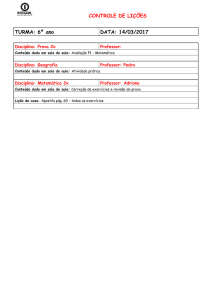
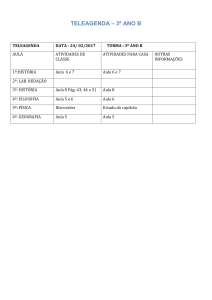
Breast Cancer Wisconsin (Diagnostic) Data Set
Engenharia Biomédica
Programa de Aprendizagem: Mineração de Dados
Professor: Celso Antônio Alves Kaestner
Aluno: Luciano Daniel Amarante
Matricula: 1895753 (externo)
Período: Fase III - 2016
CURITIBA - PR
SETEMBRO de 2016
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
SUMÁRIO
1.
RESUMO
3
2.
INTRODUÇÃO
4
3.
DETALHAMENTO DO EXERCICIO
4
3.1 Diagrama em blocos com uma visão geral do exercício e ser realizado.
4.
DATASETS
4.1 O DBA_LDA DATASET.
4
4
4
5.
RL
6
6.
RL
6
7.
RL
6
8.
RL
8
9.
CONCLUSÃO
10.
REFERÊNCIAS
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
14
15
Pág. 2 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
1.
RESUMO
Os recursos são calculados a partir de uma imagem digitalizada de uma agulha fina
aspirado (FNA) de uma massa de mama [1], de características Nuclear para o diagnóstico de tumor
de mama.
Eles descrevem características dos núcleos celulares presentes na imagem. Algumas das
imagens podem ser encontradas em http://www.cs.wisc.edu/~street/images/ o plano de separação
descrita acima foi obtido usando Multisuperfície Método-Tree (MSM-T) [KP Bennett, da "Árvore
de Decisão Construção Via Programação Linear. "Proceedings of the 4th Midwest Inteligência
Artificial e Cognitive Science Society, pp. 97-101, 1992], um método de classificação que utiliza
programação linear para construir uma árvore de decisão [1].
Características relevantes foram selecionados usando uma busca exaustiva no espaço de
1-4 características e 1-3 planos de separação [1].
O programa linear real usado para obter o plano de separação no espaço de 3-D, é descrito
em: [KP Bennett e OL Mangasarian: "Linear Robusta Programação Discriminação de dois
conjuntos linearmente Inseparáveis ", Métodos de otimização e Software 1, 1992, 23-34]. [1]
Todos os valores de características são recodificados com quatro algarismos
significativos. [1]
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 3 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
2.
INTRODUÇÃO
O exercício é para trabalhar os conceitos de mineração de dados tendo como objetivo
principal é apresentar o processo de descoberta de conhecimento e em especial de mineração de
dados, com a descrição das principais etapas do processo em data mining [2].
3.
DETALHAMENTO DO EXERCICIO
3.1 Diagrama em blocos com uma visão geral do exercício e ser realizado.
O diagrama em bloco deste exercício consiste em demonstrar uma visão
generalizada de cada etapa e seção de mineração de dados em data mining. Estes blocos vão ser
divididos em sub-blocos para melhor entendimento do problema.
Figura 01: Diagrama em blocos com uma visão geral do exercício.
4.
DATASETS
O banco de dados foi disponibilizado pelo professor Celso Antônio Alves Kaestner
[3]. Este banco está postado no link <http://archive.ics.uci.edu/ml/machine-learningdatabases/breast-cancer-wisconsin/breast-cancer-wisconsin.data> e foi acessado em 27/09/2016
pelo aluno Luciano Amarante.
A pós ter realizado uma opção de download dos dados originais, foi feito uma
conversão de dados entre duas bases de dados. Onde a primeira estava na plataforma BREASTCANCER-WISCONSIN.DATA e por conseguinte foi gerada uma nova base de dados na
plataforma Excel com o nome do arquivo DBA_LDA.CSV, com esta conversão pode-se
importado os dados para dentro do ambiente de desenvolvimento IDE R-Studio, com a linguagem
de programação R, onde vamos realizar os primeiros testes necessário.
