UNIVERSIDADE FEDERAL DE MATO GROSSO
COORDENAÇÃO DE ENSINO DE GRADUAÇÃO EM
SISTEMAS DE INFORMAÇÃO
RELATÓRIO DE ESTÁGIO SUPERVISIONADO
DESENVOLVIMENTO DE ROTINA PARA EXPORTAÇÃO
DE ARQUIVOS DE ACORDO COM LAYOUT GENÉRICO
PRÉ-DEFINIDO (LINGUAGEM ADVPL)
MICHEL RODRIGUES PEREIRA
CUIABÁ – MT
2016
UNIVERSIDADE FEDERAL DE MATO GROSSO
COORDENAÇÃO DE ENSINO DE GRADUAÇÃO EM
SISTEMAS DE INFORMAÇÃO
RELATÓRIO DE ESTÁGIO SUPERVISIONADO
DESENVOLVIMENTO DE ROTINA PARA EXPORTAÇÃO
DE ARQUIVOS DE ACORDO COM LAYOUT GENÉRICO
PRÉ-DEFINIDO (LINGUAGEM ADVPL)
MICHEL RODRIGUES PEREIRA
Relatório
apresentado
Instituto
de
Computação da Universidade Federal de
Mato Grosso, para obtenção do título de
Bacharel em Sistemas de Informação.
CUIABÁ – MT
2016
UNIVERSIDADE FEDERAL DE MATO GROSSO
COORDENAÇÃO DE ENSINO DE GRADUAÇÃO EM
SISTEMAS DE INFORMAÇÃO
MICHEL RODRIGUES PEREIRA
Relatório de Estágio Supervisionado apresentado à Coordenação do Curso de
Sistemas de Informação como uma das exigências para obtenção do título de
Bacharel em Sistemas de Informação da Universidade Federal de Mato Grosso
Aprovado por:
________________________________________
Prof. Daniel Avila Vecchiato
Instituto de Computação
(ORIENTADOR)
________________________________________
Rodrigo Seabra Leite
(SUPERVISOR)
________________________________________
Prof. MSc. Nilton Hideki
Instituto de Computação
(Coordenador de Estágios)
DEDICATÓRIA
À Deus porque até aqui Ele me ajudou.
À minha família pelo apoio e pela união, pois eles me deram a base necessária para
que eu pudesse me tornar a pessoa que sou hoje.
AGRADECIMENTOS
Agradeço à Deus porque Ele não desistiu de mim, e me deu forças para ir até o fim.
Agradeço à minha família pois sem eles não conseguiria chegar até aqui, incentivo,
apoio e união, foram pilares primordiais para minha formação.
Agradeço aos meus professores que transmitiram o conhecimento necessário ao
longo desses anos, sempre com o objetivo de nos tornar pessoas e profissionais
melhores.
SUMÁRIO
SUMÁRIO .................................................................................................................... 6
LISTA DE FIGURAS ................................................................................................... 7
LISTA DE TABELAS .................................................................................................. 8
LISTA DE SIGLAS E ABREVIATURAS.................................................................... 9
RESUMO .................................................................................................................... 10
INTRODUÇÃO .......................................................................................................... 11
OBJETIVO GERAL ................................................................................................... 12
OBJETIVOS ESPECÍFICOS ...................................................................................... 12
ESTRUTURA DO RELATÓRIO ............................................................................... 13
1.
REVISÃO DE LITERATURA ............................................................................ 14
1.1.
MVC (Model-View-Controller)................................................................. 14
1.3.
Banco de Dados ........................................................................................... 15
1.2.
2.
3.
1.4.
5.
6.
Controle de Versão ..................................................................................... 18
MATÉRIAS, TÉCNICAS E MÉTODOS ............................................................ 21
RESULTADOS ................................................................................................... 28
3.1.
Configuração da Estrutura dos Arquivos (AFAT0186) ......................... 29
3.3.
Rotina Auxiliar (PFAT0190) ..................................................................... 35
3.2.
4.
Linguagem ADVPL .................................................................................... 15
3.4.
Geração dos Arquivos (PFAT0185) .......................................................... 33
Estruturação das Rotinas .......................................................................... 36
DIFICULDADES ENCONTRADAS .................................................................. 39
CONCLUSÕES ................................................................................................... 40
REFERÊNCIAS BIBLIOGRÁFICAS ................................................................. 41
ANEXOS .................................................................................................................... 43
APÊNDICES ............................................................................................................... 72
7
LISTA DE FIGURAS
FIGURA 1 – ILUSTRAÇÃO DOS 3 COMPONENTES BÁSICOS DO MVC .............................. 14
FIGURA 2 – REPRESENTAÇÃO SIMPLIFICADA DE UM SISTEMA DE BANCO DE DADOS ..... 16
FIGURA 3 – DIAGRAMA SIMPLIFICADO DE UM AMBIENTE DE SISTEMA DE BANCO DE
DADOS .......................................................................................................................... 17
FIGURA 4 – ESQUEMA DE FUNCIONAMENTO BÁSICO DE UM SOFTWARE DE CONTROLE DE
VERSÃO ........................................................................................................................ 20
FIGURA 5 – TELA PRINCIPAL DO TOTVS | DEVELOPMENT STUDIO.............................. 24
FIGURA 6 – RANKING QUE CLASSIFICA OS SGBD’S DE ACORDO COM SUA
POPULARIDADE ............................................................................................................ 26
FIGURA 7 – ROTINAS CRIADAS E ADICIONADAS AO MENU DO SISTEMA ........................ 29
FIGURA 8 – TELA CRIADA REFERENTE A ROTINA AFAT0186 ....................................... 30
FIGURA 9 – EXEMPLO DE CONFIGURAÇÃO DE UM ARQUIVO A SER GERADO ................. 31
FIGURA 10 – EXEMPLO DE INSERÇÃO DO SCRIPT SQL DE UM DETERMINADO REGISTRO
..................................................................................................................................... 32
FIGURA 11 – EXEMPLO DE E-MAIL ENVIADO APÓS EXECUÇÃO COM SUCESSO DA ROTINA
..................................................................................................................................... 34
FIGURA 12 – EXEMPLO DE CONFIGURAÇÃO DA ROTINA PELO AGENDADOR
(SCHEDULER) ............................................................................................................... 35
FIGURA 13 – EXEMPLO DE USO DA ROTINA PFAT0190 ................................................ 36
FIGURA 14 – FLUXO PADRÃO SIMPLIFICADO DESTACANDO O RELACIONAMENTO DAS
FUNÇÕES ...................................................................................................................... 37
8
LISTA DE TABELAS
TABELA 1 – CRONOGRAMA DAS ATIVIDADES EXECUTADAS .................... 21
9
LISTA DE SIGLAS E ABREVIATURAS
ADVPL
UFMT
- Advanced Protheus Language
- Universidade Federal de Mato Grosso
ERP
- Enterprise Resource Planning
SQL
- Structured Query Language
GPL
- General Public License
SGBD
IDE
ANSI
MVC
DBA
- Sistema Gerenciador de Banco de Dados
- Integrated Development Environment
- American National Standards Institute
- Model – View – Controller
- Data Base Administrator
10
RESUMO
O principal objetivo deste relatório é descrever as atividades que compuseram o
período de estágio supervisionado na empresa Agro Amazônia.
