EXTRAÇÃO
AUTOMÁTICA
DE
ESTRUTURAS
DE
SUBCATEGORIZAÇÃO A PARTIR DE CORPORA EM PORTUGUÊS
Leonardo Zilio (PPG-Letras/UFRGS)
Adriano Zanette (PPG-Computação/UFRGS)
Carolina Scarton (ICMC/USP)
Introdução
A tarefa de identificar automaticamente estruturas de subcategorização
(subcategorization frames — SCFs), que se enquadra como um tipo de aquisição lexical
a partir de corpora, é um desafio no Processamento de Linguagem Natural (PLN) que
tem sido trabalhado em diversas línguas. Tal tarefa, além de servir para a classificação
de elementos linguísticos (como, por exemplo, de verbos e substantivos), também pode
ser utilizada para várias tarefas de descrição de linguagem, podendo inclusive ajudar a
melhorar o desempenho de um parser (Korhonen et al., 2006). Além disso, a aquisição
lexical automática pode ser útil para classificação automática de verbos (Li e Brew,
2008; Sun e Korhonen, 2009; Sun et al., 2010) e extração de informação (Surdeanu et
al., 2003), entre outros.
Tendo essa perspectiva em mente, este trabalho apresenta um sistema para a
identificação, extração e organização de SCFs para o português (Zanette, 2010; Zanette
et al., 2012), o qual iniciou como uma adaptação para o português do sistema de
Messiant (2006), e mostra a aplicação desse sistema em dois trabalhos de descrição do
português baseados em corpora. Assim, os objetivos aqui propostos são: 1) descrever a
ferramenta de extração de SCFs; 2) relatar a sua aplicação prática em dois estudos; e 3)
apresentar brevemente os resultados desses estudos.
Na seção a seguir, apresentamos uma definição de SCF e indicamos alguns
trabalhos que abordam o tema. Posteriormente, discorremos brevemente sobre o
funcionamento do sistema desenvolvido. Após a descrição da ferramenta, apresentamos
dois estudos que a utilizaram para diferentes fins, e a última seção é reservada para
nossas considerações finais.
Estruturas de subcategorização
Uma estrutura de subcategorização (subcategorization frame — SCF) é uma
representação sintática de uma sentença ou sintagma que, observada em grandes
extensões de texto, permite a classificação de determinados elementos linguísticos.
Neste trabalho, os elementos linguísticos relevantes são os verbos, sendo que as SCFs
representam a estrutura argumental dos verbos presentes em sentenças de diferentes
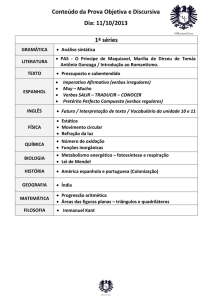
corpora. Na Figura 1, apresentamos alguns exemplos de SCFs do verbo “encontrar”
extraídos de um corpus de textos de Cardiologia.
Fig. 1: SCFs do verbo “encontrar” em um corpus de Cardiologia
Os sistemas de SCFs já foram desenvolvidos para várias línguas, como inglês
(Korhonen et al., 2006; Briscoe e Carrol, 1997), alemão (Schulte Im Walde, 2002),
francês (Messiant, 2008) e italiano (Ienco et al., 2008). Tais trabalhos foram
desenvolvidos principalmente para o reconhecimento de SCFs verbais. No inglês, os
trabalhos de SCFs já foram utilizados, por exemplo, para expandir a VerbNet (Kipper,
2005; Kipper et al., 2006), um repositório de verbos com anotação de papéis
semânticos. Para o português, o trabalho com SCFs está ainda em seus primeiros
passos. Podemos citar o sistema de Augustini (2006), que procura abranger também as
SCFs de preposições, substantivos e adjetivos. A grande restrição desse estudo, porém,
é que as SCFs têm de ser determinadas antes da extração.
Extrator de estruturas de subcategorização
O sistema que apresentamos se ocupa exclusivamente de SCFs verbais. A
entrada utilizada são corpora anotados pelo parser PALAVRAS (Bick, 2000), de modo
que o sistema extrai uma lista de SCFs para cada verbo, contendo informações de
frequência para todas as sentenças no corpus, como pôde ser visto na Figura 1. Após a
extração, o sistema armazena as informações em um banco de dados.
No momento do armazenamento, o sistema apresenta duas opções: um
armazenamento dos dados da forma como aparecem na sentença, sem qualquer
alteração em sua ordem (por exemplo, uma topicalização de objeto direto não seria
colocada na forma direta); ou uma avaliação do tipo de estrutura sintática, de modo que
os elementos sejam classificados em uma ordem direta predeterminada, que é a
seguinte: 1) sujeito; 2) objeto direto; 3) objeto indireto; 4) adjetivo (separado de um
substantivo); 5) adjunto adverbial.
