e Pratt (KMP)
O método de Knuth, Morris e Pratt (KMP), surgiu em 1970 [3], foi um dos
primeiros algoritmos lineares desenvolvidos para o problema de casamento de
string.
4
O algoritmo KMP acelera a busca em relação ao método força bruta
porque para cada diferença entre caracteres do texto e da palavra, efetua
deslocamentos, quase sempre, de mais de um caractere. O tamanho de cada
deslocamento dependerá da própria palavra.
No algoritmo KMP, após cada divergência, a varredura recomeça na
posição mais favorável da palavra, mantendo-se o texto na mesma posição ou na
seguinte (o ponteiro do texto nunca retrocede).
A reinicialização do ponteiro na palavra depende exclusivamente da
própria palavra, pois depende de que se repita uma subcadeia definida a partir de
sua primeira posição. Isto significa que há uma seqüência de deslocamentos
associados a cada palavra, fazendo corresponder a cada posição da palavra um
deslocamento conveniente.
O método KMP a varredura no texto nunca retrocede para garantir toda as
buscas de uma sub palavra o método KMP possui um vetor de falha. Montado o
vetor falha, fica fácil para o algoritmo para evitar comparações desnecessárias,
pois a cada comparação na qual ocorra a diferença, o algoritmo consulta o vetor
falha para aquela posição de erro e procura o melhor ponto na palavra para fazer
uma nova comparação.
Exemplo, executar a pesquisa com o seguinte texto (aacbcdf) e com a
seguinte palavra (aaabbb). Observa-se a pesquisa houve uma falha com a letra “c”
no texto com a letra “a” da palavra correspondendo a terceira posição, portanto
desta informação dentro da própria palavra em que posição no texto pode se
começar a próxima busca. O vetor falha é construído em cima da informação da
própria palavra.
Neste exemplo mostrará passo a passo como montar o vetor falha e a
varredura no texto utilizando o método KMP. Utilizado o texto = hernane e a
palavra = nan
O vetor falha é construído em cima das informações da própria palavra o
seu tamanho é igual ao tamanho da palavra mais uma posição:
Falha
0
-1
1
2
A primeira posição do vetor falha inicia com o valor –1.
5
3
E possui dois ponteiros para a varredura da palavra i <- 1 e o j <- 0.
J
0
N
Palavra
I
1
A
2
N
E fará comparação com a palavra N = A, é falso então falha[1] <- j.
Falha
0
-1
1
0
2
3
Agora incrementa o ponteiro i <- i +1 e o ponteiro j <- 0.
J
0
N
Palavra
I
2
1
A
N
E fará nova comparação N = N é verdadeiro então falha[2] <- falha [j]
Falha
0
-1
1
0
2
-1
3
Para a última posição do vetor falha é calculado da seguinte forma
falha[3] <- j – 1
Falha
0
-1
1
0
2
-1
3
1
Para a varredura do texto utilizando o método KMP tem que ter as
informações do vetor falha. Ao iniciar a busca os ponteiros i e o j atribui o valor
zero. E fará a comparação texto[i] = palavra[j], ou seja, H = N.
Comparação 1:
I = 0
H
E
N
A
J = 0
Falha
R
N
N
A
0
-1
1
0
N
2
-1
E
3
1
Se for falso então incrementa a variável i <- i +1 e o ponteiro j <falha[j] posteriormente incrementa j <- j + 1. E fará nova comparação texto[i] =
palavra[j], ou seja, E = N.
Comparação 2 :
I = 1
6
E
N
J = 0
H
R
A
N
N
A
0
-1
Falha
1
0
N
E
2
-1
3
1
Se for falso então incrementa a variável i <- i +1 e o ponteiro j <falha[j] posteriormente incrementa j <- j + 1. E fará nova comparação texto[i] =
palavra[j], ou seja, R = N.
Comparação 3:
H
E
I = 2
R
N
J = 0
N
A
A
N
0
-1
Falha
1
0
N
E
2
-1
3
1
Se for falso então incrementa a variável i <- i +1 e o ponteiro j <falha[j] posteriormente incrementa j <- j + 1. E fará nova comparação texto[i] =
palavra[j], ou seja, N = N.
Comparação 4:
H
E
R
Falha
0
-1
I = 3
N
N
J = 0
1
0
I = 4
A
A
J = 1
I = 5
N
N
J = 2
2
-1
E
3
1
Se for verdadeiro então incrementa o ponteiro i<- i +1 e o ponteiro j
<- j + 1 e fazendo a nova comparação. Se o ponteiro j for igual ao tamanho da
palavra representa que encontrou a palavra dentro do texto. Se houver a falha
repete o mesmo procedimento quando houve a falha mostrada neste exemplo.
Esse algoritmo leva o nome de seus autores que são Kunth, Morris e
Prattis.
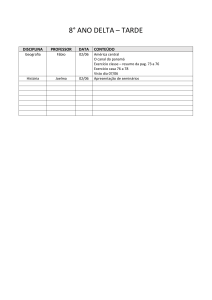
2.1.2 – Método Boyer e Moore
O algoritmo de Boyer-Moore cuja versão inicial foi publicada em 1977
[3], também é uma solução ao problema de casamento de string.