Esta etapa é
necessária e imprescindível para conclusão do curso de Sistemas de Informação da
Universidade Federal de Mato Grosso (UFMT). Neste relatório, está descrito o
caminho percorrido para o desenvolvimento de uma rotina genérica de exportação de
arquivos que contém informações relevantes, como o volume de vendas e posição de
estoque, por exemplo, referente aos produtos de um determinado fornecedor, que
neste caso é a empresa Bayer – Accera. Os dados para preenchimento dos arquivos
são trazidos do banco de dados da empresa Agro Amazônia que atua como revenda
de produtos Bayer. Para implementação, foi utilizada a linguagem ADVPL
(Advanced Protheus Language), uma linguagem proprietária implementada pelo ERP
Protheus (Sistema de Planejamento de Recursos Empresariais) pertencente à empresa
Totvs. Ao fim do desenvolvimento deste trabalho, será possível gerar arquivos texto
(em estrutura pré-definida) diretamente pelo ERP, utilizando a rotina criada.
Palavras-Chave: ADVPL; ERP, Totvs; Accera.
11
INTRODUÇÃO
Atualmente, as empresas, independente do porte, estão cada vez mais
investindo em softwares para gestão e controle de seu patrimônio. Tais soluções
acompanham as exigências do mercado e se tornam extremamente necessários para
manter a competitividade no mercado atual, tendo em vista melhor desempenho e
melhores resultados para organização.
Segundo Stamford (2000), o ERP (Enterprise Resource Planning)
possibilita um fluxo de informações único, contínuo e consistente por toda a empresa
sob uma única base de dados. É um instrumento para a melhoria de processos de
negócio, orientado por esses processos e não pelas funções e departamentos da
empresa, com informações on-line em tempo real. Permite visualizar por completo as
transações efetuadas pela empresa, desenhando um amplo cenário de seus processos
de negócios.
A Totvs (antiga Microsiga Software) é uma empresa com mais de 30 anos de
mercado e possui várias soluções, para os diversos segmentos e necessidades. O ERP
Protheus é considerado a sua principal solução, e a empresa é hoje a 6ª maior do
mundo no setor de software e aplicativos. Outro fato a ser citado, é o lançamento da
linguagem de programação própria ADVPL (Advanced Protheus Language) na
década de 90, que foi desenvolvida ao longo de 7 (sete) anos (Historia –TOTVS.
Retirado de https://www.totvs.com/a-totvs/historia).
Em vistas do mercado atual, podemos observar que a todo o momento há a
necessidade de aprimorar as análises e obter o maior nível de abstração de dados que
o software oferece ou pode oferecer. E, para se adequar à realidade tanto da empresa
quanto do mercado, o ERP permite nessas situações que surjam as “customizações”
(ou personalizações).
Customizações são alterações e/ou novas implementações que são feitas de
acordo com a necessidade da empresa, geralmente desenvolvidos para se encaixar
com a missão, visão e valores da mesma. O tema deste trabalho também se enquadra
como uma customização, visto que esse em meio as diversas rotinas (ou
funcionalidades) padrões existentes no sistema atualmente, não existe uma que supre
12
a necessidade em questão (gerar arquivo(s) em formato pré-definido e com
informações também pré-definidas).
O desafio deste trabalho foi arquitetar uma maneira para que a rotina não
ficasse direcionada somente e simplesmente para exportação de arquivos, mas, que
pudesse ser utilizada para outros fins correlacionados com a função principal. O
objetivo foi implementar algo que fosse funcional e ao mesmo tempo de fácil
manutenção, uma vez que o uso será, a priore, feito pelo próprio departamento de
Tecnologia.
OBJETIVO GERAL
O objetivo geral deste relatório, é descrever como foi desenvolvida uma rotina
no ERP Protheus, que tem como finalidade a geração de arquivos que estejam no
layout desejado pelo fornecedor e que contenham informações relevantes para
análises gerenciais, tais como volume de vendas, posição de estoques, notas fiscais
recebidas e etc., podendo o fornecedor com posse dessas informações, verificar
pontos de melhoria, necessidades relacionadas a marketing e outras questões a serem
ajustadas que impactam diretamente no bom andamento do negócio.
OBJETIVOS ESPECÍFICOS
Dentre tudo o que será descrito neste relatório, podemos destacar como seus
objetivos específicos os seguintes pontos:
Atender a necessidade de um dos maiores fornecedores da Agro
Criar rotina não existente no ERP padrão, possibilitando o uso em
Amazônia (Bayer);
outras atividades futuras;
Automatizar o processo de geração dos arquivos.