O processo de funcionamento do sistema é o seguinte: 1) para cada sentença, o
sistema extrai todos os verbos; 2) para cada verbo na sentença, o sistema busca as suas
dependências (ou seja, os elementos que se ligam, de acordo com a anotação do parser,
ao verbo); e 3) as demais informações (morfossintáticas e sintáticas) anotadas pelo
parser são avaliadas e os constituintes relevantes são utilizados para construir as SCFs.
O sistema desenvolvido mostrou-se bastante flexível conforme as necessidades.
Esse fato é comprovado pelas diferentes aplicações às quais o sistema se destina, sendo
que, na seção a seguir, apresentamos dois trabalhos distintos que fazem uso dele.
Estudos desenvolvidos com o sistema
Léxico de verbos
Um dos estudos nos quais o sistema de extração de SCFs vem sendo utilizado envolve a
construção de um léxico de verbos para o português brasileiro (Scarton e Aluísio, 2012),
baseado na VerbNet (Kipper, 2005). A VerbNet é um léxico verbal que contém
informações sintático-semânticas de verbos agrupados de acordo com as classes de
Levin (1993). Segundo Levin, verbos que compartilham padrões sintáticos (alternâncias
sintáticas) tendem a compartilhar, também, componentes semânticos. As alternâncias
sintáticas são alternâncias nas expressões dos argumentos dos verbos que podem ou não
acarretar mudança de sentido. Cada alternância é realizada em SCFs diferentes. Como
exemplo, podemos ver a alternância locativa:
Sharon sprayed water on the plants. (Sharon borrifou água sobre as plantas)
Sharon sprayed the plants with water. (Sharon borrifou as plantas com água)
No primeiro exemplo, a SCF é SUBJ[NP] V NP PP[sobre] e, no segundo, é
SUBJ[NP] V NP PP[com].
A ideia da VerbNet.Br é utilizar os alinhamentos existentes entre a VerbNet, a
WordNet (Fellbaum, 1998) e a WordNet.Br (Dias-da-Silva et al., 2008) para trazer
automaticamente verbos candidatos a membros das classes de Levin para o português
do Brasil. Após isso, verificam-se as SCFs (em corpus) dos verbos candidatos no
português. Por fim, comparam-se os padrões encontrados no corpus com padrões
definidos manualmente para cada classe. Verbos que apresentam no corpus os padrões
manualmente definidos são selecionados como membros.
Outra tarefa que também foi realizada com as SCFs foi o agrupamento
automático de verbos (AAV). Nessa tarefa, as SCFs foram utilizadas como atributos
para agrupar os verbos. O resultado das duas abordagens serão comparados com um
gold standard das classes da VerbNet para o português do Brasil, criado com o apoio da
Drª. Karin Kipper e da Drª. Magali Duran.
Para ambas as tarefas, como pôde ser visto nos exemplos acima, o sistema foi
adaptado de modo a apresentar a posição do verbo e do sujeito na SCF. Portanto, em
comparação com a coluna 1 da Figura 1, os padrões são um pouco diferentes. Neste
estudo, usamos, por exemplo, SUBJ[NP] V NP PP[em], em vez de simplesmente
NP_NP_PP[em] (ver Figura 1).
Inicialmente, utilizou-se como entrada para o sistema o corpus Lácio-Ref
(Aluísio et al., 2004), que tem aproximadamente 9 milhões de palavras e apresenta 4
gêneros: científico, informativo, judiciário e literário. Como a quantidade de verbos
identificados e a frequência dos mesmos não era suficiente para a tarefa de AAV, foi
necessário processar mais textos. Para isso, escolheram-se o corpus PLN-BR-FULL
(Bruckschen et al., 2008) do gênero jornalístico (aproximadamente 26 milhões de
palavras) e o corpus da Revista FAPESP (http://revistapesquisa.fapesp.br) (Aziz e
Specia, 2011) do gênero de divulgação científica (aproximadamente 6 milhões de
palavras). Somando-se os três corpora, foram identificados 3.779 verbos (com
frequência superior a 10) e 3.578 SCFs (com frequência superior a 5).
O melhor resultado apresentado para a VerbNet.Br foi de 51,18% para Fmeasure. Já o melhor resultado para a tarefa de agrupamento de verbos atingiu uma Fmeasure de 49,07% (esse resultado é promissor se comparado com resultados obtidos
para o inglês (63,30%) (Sun e Korhonen, 2009) e para o francês (50,60%) (Sun et al.,
2010), considerando que essas línguas possuem recursos maiores e ferramentas mais
precisas).