4.1 O DBA_LDA DATASET.
O conjunto de dados DBA_LDA.csv, foi obtido a partir da Universidade de
Wisconsin Hospitais, Madison do Dr. William H. Wolberg, onde está base de dados se chamava
BREAST-CANCER-WISCONSIN [1]. As amostras foram recebidas periodicamente por Dr.
Wolberg que relata os seus casos clínicos. Por conseguinte, o banco de dados reflete este
agrupamento cronológica dos dados [1]. Esta informação de agrupamento aparece imediatamente
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 4 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
abaixo, tendo sido removido a partir dos próprios dados [1], gerando os grupos de 1 a 8:
1.
Grupo 1: 367 casos (Janeiro de 1989);
2.
Grupo 2: 70 casos (Outubro de 1989);
3.
Grupo 3: 31 casos (Fevereiro de 1990);
4.
Grupo 4: 17 casos (Abril de 1990);
5.
Grupo 5: 48 casos (Agosto de 1990);
6.
Grupo 6: 49 casos (Actualizado em Janeiro de 1991);
7.
Grupo 7: 31 casos (Junho de 1991);
8.
Grupo 8: 86 casos (Novembro de 1991).
Totalizando 699 amostras por pontos (a partir do database doado em 15 de Julho de
1992.), à este médico [1].
Note-se que os resultados resumidos acima têm aplicações anteriores
referem-se a um conjunto de dados de tamanho 369, enquanto que o grupo 1 tem apenas 367 nestes
casos. Isto é porque originalmente continha 369 casos; 2 foram removidos. A seguinte declaração
resume as alterações no conjunto do Grupo 1 original de dados [1]:
Os atributos de Informações são: (atributo de classe que foi movido para a
última coluna) donde temos os atributos de domínio [1].
1.
Amostra número de número de código de ID;
2.
Espessura moita, 1 – 10;
3.
Uniformidade de Cell Size, 1 – 10;
4.
Uniformidade de Forma celular, 1 – 10;
5.
Adesão Marginal, 1 – 10;
6.
Único células epiteliais Tamanho, 1 – 10;
7.
Nua Núcleos, 1 – 10;
8.
Bland cromatina, 1 – 10;
9.
Normal nucléolos, 1 – 10;
10.
Mitoses, 1 – 10;
11.
Classe: (2 para benigna, 4 para maligna).
Em seguida foi gerado uma tabela com os Atributos e Instancias com demonstra abaixo
com tabela 01.
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 5 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
Tabela 01: Onde temos os Atributos e Domain.
5.
IMPORTAR E EXPORTAR DADOS NA PLATAFORMA R
Agora que temos os dados normalizado no formato desejado *.CSV vamos importar
estes dados a partir da importação/exportação de dados para arquivos *.CSV [2], com o uso das
funcionalidades de mineração de dados em R, internas do ambiente de desenvolvimento.
Para utilizar os comandos descrito no R and Data Mining, deve-se realizar um conjunto
de operação. Os dados em R podem ser salvos como os arquivos .rdata com a função save ( ) e
arquivos .rdata pode ser recarregado na R com load ( ).
Porém vamos utilizar a função read.csv ( ), para ler os dados com sua devida sintaxe e
armazenar dentro de uma variável local:
DADOS01 = read.csv (file = "C:\\Users\\luciano_desk\\OneDrive\\Mestrado\\2017\\Mineração de
Dados\\Exercicio01\\Exe01_luciano_amarante\\data\\DBA_LDA.csv"),
assim pode-se armazenar os dados
dentro do objeto local DADO01.
Com os dados devidamente carregados no objeto local DADOS01, pode-se agora
começar a manipular de acordo com a necessidade e especificações.
6.