13
ESTRUTURA DO RELATÓRIO
O restante desse relatório está organizado da seguinte maneira: A seção 1
discorre sobre a revisão da literatura, a seção 2 discorre sobre as matérias, métodos e
técnicas utilizadas, a seção 3 discorre sobre os resultados obtidos, a seção 4 discorre
sobre as dificuldades encontradas, a seção 5 discorre sobre a conclusão e a seção 6
expõe as referências bibliográficas.
14
1. REVISÃO DE LITERATURA
Esta seção abordará as referências utilizadas para o desenvolvimento das
atividades propostas no período de estágio. Saliento que, aquilo que foi aprendido em
sala de aula, todo o conhecimento repassado pelos professores, foi de suma
importância para o bom desenvolvimento dos trabalhos.
1.1.
MVC (Model-View-Controller)
Neste trabalho, a arquitetura utilizada foi a Model-View-Controller ou MVC.
A arquitetura MVC, como é mais conhecida, é um padrão de arquitetura de software
que visa separar a lógica de negócio da lógica de apresentação (a interface),
permitindo o desenvolvimento, teste e manutenção isolados de ambos. Tal arquitetura
possui três componentes básicos, conforme Figura 1:
Figura 1 – Ilustração dos 3 (três) componentes básicos do MVC
Fonte: Repositório Digital TOTVS
Em nota de rodapé: Disponível em: http://tdn.totvs.com/display/public/mp/AdvPl+utilizando+MVC,
Acesso em mar. de 2016
Model ou modelo de dados: representa as informações do domínio do aplicativo
e fornece funções para operar os dados, isto é, ele contém as funcionalidades do
aplicativo. Nele definimos as regras de negócio: tabelas, campos, estruturas,
15
relacionamentos etc. O modelo de dados (Model) também é responsável por
notificar a interface (View) quando os dados forem alterados;
View ou interface: responsável por renderizar o modelo de dados (Model) e
possibilitar a interação do usuário, ou seja, é o responsável por exibir os dados;
1.2.
Controller: responde às ações dos usuários, possibilita mudanças no Modelo
de dados (Model) e seleciona a View correspondente.
Linguagem ADVPL
O AdvPL (Advanced Protheus Language), que foi utilizada neste trabalho, é
uma linguagem de programação padrão xBase (como Clipper, Visual Objects e
Fivewin) com comandos, funções, operadores, estruturas de controle de fluxo e
palavras reservadas que permite o desenvolvimento de programas seguidos do
paradigma de orientação a objetos ou procedural. Desenvolvida em 1994, teve o seu
foco mantido no desenvolvimento de sistemas de gestão empresarial ERP do grupo
TOTVS. AdvPL é considerada uma linguagem compilada e interpretada ao mesmo
tempo pois, além de passar pelo processo de compilação, a mesma utiliza uma
aplicação denominada “App Server” (aplicação interna do Protheus) que interpreta as
instruções em tempo de execução (Onishi,2015).
1.3.
Banco de Dados
Bancos de dados e sistemas gerenciadores de banco de dados (SGBD) são
componentes essenciais da vida na sociedade moderna. Diversas atividades que
envolvem alguma interação com um banco de dados são usadas cotidianamente (uma
lista telefônica, um catálogo ou um sistema de controle de RH de uma empresa).
Essas interações são exemplos de aplicações de banco de dados tradicionais, em que
a maior parte da informação armazenada e acessada é textual ou numérica (Navathe,
2010).
Conforme Figura 2,
podemos identificar de forma simplificada, o
funcionamento de um sistema de banco de dados e como são organizadas e
consumidas as informações contidas no mesmo.
16
Figura 2 - Representação simplificada de um sistema de banco de dados
Fonte: Adaptado de Date (2003)
Conforme Ramakrishnan e Gehrke (2008), um banco de dados é uma coleção
de dados que, tipicamente, descreve atividades de uma ou mais organizações
relacionadas. Por exemplo, um banco de dados de uma universidade poderia conter
informações sobre:
Entidades como alunos, professores, cursos e turmas;
Relacionamentos entre outras entidades como a matricula dos
alunos nos cursos, cursos ministrados pelos professores, e o uso de
salas por cursos.
Como as informações são muito importantes na maioria das organizações, os
cientistas da computação desenvolveram um grande grupo de conceitos e técnicas
para gerenciar dados. Um sistema de gerenciamento de banco de dados (SGBD), por
exemplo, é uma coleção de dados inter-relacionados e um conjunto de programas
para acessar esses dados. A coleção de dados normalmente chamada de banco de
dados, contém informações relevantes a uma empresa. O principal objetivo de um
SGBD é fornecer uma maneira de recuperar informações de banco de dados que seja
17
tanto conveniente quanto eficiente (Korth, 2006). Conforme ilustrado na Figura 3,
conseguimos observar a divisão em camadas, existente em um ambiente que possui
um sistema de banco de dados. É possível definir claramente o escopo e a visibilidade
de cada camada.
Figura 3 - Diagrama simplificado de um ambiente de sistema de banco de dados.
Fonte – Navathe, 2010.
O SGBD é um sistema de software de uso geral que facilita o processo de
definição, construção, manipulação e compartilhamento de bancos de dados entre
diversos usuários e aplicações. Definir um banco de dados envolve especificar os
tipos, estruturas e restrições dos dados a serem armazenados. A definição ou
informação descritiva do banco de dados também é armazenada pelo SGBD na forma
de um catálogo ou dicionário, chamado de metadados. A construção do banco de
dados é o processo de armazenar os dados em algum meio controlado pelo SGBD. A
manipulação de um banco de dados inclui funções como consulta para recuperar
dados específicos, atualização para refletir mudanças e geração de relatórios com
18
base nos dados. O compartilhamento permite que diversos usuários e programas
acessem-no simultaneamente (Korth, 2006).