Anotação de papéis semânticos
Outro trabalho desenvolvido com a ferramenta de extração de SCFs envolve a
anotação semiautomática de papéis semânticos em corpora escritos em português
brasileiro. O objetivo é gerar uma lista de verbos com suas respectivas SCFs e papéis
semânticos, além de dois corpora com orações semanticamente anotadas. De modo
sucinto, os papéis semânticos identificam um significado mais abstrato e esquemático
dos argumentos de um elemento linguístico (em nosso caso, um verbo). Um exemplo
bastante simples, somente a título de ilustração, seria indicar que, na oração “João viu
Maria.”, existe um verbo que é “ver” (em sua forma canônica) e dois argumentos. A
anotação de papéis semânticos indica que o argumento “João” é o experienciador e o
argumento “Maria” é o experienciado.
Este estudo utiliza dois corpora anotados com o parser PALAVRAS (Bick,
2000), sendo um de linguagem especializada composto por artigos científicos da área de
Cardiologia (Zilio, 2009) e outro de linguagem não especializada contendo textos
jornalísticos do Diário Gaúcho (compilado pelo projeto PorPopular, disponível em
http://www6.ufrgs.br/textecc/porlexbras/porpopular/). A ferramenta de extração de
SCFs que descrevemos neste trabalho auxilia a anotação dos papéis semânticos por
meio da extração e organização dos dados presentes nos dois corpora e também por
meio de uma interface de anotação, que é gerada automaticamente a partir do banco de
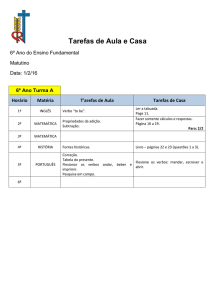
dados (Figura 2).
Fig. 2: Interface para anotação dos papéis semânticos.
Na Figura 2, cada sentença com o verbo “levar” é organizada em exemplos, e os
argumentos desse verbo em cada um dos exemplos já se apresentam classificados na
ordem discutida anteriormente. Para cada argumento, é apresentada a anotação sintática
e uma caixa de rolagem que permite a seleção de um papel semântico. A lista dos papéis
semânticos presentes na caixa de rolagem se encontra em um arquivo separado,
podendo ser modificada facilmente conforme a necessidade do pesquisador.
Atualmente, desenvolvemos um estudo-piloto que visou a testar se a lista de
papéis semânticos selecionada seria aplicável em grande escala. A lista contém 46
papéis semânticos e foi proposta nos trabalhos de Brumm (2008) e Gelhausen (2010).
Os papéis semânticos são estes: agente, paciente, ação, experienciador, experienciado,
estímulo, beneficio, beneficiante, beneficiado, possuidor, posse, donatário, recipiente,
dimensão geográfica, local, local de origem, local de destino, trajeto, dimensão
temporal, momento, início, fim, frequência, guia, acompanhante, comparado, modelo,
contrariado, opositor, ator, papel, qualificado, qualidade, substituto, substituído, tema,
descrição, todo, parte, criador, resultado, causa, requisito, intenção, instrumento e modo.
O espaço neste artigo não permite que se explique cada um dos papéis
semânticos individualmente, mas ressaltamos que os nomes de alguns podem confundir
o leitor, sendo importante a leitura dos artigos que os descrevem. O papel “tema”, por
exemplo, representa a contraparte do papel “descrição”, e não está relacionado com o
papel “tema” da forma como é empregado, por exemplo, na VerbNet, em que ele
representa “participantes que estão em um lugar ou que estão mudando de lugar”
(Kipper, 2005). Como essa lista de papéis foi desenvolvida com a ideia de se poder usar
mais de um papel semântico por argumento e também de se anotarem argumentos de
substantivos e de outros elementos não verbais, os 18 papéis compreendidos na lista
entre “guia” e “resultado” são papéis com função principalmente descritora,
representando uma maior especificação do argumento em relação aos demais papéis.
Para o estudo-piloto, selecionamos quatro verbos (receber, levar, usar e
encontrar) presentes nos dois corpora e anotamos até dez sentenças por SCF (somente
usamos SCFs com frequência maior que dez), totalizando 482 sentenças, das quais
resultaram 138 diferentes grupos de papéis semânticos. O estudo permitiu observar que
alguns papéis semânticos da lista podem ser unidos e que outros são demasiado
específicos. Um exemplo de papéis semânticos que poderiam ser unidos são os papéis
de posse e benefício, que se apresentam nas mesmas estruturas argumentais e com os
mesmos verbos, diferindo apenas na semântica do léxico presente no argumento, mas
não na semântica do verbo propriamente dita.