7
O método de busca BM também aproveita da informação contida na
palavra mas difere dos dois anteriores na forma como os caracteres da palavra são
comparados com os caracteres do texto. Em vez de percorrer a palavra no sentido
esquerda -direita a varredura é feita da direita para a esquerda, isto é, do fim para
o começo da palavra. O primeiro caractere da palavra a ser comparado é o último.
O método Boyer Moore tem a característica de poder saltar no texto uma
ou mais posições, assim aliviando o esforço computacional, para dar a informação
quantas posições pode saltar no texto é dados pelo vetor delta_1 e o delta_2.
A construção destes vetores necessita-se somente da informação da
palavra e do alfabeto. Para montar o vetor delta_1 necessita-se de um vetor falha
que será mostrado posteriormente. Precisa de dois ponteiros i <- 1 e j <- 2 para
percorrer a palavra.
Palavra
I
1
A
0
N
J
2
N
O delta_1 inicia todas as suas posições igual a zero.
Delta_1
0
0
1
0
2
0
O vetor falha inicia a sua última posição igual ao tamanho da palavra.
Falha
0
1
2
3
Para a informação do falha[i] <- j e o j <- 2.
Falha
I
1
2
0
2
3
E verifica a palavra[i] = palavra [j], ou seja, A = N
Palavra
I
1
A
0
N
J
2
N
É diferente então verifica se o delta_1 [2] é igual a zero.
Delta_1
0
0
1
0
É verdadeiro então delta_1 [2] <- m – 1 - i
8
2
0
Delta_1
0
0
1
0
2
1
Passa a montar a próxima informação do vetor falha[0] <- j
I
1
2
0
2
Falha
2
3
Vai verificar a palavra[i] = palavra [j], ou seja, N = N
i
0
Palavra
J
2
N
1
A
N
Agora com as informações do vetor falha pronta poderá montar todas as
informações do delta_1. Para isso inicia o ponteiro j <- 2 e o ponteiro i <- 0.
O primeiro passo é verificar se o i = j se for falso então delta_1[0] <m+1-i-1
Delta_1
0
4
1
3
2
1
E o ponteiro i <- 1 e fará comparação i = j é falso então delta_1[1] <m+1-i-1
Delta_1
0
4
1
3
2
1
Agora temos a informação completa do vetor delta_1.
Para montar todas as informações do vetor delta_2 é necessário saber o
tamanho do alfabeto, por exemplo, se o alfabeto for binário 0 ou 1 então o
alfabeto será do tamanho 2 se o alfabeto for letras alfabéticas portuguesa então o
tamanho do alfabeto será 23. Neste exemplo será usado o tamanho do alfabeto
igual a 23. Para montar as informações do delta 2 [i] <- m – 1 – i até o tamanho da
palavra, o restante da informação será montar o valor igual ao tamanho da palavra.
Delta_2
0
2
1
1
2
0
4
3
...
...
23
3
Utiliza-se o seguinte exemplo para mostrar o funcionamento do algoritmo
Boyer Moore. Como ilustração o texto = hernane e a palavra nan.
9
Para fazer a pesquisa no texto o algoritmo BM posiciona mais a esquerda
da palavra, e no texto, se a palavra tiver três caracteres irá posicionar na posição 3
e fará a comparação. Se texto[2] = palavra[2], ou seja, R = N.
Comparação 1:
H
N
I = 2
R
N
J = 2
E
A
N
A
N
E
Se for diferente então o ponteiro i é somado com o comparativo do vetor
delta_1[j] e o vetor delta_2[i]. Se o delta_1[2] é maior que delta_2[2], ou seja, 1
> 0.
Delta_1
Delta_2
0
2
0
4
2
0
1
1
2
1
1
3
4
3
5
3
6
3
N
E
Se for verdadeiro o ponteiro i <- i + delta_1[2].
Comparação 2 :
I = 3
H
E
N
N
R
A
A
N
J = 2
E fará novamente a comparação texto[3] = palavra [2], ou seja, N = N se for
verdadeiro então decrementa i <- 2 o e j <- 1
Comparação 3 :
H
E
I = 2
R
N
N
A
N
A
J = 1
E
N
E fará novamente a comparação texto[2] = palavra [1], ou seja, R = A se
for falso então o ponteiro i é somado com a comparação dos vetores delta_1[j] e o
delta_2[i]. Se delta[1] > delta[2], ou seja 3 > 0.
Delta_1
1
3
0
4
10
2
1
Delta_2
0
2
2
0
1
1
4
3
5
3
6
3
Se for verdadeiro então i <- i + delta[1] e atribui o valor j <- 0. E fará a
comparação texto[i] = palavra[j], ou seja, N = N então decrementa o ponteiro i<- i
–1 e o ponteiro j <- j – 1 assim sucessivamente até o valor do ponteiro j for igual a
zero significando que encontrou a palavra no texto. Quando houver falha repete o
processo de falha mostrado anteriormente.
Comparação 4 :
H
E
R
I = 3
N
N
J = 0
I = 4
A
A
J = 1
I = 5
N
N
J = 2
E
2.2 – Conclusão
Este capítulo definiu a importância em agilizar o processo de consulta.
Com os algoritmos mostrados o método força bruta é menos eficiente
em relação ao KMP, como se verifica em cada exemplo. O método força bruta
executa 6 comparações e o método KMP executa 4 comparações e o método
Boyer Moore executa na busca somente 4 comparações.