Structured Query Language (SQL) ou Linguagem Estruturada de Consulta é
uma linguagem de computador padrão para gerenciamento de banco de dados
relacional e manipulação de dados. SQL é usado para consultar, inserir, atualizar e
modificar dados. A maioria dos bancos de dados relacionais utilizam SQL, que é um
benefício adicional para os administradores de banco de dados (DBAs), como eles
são muitas vezes obrigados a suportar bancos de dados através de várias plataformas
diferentes. Desenvolvido pela primeira vez no início de 1970 na IBM por Raymond
Boyce e Donald Chamberlin, SQL foi lançada comercialmente pela Relational
Software Inc. (agora conhecido como Oracle Corporation) em 1979. A versão SQL
padrão atual é voluntária e monitorada pela American National Standards Institute
(ANSI). A maioria dos principais fornecedores também têm versões proprietárias que
são incorporadas e construídas em ANSI SQL, por exemplo, SQL * Plus (Oracle), e
Transact-SQL (T-SQL) (Microsoft).
1.4.
Controle de Versão
O controle de versão combina procedimentos e ferramentas para gerenciar
diferentes versões dos objetos de configuração criados durante o processo de
software. Um sistema de controle de versão implementa ou está diretamente
integrado com quatro recursos principais: (1) um banco de dados de projeto
(repositório) que armazena todos os objetos de configuração relevantes, (2) um
recurso de gestão de versão que armazena todas as versões de um objeto de
configuração (ou permite que qualquer versão seja construída usando diferenças das
versões anteriores), (3) uma facilidade de construir que permite coletar todos os
objetos de configuração relevantes e construir uma versão especifica de software.
Além disso, os sistemas de controle de versão e controle de alteração muitas vezes
implementam um recurso chamado “acompanhamento de tópicos” (também
conhecido como acompanhamento de bug), que permite à equipe de software
19
registrar e acompanhar o status de todos os problemas pendentes associados com
cada objeto de configuração (Pressman, 2009).
Um controle de versão tem basicamente dois objetivos. Em primeiro lugar, ele
deve guardar a cada versão de cada arquivo armazenado nele e garantir acesso a ela.
Tais sistemas também fornecem uma forma de associar metadados – isto é,
informação que descreve os dados armazenados – a cada arquivo ou grupo de
arquivo. Em segundo lugar, ele permite que equipes distribuídas no tempo e espaço
colaborem (Humble, 2014).
Segundo Pressman (2009), durante as últimas décadas foram propostas muitas
abordagens automáticas diferentes para o controle de versão. A diferença primaria
entre as abordagens é a sofisticação dos atributos usados para construir versões
específicas e variantes de um sistema e os mecanismos do processo de construção.
A Figura 4 mostra a esquematização de funcionamento básico de um software
para controle de versão. Como pode ser observado, existem 2 funções básicas em um
servidor SVN: Commit e Update. Commit, conforme Ben (2009), é o comando
responsável por publicar alterações para qualquer número de arquivos e diretórios
como uma única transação atômica. Em sua cópia de trabalho, você pode alterar o
conteúdo de arquivos, criar, apagar, renomear e copiar arquivos e diretórios, e depois
fazer o “commit” do conjunto completo de alterações em uma transação atômica. Já
Update, é o comando responsável por atualizar a cópia de trabalho local, de acordo
com o que está disponível no servidor SVN.
20
Figura 4 – Esquema de funcionamento básico de um software de controle de versão.
Fonte – Autor
21
2. MATÉRIAS, TÉCNICAS E MÉTODOS
Para que a rotina fosse implementada, foram necessárias algumas ferramentas
essenciais, tanto para aumento na produtividade quanto para melhor organização no
desenvolvimento. O ambiente de desenvolvimento foi composto pelas seguintes
ferramentas: TOTVS | Developer Studio 11.2, SGBD Microsoft SQL Server e
Tortoise SVN.
2.1.
Processo de Desenvolvimento
Nesta seção serão descritas informações referente ao processo de
desenvolvimento como um todo durante. Serão abordados os seguintes tópicos:
Cronograma, Equipe, Reuniões e Testes.
2.1.1 Cronograma
De acordo com as exigências do fornecedor, e devido à necessidade do
mapeamento das necessidades do projeto, foi desenvolvido um cronograma,
conforme Tabela 1, onde estão especificadas as seguintes informações: Índice
(Ordem da Atividade), Atividade, Início e Término respectivamente.
Indice
1
2
3
4
5
6
7
8
Atividade
Definir local para geração dos arquivos
Instalar o conector Accera
Desenvolver rotina
Adicionar possibilidade de geração manual
Programar geração automática
Realizar os testes de geração especificados
Enviar via email os arquivos gerados para validação
Implantar o processo em ambiente de Produção
Inicio
18/01/2016
25/01/2016
01/02/2016
01/03/2016
07/03/2016
14/03/2016
28/03/2016
04/04/2016
Término
23/01/2016
30/01/2016
29/02/2016
05/03/2016
12/03/2016
26/03/2016
31/03/2016
08/04/2016
Tabela 1 – Cronograma de Execução das atividades do projeto. Fonte – Autor.
22
2.1.2. Equipe
A equipe envolvida no desenvolvimento e homologação do projeto, foi
composta por 5 (cinco) pessoas. Sendo que dessas cinco, 2 (duas) são funcionários da
Agro Amazônia (Programadores responsáveis pela análise e desenvolvimento da
rotina - incluindo o autor deste trabalho) e as outras 3 (três) são funcionários da
empresa Accera, que somente ficaram incumbidos de prestar suporte desde o inicio
do projeto para eventuais duvidas e foram os responsáveis pela homologação/teste
final dos arquivos gerados.