DATA MINING
A mineração de dados é o processo de descobrir conhecimentos interessantes de
grandes quantidades de dados, que estão escondidos nos dados. É um campo interdisciplinar, com
contribuições de muitas áreas, tais como estatísticas, aprendizado de máquina, recuperação de
informação, reconhecimento de padrões e bioinformática [2]. As principais técnicas para a
mineração de dados incluem classificação e previsão, clustering, outlier detecção, regras de
associação, análise de sequência, análise de séries temporais e de mineração de texto, e também
algumas novas técnicas, como análise de rede social e análise de sentimento [2].
Em aplicações do mundo real, um processo de mineração de dados pode ser dividido
em seis fases principais: entendimento do negócio, a compreensão de dados, preparação de dados,
modelagem, avaliação e implementação, conforme definido pelo CRISP-DM (Standard Industry
Cruz Processo de Data Mining) [2].
7.
INTRODUÇÂO AO AMBIENTE RSTUDIO
É sempre uma boa prática para começar a programar R com um projeto RStudio, cria
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 6 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
uma pasta onde vamos colocar seu código fonte R, e os arquivos de dados e números gerados. Para
criar um novo projeto, clique no botão “Project” no canto superior direito e escolha “New
Project”. Depois disso, selecione “create project from new directory” em seguida selecione
“Empty Project”. Logo em segui digitar um nome de diretório onde, que será também o seu nome
do projeto, clique em “Create Project” para criar a pasta e os arquivos de projeto [2].
Se você abrir um projeto já existente, o RStudio definirá automaticamente o diretório
de trabalho para o diretório do projeto, que é muito conveniente [2].
Depois disso, criar três pastas como a seguir [2]:
i.
Code, (código, onde colocar o seu código souce R);
ii.
Data, (dados, onde colocar seus conjuntos de dados);
iii.
Figures, (figuras, onde colocar diagramas produzidos).
Além de três pastas acima criada na maioria dos projetos, você pode criar pastas
adicionais abaixo [2]:
iv.
Rawdata, (dados brutos, onde colocar todos os dados brutos);
v.
Models, (modelos, onde colocar todos os modelos de análise
produzidos);
vi.
Reports, (relatórios, onde colocar os seus relatórios de análise).
Abaixo temos uma olhada na estrutura do conjunto de dados com str ( ). Note que
todos os nomes de variáveis, nomes de pacotes e nomes de função em R diferenciam maiúsculas
de minúsculas.
Vamos executar o comando str ( ), para vermos os resultados de nossa base de dados.
> str(DADOS01)
'data.frame':
699 obs. of 1 variable:
$
ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucleoli.Mitoses.Class:
Factor w/ 691 levels "1000025;5;1;1;1;2;1;3;1;1;2",..: 1 4 5 6 8 10 11 12 16 17 ...
A partir do resultado, podemos ver que há 699 observações (registros, ou linhas) e 1
variável (ou colunas) no conjunto de dados.
O ambiente R também fornece a função save.image ( ), para guardar tudo na área de
trabalho atual em um único arquivo, o que é muito conveniente para salvar seu trabalho atual e
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 7 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
retomá-la mais tarde, se os dados carregados em R não são muito grandes [2].
8.
EXPLORAÇÃO DE DADOS E VISUALIZAÇÃO
A partir de agora vamos mostra exemplos de exploração de dados com R. Começa com
inspecionar a dimensionalidade, a estrutura e os dados de um objeto R, seguido de estatísticas
básicas e vários gráficos como gráficos de pizza e histogramas [2].
Assim pode-se realizar exploração de múltiplas variáveis, incluindo a distribuição,
boxplots agrupadas, lote dispersos e pares trama (including grouped distribution, grouped
boxplots, scattered plot and pairs plot) [2].
Depois disso, os exemplos são apresentados em terreno plano, traçado de contorno e
enredo 3D. Ele também mostra como salvar gráficos em arquivos de vários formatos como PDF e
mais.
8.1 Analisando os dados.
Os dados do banco de dados DADOS01 é usado neste trabalho, para
demonstração de exploração de dados na plataforma com R.