O próximo capítulo mostrará um estudo sobre a aplicação e a
importância de cada algoritmo.
11
3 - Aplicações dos Algoritmos
Este capítulo consiste em mostrar a importância dos algoritmos FB,
KMP e BM na ciência da computação. Sem estes algoritmos seriam impossíveis o
trabalho, a flexibilidade e a rapidez que hoje a informática nos oferece. Estes
algoritmos podem ser aplicados nos editores de texto, compiladores, internet e nos
antivírus que serão exemplificados no decorrer do capítulo.
3. 1 - Editor de Texto
O computador idealizado para computar números teve sua função
ampliada pelas tecnologias para o processamento de palavras [3]. Os editores de
textos são programas para elaboração e divulgação de texto, com estrutura de
funcionamento bastante simples. Os editores de textos oferecem a grande
vantagem dos textos poderem ser apagados, corrigidos e reagrupados antes de
serem impressos no papel.
Com a grande gama de informações nos editores de texto ficou difícil a
busca de determinados conteúdos, ocorrendo uma grande perda de tempo em
localizar a palavra desejada. Os algoritmos FB, KMP e BM facilitam os tipos de
consultas, mas vale ressaltar quais destes seriam mais apropriados para serem
utilizados no sistema de busca dos editores o que será exemplificado
posteriormente.
O programa Blocos de Notas, no seu sistema de pesquisa consta como
ilustração a figura 3.1 (Localizar Palavras) que é parte de uma das operações nos
editores de textos.
12
Figura 3.1 – Localizar Palavras
A operação substituir palavras no editor de texto tem o seguinte
funcionamento [8]. Primeiro o usuário vai procurar uma determinada palavra
para substituir. Esta busca é facilitada já que o sistema tem o recurso de buscar
todas as palavras do texto que o usuário desejar trocar como mostra a figura
3.2 – (Localizar e Substituir Palavras).
Figura 3.2 – Localizar e Substituir Palavras
Os editores de texto possuem um banco de dados contendo palavras
corretas e a concordância gramatical. Ao digitar um texto, automaticamente o
editor fará a comparação com o seu banco e mostrará todas as palavras que não
coincidam com sua base de dados. Exemplo figura 3.3 (Verificar Ortografia e
Gramática)
13
Banco de
Dados
Figura 3.3 – Verificar Ortografia e Gramática
3.2 - Compiladores
O meio mais eficaz de comunicação é a linguagem. Na programação de
computadores uma linguagem de programação serve como meio de comunicação
entre o indivíduo que deseja resolver um problema e o computador. Foram
montadas as linguagens simbólicas (Assembly) projetadas para minimizar as
dificuldades da programação binária. O processamento de um programa em
linguagem simbólica requer tradução para linguagem de máquina antes de ser
executada [4].
Programa Fonte
Analise Léxico
Análise Sintática
e Semântica
Tabela Gerência
Código
Intermediário
Tabela de Erro
Otimizar Código
Código Objeto
Figura 3.4 - Compilador
Abaixo detalhes dos dados constantes na Figura 3.4 (Compilador).
14
O Compilador ao receber o programa fonte fará a tradução para a
linguagem de máquina procedendo da seguinte forma: primeiro identificará
seqüências de caracteres que constituem unidades léxicas. O analisador léxico
lerá, caracter a caracter, do texto fonte, verificando se os caracteres lidos
pertencem ao alfabeto da linguagem, identificando os tokens, e desprezando
comentários e brancos desnecessários. Ao sair do analisador léxico passa-se por
uma cadeia de tokens para a fase de análise sintática e semântica numa sub rotina
comandada pelo analisador sintático.
Na fase da análise semântica verifica-se se as estruturas do programa
farão sentido durante a execução, e também a detecção de erros identificando de
forma clara e objetiva a posição e o tipo de erro ocorrido. A fase seguinte
trabalhará para construir o código objeto: geração do código intermediário e
otimização do código.
A geração de código intermediário será utilizada na representação
produzida pelo analisador sintático que gera, na saída, uma seqüência de código.
Esse código pode ser o código objeto final ou constituir-se de um código
intermediário, pois a tradução de código fonte para objeto apresenta algumas
vantagens:
Otimizar o código intermediário para se obter código objeto final mais
eficiente, em termos de velocidade de execução e espaço de memórias. A grande
diferença entre o código intermediário e o código objeto final, é que o
intermediário não especifica detalhes tais como registradores que serão usados e
quais endereços de memória serão utilizados.
A geração código objeto oferece algumas dificuldades ao requerer uma
seleção cuidadosa das instruções e dos registradores da máquina na produção de
código objeto eficiente.
A gerência de tabela difere dos anteriores porém compreende um
conjunto de tabelas e rotinas associadas, que serão utilizadas em quase todas as
fases do tradutor.
O atendimento de erro, por exemplo, o objetivo é analisar erros
detectados em todas as fases do programa fonte. A fase analítica deve prosseguir,
15
ainda que erros tenham sido detectados. Isto poderá ser realizado através de
mecanismo de recuperação de erros, encarregados de re-sincronizar a fase com o
ponto do texto em análise. A perda deste sincronismo fará a análise prosseguir em
erro propagando o defeito.
No compilador os algoritmos FB, KMP e BM seriam utilizados no
programa fonte fazendo análises léxicas, sintáticas e semânticas e nas tabelas de
geração de código intermediário na otimização de código e gerador de código
objeto.