2.1.3. Reuniões
Por fins de alinhamento e verificação do andamento do projeto, eram
realizadas reuniões semanais da equipe envolvida juntamente com a gerente de
Tecnologia da Agro Amazônia. Não foram utilizadas metodologias de gerenciamento
de projetos mas nessas reuniões, a pauta principal era verificação do progresso do
projeto e identificação de possíveis “fugas” do foco principal que poderiam ocorrer
no decorrer do desenvolvimento.
2.1.4. Testes
Para verificação da integridade e boa qualidade das informações geradas pela
nova rotina em desenvolvimento, foram projetados vários testes em ambiente de
homologação, além daqueles já propostos no documento de Layout Enviado
(Anexos). Dentre eles estão: Geração dos arquivos manualmente e tentativa de
importação na ferramenta Accera, Geração dos arquivos automaticamente e tentativa
de importação na ferramenta Accera, Geração de Todos os arquivos e tentativa de
importação na ferramenta Accera, Geração de Todos os Arquivos em Períodos
diferentes e tentativa importação na ferramenta Accera, Geração de Arquivos
intercalados e tentativa de importação na ferramenta Accera. Caso o resultado de
todos esses testes fossem positivos, a homologação seria validada.
23
2.2. TOTVS | Developer Studio 11.2
O TOTVS | Development Studio é um ambiente de desenvolvimento
integrado (IDE) que permite editar, compilar e depurar programas, escritos na
linguagem AdvPL.
Como ferramenta de edição, engloba todos os recursos disponíveis nas
melhores ferramentas de desenvolvimento do mercado. Já como ferramenta de
depuração, dispõe de ações básicas de depuração (percorrer linha, pular linha,
executar, seguir até o retorno, pausar execução e derrubar client, etc.)., permitindo ao
usuário executar e depurar suas rotinas de dentro de seu ambiente integrado,
inspecionando o ambiente de execução de suas rotinas através de diversas janelas de
informações, como variáveis (divididas entre variáveis locais, públicas, privadas e
estáticas), expressões em watch, tabelas, índices e campos, breakpoints, programas
registrados (inspetor de objetos) e pilha de chamadas. Além disso, os programas
criados são compilados diretamente no TOTVS | Development Studio, onde são
mantidos em projetos e grupos de projetos.
Os grupos de projetos facilitam a compilação de um ou mais projetos de
arquivos, utilizando conceitos de repositórios e diretivas de compilação,
possibilitando inclusive a manutenção de bibliotecas de rotinas do usuário.
24
Figura 5 – Tela Principal do TOTVS | Development Studio
Conforme ilustrado na Figura 5, o IDE foi construído sob a plataforma
Eclipse (https://eclipse.org/), que é uma ferramenta de uso geral configurável e
extensível para várias tarefas. O funcionamento é praticamente o mesmo de quando o
utilizamos para desenvolvimento em Java ou outras linguagens por ele suportadas.
2.3. SGBD Microsoft SQL
Um SGBD (sistema de gerenciamento de banco de dados) é um programa que
gerencia os dados, geralmente utilizando uma linguagem para isso (SQL).
O SQL Server (www.microsoft.com/SQL) é um SGBD da Microsoft, criado
em parceria com a Sybase (http://www.sybaseproducts.com/), em 1988, inicialmente
como um complementar do Windows NT, sendo que depois passou a ser
aperfeiçoado e vendido separadamente. A parceria com a Sybase terminou em 1994,
e a Microsoft continuou a melhorar o programa após isto.
25
Basicamente, o SQL Server é um banco de dados relacional que, por
definição possui as seguintes principais características básicas (Jobstraibizer,2009):
As informações devem ser representadas de uma única forma, como
Todo dado pode ser acessado logicamente, usando o nome da tabela, o
dados em uma tabela;
valor da chave primária e o nome da coluna (é preferível sempre
trabalhar com os índices de chave primária e nomes de colunas e
tabelas para melhor desempenho do banco de dados);
Os valores nulos, (diferentes de zero, de uma string vazia e outros
valores não nulos), existem para representar dados não existentes de
forma física e independente do tipo de dado;
Suporta várias linguagens e formas de uso, porém, deve possuir ao
menos uma linguagem com sintaxe bem definida e expressa por cadeia
de caracteres e com habilidade de apoiar a definição de dados, a
definição de views, a manipulação de dados, as restrições de
integridade, e a autorização de transações;
Os programas de aplicação ou atividades de terminal permanecem
logicamente inalterados, quaisquer que sejam as modificações na
representação de armazenagem, ou métodos de acesso internos ou
mudanças de informação que permitam teoricamente a não alteração
das tabelas-base;
As relações de integridade, especificas de um banco de dados
relacional, devem ser definidas em uma sub-linguagem de dados e
armazenadas no catálogo de dados (e não em programas);
A linguagem de manipulação de dados deve possibilitar que as
aplicações permaneçam inalteradas, estejam os dados centralizados ou
distribuídos fisicamente.
Esse SGBD é dos mais usados no mundo atualmente, tendo como
competidores sistemas como o MySQL e Oracle. O mesmo possui versões gratuitas e
pagas. Este programa é bastante usado em sites, onde são necessários cadastros, e
também em sistemas de lojas, onde são lançados os produtos, o preço, marca entre
outras informações.
26
Segundo
pesquisas
realizadas
pelo
site
“DB-Engines”
(http://db-
engines.com/en/ranking), o SQL Server é considerado um dos 3 mais populares
SGBD’s do mercado (Figura 6), entretanto está perdendo espaço para o MySQL, pois
o MySQL tem código livre, e não tem custo nenhum. Um dos problemas do SQL
Server é a dificuldade encontrada, em algumas versões, de suporte para programas de
outras empresas, e a dificuldade de instalar o programa em outros Sistemas
operacionais, que não sejam o Windows.