Primeiro vamos verificar o tamanho da estrutura dos dados. No código
abaixo, a função dim ( ), retorna a dimensionalidade dos dados, o que mostra que há 699
observações (ou linhas ou registros) e 1 variável (ou colunas).
> dim(DADOS01)
[1] 699 1
> names(DADOS01)
[1] "ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucleoli.Mitoses.Class"
> attributes(DADOS01)
$names
[1]
"ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucleoli.Mitoses.Cl
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 8 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
ass"
$class
[1] "data.frame"
$row.names
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
[22] 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
[43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
[64] 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84
[85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105
[106] 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126
[127] 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147
[148] 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168
[169] 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189
[190] 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210
[211] 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231
[232] 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252
[253] 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273
[274] 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294
[295] 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315
[316] 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336
[337] 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357
[358] 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378
[379] 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399
[400] 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 9 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
[421] 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441
[442] 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462
[463] 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483
[484] 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504
[505] 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525
[526] 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546
[547] 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567
[568] 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588
[589] 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609
[610] 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630
[631] 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651
[652] 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672
[673] 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693
[694] 694 695 696 697 698 699
Em seguida, vamos ter um olhar para as cinco primeiras linhas de dados.
> DADOS01[1:5, ]
[1] 1000025;5;1;1;1;2;1;3;1;1;2 1002945;5;4;4;5;7;10;3;2;1;2 1015425;3;1;1;1;2;2;3;1;1;2
[4] 1016277;6;8;8;1;3;4;3;7;1;2 1017023;4;1;1;3;2;1;3;1;1;2
691 Levels: 1000025;5;1;1;1;2;1;3;1;1;2 ... 95719;6;10;10;10;8;10;7;10;7;4
A primeira ou última linhas de dados podem ser recuperados com a função
head( ) ou tail( ), que por padrão retornar as primeiras 6 últimas linhas. Alternativamente, podemos
obter um determinado número de linhas, definindo o segundo parâmetro para ambas as funções.
Por exemplo, as primeiras 10 linhas serão devolvidas com head(10), do objeto DADO01.
> head(DADOS01)
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 10 de 15
1
2
3
4
5
6
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucleoli.Mitoses.Class
1000025;5;1;1;1;2;1;3;1;1;2
1002945;5;4;4;5;7;10;3;2;1;2
1015425;3;1;1;1;2;2;3;1;1;2
1016277;6;8;8;1;3;4;3;7;1;2
1017023;4;1;1;3;2;1;3;1;1;2
1017122;8;10;10;8;7;10;9;7;1;4
> tail(DADOS01)
ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucleoli.Mitoses.Class
694
763235;3;1;1;1;2;1;2;1;2;2
695
776715;3;1;1;1;3;2;1;1;1;2
696
841769;2;1;1;1;2;1;1;1;1;2
697
888820;5;10;10;3;7;3;8;10;2;4
698
897471;4;8;6;4;3;4;10;6;1;4
699
897471;4;8;8;5;4;5;10;4;1;4
Uma amostra aleatória de os dados com 5 podem ser recuperados com a
sample( ) no código abaixo.
> ## draw a sample of 5 rows
> idx <- sample(1:nrow(DADOS01), 5)
> idx
[1] 38 491 523 533 96
> DADOS01[idx, ]
[1] 1081791;6;2;1;1;1;1;7;1;1;2 1115293;1;1;1;1;2;1;1;1;1;2 412300;10;4;5;4;3;5;7;3;1;4
[4] 869828;1;1;1;1;1;1;3;1;1;2 1164066;1;1;1;1;2;1;3;1;1;2
691 Levels: 1000025;5;1;1;1;2;1;3;1;1;2 ... 95719;6;10;10;10;8;10;7;10;7;4
Nós também podemos recuperar os valores de uma única coluna. Por
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 11 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
exemplo, o 10 primeiro valor de ID pode ser obtido de três maneiras diferentes abaixo.