3. 3 - Evolução da Internet
Com o surgimento da Internet integrando os computadores em rede
mundial, foi necessário desenvolver banco de dados textuais para atender a
crescente demanda por informações. Com este objetivo, os especialistas da área SI
(Sistema de Informação) desenvolveram técnicas de modelagem e armazenamento
de dados coerentes [9]. Umas das técnicas muito utilizadas permite estruturar e
organizar os dados em campos (linhas e colunas) relacionais.
Os bancos de dados que utilizam estas técnicas são chamados de banco
de dados relacionais. Este tipo de banco de dados teve enorme crescimento com o
advento da internet, principalmente com o surgimento dos SRIs (sistemas de
recuperação de informação). São operados conforme demonstra a figura 3.5
(Funcionamento de Busca Internet).
Banco de Dados
Figura 3.5 – Funcionamento de Busca Internet
16
Para pesquisa na internet os algoritmos FB, KMP e BM oferecem a
facilidade de recuperação de informação no banco de dados onde estão
armazenados dados em imagem, sons, vídeos e textos.
3.4 - Vírus e Antivírus
O vírus de computador é um programa que pode infectar outro
programa, através da modificação do programa de forma incluir uma cópia de si
mesmo, seria uma analogia com vírus biológico que transforma a célula em uma
fábrica de cópias dele. Os vírus podem atacar qualquer computador, independente
de sua função ou localização, a forma de contaminar o computador pode ser a
partir da internet, por e-mail, através de mídias infectadas ou em qualquer entrada
para o dispositivo. O dano causado por vírus pode variar apenas em buscar
informações sigilosas para o seu desenvolvedor ou absolutamente desastrosos
apagando dados em seu computador [2].
Alguns exemplos quando o seu computador pode estar infectado por
vírus.
Aumento nos tamanhos dos programas.
Lentidão em todos os sistemas e demora na execução dos programas.
Quando o seu computador estiver infectado por vírus a forma de
eliminá-lo seria utilizando antivírus.
Os antivírus são ferramentas para executar varredura de vírus, abrindo
cada um dos arquivos e examinando o código de cada arquivo [2]. Quando
encontrar um código característico de vírus, o antivírus analisa e verifica este
código, e se realmente pertence a um vírus, aciona a mensagem de alerta para o
usuário e limpará este vírus.
Em uma empresa de grande porte há a necessidade de se executar uma
varredura de rede, porém esta varredura pode ser executada somente quando o
tráfego da rede possuir uma pequena quantidade de largura de banda. No entanto,
esta varredura em busca de vírus à noite, apresenta alguns problemas para
empresa, pois a maioria das empresas excutam seus backups de rede à noite. Os
backups de rede ocupam quantidades maciças de largura de banda. Isso
17
prejudicará severamente qualquer tentativa de varredura antivírus. Pode se
utilizar, por exemplo, o programa OfficeScan demonstrado na figura 3.6
(Antivírus).
Banco de Dados
Figura 3.6 - Antivírus
Para a execução de antivírus os algoritmos FB, KMP e BM são
fundamentais na busca de um vírus, mas o importante é verificar qual destes
algoritmos seria o mais viável e eficiente para executar esta varredura. Esta
análise dos algoritmos será mostrada posteriormente.
3.5 - Conclusão
Percebe-se a importância dos algoritmos FB, KMP e BM na pesquisa
no editor de texto, no compilador, na internet e na localização de vírus de
programação.
O próximo capítulo mostrará o desenvolvimento a funcionalidade e a
aplicabilidade de busca de curinga.
18
4 – Busca de Curinga
Este capítulo consiste em mostrar a importância de executar busca
aproximada. É um recurso muito interessante e eficaz que permite localização
mais rápida numa programação construída no sentido de ganho de tempo e
perfeição.
4.1 – Funcionamento
O usuário que queira buscar um ou mais documentos segundo critérios
estabelecidos por uma fórmula booleana, poderá fazê-lo, com os exemplos
demonstrativos apresentados a seguir:
4.1.1 – ADJ
Operador de adjacência ADJ[5], busca registros ou documentos da base
pesquisada que contenham a palavra seguinte ao ADJ, imediatamente após a
palavra que aparece antes do operador, por exemplo, super adj homem, buscará
documentos que contenham as palavras super e homem, juntas e nessa ordem.
4.1.2- OR
Operador de lógica booleana OR[5], busca registros ou documentos da
base pesquisada que contenham uma das duas palavras, juntas ou separadas, em
qualquer ordem e em qualquer trecho do documento, como por exemplo, medicina
or cirurgia, serão buscados todos os documentos que contenham a palavra
medicina ou a palavra cirurgia, juntas ou separadas, em qualquer ordem e em
qualquer trecho.
19
4.1.3 – AND
Operador de lógica booleana AND[5], procura registros ou
documentos que contenha ambas as palavras separadas pelo AND, como por
exemplo, Jean and Claude, buscará documentos em que as palavras Jean e
Claude estiverem presentes, em qualquer ordem.
4.1.4 – NOT
Operador de lógica booleana NÃO[5], pesquisa registros ou
documentos que contenha a palavra anterior ao NOT, mas não a palavra que
vem a seguir, como por exemplo, Marcos not Clarimundo, serão recuperados
documentos que contenha a palavra Marcos e não contenham a palavra
Clarimundo.