Conforme ranking ilustrado abaixo (Figura 6), podemos observar que desde
março/2015, todos os 5 primeiros SGBD’s relacionais (“Database Model”)
manteram suas posições (“Rank”) levando em consideração o nível de popularidade
de cada um (“Score”).
Figura 6 – Ranking que classifica os SGBD’s de acordo com sua popularidade.
Fonte - DB-Engines
2.4. Tortoise SVN
Tortoise SVN é um software gratuito sob a licença GLP (General Public
License) para controle de versão arquivos, para plataforma Windows. Ele é baseado
no ApacheTM Subversion (SVN) ® e fornece uma interface fácil e amigável para o
usuário.
Como o mesmo não tem nenhum tipo de integração com um IDE especifico, é
possível utiliza-lo com quaisquer ferramentas de desenvolvimento e qualquer tipo de
arquivo.
Neste trabalho, o versionamento de código foi utilizado para controle do
andamento do projeto e prevenção de perca/alteração indevida das funções
envolvidas. Diariamente, ao iniciar o expediente de trabalho, era realizado o
27
“Update”(Atualização) do projeto no computador, para evitar divergências. E, após a
conclusão do dia (fim do expediente) e novas implementações realizadas, era
realizado o “Commit”(Envio) dessas novas implementações para o servidor do SVN
para atualização do arquivo que lá estava, mantendo a integridade do ambiente de
desenvolvimento.
28
3. RESULTADOS
Com o surgimento da necessidade para desenvolvimento de uma rotina
especifica para a exportação de arquivos, foi observado que poderia melhorar a
funcionalidade da mesma e criar um produto mais robusto e completo, e que pudesse
ser reutilizado para outras atividades em momentos oportunos. Atualmente no
sistema padrão, não existe rotina ou processo configurável que possa atender essa
demanda da maneira que foi proposta. Dessa forma, foi necessária a customização,
tanto para atender o que foi solicitado, quanto para otimizar o trabalho da pessoa
responsável que iria coletar tais informações de forma manual e trabalhosa. A rotina
de exportação, a priori, será utilizada somente pelo departamento de Tecnologia de
Informação da Agro Amazônia pois, como se trata de uma ferramenta que trabalha
com dados importantes e sigilosos, tais como informações valores de vendas, saldos
de estoque, cadastros de clientes/filiais entre outros. Por esse motivo, a gerência da
empresa decidiu que o cenário seria este até segunda ordem.
Basicamente, a rotina de exportação gera um arquivo texto (padrão ANSI), na
modalidade linha versus coluna, contendo informações relevantes dos produtos e
operações realizadas que estiverem relacionadas ao fornecedor “Bayer”. De acordo
com o manual de layout enviado pelo fornecedor, devem ser gerados 6 tipos de
arquivos com informações distintas, tais como: Cadastro de Produtos, Cadastro de
Lojas/Filiais, Posição de Estoques, Vendas ao Cliente, Cadastro de Clientes e Notas
Fiscais Recebidas. No referido manual de layout, o fornecedor esclarece todos os
parâmetros necessários para o efetivo funcionamento da rotina, bem como o
detalhamento das informações que devem estar contidas em cada arquivo. A estrutura
dos arquivos a serem gerados, bem como o dicionário de dados detalhado, será
exposta na seção de “Anexos”.
Atualmente, para facilitar e organizar o desenvolvimento, o processo de
geração dos arquivos está divido em duas rotinas acessíveis: “Configuração Arquivos
Txt” (AFAT0186) e “Gera Arquivos Txt Bayer” (PFAT0185) conforme apresentado
na Figura 7 e uma rotina auxiliar “PFAT0190”.
29
Figura 7 – Rotinas criadas e adicionadas ao menu do sistema
O conjunto dessas 3 (três) rotinas citadas, formam o processo completo
referente à proposta deste trabalho. Abaixo serão abordadas as especificidades e
funcionalidades de cada rotina detalhadamente.
3.1. Configuração da Estrutura dos Arquivos (AFAT0186)
Primeiramente temos a rotina “AFAT0186” (nomenclatura formada por
definição interna da Agro Amazônia, onde “A” significa “Atualizações” (ex. Tela),
“FAT” refere-se ao módulo relacionado, no caso “Faturamento”, e “0186” é uma
sequência numérica interna), conforme código listado no Apêndice I, a mesma é
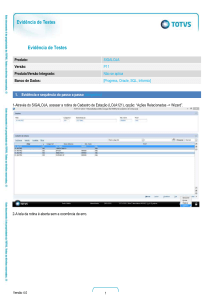
responsável basicamente pela construção da tela de configuração dos arquivos
(Figura 8). Ao abrir a rotina, é exibida uma tela onde estão disponíveis as funções
básicas de um CRUD (Create, Read, Update e Delete - Criação, Leitura, Alteração e
Remoção). Assim, a tela exibirá (caso existam registros previamente incluídos) a lista
dos registros. Ainda é possível fazer filtros, consultas e até mesmo impressão sobre a
lista de registros.
30
Figura 8 – Tela criada referente a rotina AFAT0186
O programa está estruturado no padrão MVC (model, view, controller) e
utiliza as propriedades básicas de identação e comentários em seu código.
Tecnicamente, será criada uma tela comum e nela é possível a criar relacionamentos
linha (detalhe) versus coluna (header). Ou seja, em cada coluna referente ao
“registro”, poderemos ter várias linhas relacionadas aos “itens de registro” (conforme
Figura 9). Quando a função “Imprimir” for utilizada, a tela de seleção de impressora
será aberta, e serão impressos somente os cabeçalhos dos arquivos configurados, caso
existam.
31
Figura 9 – Exemplo de Configuração de um arquivo a ser gerado
Para
configuração do
“Registro”
(Quadrante
superior
selecionado),
precisamos informar a “Descrição” e inserir o “Script Sql”, que nada mais é a
consulta que será realizada no banco de dados, de acordo com a necessidade do
arquivo, que será utilizado pelos “Itens do Registro” posteriormente relacionados
(Figura 10).