> DADOS01[1:10, “ID”]
[1] 1000025;5;1;1;1;2;1;3;1;1;2 1002945;5;4;4;5;7;10;3;2;1;2
[3] 1015425;3;1;1;1;2;2;3;1;1;2 1016277;6;8;8;1;3;4;3;7;1;2
[5] 1017023;4;1;1;3;2;1;3;1;1;2 1017122;8;10;10;8;7;10;9;7;1;4
[7] 1018099;1;1;1;1;2;10;3;1;1;2 1018561;2;1;2;1;2;1;3;1;1;2
[9] 1033078;2;1;1;1;2;1;1;1;5;2 1033078;4;2;1;1;2;1;2;1;1;2
691 Levels: 1000025;5;1;1;1;2;1;3;1;1;2 ... 95719;6;10;10;10;8;10;7;10;7;4
> DADOS01[1:10, 1]
[1] 1000025;5;1;1;1;2;1;3;1;1;2 1002945;5;4;4;5;7;10;3;2;1;2
[3] 1015425;3;1;1;1;2;2;3;1;1;2 1016277;6;8;8;1;3;4;3;7;1;2
[5] 1017023;4;1;1;3;2;1;3;1;1;2 1017122;8;10;10;8;7;10;9;7;1;4
[7] 1018099;1;1;1;1;2;10;3;1;1;2 1018561;2;1;2;1;2;1;3;1;1;2
[9] 1033078;2;1;1;1;2;1;1;1;5;2 1033078;4;2;1;1;2;1;2;1;1;2
691 Levels: 1000025;5;1;1;1;2;1;3;1;1;2 ... 95719;6;10;10;10;8;10;7;10;7;4
>DADOS01$ID.Thrickness.CellSize.CellShape.Adhesion.SECS.BareNuclei.BChomatin.Nnucle
oli.Mitoses.Class[1:10]
[1] 1000025;5;1;1;1;2;1;3;1;1;2
1002945;5;4;4;5;7;10;3;2;1;2
[3] 1015425;3;1;1;1;2;2;3;1;1;2
1016277;6;8;8;1;3;4;3;7;1;2
[5] 1017023;4;1;1;3;2;1;3;1;1;2
1017122;8;10;10;8;7;10;9;7;1;4
[7] 1018099;1;1;1;1;2;10;3;1;1;2 1018561;2;1;2;1;2;1;3;1;1;2
[9] 1033078;2;1;1;1;2;1;1;1;5;2
1033078;4;2;1;1;2;1;2;1;1;2
691 Levels: 1000025;5;1;1;1;2;1;3;1;1;2 ... 95719;6;10;10;10;8;10;7;10;7;4
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 12 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
9.
EXPLORAR VARIÁVEIS INDIVIDUAIS
Distribuição de cada variável numérica pode ser verificado com resumo a
função summary ( ), que retorna o Mínimo, Máximo, Média, Mediana, e os primeira quartis ou
seja (25%) e o terceiro quartis ou seja (75%) dos 100% de dados.
....
......
..........
........
...........
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 13 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
10.
CONCLUSÃO
Embarcado
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 14 de 15
R and Data Mining: Examples and Case Studies
Versão:
2.0
Tipo: Exercicio de Fixação
Data:
27/09/2016
11.
REFERÊNCIAS
1.
Irvine Machine Learning Repository. Diagnostic Wisconsin Breast Cancer Database. Disponivel em:
<http://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29>. Acessado em:
27/09/2016.
2.
R and Data Mining: Examples and Case Studies. RDataMining.com: R and Data Mining. Disponivel
em: < http://www.rdatamining.com/docs/r-and-data-mining-examples-and-case-studies >. Acessado em:
27/09/2016.
3.
Kaestner, C. A. A.; Lopes, H. S. MINERAÇÃO DE DADOS. Disponivel em:
<http://www.dainf.ct.utfpr.edu.br/~kaestner/Mineracao/Mineracao_de_Dados_PPGCA_2016-3.htm>.
Acessado em: 27/09/2016.
Programa de Pós-Graduação em Computação Aplicada (PPGCA) 2017.
Pág. 15 de 15