4.1.5 – Curinga
Este método consiste na adoção de um curinga que opera com um único
caracter. Assim, uma busca feita com a palavra cas?, relacionará documentos que
contenham palavras como: caso, casa,case etc[5].
Operando curinga com uma seqüência de caracteres. Funciona da
seguinte forma: busca feita com a palavra micro*, relacionará documentos que
contenham palavras como: microcomputador, microscópio, etc. E uma busca
feita com a palavra *logia, relacionará documentos que contenham palavras como:
biologia, antologia. Etc.
O asterisco (*) usado antes do caracter consiste em captar as palavras
iniciais e o asterisco (*) usado após o caracter, captura as palavras posteriores. O
asterisco (*) pode também ser aplicado em meio de caracteres por exemplo: ca*a
tem por objetivo capturar sua complementação assim: casa, cala, cara, etc.
4.2 – Algoritmo
A
implementação do algoritmo na linguagem C++ para executar
busca por curinga será mostrado a seguir.
20
Algoritmo Busca de Curinga [3].
Const int scan = -1;
Int match (char *a)
{
int n1,n2; Deque dq(100);
int j=0, N = strlen(a), state = next1[0];
dq.put(scan);
while (state)
{
if (state == scan)
{
j ++;
dq.put(scan);
}
else
if (ch[state] = = a[j] )
dq.put(next1[state]);
else
if (ch[state] == ‘’)
{
n1 = next1[state]; n2 = next2[state];
dq.push(n1); if (n1 != n2) dq.push(n2);
}
if (dq.empty() || j = = N)
return 0;
state = dq.pop( );
}
return j;
}
4.3 – Aplicabilidade
Algoritmo de busca por curinga, pode ser aplicado em qualquer parte da
computação, como por exemplo, nos editores de texto, na internet e na busca de
arquivos e aplicações que tenham necessidades de busca por aproximação.
4.4 – Conclusão
A busca por aproximação tem uma grande importância na ciência da
computação, como demonstrado nas diversas formas de pesquisa com a utilização
de operadores booleanos.
A implementação do algoritmo busca de curinga não foi abordado um
estudo aprofundado, assim, uma proposta para o desenvolvimento de um trabalho
futuro. Para que possa ser desenvolvida uma implementação mais detalhada desse
21
algoritmo e até mesmo fazer uma adaptação dos algoritmos Força Bruta, KnuthMorris-Pratti e o Boyer Moore para que possa executar busca por aproximação.
O próximo capítulo mostrará o desenvolvimento dos algoritmos FB,
KMP e BM, e um estudo de caso que delineará o mais eficiente.
1.
INTRODUÇÃO
22
5 – Estudo de Caso
Neste capítulo será desenvolvido o algoritmo FM, KMP e BM, a
construção da complexidade de cada algoritmo e também teste prático para obter
resultados mais coerente na comparação de cada algoritmo.
5.1 - Algoritmo Força Bruta
O algoritmo imediato de busca tentará todas as possibilidades e em
cada estágio do texto comparará o perfil de cada abertura ou janela do texto a
partir da posição inicial se a um erro na janela na fase inicial i outra tentativa
fará na que inicia na posição i + 1. A técnica de força bruta comparará com
todos os fatores do texto com a palavra [1][3][11][12]. Para o valor do
tamanho do texto será atribuído a variável n e para o valor do tamanho da
palavra será atribuído a variável m. E o texto será atribuído a variável t e a
palavra será atribuído a variável p.
Algoritmo Força Bruta[13].
função forcabruta (t,n,p,m)
inicio
i <- 0;
j <- 0;
cont <- 0;
repita para (i <- 0;i < n;i <-i+1)
inicio repita para
repita para (j <- 0;(j < m) e (t[i <- i+j] = p[j]);j<-j+1)
se (j = m)
cont <- cont + 1;
fim repita para
fim da função
23
5.2 - Algoritmo Knuth, Morris e Pratt
O primeiro passo do algoritmo KMP é receber o texto e o seu tamanho
com a palavra e o tamanho da palavra a ser pesquisada [1][3][11][12]. Para o
valor do tamanho do texto será atribuído a variável n e para o valor do tamanho da
palavra será atribuído a variável m. E o texto será atribuído a variável t e a palavra
será atribuído a variável p. Exemplo
Algoritmo Knuth-Morris-Pratt[13].
função kmp (t,n,p,m)
Este algoritmo possui algumas variáveis que auxiliam e agilizam a
busca. A primeira variável, a de falha, este vetor é dinâmico e mostra qual a
próxima posição da palavra em que estará para fazer a comparação. Exemplo.
falha <- aloca_memoria (m + 1)
A segunda variável auxiliará na varredura do texto.
i <- 1
j <- 0
E também a variável contador que será responsável em computar
quantas palavras foram encontradas dentro do texto.
cont <- 0
Este laço tem a função de montar o vetor falha responsável por
armazenar informação da palavra a ser procurada no texto e fazer a comparação
do primeiro caracter da palavra com o seu restante.
enquanto i < m faça
inicio enquanto
se p[i] = p[j]
falha [i] <- falha [j]
Senão
falha [i] <- j
enquanto j >=0 e p[i]≠p[j] faça
24
j = falha[j]
i<-i+1
j<-j+1
Fim enquanto
falha[i] <- j - 1;
Este laço tem a função de percorrer o texto e procurar a palavra
desejada e contar quantas vezes foi encontrada no texto.