Na comparação dos resultados nos dois corpora, percebemos que os SCFs e os
papéis semânticos empregados foram muito próximos. O verbo “usar” foi o mais similar
nos dois corpora, sendo que os papéis semânticos empregados foram realmente muito
próximos. O mesmo se pode dizer do verbo “receber”, que apresentou papéis
semânticos como recipiente e posse, benefício e beneficiado, e experienciador e
experienciado na maioria dos casos em ambos os corpora. Quanto ao verbo “encontrar”,
também observamos uma distribuição de papéis semânticos bastante parecida nos dois
corpora, com predominância dos papéis agente, paciente e tema.
Esses resultados pareceriam levar à conclusão de que as diferenças entre
especializado e não especializado estão apenas no vocabulário, e não atingem um nível
semântico mais abstrato. Mas as ocorrências do verbo “levar” mostraram que a questão
é um pouco mais complexa. Enquanto o corpus de Cardiologia privilegiou papéis como
criador e resultado, o corpus do Diário Gaúcho claramente privilegiou os papéis de
agente e paciente; ainda que tenham existido também configurações muito próximas,
como a de experienciador e experienciado nos dois corpora.
Essas observações ainda não são robustas o suficiente para uma conclusão
acerca do assunto, tendo em vista o número pequeno de observações realizadas, mas já
servem como um ponto de partida para as observações futuras, nas quais serão
utilizados mais verbos e mais sentenças.
Considerações finais
A ferramenta aqui apresentada, um extrator e organizador de SCFs, se mostrou
bastante útil para a descrição do português brasileiro. Isso é visível a partir da aplicação
que demonstramos em dois estudos de cunho diferente, que visam a aumentar a
capacidade que temos de processar a linguagem natural. Além disso, a ferramenta pode
ser aplicada a outros corpora para desenvolver outros tipos de trabalho, sendo bastante
flexível, uma possibilidade seria a anotação de frames no estilo da FrameNet (Baker et
al., 1998).
Um limite que a ferramenta apresenta é o uso do parser PALAVRAS como
base, pois ele é, infelizmente, um recurso pago ao qual o acesso é bastante restrito. A
opção por esse parser se deu por ele ser atualmente o mais preciso, porém, seria
interessante ter como alternativa a possibilidade de se usar um parser gratuito na
anotação das dependências. Esse é um dos passos que deve ser levado adiante nos
trabalhos futuros relacionados à ferramenta.
Agradecimentos
A CAPES, CNPq e FAPESP pelo apoio financeiro e ao projeto CAPES/Cofecub
707/11 pelo suporte.
Referências
ALUÍSIO, S.; PINHERO, G. M.; MANFRIM, A. M. P.; OLIVEIRA, L. H. M. de;
GENOVES JR., L. C.; TAGNIN, S. E. O. (2004). “The Lácio-Web: Corpora and Tools
to advance Brazilian Portuguese Language Investigations and Computational Linguistic
Tools”, in: The Proceedings of the 4th International Conference on Language
Resources and Evaluation (LREC 2004). Lisboa, Portugal, 1779-1782.
AUGUSTINI, A. (2006). Aquisição Automática de Subcategorização SintácticoSemântica e sua Utilização em Sistemas de Processamento da Língua Natural. Tese de
Doutorado em Informática: Universidade Nova de Lisboa.
AZIZ, W. e SPECIA, L. (2011). “Fully Automatic Compilation of a Portuguese-English
Parallel Corpus for Statistical Machine Translation”, in: Proceedings of the 8th
Brazilian Symposium in Information and Human Language Technology, Cuiabá, Brasil.
BAKER, C. F., FILLMORE, C. J. e LOWE, J. F. (1998). “The Berkeley FrameNet
Project”, in: Proceedings of the 36th Annual Meeting of the Association for
Computational Linguistics and 17th International Conference on Computational
Linguistics, University of Montréal, Canadá, pp. 86-90.
BICK, E. (2000). The Parsing System PALAVRAS: Automatic Grammatical Analysis of
Portuguese in a Constraint Grammar Framework. Aarhus: Aarhus University Press.
BRISCOE, T.; CARROL, J. (1997). “Automatic extracton of subcategorization from
corpora”, in: Proceedings of the fifth conference on Applied natural language
processing, Washington, DC, 356-363.
BRUCKSCHEN, M., MUNIZ, F., SOUZA, J. G. C., FUCHS, J. T., INFANTE, K.,
MUNIZ, M., GONÇ ALVES, P. N., VIEIRA, R. e ALUÍSIO, S. M. (2008). “Anotação
Lingüística em XML do Corpus PLN-BR”, in: Série de Relatórios do NILC. NILC-TR09-08, 39 p.
