Sistema especialista para extrair conteúdo de log de conversas pela
Internet
Carlos Henrique P. C. Chaves, Antonio Montes e José Demisio Simões da Silva
Instituto Nacional de Pesquisas Espaciais – INPE
Laboratório Associado de Computação e Matemática Aplicada
Av. dos Astronautas, 1758 – 12227-010 – São José dos Campos, SP.
E-mail: {cae,montes,demisio}@lac.inpe.br
Resumo
Este artigo descreve o desenvolvimento de um sistema especialista, chamado IRCTAES - IRC Traffic
Analyser Expert System, que classifica as mensagens
referentes a diálogos entre usuários e descarta as outras. O objetivo disto é separar as informações relevantes em um tráfego de IRC, como a conversa entre
hackers ou script kids e comandos que possam ser passados a ferramentas utilizando-se mensagens do IRC.
Palavras-chave: sistema especialista, IRC
1
Introdução
Os hackers e script kids utilizam um protocolo para
conversar e também para disparar ataques de negação
de serviço distribuídos através da Internet. Este protocolo é o IRC - Internet Relay Chat.
O IRC possui vários tipos de mensagens, como
controle e pesquisa. Assim, em um arquivo de log contendo o tráfego do protocolo, existem, além das mensagens que contém o diálogos entre os usuário, várias
outras mensagens utilizadas pelos servidores. Sendo
assim, surge a motivação para desenvolver um sistema
especialista que classifique cada mensagem do protocolo IRC, separando as mensagens que possuem apenas diálogo entre pessoas das outras mensagens.
Para o desenvolvimento do sistema especialista, serão estudados os conceitos de sistema especialista e
encadeamento para frente. Além disso, será escolhida a forma de implementar o sistema: utilizando uma
linguagem de programação lógica (PROLOG) ou uma
linguagem imperativa (C).
Este artigo descreve brevemente o protocolo IRC,
apresenta conceitos de sistemas especialistas, encadeamento para frente e mostra a implementação de um
sistema especialista para análise de conversas pela Internet - IRCTAES.
2
Protocolo Internet Relay Chat
O protocolo IRC (Internet Relay Chat) foi projetado para ser usado por conferências textuais. Ele é
um sistema de teleconferência que (através do uso do
paradigma cliente-servidor) é bem adaptado para ser
executado em várias máquinas, de maneira distribuída.
Uma arquitetura simples envolve um único processo
(servidor) que se constitui em um ponto central para que os clientes (ou outros servidores) se conectem,
executando a entrega/multiplexação de mensagens e
outras funções [5].
2.1
Servidores
Os servidores formam o backbone do IRC, provendo um ponto onde os clientes possam se conectar para conversar uns com os outros, e um ponto onde outros servidores possam se conectar, formando uma rede IRC [5].
2.2
Clientes
Um cliente é qualquer coisa conectada a um servidor que não seja outro servidor. Cada cliente é diferenciado dos outros por um apelido único que possui
um tamanho máximo de nove caracteres. Em adição
ao apelido, todos os servidores devem possuir as seguintes informações sobre todos os clientes: o nome
real do host onde o cliente está rodando, o username
do cliente naquele host, e o servidor no qual o cliente
está conectado.
Uma classe especial de clientes (operadores) tem
permissão de executar funções de manutenção gerais
na rede. Além disso, os operadores devem estar aptos
a executar tarefas básicas como desconectar e conectar
servidores, e fechar a conexão entre qualquer cliente e
seu servidor [5].
2.3 Canais
Um canal é um grupo de um ou mais clientes, onde todos receberão todas as mensagens enviadas a este
canal. O canal é criado implicitamente quando o primeiro cliente se junta a ele, e deixa de existir quando o último cliente o deixa. Enquanto o canal existir,
qualquer cliente pode referenciar o canal usando o seu
nome.
O operador de canal (também conhecido como
“chop” ou “chanop”) é considerado dono do canal.
Assim, ele possui certos poderes que o permitem manter o controle do canal. Ele é identificado pelo símbolo
@ ao lado do apelido [5].
2.4
2.4.1
Protocolo do IRC
Códigos de caracteres
Nenhum conjunto específico de caracteres é especificado. O protocolo é baseado em um conjunto de códigos compostos de oito bits, formando um octeto. Cada
mensagem pode ser composta por vários octetos; entretanto, alguns octetos são usados como códigos de
controle que agem como delimitadores de mensagens
[5].