32
Figura 10 – Exemplo de Inserção do Script Sql de um determinado registro
Já para configuração dos “Itens de Registro” (Quadrante inferior selecionado),
precisamos informar “Descrição”, “Tipo do Item” (Caractere, Numérico ou Data),
“Tamanho”, “Conteúdo” e o “Tipo do Conteúdo” (valor informado, campo registro
ou macro). É necessário detalhar que o “Tipo de Conteúdo” determinará como os
dados serão buscados para alimentação dos arquivos. Quando for “Valor Informado”,
o que for inserido no “Conteúdo” será levado para o arquivo. Quando for “Campo
Registro”, será utilizado o script SQL inserido anteriormente no “Registro”, levando
em consideração que o que for informado no “Conteúdo” será considerado a coluna
do script. Quando for “Macro”, serão considerados os resultados de funções e/ou
expressões diretamente informadas no “Conteúdo”.
33
3.2. Geração dos Arquivos (PFAT0185)
Posteriormente, temos a rotina “PFAT0185” (nomenclatura formada por
definição interna da Agro Amazônia, onde “P” significa “Processamento”, “FAT”
refere-se ao módulo relacionado, no caso “Faturamento”, e “0185” é uma sequência
numérica interna), conforme código listado no Apêndice II, que é responsável pelo
processamento propriamente dito referente à geração do arquivo. Nela estão
concentradas todas as funções de consulta, processamento e controle que serão
necessárias para o processamento correto e seguro dos dados. Esta rotina é composta
por basicamente 10 funções: Validação do tipo de geração (Scheduler ou Manual),
Pesquisa dos arquivos a serem gerados (cadastrados anteriormente na rotina
AFAT0186), Pesquisa dos registros (seguindo estrutura configurada), Pesquisa das
colunas, Geração do Arquivo .TXT, Execução de Script SQL, Envio de e-mail
(Figura 11), Retorno do mês por extenso e parâmetros que serão exibidos para o
usuário antes da geração. Abaixo segue breve descrição da funcionalidade de cada
uma das funções:
Validação do tipo de geração: Função responsável por fazer a
verificação da origem da geração dos arquivos: Scheduler ou
Manual;
Pesquisa dos arquivos a serem gerados: Função responsável pela
Pesquisa dos registros: Função responsável pela pesquisa dos
Pesquisa das colunas: Função responsável pela pesquisa das
Geração do Arquivo .TXT: Função responsável pela geração
pesquisa dos arquivos (previamente configurados), para geração;
registros relacionados ao arquivo que será gerado;
colunas relacionadas ao arquivo que será gerado;
propriamente dita do arquivo texto;
34
Execução de Script SQL: Função responsável por fazer o
Envio de e-mail: Função responsável pelo envio de email
Retorno do mês por extenso: Função auxiliar para retorno do mês
Parâmetros que serão exibidos para o usuário antes da geração:
processamento do script SQL, caso exista no registro em corrente;
relacionado a geração do arquivo (sucesso, falha e lembrete);
corrente por extenso;
Parâmetros que serão exibidos ao usuário, caso seja feita execução
manual.
No Protheus existe a possibilidade de adicionar uma rotina para que seja
executada automaticamente em determinada data e horário especificados. Para isso, é
necessário configurar a rotina em uma rotina especifica (Scheduler) e em um módulo
especifico (SIGACFG) do sistema, conforme Figura 12. Para configuração do
agendamento, é necessário informar: Usuário responsável, Nome da rotina, Data de
Inicio, Hora de Inicio, Empresa/Filial e Módulo do Sistema.
Figura 11 – Exemplo de E-mail enviado após execução com Sucesso da rotina
35
Figura 12 – Exemplo de Configuração da rotina pelo agendador (Scheduler)
3.3. Rotina Auxiliar (PFAT0190)
E por fim, sendo considerada como uma rotina auxiliar, temos a “PFAT0190”
(conforme código listado no Apêndice III). Esta rotina é utilizada para garantir a
integridade dos dados processados e o bom funcionamento da geração dos arquivos
que envolvem os dados da empresa/filiais. Basicamente, a rotina fará o
posicionamento correto no cadastro da empresa/filial correta. Dessa forma, essa
rotina será apenas instanciada dentro do cadastro do registro (feito na rotina
“AFAT0186”), não havendo nenhuma interação transparente com o usuário
(conforme Figura 13).
36
Figura 13 – Exemplo de uso da rotina PFAT0190
3.4. Estruturação das Rotinas
Da forma que as rotinas foram estruturadas, cada função está de alguma
forma “conectada” com as demais. A Figura 14, situada abaixo, ilustra o fluxo
simplificado do relacionamento entre as funções:
37
Figura 14 – Fluxo Padrão Simplificado destacando o relacionamento das funções
Conforme podemos observar, as funções implementadas pelas rotinas estão
intimamente ligadas, causando um nível alto de dependência entre elas. Sendo assim,
e necessário que todas as etapas do processo sejam seguidas corretamente para que o
produto final seja gerado de forma integra e confiável. Podemos ainda, para facilitar a
compreensão do fluxo (Figura 14), dividir a totalidade do processo em dois grandes
grupos: Configuração do Layout e Geração do Arquivo. Onde, podemos definir o
grupo “Configuração do Layout” sendo integrado pelas seguintes funções:
“MontaTela()”, “ConfiguraLayout()” e “PFAT0190()” (como função auxiliar). Por
38
outro lado, relacionado ao grupo “Geração do Arquivo” podemos integrar as funções:
“BuscaLayout()”, “PesquisaRegistros()”, “GeraArquivo()” e “EnviaEmail()”.