i <- j <- 0;
enquanto i < n faça
inicio enquanto
enquanto j >= 0 e p[j] ≠ t[i] faca
j <- falha [j]
se j = m – 1
inicio se
cont <- cont + 1;
j <-
falha [m]
fim se
senão
inicio senão
i<-i+1
j<-j+1
fim senão
fim enquanto
5. 3 – Algoritmo Boyer Moore
O primeiro passo do algoritmo BM é receber o texto e o seu tamanho
com a palavra e o tamanho da palavra a ser pesquisada [1][3][11][12]. Para o
valor do tamanho do texto será atribuído a variável n e para o valor do tamanho da
palavra será atribuído a variável m. E o texto será atribuído a variável t e a palavra
será atribuído a variável p. Exemplo:
Algoritmo Boyer Moore[13]
função bm(t,n,p,m)
E possui as seguintes variaveis
25
i, j, cont;
delta_1 = aloca_memoria(tam_palavra);
delta_2 = aloca_memoria(TAM_ALFABETO);
falha_r = aloca_memoria(tam_palavra);
Este laço tem a função de preencher toda a informação delta_1 igual ao
valor do m
Repita para i = 0; i < m;delta_1[i<-i+1] = 0;
Este laço tem a função de montar o vetor delta_1 responsável por
armazenar informação da palavra a ser procurada no texto e fazer a comparação
do primeiro caracter da palavra com o seu restante.
falha_r[m - 1] = m;
i = m - 2;
j = m - 1;
enquanto(i >= 0) faça
inicio enquanto
falha_r[i] <- j;
enquanto((j < m) e (p[i] ≠ p[j])) faça
inicio enquanto
se(!delta_1[j])
delta_1[j] <- m - 1 - i;
j <- falha_r[j];
fim enquanto
i<- i -1;
j<- j - 1;
fim enquanto
Este laço tem a função de preencher todas as informações do vetor
delta_1.
j++;
repita para (i = 0; i < m; i++)
inicio repita para
se(i = j)
j <- falha_r[j - 1] + 1;
se(!delta_1[i])
delta_1[i] <- m + j - i - 1;
fim repita para
Este laço é responsável em montar o vetor delta_2 que auxiliará no
momento da busca e indicará qual a próxima posíção do texto.
Repita para(i <- 0; i < TAM_ALFABETO; delta_2[i<-i+1] <- m)
Repita para(i <- 0; i < tam_palavra; i++)
delta_2[i] = m - 1 - i;
26
Este laço é responsável em fazer a busca no texto e contar quantas vezes
foi encontrada a palavra. E também tornar dinâmica a consulta por causa do
deslocamento fornecidos pelos vetores delta_1 e delta_2.
i = j = m - 1;
enquanto (i < n) faça
inicio enquanto
enquanto((j >= 0) e (t[i] = p[j]))
inicio enquanto
i<- i-1
j<- j-1
fim do enquanto
se(j < 0)
inicio se
cont <- cont +1
i <- i + 1 + delta_1[0]
fim se
senão
inicio senão
i <- i + (delta_1[j] > delta_2[(int) texto[i]] ? delta_1[j]
: delta_2[(int) texto[i]]);
j = tam_palavra - 1;
fim senão
fim enquanto
5.4 – Análise da Complexidade do Algoritmo Força Bruta
Para a análise da complexidade do algoritmo de busca, o valor do
tamanho do texto de assumir igual a variável n e o tamanho da palavra igual a
variável m. Esta análise será medida o custo de cada laço para o algoritmo força
bruta. No primeiro laço o seu custo C1 é igual à n + 1
repita para i = 0; i <= (tam_texto – tam_palavra)
Para o segundo laço do algoritmo o custo C2 é igual à (n – m) *n.
Assim a sua complexidade é definida da seguinte forma:
T(n) = n2 + n – nm + 1
T(n) = θ(nm)
5.5 – Análise da Complexidade do Algoritmo Knuth, Morris e Pratt
Para a análise da complexidade do algoritmo de busca, o valor do
tamanho do texto de assumir igual a variável n e o tamanho da palavra igual a
27
variável m. Nesta análise será medido o custo de cada laço para o algoritmo KMP
o primeiro laço o seu custo C1 é igual à m.
enquanto i < tam_palavra faça
Para calcular o valor da complexidade do segundo laço o valor do C2 é igual a
(m-1) * m.
enquanto j >=0 e palavra [i] != palavra [j] faça
Para calcular o custo do terceiro laço, é definida da seguinte forma C3 é
igual a n + 1.
enquanto i < tam_texto faça
A definição do custo C4 é igual à n * (m + 1).
enquanto j >= 0 e palavra[j] != texto[i] faca
Assim o tempo da complexidade do algoritmo KMP.
T(n) = m2 + nm + 2n + 1
T(n) = m (n + m) + 2n + 1
T(n) = θ(n + m)
5.6 – Análise da Complexidade do Algoritmo Boyer Moore
Para a análise da complexidade do algoritmo de busca, o valor do
tamanho do texto de assumir igual a variável n e o tamanho da palavra igual a
variável m. Nesta análise será medido o custo de cada laço para o algoritmo BM o
primeiro laço o seu custo C1 é igual à m + 1.