2.4.2
Mensagens
Servidores e clientes enviam uns aos outros mensagens que podem ou não gerar uma resposta. Se a mensagem contém um comando válido, o cliente deve esperar uma resposta, porém não deve esperar para sempre; a comunicação cliente para servidor e servidor para cliente é essencialmente assíncrona.
Cada mensagem do IRC deve consistir de três partes principais: o prefixo (opcional), o comando e os
parâmetros do comando (que podem ser até 15). O
prefixo, o comando e todos os parâmetros são separados por um ou mais caracteres de espaço ASCII
(0x20). A presença de um prefixo é indicada com um
caractere de “dois pontos” precedente (:, 0x3b), que
deve ser o primeiro caractere da mensagem. Não devem existir espaços em branco entre os “dois pontos”
e o prefixo. O prefixo é usado pelos servidores para
indicar a origem verdadeira da mensagem. Se o prefixo estiver faltando na mensagem, a sua origem é assumida pelo outro lado da conexão de que ela veio.
Os clientes não devem usar prefixos quando estiverem
enviando mensagens deles; se eles usarem um prefixo,
o único prefixo válido é o apelido associado ao cliente. Se a fonte identificada pelo prefixo não puder
ser encontrada no banco de dados do servidor, ou se
a fonte for registrada a outro link, diferente do que a
mensagem veio, o servidor deve ignorar a mensagem
silenciosamente.
O comando deve ser um comando IRC válido ou
um número de três dígitos representado em ASCII. As
mensagens do IRC são linhas de caracteres terminadas
com um par CRLF (Carriage Return - Line Feed), e
essas mensagens não devem exceder 512 caracteres,
contando todos os caracteres incluindo o par CRLF.
Assim, existe um tamanho de 510 caracteres para o
comando e seus parâmetros.
As mensagens do protocolo devem ser extraídas do
fluxo de octetos. A solução corrente é designar dois
caracteres, CR (0xd) e LF (0xa), como separadores das
mensagens. As mensagens vazias são ignoradas, o que
permite o uso da seqüência CRLF entre as mensagens
sem problema.
A mensagem extraída é analisada nos componentes
<prefixo>, <comando> e lista de parâmetros que casam com os componentes <meio> ou <complemento>
[5].
A representação da mensagem, segundo Oikarinen
e Reed, é da seguinte forma:
<mensagem> ::= [ ´:´<prefixo><ESPAÇO> ] <comando> <parâmetros> <crlf>
<prefixo> ::= <servidor> | <apelido> [ ´!´ <usuário> ]
[ ´@´ <host> ]
<comando> ::= <letra> { <letra> } | <número> <número> <número>
<ESPAÇO> ::= ´ ´ { ´ ´ }
<parâmetros> ::= <ESPAÇO> [ ´:´ <complemento> |
<meio> <parâmetros> ]
<meio> ::= <qualquer seqüência não vazia de octetos
não incluindo ESPAÇO ou NULO ou CR ou LF, e o
primeiro caractere não pode ser ´:´>
<complemento> ::= <qualquer seqüência possivelmente vazia de octetos não incluindo NULO ou CR
ou LF>
<crlf> ::= CR LF
2.5
Tipos de mensagem
O protocolo IRC possui vários tipos de mensagens
que constituem o arcabouço para as conversas entre os
usuários. Nesse artigo serão tratados apenas três tipos
de mensagens, que interessam diretamente ao seu objetivo. As outras mensagens são descartadas pelo sistema especialista, que classifica quais mensagens são
ou não importantes para o seu propósito. Para mais
informações sobre os outros tipos de mensagens, consultar a RFC [5].
2.5.1
Mensagem privada
Comando: PRIVMSG
Parâmetro: <destinatário> { <destinatário> }
<mensagem>
O comando PRIVMSG é utilizado para enviar uma
mensagem privada entre usuários. <destinatário> representa o apelido do usuário a quem se deseja enviar
a mensagem, porém pode ser uma lista de nomes ou
canais separados por vírgula.