BRUMM, T. (2008). Erstellung eines Systems thematischer Rollen mit Hilfe einer
multiplen Fallstudie. Trabalho de conclusão de curso.
DIAS-DA-SILVA, B. C., DI FELIPPO, A. E NUNES, M. G. V. (2008). The automatic
mapping of Princeton WordNet lexical conceptual relations onto the Brazilian
Portuguese WordNet database. In Proceedings of the 6th International Conference on
Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, pp. 15351541.
FELLBAUM, C. (1998). WordNet: An electronic lexical database. Cambridge: MIT
Press.
GELHAUSEN, T. (2010). Modellextraktion aus natürlichen Sprachen: Eine Methode
zur systematischen Erstellung von Domänenmodellen. Karlsruhe: KIT Scientific
Publishing. Tese de doutorado, Karlsruher Institut für Technologie.
IENCO, D., VILLATA, S., BOSCO, C. (2008). “Automatic extraction of
subcategorization frames for Italian”, in: Proceedings of the sixth International
Conference on Language Resources and Evaluation (LREC 2008), Marrakech,
Marocco, 28-30.
KIPPER, K. (2005). VerbNet: a broad-coverage, comprehensive verb lexicon.
University of Pennsylvania. Doutorado em Computer and Information Science:
University of Pennsylvania.
KIPPER, K.; KORHONEN, A.; RYANT, N.; PALMER, M. (2006). “Extending
VerbNet with Novel Verb Classes”, in: Fifth International Conference on Language
Resources and Evaluation (LREC 2006), Genoa, Italy.
KORHONEN, A.; KRYMOLOWSKI, Y.; BRISCOE T. (2006). “A Large
Subcategorization Lexicon for Natural Language Processing Applications”, in:
Proceedings of the fifth international conference on Language Resources and
Evaluation (LREC 2006), Genova, Italy.
LI, J.; BREW, C. (2008). “Which are the Best Features for Automatic Verb
Classification”, in: Proceedings of the 46th Annual Meeting of the Assoication for
Computational Linguistics, Columbus, Ohio.
MESSIANT, C. (2006). “A subcategorization acquisition system for French verbs”, in:
Proceedings of the 46th Annual Meeting of the Association for Computational
Linguistics on Human Language Techonologies, Columbus, Ohio, 55-60.
SCARTON, C. e ALUÍSIO, S. M. (2012). “Towards a cross-linguistic VerbNet-style
lexicon to Brazilian Portuguese”, in: Proceedings of the LREC 2012 Workshop on
Creating Cross-language Resources for Disconnected Languages and Styles
(CREDISLAS 2012), Istanbul, Turkey.
SCHULTE IM WALDE, S. (2002). “A Subcategorisation Lexicon for German Verbs
induced from a Lexicalised PCFG”, in: Proceedings of the 3rd Conference on Language
Resources and Evaluation, v. IV, Las Palmas de Gran Canaria, Espanha, p. 1351-1357.
SUN, L.; KORHONEN, A. (2009). “Improving verb clustering with automatically
acquired selectional preferences”, in: Proceedings of the 2009 Conference on Empirical
Methods in Natural Language Processing (EMNLP 2009), Singapura, pp. 638-647.
SUN, L.; KORHONEN, A.; POIBEAU, T.; MESSIANT, C. (2010). “Investigating the
cross-linguistic potential of VerbNet: style classification”, in: Proceedings of the 23rd
International Conference on Computational Linguistics (COLING 2010), Beijing,
China, 1056-1064.
SURDEANU, M.; HARABAGIU, S.; WILLIAMS, J.; AARSETH, P. (2003). “Using
predicate-argument structures for information extraction”, in: The Proceedings of the
41st Annual Meeting of ACL, Sapporo, Japan, 8-15.
ZANETTE, A. (2010). Aquisição de Subcategorization frames para Verbos da Língua
Portuguesa. Projeto de Diplomação orientado por Aline Villavicencio, UFRGS.
ZANETTE, A.; SCARTON, C.; ZILIO, L. (2012). “Subcategorization frames extractor
from corpus: an approach to Portuguese language”, in: Demo session of PROPOR 2012,
17 a 20 de abril de 2012, Coimbra, Portugal.
ZILIO, L. (2009). Colocações especializadas e Komposita: um estudo contrastivo
alemão-português na área de Cardiologia. Dissertação de Mestrado orientada por
Maria José Bocorny Finatto, UFRGS.