Repita para i = 0; i < tam_palavra;delta_1[i++] = 0;
Para o cálculo do custo C2 é igual à m
enquanto(i >= 0) faça
Para o cálculo do custo C3 é igual à m * (m – 1)
enquanto((j < tam_palavra) e (p[i] != p[j])) faça
Para o cálculo do custo C4 é igual à m + 1
repita para (i = 0; i < tam_palavra; i++)
Para o cálculo do custo C5 é igual à m + 1
Repita para(i = 0; i < TAM_ALFABETO; delta_2[i++] = tam_palavra)
28
Para o cálculo do custo C6 é igual à m + 1
Repita para(i = 0; i < tam_palavra; i++)
Para o cálculo do custo C7 é igual à (n + 1 /m)
enquanto (i < tam_texto) faça
Para o cálculo do custo C8 é igual à n/m * m
enquanto((j >= 0) e (texto[i] == palavra[j]))
Agora vamos calcular o tempo da complexidade do Algoritmo BM da
seguinte forma:
T(n) = m2 + 4m +4 + n/m + 1/m + n
T(n) = n/m
T(n) = θ(n/m)
5.7 – Código fonte do algoritmo FB linguagem C++
Código Fonte do algorimto FB [13].
void forcabruta(char *p, int m, char *t, int n) {
int i, j,ocr = 0;
for(i = 0; i <= n; i++) {
for(j = 0; (j < m) && (t[i + j] == p[j]); j++);
f(j == m)
ocr ++;
}
}
I
5.8 – Código fonte do algoritmo KMP linguagem C++
Código Fonte do algorimto KMP [13].
void kmp(char *p, int m, char *t, int n) {
int *falha = (int *) malloc((m + 1) * sizeof(int));
int i, j,ocr = 0;
falha[0] = -1;
i = 1;
j = 0;
while(i < m) {
falha[i] = (p[i] == p[j]) ? falha[j] : j;
while((j >= 0) && (p[i] != p[j]))
j = falha[j];
i++;
j++;
} falha[i] = j - 1;
29
/* Executa a busca. */
i = j = 0;
}
while(i < n) {
while((j >= 0) && (p[j] != t[i]))
j = falha[j];
if(j == (m - 1)) {
ocr++;
j = falha[m];
}
else {
i++;
j++;
}
}
5.9 – Código fonte do algoritmo BM linguagem C++
Código Fonte do algorimto Boyer Moore [13].
void bm(char *p, int m, char *t, int n) {
int
int
int
int
i, j, ocr=0;
*delta_1 = (int *) malloc((m + 1) * sizeof(int));
*delta_2 = (int *) malloc(TAM_ALFABETO * sizeof(int));
*falha_r = (int *) malloc((m + 1) * sizeof(int));
for(i = 0; i < m; delta_1[i++] = 0);
falha_r[m - 1] = m;
i = m - 2;
j = m - 1;
while(i >= 0) {
falha_r[i] = j;
while((j < m) && (p[i] != p[j])) {
if(!delta_1[j])
delta_1[j] = m - 1 - i;
j = falha_r[j];
}
i--;
j--;
}
j++;
for(i = 0; i < m; i++) {
if(i == j)
j = falha_r[j - 1] + 1;
if(!delta_1[i])
delta_1[i] = m + j - i - 1;
}
30
for(i = 0; i < TAM_ALFABETO; delta_2[i++] = m);
for(i = 0; i < m; i++)
delta_2[(int) p[i]] = m - 1 - i;
i = j = m - 1;
while(i < n) {
while((j >= 0) && (t[i] == p[j])) {
i--;
j--;
}
if(j < 0) {
ocr ++;
i = i + 1 + delta_1[0];
}
else
i = i + (delta_1[j] > delta_2[(int) t[i]] ? delta_1[j] :
delta_2[(int) t[i]]);
j = m - 1;
}
free(delta_1);
free(delta_2);
free(falha_r);
5.10 – Testes Prático
Agora será feito vários teste em comparação da prática de cada algoritmo e
com a sua representação gráfica com os resultados obtidos.