2.5.2
Mensagem de notificação
Comando: NOTICE
Parâmetro: <apelido> <mensagem>
A mensagem de notificação é usada similarmente a
mensagem privada. A diferença está no fato que respostas automáticas nunca devem ser enviadas quando
um usuário receber uma mensagem de notificação.
3
Sistema Especialista
Os sistemas especialistas são sistemas baseados em
regras de produção cujo objetivo é reproduzir o comportamento de especialistas humanos na resolução de
problemas do mundo real, mas o domínio destes problemas é altamente restrito. Eles são desenvolvidos
para resolver problemas em muitos domínios diferentes, incluindo: agricultura, química, sistemas de computadores, eletrônica, engenharia, geologia, gerenciamento de informações, direito, matemática, medicina, aplicações militares, física, controle de processos
e tecnologia espacial.
A memória de trabalho pode conter qualquer tipo
de estrutura de dados. Porém, elas devem respeitar um
método de representação do conhecimento, isto é, uma
linguagem formal e uma descrição matemática do seu
significado.
A base de regras passa a conter condições que representam “perguntas” à representação do conhecimento da memória de trabalho. Estas perguntas podem ser de diferentes tipos, mas em geral envolvem
variáveis a serem instanciadas e eventualmente algum
tipo de inferência. A sintaxe das regras varia de acordo com o sistema, pode ser bastante flexível e próxima
da linguagem natural ou bastante formal.
O motor de inferência controla a atividade do sistema. Esta atividade ocorre em ciclos, cada ciclo consistindo em três fases:
1. Correspondência de dados, onde as regras que satisfazem a descrição da situação atual são selecionadas.
2. Resolução de conflitos, onde as regras que serão
realmente executadas são escolhidas dentre as regras que foram selecionadas na primeira fase, e
ordenadas.
3. Ação, a execução propriamente dita das regras.
A chave para o desempenho de um sistema especialista está no conhecimento armazenado em suas regras e em sua memória de trabalho. Este conhecimento deve ser obtido junto a um especialista humano do
domínio e representado de acordo com regras formais
definidas para codificação do sistema em questão [1].
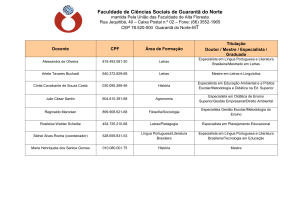
3.1
Figura 1. Arquitetura de um Sistema Especialista.
Fonte: [1]
Um sistema especialista, conforme mostrado na Figura 1, apresenta uma arquitetura com três módulos:
uma base de regras, uma memória de trabalho e um
motor de inferência. A base de regras e a memória de
trabalho formam a chamada base de conhecimento do
sistema especialista, onde está representado o conhecimento sobre o domínio. O motor de inferência é o
mecanismo de controle do sistema que avalia e aplica
as regras de acordo com as informações da memória
de trabalho.
Encadeamento para frente
Os sistemas especialistas provêm estratégias e mecanismos para processar fatos de acordo com o estado de um determinado ambiente, e derivar inferências
lógicas a partir dos primeiros. Este processo de avaliação de fatos levando a afirmação de um novo fato
ou conclusão é chamado de encadeamento para frente. Um sistema de encadeamento para frente baseado
em regras é movido pelos dados: cada fato afirmado
deve satisfazer as condições nas quais novos fatos ou
conclusões são derivados. Neste sistema, pode-se estabelecer uma cadeia ou conjunto de regras, onde uma
série de fatos afirmados pode levá-lo a deduzir uma
conclusão [4].
3.1.1
Componentes de sistemas de encadeamento
para frente
A estratégia por trás de um sistema de encadeamento
para frente envolve a avaliação de cada fato apresentado ao sistema em expressões condicionais que, quando
satisfeitas, derivam a novos fatos e conclusões. Neste contexto, um fato é uma instrução afirmada no sistema cuja validade é aceita (por exemplo, “existe fumaça”). Os fatos são freqüentemente implementados
como atributos e valores que representam um estado
do ambiente no qual o sistema especialista é aplicado.
Uma regra é uma fórmula de inferência na forma φ1 ,
φ2 , ..., φn deduz ψ. Ela pode ser expressa como uma
regra de produção, como IF ... THEN ... simbolos
originais
Regras de produção são os elementos básicos com
os quais um sistema especialista é programado para
interpretar e descobrir significados a partir de sinais
recebidos do ambiente, como em
IF existe fumaça THEN o fogo está perto.