39
4. DIFICULDADES ENCONTRADAS
No decorrer do desenvolvimento deste trabalho, foram encontradas algumas
dificuldades que, no mínimo, atrasaram certas etapas do projeto. A rotatividade da
equipe responsável pela validação do arquivo gerado por parte da Accera - Bayer
(fornecedor) e a falta de uma comunicação direta com os mesmos, trouxe morosidade
ao projeto.
A equipe de validação, responsável pela posterior análise dos arquivos
gerados pela rotina que é objeto deste trabalho, foi alterada 4 vezes devido a questões
internas da empresa. Devido a isso, a cada alteração da equipe, era necessário
reiniciar o processo de validação e verificação. Após a 4ª troca, a equipe se
estabilizou e conseguimos dar prosseguimento eficaz nesta etapa.
A linguagem utilizada para desenvolvimento (ADVPL), é considerada
também como uma dificuldade, pois foi necessário um estudo mais aprofundado
sobre as funções e técnicas de desenvolvimento disponíveis para uso. Técnicas
consideradas como “melhores práticas” foram estudadas e utilizadas, mas
demandaram tempo de pesquisa e aprendizado.
Em se tratando da comunicação, toda interação que era necessária com a
equipe de validação, somente poderia ser feita via e-mail (exigência do fornecedor), e
isso, por muitas vezes, ocasionou falha no entendimento e perca de tempo
desnecessário. Após vários debates e reuniões, foram disponibilizados dois novos
canais de comunicação, que agilizaram o processo e otimizaram o tempo produção, o
telefone e o comunicador Skype.
40
5. CONCLUSÕES
A demanda por informações e melhoria de processos, vem aumentando
progressivamente de acordo com o avanço da tecnologia e da competitividade do
mercado. Com isso, empresas, fornecedores e os demais envolvidos nessa imensa
rede, cada vez mais buscam maneiras de verificar o andamento de suas transações e
com base nessas informações, criar mecanismos para minimizar os impactos e/ou
melhorar o rendimento daquele processo. Este trabalho em especial, trata de uma
exigência de um dos fornecedores da empresa Agro Amazônia, denominado Accera –
Bayer. As informações contidas nos arquivos gerados, serão de grande valia para o
fornecedor e consequentemente para a empresa.
A primeira fase trata-se da configuração dos arquivos que serão gerados
(AFAT0186), baseada no layout enviado pelo fornecedor. Nesta rotina serão
configurados os dados que serão extraídos, bem como a estrutura do arquivo a ser
gerado. Dessa forma, o utilizador deverá se atentar para o tipo de informação que está
extraindo do banco de dados e se a estrutura do arquivo está de acordo com o
pretendido.
A segunda fase refere-se à geração propriamente dita do arquivo
(PFAT0185). Levando em consideração a configuração dos arquivos previamente
realizada, esta rotina irá fazer tanto o processamento dos registros e das informações
que deverão estar carregadas, quanto a geração do arquivo físico. E ainda se tratando
da geração, a rotina está preparada para ser incluída em um “Scheduler” (agendador)
para que seja executada automaticamente sem necessidade de intervenção nenhuma
do usuário.
Como plano futuro, para facilitar a configuração dos arquivos, bem como
diminuir a complexidade dos relacionamentos, está em estudo o desenvolvimento de
uma forma mais intuitiva e simples de configuração e seleção das informações que
serão geradas. Dessa forma poderemos liberar, caso necessário, o uso para usuários
comuns da empresa, não somente restringindo para o departamento de Tecnologia.
41
6. REFERÊNCIAS BIBLIOGRÁFICAS
COLLINS-SUSSMAN, Ben; FITZPATRICK, Brian W.; PILATO, C. Michael.
Subversion 1.6 Official Guide: Version Control with Subversion, Fultus Corporation,
2009.
DATE, C. J. Introdução a Sistemas de Bancos de Dados, Editora Campus, Oitava
Edição, 2003.
ELMASRI, Rames; NAVATHE, Shamkant. Sistemas de banco de dados, Editora
Pearson, Sexta Edição, 2010.
HUMBLE, Jez; FARLEY David. Entrega Continua: Como entregar software de
forma rápida e confiável, Editora Bookman, 2014.
JOBSTRAIBIZER, Flavia. Guia Profissional Microsoft SQL Server 2008, Editora
Digerati Books, 2009.
KRETCHMAR, James M.. Open Source Network Administration, Editora Prentice
Hall Professional, 2004.
OLIVEIRA, Celso H. P. SQL – Curso Prático, Novatec Editora Ltda, 2002, São
Paulo-SP.
ONISHI, Rogério. Lógica de Programação ADVPL em 7 Passos, 2015.
PRESSMAN, Roger S.. Engenharia de Software, Editora AMGH, 2009.
RAMAKRISHNAN, Raghu; GEHRKE, Johannes. Sistemas de Gerenciamento de
Banco de Dados, AMGH Editora, Terceira edição, 2008.
REISSWITZ, Flavia. Análise De Sistemas Vol X, 2009.
42
SANTOS, Rafael. Introdução à Programação Orientada a Objetos Usando Java,
Editora Elsevier Brasil, Segunda Edição, 2015.
SILVA, Matheus. SQL Server. Disponível por www em http://www.computers.com/pt/conselho-672518.htm (acessado em 19 de março de 2016).
SILVA,
Matheus.
TDS
Versão
11.2.
Disponível
por
www
em
http://tdn.totvs.com/pages/viewpage.action?pageId=23200029 (acessado em 12 de
fevereiro de 2016).
TECHOPEDIA. Structured Query Language (SQL). Disponível por www em
https://www.techopedia.com/definition/1245/structured-query-language-sql (acessado
em 04 de abril de 2016).
43
ANEXOS
Anexo I – Layout para configuração dos arquivos
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
APÊNDICES
APÊNDICE I – Rotina AFAT0186
73
74
APENDICE II – Rotina PFAT0185
75
76
77
78
79
80
81
82
83
84
APENDICE III – Rotina PFAT0190
85