5.10.1 – Primeiro Teste
Texto: globo
Palavra: bo
Algoritmo
Comparações
Encontrou
FB
5
1
KMP
4
1
BM
2
1
Representação Gráfica
31
6
FB
4
KMP
2
BM
0
Comparações
figura 4.1 – Resultado do Teste 1
5.10.2 – Segundo Teste
Texto: cienciadacomputção
Palavra: geo
Algoritmo
Comparações
Encontrou
FB
17
0
KMP
17
0
BM
7
0
Representação Gráfica:
20
FB
15
KMP
10
BM
5
0
Comparações
figura 4.2 – Resultado do Teste 2
5.10.3 – Terceiro Teste
Texto: unitcentrouniversitáriodotriângulo
Palavra: triângulo
Algoritmo
Comparações
Encontrou
FB
26
1
KMP
25
1
BM
5
1
32
Representação Gráfica:
30
FB
20
KMP
BM
10
0
Comparações
figura 4.3 – Resultado do Teste 3
5.10.4 – Quarto Teste
Texto: 150 caracteres
Palavra: algoritmo
Algoritmo
Comparações
Encontrou
FB
142
2
KMP
124
2
BM
22
2
Representação Gráfica
150
FB
100
KMP
BM
50
0
Comparções
figura 4.4 – Resultado do Teste 4
5.10.5 – Quinto Teste
33
Texto: 150 caracteres
Palavra: a
Algoritmo
Comparações
Encontrou
FB
150
19
KMP
150
19
BM
150
19
Representação Gráfica:
150
FB
KMP
BM
100
50
0
Comparções
figura 4.5 – Resultado do Teste 5
5.10.6 – Sexto Teste
Texto: 150 caracteres
Palavra: marcos
Algoritmo
Comparações
Encontrou
FB
145
0
KMP
144
0
BM
30
0
Representação Gráfica
34
150
FB
100
KMP
BM
50
0
Comparções
figura 4.6 – Resultado do Teste 6
5.10.7 – Sétimo Teste
Texto: 150 caracteres
Palavra: desenvolviment
Algoritmo
Comparações
Encontrou
FB
137
0
KMP
123
0
BM
12
0
Representação Gráfica:
150
FB
100
KMP
BM
50
0
Comparções
figura 4.7 – Resultado do Teste 7
5.11 – Conclusão
Ficou demonstrado quando a palavra for somente um caracter para a
pesquisa os algorimtos FB, KMP e BM executa o mesmo esforço computacional.
E quando for maior o tamanho da palavra o algoritmo FB retroceder o seu
ponteiro no texto executará um maior esforço computacional em comparação ao
algoritmo KMP e BM. Quando o algoritmo BM soltar uma ou mais posições no
35
texto torna-se mais eficiente em comparação ao algoritmo KMP e FB porque
executa um menor esforço computacional.
36
6 - Conclusão
A busca de uma cadeia de caracteres é um processo presente em quase
todas as áreas da ciência da computação para localizar, substituir ou corrigir um
texto no documento de um editor de texto, para localizar um vírus no software por
um antivírus. Para um programa numa linguagem de alto nível é necessária
aplicação de um processo de busca.
Apesar do aumento crescente da velocidade e desempenho do
processador, é importante aumentar a eficiência da complexidade de um algoritmo
mais precisamente um algoritmo de busca.
Este trabalho mostra com clareza a possibilidade de aumentar a
eficiência de algoritmo através de um estudo comparativo de três algoritmos: FB,
KMP e BM.
Um estudo sobre a busca de curinga foi abordado de forma não
exaustiva fica portanto uma proposta para trabalho futuro, ou seja,
desenvolvimento e a implementação do algoritmo de busca de curinga.
37
Referência Bibliográficas
[1] SALVETTI, DIRCEU DOUGLAS; BARBOSA, LISBETE MADSEN.
Algoritmos. MAKRON books do Brasil do Brasil Editora Ltda.
[2] SELLER, BEST. Manual Completo do Hacker. Book Express 3º Edição
Especial Ampliada.
[3] SEDGEWICK, ROBERT. Algorithm in C++. Addison-Wesley Publishing
Company. Inc, 1992.
[4] PRICE, ANA MARIA DE ALENCAR; TOSCANI, SIMÃO SIRINEO.
Implementação de Linguagens de Programação: Compiladores. Editora Sagra
Luzatto, 2000.
[5] Guimalhães, Reinaldo.Operadores de Busca Textual. Disponível em
http://www.cnpq.br/gpesq3/busca_textual/operador_busca.htm. Acessado em 27
de outubro de 2003.
[6] Filho, Gabriel Manzano. A batalha do Genoma. Disponível em
http://galileu.globo.com/edic/100/tecnologia1b.htm Acessado em 21 de abril de
2003.
38
[7]
Vieira,
Martha
Barcellos.
Editor
de
Texto.
Disponivel
em.
http://www.dein.ucs.br/profs/mbvieira/material_apoio/introinfo219B/consider_wo
rd.html#edittexto. Acessado em 20 de setembro de 2003.
[8] German, Euler; Goyvaerts, Jan. Editar/Localizar e Substituir. Disponível em
http://www.helpscribble.com.br/webhelp/navbar/hs11330.htm. Acessado em 20
de setembro de 2003.
[9] Neubert, Marden S. Recuperação Aproximada de Informação em Textos
Comprimidos
e
Indexados.
Disponível
em
http://www.dcc.ufmg.br/pos/html/spg99/anais/marden/spg.html#glimpse.
Acessado em 20 de setembro de 2003.
[10]
Fundão
Inc.
Algoritmos.
Disponível
em
http://www2.fundao.pro.br/resources/algoritmos/. Acessado em 23 de setembro de
2003.
[11] Pauda, Antônio. Algoritmos de Busca em texto. Disponível em
http://www.buscaemtexto.hpg.ig.com.br. Acessado em 23 de setembro de 2003.
[12] EXACT STRING MATCHING ALGORITHMS. Disponível em http://wwwigm.univ-mlv.fr/~lecroq/string/index.html. Acessado em 26 de setembro de 2003.
[13] Kobayashi, Nami. Autômatos e Algoritmos de Busca de Padrões. Disponível
em http://www.ime.usp.br/~rsouza/pmatching.html. Acessado em 7 de março de
2003.
[14] Zweben, Stuart H.. On Improving the Worst Case Running Time of the
Boyer Moore String Matching Algorithm.Communications of the ACM, Setember
1979.
39