Uma regra de produção consiste em duas partes: o
antecedente (lado esquerdo da regra) e o conseqüente
(lado direito da regra), como mostrado na Figura 2.
Quando as condições no antecedente são satisfeitas, a
regra é ativada. O componente lógico com o qual o
sistema especialista avalia um fato contra a regra de
produção é chamado de motor de inferência.
res e operadores de canal. As mensagens que referem
à conversa propriamente dita são do tipo citado na Seção 2.5. A partir daí, surgiu a motivação para criar um
sistema especialista - IRCTAES (IRC Traffic Analyser
Expert System) - que analisasse as mensagens contidas
em um log de IRC, e classificasse quais mensagens interessam para o propósito descrito acima.
4.1
Um log de tráfego de rede, criado com o auxílio
de uma ferramenta de captura de tráfego (tcpdump1 ),
deve possuir todos os pacotes que passaram na rede
no ponto onde a ferramenta estava monitorando. Um
log de IRC deve possuir todos os pacotes, referentes a
este protocolo, que trafegaram pela rede. Os logs utilizados no desenvolvimento e teste do IRCTAES foram
cedidos gentilmente pela equipe Honeynet.BR2 .
Uma vez que os logs disponíveis estavam em formato tcpdump, foi necessário desenvolver um programa, na linguagem C, que retirasse as mensagens dos
pacotes contidos no log. Chaves desenvolveu uma
ferramenta que analisa o tráfego de pacotes da pilha
TCP/IP [2]. Assim, o código desta foi aproveitado,
retirando-se o que era desnecessário e adicionando
uma rotina para obter as mensagens do IRC dos pacotes TCP.
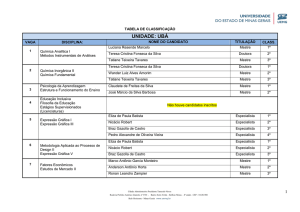
4.2
Figura 2. Estrutura das regras de produçªo.
Fonte: [4]
A coleção de fatos disponíveis ao sistema é chamada base de fatos (factbase) ou memória de trabalho. A
coleção de regras é chamada de base de conhecimento
ou memória de produção [4].
4
IRCTAES
O IRC é o protocolo de conversas pela Internet mais
utilizado pelos hackers e script-kids. Assim, é interessante que a conversa entre eles, através do protocolo,
seja monitorada. Um log contendo pacotes do IRC deve possuir todas as mensagens que trafegaram pela rede no ponto onde se está monitorando. Porém o protocolo possui um número muito grande de tipos de mensagens, onde a maioria contém comandos de controle
e de obtenção de informações necessárias aos servido-
Como obter as mensagens
Sistema Especialista
O sistema especialista desenvolvido tem o propósito de classificar se uma mensagem faz parte do diálogo
entre dois usuários (mensagem aceita) ou se contém
apenas comandos de controle ou outros comandos disponíveis no IRC (mensagem rejeitada).
No momento, a mensagem estava disponível em
um ponteiro (char *), em uma função do programa desenvolvido na linguagem C, descrito no fim da Seção
4.1. Duas opções surgiram neste ponto: 1 - armazenar
as mensagens em arquivo e criar o sistema especialista em PROLOG para ler o arquivo e retornar a resposta ou; 2 - criar o sistema especialista utilizando a
linguagem C. A segunda opção foi escolhida por dois
motivos: 1 - o sistema especialista feito em PROLOG
iria depender de outro software, para obter as mensagens e gravar em um arquivo; 2 - curiosidade de como
implementar um sistema especialista utilizando uma
linguagem imperativa.
Uma mensagem do IRC, como descrito na Seção
2.4.2, possui um formato específico. Assim, os componentes da mensagem devem ser avaliados e, se todos
estiverem corretos, a mensagem pode ser classificada
como válida. Conclui-se então que um sistema de encadeamento para frente resolve o problema. Se todos
1 http://www.tcpdump.org
2 http://www.honeynet.org.br
os fatos (componentes da mensagem) foram avaliados
e satisfeitos, então a mensagem pode ser classificada
como aceita.
4.3 Desenvolvimento do sistema especialista
Para classificar se uma mensagem faz parte do diálogo entre dois usuários, foi necessário saber quais tipos de comandos eles utilizam para conversar. Como
descrito na Seção 2.5, os comandos PRIVMSG e NOTICE possuem como parâmetros a(s) frase(s) enviada(s) de um para outro. Logo, mensagens contendo
estes comandos são classificadas como interessantes
para o sistema especialista. Além disso, alguns campos da mensagem devem ser encontrados, como por
exemplo, o apelido de quem envia a mensagem.
Levine et al apresenta os componentes de um sistema de encadeamento para frente, desenvolvido em
uma linguagem imperativa (BASIC). Eles são a base
de conhecimento, uma lista de variáveis das cláusulas,
uma fila de variáveis da conclusão e um ponteiro para
as variáveis da cláusula [3].
A base de conhecimento contém as regras do sistema especialista. Estas contém variáveis, que representam os fatos. A Tabela 1 apresenta o nome das variáveis e o seu significado.
Nome
Message
Interesting_Msg
Nick
User
Host
Command
Target
Parameter
Nick_Ind
User_Ind
Host_Ind
Command_Ind
Target_Ind
Parameter_Ind
Significado
Mensagem aceita?
Mensagem interessante.
Apelido ou servidor do emissor da mensagem
encontrado.
Nome do usuário emissor da mensagem encontrado.
Host do usuário emissor da mensagem encontrado.
Comando enviado na mensagem encontrado.
Alvo da mensagem (canal ou apelido) encontrado.
Corpo da mensagem encontrado.
Caractere ’:’ encontrado (no início da mensagem).
Caractere ’!’ encontrado.
Caractere ’@’ encontrado.
Caractere ’ ’ encontrado (na posição correta).
Caractere ’ ’ encontrado (na posição correta).
Caractere ’:’ encontrado (na posição correta).
Tabela 1. Nomes de variáveis.
Regra 01
Se Parameter = FOUND então Message = ACCEPTED
Regra 02
Se Interesting_Msg = TRUE e Nick_Ind = TRUE e
User_Ind = TRUE então Nick = FOUND
Regra 03
Se Nick = FOUND e Host_Ind = TRUE então
User = FOUND
Regra 04
Se User = FOUND e Command_Ind = TRUE então
Host = FOUND
Regra 05
Se Host = FOUND e Target_Ind = TRUE então
Command = FOUND
Regra 06
Se Command = FOUND e Parameter_Ind = TRUE
então Target = FOUND
Rule 07
If Target = FOUND então Parameter = FOUND
Figura 3. Base de conhecimento
variável Interesting_Msg, contendo o valor TRUE, estiver na fila de variáveis de conclusão, então todas as
regras da base de conhecimento que contém a sentença Interesting_Msg = TRUE serão ativadas e a variável
na parte direita da regra (após o então) será colocada
na fila.
O ponteiro de variáveis das cláusulas segue a cláusula dentro da regra que está examinando, sendo formado pelo número da regra e pelo número da cláusula.
Por exemplo, se a variável na frente da lista de variáveis da conclusão é Interesting_Msg, então o ponteiro
de variáveis das cláusulas aponta para regra 4 (valor
encontrado através de uma pesquisa na lista de variáveis das cláusulas).
O algoritmo de encadeamento para frente, proposto
por Levine et al, foi implementado neste sistema especialista e os seus passos são os seguintes:
1. A condição é identificada.
Uma vez que as variáveis foram apresentadas, a base de conhecimento foi desenvolvida como mostra a
Figura 3.
A lista de variáveis das cláusulas, mostrada na Figura 4, informa quais variáveis do problema estão associadas às partes Se das sentenças Se-Então da base
de conhecimento. Ela foi implementada como um vetor de cadeia de caracteres, como sugerido por Levine
et al [3]. Existem quatro locais reservados para cada
regra. Se uma regra não utilizar a todos, eles permanecerão em branco.
A fila de variáveis da conclusão contém o nome da
variável que se está avaliando na base de conhecimento. Assim, todas as regras que contém essa variável
na parte esquerda serão avaliadas. Por exemplo, se a
2. A variável da condição é colocada na fila de variáveis da conclusão.
3. A lista de variáveis das cláusulas é examinada à
procura da variável cujo nome é o mesmo daquela que estiver na frente da fila. Se encontrada, o
número da regra e o número 1 são colocados no
ponteiro de variáveis da cláusula. Se ela não for
encontrada, vá para o passo 6.
4. Cada variável na parte Se da regra que ainda não
tenha sido instanciada é instanciada agora. As variáveis estão nas listas de variáveis das cláusulas.
Se todas as cláusulas forem verdadeiras, a parte
Então será chamada.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Parameter
Interesting_Msg
Nick_Ind
User_Ind
Message Accepted.
Message: :[email protected] PRIVMSG #manehchannel :
ze_maneh eu tambem tou com Mandrake 9,0
Nick
Host_Ind
Message Accepted.
Message: :ze_maneh!JoseM @xxx.yyy.zzz.www PRIVMSG #manehchannel :
ok. qual seu modem?
User
Command_Ind
Message Accepted.
Message: :[email protected] PRIVMSG #manehchannel :
ze_maneh seu modem é qual?
Message Accepted.
Message: :[email protected] PRIVMSG #manehchannel :
pctel amr
Host
Target_Ind
Message Accepted.
Message: :[email protected] PRIVMSG #manehchannel :
ze_maneh o meu tambem
Command
Parameter_Ind
Figura 5. Saída da ferramenta.
Target
Figura 4. Lista de variáveis das cláusulas.
5. A variável da parte Então instanciada é colocada
no fundo da fila de variáveis da conclusão.
6. Quando não mais existirem sentenças Se contendo a variável que está na frente da fila de variáveis
da conclusão, aquela variável será removida.
7. Senão houver mais variáveis na fila de variáveis
da conclusão, encerre a sessão. Se ainda houver
variáveis, volte ao passo 3.
Ao final da execução deste algoritmo, uma conclusão será obtida: a mensagem foi ACEITA ou REJEITADA.
5 Resultados
A ferramenta foi executada com um arquivo de log
no formato tcpdump, e apresentou a saída conforme
mostrado na Figura 5. Apenas as mensagens relativas ao diálogos entre os usuários foram selecionadas,
o que mostra a eficiência da utilização do sistema especialista para resolução do problema.
6
Message Accepted.
Message: :[email protected] PRIVMSG #manehchannel :
algo assim: ./fixscript motulo.o deve funcionar (funcionou pra
mim no driver do winmodem para o mandrake9)
Conclusões
O protocolo Internet Relay Chat é utilizado por
hackers e script kids para conversa pela Internet e para disparar ataques de negação de serviço distribuídos. Deste modo, o monitoramento de suas mensagens
torna-se interessante. Porém, devido a grande variedade de tipos de mensagens, a análise dos log é uma
tarefa difícil.
Este artigo apresentou o Internet Relay Chat, conceituou um sistema especialista e o encadeamento para
frente e, finalmente, mostrou a implementação de um
sistema especialista na linguagem C para análise de
conversas pela Internet - IRCTAES.
A ferramenta analisa os fatos, como por exemplo,
se a mensagem é referente a um diálogo, se a mensagem possui todos os campos definidos pelo protocolo,
e retorna uma classificação, aceitando-a ou rejeitandoa.
O IRCTAES atingiu o resultado esperado, uma vez
que apenas as mensagens que continham diálogo entre
pessoas foram selecionadas.
Referências
[1] Bittencourt, G. Inteligência Artificial - Ferramentas e Teorias. Editora da UFSC, Florianópolis, 2nd
edn., 2001.
[2] Chaves, C. H. P. C. “Ferramenta de Visualização Gráfica do Tráfego em Redes TCP/IP - TrafficShow”. Relatório Técnico 04/2003, 2003. Pp.
28-33.
[3] Levine, R. I. & Drang, D. E. & Edelson, B. Inteligência Artificial e Sistemas Especialistas - Aplicações e Exemplos Práticos. Editora McGraw-Hill,
São Paulo, 1988. Pp. 33-55.
[4] Lindqvist, U. & Porras, P. A. “Detecting Computer and Network Misuse Throught the ProductionBased Expert System Toolset (P-BEST)”. In IEEE Symposium on Security and Privacy. Oakland.
1999.
[5] Oikarinen, J. & Reed, D.
“Internet Relay
Chat Protocol”. Request for Comments: 1459,
Network Working Group, 1993. http://www.
rfc-editor/org/search/.